基于DARPin的新型CD123接合物
文献发布时间:2024-04-18 19:58:26
相关专利申请的交叉引用
本申请要求于2021年3月9日提交的US 63/158,539、于2021年4月9日提交的US63/173,227和于2021年12月9日提交的US 63/265,187的优先权益。这些专利申请的公开内容以引用方式整体并入本文用于所有目的。
技术领域
本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中锚蛋白重复结构域对人CD123具有结合特异性。此外,本发明涉及编码此类重组结合蛋白的核酸、包含此类蛋白质或核酸的药物组合物,以及此类结合蛋白、核酸或药物组合物在用于治疗或诊断包括人在内的哺乳动物的疾病诸如癌症(例如,急性髓性白血病(AML))的方法中的用途。
背景技术
急性髓性白血病(AML)是一种异质和复杂的恶性疾病,其特征在于快速的细胞增殖、侵袭性的临床过程和通常高的死亡率。治疗抗性仍然是急性AML相关死亡的主要原因(Winer和Stone,Ther Adv Hematol;2019;10)。虽然采用化学疗法的标准方案仍然是世界范围内应用的主要治疗方法,但是免疫疗法的最新进展已经为化学疗法抗性AML提供了有效的治疗选择。此类免疫疗法方法包括单克隆抗体、双特异性抗体和表达嵌合抗原受体的T细胞(CAR-T细胞)。
CD123是治疗癌症(尤其是AML)的有吸引力的靶标,因为CD123在大约70%-80%的AML母细胞和白血病干细胞上表达(Ehninger等人Blood Cancer Journal 4,e218(2014))。CD123也已被临床验证为AML疗法的靶标,抗CD123抗体可用作单药疗法或与细胞毒性剂结合使用(Winer和Stone,Ther Adv Hematol;2019;10)。然而,这些药物已显示出显著的副作用或低功效。例如,用塔妥珠单抗(talcotuzumab,一种人源化抗CD123单克隆抗体)治疗未能提供有效的治疗效果。Tagraxofusp(一种经FDA批准用于治疗成人和2岁及以上儿科患者的母细胞性浆细胞样树突状细胞肿瘤(BPICN)的抗CD123)与毛细血管渗漏综合征相关。毛细血管渗漏综合征是一种罕见但可能致命的病症,其中血管渗漏血浆引起血压严重下降。这可能导致器官衰竭。
CAR-T细胞疗法是一种强烈影响淋巴恶性肿瘤管理的方法。尽管在将该技术也应用于AML方面存在很大兴趣,但是在实践中这已经被证明具有挑战性。关于单克隆抗体,CD123已被认为是AML中CAR-T细胞疗法的最有希望的靶标。然而,这种方法的临床前模型显示出对非AML细胞的广泛副作用(靶向/肿瘤外毒性(on-target/off-tumor toxicity)),并且细胞因子释放综合征(CRS)是另一种公认的副作用。
使用双特异性抗体的T细胞定向杀伤肿瘤细胞是另一种最新的治疗工具,其已经用于治疗各种癌症类型,包括AML。这些T细胞接合物(TCE)双特异性抗体包含两个不同的可变区:一个结合T细胞受体复合物亚单位CD3,另一个结合肿瘤细胞表面抗原。TCE与这两个靶标的结合提供了细胞间的功能性连接,导致T细胞激活和针对肿瘤细胞的细胞毒性活性,绕过了正常的TCR-MHC相互作用(Ellerman,Methods;154:102-117(2019))。伏妥珠单抗(Flotetuzumab)是双亲和力重靶向抗体
然而,单特异性抗体疗法和双特异性抗体疗法二者都可能存在各种缺点,诸如生产成本高,并且它们可能导致严重的副作用,诸如细胞因子释放综合征(CRS)(Shimabukuro-Vornhagen等人,J Immunother Cancer;6(1):56(2018);Labrjin等人,NatRev Drug Discov;18(8):585-608(2019))和/或靶向/肿瘤外毒性(Weiner等人,CancerRes.;55(20):4586–4593(1995);Weiner等人,Cancer Immunol.Immunother.;42(3);141–150(1996))。当与天然TCR-MHC相互作用相比时,基于抗体的T细胞接合物通常显示出对CD3的亲和力高超过1000倍(Wu等人,Pharmacol Ther;182:161–75(2018);WO2014/167022;Junntila等人,Cancer Res.;19:5561–71(2014);Yang等人,J Immunol Aug.;15(137):1097–100(1986))。