面向电力客服问答的实体属性对抽取方法和系统
文献发布时间:2023-06-19 12:10:19
技术领域
本发明属于智能问答的实际应用技术领域,涉及一种面向电力客服问答知识图谱的实体属性对联合抽取方法和系统。
背景技术
目前,在智能问答的实际应用领域,多采用的是基于常见问答数据集的方式,即依据常见问答对构成的初始数据,对输入问题,检索常见问答数据集中与之匹配的问题,直接查询与之匹配问题的答案,作为输入问题的答案。这种检索方法是目前实现智能问答的一种重要技术途径,但是,检索方法对初始常见问答数据的依赖性非常强,其可行性很大程度上依赖于采集常见问答数据的覆盖度和精确性。
在电力客服领域,基于检索方法构建的领域问答系统确实能回答领域中相当一部分的问题,但是由于缺乏电力客服领域知识,难以求解需要利用领域知识之间的关联、逻辑、因果等关系推理生成答案的复杂问题。
当前,通过构建电力客服知识图谱形成领域知识库,是支撑复杂问题求解的关键技术。在电力客服领域,由于大量的用户、营销、产品、政策、条例、规章等数据资料用语用词规范,采用模板和机器学习方法,命名实体识别和事件识别能够达到较高精确度。然而,电力客服业务范围广,涉及到从客户到电力产品、网络营销等多方面的知识,构建完整的电力客服知识图谱既面临着大规模数据整理和劳务成本高昂、大规模多源异构数据处理难等诸多问题,也面临大规模知识图谱对智能问答针对性不强、运行效率低下的问题。如何构建专门针对电力客服问答的知识图谱,是亟待解决的问题。构建面向电力客服问答的知识图谱,主要可细化为三个具体的研究任务:电力客服问答的知识图谱的实体识别,电力客服问答的知识图谱的实体属性挖掘,电力客服问答的知识图谱的关系挖掘。前面的工作,已经完成电力客服知识图谱的实体识别工作,并取得良好的实验效果,电力客服问答的知识图谱的实体属性挖掘自然成为我们重点的研究对象,且实体属性对抽取是面向非结构数据,相对于从结构化或者半结构数据中抽取实体属性对,本任务更加复杂且颇具挑战新,也更加具有实际意义。
随着电力客服人员的规范梳理和长期积累,以及智能问答系统的初步应用,形成了大量的问答对话记录,使得针对电力客服问答和FAQ库抽取电力客服问答知识图谱的实体属性对成为可能。
探索面向电力客服问答的知识图谱实体属性对抽取有三个关键问题需要解决:
(1)基于深度学习算法,在保证标注质量情况下,如何最小人工成本去标注数据?
(2)当文本中只含有实体的属性语义,未出现属性词,如果抽取处实体属性对?
(3)当文本只含有一个实体,语义中涉及到多个属性语义时,如何只“看”一次文本,一次抽取所有的实体属性对?
