准确测量未加工的C末端赖氨酸的重肽方法
文献发布时间:2023-06-19 19:32:07
相关申请的交叉引用
本申请要求2020年6月18日提交的美国临时专利申请号63/041,015的优先权和权益,该专利申请通过引用并入本文。
技术领域
本申请涉及在液相色谱-质谱分析中使用重同位素标准品对感兴趣蛋白质中的翻译后修饰(PTM)进行鉴定和定量的方法。
背景技术
治疗性单克隆抗体(mAb)和双特异性抗体(bsAb)在治疗许多病症中起着关键作用。这类药物的优点,包含对种类繁多的分子靶标的高特异性和亲和力,保证了它们的持续发展,并导致批准用于治疗健康状况,如哮喘、类风湿性关节炎和低密度脂蛋白胆固醇升高等。虽然治疗性抗体在商业和科学上的成功是前所未有的,但它们的固有益处因其巨大的尺寸、复杂性和化学异质性而受到限制,因此需要使用众多方法来评估它们的安全性和有效性。
这些方法的很大一部分通常用于评估翻译后修饰(PTM),这是一种产品质量属性,也是质量和电荷异质性的主要来源。高灵敏度质谱仪检测器与不断增加的液相色谱柱化学和酶处理条件相结合形成了一套成熟的PTM表征方法。基于质谱(MS)的肽图谱测定允许对所有相关的PTM进行鉴定、定位和定量,且在最佳条件下检测限例如小于0.1%。
通过提取离子色谱图(XIC)进行PTM定量的优势伴随着一些挑战,这些挑战对该方法的准确性和精确性产生影响。这些问题中的许多都与未修饰的肽与修饰形式的肽的电离差异有关。例如,与未加工形式(K,z=2+)相比,由于电离效率的差异和肽的主要电荷状态减小到1+,C末端K截短(des-K)值可能特别受影响。未加工的C末端K的相对丰度百分比通常是相对于K和des-K的和来计算的,但是先前的研究发现,在肽图谱定量期间,K的百分比可能被高估,因为,例如,肽序列C末端上额外的K相对于des-K肽增加了电离效率。
一些最小化该误差的尝试包含仅使用最丰富的电荷状态来计算每种肽的XIC曲线下面积(AUC),或者使用通过将等摩尔量的每种肽注射到LC柱上并测定质谱仪响应来确定的校正因子。然而,虽然第一种方法可以降低未加工的C末端K值的大小,但是此时没有或很少有经验知道该值应该降低多少。校正因子方法假设校正因子在未加工的C末端K的可能浓度范围内,在潜在的共洗脱肽存在下,并且在不同的质谱仪之间保持不变。这些因素的变化将导致加工后的测量值与未加工的C末端K值相比更不准确,这在使用静态校正因子时可能无法补偿。
因此,需要一种方法对感兴趣蛋白质中PTM的存在进行准确定量,以校正经修饰的肽和未修饰的肽的电离效率的差异。
发明内容
本发明提供了使用重肽方法准确和精确表征蛋白质诸如抗体中PTM的方法。更具体地,本公开提供了对抗体中未加工的C末端赖氨酸(K)进行定量的方法。提供了使用重肽方法对C末端K进行定量的方法。
在一些示例性实施例中,该方法包括(a)将包含所述感兴趣蛋白质的样品与消化酶接触,以获得肽消化物;(b)向所述肽消化物中加入一组重肽标准品,其中至少一种重肽标准品包含所述翻译后修饰,并且至少一种重肽标准品不包含所述翻译后修饰;(c)使用液相色谱-质谱法对所述添加了所述重肽标准品的肽消化物进行分析,以获得与所述肽消化物和所述重肽标准品的每种肽对应的信号;(d)使用包含所述翻译后修饰的所述至少一种重肽标准品与不包含所述翻译后修饰的所述至少一种重肽标准品相比的相对信号,生成校准曲线;(e)使用来自包含所述翻译后修饰的所述感兴趣蛋白质的至少一种肽与来自不包含所述翻译后修饰的所述感兴趣蛋白质的至少一种肽相比的相对信号对所述感兴趣蛋白质的翻译后修饰进行定量;和(f)使用(d)的校准曲线校正(e)的结果,以进一步对所述感兴趣蛋白质的所述翻译后修饰进行定量。
在一个方面,感兴趣蛋白质是治疗性蛋白质。在具体方面,所述治疗性蛋白质选自由抗体、可溶性受体、抗体-药物缀合物和酶组成的组。
在一个方面,所述感兴趣蛋白质是单克隆抗体。在另一方面,所述感兴趣蛋白质是双特异性抗体。
在一个方面,所述翻译后修饰是存在未加工的C末端赖氨酸。
在一个方面,所述重肽标准品相对于至少一种其他重肽标准品以约1:1至约1:1000的摩尔比存在。在另一方面,所述重肽标准品包括约1至约16种重同位素。在另一方面,所述重肽标准品包括C
在一个方面,所述消化酶是胰蛋白酶。
在一个方面,所述液相色谱法包括反相液相色谱法、离子交换色谱法、尺寸排阻色谱法、亲和色谱法、疏水相互作用色谱法、亲水相互作用色谱法、混合模式色谱法或其组合。
在一个方面,所述质谱仪是电喷雾电离质谱仪、纳米电喷雾电离质谱仪(诸如Orbitrap质谱仪)、Q-TOF质谱仪或三重四极质谱仪,其中所述质谱仪与所述液相色谱系统联用,并且其中所述质谱仪能够进行LC-MS、LC-MRM-MS和/或LC-MS/MS分析。
本公开还提供了用于实施本发明的方法的试剂盒。在一些示例性实施例中,该试剂盒包括第一组合物,其包含至少一种包含翻译后修饰的重肽标准品;和第二组合物,其包含至少一种不包含所述翻译后修饰的重肽标准品,其中当通过质谱分析时,包含所述翻译后修饰的所述至少一种重肽标准品与不包含所述翻译后修饰的所述至少一种重肽标准品相比的相对信号可用于生成校准曲线,其中所述校准曲线可用于对感兴趣蛋白质的翻译后修饰进行定量。
在一个方面,所述翻译后修饰是存在未加工的C末端赖氨酸。
在一个方面,所述重肽标准品相对于至少一种其他重肽标准品以约1:1至约1:1000的摩尔比存在。在另一方面,所述重肽标准品包括约1至约16种重同位素。在另一方面,所述重肽标准品包括C
在一个方面,试剂盒还包括至少一种轻肽标准品。
在一个方面,试剂盒的组合物可以包装在水性介质中或呈冻干形式。
在一个方面,组合物可以在容器中提供。该试剂盒的容器装置通常将包含组分可以放置于其中并且优选地是适当等分的至少一个小瓶、试管、烧瓶、瓶子、注射器或其他容器装置。在另一方面,试剂盒的组合物可以干粉形式提供。当试剂和/或组分以干粉形式提供时,可以通过添加合适的溶剂来对粉末进行重构。设想溶剂也可以在另一个容器装置中提供。
当结合以下描述和附图考虑时,将更好地认识和理解本发明的这些方面和其他方面。以下描述虽然表明各个实施例及其众多具体细节,但是以说明而非限制的方式给出的。在本发明的范围内可以进行许多替换、修改、添加或重新排列。
附图说明
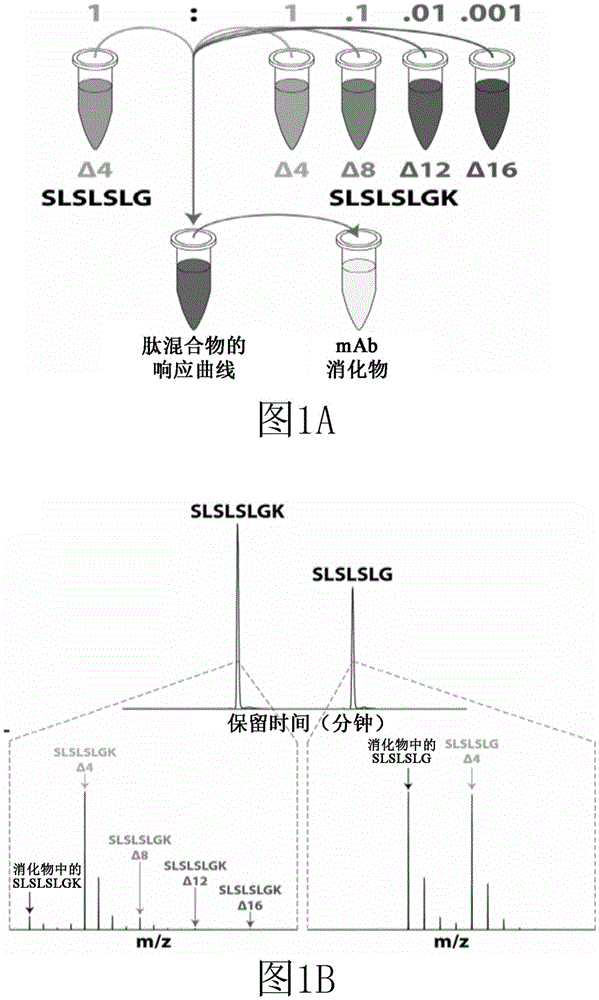