这种高亲和力与较低的T细胞激活和肿瘤细胞杀伤效率相关(Bortoletto等人,Eur.J.Immunol.,32;11:3102–3107(2002);Ellerman,Methods;154:102-117(2019);Mandikian等人,Mol.Cancer Ther.;17(4):776LP-785(2018);Vafa等人,Frontiers in Oncology;10:446(2020))。此外,由TCE靶向的肿瘤表面标记的下调可导致肿瘤对TCE疗法的抗性。
急性髓性白血病(AML)是在许多方面例证了癌症疗法的挑战和目前可用的癌症疗法的缺点的一种癌症类型,如上文所讨论。对于AML,由于高死亡率导致的医疗需要仍然很高,并且复发性或难治性AML的治疗继续在治疗上具有挑战性。
因此,仍然需要具有有益性质的新型CD123特异性结合蛋白。此类结合蛋白可以用于治疗和表征疾病(包括癌症,诸如AML)的治疗和诊断方法。具体而言,需要可以用于特异性靶向癌细胞上的CD123并且还可以容易地与其他功能部分(诸如,一个或多个结合部分)组合的新型CD123特异性结合蛋白。
发明内容
本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中锚蛋白重复结构域对人CD123具有结合特异性。此外,本发明涉及编码此类重组结合蛋白的核酸、包含此类蛋白质或核酸的药物组合物,以及此类结合蛋白、核酸或药物组合物在用于治疗或诊断包括人在内的哺乳动物的疾病诸如癌症(例如,急性髓性白血病(AML))的方法中的用途。
本发明的重组结合蛋白特异性结合至或靶向肿瘤相关抗原(TAA)CD123。本发明的此类结合蛋白可以作为用于产生新型治疗剂或诊断剂的工具或结构单元。本文还公开了这样的重组结合蛋白,其中CD123特异性锚蛋白重复结构域与一个分子中的一个或多个其他功能部分组合。此类其他功能部分包括对免疫细胞上表达的靶标具有结合特异性的结合部分、半衰期延长部分、对另一种肿瘤相关抗原具有结合特异性的结合部分和/或细胞毒性剂。因此,具有针对CD123的结合特异性的本发明的重组结合蛋白可用于产生新型治疗分子,与目前的治疗方式相比,该新型治疗分子可以提供改善的毒性特征和/或治疗窗口。
基于本文提供的公开内容,本领域技术人员将认识到或仅能够使用常规实验来确定本文所述的本发明的具体实施方案的许多等同物。此类等同物旨在由以下实施方案(E)涵盖。
1.在第一实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQ ID NO:12至30和58至59,以及(2)其中SEQ ID NO:12至30和58至59中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。
2.在第二实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少85%氨基酸序列同一性的氨基酸序列。
3.在第三实施方案中,本发明涉及根据实施方案1和2所述的重组结合蛋白,其中所述锚蛋白重复结构域在PBS中以小于约150nM、任选地约5pM至约150nM范围内的解离常数(K
4.在第四实施方案中,本发明涉及根据任一前述实施方案所述的重组结合蛋白,其中所述锚蛋白重复结构域以0.1nM至约100nM范围内的EC
5.在第五实施方案中,本发明涉及根据任一前述实施方案所述的重组结合蛋白,还包含对免疫细胞上表达的靶标具有结合特异性的结合部分。
6.在第六实施方案中,本发明涉及根据实施方案5所述的重组结合蛋白,其中所述免疫细胞是T细胞并且其中免疫细胞上表达的所述靶标是CD3。
7.在第七实施方案中,本发明涉及根据实施方案5至6中任一项所述的重组结合蛋白,其中对免疫细胞上表达的靶标具有结合特异性的所述结合部分是锚蛋白重复结构域。
8.在第八实施方案中,本发明涉及根据实施方案5至7中任一项所述的重组结合蛋白,其中对免疫细胞上表达的靶标具有结合特异性的所述结合部分是对人CD3具有结合特异性的锚蛋白重复结构域。