发明内容
为解决现有技术中的不足,本申请提供一种面向电力客服问答知识图谱实体属性对联合抽取方法,能够采用已有电力客服问答的历史记录和FAQ库,首先设计闭域的属性模式,其次利用远程监督的方式标注嵌套实体,再经过人工标注属性id,形成训练,验证,测试数据集;基于深度学习联合建模抽取电力客服问答数据集中的实体和属性对。本发明具有自动抽取嵌套实体及属性对的能力,通过拓展闭域的属性模式的设计,抽取更加复杂的实体属性对。
具体地,本发明提出一种面向电力客服问答知识图谱的实体属性对联合抽取方法,所述方法包括以下步骤:
步骤S1,将电力客服历史问答记录数据和电力客服常见问答FAQ库作为基础语料,初步形成原始数据集;
步骤S2,对原始数据集数据预处理,删除脏数据和格式化输入,形成待标注数据集;
步骤S3,通过专家知识,设计所有实体词的属性模式;
步骤S4,利用电力客服实体,实体类型的字典,采用远程监督的方式就回标待标记的实体,采用BIO方式标注嵌套的实体,人工标注每个实体对应属性;
步骤S5,基于BERT预训练模型,对BERT的输出采用span分类,span过滤,属性多分类,联合抽取面向电力客服问答知识图谱的实体属性对。
进一步地,所述步骤S2包括:
步骤S21,针对电力客服历史问答记录数据,整理成若干行文本,每一行表示一个问题或者一次回答,对于常见问答FAQ采用同样的处理方式,一行文本表示一条FAQ中的A问题或者Q回答;
步骤S22,先去掉行中所有空格,然后删除字符没有中文的行或者字符数少于2的行;
步骤S23,遍历所有行,将字符超过510的行直接截断,直到数据集中所有行的字符都不超过510个字符,使其满足模型输入要求;
步骤S24,对经过截断处理的数据集,再次清洗,去掉先去掉行中空格,然后删除字符没有中文的行或者字符数少于2的行。
其中所述步骤S23具体为:
逐行查看字符数,当字符数小于510个字符,直接保存该行,当字符数大于510时,先取510个字符当做新行,对于剩下的字符重复上述操作。
进一步地,所述步骤S3包括:
根据电力客服专家知识和语料语义,设计所有的实体的属性schema,其中联合抽取的实体属性对,属性都来源于上述设计的属性schema。
所述实体属性对抽取的属性取值都包含在所设计的属性schema集合中。
进一步地,所述步骤S4包括:
步骤S41:利用电力客服非嵌套NER模型,制作电力客服实体-实体类型字典;
步骤S42:利用电力客服实体-实体类型字典标注实体,标注的时候采用嵌套BIO的标注方式;
步骤S43:人工手动标注每个实体对应的属性模式。
进一步地,远程监督标注数据,仅仅针对实体,而实体对应的属性,需要人工标注。
进一步地,所述步骤S41具体为:
电力客服非嵌套NER模型,非嵌套的含义是指所有实体不可再分割且只对应一个实体类型,相反,非嵌套NER任务是指存在实体是可再分割的且子串(含字符串本身)对应1个或者多个实体类型。
进一步地,所述步骤5包括:
步骤S51,将每行对BERT模型的输出采用Span的方式识别实体;
步骤S52,判断每一个Span形成的实体和所有属性模式集合中的组成一个实体属性对的概率;
步骤S53,设置超参数λ,当步骤S52中实体属性对概率超过λ,则输出该实体属性对。
本发明还提出一种面向电力客服问答知识图谱的实体属性对联合抽取系统,所述系统包括:
基础数据集构建模块,用于将电力客服历史问答记录数据和电力客服FAQ作为基础语料,形成每行字符大于2且小于510的带标注的数据集;
远程监督标注模块,结合现有非嵌套NER电力客服模型,形成电力客服实体-实体类型字典,利用该字典远程监督去嵌套给数据做BIO标注,然后再人工去标注每个实体对应的属性模式;