图1A示出了根据示例性实施例的本发明的测定的示意图。将“剪切的”肽(对应于缺乏C末端赖氨酸的蛋白质的C末端)与四种“未剪切的”肽(对应于具有C末端赖氨酸的蛋白质的C末端)混合,以形成响应曲线(校准曲线)肽混合物。然后将该响应曲线肽混合物与代表潜在抗体制造样品(mAb消化物)的样品混合,以准确地对抗体样品中存在的C末端赖氨酸的量进行定量。
图1B示出了根据示例性实施例的当进行液相色谱-质谱分析时,观察到的每一肽种类的分析峰。
图2A-2E示出了根据示例性实施例的含有
图3示出了根据示例性实施例的校准曲线(CC),其表现出“剪切的”肽和“未剪切的”肽之间的比例关系。
图4示出了根据示例性实施例的使用重链(HC)C末端肽的示例性响应曲线。
图5A示出了根据示例性实施例的“未剪切的”SLSLPGK(SEQ ID NO:4)和“剪切的”SLSLSPG(SEQ ID NO:3)的等摩尔混合物的UV色谱图。
图5B示出了根据示例性实施例的等摩尔量的SLSLPGK(SEQ ID NO:4)和SLSLSPG(SEQ ID NO:3)试剂组的提取离子色谱图(XIC)。
具体实施方式
治疗性单克隆抗体(mAb)和双特异性抗体(bsAb)在治疗许多病症中起着关键作用。这类药物的优点,包含对种类繁多的分子靶标的高特异性和亲和力,保证了它们的持续发展,并导致批准用于治疗健康状况,如哮喘、类风湿性关节炎和低密度脂蛋白胆固醇升高等。虽然治疗性抗体在商业和科学上的成功是前所未有的,但它们的固有益处因其巨大的尺寸、复杂性和化学异质性而受到限制,因此需要使用众多方法来评估它们的安全性和有效性。
这些方法的很大一部分用于评估PTM,这是一种产品质量属性,也是质量和电荷异质性的主要来源。单个抗体的PTM补体是多种多样的,但几乎所有mAb和bsAb之间都共享共同的修饰,诸如C末端赖氨酸截短、糖基化、N末端pyro-Glu形成、氧化、酰胺化、脱酰胺化、琥珀酰亚胺中间体形成、糖化、异构化、半胱氨酸化和三硫化物结合。
仔细监测这些PTM水平能够通过预定义的验收标准对其进行控制,并且由于两种不同的原因已经成为一种常见的策略。首先,大量报道表明PTM,尤其是位于互补决定区(CDR)中时,可以影响抗体的稳定性和生物活性。其次,PTM水平的可变性可能指示缺乏过程控制。
翻译后修饰用色谱技术和电泳技术在全局层面进行测定,包含如尺寸排阻色谱多角度激光扫描(SEC-MALLS)、毛细管电泳十二烷基硫酸钠(CE-SDS)、成像毛细管等电聚焦(iCIEF)和阳离子交换色谱(CEX)等方法。这些方法已被广泛接受,但通常仅鉴定最丰富的修饰,而不确定它们在氨基酸序列内的具体位置。
例如,CEX色谱图中的酸性物质将最可能含有PTM,如脱酰胺基、糖化和半胱氨酸化,而碱性物质则由修饰如未加工的C末端K、氧化和异构化构成。然而,由于这些PTM的氨基酸位置在全局分析中是不能确定的,因此确定它们是否位于CDR中以及处于何种丰度具有挑战性。
高灵敏度质谱仪检测器与不断增加的液相色谱柱化学和酶处理条件相结合形成了一套成熟的PTM表征方法。通过液相色谱质谱(LC-MS)对抗体进行完整的质量分析不会产生位点特异性PTM数据,但它需要最少的样品制备,并且可以提供对较大PTM的分析,且具有质量鉴定的额外益处。
二硫键减少和/或利用酶如IdeS、木瓜蛋白酶、
肽图谱方法需要抗体的酶促消化,从而产生肽混合物,该肽混合物通过液相色谱分离并通过紫外/可见(UV/Vis)吸光度进行检测,然后被电离并注入质谱仪中。获得完整的MS谱,并且选择肽并使其片段化以产生MS/MS谱,谱用于验证肽的身份或定位含有多于一个潜在修饰位点的肽上的PTM。虽然肽图谱可能会给抗体序列带来制备相关的假象,并显著增加实验的时间和复杂性,但它通常是最灵敏的PTM表征方法,且也是位点特异性的。
可以使用UV或使用质谱提取离子色谱图(XIC)对每个修饰进行定量。UV定量由于共洗脱肽而变得模糊,并且本质上不如现代质谱仪灵敏。因此,常规进行基于XIC的定量,并且基于MS的肽图谱测定允许对所有相关的PTM进行鉴定、定位和定量,且在最佳条件下检测限小于约0.1%。
通过XIC进行PTM定量的优势伴随着一些独特的挑战,这些挑战对该方法的准确性和精确性产生影响。由于许多潜在的原因,这些问题中的许多与未修饰的肽与修饰形式的肽的电离差异有关。共洗脱肽峰中的一种或两种肽形式可能受到离子抑制。在不同的保留时间洗脱的两种肽形式之间的溶剂环境可能存在差异。相对于未修饰的肽,经修饰的肽的电离效率可能存在差异。最后,质谱仪之间可能存在可变性。所有PTM的肽图谱定量受这些因素的影响,但C末端K截短(des-K)定量由于电离效率不同且与主要电荷状态为2+的未加工形式(K)相比,肽的主要电荷状态减少至1+而可能尤其受到影响。
由于在从哺乳动物组织培养细胞生产期间羧肽酶的活性,很容易发生C末端K截短。因此,重组mAb或bsAb中的主要形式是des-K。未加工的C末端K的相对丰度百分比通常是根据K和des-K的和计算的。未加工的C末端K不被认为是抗体的功效或安全性问题,因为它不在CDR中,并且已显示在注射后会迅速消失,且半衰期约为一小时。然而,对这种PTM的仔细监测证明了过程控制,并且据报道,具有更碱性pI值的抗体也可能具有增加的组织摄取和血液清除。
由于这些原因,未加工的C末端K测量仍然是重要的,并且先前的努力已经发现,在肽图谱定量期间,K的百分比可能被高估,因为肽序列的C末端上的额外K相对于des-K肽增加了电离效率。
一些最小化该误差的尝试包含仅使用最丰富的电荷状态来计算每种肽的XIC曲线下面积(AUC),或者使用通过将等摩尔量的每种肽注射到LC柱上并测定质谱仪响应来确定的校正因子。然而,虽然第一种方法降低了未加工的C末端K值的大小,但是此时没有或很少有经验知道该值应该降低多少。校正因子方法假设校正因子在未加工的C末端K的可能浓度范围内,在潜在的共洗脱肽存在下,并且在不同的质谱仪之间保持不变。这些因素的变化将导致加工后的测量值与未加工的C末端K值相比更不准确,这在使用静态校正因子时可能无法补偿。
为了解决准确地对重组蛋白中的PTM(例如重组抗体的未加工的C末端赖氨酸)进行定量的挑战,本文描述了使用重同位素肽标准品生成校准曲线以将经修饰的肽和未修饰的肽之间的检测差异归一化的方法和试剂盒。
本发明的示例性实施例在图1A和图1B中示出,其中在抗体消化物的存在下共培养五种重肽以产生可检测的信号。可检测的信号可以指示“剪切的”和“未剪切的”C末端赖氨酸(K)的准确测量。
使用新的一组重肽和分析化学(例如,液相色谱和质谱)的本发明的测定可以被校准以提供高度准确的测量。这种测定保真度是制造复杂蛋白质分子例如设计用于引入人类患者中的治疗性抗体的关键。