9.在第九实施方案中,本发明涉及根据实施方案5至7中任一项所述的重组结合蛋白,其中对免疫细胞上表达的靶标具有结合特异性的所述结合部分是对人CD3具有结合特异性的锚蛋白重复结构域,并且其中对人CD3具有结合特异性的所述锚蛋白重复结构域包含与SEQ ID NO:34至38中的任一者具有至少85%氨基酸序列同一性的氨基酸序列。
10.在第十实施方案中,本发明涉及根据实施方案9所述的重组结合蛋白,其中对人CD3具有结合特异性的所述锚蛋白重复结构域包含SEQ ID NO:34至38中的任一者的氨基酸序列。
11.在第十一实施方案中,本发明涉及根据实施方案5至10中任一项所述的重组结合蛋白,其中对人CD123具有结合特异性的所述锚蛋白重复结构域和对免疫细胞上表达的靶标具有结合特异性的所述结合部分与肽接头共价连接。
12.在第十二实施方案中,本发明涉及根据实施方案11所述的重组结合蛋白,其中所述肽接头是富含脯氨酸-苏氨酸的肽接头。
13.在第十三实施方案中,本发明涉及根据实施方案11至12所述的重组结合蛋白,其中所述肽接头的氨基酸序列具有1个至50个氨基酸的长度。
14.在第十四实施方案中,本发明涉及根据任一前述实施方案所述的重组结合蛋白,其中所述结合蛋白还包含半衰期延长部分。
15.在第十五实施方案中,本发明涉及根据实施方案14所述的重组结合蛋白,其中所述半衰期延长部分是对人血清白蛋白具有结合特异性的锚蛋白重复结构域。
16.在第十六实施方案中,本发明涉及根据实施方案15所述的重组结合蛋白,其中对人血清白蛋白具有结合特异性的所述锚蛋白重复结构域包含与SEQ ID NO:31至33中的任一者的氨基酸序列具有至少85%同一性的氨基酸序列。
17.在第十七实施方案中,本发明涉及根据实施方案15和16所述的重组结合蛋白,其中对人血清白蛋白具有结合特异性的所述锚蛋白重复结构域包含SEQ ID NO:31至33中的任一者的氨基酸序列。
18.在第十八实施方案中,本发明涉及根据前述实施方案中任一项所述的重组结合蛋白,其中所述结合蛋白还包含对在肿瘤细胞中表达的靶标具有结合特异性的至少一个结合部分,其中在肿瘤细胞中表达的所述靶标与人CD123不同。
19.在第十九实施方案中,本发明涉及编码根据前述实施方案中任一项所述的重组结合蛋白的核酸。
20.在第二十实施方案中,本发明涉及一种药物组合物,所述药物组合物包含根据实施方案1至18中任一项所述的重组结合蛋白或根据实施方案19所述的核酸,以及药学上可接受的载剂和/或稀释剂。
21.在第二十一实施方案中,本发明涉及一种人类患者的肿瘤组织中的免疫细胞激活的方法,所述方法包括向所述患者施用根据实施方案1至18中任一项所述的重组结合蛋白、根据实施方案19所述的核酸或根据实施方案20所述的药物组合物的步骤。
22.在第二十二实施方案中,本发明涉及根据实施方案21所述的方法,其中所述免疫细胞是T细胞。
22a.在实施方案22a中,本发明涉及根据实施方案21所述的方法,其中所述免疫细胞是自然杀伤(NK)细胞。
23.在第二十三实施方案中,本发明涉及一种治疗医学病症的方法,所述方法包括向有需要的患者施用治疗有效量的根据实施方案1至18中任一项所述的重组结合蛋白、根据实施方案19所述的核酸或根据实施方案20所述的药物组合物的步骤。
24.在第二十四实施方案中,本发明涉及根据实施方案23所述的方法,其中所述医学病症是癌症。
25.在第二十五实施方案中,本发明涉及根据实施方案23所述的方法,其中所述医学病症是以液体肿瘤为特征的癌症。
26.在第二十六实施方案中,本发明涉及根据实施方案23所述的方法,其中所述医学病症是白血病。
27.在第二十七实施方案中,本发明涉及根据实施方案23所述的方法,其中所述医学病症是急性髓性白血病。
28.在第二十八实施方案中,本发明涉及根据实施方案1至18中任一项所述的重组结合蛋白、根据实施方案19所述的核酸或根据实施方案20所述的药物组合物,所述重组结合蛋白、所述核酸或所述药物组合物在疗法中使用。
29.在第二十九实施方案中,本发明涉及根据实施方案1至18中任一项所述的重组结合蛋白、根据实施方案19所述的核酸或根据实施方案20所述的药物组合物,所述重组结合蛋白、所述核酸或所述药物组合物在治疗癌症中使用,任选地在治疗以液体肿瘤为特征的癌症中使用。
30.在第三十实施方案中,本发明涉及根据实施方案29所述使用的重组结合蛋白或核酸或药物组合物,其中所述癌症是白血病,任选地其中所述癌症是急性髓性白血病。
附图说明
图1(A-B).结合至人CD123的锚蛋白重复蛋白的表面等离子共振(SPR)分析。图1A.
