基于深度网络视频编解码的后处理优化方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及视频编解码技术领域,特别涉及一种基于深度网络视频编解码的后处理优化方法。
背景技术
HEVC是一种新的视频压缩标准,用来替代H.264/AVC编码标准,2013年1 月26号,国际电信联盟电信标准化部门(ITU-T)正式批准HEVC成为新一代国际视频编解码标准。其目标是通过融合最新的技术和算法来达到在保证视频质量的基础上,压缩效率比H.264高一倍的目的,满足人们对高清以及超高清视频的需求。随着科技进步,各学科的交叉研究得到较为广泛的关注,随着深度学习的飞速发展,基于深度学习的视频编解码后处理也取得了不错的成果。 2020年,提出了基于STDF(Spatio-Temporal Deformable Fusion,时空可变融合技术)和QE(Qual ity Enhancement,图像质量提升)两个神经网络来进一步针对H.265/HEVC解码后的视频序列做后处理增强。但是当下STDF网络和QE网络均较为复杂,层次较深,无法满足实时应用的需求,因而不能在业界得到推广。
发明内容
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于深度网络视频编解码的后处理优化方法,能够在具有较好的图像后处理增强质量的情况下,简化模型结构,缩短神经网络卷积计算时间,降低算法复杂度,提升对码流中存在的解码信息的利用率,满足应用的实时需求。
本发明还提出一种基于深度网络视频编解码的后处理优化系统。
本发明还提出一种具有上述基于深度网络视频编解码的后处理优化方法的基于深度网络视频编解码的后处理优化装置。
本发明还提出一种计算机可读存储介质。
一方面,本实施例提供了一种基于深度网络视频编解码的后处理优化方法,包括:
读取解码图像,在时空可变融合模块中对所述解码图像进行偏移量预测,所述偏移量预测包括对所述解码图像进行两次下采样和两次上采样,以得到第一偏移量;
获取参考帧的运动矢量;
根据所述运动矢量和第一偏移量计算得到第二偏移量;
将所述第二偏移量用可变卷积计算得到特征图,使用图像质量提升模块处理所述特征图以得到残差图,将所述残差图加到所述解码图像以得到图像质量增强的所述解码图像。
根据本发明实施例的基于深度网络视频编解码的后处理优化方法,至少具有如下有益效果:读取解码图像,在时空可变融合模块对解码图像进行偏移量预测,时空可变融合模块主要可以包括偏移量预测单元和时空可变卷积单元,在偏移量预测单元中对解码图像进行偏移量预测,偏移量预测包括对所述解码图像进行两次下采样和两次上采样,以得到第一偏移量,再获取运动矢量信息,根据运动矢量和第一偏移量计算得到第二偏移量,运动矢量可以反映像素点的运动情况,所以可以用运动矢量来预测偏移量的大体范围,然后通过简化后的时空可变融合模块在运动矢量附近寻找第二偏移量,第二偏移量即为运动矢量附近较佳的偏移量,本实施例能够有效降低算法复杂度,缩短神经网络卷积计算时间,提升了对码流中存在的解码信息的利用率,满足应用的实时需求。
下采样用于将搜索范围扩大,便于更准确的找到快速运动物体的偏移量,上采样用于将找到的偏移量还原到所述解码图像。相较于常规的3次上下采样的操作,本实施例只有两次上下采样操作,能有效降低算法复杂度,缩短了神经网络卷积计算时间,结合运动矢量来预测偏移量的大体范围,能够在有效降低算法复杂度、缩短了神经网络卷积计算时间的同时,使图像后处理增强质量保持在较优的水平。