本发明还提供了用于实施本发明的测定的试剂盒。在示例性实施例中,测定中用于确定PTM(例如C末端赖氨酸(K))的存在的准确和真实测量的关键步骤是使用一种或多种足够多的重肽,使得当与适当的标准品和样品混合时,提供可读信号。该信号通常使用分析化学,例如液相色谱-质谱(LC-MS)来测量。
因此,用于实施本发明的方法的试剂盒的示例性组分可以包含没有感兴趣PTM的标准肽,例如C末端赖氨酸的“剪切的”肽;具有感兴趣PTM的标准肽,例如,“未剪切的”肽;标准重肽(“剪切的”和“未剪切的”),包含例如本文公开的一种或多种以下示例性肽;和使用说明,包含例如校准、数据提取、分析和解释的说明。
因此,本发明提供了用于改善重要的抗体制造化学、制造和控制(CMC)终点的方便的测试试剂盒和说明书。
应当理解,本发明提供了对治疗性蛋白质(诸如治疗性抗体)的精细结构和确切氨基酸序列的准确确定。因此,本发明补充和改进了任何商业生产的治疗性蛋白质诸如治疗性抗体的CMC(化学、制造和控制)。
例如,本发明允许改进许多抗体疗法的制造和保护。此类抗体疗法包含阿昔单抗、阿达木单抗、阿达木单抗-atto、相比恩美曲妥珠单抗、阿仑单抗、阿莫罗布单抗、阿替利珠单抗、阿维鲁单抗、巴利昔单抗、贝利单抗、贝伐珠单抗、贝洛托单抗、博纳吐单抗、本妥昔单抗、布罗达单抗、康纳单抗、卡罗单抗喷地肽、赛妥珠单抗、西妥昔单抗、达克珠单抗(赛尼哌)、达克珠单抗(Zinbryta)、达雷木单抗、狄诺塞麦、地努图希单抗、度普利尤单抗、德瓦鲁单抗、依库丽单抗、埃罗妥珠单抗、依洛尤单抗、戈利木单抗、戈利木单抗、替伊莫单抗、依达赛珠单抗、英利昔单抗、英利昔单抗-abda、英利昔单抗-dyyb、伊匹木单抗来奇珠单抗、美泊利单抗、那他珠单抗、耐昔妥珠单抗、纳武利尤单抗、奥托昔单抗、奥滨尤妥珠单抗、奥瑞珠单抗、奥法木单抗、奥拉单抗、奥马珠单抗、帕利珠单抗、帕尼单抗、派姆单抗、帕妥珠单抗、雷莫芦单抗、兰尼单抗、瑞西巴库、瑞利珠单抗、利妥昔单抗、苏金单抗、司妥昔单抗、托珠单抗、托珠单抗、曲妥珠单抗、优特克单抗、维多珠单抗、沙利鲁单抗、利妥昔单抗、透明质酸酶古塞库单抗、奥英妥珠单抗、阿达木单抗-adbm、吉妥珠单抗奥唑米星、贝伐单抗-awwb、贝那利珠单抗、艾美赛珠单抗-kxwh、曲妥珠单抗-dkst、英夫利昔单抗-qbtx、伊巴利珠单抗-uiyk、替拉珠单抗-asmn、布罗索尤单抗-twza和厄瑞奴单抗-aooe。
用于本发明主题的各种适应症的其他感兴趣治疗性抗体包含:阿柏西普,用于治疗眼病症;利洛那普,用于治疗失明和转移性结直肠癌;阿莫罗布单抗,用于治疗家族性高胆固醇血症或临床动脉粥样硬化性心血管疾病(ASCVD);度普利尤单抗,用于治疗特应性皮炎;沙利鲁单抗,用于治疗类风湿性关节炎和COVID-19;塞米普利单抗,用于治疗PD-1相关疾病;以及用于治疗埃博拉的抗体。
除非另外描述,否则本文所使用的所有技术术语和科学术语的含义与本发明所属领域的普通技术人员通常所理解的含义相同。本领域技术人员已知的与本文所述类似或等同的方法和材料可用于实践本文所述的特定实施例。所有提及的出版物在此通过引用全文并入本文。
术语“一个(a)”应理解为意指“至少一个”,并且术语“约”和“大约”应理解为允许标准变化,如本领域普通技术人员将理解的,并且在提供范围的情况下,包含端点。如本文所使用的,术语“包含(include)”、“包含(includes)”和“包含(including)”意指是非限制性的,并且被理解为分别意指“包括(comprise)”、“包括(comprises)”和“包括(comprising)”。
如本文所使用的,术语“蛋白质”或“感兴趣蛋白”可以包含具有共价连接的酰胺键的任何氨基酸聚合物。蛋白质包括一个或多个氨基酸聚合物链,在本领域中通常称为“多肽”。“多肽”是指由氨基酸残基、相关的天然存在的结构变体以及通过肽键连接的其合成的非天然存在的类似物、相关的天然存在的结构变体及其合成的非天然存在的类似物构成的聚合物。“合成肽或多肽”是指非天然存在的肽或多肽。合成肽或多肽可以例如使用自动化多肽合成仪合成。各种固相肽合成方法是本领域的技术人员已知的。蛋白质可以包括一种或多种多肽以形成单一功能性生物分子。在另一个示例性方面,蛋白质可以包含抗体片段、纳米抗体、重组抗体嵌合体、细胞因子、趋化因子、肽激素等。感兴趣蛋白质可以包含以下中的任一种:生物治疗性蛋白、用于研究或疗法的重组蛋白、trap蛋白和其他嵌合受体Fc融合蛋白、嵌合蛋白、抗体、单克隆抗体、多克隆抗体、人抗体和双特异性抗体。蛋白质可以使用基于重组细胞的生产系统来生产,诸如昆虫杆状病毒系统、酵母系统(例如,毕赤酵母属)或哺乳动物系统(例如,CHO细胞和CHO衍生物,如CHO-K1细胞)。对于最近讨论生物治疗性蛋白及其生产的综述,参见Ghaderi等人,“用于生物治疗性糖蛋白的生产平台-非人类唾液酸化的发生、影响和挑战(Production platforms for biotherapeuticglycoproteins.Occurrence,impact,and challenges of non-human sialylation)”(Darius Ghaderi等人,用于生物治疗性糖蛋白的生产平台。非人类唾液酸化的发生、影响和挑战,28《生物技术和基因工程综述(BIOTECHNOLOGY AND GENETIC ENGINEERINGREVIEWS)》147-176(2012),所述文献的全部教导内容通过引用并入本文)。蛋白质可以根据组成和溶解度来分类,并且因此可以包含简单蛋白质,诸如球状蛋白质和纤维状蛋白质;缀合蛋白,诸如核蛋白、糖蛋白、粘蛋白、色蛋白、磷蛋白、金属蛋白和脂蛋白;以及源性蛋白质,诸如初级源性蛋白质和次级源性蛋白质。
在一些示例性实施例中,感兴趣蛋白质可以是重组蛋白、抗体、双特异性抗体、多特异性抗体、抗体片段、单克隆抗体、融合蛋白、scFv和其组合。
如本文所使用的,术语“重组蛋白”是指由于在已经引入到合适的宿主细胞中的重组表达载体上携带的基因的转录和翻译而产生的蛋白质。在某些示例性实施例中,重组蛋白可以是抗体,例如,嵌合抗体、人源化抗体或完全人抗体。在某些示例性实施例中,重组蛋白可以是选自由以下组成的组的同型的抗体:IgG、IgM、IgA1、IgA2、IgD或IgE。
