一次性声学回声生成网络
文献发布时间:2023-06-19 19:07:35
技术领域
本发明总体上涉及机器学习,更具体地,涉及用于生成模拟真实世界数据的音频记录的系统和方法。
背景技术
声学回声消除(AEC)是一个重要组成部分音频记录以减少或消除回声和显着改善声音质量为一个用户。回声消除现在变得更加重要,因为移动计算和视频通信已经导致数字语音消费的爆炸式增长。该技术可应用于许多视频会议、音频通话、视频录制、播客等领域。然而,用户在室内或室外等多种应用环境中录制音频,并使用多种录音设备,这对声学回声消除提出了挑战。神经网络是一种很有前途的声学回声消除技术,但该技术可能需要大量的训练数据(例如录音)来训练神经网络以获得足够的性能。
当前收集用于训练AEC神经网络的大型录音数据集的方法既昂贵又费力。传统方法需要手动收集来自许多不同环境的录音,以提供代表每个环境中回声的训练示例,这些示例可用于应用程序的实际使用中。尤其地,研究者可设立多个模拟房间以及不同的记录设备和再现设备(用于播放音频样本),以模拟不同的环境。在每个房间收集数据并测量每个房间的特征的过程可能是劳动密集型的。此外,他达到的训练数据基础上的房间,研究人员能够建立和使用记录的数量是有限的。这种方法是劳动密集型和昂贵的,并且限制了训练数据中可以表示的不同环境的数量。有时,可以使用基于数字信号处理(DSP)的回波生成来辅助数据生成,但这种方法仍然需要收集有关房间或其他复杂测量任务的信息。因此,由于基于有限数量的训练数据的不正确泛化,AEC神经网络可能表现不佳。
声学回声消除领域需要更有效地生成训练数据。期望通过用于生成音频记录的系统和方法来克服传统方法的问题,该系统和方法模拟各种不同环境的声学回声特性以训练用于声学回声消除的神经网络
发明内容
一般而言,本说明书中描述的主题的一个创新方面可以体现在包括用于生成回波记录的操作的系统、计算机可读介质和方法中。一种系统执行由自动编码器接收表示音频信号的音频信号表示和包括关于目标房间的信息的目标回声嵌入的操作,其中自动编码器包括编码器和解码器。该系统发电机密封ES,由编码器中,内容中嵌入和估计的回声嵌入。该系统发电机密封ES,由解码器,基于所述内容嵌入和目标的回波记录表示回声嵌入。回声记录表示是表示包括在目标房间播放估计回声的音频信号。
在系统的另一方面,目标回波嵌入对关于目标房间的几何形状和一个或多个回波路径的信息进行编码。
在系统的另一方面,当目标回声嵌入与估计的回声嵌入相同时,音频信号表示与回声记录表示相同。
在该系统的另一方面,目标回声嵌入是通过将第二音频信号表示输入到自动编码器中来生成的,该第二音频信号表示表示在目标房间中记录的第二音频信号。
在系统的另一方面,音频信号表示包括音频信号的短时傅立叶变换(STFT)。
在该系统的另一个方面,该系统发电机密封上课从回波记录表示一个回声记录。该系统列车使用回波记录的声学回声消除系统。
在该系统的另一方面,自编码器包括一个或多个权重,这些权重是通过在连体重建网络中训练自编码器而学习的。
在系统的另一方面,连体重建网络包括串联的自动编码器的两个副本,其中自动编码器的第一副本的输出包括自动编码器的第二副本的输入。
在系统的另一方面,Siamese重建网络被训练以最小化Siamese重建网络的输入音频信号表示和输入回声嵌入与Siamese重建网络的输出音频信号表示和输出回声嵌入之间的重建损失.
在该系统的另一方面,使用生成对抗网络(GAN)训练自动编码器以最小化鉴别器损失。
从详细描述、权利要求和附图中,本公开的更多应用领域将变得显而易见。详细描述和具体示例仅用于说明而不用于限制本公开的范围。
附图说明
从详细描述和附图中可以更好地理解本公开,其中:
图1是示出一些实施例可以在其中操作的示例性网络环境的图;
图2是示出一些实施例可以在其中运行的示例性环境的图;
图3是图示根据本公开的一个实施例的示例性自动编码器的图;
图4是图示根据本公开的一个实施例的示例性重构网络的图;
图5是图示根据本公开的一个实施例的示例性的图;
图6是图示可以在一些实施例中执行的示例性方法的流程图;
图7是图示可以在一些实施例中执行的示例性方法的流程图;
图8A-B是图示可以在一些实施例中执行的示例性方法的流程图;
图9是图示可以在一些实施例中执行的示例性方法的流程图;和
图10图示了其中可以执行实施例的示例性计算机系统。
具体实施方式
在本说明书中,详细参考了本发明的具体实施例。在附图中示出了一些实施例或其方面。
为了解释清楚,已经参考特定实施例描述了本发明,但是应当理解,本发明不限于所描述的实施例。相反,本发明涵盖可包括在由任何专利权利要求限定的其范围内的替代、修改和等同物。本发明的以下实施例在不丧失对所要求保护的发明的一般性且不对其施加限制的情况下被阐述。在以下描述中,阐述了具体细节以提供对本发明的透彻理解。可以在没有这些特定细节中的一些或全部的情况下实践本发明。此外,可能没有详细描述众所周知的特征以避免不必要地模糊本发明。
