一种基于数据驱动的无线网络流量预测方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及一种数据挖掘和建模业务,旨在通过深入对移动运营商后台的历史流量数据进行深入地分析和系统地理论抽象。从数据的角度出发,挖掘基站流量随时间变化的内在规律,归纳和提取城市区域中流量序列的典型波动模式,进而对每种典型模式建立针对性的预测模型。最大限度地保证区域内无线基站流量预测性能,属于大数据分析与深度学习领域。
背景技术
随着移动通信技术的发展和无线信息传输服务的不断普及,近年来移动用户和设备的数量呈爆炸式增长。根据思科的最新数据,2016年至2021年,无线传输流量预计将增长7倍。无线业务的快速增长对移动运营商在合理配置基站资源、提高用户体验等方面提出了更高的要求。可靠的流量预测可以使网络尽早平衡用户之间的物理资源分配,从而保证用户的QoS。如果能够预见到流量拥塞或闲置,进而及时进行相应的资源调整,提高资源利用效率,保证网络稳定,提高用户体验。另外,如果提前预测基站未来将有一段时间处于闲置状态,可以提前适当关闭基站,减少不必要的能量损失。
无线流量预测是网络智能化运维的研究热点之一。通常可以将其建模为一般的时间序列预测问题。其中,季节自回归滑动平均(SARIMA)作为经典的时间序列分析方法被广泛应用。然而,SARIMA缺乏对非线性波动的捕捉能力限制了其性能上限。近年来,深度学习的兴起使得许多学者尝试将神经网络应用于流量预测。其中,一种基于循环神经网络(RNN)的变体结构:长短期记忆网络(LSTM)被广泛应用。此外,也有一些研究引入基于梯度提升法的集成学习模型应用于流量预测,例如XGBoost、LightGBM等。
从本质上讲,流量预测问题是一个时间序列拟合问题,以上研究虽然在一定程度上取得了一些成果,但应用于真实运维场景中仍存在以下问题:(1)缺少对原始数据的预处理,真实的运维数据通常带有大量突发噪声,这些噪声若不加以提取和剥离,会严重限制模型的拟合性能。(2)仅使用单条时间序列建模,即一次训练只能针对一座基站,缺乏对整个服务区域内不同基站流量波动的共性特征进行挖掘和提取,训练开销过大。(3)相对应地,也有一些研究者将全部基站流量数据共同训练一个预测模型,这样又忽视了部分基站流量波动之间的差异性,不同波动规律的流量序列相互影响,限制了模型的拟合性能。
发明内容
有鉴于此,本发明的目的是提供一种基于数据驱动的城市蜂窝网络流量预测方法。需要先从数据库中提取基站的历史流量数据,去除无效记录后,保存记录周期完整的流量数据和对应的基站信息。进而对流量数据进行预处理,剔除原始数据中的残差(residual)分量、保留基线(baseline)特征分量。进而采用基于密度的聚类方法:挖掘不同基站baseline特征之间的相似性和差异性,将波动规律相似的baseline特征对应的基站划分至有限的聚类簇中。最后,针对不同的聚类簇,使用baseline特征和训练对应的流量预测模型,实现对流量波动规律的拟合及预测;将residual分量视为随机变量,根据时间特征将随机变量分组,每组随机变量均视为服从正太分布的样本,采用极大似然估计法获得正态分布参数,实现对不同时刻下噪声分量的预估。
1.蜂窝基站流量数据预处理方法
本发明采用了滑动窗口平均法从原始流量序列中提取baseline分量,再将原始序列于baseline分量做差获取residual分量。设单座基站的原始流量序列由以下一维向量x=(x
其中,正常情况下的滑动窗口长度为2τ+1,即(1)式中的第2子式是计算baseline分量的一般算法,而第1,3子式是处理左右边界时的特殊情况。单座基站的流量序列经滑动窗口法可以得到完整的baseline序列,b=(b
2.基于基线(baseline)特征的基站聚类方法
聚类的目的是使距离相近的特征被划归到同一类中。对于基站的聚类,首先需要对任意两座基站的baseline向量的相似程度加以定义。本发明采用基于序列形态的距离(shape-based distance,SBD),以下简称为“形态距离”或SBD,做为时间序列之间的距离。序列x
d(x
(2)式中,函数corr(·,·)用于求两条时间序列的互相关函数,它返回一个一维向量,其中的每个元素均为两条序列的“错位内积”,函数max(·)返回输入序列的最大值。根据(2)式定义易知:0≤d(x
3.训练流量预测模型
本发明首先使用滑动窗口法制备训练数据,设滑动窗口长度为W,通过不断平移窗口截取作为模型输入的baseline特征,相应的下一时刻的采样值作为模型的输出标签。即实现使用历史的W个流量采样预测未来时刻的流量值。其次,本发明设计了一个基于Bi-LSTM网络的深度学习模型,见图5。所有聚类的模型均采用相同的模型结构。