根据本发明的一些实施例,所述图像质量提升模块包括输入层和输出层。常规的STDF网络结构中QE模块一共包含8层,含1层输入、1层输出和6层隐藏层,由于并不是卷积层深度越深,整体的后处理质量性能就会呈线性大幅增加,所以本实施例简化QE模块是通过直接去掉中间的隐藏层,只保留输入层和输出层,以此来简化QE模块,大幅降低QE模块的计算量,还能较好的保障后处理图像增强质量,能够有效降低模型的复杂程度,大幅减小运算量,节约神经网络卷积计算时间,具有非常好的应用价值。
根据本发明的一些实施例,所述运动矢量从视频解码器输出的码流信息中提取。常规的后处理过程和HEVC自身解码过程相对独立,在后处理质量增强的网络计算中,没有较好的利用解码信息来进行简化模型,提高深度网络质量、提升性能。本实施例中从解码信息中提取出参考帧的运动矢量,再结合第一偏移量计算得到第二偏移量,第二偏移量即为运动矢量附近较佳的偏移量,将运动矢量加入到偏移量预测网络中,降低偏移量搜索难度,以此降低STDF模块复杂度的同时,能够较好的利用解码信息来进行简化模型,有效保障后处理质量性能。
根据本发明的一些实施例,所述使用图像质量提升模块处理所述特征图以得到残差图,包括步骤:对所述特征图经过若干卷积层处理以得到所述残差图。
根据本发明的一些实施例,所述图像质量提升模块包括输入层、输出层和0 至5个隐藏层。常规的STDF网络结构中QE模块一共包含8层,含1层输入、1 层输出和6层隐藏层,每一次网络的维度由48-64层不等,用以提取恢复更深层次的和细节特征,最后得到残差图,将残差图与原始帧相加得到质量增强后的新图像,但是并不是卷积层深度越深,整体的后处理质量性能就会呈线性大幅增加,所以本实施例简化QE模块是通过去掉中间的一层或者多层隐藏层,中间的隐藏层的数量可以是0至5中的任意整数,如隐藏层的数量可以是5,当然也可以是 1、2、3或者4,能够有效降低QE模块的计算复杂量,缩短数据处理时间。
第二方面,本实施例提供了一种基于深度网络视频编解码的后处理优化系统,包括:
时空可变融合模块,包括偏移量预测单元和可变卷积单元,所述偏移量预测单元用于对解码图像进行偏移量预测;
图像质量提升模块,包括输入层、输出层。
根据本发明实施例的一种基于深度网络视频编解码的后处理优化系统,至少具有如下有益效果:基于深度网络视频编解码的后处理优化系统包括时空可变融合模块和图像质量提升模块,时空可变融合模块包括偏移量预测单元和可变卷积单元,所述偏移量预测单元用于对解码图像进行偏移量预测,图像质量提升模块包括输入层、输出层,相较于常规的QE模块的,本实施例去掉了设置在输入层、输出层之间的隐藏层,大幅降低QE模块的计算量,缩短了数据处理的时间,有效提升了数据处理的效率,同时还能基本保持后处理视频增强质量。且本实施例的偏移量预测单元只进行2次上采样和2次下采样,相较于常规的进行三次上下采样的操作,大幅减小了计算量,有效提升了视频后处理图像增强的处理效率,缩短了处理时间,同时还能使图像增强的质量基本保持不变,具有非常好的实用价值。
根据本发明的一些实施例,所述输入层和所述输出层均为卷积层。
第三方面,本实施例提供了一种基于深度网络视频编解码的后处理优化装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的基于深度网络视频编解码的后处理优化方法。
根据本发明实施例的一种基于深度网络视频编解码的后处理优化装置,至少具有如下有益效果:基于深度网络视频编解码的后处理优化装置应用了如第一方面所述的基于深度网络视频编解码的后处理优化方法,能够在图像增强的质量基本保持不变的前提下,大幅减小偏移量预测计算量和图像质量提升的计算量,大幅缩短数据处理的时间,有效提升图像视频后处理的数据处理效率,具有非常好的实用价值。