如本文所使用的术语“抗体”包含包括四条多肽链、通过二硫键相互连接的两条重(H)链和两条轻(L)链以及其多聚体(例如,IgM)的免疫球蛋白分子。每条重链包括重链可变区(在本文中缩写为HCVR或VH)和重链恒定区。重链恒定区包含三个结构域:CH1、CH2和CH3。每条轻链包括轻链可变区(在本文中缩写为LCVR或VL)和轻链恒定区。轻链恒定区包括一个结构域:CL1。VH区和VL区可以进一步细分为被称作互补决定区(CDR)的高变区,高变区散布有更保守的被称作框架区(FR)的区。每个VH和VL由按照以下顺序从氨基末端到羧基末端排列的三个CDR和四个FR构成:FR1、CDR1、FR2、CDR2、FR3、CDR3和FR4。在本发明的不同实施例中,抗大ET-1抗体(或其抗原结合部分)的FR可以与人种系序列相同或可以是天然的或经人工修饰的。可以基于两个或更多个CDR的并列分析来定义氨基酸共有序列。如本文所使用的,术语“抗体”还包含完整抗体分子的抗原结合片段。如本文所使用的,术语抗体的“抗原结合部分”、抗体的“抗原结合片段”等包含任何天然存在的、可酶促获得的、合成的或经基因工程化的多肽或糖蛋白,其与抗原特异性结合以形成复合物。抗体的抗原结合片段可以例如使用任何合适的标准技术衍生自完整抗体分子,标准技术诸如蛋白水解消化或涉及操纵和表达编码抗体可变结构域以及任选地恒定结构域的DNA的重组基因工程技术。此类DNA是已知的和/或易于从例如商业来源、DNA文库(包含例如噬菌体-抗体文库)获得,或者可以合成。可以通过化学方法或通过使用分子生物学技术对DNA进行测序和操纵,例如,将一个或多个可变结构域和/或恒定结构域排列成合适的构型或引入密码子、产生半胱氨酸残基、修饰、添加或缺失氨基酸等。
如本文所使用的,“抗体片段”包含完整抗体的一部分,诸如例如抗体的抗原结合或可变区。抗体片段的示例包含但不限于Fab片段、Fab'片段、F(ab')2片段、scFv片段、Fv片段、dsFv双功能抗体、dAb片段、Fd'片段、Fd片段和分离的互补决定区(CDR)区域以及三功能抗体、四功能抗体、线性抗体、单链抗体分子和由抗体片段形成的多特异性抗体。Fv片段是免疫球蛋白重链和轻链的可变区的组合,并且ScFv蛋白是重组单链多肽分子,其中免疫球蛋白轻链和重链可变区通过肽连接子连接。在一些示例性实施例中,抗体片段包括亲本抗体的足够的氨基酸序列,该氨基酸序列是该亲本抗体的片段,使得其如亲本抗体那样与同一抗原结合;在一些示例性实施例中,片段与具有与亲本抗体的亲和力相当的亲和力的抗原结合和/或与亲本抗体竞争以与抗原结合。抗体片段可以通过任何方式产生。例如,抗体片段可以通过完整抗体的片段化酶促地或化学地产生和/或抗体片段可以由编码部分抗体序列的基因重组地产生。可替代地或另外地,抗体片段可以完全地或部分地合成产生。抗体片段可以任选地包括单链抗体片段。可替代地或另外地,抗体片段可以包括例如通过二硫键连接在一起的多条链。抗体片段可以任选地包括多分子复合物。功能性抗体片段通常包括至少约50个氨基酸,并且更通常包括至少约200个氨基酸。
术语“双特异性抗体”包含能够与两个或更多个表位选择性结合的抗体。双特异性抗体通常包括两个不同的重链,其中每个重链与两个不同分子(例如,抗原)上或同一分子上(例如,同一抗原上)的不同表位特异性结合。如果双特异性抗体能够与两个不同的表位(第一表位和第二表位)选择性结合,则第一重链对第一表位的亲和力通常比第一重链对第二表位的亲和力低至少一至两个或三个或四个数量级,反之亦然。双特异性抗体可以例如通过组合识别同一抗原的不同表位的重链来制备。例如,编码识别同一抗原的不同表位的重链可变序列的核酸序列可以与编码不同重链恒定区的核酸序列融合,并且此类序列可以在表达免疫球蛋白轻链的细胞中表达。
典型的双特异性抗体具有两条重链,两条重链各自具有三条重链CDR,随后是CH1结构域、铰链、CH2结构域和CH3结构域以及免疫球蛋白轻链,免疫球蛋白轻链不赋予抗原结合特异性但可以与每条重链缔合,或可以与每条重链缔合且可以结合由重链抗原结合区结合的表位中的一个或多个表位,或可以与每条重链缔合且使得重链中的一条或两条重链能够与一个或两个表位结合。bsAb可以分成两个主要类别:一类是带有Fc区(IgG样);以及另一类是缺乏Fc区,后者通常小于包括Fc的IgG和IgG样双特异性分子。IgG样bsAb可以具有不同形式,诸如但不限于三功能抗体、杵臼IgG(kih IgG)、crossMab、orth-Fab IgG、双可变结构域Ig(DVD-Ig)、二合一或双功能Fab(DAF)、IgG-单链Fv(IgG-scFv)或κλ体。非IgG样不同形式包含串联scFv、双功能抗体形式、单链双功能抗体、串联双功能抗体(TandAb)、双亲和力再靶向分子(DART)、DART-Fc、纳米抗体或通过对接锁定(dock-and-lock,DNL)方法产生的抗体(Gaowei Fan、Zujian Wang和Mingju Hao,双特异性抗体及其应用(Bispecificantibodies and their applications),8《血液学与肿瘤学杂志(JOURNAL OFHEMATOLOGY&ONCOLOGY)》130;Dafne Müller和Roland E.Kontermann,双特异性抗体(Bispecific Antibodies),《治疗性抗体手册(HANDBOOK OF THERAPEUTIC ANTIBODIES)》265-310(2014),这些文献的全部教导内容通过引用并入本文)。产生bsAb的方法不限于基于两种不同的杂交瘤细胞系的体细胞融合的四杂交瘤技术、涉及化学交联剂的化学缀合以及利用重组DNA技术的基因方法。bsAb的示例包含在以下专利申请中公开的bsAb,专利申请特此通过引用并入:于2010年6月25日提交的美国序列号12/823838;于2012年6月5日提交的美国序列号13/488628;于2013年9月19日提交的美国序列号14/031075;于2015年7月24日提交的美国序列号14/808171;于2017年9月22日提交的美国序列号15/713574;于2017年9月22日提交的美国序列号15/713569;于2016年12月21提交的美国序列号15/386453;于2016年12月21日提交的美国序列号15/386443;于2016年7月29日提交的美国序列号15/22343;以及于2017年11月15日提交的美国序列号15814095。在制造双特异性抗体期间的若干个步骤中可能存在低水平的同二聚体杂质。当使用完整质量分析进行时,由于同二聚体杂质的低丰度以及当使用常规液相色谱法进行时这些杂质与主要物质的共洗脱,此类同二聚体杂质的检测可能是具有挑战性的。