4.残差(residual)分量的处理方法
本发明设计了一种处理residual分量的方法:将residual特征中的每个分量视为服从一维正态分布的随机变量,进而对每个聚类簇中的residual样本采用极大似然估计法计算对应的正态分布参数,已知正态分布的对数似然函数为:
其中,r
附图说明
图1为摘要附图。
图2为无线网络流量预测架构示意图。
图3为原始数据的特征提取模块示意图。
图4为基于多层次密度聚类的小区划分模块示意图。
图5为基于Bi-LSTM模型的流量预测模块示意图。
图6为残差特征参数估计模块示意图。
图7为本发明流量预测模型与对照组模型的拟合优度(R2)对比图。
图8为本发明流量预测模型与对照组模型的满足R2阈值基站比率曲线图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步的详细描述。
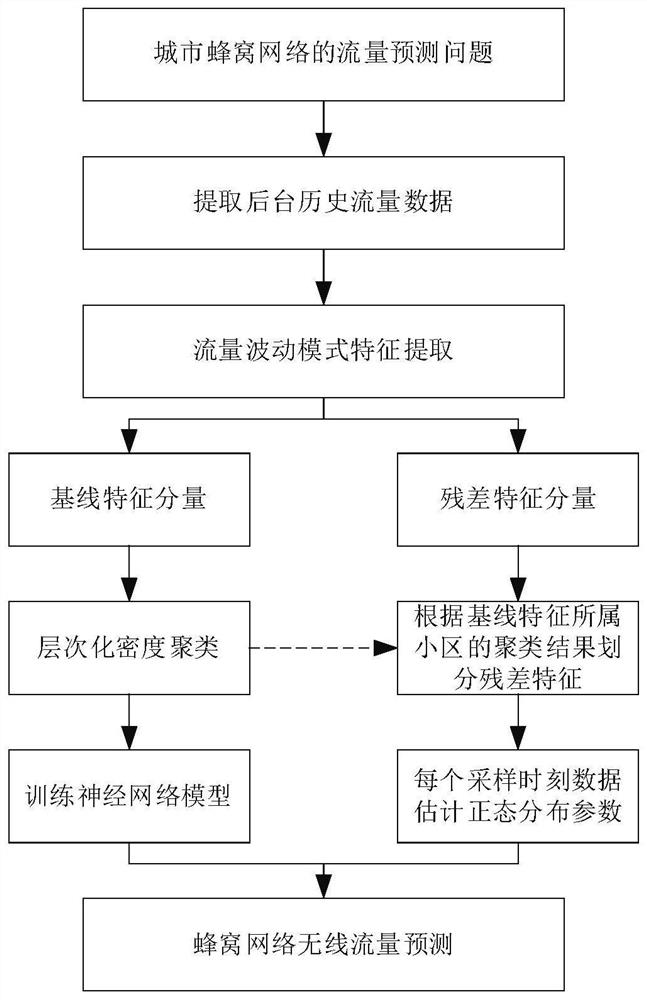
参见图2,无线网络流量预测架构示意图。原始流量序列首先被分解为基线特征和残差特征。然后,通过具有基于层次化密度聚类策略的无监督算法对基线特征进行聚类,从而获得一些基线特征聚类簇。此外,残差特征的分组也遵循基线特征。对于每个簇的特征数据,本发明提出一种基于Bi-LSTM的神经网络模型来拟合基线特征。同时,本发明假设单个簇的残差特征在每个小时下的采样样本服从正态分布。进而通过使用最大似然估计法来求解参数,以获得更准确的性能。
参见图3,原始数据的特征提取模块示意图。设置合理的滑动窗口长度,每个时刻的流量值采用滑动窗口中的流量记录的平均值替换,得到规律明显且平滑的基线分量特征序列。“取反”指取序列元素的相反数,再通过加法器与原始序列相加,实现做减法的表示。即:残差序列是由原始流量序列与基线特征序列相互做差得到。
参见图4,基于多层次密度聚类的小区划分模块示意图。初始化相关参数,调用sci-kit learn中的DBSCAN接口对所有基站的基线特征分量聚类。通过不断放宽eps参数,保证每次聚类的结果能够聚类出足够数量的基站,保证聚类出有限且差异明显的聚类结果。
参见图5,基于Bi-LSTM模型的预测模块示意图。使用过去24小时的数据预测未来1小时的数据。本发明设计了基于Bi-LSTM的神经网络结构。对每个聚类簇的极限特征分别训练各自的预测模型。其中,每个模型均采用相同的结构:输入层由24个神经元构成,下方连接Bi-LSTM层,正向LSTM神经元数和反向LSTM神经元数均为18个。双向LSTM层分别输出18维特征在下一层拼接成36维特征。后续再进入18单元的全连接层,最后到达单神经元的输出层,模型输出结果作为预测基线特征。使用Tensorflow部署和训练模型。
参见图6,残差特征参数估计模块示意图。本发明假设不同时刻的残差特征均服从不同均值和方差的正态分布。对于每个分簇内的残差特征数据,首先将这些数据根据“小时”分组。即0~23时,共24组。然后,对每一组残差样本采用极大似然估计法计算正太分布的均值和方差,建立分时刻概率模型。
参见图7,本发明流量预测模型与对照组模型的拟合优度(R2)对比图。其中,分簇1~分簇8对应的粉色柱对应本发明提出的预测方案。分簇0对应的是层次化聚类后剩余的“离群点”小区。total表示未采用层次化聚类,而将全部数据进行模型训练的情况。我们以total情况下采用基于Bi-LSTM构建的深度神经网络的结果作为参照,即黑色虚线。从中可以明显看出,本发明所提出的通过提取基线特征,进而对基线特征做密度聚类,再使用神经网络拟合得到的模型的方案的拟合优度要明显优于其它对照方案。本发明所提方案能够得到更加良好的预测性能。
参见图8,本发明流量预测模型与对照组模型的满足R2阈值基站比率曲线图。横轴表示R2阈值,纵轴表示单基站预测的拟合优度超过横轴对应阈值的百分比。显然,随着R2阈值增加,对系统性能的要求逐渐严苛,所有方案的曲线均称下降趋势。对比其它方案,本发明的拟合性能曲线(蓝色粗线)均处于最高位置,在85%拟合性能门限要求下仍能够保证超过90%基站的拟合性能,本发明提出流量预测方案能够尽可能地保证绝大多数无线小区的预测结果。
以上所述仅为本发明的一个实例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 一种基于数据驱动的无线网络流量预测方法
- 一种基于生成对抗网络的无线网络流量预测方法和设备