第四方面,本实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如第一方面所述的基于深度网络视频编解码的后处理优化方法。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中摘要附图要与说明书附图的其中一幅完全一致:
图1是本发明一个实施例提供的基于深度网络视频编解码的后处理优化方法的流程图;
图2是本发明另一个实施例提供的基于深度网络视频编解码的后处理优化方法中的参考帧运动矢量的示意图;
图3是本发明另一个实施例中STDF模块结构示意图;
图4是本发明另一个实施例中简化后的STDF模块结构示意图;
图5是本发明另一个实施例中简化后的STDF模块+运动矢量结构示意图;
图6是本发明另一个实施例中3*3的常规卷积和可变形卷积的采样网格图;
图7是本发明另一个实施例中简化后的图像质量提升模块;
图8是本发明另一个实施例中整体的实验开发环境配置信息图;
图9是本发明另一个实施例中HEVC标准测试序列图;
图10是本发明另一个实施例中随迭代次数训练的模型在验证集上表现的质量增强性能图;
图11是本发明另一个实施例中在测试集上的测试结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
需要说明的是,虽然在系统示意图中进行了功能模块划分,在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于系统中的模块划分,或流程图中的顺序执行所示出或描述的步骤。说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
HEVC是一种新的视频压缩标准,用来以替代H.264/AVC编码标准,2013年 1月26号,国际电信联盟电信标准化部门(ITU-T)的正式批准HEVC成为新一代国际视频编解码标准。其目标是通过融合最新的技术和算法来达到在保证视频质量的基础上,压缩效率比H.264高一倍的目的,以满足人们对高清以及超高清视频的需求。随着科技进步,各学科的交叉研究得到较为广泛的关注,随着深度学习的飞速发展,基于深度学习的视频编解码后处理也取得了不错的成果。202 0年,提出了基于STDF和QE两个神经网络来进一步针对H.265/HEVC解码后的视频序列做后处理增强。但是当下STDF和QE网络均较为复杂,层次较深,无法满足实时应用的需求,因而不能在业界得到推广。并且,当前深度学习后处理网络和H.265/HEVC解码流程相对独立,并不能较好的使用码流中存在的解码信息,从视频编码角度来分析,存在较大的冗余性。
以2020年发表的基于深度网络视频图像质量增强的模型为例,该卷积神经网络由时空变形卷积STDC和质量增强QE两个部分构成。首先在STDC(Spatio-T emporalDeformable Convolution)模块中,需要对当前模型进行3次下采样,使得在相同的搜索步长条件下,实际搜索寻找范围更大,提高卷积偏移量(off set)的精度,完成3次下采样后,在进行3次上采样把偏移量恢复到原始图片大小,得到前后R个相邻帧和当前帧共(2r+1)个帧的偏移量,这些偏移量用于时空可变卷积(Spatio-Temporal Deformable Convolution)的计算,通过时空可变卷积的计算,将当前帧空间和时间上的信息融合得到时空特征图,在经过QE 模块,包含输入、输出、隐藏层共8层的复杂网络,每一次网络的维度由48至 64层不等,用以提取恢复更深层次的和细节特征,最后得到残差图,将次残差图与原始帧相加得到质量增强后的新图像。所以总体上看,该网络存在较高的计算复杂度,耗时较大。并且后处理过程和HEVC自身解码过程相对独立,在后处理质量增强的网络计算中,没有较好的利用解码信息来进行简化模型,提高深度网络质量、提升性能。