如本文所使用的,术语“多特异性抗体”是指对至少两种不同抗原具有结合特异性的抗体。虽然这些分子通常将仅与两种抗原(即,双特异性抗体,bsAb)结合,但具有另外特异性的抗体,诸如三特异性抗体和KIH三特异性抗体也可以通过本文所公开的系统和方法来解决。
如本文所使用的,术语“单克隆抗体”不限于通过杂交瘤技术产生的抗体。单克隆抗体可以通过本领域的任何可获得或已知的方式源自单个克隆,包含任何真核、原核或噬菌体克隆。可以使用本领域已知的各种技术来制备可用于本公开的单克隆抗体,包含使用杂交瘤、重组和噬菌体展示技术或其组合。
短语“重组宿主细胞”(或简称为“宿主细胞”)包含引入了编码感兴趣蛋白质的重组表达载体的细胞。应当理解,该术语不仅指特定的受试者细胞,还指这种细胞的子代。因为由于突变或环境影响,某些修饰可能在后代中发生,这种子代实际上可能与亲代细胞不同,但仍包含在本文所用术语“宿主细胞”的范围内。在实施例中,宿主细胞包含选自任何生命界的原核和真核细胞。在一个方面,真核细胞包含原生生物、真菌、植物和动物细胞。在另一方面,宿主细胞包含真核细胞,诸如植物和/或动物细胞。细胞可以是哺乳动物细胞、鱼类细胞、昆虫细胞、两栖动物细胞或鸟类细胞。在特定的方面,宿主细胞是哺乳动物细胞。适合在培养物中生长的多种哺乳动物细胞系可从美国典型培养物保藏中心(弗吉尼亚马纳萨斯(Manassas,Va.))和其他保藏中心以及商业供应商处获得。可用于本发明的过程的细胞包含但不限于MK2.7细胞、PER-C6细胞、中国仓鼠卵巢细胞(CHO),诸如CHO-K1(ATCC CCL-61)、DG44(Chasin等人,1986,《体细胞与分子遗传学(Som.Cell Molec.Genet.)》12:555-556;Kolkekar等人,1997,《生物化学(Biochemistry)》36:10901-10909;和WO 01/92337A2)、二氢叶酸还原酶阴性CHO细胞(CHO/-DHFR,Urlaub和Chasin,1980,《美国国家科学院院刊(Proc.Natl.Acad.Sci.USA)》77:4216)和dp12.CHO细胞(美国专利号5,721,121);猴肾细胞(CV1,ATCC CCL-70);SV40转化的猴肾CV1细胞(COS细胞,COS-7,ATCC CRL-1651);HEK 293细胞和Sp2/0细胞、5L8杂交瘤细胞、Daudi细胞、EL4细胞、HeLa细胞、HL-60细胞、K562细胞、Jurkat细胞、THP-1细胞、Sp2/0细胞、原代上皮细胞(例如角化细胞、宫颈上皮细胞、支气管上皮细胞、气管上皮细胞、肾上皮细胞和视网膜上皮细胞)和已建立的细胞系及其菌株(例如人胚胎肾细胞(例如293细胞,或在悬浮培养物中亚克隆生长的293细胞,Graham等人,1977,《普通病毒学杂志(J.Gen.Virol.)》36:59);幼仓鼠肾细胞(BHK,ATCC CCL-10);小鼠支持细胞(TM4,
如本文所使用的,术语“治疗性蛋白质”是指可以施用于受试者用于治疗疾病或病症的任何蛋白质。治疗性蛋白质可以是具有药理学作用的任何蛋白质,例如抗体、可溶性受体、抗体-药物缀合物或酶。
如本文所使用的,术语“液相色谱”是指其中由液体携带的生物/化学混合物可以由于组分在其流经(或进入)固定的液相或固相时的差异分布而分离成组分的过程。液相色谱的非限制性示例包含反相液相色谱、离子交换色谱、尺寸排阻色谱、亲和色谱、混合模式色谱、疏水性色谱或混合模式色谱。
如本文所使用的,术语“质谱仪”包含能够鉴定特异性分子物质并且测量其准确质量的装置。该术语意味着包含可以表征多肽或肽的任何分子检测器。质谱仪可以包含三个主要部分:离子源、质量分析器和检测器。离子源的作用是产生气相离子。分析物原子、分子或簇可以被转移到气相中,并且同时(如以电喷雾电离的方式)或通过单独的过程被电离。离子源的选择取决于应用。
在一些示例性实施例中,该质谱仪可以是串联质谱仪。如本文所使用的,术语“串联质谱”包含通过使用多阶段的质量选择和质量分离来获得关于样品分子的结构信息的技术。先决条件是样品分子被转化为气相并被电离,以便在第一次质量选择步骤后以可预测和可控的方式形成片段。多级MS/MS或MS
如本文所使用的,术语“数据库”指可能存在于样品中的蛋白质序列的汇编集合,例如以FASTA格式的文件形式。相关的蛋白质序列可以来源于被研究物种的cDNA序列。可用于搜索相关蛋白质序列的公共数据库包含由例如Uniprot或Swiss-prot托管的数据库。可以使用本文所称的“生物信息学工具”来搜索数据库。生物信息学工具提供了针对数据库中所有可能的序列搜索未解释的MS/MS谱的能力,并提供解释的(注释的)MS/MS谱作为输出。此类工具的非限制性示例是Mascot(www.matrixscience.com)、Spectrum Mill(www.chem.agilent.com)、PLGS(www.waters.com)、PEAKS(www.bioinformaticssolutions.com)、Proteinpilot(download.appliedbiosystems.com//proteinpilot)、Phenyx(www.phenyx-ms.com)、Sorcerer(www.sagenresearch.com)、OMSSA(www.pubchem.ncbi.nlm.nih.gov/omssa/)、X!Tandem(www.thegpm.org/TANDEM/)、Protein Prospector(prospector.ucsf.edu/prospector/mshome.htm)、Byonic(www.proteinmetrics.com/products/byonic)或Sequest(fields.scripps.edu/sequest)。
在一些示例性实施例中,质谱仪可以与液相色谱系统联用。在一些示例性实施例中,质谱仪可以与液相色谱-多反应监测系统联用。更一般地,质谱仪能够通过选择性反应监测(SRM),包含连续反应监测(CRM)和平行反应监测(PRM)进行分析。