此外,应当理解,该示例性专利中阐述的示例性方法的步骤可以以与本说明书中呈现的顺序不同的顺序执行。此外,示例性方法的一些步骤可以并行执行而不是顺序执行。此外,示例性方法的步骤可以在网络环境中执行,其中一些步骤由联网环境中的不同计算机执行。
一些实施例由计算机系统实现。计算机系统可以包括处理器、存储器和非暂时性计算机可读介质。存储器和非暂时性介质可以存储用于执行这里描述的方法和步骤的指令。
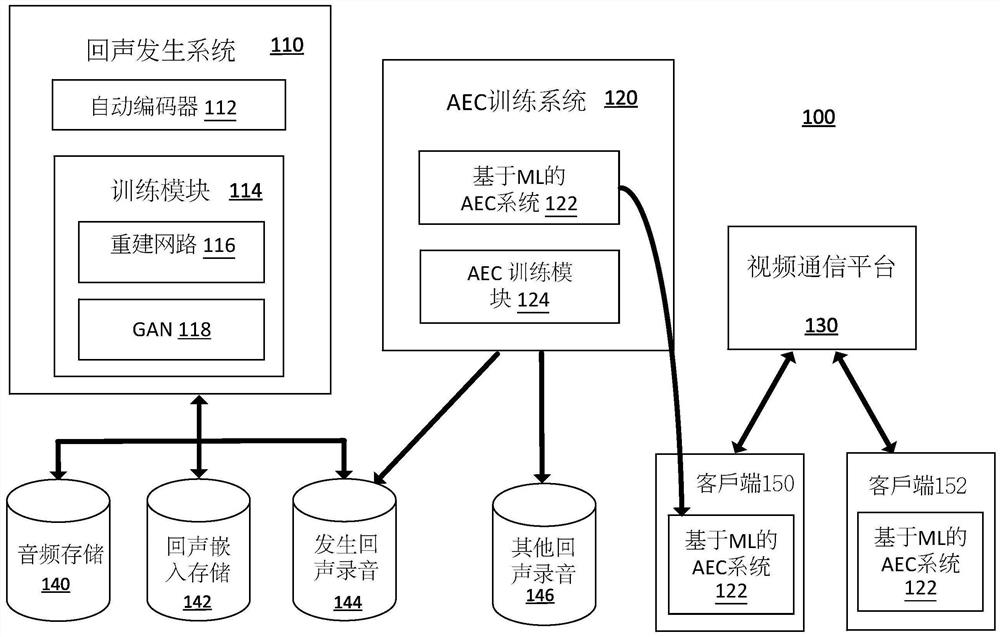
图1是图示一些实施例可以在其中操作的示例性网络环境100的图。在示例性环境中,回波生成系统110可以包括用于生成回波记录的计算机系统。回声生成系统110可以包括自动编码器112和用于训练自动编码器112的训练模块114。训练模块114可以包括软件模块,该软件模块包括重建网络116和生成对抗网络(GAN)118。在一些实施例中,自动编码器112、重建网络GAN116和GAN 118可以包括一个或多个神经网络,例如深度神经网络(DNN)。DNN可以使用深度学习来实现其功能的一个或多个方面。回声生成系统110可以连接到一个或多个存储库和/或数据库,包括音频存储库140、回声嵌入存储库142和生成的回声记录存储库144。一个或多个数据库可以组合或分成多个数据库。
音频储存库140可以存储一个或多个音频记录,例如用于训练自动编码器112的训练样本、用于提取回声嵌入的房间参考样本、用作生成的回声记录的基本音频的音频基础样本,等等。音频储存库140中的音频记录可以用于这些示例性目的中的一个或多个。回声嵌入储存库142可以存储一个或多个回声嵌入。回声嵌入可以包括关于房间的信息的数字表示,例如与房间中回声的生成有关的信息。例如,回声嵌入可以包括关于房间的几何形状和/或大小、房间中的一个或多个回声路径等的信息。房间的几何形状可以包括关于房间的布局和尺寸以及房间中影响房间中回声的对象的信息。回声嵌入中编码的房间信息可以从音频信号中估计出来,不需要精确。生成的回波记录储存库144可以存储由回波生成系统110生成的一个或多个回波记录。
在一些实施例中,声学回声消除(AEC)训练系统120可以使用所生成的回波记录来训练机器学习(ML)基于AEC系统122AEC训练系统120可包括计算机系统,该系统可以是相同,或从分开的,所述回波生成系统110AEC训练系统120可以包括基于ML-AEC系统122,其可以包括软件存储在存储器和/或计算机存储和在一个或多个处理器执行。在一些实施例中,基于ML的AEC系统122可以包括一个或多个神经网络,例如DNN,用于声学回声消除。声学回声消除可以包括从一个或多个音频信号减少或去除回声。基于ML的AEC系统122可以包括可以确定基于ML的AEC系统122的操作的一个或多个内部权重(例如,参数)。可以通过训练基于ML的AEC系统1来学习内部权重22使用AEC培训模块124,该模块可以包括软件模块。例如,可以通过在基于ML的AEC系统122中通过反向传播更新权重来学习内部权重,以最小化损失函数。基于ML的AEC系统122可以使用来自生成的回波记录存储库144的生成的回波记录进行训练。基于ML的AEC系统122也可以使用来自其他回波记录存储库146的其他回波记录进行训练,例如真实的世界回声录音。真实世界的回声记录可以从受控环境中收集,例如实验室记录,或从实际用户记录中收集,这些记录可能被认为是野生录音。
在训练之后,基于ML的AEC系统122可以被部署到客户端设备150和客户端设备152上的视频会议软件中。每个客户端设备可以包括具有视频会议软件的设备,该视频会议软件包括基于ML的AEC系统122作为一个模块,可用于在视频会议期间执行声学回声消除。客户端设备150和客户端设备152通过视频通信平台130连接,视频通信平台130可以包括用于执行视频会议软件的后端功能的计算机系统。图示了两个客户端设备,但实际上更多或更少的客户端设备可以通过视频通信平台130连接用于视频会议。每个客户端设备可以通过视频通信平台130参与视频会议。例如,每个客户端设备可以包括具有用于显示视频会议的显示器以及用于发送和接收音频信息的麦克风和扬声器的设备。客户端设备150和客户端设备152可以向视频通信平台130发送和接收信号和/或信息。每个客户端设备可以被配置为执行与呈现和回放视频、音频、文档、注释和其他材料相关的功能在视频通信平台130上的视频演示(例如,虚拟课程、讲座、网络研讨会或任何其他合适的视频演示)内。在一些实施例中,客户端设备150和客户端设备152可以包括嵌入式或连接的摄像头,其能够实时或基本实时生成和传输视频内容的过程。例如,一个或多个客户端设备可以是具有内置摄像头的智能手机,智能手机操作软件或应用程序可以提供基于内置摄像头生成的视频广播直播流的能力。在一些实施例中,客户端设备150和客户端设备152是能够托管和执行一个或多个能够发送和/或接收信息的应用程序或其他程序的计算设备。