本发明提供了一种基于深度网络视频编解码的后处理优化方法,能够减少视频编解码后处理质量增强技术的处理时间,降低计算复杂度,简化网络模型,以满足实时应用的需求,有利于视频后处理技术在业界进一步推广使用。
下面结合附图,对本发明实施例作进一步阐述。
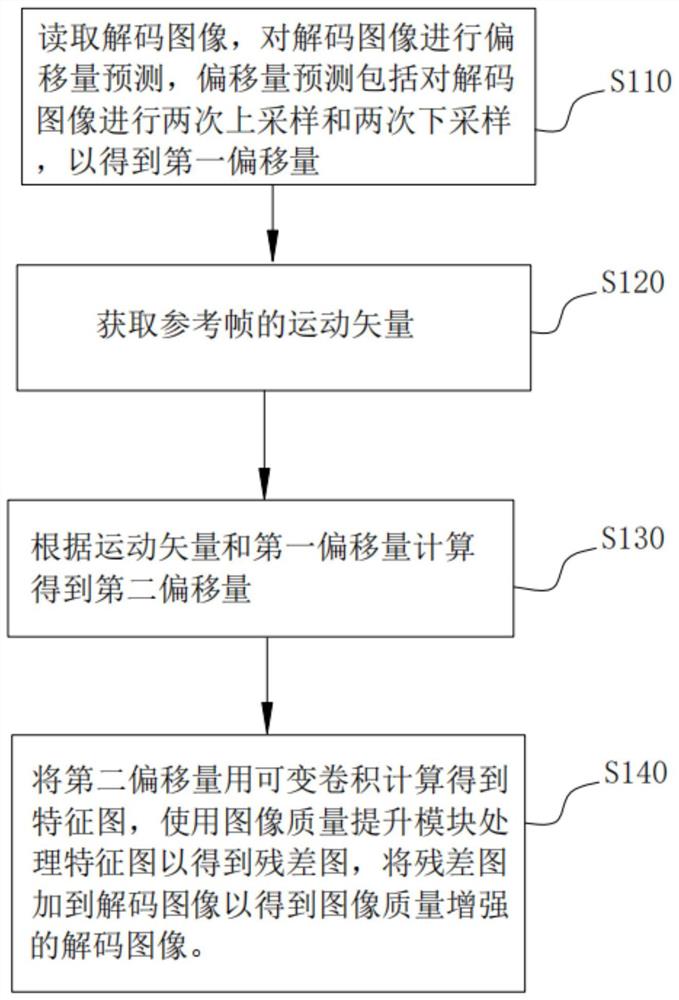
参照图1和图2,图1是本发明一个实施例提供的基于深度网络视频编解码的后处理优化方法的流程图,图2是本发明另一个实施例提供的基于深度网络视频编解码的后处理优化方法中的参考帧运动矢量的示意图,基于深度网络视频编解码的后处理优化方法包括但不仅限于步骤S110至步骤S140。
步骤S110,读取解码图像,对解码图像进行偏移量预测,偏移量预测包括对解码图像进行两次下采样和两次上采样,以得到第一偏移量;
步骤S120,获取参考帧的运动矢量;
步骤S130,根据运动矢量和第一偏移量计算得到第二偏移量;
步骤S140,将第二偏移量用可变卷积计算得到特征图,使用图像质量提升模块处理特征图以得到残差图,将残差图加到解码图像以得到图像质量增强的解码图像。
参考图3、图4和图5,图3是本发明另一个实施例中STDF模块结构示意图;图4是本发明另一个实施例中简化后的STDF模块结构示意图;图5是本发明另一个实施例中简化后的STDF模块+运动矢量结构示意图。
时空可变融合技术是一种新型的视频编码后处理技术,该技术的目的是为了在视频解码端对解码图像进行后处理质量增强,与先前的视频编码后处理质量增强方案不同,先前的方案大多数采用基于光流的运动补偿来消除帧间时间上的运动,光流的计算可能因为解码图像的失真而不准确,所以时空可变融合技术(ST DF)不采用计算光流的方法,而是通过可变卷积(Deformable Convolution)的方式来融合时间和空间的信息,但是,可变卷积(Deformable Convolution)的计算首先需要为卷积核中的每个点寻找最优的水平和垂直2个方向上的偏移量,这个寻找最优偏移量的过程是比较耗时、复杂的。时空可变融合技术(STDF)的STDF 模块采用3次下采样,3次上采样,以及跳连接方式,由近及远,大范围搜索最优的偏移量,搜索到的偏移量用于可变卷积计算,输出特征图,然后QE(Qualit yEnhancement)模块(包含8层卷积层)经过多层卷积层整合STDF模块输出的特征,最后得到残差图230,利用残差网络的思想,将残差图230加到原始图像上得到后处理质量增强后的图像帧。
在一实施例中,为了降低时空可变融合技术(STDF)的整体复杂度,提高后处理速度,本实施例从两个模块出发,即QE模块和STDF模块,对于QE模块,可以考虑减少某些层,在牺牲少量质量性能的情况下,降低网络的复杂度;对于S TDF模块,可以简化搜索偏移量的过程,然后通过加入码流中的运动矢量信息,帮助降低STDF模块的复杂度的同时,减少质量性能的损失。
在一实施例中,首先,读取解码图像,对解码图像进行偏移量预测,包括对解码图像进行2次上采样和2次下采样,以及跳连接方式,由近及远,大范围搜索最优的偏移量,以得到第一偏移量,相较于常规的3次上采样和3次下采样的操作,本实施例的寻找偏移量的过程更为简单,能够有效缩减数据处理的过程。但是,只进行2次上下采样的操作,搜索到的偏移量精度相应的会下降,后处理质量增强性能也会下降,所以为了弥补质量性能的损失,本实施例从视频解码器输出的码流信息中提取运动矢量(MV)信息,运动矢量(MV)表示当前帧与参考帧在时间上的运动方向和大小,类似于光流,但是由于MV是基于块的,所以精度没有光流那么高,但是基本上可以反映像素点的运动情况。所以可以用MV来预测偏移量的大体范围,然后通过简化后的STDF模块在MV附近寻找最优的偏移量,用于改善简化后的STDF模块由于减少1次下采样导致的搜索精度不足的问题。