面向电力客服问答知识图谱的实体属性对联合抽取模块,利用SpanBERT算法框架,联合抽取实体属性对。
所述SpanBERT算法框架指的是所述步骤5的算法流程。
本申请所达到的有益效果:
1.本发明采用远程监督学习的方式,在保证标注质量的情况下,减少了人工标注的工作量;
2.本发明采用自定义属性schema,可以挖掘处文本没有出现的属性,形成实体属性对;
3.本发明采用SpanBERT算法框架,针对文本语义中暗含一个实体和多个属性,抽取所有的实体属性对。
附图说明
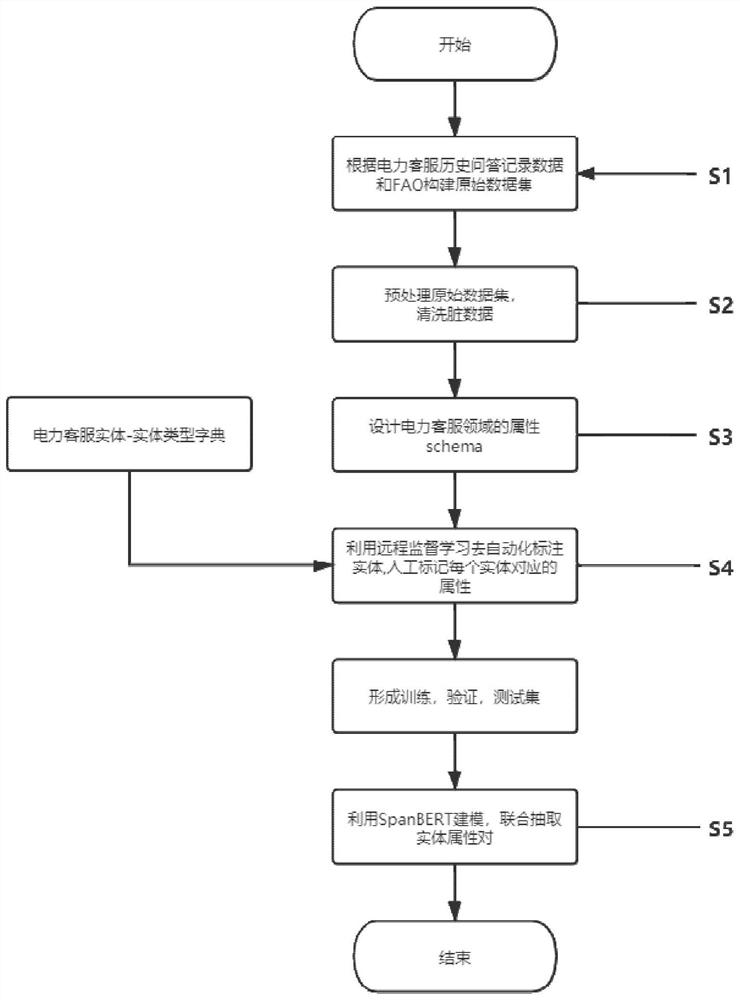
图1为本发明一种面向电力客服问答知识图谱的实体属性对联合抽取方法的流程示意图。
图2为本发明实施例中数据集的预处理和清洗流程示意图。
图3为本发明实施例中清洗过程中对数据进行截断详细的流程示意图。
图4为本发明实施例中远程监督标注实体和人工标注属性的流程示意图。
图5为本发明实施例中SpanBERT算法框架流程示意图。
图6为本发明实施例中SpanBERT算法原理框架示意图。
具体实施方式
下面结合附图对本申请作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本申请的保护范围。
如图1所示,本发明的一种面向电力客服问答图谱实体属性对抽取方法,包括步骤S1-S5:
步骤S1,将电力客服常见历史问答记录数据和电力客服常见问答库作为基础语料,形成由问题-答案对构成的电力客服问答实体识别基础数据集;
步骤S2,对经过步骤一简单整合形成的数据集进行数据的预处理和清洗工作,如图2所示,包括如下步骤:
步骤S21,首先,针对电力客服历史问答记录数据,整理成若干行文本,每一行表示一个问题或者一次回答,对于FAQ采用同样的处理方式,一行文本表示一条FAQ中的A(Answer)或者Q(Question)。
步骤S22,先去掉行中所有空格,然后删除字符没有中文的行或者字符数少于2的行(我们假设字符数少于2的行是不存在实体属性对知识的)。
步骤S23,遍历所有行,将字符超过510的行直接截断,直到数据集中所有行的字符都不超过510个字符,使其满足我们的模型输入要求,更加详细的流程参见图3。
步骤S24,对经过截断处理的数据集,再次清洗,去掉先去掉行中空格,然后删除字符没有中文的行或者字符数少于2的行。
步骤S3主要是通过专家知识,人工地,自定义属性schema,本文提到的实体属性对抽取,属性的取值范围都是预先定义在属性schema中,将这种实体属性对的抽取成为闭域的实体属性对的抽取,这样自定义属性对的优势是可以自动挖掘文本中实体的潜在属性。
如“什么是峰谷电价?”这句话语义是潜在询问《峰谷电价,定义》这样的一对实体属性对,另一方面,利用预定义的属性schema也可以比较好准确的解决一个实体对应多个属性的多实体属性对的抽取工作,如“什么是分时电价,居民分时电价的费用是多少”,可以准确的抽取出《分时电价,定义》,《分时电价,价格》这样的两对实体。
由此,初步解决了一个实体对应多个属性的问题,且比较准确。
通过专家知识和业务理解,总结模式schema如下:
{"无属性":0,"查询":1,"异常":2,"业务介绍":3,"方式":4,"办理":5,"定义":6,"时间":7,"变更":8,"价格":9}
步骤S4的具体工作流程,如图4所示:
步骤S41:首先利用现有的电力客服非嵌套NER模型,制作电力客服实体-实体类型字典。
步骤S42:利用电力客服实体-实体类型字典去标注实体,标注的时候采用嵌套BIO的标注方式。