在一些实施例中,客户端设备150和客户端设备152可以是台式计算机或膝上型计算机、移动电话、虚拟助理、虚拟现实或增强现实设备、可穿戴设备或能够发送和接收信息的任何其他合适的设备。在一些实施例中,视频通信平台130的功能可以全部或部分地作为上执行的应用或web服务托管客户端设备150或客户端设备152在一些实施例中,一个或多个视频通信的平台1 30例如,客户端设备150、客户端设备152、回声生成系统110和AEC训练系统120可以是相同的设备。在一些实施例中,除了客户端设备之外或代替客户端设备,基于ML的AEC系统122可以部署在视频通信平台130上,并且基于ML的AEC系统122可以在之前从客户端设备接收的音频信号执行声学回声消除。发送的音频信号到其他客户端设备。在一些实施例中,第一客户端设备150与视频通信平台上的第一用户帐户相关联130,和第二客户端设备152被相关联的与第二用户帐户的视频通信平台上130。
示例性网络环境100是关于视频通信平台130示出的,但也可以包括其他应用,例如音频呼叫、音频记录、视频记录、播客等等。使用生成的回声记录储存库144和其他回声记录储存库146训练的基于ML的AEC系统122可以用作除了视频通信之外或代替视频通信的用于上述应用的软件应用中的声学回声消除的软件模块.
如示例性网络环境100中所示,回声生成系统110可以允许生成模拟和/或合成而不是从现实世界收集的回声记录。使用更多数量的记录作为基于ML的AEC系统122的训练样本可能与性能和准确性的提高有关。因此,与仅在真实世界记录上训练基于ML的AEC系统122相比,使用生成的回波记录可以产生改进的结果。回声生成系统100的使用可以使得能够以更少的劳动和成本以及提高的效率来创建生成的回声记录。此外,回声生成系统100可以减少或消除根据复杂参数设置模拟室以模拟不同环境的需要。
相比之下,自动编码器112的训练过程可能要少得多。在一些实施例中,可基于从野外收集的音频记录使用训练模块114来训练自动编码器112。此外,单次学习可以使用由自动编码器112提取关于一个房间到一个信息回波基于在房间收集单个参考音频记录嵌入。回波嵌入可被用于产生回波记录该模拟从室收集的音频录音。
图2是示出一些实施例可以在其中运行的示例性环境200的图。语音样本A 212可以包括来自音频储存库140的音频记录,在房间A 210中播放并且由房间A 210中的麦克风214记录以生成音频信号A 216。音频信号A 216可以被转换成音频信号表示A 217,例如频谱图或其他表示。音频信号表示A 217可以被输入到自动编码器112以生成回声嵌入A 218。
类似地,可以包括来自音频存储库140的音频记录的语音样本B 222在房间B 220中播放并且由房间B 220中的麦克风224记录以生成音频信号B 226。音频信号B 226可以被转换为音频信号表示B 227,例如频谱图或其他表示。音频信号表示B 227可以被输入到自动编码器112以生成回声嵌入B 218。
使用本文进一步描述的方法,回声生成系统110可用于生成回声记录以模拟在房间B 220中播放的语音样本A,包括来自房间B 220的估计回声,以及模拟语音样本B的回声记录在房间A 210中播放,包括来自房间A 210的估计回声。
图3是图示根据本公开的一个实施例的示例性自动编码器112的图。自动编码器112可以包括编码器320和解码器340。音频信号表示310和目标回声嵌入312可以输入到自动编码器112。音频信号表示310可以包括适合由自动编码器112处理的音频信号的数字表示。例如,音频信号表示310可以包括通过对音频信号执行短时傅立叶变换(STFT)而生成的频谱图。音频信号可以包括来自音频储存库140的音频记录,例如语音记录。在一个实施例中,频谱图可以包括二维向量,其中第一维表示时间,第二维表示频率,并且每个值表示特定时间在特定频率的幅度或幅度。在示例性音频信号表示310中,不同的值可以由不同的颜色强度来表示。或者,音频信号表示310可以包括音频信号的其他特征,例如STFT的幅度、STFT的幅度和相位、STFT的实部和虚部、能量、对数能量、梅尔谱、梅尔频率倒谱系数(MFCC)、这些特征和其他特征的组合。在一些实施例中,音频信号表示310可以由这些特征中的一个或多个的频谱图来表示。
编码器320和解码器340可以各自包括神经网络,例如DNN。在一个实施例中,自编码器112可以包括矢量量化变分自编码器(VQ-VAE)。编码器320和解码器340均可以包括多个节点,每个节点具有一个或多个权重,其中权重是通过训练学习的。编码器320和解码器340可以使用这里描述的重构损失和/或GAN鉴别器损失一起训练。