根据第一偏移量和运动矢量进行偏移量预测获得第二偏移量,将第二偏移量用可变卷积计算得到特征图,使用图像质量提升模块处理特征图以得到残差图2 30,将残差图230加到解码图像以得到图像质量增强的解码图像。
需要说明的是,对解码图像的偏移量预测也不仅限于2次上下采样,也可以是1次上下采样,能实现偏移量预测即可,本实施例对其不构成限制。
参考图6,图6是本发明另一个实施例中3*3的常规卷积和可变形卷积的采样网格图。
可变卷积是给常规卷积的每个网格采样点添加2维的偏移量,使得2维卷积不再采用固定的位置做卷积计算,而是可以使用任意位置的采样点做卷积。
具体来说,2维卷积由两部分组成:
(1)在输入的特征图X上使用常规的采样网格R进行采样;
(2)所有采样值通过W加权后求和。
比如R={(-1,-1),(-1,0),(-1,1),(0,-1),(0,0),(0,1),(1,-1),(1,0), (1,1)}定义了一个常规的3*3采样网格。对于输出特征图y中任意位置p0处的值y(p
可变卷积用偏移量{Δp
因此,可变卷积由于增加了偏移量Δp
偏移量预测网络通过学习的方式学习到偏移量Δp
其中MV是从解码器输出的码流信息中提取出来的,Δp′
下面介绍MV的提取过程,由于编码器采用前向预测的原因,码流信息中只能提取出当前帧前面某一帧参考帧的MV信息,其余的前面(R-1)个参考帧的MV 根据解码出来的参考帧的位置和MV信息按比例推算,当前帧后面的R个参考帧由于相距编码器使用的参考帧太远,按比例推算的MV没有太多参考价值,所以统一用0填充。如图2所示的结构,除了解码器提取出来的已知参考帧t0-1的M V,其他参考帧的MV(MV
参考图7,图7是本发明另一个实施例中简化后的图像质量提升模块。
在一实施例中,图像质量提升模块包括输入层210和输出层220,常规的S TDF网络结构中QE模块一共包含8层,含1层输入、1层输出和6层隐藏层,由于并不是卷积层深度越深,整体的后处理质量性能就会呈线性大幅增加,所以本实施例简化QE模块是通过直接去掉中间的隐藏层,只保留输入层21和输出层 220,以此来简化QE模块,大幅降低QE模块的计算量,还能较好的保障后处理图像增强质量,能够有效降低模型的复杂程度,大幅减小运算量,节约神经网络卷积计算时间,具有非常好的应用价值。
本实施例对QE模块和STDF模块的网络都做了简化,降低了STDF技术的整体复杂度。具体来说,对QE模块做了模型压缩,即将原来的8层卷积层压缩为 2层卷积层;对STDF模块,简化了偏移量预测网络,将原来3次上下采样简化为2次上下采样,同时为了弥补简化后带来的偏移量预测精度损失较大导致的后处理质量性能损失也比较大问题,本发明从码流中提取出参考帧的运动矢量(M V),并预测出其他参考帧的MV,然后将MV加入到偏移量预测网络中,降低偏移量搜索难度,以此降低STDF模块复杂度的同时,保障后处理质量性能。
下采样用于将搜索范围扩大,便于更准确的找到快速运动物体的偏移量,上采样用于将找到的偏移量还原到所述解码图像。
在一实施例中,运动矢量是由视频解码器输出的码流信息中提取的。常规的后处理过程和HEVC自身解码过程相对独立,在后处理质量增强的网络计算中,没有较好的利用解码信息来进行简化模型,提高深度网络质量、提升性能。本实施例中从解码信息中提取出参考帧的运动矢量,再结合第一偏移量计算得到第二偏移量,第二偏移量即为运动矢量附近较佳的偏移量,将运动矢量加入到偏移量预测网络中,降低偏移量搜索难度,以此降低STDF模块复杂度的同时,有效保障后处理质量性能。