如本文所使用的,“多反应监测”或“MRM”是指基于质谱的技术,其可以以高灵敏度、特异性和宽动态范围精确地对复杂基质中的小分子、肽和蛋白质进行定量(PaolaPicotti和Ruedi Aebersold,基于特定反应监测的蛋白质组学:工作流程、潜力、缺陷和未来方向(Selected reaction monitoring-based proteomics:workflows,potential,pitfalls and future directions),9《自然方法(NATURE METHODS)》555–566(2012))。MRM通常可以用三重四极质谱仪进行,其中在第一个四极中选择对应于所选小分子/肽的前体离子,并且在第三个四极中选择前体离子的碎片离子用于监测(Yong Seok Choi等人,用于验证多种阿尔茨海默病生物标志物候选物的靶向人类脑脊液蛋白质组学(Targeted humancerebrospinal fluid proteomics for the validation of multiple Alzheimersdisease biomarker candidates),930《色谱杂志B(JOURNAL OF CHROMATOGRAPHY B)》129–135(2013))。
在一些方面,本申请的方法或系统中的质谱仪可以是电喷雾电离质谱仪、纳米电喷雾电离质谱仪或三重四极质谱仪,其中质谱仪可以与液相色谱系统联用,其中质谱仪能够执行LC-MS(液相色谱-质谱)或LC-MRM-MS(液相色谱-多反应监测-质谱)分析。
如本文所使用的,术语“消化”指蛋白质的一个或多个肽键的水解。使用合适的水解剂对样品中的蛋白质进行消化有几种方法,例如酶促消化或非酶促消化。
如本文所使用的,术语“消化酶”是指能够执行蛋白质消化的大量不同药剂中的任何一种。可以进行酶促消化的水解剂的非限制性示例包含来自斋藤曲霉的蛋白酶、弹性蛋白酶、枯草杆菌蛋白酶、蛋白酶XIII、胃蛋白酶、胰蛋白酶、Tryp-N、胰凝乳蛋白酶、曲霉蛋白酶I、LysN蛋白酶(Lys-N)、LysC内切蛋白酶(Lys-C)、内切蛋白酶Asp-N(Asp-N)、内切蛋白酶Arg-C(Arg-C)、内切蛋白酶Glu-C(Glu-C)或外膜蛋白T(OmpT)、化脓性链球菌的免疫球蛋白降解酶(IdeS)、嗜热菌蛋白酶、木瓜蛋白酶、链霉蛋白酶、V8蛋白酶或其生物活性片段或同源物或其组合。对于讨论蛋白质消化的可用技术的最近综述,参见Switazar等人,“蛋白质消化:可用技术和最新开发的概述(Protein Digestion:An Overview of the AvailableTechniques and Recent Developments)”(Linda Switzar、Martin Giera和WilfriedM.A.Niessen,蛋白质消化:可用技术和最近开发的概述,12《蛋白质组学研究杂志(JOURNALOF PROTEOME RESEARCH)》1067–1077(2013))。
可以适当选择消化酶的量和消化所需的时间。当酶与底物的比率过高时,相应的高消化率将不允许有足够的时间用质谱仪对肽进行分析,并且序列覆盖范围将受到损害。在另一方面,低酶与底物的比率需要长的消化时间,且因此需要长的数据采集时间。酶与底物的比率可以在约1:0.5到约1:200的范围内。
如本文所使用的,通用术语“翻译后修饰”或“PTM”是指多肽在其核糖体合成期间(共翻译修饰)或之后(翻译后修饰)经历的共价修饰。PTM通常由特定的酶或酶途径引入。许多发生在蛋白质骨架内特定特征蛋白质序列(特征序列)的位点。已经记录了几百种PTM,并且这些修饰总是会影响蛋白质的结构或功能的某一方面(Walsh,G.的“蛋白质(Proteins)”(2014),第二版,由威利父子有限公司(Wiley and Sons,Ltd.)出版,ISBN:9780470669853)。各种翻译后修饰包含但不限于切割、N末端延伸、蛋白质降解、N末端的酰化、生物素化(赖氨酸残基与生物素的酰化)、C末端的酰胺化、糖基化、碘化、辅基基团的共价连接、乙酰化(通常在蛋白质N末端处添加乙酰基基团)、烷基化(通常在赖氨酸或精氨酸残基处添加烷基基团(例如甲基、乙基、丙基))、甲基化、腺苷化、ADP-核糖基化、多肽链内或之间的共价交联、磺化、异戊烯化、维生素C依赖性修饰(脯氨酸和赖氨酸羟基化和羧基末端酰胺化)、维生素K依赖性修饰(其中维生素K是谷氨酸残基的羧基化的辅因子,导致γ-羧基谷氨酸盐(glu残基)的形成)、谷氨酰化(谷氨酸残基的共价连接)、甘氨酰化(甘氨酸残基的共价连接)、糖基化(将糖基基团添加到天冬酰胺、羟赖氨酸、丝氨酸或苏氨酸上,产生糖蛋白)、异戊二烯化(添加类异戊二烯基团,诸如法呢醇和香叶基香叶醇)、脂酰化(连接脂质酸官能团)、磷酸泛酸硫基乙胺化(添加来自辅酶A的4′-磷酸泛酸硫基乙胺基部分,如在脂肪酸、聚酮化合物、非核糖体肽和亮氨酸生物合成中)、磷酸化(通常向丝氨酸、酪氨酸、苏氨酸或组氨酸中添加磷酸基团)和硫酸化(通常向酪氨酸残基中添加硫酸基团)。改变氨基酸的化学性质的翻译后修饰包含但不限于瓜氨酸化(通过脱亚胺基化将精氨酸转化为瓜氨酸)和脱酰胺化(将谷氨酰胺转化为谷氨酸或将天冬酰胺转化为天冬氨酸)。涉及结构变化的翻译后修饰包含但不限于二硫键的形成(两个半胱氨酸氨基酸的共价连接)和蛋白质水解切割(肽键处蛋白质的切割)。在示例性实施例中,翻译后修饰是在蛋白质C末端切割赖氨酸。某些翻译后修饰涉及添加其他蛋白质或肽,诸如ISG化(与ISG15蛋白质的共价连接(干扰素刺激基因))、SUMO化(与SUMO蛋白质的共价连接(小泛素相关修饰物))和泛素化(与蛋白质泛素的共价连接)。对于由UniProt策划的PTM的更详细的受控词汇表,参见欧洲生物信息学研究所蛋白质信息资源SIB瑞士生物信息学研究所、欧洲生物信息学研究所DRS-果蝇霉素前体-黑腹果蝇(果蝇)-DRS基因与蛋白质(European Bioinformatics InstituteProteinInformation ResourceSIB Swiss Institute of Bioinformatics,EUROPEANBIOINFORMATICS INSTITUTE DRS-DROSOMYCIN PRECURSOR-DROSOPHILA MELANOGASTER(FRUIT FLY)-DRS GENE&PROTEIN),http://www.uniprot.org/docs/ptmlist。
如本文所使用的,术语“C末端赖氨酸(K)”或“K肽”指氨基酸序列末端可能存在或不存在的氨基酸赖氨酸残基或“K”残基。在示例性实施例中,C末端赖氨酸位于抗体的重链上。术语“截短的肽”或“(des-K)”指具有缺失一个C末端赖氨酸(K)的C末端氨基酸序列的蛋白质的代表性部分。