音频信号表示310可以被输入到编码器320以生成内容嵌入330和估计的回声嵌入352。内容嵌入330可以包括关于音频信号的内容的信息的数字表示,例如语音或其他内容,例如作为声音或音乐。估计的回声嵌入352可以包括关于音频信号被记录的房间的信息的数字表示,例如与房间中回声的产生有关的信息。在一些实施例中,嵌入可以包括可用于生成信息的高维向量表示的低维学习向量表示,例如通过自动编码器112。在一些实施例中,嵌入以压缩的、空间高效的格式对信息进行编码。例如,所述的嵌入可以表示与一个信息矢量表示是较小的比输入到编码器320。嵌入可以是有损和可能失去在编码的过程中的数据的一些量。
内容嵌入330和目标回声嵌入312可以被输入到解码器340。目标回声嵌入312可以包括用于目标房间的回声嵌入。特别地,目标回声嵌入312可以包括关于目标房间的信息,例如与目标房间中回声的生成有关的信息。解码器340生成的回波记录基于所述内容中嵌入330和目标回波嵌入312表示350在一个实施例中,解码器340可以将内容从内容与房间信息嵌入330结合包含在目标回波嵌入312和解码所得COMBIN通货膨胀包含内容和房间信息以生成回声记录表示350。的回波记录表示350可以包括估计在目标室,包括从目标房间推定回波正被播放的音频信号的估计的音频信号的表示。回声记录表示350的格式可以包括如关于音频信号表示310或本文别处所描述的音频信号的频谱图或其他特征。
回声记录表示350可以通过执行用于生成音频信号表示的函数的逆来转换为回声记录。当回波记录表示350是一个STFT表示,所述回波记录可以通过执行逆STFT(生成ISTFT上)回波记录表示350的ISTFT函数可以使用幅度和相位信息。在一个实施方案中,可用于音频信号表示310的相同的相位信息ISTFT所述的回波记录表示350基于一个假设,即它们具有相同的相位。
第i个编码器N,输入频谱分解成一个内容中嵌入330和回波。是带有回声嵌入E的频谱S。编码器网络可以表示为
随着所述解码器d,所述内容中嵌入330和回声嵌入312被用来产生频谱。解码器网络可以表示为:
如果目标回声嵌入312和估计回声嵌入352相同,则自动编码器112变成重建网络,将音频信号表示310重建为回声记录表示350。例如,当目标回声嵌入312与估计回声嵌入352,则音频信号表示310与回声记录表示350相同。否则,当回声嵌入不同时,自动编码器112可以包括回声生成网络。可以使用两个目标函数、重建损失和鉴别器损失来训练自动编码器112。
在一个实施例中,自动编码器112可以在两个步骤中使用。在第一步中,第一音频信号被转换为第一音频信号表示并与第一回声嵌入一起输入到自动编码器112。自编码器112生成第一估计回声嵌入,其表示关于记录第一音频信号的房间的信息。在第二步中,第二音频信号被转换为第二音频信号表示并与第一估计回声嵌入一起输入到自动编码器112。自编码器112生成第二回声记录表示。可以例如通过iSTFT将第二回声记录表示转换为生成的回声记录,其表示在记录第一音频信号的房间中播放的第二音频信号的估计。
自动编码器112的使用可以关于示例性环境200来说明。在第一步骤中,音频信号表示A 217和任意回声嵌入(例如随机回声嵌入)可以被输入到自动编码器112以生成回声嵌入A 218。自编码器112还可以生成不需要在该示例中使用的回声记录表示。由于自编码器112仅使用单个输入示例(例如,音频信号表示A 217)生成表示关于房间A 210的信息的回声嵌入A 218,因此可以说自编码器112以一次性方式操作并且是一个的实例-射击学习。在第二步中,音频信号表示B 227和回声嵌入A 218可以被输入到自动编码器112以生成回声记录表示。回声记录表示可以例如通过iSTFT被转换为回声记录,其估计在房间A 210中播放并从麦克风214记录的语音样本B 222,包括将被记录的来自房间A 210的估计回声。自编码器112还可生成回声嵌入B 228,其可类似地与音频信号表示A 217一起输入到自编码器112以获得估计在房间B 220中播放的语音样本A 212的回声记录。
在一个实施例中,房间A 210和房间B 220可以可选地是野外房间,例如来自用户数据或音频记录数据集。例如,音频信号A 216和音频信号B 226可以是来自用户数据的记录,例如从一个或多个用户的视频会议收集的音频。余地信息是由自动编码器112自动地提取到回波中嵌入218和回声嵌入乙228没有回波生成系统110或自动编码器112直接OBSERVING或测量电荷兰国际集团室A 210或房间B 220可替代地,室A 210和室B 220可以是被设置为模拟特定环境的模拟室,并且音频信号A 216和音频信号B 226可以被记录在模拟室中。
图4是图示根据本公开的一个实施例的示例性重建网络116的图。重建网络116可以包括连体重建网络,该网络包括具有相同结构并共享相同内部权重的两个自动编码器112。重建网络116可用于学习和更新自动编码器112的权重,使用重建损失来训练自动编码器112以生成回声记录和回声嵌入,如图1所示。3和本文其他地方。