图2.本发明的示例性结合蛋白与表达CD123的肿瘤细胞的结合。图中显示了
图3.通过测量激活标记CD25确定的短期T细胞激活。将Pan-T效应细胞和Molm-13靶细胞以5:1的E:T比率温育,并且在所示分子的系列稀释液的存在下共培养24小时后通过FACS评估T细胞激活。将激活的T细胞作为活的CD8+/CD25+细胞进行门控。图中显示了由选定的锚蛋白重复蛋白
图4.肿瘤细胞杀伤作用通过测量LDH释放的细胞毒性测定法来评估。将Pan-T效应细胞和Molm-13靶细胞以5:1的E:T比率温育,并且在所示分子的系列稀释液的存在下共培养24小时后通过FACS评估肿瘤细胞杀伤作用。图中显示了由选定的锚蛋白重复蛋白
图5(A-B):通过HTRF评估CD123特异性锚蛋白重复蛋白与(图5A)全长CD123靶标(NTD/D2/D3结构域)和(图5B)截短的CD123靶标(D2/D3结构域)的结合。测试
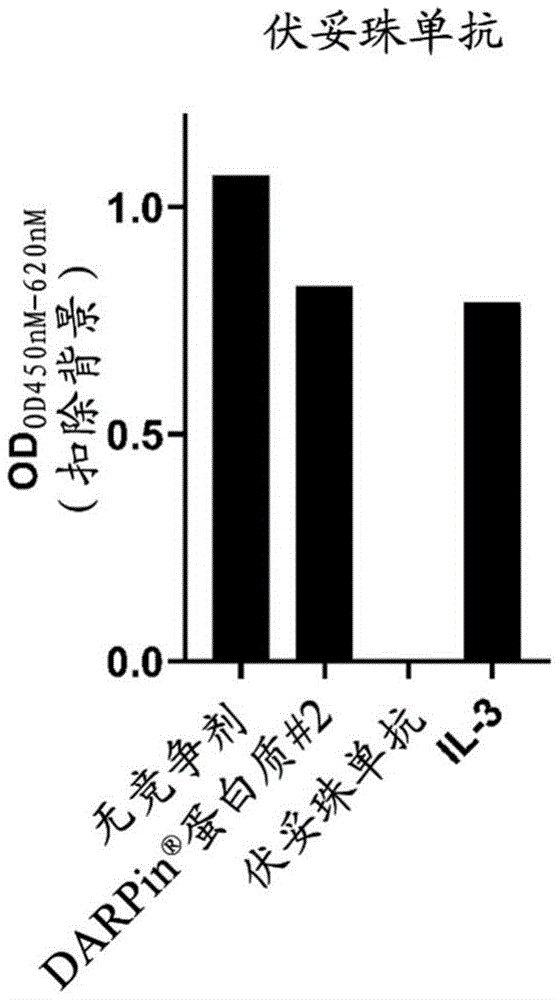
图6(A-B):通过ELISA对CD123结合DARPin、伏妥珠单抗和配体的结合竞争测定。在使用抗链霉亲和素-POD检测剂测试对固定化的
图7(A-B).图7A:在腹膜内注射hPBMC、在hPBMC注射后两天皮下异种移植MOLM-13肿瘤细胞并用PBS1X(黑色圆形)或0.5mg/kg的多结构域形式的
具体实施方式
本文公开了包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性。本文还公开了编码重组结合蛋白的核酸、包含结合蛋白或核酸的药物组合物、以及使用结合蛋白、核酸或药物组合物的方法。
锚蛋白重复结构域
所描述的包含经设计的锚蛋白重复基序或模块的重组结合蛋白或它们的结合域在本文中也称为
本文所述的锚蛋白重复结构域通常包含提供结构的核心支架,以及结合到靶标的靶标结合残基。结构核心包括保守的氨基酸残基,并且靶标结合表面包括根据靶标而不同的氨基酸残基。
经设计的锚蛋白重复蛋白文库(WO2002/020565;Binz等人,Nat.Biotechnol.22,575-582,2004;Stumpp等人,Drug Discov.Today 13,695-701,2008)可用于选择以高亲和力结合其靶标的靶标特异性设计的锚蛋白重复结构域。此类靶标特异性设计的锚蛋白重复结构域继而可用作用于治疗疾病的重组结合蛋白的有价值的组分。经设计的锚蛋白重复蛋白是一类结合分子,其具有克服单克隆抗体限制的潜力,从而允许新型治疗方法。此类锚蛋白重复蛋白可包含单个经设计的锚蛋白重复结构域,或者可包含两个或更多个具有相同或不同靶标特异性的经设计的锚蛋白重复结构域的组合(Stumpp等人,Drug Discov.Today13,695-701,2008;美国专利号9,458,211)。仅包含单个经设计的锚蛋白重复结构域的锚蛋白重复蛋白为小蛋白质(14kDa),其可被选择为以高亲和力和特异性结合给定靶蛋白。这些特征以及在一种蛋白质中组合两个或更多个经设计的锚蛋白重复结构域的可能性使得经设计的锚蛋白重复蛋白成为理想的激动、拮抗和/或抑制性药物候选物。此外,此类锚蛋白重复蛋白可被工程化以携带各种效应子功能,例如细胞毒性剂或半衰期延长剂,从而实现全新的药物形式。
经设计的锚蛋白重复蛋白还可以靶向单克隆抗体不易接近的表位。所描述的经设计的锚蛋白重复蛋白的其他优点是它们通常具有低免疫原性潜力并且没有脱靶效应或脱靶效应不显著。
是Molecular Partners AG(Switzerland)拥有的商标。
如上文所讨论,CD123是治疗某些癌症(特别是AML)的有吸引力的治疗靶标。本文所述的重组结合蛋白包含特异性结合至人CD123的锚蛋白重复结构域和锚蛋白重复模块。
在一个实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQID NO:12至30和58至59,以及(2)其中SEQ ID NO:12至30和58至59中的任一者中的至多9个氨基酸被另一氨基酸取代的序列。
在一个实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQID NO:12至30和58至59,以及(2)其中SEQ ID NO:12至30和58至59中的任一者中的至多9个、至多8个、至多7个、至多6个、至多5个、至多4个、至多3个、至多2个或至多1个氨基酸被另一氨基酸取代的序列。
在一个实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:SEQ IDNO:12至30和58至59。
在另一个实施方案中,本存在发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少约85%氨基酸序列同一性的氨基酸序列。