在一实施例中,特征图经过若干卷积层处理以得到残差图230。图像质量模块包括输入层210和输出层220,输入层210和输出层220都为卷积层,特征图经过图像质量模块处理以得到残差图230。
在一实施例中,输入层210和输出层220之间还包括若干个隐藏层。常规的 STDF网络结构中QE模块一共包含8层,含1层输入、1层输出和6层隐藏层,每一次网络的维度由48-64层不等,用以提取恢复更深层次的和细节特征,最后得到残差图230,将残差图230与原始帧相加得到质量增强后的新图像,但是并不是卷积层深度越深,整体的后处理质量性能就会呈线性大幅增加,所以本实施例简化QE模块是通过去掉中间的一层或者多层隐藏层,中间的隐藏层的数量可以是0至5中的任意整数,如隐藏层的数量可以是5,当然也可以是1、2、3或者4,能够有效降低QE模块的计算复杂量,缩短数据处理时间。
本发明还提供了一种基于深度网络视频编解码的后处理优化系统,包括:
时空可变融合模块,包括偏移量预测单元和可变卷积单元,所述偏移量预测单元用于对解码图像进行偏移量预测;
图像质量提升模块,包括输入层210、输出层220。
在一实施例中,基于深度网络视频编解码的后处理优化系统包括时空可变融合模块和图像质量提升模块,时空可变融合模块包括偏移量预测单元和可变卷积单元,所述偏移量预测单元用于对解码图像进行偏移量预测,图像质量提升模块包括输入层210、输出层220,相较于常规的QE模块的,本实施例去掉了设置在输入层210、输出层220之间的隐藏层,大幅降低QE模块的计算量,缩短了数据处理的时间,有效提升了数据处理的效率,同时还能基本保持后处理视频增强质量。且本实施例的偏移量预测单元只进行2次上采样和2次下采样,相较于常规的进行三次上下采样的操作,大幅减小了计算量,有效提升了视频后处理图像增强的处理效率,缩短了处理时间,同时还能使图像增强的质量基本保持不变,具有非常好的实用价值。
在一实施例中,输入层210和输出层220均为卷积层。
本发明还提供了一种基于深度网络视频编解码的后处理优化装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述的基于深度网络视频编解码的后处理优化方法。基于深度网络视频编解码的后处理优化装置应用了上述的基于深度网络视频编解码的后处理优化方法,能够在图像增强的质量基本保持不变的前提下,大幅减小偏移量预测计算量和图像质量提升的计算量,大幅缩短数据处理的时间,有效提升图像视频后处理的数据处理效率,具有非常好的实用价值。
此外,本发明的一个实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个控制处理器执行,例如,控制处理器能够执行图1中的方法步骤S110至步骤S140。
参考图8、图9、图10和图11,图8是本发明另一个实施例中整体的实验开发环境配置信息图;图9是本发明另一个实施例中HEVC标准测试序列图;图 10是本发明另一个实施例中随迭代次数训练的模型在验证集上表现的质量增强性能图;图11是本发明另一个实施例中在测试集上的测试结果图。
在一实施例中,将基于深度网络视频编解码的后处理优化方法应用在实际的测试平台。
(1)实验环境
本实施例整个模型的训练和测试平台是PC端,使用Ubuntu18.04的操作系统,GPU型号为GeForce RTX 2080,8G显存。采用Anaconda3.5第三方依赖库管理工具构造虚拟的Python3.7开发环境,实验的深度学习框架是Pytorch框架,由于整个实验是需要在GPU上面做训练,所以还需要安装CUDA的驱动程序,此外需要安装其他的依赖库,包括TQDM,LMDB,PYYAML,OPENCV-PYTHON, SCIKIT-IMAGE。视频编解码器使用H.265/HEVC视频编码标准的参考编解码器 HM16.9(HEVC Test Model)。图8展示了整体的实验开发环境配置信息。