如本文所使用的,术语“未剪切的”指蛋白质C末端序列,其中C末端序列具有末端赖氨酸(K)氨基酸残基。如本文所使用的,术语“剪切的”指蛋白质C末端序列,其中C末端序列缺失末端赖氨酸(K)氨基酸残基。
如本文所使用的,术语“对K肽的百分比进行分析和定量”是指比较第一测定信号和第二测定信号之间的差异,足以确定蛋白质序列的C末端赖氨酸的相对存在或不存在。在示例性实施例中,蛋白质序列是抗体重链。
如本文所使用的,术语“重肽”指本发明的任何肽或其等价物,其中肽的至少一个或多个碳或氮原子是其重同位素,例如
如本文所使用的,术语“肽消化物”是指由蛋白质与一种或多种能够消化蛋白质序列的酶接触而产生的肽混合物。在示例性实施例中,肽消化物包含代表消化蛋白质C末端的多肽序列。
应当理解,本发明不限于任何上述感兴趣蛋白质、治疗性蛋白质、重组蛋白、重组宿主细胞、抗体、液相色谱系统、质谱仪、数据库、生物信息学工具、消化酶、翻译后修饰或重肽,并且任何感兴趣蛋白质、治疗性蛋白质、重组蛋白、重组宿主细胞、抗体、液相色谱系统、质谱仪、数据库、生物信息学工具、消化酶、翻译后修饰或重肽可以通过任何合适的方式进行选择。
通过参考以下示例,将更充分地理解本发明。然而,以下示例不应被解释为限制本发明的范围。
示例
材料和方法。当由本领域的技术人员实践时,本发明可以利用药物化学、免疫学、分子生物学、细胞生物学、重组DNA技术以及测定技术领域中的常规技术,如在以下文献中描述的技术:例如,Sambrook等人,《分子克隆:实验室手册(Molecular Cloning:ALaboratory Manual)》,第3版,2001;Ausubel等人,《精编分子生物学实验指南(ShortProtocols in Molecular Biology)》,第5版,1995;《酶学方法(Methods inEnzymology)》,学术出版社有限公司(Academic Press,Inc.);MacPherson、Hames和Taylor(编辑),《PCR 2:实用方法(PCR 2:A practical approach)》,1995;Harlow和Lane(编辑),《抗体:实验室手册(Antibodies,a Laboratory Manual)》1988;Freshney(编辑),《动物细胞培养(Culture of Animal Cells)》,第4版,2000;《分子生物学方法(Methods inMolecular Biology)》,第149卷(John Crowther,《ELISA指南(The ELISA Guidebook)》),胡马纳出版社(Humana Press)2001,以及这些论文的后期版本(例如,Michael Green,《分子克隆(Molecular Cloning)》(第4版,2012)以及Freshney,《动物细胞培养》(第7版,2015),以及当前的电子版本。
在本公开内提供了可用于对蛋白质中的PTM进行定量和分析的方法。更具体地,本公开提供了对蛋白质(例如抗体)中的C末端赖氨酸(K)进行定量和分析的方法。该方法包含将一组重C末端肽标准品应用于消化的蛋白质。蛋白质可以被蛋白酶诸如胰蛋白酶和其他合适的酶消化。
本发明的方法可涉及在每次LC-MS/MS运行中将校准曲线加入抗体消化物中,并将与消化的des-K肽大约等摩尔量的重des-K肽注射到柱上。未加工的C末端K可以在单个LC-MS/MS肽图谱实验中定量。
本发明的方法可以涉及生成跨越约1:1000-1:1K与des-K肽的比率范围的校准曲线。校准曲线可以具有小于约10%、小于约9%或小于约8%的误差。
质谱可以使用各种光谱仪进行定量,诸如例如Thermo Q-Exactive Plus 3、Q-Exactive Plus 4或Orbitrap Fusion Lumos质谱仪。
以下工作示例证明了对重组蛋白中的PTM进行鉴定和定量的示例性方法。
示例1.测定设计和校准方法
该示例显示了本发明测定的实验设计,用于生成校准曲线,以准确地评估用PTM修饰的肽和不含所述PTM的相同肽的比率。
所有轻同位素肽标准品和重同位素肽标准品均购自新英格兰肽公司(NewEngland Peptide)(马萨诸塞加德纳(Gardner,MA))。三氟乙酸(TFA)、甲酸(FA)、三[2-羧乙基]膦盐酸盐(TCEP-HCl)和Optima LC/MS级乙腈(ACN)购自赛默飞世尔科技公司(ThermoFisher Scientific)(伊利诺伊罗克福德(Rockford,IL)),而冰醋酸和碘乙酰胺(IAM)购自西格玛奥德里奇公司(Sigma-Aldrich)(密苏里圣路易斯(St.Louis,MO))。测序级修饰胰蛋白酶、超纯尿素和超纯1M三(羟甲基)氨基甲烷盐酸盐(Tris-HCl)分别购自普洛麦格公司(Promega)(威斯康辛麦迪逊(Madison,WI))、阿法埃莎(Alfa Aesar)(马萨诸塞黑弗里尔(Haverhill,MA))和英杰公司(Invitrogen)(加利福尼亚卡尔斯巴德(Carlsbad,CA))。Milli-Q水通过Millipore Milli-Q Advantage A10水纯化系统进行纯化。
同位素HC C末端肽标准品用于将相应的轻未加工的肽和经加工的肽之间的质谱仪响应归一化。肽标准品包含SLSLSLG(SEQ ID NO:1)、SLSLSLGK(SEQ ID NO:2)、SLSLSPG(SEQ ID NO:3)和SLSLSPGK(SEQ ID NO:4)。
图1显示了重同位素SLSLSLGK(SEQ ID NO:2)标准品。
将肽标准品溶解在10% ACN、0.1% TFA中,并根据C末端序列(LGK或PGK)合并成两个校准曲线组。每组含有等摩尔浓度的Δ4des-K和K肽以及Δ8、Δ12和Δ16K肽(K与des-K的摩尔比分别为1:10、1:100和1:1000)。如图3所示,通过XIC分析混合物。
如图4A所示,SLSLSPGK(SEQ ID NO:4)和SLSLSPG(SEQ ID NO:3)的等摩尔混合物通过UV色谱法定量。PGK肽的相应K AUC/des-K AUC值为1.08。类似地,LGK肽的K AUC/des-KAUC值为1.07。如图4B所示,等摩尔量的SLSLSPGK(SEQ ID NO:4)和SLSLSPG(SEQ ID NO:3)试剂组由XIC定量。PGK和LGK肽的重AUC/轻AUC值如表1所示。
表1.