在另一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:1具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:2具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:3具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:4具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:5具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:6具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:7具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:8具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:9具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:55具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:56具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述锚蛋白重复结构域包含与SEQ ID NO:57具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在另一个实施方案中,本发明涉及一种包含锚蛋白重复结构域的重组结合蛋白,其中所述锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述锚蛋白重复结构域包含选自由以下项组成的组的氨基酸序列:SEQ ID NO:1至9和55至57。
在另一个方面,本发明涉及如上所述的重组结合蛋白,还包含对免疫细胞上表达的靶标具有结合特异性的至少一个结合部分。在一个实施方案中,所述免疫细胞是T细胞。在另一个实施方案中,所述免疫细胞是自然杀伤(NK)细胞。用于本发明的对免疫细胞上表达的靶标具有结合特异性的结合部分的示例包括抗体、替代性支架和多肽。
抗体包括包含衍生自抗体或免疫球蛋白分子的抗原结合结构域的任何多肽或蛋白质。抗原结合结构域可衍生自例如单克隆抗体、多克隆抗体、重组抗体、人抗体、人源化抗体和单结构域抗体,例如来自例如人或骆驼科动物来源的重链可变结构域(VH)、轻链可变结构域(VL)和可变结构域(VHH)。在一些情况下,有利的是抗原结合结构域衍生自结合部分最终将在其中使用的相同物种。例如,对于在人中的应用,本文所述的结合部分的抗原结合结构域包含人或人源化抗原结合结构域可能是有益的。抗体可使用本领域熟知的技术获得。
在一个实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分是抗体。
在一个实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分是骆驼科动物纳米抗体。骆驼科动物纳米抗体(也称为骆驼科动物单一结构域抗体或VHH)衍生自哺乳动物的骆驼科家族,诸如美洲驼、骆驼和羊驼。与其他抗体不同,骆驼科动物抗体缺乏轻链并且由两条相同的重链构成。骆驼科动物抗体通常具有大约15kDa的相对低的分子量。
在一个实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分是鲨鱼抗体结构域。鲨鱼抗体结构域,如骆驼科动物纳米抗体,也缺乏轻链。
替代性支架包括包含结合结构域的任何多肽或蛋白质,该结合结构域能够结合抗原(诸如药物分子)且不衍生自抗体或免疫球蛋白分子。替代性支架的结合结构域可包含或可衍生自多种不同的多肽或蛋白质结构。替代性支架包括但不限于阿德耐汀(单抗体)、亲和体、阿菲林、阿菲默和适体、阿非汀、α抗体、抗运载蛋白、基于犰狳重复蛋白的支架、阿去默、阿维默、基于锚蛋白重复蛋白的支架(诸如
在一个实施方案中,对免疫细胞上表达替代靶标具有结合特异性的结合部分是替代性支架。在一个实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分包括抗原结合结构域,该抗原结合结构域衍生自以下或与以下相关:阿德耐汀、单抗体、亲和体、阿菲林、阿菲默、适体、阿非汀、α抗体、抗运载蛋白、重复蛋白结构域、犰狳重复结构域、阿去默、阿维默、锚蛋白重复结构域、非诺莫、打结素、库尼兹结构域或T细胞受体(TCR)。
阿德耐汀最初衍生自人III型纤连蛋白蛋白的第十个细胞外结构域(10Fn3)。III型纤连蛋白结构域具有7个或8个β链,其分布在两个β片层之间,该两个β片层自身彼此堆积以形成蛋白质的核心,并且还含有环(类似于CDR),该环将β链彼此连接并且暴露于溶剂。在β片层夹层的每个边缘处存在至少三个这样的环,其中边缘是垂直于β链方向的蛋白质的边界(参见美国专利号6,818,418)。由于这种结构,这种非抗体支架模拟在性质和亲和力上与抗体的性质和亲和力类似的抗原结合性质。这些支架可用于体外的环随机化和改组策略,其类似于体内抗体的亲和力成熟过程。
亲和体亲和配体由基于蛋白A的IgG结合结构域之一的支架的三螺旋束构成,该蛋白A是来自细菌金黄色葡萄球菌(Staphylococcus aureus)的表面蛋白。该支架结构域由58个氨基酸组成,其中13个氨基酸被随机化以产生具有大量配体变体的亲合体文库(参见例如美国专利号5,831,012)。亲和体分子模拟抗体,但与抗体的约150kDa的分子量相比,亲和体分子相当小,具有约6kDa的分子量。尽管大小不同,但亲和体分子的结合位点与抗体的结合位点相似。