(2)实验数据
本发明使用JianingDeng等人在论文“Spatio-Temporal DeformableConvolution for Compressed Video Quality Enhancement”中给出的公开未压缩的130个原始视频序列数据(YUV格式),这些原始视频序列包括了各种分辨率和各种视频内容,它们基本上来自Xiph和VQEG这个两大数据库。本发明选取其中的108个序列作为训练的视频序列集,其余的作为验证的视频序列集。然后对于测试的序列,我们选取了10个视频编码联合组(Joint Collaborative Teamon Video Coding)给出的未压缩的H.265标准测试序列,这些测试序列包括了 416x240、832×480、1280×720三种分辨率,如图9所示。为了用这些视频序列做训练和测试,本实验用H.265/HEVC的参考编码器HM16.9在Low Delay P(LDP)的配置下,量化参数(QP)设置为37,对上面提到的108个训练序列和10个测试序列做视频编解码,得到解码的视频序列,同时从解码的码流信息中提取出每个视频序列的运动矢量(MV)信息,并预测其他参考帧的运动矢量信息,把这些 MV都存在npy格式的文件中以便用来训练优化后的STDF模型。图9展示了HEVC 标准测试序列。
(3)优化后的STDF模型的训练方法
本发明优化的STDF模型的训练方法参考原始STDF模型的训练,采用 PyTorch框架在GPU上做训练和测试,对于模型的训练,采用以下训练方法:
由于训练时间成本和硬件成本问题,本发明将解码视频帧、解码帧前后3 帧参考帧、该帧对应的原始视频帧和对应的MV在对应位置任意截取128*128的图片作为训练的样本。
采用旋转、翻转等方法扩展现有的训练样本,帮助模型具备更强的泛化能力,增强其鲁棒性。
对神经网络训练的最大迭代次数为300000个batch,batch_size为32,由于训练视频帧较多,每个epoch需要迭代大约30000个batch,即需要做20个 epoch的训练。
本发明用端对端的方式联合优化STDF模块和QE模块的训练参数,所以本发明采用后处理增强后的目标帧
使用Adam优化器优化模型的权重,Adam优化器的参数β
参考原始的STDF模型训练方法,学习率固定为0.0001。
(4)模型的性能评估方法
首先对于质量性能的评估,由于仅仅对YUV视频的Y通道空间做质量增强,所以本发明在Y通道上计算增强后的视频的峰值信噪比PSNR′与压缩解码后的视频的峰值信噪比PSNRo的差值ΔPSNR,用ΔPSNR来衡量质量增强性能,如果ΔPSNR 越大,表示后处理模型增强的视频质量越多,模型的质量增强性能也就越强。除此之外,本发明还需要与原始的STDF模型质量性能做对比,用ΔΔPSNR作为与原始STDF模型质量性能的损失衡量,如公式(6)所示,ΔPSNR
ΔΔPSNR=ΔPSNR
ΔPSNR=PSNR′-PSNR
其次对于时间性能的评估。我们分别统计优化后的STDF模型和原始STDF 模型的后处理增强时间t
(5)实验结果及分析
如图8展示了原始的STDF模型(0riginalSTDF)和本发明优化后的STDF模型(0ptimizedSTDF),在验证集上随迭代次数(按Batch的迭代次数)训练得到的模型所展现的后处理质量增强性能的变化图。从图中可以看到,在验证集上,训练迭代230000个batch后,两个模型的质量增强性能基本上趋于稳定,本实施例选取迭代训练270000次batch后的模型作为最终的模型(从图中可以看到 270000次迭代训练的模型具有最高的质量性能)。另外,还可以看到,在验证集上,优化速度后的STDF模型(Optimized STDF)与原始的STDF模型(Original STDF) 在质量性能方面对比,Optimized STDF相对于Original STDF大概损失0.15 个db。图10表示随迭代次数训练的模型在验证集上表现的质量增强性能。