音频信号表示410和回声嵌入412可以被输入到第一自动编码器112。在一些实施例中,音频信号表示410可以包括来自野外的任意音频记录,例如来自视频通信平台130的用户音频记录。或者,音频信号表示410可以从音频记录数据集或模拟室收集。回声嵌入412可以包括任意回声嵌入,例如随机回声嵌入。
第一自动编码器112基于音频信号表示410和回声嵌入412生成中间音频信号表示420和中间回声嵌入422。中间音频信号表示420可以表示包括根据任意回声嵌入412估计的回声的音频信号表示410,并且中间回声嵌入422可以表示来自音频信号表示410的房间信息。
中间音频信号表示420和中间回声嵌入422被输入到第二自动编码器112以生成回声记录表示430和估计的回声嵌入432。回声记录表示430表示音频信号表示410的音频信号,包括根据录制音频信号的房间估计回声。估计的回声嵌入432表示来自中间音频信号表示420的房间信息,其由第一自动编码器112使用任意回声嵌入412生成。因此,可以训练重建网络116和包括重建网络116的自动编码器112通过分别评估输入到重建网络116的音频信号表示410和回声嵌入412与输出的回声记录表示430和估计的回声嵌入432之间的误差。例如,在一些实施例中,音频信号表示410和回声记录表示430之间的误差以及回声嵌入412和估计的回声嵌入432之间的误差被计算并且求和,并且总和包括总误差。该总体误差可以包括损失函数。训练可以包括通过反向传播更新自动编码器112的权重以最小化误差,其可以表示为损失函数。在一些实施例中,误差可以包括均方误差(MSE)、平均绝对误差(MAE)或其他损失函数。对于所述重建网络116中的错误或损失的功能可以被称为一个S上的重建的损失。
可以包括训练数据集中的频谱。E可以包括随机回声嵌入。并且包括具有回声嵌入E和估计回声嵌入E的生成频谱。利用两个自动编码器网络112建立重建网络。
网络然后将源频谱和目标回波嵌入E'作为输入并生成和E和E'可以被用来作为地面实况监督在这个重建任务的训练。该重建网络的目标可能包括:
可以表示为,因为E'在每个时期都是给定和固定的。
在一个实施例中,通过使用重建网络116的重建损失来训练自动编码器112使得能够在没有地面实况信息的情况下执行训练,例如编码真实房间信息的地面实况回声嵌入。重建网络116可以用来自野外的音频信号(例如用户录音)进行训练,而没有对应的地面实况房间信息或音频信号的地面实况回声嵌入。可以在没有关于其中记录训练音频样本的房间的信息的情况下训练重建网络116,例如没有测量、布局、尺寸、几何形状或回声路径信息。
图5是图示根据本公开的一个实施例的示例性GAN 118的图。GAN 118可用于使用鉴别器损失来学习和更新自动编码器112的权重。在一个实施例中,GAN 118可以包括具有梯度惩罚的Wasserstein GAN(WGAN-GP),其中鉴别器530可以包括评论家。
在一些实施方案中,重建网络116可以不必包括上中间音频信号表示420,它约束包括分布类似于一个真实世界的音频信号表示。仅使用重建网络116进行训练可能会从自动编码器112产生看起来不真实的生成的音频信号表示。GAN118可以训练自动编码器112吨出现更多产生输出类似于一个真实世界的音频信号表示,例如通过具有一个类似的分配中。用GAN 118训练以最小化鉴别器损失可以提高生成的回声记录表示350的质量。在一些实施例中,重建损失和鉴别器损失可以在损失函数中组合以最小化训练期间的两个错误。例如,整体损失可能是重建损失和鉴别器损失的总和。反向传播可被用来更新自动编码器112的权重,以尽量减少吨他整体损失函数。
在训练期间与重建网络116,音频信号表示410和回声嵌入412被输入到FIRST自动编码器112,以产生中间音频信号表示420和中间回波嵌入422的音频信号表示410和中间音频信号表示420被输入到鉴别器530。鉴别器530可以包括神经网络,例如DNN,其被训练来确定两个输入中的哪一个是真实世界的音频信号表示410,以及哪个是从输入中生成的中间音频信号表示420。第一自动编码器112。鉴别器损失函数535可以测量鉴别器530在两个音频信号表示之间正确选择(例如,鉴别)的能力。最小化鉴别器损失函数535可能与鉴别器530在鉴别两个音频信号表示方面做得更差以及自动编码器112生成更类似于现实世界音频信号表示的回声记录表示相关。在WGAN-GP中,鉴别器530可以包括对音频信号表示的真实性或虚假性进行评分的评论者。
在一个实施例中,GAN 118,其包括WGAP-GP,被施加以迫使本地频谱贴片的分布在中间音频信号表示420以接近与天然光谱。目标函数可以包括:
其中R包括GAN 118的评论家(鉴别器530)。为整体损失的网络可以包括重建损耗和鉴别器损耗之和。首先,在有六个下采样层和八个残差块的情况下训练网络。然后嵌入通过三个残差块和两个具有全连接层的残差块,分别获得内容嵌入和回声嵌入。然后在几个残差块之后添加这些嵌入。最后,经过六个上采样层后生成生成的回波谱。因此,可以在下采样层和上采样层之间添加六个跳跃层。例如,可以使用基于梯度的优化算法来训练网络。最后,生成的频谱可以转换为音频信号,例如使用iSTFT。
图6是图示可以在一些实施例中执行的示例性方法600的流程图。
在步骤602,自编码器112接收表示音频信号的音频信号表示310和包括关于目标房间的信息的目标回声嵌入312。他自动编码器可以包括编码器320和解码器340。在一个实施例中,音频信号可以包括语音记录并且音频信号表示310可以包括音频信号的STFT或其他音频特征。在一实施例中,目标回波嵌入对关于目标房间的几何形状和一个或多个回波路径的信息进行编码。在一个实施例中,目标回声嵌入是通过将表示在目标房间中记录的第二音频信号的第二音频信号表示输入到自动编码器中来生成的。
在步骤604,编码器320生成内容嵌入330和估计的回声嵌入352。内容嵌入330可以包括关于音频信号的内容的信息的数字表示,并且估计的回声嵌入352可以包括关于音频信号被记录的房间的信息的数字表示。在一个实施例中,编码器320可以包括神经网络,例如DNN。
在步骤606,解码器340基于内容嵌入330和目标回声嵌入312生成回声记录表示350。在一个实施例中,解码器340可以将来自内容嵌入330的内容与包含在目标回声嵌入312中的房间信息进行组合,并对包含内容和房间信息的所得组合进行解码以生成回声记录表示350。回声表示350可以表示音频信号,包括在目标房间播放的估计回声。在一个实施例中,解码器340可以包括神经网络,例如DNN。
在一些实施例中,当目标回声嵌入312与估计的回声嵌入352相同时,音频信号表示310与回声记录表示350相同。在一些实施方案中,母鸡目标回波嵌入312是类似于估计回声嵌入352,则音频信号表示310可类似于回声记录表示350。
在一些实施例中,一个可从回声记录表示生成回波记录350。回声记录可用于训练声学回声消除系统122。
在一些实施例中,自编码器112包括通过在连体重建网络116中训练自编码器112而学习的一个或多个权重。他连体重建网络116可包括串联的自动编码器,其中,所述自动编码器的第一拷贝的输出包括输入到自动编码器的第二拷贝的两个副本。的连体重建网络116可以被训练来最小化输入音频信号表示和输入之间重建损耗回声嵌入连体重建网络116和输出音频信号表示和输出回声嵌入连体重建网络116。在实施例中,他自动编码器112可以被训练以最小化使用鉴别损失GAN 118。
图7是图示可以在一些实施例中执行的示例性方法700的流程图。
在步骤702,自编码器112接收代表第一音频信号和第一回声嵌入的第一音频信号表示。自动编码器可以包括编码器320和解码器340。在一个实施例中,第一音频信号可以包括语音记录并且第一音频信号表示可以包括第一音频信号的STFT或其他音频特征。在一个实施例中,第一回声嵌入可以是任意嵌入,例如随机回声嵌入。
在步骤704,自编码器112生成目标回声嵌入,其包括关于记录第一音频信号的房间的信息。自编码器112可以可选地生成回声记录表示,该表示表示包括基于第一回声嵌入的估计回声的第一音频信号。
在步骤706,自动编码器112接收表示第二音频信号和目标回声嵌入的第二音频信号表示。在实施例中,所述第二音频信号可以包括语音记录和第二音频信号表示可以包括所述的STFT第二音频信号或其它音频功能。第二音频信号可以不同于第一音频信号。
在步骤708,自动编码器112基于第二音频信号表示和目标回声嵌入生成回声记录表示。在一个实施例中,自动编码器112可以将来自第二音频信号表示的音频内容与包含在目标回声嵌入中的房间信息组合以生成回声记录表示。回声记录表示可以表示第二音频信号,包括来自在记录第一音频信号的房间中播放的估计回声。自编码器112可以可选地生成估计的回声嵌入,其表示关于记录第二音频信号的房间的信息。
图8A-B是图示可以在一些实施例中执行的示例性方法800的流程图。
在步骤802,重构网络116接收表示第一音频信号的第一音频信号表示410和第一回声嵌入412,其中重构网络116包括共享相同结构并共享的第一自动编码器和第二自动编码器。相同的内部权重。在一个实施例中,第一音频信号可以包括语音记录并且第一音频信号表示410可以包括第一音频信号或其他音频特征的STFT。在一个实施例中,第一回声嵌入412可以是任意嵌入,例如随机回声嵌入。
在步骤804中,第一自动编码器产生,基于所述第一音频信号表示410和第一回波嵌入412,中间音频信号表示420和中间回波嵌入422。第一自动编码器接收第一音频信号表示410和第一回声嵌入412作为输入。在一个实施例中,中间音频信号表示420可以表示包括估计回声的音频信号表示410,好像它是在通过第一回声嵌入412编码的房间中播放的,并且中间回声嵌入422可以表示来自音频信号表示的房间信息410.