阿菲林是结构上衍生自人泛素(历史上也衍生自γ-B晶体蛋白)的合成抗体模拟物。阿菲林由两个相同的结构域组成,主要具有β片层结构,总分子质量为约20kDa。它们含有几种适于修饰的表面暴露的氨基酸。阿菲林在其对抗原的亲和力和特异性方面类似于抗体,但在结构上不类似。
阿菲默是一种肽适体,具有已知为SQT(胱抑蛋白A四重突变体-Tracy)的结构。适体和阿菲默是负责与用于结构限制的惰性和刚性蛋白支架亲和结合的短肽,其中结合肽的N-末端和C-末端都嵌入惰性支架中。
阿非汀是DNA结合蛋白Sac7d的变体,其被工程化以获得特异性结合亲和力。Sac7d最初衍生自古细菌超嗜热菌嗜酸热硫化叶菌(Sulfolobus acidocaldarius)并与DNA结合以防止其热变性。阿非汀在商业上被称为纳米菲汀(Nanofitin)。
α抗体是小的(大约10kDa)蛋白质,其被工程化以结合多种抗原,因此是抗体模拟物。α抗体支架是基于卷曲螺旋结构计算设计的。标准α抗体支架含有三个α-螺旋,每个由四个七肽重复(7个残基的片段)构成,通过富含甘氨酸/丝氨酸的接头连接。标准七肽序列是“IAAIQKQ”。α抗体靶向细胞外和细胞内蛋白的能力以及它们的高结合亲和力可允许它们结合抗体不能达到的靶标。
抗运载蛋白是具有在脂质运载蛋白中发现的稳健且保守的β-桶结构的一组结合蛋白。脂质运载蛋白是一类包含一条肽链(150个-190个氨基酸)的细胞外蛋白,其负责识别、储存和运输各种生物分子,诸如信号传导分子。
基于犰狳重复蛋白的支架在真核生物中是丰富的,并且涉及广泛的生物过程,尤其是与核运输相关的那些过程。基于犰狳重复蛋白的支架通常由三至五个内部重复和两个封端元件组成。它们还具有串联伸长的超螺旋结构,其使得能够以延伸构象与其相应的肽配体结合。
阿去默是来源于称为四连蛋白的三聚血浆蛋白的支架,该四连蛋白属于由三个相同单元组成的C型凝集素家族。四连蛋白内的C型凝集素结构域(CTLD)的结构具有介导与靶向分子的相互作用的五个柔性环。
阿维默衍生自含有天然A结构域的蛋白质,诸如HER3,并且由通过氨基酸接头连接的许多不同的“A结构域”单体(2个-10个)组成。可使用例如美国专利申请公开号2004/0175756、2005/0053973、2005/0048512和2006/0008844中描述的方法产生可与靶抗原结合的阿维默。
非诺莫是从人Fyn酪氨酸激酶的Src同源结构域3(SH3)的氨基酸83-145进化而来的小的球状蛋白(大约7kDa)。非诺莫是有吸引力的结合分子,这是由于它们的高热稳定性、不含半胱氨酸的支架和人源,这降低了潜在的免疫原性。
打结素,也称为半胱氨酸结小蛋白,通常是长度为30个氨基酸的蛋白质,其包含三个反向平行的β-片层和由二硫键束缚的限制环,该二硫键产生半胱氨酸结。这种二硫键赋予高热稳定性,使得打结素成为有吸引力的抗体模拟物。
库尼兹结构域肽或库尼兹结构域抑制剂是一类具有不规则二级结构的蛋白酶抑制剂,该不规则二级结构含有具有三个二硫键和三个环的约60个氨基酸,其可在不使结构框架不稳定的情况下突变。
在一个实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分是包含衍生自T细胞受体(TCR)的抗原结合结构域的多肽或蛋白质。
在一个优选的实施方案中,对免疫细胞上表达的靶标具有结合特异性的结合部分是锚蛋白重复结构域。
对所述免疫细胞上表达的靶标的性质没有特别限制。在一个实施方案中,靶标在免疫细胞(T细胞)上表达,并且所述免疫细胞上表达的靶标是CD3。
因此,在一个优选的实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQ ID NO:12至30和58至59,以及(2)其中SEQ IDNO:12至30和58至59中的任一者中的至多9个、至多8个、至多7个、至多6个、至多5个、至多4个、至多3个、至多2个或至多1个氨基酸被另一氨基酸取代的序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对CD3,更优选地人CD3,具有结合特异性。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQ ID No:12至30和58至59,以及(2)其中SEQ ID No:12至30和58至59中的任一者中的至多9个、至多8个、至多7个、至多6个、至多5个、至多4个、至多3个、至多2个或至多1个氨基酸被另一氨基酸取代的序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含与SEQ ID No:34至38中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:SEQ ID No:12至30和58至59,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含与SEQ ID No:34至38中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:(1)SEQ ID No:12至30和58至59,以及(2)其中SEQ ID NO:12至30和58至59中的任一者中的至多9个、至多8个、至多7个、至多6个、至多5个、至多4个、至多3个、至多2个或至多1个氨基酸被另一氨基酸取代的序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含SEQ ID NO:34至38中的任一者的氨基酸序列。