图11展示了优化的STDF模型与原始STDF模型在测试序列上的测试结果。首先从平均意义上看,优化的STDF模型相比原始STDF模型,在损失0.15db的 psnr质量性能的同时,降低了STDF模型大约35%的时间复杂度。总体上看,优化后的STDF模型在高清视频(720P)上可以保留较好的质量性能,比如720P的视频序列Johnny相比与原始模型仅仅牺牲了少量的质量性能(0.038db)就能降低 29%的时间复杂度。反观低分辨率的测试序列,模型的质量增强性能损失较大的同时也能降低较多的时间复杂度。对于运动物体较多,运动较大的BQMall和 BasketballPass等低分辨率序列,优化后的模型质量增强性能损失较多,很可能是增加的MV也未能较准确的帮助STDF模型寻找偏移量。
基于深度网络视频编解码的后处理优化算法因降低了算法复杂度,提升速度,从而不仅可以实现已有非直播视频后处理增强,还可以进一步考虑在网络直播,视频点播,线上课堂的实时应用的后处理,
基于深度网络视频编解码的后处理优化算法还可以进一步利用解码信息帧中,CU块的划分,QP等信息来判断当前图像质量及信息,从而是否需要进行后处理增强。并且可以利用这些解码信息进行简化神经网络中冗余的计算,再次提升计算速度。
本实施例的技术关键点在于将深度学习神经网络后处理结合到H.265/HEVC 解码功能后,对神经网络模型压缩的同时,能够利用解码的MV信息弥补了模型压缩时间优化后带来的质量损失过大问题,能够在降低计算复杂度,减少耗时的同时使用mv信息提高后处理增强质量,从而达到实时应用的需求。最终本发明相比于原来深度学习神经网络,降低了35%的时间复杂度,质量损失只有0.15db,说明可以利用mv等解码信息提高后处理效果,并与原模型相比在后处理增强损失质量极小的情况下,极大的简化了模型结构,降低了神经网络卷积计算时间,降低了算法复杂度,满足应用的实时需求。
本领域普通技术人员可以理解,上文中所公开方法中的全部或某些步骤、系统可以被实施为软件、固件、硬件及其适当的组合。某些物理组件或所有物理组件可以被实施为由处理器,如中央处理器、数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。这样的软件可以分布在计算机可读介质上,计算机可读介质可以包括计算机存储介质(或非暂时性介质)和通信介质(或暂时性介质)。如本领域普通技术人员公知的,术语计算机存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的任何方法或技术中实施的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储、磁盒、磁带、磁盘存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质。此外,本领域普通技术人员公知的是,通信介质通常包含计算机可读指令、数据结构、程序模块或者诸如载波或其他传输机制之类的调制数据信号中的其他数据,并且可包括任何信息递送介质。
以上是对本发明的较佳实施进行了具体说明,但本发明并不局限于上述实施方式,熟悉本领域的技术人员在不违背本发明精神的前提下还可作出种种的等同变形或替换,这些等同的变形或替换均包含在本发明权利要求所限定的范围内。
- 基于深度网络视频编解码的后处理优化方法
- 一种基于帧分类的视频后处理优化方法及装置