在步骤806,第二自编码器基于中间回声记录表示420和中间回声嵌入422生成回声记录表示430和估计的回声嵌入432。第二自动编码器接收由第一自动编码器输出的中间回声记录表示420和中间回声嵌入422作为输入。在一个实施例中,回声记录表示430表示第一音频信号表示410的第一音频信号,包括根据记录第一音频信号的房间估计的回声。估计的回声嵌入432表示来自中间音频信号表示420的房间信息,其由第一自动编码器112使用第一回声嵌入412生成。
在步骤808,基于回声记录表示430和第一音频信号表示410之间的差异以及估计的回声嵌入432和第一回声嵌入412之间的差异来确定重建损失。在一个实施例中,重建损失包括回波记录表示之间的误差的总和430和第一音频信号表示410和之间的估计的回声嵌入432和第一回波嵌入412。误差可能包括MSE、MAE或其他损失函数。
在步骤810,鉴别器530接收第一音频信号表示410和中间音频信号表示420。鉴别器530可以是GAN 118的组件并且可以包括神经网络,例如DNN。鉴别器530可以被训练以区分真实世界的音频信号表示和生成的音频信号表示。
在步骤812,鉴别器530基于鉴别器区分第一音频信号表示410和中间音频信号表示420的能力来确定鉴别器损失。在一个实施例中,鉴别器530可以尝试区分第一音频信号表示410和中间音频信号表示420以确定哪个包括真实世界的音频信号表示以及哪个包括生成的音频信号表示。在一个实施例中,鉴别器530可以包括评价第一音频信号表示410和中间音频信号表示420看起来是多么真实或虚假的评价者。
在步骤814,基于重构损失和鉴别器损失更新第一自动编码器和第二自动编码器的一个或多个内部权重。在一个实施例中,整体损失函数包括重建损失和鉴别器损失的总和,并且第一自动编码器和第二自动编码器的一个或多个内部权重被更新以最小化整体损失函数,例如通过使用基于梯度的优化算法。
图9是图示可以在一些实施例中执行的示例性方法900的流程图。
在步骤902,提供包括一个或多个音频信号的音频记录数据集。在一个实施例中,音频信号可以包括语音记录,例如野外语音记录(例如,用户音频记录)、来自音频记录数据集的语音记录、从模拟室收集的语音记录或其他类型的语音记录。音频信号可以记录在多个不同的房间中。
在步骤904,多个音频信号表示的是生成基于所述音频记录数据集。音频信号表示可以包括音频信号的STFT或其他音频特征。
在步骤906,多个音频信号表示被输入到回声生成系统110以生成一个或多个模拟回声记录144。他回波生成系统110可以包括自动编码器112在一个实施例中,一个或多个音频信号的表示包括记录在各种不同的室,室参照表示代表了其中可以在目标的软件应用程序的环境中使用。房间参考表示可以被输入到回声生成系统110的自动编码器112以生成多个回声嵌入。在一个实施例中,一个或多个音频信号表示包括包含用于训练的语音的音频基础表示。音频基础表示可以输入到回声生成系统110的自动编码器112,并带有选择的回声嵌入,以生成模拟回声记录144,模拟回声记录144包括在各种不同房间中被模拟记录的各种不同语音音频。
在步骤908,基于一个或多个模拟回波记录144训练基于ML的AEC系统122。可选地,也可以基于其他回波记录146训练基于ML的AEC系统122。ML基于AEC系统122可以包括神经网络,例如DNN。在一个实施例中,基于ML-AEC系统122可以包括被更新以最小化基于损失函数的一个或多个内部砝码一个基于梯度的优化算法。
在步骤910,来自用户的音频记录的声学回声消除由基于ML的AEC系统122执行。在一个实施例中,基于ML的AEC系统122可以使用其处理音频记录神经网络,诸如DNN,以执行声学回声消除以去除或减少回波在一个音频记录从用户。在一个实施例中,来自用户的音频记录可以包括来自视频会议软件记录的视频会议的实时音频。例如,客户端150上的基于ML的AEC系统122可以在将音频记录传输到视频通信平台130或其他客户端152之前对音频记录执行声学回声消除。
这里的系统和方法也可以用于生成具有其他类型信息的音频记录,例如噪声、语音增强和其他类型的声音或增强。对于例如,本文可用于去噪音频记录和用于语音增强系统和方法。目标回声嵌入312可以由噪声嵌入或语音增强嵌入代替以分别编码噪声或语音增强信息,并将噪声或语音增强添加到音频信号。
在一个实施例中,自动编码器112可以生成表示具有添加噪声的音频信号的噪声记录。表示音频信号和目标噪声嵌入的音频信号表示可以被输入到自动编码器112。噪声嵌入可以包括目标噪声的数字表示。
音频信号表示可以被输入到编码器320以生成内容嵌入和估计的噪声嵌入。内容嵌入可以包括关于音频信号内容的信息的数字表示。估计的噪声嵌入可以包括音频信号中噪声的数字表示。
内容嵌入和目标噪声嵌入可以被输入到解码器340。解码器340基于内容嵌入和目标噪声嵌入生成噪声记录表示。在一个实施例中,解码器340可以结合内容与所述噪声信息嵌入包含在所述目标噪声嵌入和含有内容和噪声信息来生成噪声表示记录所得到的组合进行解码。噪声记录表示可以包括估计音频信号的表示,该估计音频信号估计与目标噪声一起播放的音频信号。通过执行用于生成音频信号表示的反函数,可以将噪声记录表示转换为噪声记录。
在一个实施例中,自动编码器112可以在两个步骤中使用。在第一步中,第一音频信号被转换为第一音频信号表示并与第一噪声嵌入一起输入到自动编码器112。自编码器112生成第一估计噪声嵌入,其表示关于第一音频信号中的噪声的信息。在第二步中,第二音频信号被转换为第二音频信号表示并与第一估计噪声嵌入一起输入到自动编码器112。自编码器112生成第二噪声记录表示。可以例如通过iSTFT将第二噪声记录表示转换为生成的噪声记录,其表示利用来自第一音频信号的噪声播放的第二音频信号的估计。
在一个实施例中,自动编码器112可以生成表示具有添加的语音增强的音频信号的语音增强记录。表示音频信号和目标音频信号表示的语音增强嵌入可被输入到自动编码器112。目标语音增强嵌入可以包括的数字表示一个目标语音增强。