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含锚蛋白重复模块,该锚蛋白重复模块具有选自由以下项组成的组的氨基酸序列:SEQ ID NO:12至30和58至59,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含SEQ ID NO:34至38中的任一者的氨基酸序列。
在另一个优选的实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述第一锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对CD3,更优选地人CD3,具有结合特异性。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含与SEQ ID NO:34至38中的任一者具有至少约85%序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含SEQ ID NO:1至9和55至57中的任一者的氨基酸序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含与SEQ ID NO:34至38中的任一者具有至少约85%序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域具有对人CD123的结合特异性,并且其中所述第一锚蛋白重复结构域包含与SEQ ID NO:1至9和55至57中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含SEQ ID NO:34至38中的任一者的氨基酸序列。
在另一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,并且其中所述第一锚蛋白重复结构域包含SEQ ID NO:1至9和55至57中的任一者的氨基酸序列,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,并且其中所述第二锚蛋白重复结构域包含SEQ ID NO:34至38中的任一者的氨基酸序列。
本发明还涉及一种重组结合蛋白,所述重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,其中所述重组结合蛋白包含与SEQ ID NO:10、11和60至64中的任一者具有至少约85%氨基酸序列同一性,诸如至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或100%氨基酸序列同一性的氨基酸序列。
在一个实施方案中,本发明涉及一种重组结合蛋白,该重组结合蛋白包含(i)第一锚蛋白重复结构域,其中所述第一锚蛋白重复结构域对人CD123具有结合特异性,以及(ii)第二锚蛋白重复结构域,其中所述第二锚蛋白重复结构域对人CD3具有结合特异性,其中所述重组结合蛋白包含与SEQ ID NO:10、11和60至64中的任一者具有至少约85%氨基酸序列同一性的氨基酸序列。
半衰期延长部分
与不具有半衰期延长部分的相同蛋白质相比,“半衰期延长部分”延长了本文所述的重组结合蛋白的体内血清半衰期。半衰期延长部分的示例包括但不限于多组氨酸、Glu-Glu、谷胱甘肽S转移酶(GST)、硫氧还蛋白、蛋白质A、蛋白质G、免疫球蛋白结构域、麦芽糖结合蛋白质(MBP)、人血清白蛋白(HSA)结合结构域或聚乙二醇(PEG)。
在一些实施方案中,本文所述的重组结合蛋白包含特异性结合血清白蛋白(诸如优选地人血清白蛋白)的锚蛋白重复结构域,在本文也称为“血清白蛋白结合结构域”。本文所述的重组结合蛋白还可包含不止一个血清白蛋白结合结构域,例如两个或三个血清白蛋白结合结构域。因此,本文所述的重组结合蛋白可包含第一和第二血清白蛋白结合结构域,或第一、第二和第三血清白蛋白结合结构域。下文提供的实施方案描述了此类第一血清白蛋白结合结构域、第二血清白蛋白结合结构域和/或第三血清白蛋白结合结构域。
在一些实施方案中,本文所述的半衰期延长部分包含血清白蛋白特异性锚蛋白重复结构域,该锚蛋白重复结构域包含与SEQ ID NO:31至33中的任一者至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或约100%同一性的氨基酸序列。在一个示例性实施方案中,本文所述的半衰期延长部分包含与SEQ ID NO:31至33中的任一者具有至少约90%同一性的氨基酸序列。在一个实施方案中,本文所述的半衰期延长部分与SEQ ID NO:32具有至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%同一性的氨基酸序列。在一个示例性实施方案中,本文所述的半衰期延长部分包含与SEQ ID NO:32具有至少90%同一性的氨基酸序列。