如表1所示,重肽的信号近似等于相应的轻肽,证实了重肽在生成可应用于轻肽的校准曲线中的用途。
为了确定该方法的准确性,已知量的轻des-K和K在1:10–1:1000K与des-K肽的比率范围内加入试剂组,并使用校准曲线校正方法进行测量。如表2所示,校准曲线校正值(或“归一化”值)与预期的赖氨酸百分比非常接近。
表2.
示例2.mAbs的未加工的C末端赖氨酸定量
该示例显示了对重组蛋白的C末端赖氨酸(K)进行准确定量的本发明测定的实验设计。
对于抗体分析,将校准曲线加到抗体消化物中,以便在每次LC-MS/MS运行中,将大约等摩尔量的重des-K肽与消化的des-K肽注射到柱上。
抗体消化。在80℃变性和还原十分钟之前,将等重量的五个IgG4 mAb样品缓冲交换到5mM乙酸和5mM TCEP-HCl中。将样品在4M尿素/0.1m Tris-HCl,pH 7.5中进一步变性,并在室温和黑暗中用5mM IAM烷基化30分钟。通过加入0.1M Tris-HCl,pH 7.4,将尿素浓度降低至1M,并且在37℃下以1:20的抗体与胰蛋白酶比率消化抗体4小时。通过在0.2% TFA中酸化样品来淬灭酶活性。
LC-MS和LC-MS/MS参数。将5μg抗体消化物的等分试样注射到2.1mm×150mmWaters Acquity超高效液相色谱(UPLC)带电表面杂化(CSH)C18柱上,该柱具有1.7μm颗粒。使用Waters Acquity I-Class UPLC装置在该柱上分离肽,流速设定为250μL/min,且柱温为40℃。梯度由有机流动相(ACN和0.1% FA)相对于水增加0.1-35%,且0.1% FA超过95分钟组成。
使用Thermo Q-Exactive Plus,使用QE Plus 3和4系统和/或Orbitrap FusionLumos质谱仪获得质量数据。针对由设定为1×106的自动增益控制(AGC)目标或50ms的最大离子注入时间(max IT)限制的离子群,在Q-Exactive Plus上进行全质量扫描,在140,000分辨率(m/z 200)下获得300–2000的m/z范围。
对于需要通过数据相关采集(DDA)进行MS/MS鉴定的实验,通过使用归一化碰撞能量为30的高能碰撞解离(HCD)以1.5Th窗口分离和碎裂五种最强的肽离子中的每一者,开始单个dd-MS/MS环路。
使用1×105的AGC目标或100ms的max IT来收集碎片离子群数据,然后以17,500的分辨率进行扫描,此时将采样的前体放在排除列表中10秒钟,以确保对强度较低的离子进行分析。
用于MS采集的Orbitrap Fusion Lumos参数与QE-Plus的参数相同,只是分辨率设定为120,000(m/z 200),且ACG目标设定为5×105。MS/MS设置的差异如下:通过一秒的循环时间而不是通过前体的数量来限制DDA;将AGC目标设定为2×104;将max IT控制在50ms,但如果有可并行的时间,则允许继续注入;并以15,000的分辨率(m/z200)进行扫描。
相关的LC-MS/MS原始文件通过Byonic 3.0使用自定义的fasta文件根据以下参数对每种抗体进行分析:(1)切割位点:R、K;(2)切割侧:C末端;(3)消化特异性:完全特异性;(4)前体质量公差:10ppm;(5)碎裂类型:QTOF/HCD;(6)碎片质量公差:20ppm;(7)固定和可变修饰:固定C氨基甲基,可变M氧化,可变E/Q对pE,和可变C末端K损失;和(8)聚糖修饰:50种常见的双天线N-聚糖。通过设定为10ppmm/z公差的Genesis算法在Thermo Xcalibur 3.1中提取轻和重C末端肽的1+和2+电荷状态的离子色谱图。将定量AUC测量结果导出到Microsoft Excel,其中构建了1:1000–1:1k与des-K范围内的校准曲线,以计算每个样品中未加工的C末端K的百分比。
表3显示了使用校准曲线校正方法获得的结果,与正常的未校正的肽图谱进行比较。如表3所示,与本公开的校准曲线(CC)校正方法相比,在使用未校正的肽图谱进行肽定量期间,C末端赖氨酸的百分比被高估。因此,本发明的方法为定量重组蛋白PTM,例如抗体的C末端赖氨酸,提供了关键的校正。
表3.
示例3.双特异性抗体(bsAb)的未加工的C末端赖氨酸定量
该示例显示了准确地对双特异性抗体(bsAb)的PTM进行定量的本发明测定的实验设计。
如上所述消化七种基于IgG4的bsAb,且bsAb含有SLSLSLGK(SEQ ID NO:2)和SLSLSPGK(SEQ ID NO:4)C末端序列。在每次LC-MS/MS运行中,将校准曲线加到抗体消化物中,并将与消化的des-K肽大约等摩尔量的重des-K肽注射到柱上。对对照bsAb消化物进行传统的、未校正的肽图谱分析。
表4显示了使用校准曲线校正方法获得的结果,与PGK C末端序列的正常的、未校正的肽图谱进行比较。如表4所示,与本公开的CC校正方法相比,在使用未校正的肽图谱进行肽定量期间,C末端赖氨酸的百分比被显著高估。
表4.
表5显示了使用校准曲线校正方法获得的结果,与LGK C末端序列的未校正的肽图谱比较。如表5所示,与本公开的CC校正方法相比,在使用未校正的肽图谱进行肽定量期间,C末端赖氨酸的百分比被显著高估。
表5.
当使用本发明的方法时,进行了进一步的实验来研究仪器之间的定量变化。如上所述消化五种IgG4 mAb和一种IgG1 mAb。在每次LC-MS/MS运行中,将校准曲线加到抗体消化物中,并将与消化的des-K肽大约等摩尔量的重des-K肽注射到柱上。对对照mAb消化物进行传统的、未校正的肽图谱分析。使用Thermo Q-Exactive Plus和Orbitrap Fusion Lumos质谱仪获得质量数据。
如表6所示,当使用CC校正方法时,当使用QE-Plus或Fusion质谱仪定量时,赖氨酸百分比的差异为零或很小。然而,当使用未校正的肽图谱时,在仪器之间观察到更大的赖氨酸百分比可变性。
表6.
进行了额外的实验,以研究当应用于bsAb时,由于使用本发明方法的仪器而导致的信号可变性。如上所述消化七种基于IgG4的bsAb(含有SLSLSLGK(SEQ ID NO:2)和SLSLSPGK(SEQ ID NO:4)C末端序列)。在每次LC-MS/MS运行中,将校准曲线加到抗体消化物中,并将与消化的des-K肽大约等摩尔量的重des-K肽注射到柱上。对对照bsAb消化物进行传统的、未校正的肽图谱分析。
使用Thermo Q-Exactive Plus和Orbitrap Fusion Lumos质谱仪获得质量数据。如表7所示,当使用CC校正方法时,使用QE-Plus或Fusion质谱仪进行定量时,赖氨酸的百分比差异为零或很小。然而,当使用未校正的肽图谱时,在仪器之间观察到更大的赖氨酸百分比可变性。
表7.
/>
- 人白细胞介素29成熟肽第33位赖氨酸、35位精氨酸定点突变为精氨酸、赖氨酸的变异体及其制备方法
- 抗N末端脑钠肽前体的抗体和检测N末端脑钠肽前体的试剂和试剂盒