步骤S43:然后,人工去手动标注每个实体对应的属性schema。
如图5所示,步骤S5包括以下实施步骤:
步骤S51,span分类,将每行(表示一个训练样本)采用Span编码的方式处理预训练中文BERT模型的输入。
所述span分类:应理解span的编码方式,举个例子,对于一个输入句子,采用span编码的方式采样句子中的实体,如“我想查看以下南京市的分时电价”。
首先,定义span的长度范围[2,10];
其次,从头遍历字符串,利用span获取候选的实体,如上例,分为“我想”,“想查”,“查看”,……“电价”,这些是span长度为2的实体,“我想查”,“想查看”…“时电价”,这些是span长度为3的实体,…“我想查看以下南京市的”,“想查看以下南京市的分”,…“以下南京市的分时电价”,这些是span长度为10候选实体。最终形成一个实体span的集合。
span实体的编码的过程,得到span实体的依赖于三个输入:
1)BERT embedding(BERT嵌入编码),首先定义BERT输出的token embedding序列为:
L=cls,e
其中L表示BERT输出得token得编码向量得集合,cls表示BERT的[CLS]的编码信息,e
2)实体长度embedding,对于不同长度的实体都给一个embedding编码,即为w
3)实体span编码表征:
e(s)=concate(f(e
其中f表示一种pooling方式,可以是max pooling,mean pooling等方式,e
4)我们定义:
x
其中,concate表示把两个向量拼接在一起,cls表示BERT的[CLS]的编码信息,e(s)表示span的编码,x
经过softmax函数,有:
y
y
w,b都为随机初始化的参数,利用反向传播算法,自动更新。
步骤S52,span过滤,判断每个span实体是否是一个真实的实体还是非实体。
步骤S53,属性多分类,判断每一个Span实体与属性schema集合中各个属性的组成一个实体属性对的概率。
属性分类:属性分类依赖属性的语义表征,属性的语义表征经过以下三个步骤:
1)Content token embedding(上下文编码),对于BERT输出的token embedding序
列为
L=cls,e
则我们定义上下文编码为:
x
其中,x
2)entity-attribute embedding(实体-属性对编码),我们定义:
x
concate表示把两个向量拼接在一起,x
3)利用sigmoid对属性做多分类:
Logit(p)=sigmoid(W*x
W,b都为随机初始化的参数。x
步骤S54,设置超参数λ,当步骤S53中实体属性对概率超过λ,则输出该实体属性对。
步骤S54,我们将S51~S54中的流程称作SpanBERT算法流程,更进一步地,SpanBERT算法原理框架如图6所示。
本发明还公开了一种面向电力客服问答知识图谱实体属性对抽取系统,包括:
基础数据集构建模块,用于将电力客服历史问答记录数据和电力客服FAQ作为基础语料,形成每行字符大于2且小于510的带标注的数据集;
远程监督标注模块,结合现有非嵌套NER电力客服模型,形成电力客服实体-实体类型字典,利用该字典远程监督去嵌套给数据做BIO标注,然后再人工去标注每个实体对应的属性;
面向电力客服问答知识图谱的实体属性对联合抽取模块,利用SpanBERT算法框架,联合抽取实体属性对。
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
- 面向电力客服问答的实体属性对抽取方法和系统
- 面向电力客服问答的渐增式知识图谱实体抽取方法和系统