音频信号表示可以被输入到编码器320以生成内容嵌入和估计的语音增强嵌入。内容嵌入可以包括关于音频信号内容的信息的数字表示。估计的语音增强嵌入可以包括音频信号中语音增强的数字表示。
内容嵌入和目标语音增强嵌入可以被输入到解码器340。解码器340基于内容嵌入和目标语音增强嵌入生成语音增强记录表示。在一个实施例中,解码器340可将内容从所述内容与所述嵌入结合语音增强信息包含在目标语音增强嵌入和含有含量和所得组合解码语音增强信息以生成所述语音增强记录表示。的语音增强记录表示可以包括其估计正在播放与所述音频信号的估计的音频信号的表示语音增强。通过执行用于生成音频信号表示的反函数,语音增强记录表示可以被转换为语音增强记录。
在一个实施例中,自动编码器112可以在两个步骤中使用。在第一步中,第一音频信号被转换为第一音频信号表示并与第一语音增强嵌入一起输入到自动编码器112。自编码器112生成第一估计的语音增强嵌入,其表示关于第一音频信号中的语音增强的信息。在第二步中,第二音频信号被转换为第二音频信号表示并与第一估计的语音增强嵌入一起输入到自动编码器112。自编码器112生成第二语音增强记录表示。可以例如通过iSTFT将第二语音增强记录表示转换为生成的语音增强记录,其表示利用来自第一音频信号的语音增强播放的第二音频信号的估计。
自动编码器112可以被训练以使用重建网络116和GAN 118使用这里描述的重建损失和/或鉴别器损失来生成噪声记录表示和语音增强记录表示。生成的噪声记录和生成的语音增强记录可以分别用于训练基于ML的去噪系统和基于ML的语音增强系统,它们都可以包括神经网络。生成的噪声记录和生成的语音增强记录可以分别用作基于ML的去噪系统和基于ML的语音增强系统的训练数据。两个系统都可以包括客户端150、152或视频通信平台130上的视频会议软件中的软件模块,并且可以用于在视频会议期间对语音进行降噪和增强,或者可以用于其他应用,例如音频呼叫、音频记录、视频记录、播客等等。
图10是图示在一些实施例中可以执行处理的示例性计算机的图。示例性计算机1000可以执行与一些实施例一致的操作。计算机1000的体系结构是示例性的。计算机可以以多种其他方式实现。根据这里的实施例,可以使用各种各样的计算机。
处理器1001可以执行计算功能,例如运行计算机程序。易失性存储器1002可以为处理器1001提供数据的临时存储。RAM是一种易失性存储器。易失性存储器通常需要电力来维持其存储的信息。存储器1003为数据、指令和/或任意信息提供计算机存储器。非易失性存储器,即使在不通电的情况下也可以保存数据,包括磁盘和闪存,是存储的一个例子。存储1003可以组织为文件系统、数据库或以其他方式。数据、指令和信息可以从存储器1003加载到易失性存储器1002中以供处理器1001处理。
计算机1000可以包括外围设备1005。外围设备1005可以包括输入外围设备,例如键盘、鼠标、轨迹球、摄像机、麦克风和其他输入设备。外围设备1005还可以包括诸如显示器之类的输出设备。外围设备1005可以包括可移动媒体设备,例如CD-R和DVD-R记录器/播放器。通信设备1006可以将计算机1000连接到外部介质。例如,通信设备1006可以采用向网络提供通信的网络适配器的形式。计算机1000还可以包括各种其他设备1004。计算机1000的各种组件可以通过诸如总线、交叉开关或网络之类的连接介质连接。
前面详细描述的某些部分已经根据对计算机存储器内的数据位进行操作的算法和符号表示来呈现。这些算法描述和表示是数据处理领域的技术人员用来最有效地向本领域的其他技术人员传达他们工作的实质的方式。算法在这里并且通常被认为是导致所需结果的自洽操作序列。这些操作是那些需要对物理量进行物理操作的操作。通常,尽管不一定,这些量采用能够存储、组合、比较和以其他方式处理的电或磁信号的形式。有时,主要是出于常用的原因,将这些信号称为位、值、元素、符号、字符、术语、数字等已被证明是方便的。
然而,应该记住,所有这些和类似的术语都与适当的物理量相关联,并且只是适用于这些量的方便标签。除非从上面的讨论中清楚地另有说明,否则应理解,在整个描述中,使用诸如“识别”或“确定”或“执行”或“执行”或“收集”或“创建”或“发送”等术语的讨论”等,指的是计算机系统或类似电子计算设备的操作和过程,该设备将在计算机系统的寄存器和存储器中表示为物理(电子)量的数据处理和转换为在计算机系统的寄存器和存储器中以类似方式表示为物理量的其他数据。计算机系统存储器或寄存器或其他此类信息存储设备。
本公开还涉及一种用于执行这里的操作的装置。该装置可以为预期目的而专门构造,或者它可以包括由存储在计算机中的计算机程序选择性地激活或重新配置的通用计算机。这种计算机程序可以存储在计算机可读存储介质中,例如但不限于任何类型的磁盘,包括软盘、光盘、CD-ROM、磁光盘、只读存储器(ROM)、随机存取存储器(RAM)、EPROM、EEPROM、磁卡或光卡,或任何类型的适合存储电子指令的介质,每个都耦合到计算机系统总线。
各种通用系统可以与根据这里的教导的程序一起使用,或者构造更专门的装置来执行该方法可以证明是方便的。各种这些系统的结构将如以上描述中所阐述的那样出现。此外,本公开没有参照任何特定的编程语言进行描述。应当理解,可以使用多种编程语言来实现如本文所述的本公开的教导。
本公开可以作为计算机程序产品或软件提供,其可以包括其上存储有指令的机器可读介质,其可以用于对计算机系统(或其他电子设备)进行编程以执行过程根据本公开。机器可读介质包括用于以机器(例如,计算机)可读的形式存储信息的任何机制。例如,机器可读(例如,计算机可读)介质包括机器(例如,计算机)可读存储介质,诸如只读存储器(“ROM”)、随机存取存储器(“RAM”)、磁盘存储介质、光存储介质、闪存设备等。
在前述公开中,已经参考本公开的具体示例实施方式描述了本公开的实施方式。很明显,在不脱离如以下权利要求中阐述的本公开的实施方式的更广泛精神和范围的情况下,可以对其进行各种修改。因此,本公开和附图被认为是说明性的而不是限制性的。
- 一种基于最优空时聚焦技术的声学覆盖层回声降低测量方法
- 声学回声抑制装置以及声学回声抑制方法
- 声学回声消除装置和声学回声消除方法以及记录介质