在一些实施方案中,血清白蛋白结合结构域位于本发明的重组结合蛋白的N-末端。在一些实施方案中,优选两个或更多个血清白蛋白结合结构域。在一些实施方案中,两个血清白蛋白结合结构域位于本发明的重组结合蛋白的N-末端。
在一些实施方案中,半衰期延长部分包含免疫球蛋白结构域。在一些实施方案中,免疫球蛋白结构域包含Fc结构域。在一些实施方案中,Fc结构域来源于以下已知重链同种型中的任一者:IgG(γ)、IgM(μ)、IgD(δ)、IgE(ε)或IgA(α)。在一些实施方案中,Fc结构域来源于以下已知的重链同种型或亚型中的任一者:IgG
在一些实施方案中,Fc结构域包含Fc结构域的不间断天然序列(即野生型序列)。在一些实施方案中,免疫球蛋白Fc结构域包含导致改变的生物活性的变体Fc结构域。例如,可将至少一个点突变或缺失引入Fc结构域中以便降低或消除效应子活性(例如国际专利公布WO 2005/063815),以及/或者增加重组结合蛋白产生期间的同质性。在一些实施方案中,Fc结构域是人IgG
对肿瘤相关抗原具有结合特异性的其他结合部分
在另一个方面,本发明涉及如上所述的重组结合蛋白,还包含对不同于CD123的肿瘤相关抗原(TAA)具有结合特异性的至少一个结合部分。在一个实施方案中,所述不同于CD123的一个或多个TAA是与来自相同癌症的细胞中的CD123共表达的TAA。在另一个实施方案中,所述不同于CD123的一个或多个TAA是在以液体肿瘤为特征的癌症中与CD123共表达的TAA。在一个优选的实施方案中,所述不同于CD123的一个或多个TAA是在白血病中与CD123共表达的TAA,诸如在AML癌细胞中与CD123共表达的TAA。用于本发明的对不同于CD123的肿瘤相关抗原(TAA)具有结合特异性的结合部分的示例包括抗体、替代性支架和多肽。很多TAA是本领域已知的,包括在AML癌细胞中表达的TAA。
取代
在一些实施方案中,在相对于SEQ ID NO:12至30和58至59的序列的本发明的重组结合蛋白的任何锚蛋白重复模块中进行不超过9个、不超过8个、不超过7个、不超过6个、不超过5个、不超过4个、不超过3个、不超过2个或不超过1个取代。在一些实施方案中,相对于SEQ ID NO:12至30和58至59的序列进行不超过5个取代。在一些实施方案中,相对于SEQ IDNO:12至30和58至59的序列进行不超过4个取代。在一些实施方案中,相对于SEQ ID NO:12至30和58至59的序列进行不超过3个取代。在一些实施方案中,相对于SEQ ID NO:12至30和58至59的序列进行不超过2个取代。在一些实施方案中,相对于SEQ ID NO:12至30和58至59的序列进行不超过1个取代。
在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变本发明的重组结合蛋白的任何锚蛋白重复结构域的不超过15%、不超过14%、不超过13%、不超过12%、不超过11%、不超过10%、不超过9%、不超过8%、或不超过7%、不超过6%、不超过5%、不超过4%、不超过3%、不超过2%或不超过1%的氨基酸序列。在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变不超过10%的氨基酸序列。在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变不超过8%的氨基酸序列。在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变不超过6%的氨基酸序列。在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变不超过4%的氨基酸序列。在一些实施方案中,通过相对于SEQ ID NO:1至9和55至57的序列的取代来改变不超过2%的氨基酸序列。
在一些方面,与未取代的结合剂的K
在某些实施方案中,取代是根据表1的保守取代。在某些实施方案中,在锚蛋白重复结构域的结构核心残基之外进行取代,例如,在连接α-螺旋的β环中。
表1:氨基酸取代
在某些实施方案中,在锚蛋白重复结构域的结构核心残基内进行取代。在其他实施方案中,在锚蛋白重复结构域的结构核心残基外进行取代。例如,锚蛋白结构域可包含共有序列:xDxxGxTPLHLAxxxGxxxlVxVLLxxGADVNA(SEQ ID NO:40),其中“x”表示任何氨基酸(优选地不是半胱氨酸、甘氨酸或脯氨酸);或xDxxGxTPLHLAAxxGHLEIVEVLLKzGADVNA(SEQID NO:41),其中“x”表示任何氨基酸(优选地不是半胱氨酸、甘氨酸或脯氨酸),并且“z”是选自由天冬酰胺、组氨酸或酪氨酸组成的组。在一个实施方案中,对命名为“x”的残基进行取代。在另一个实施方案中,对未命名为“x”的残基进行取代。
另外,本发明的重组结合蛋白的任何锚蛋白重复结构域的倒数第二个位置可以是“A”或“L”,和/或最后一个位置可以是“A”或“N”。因此,在一些实施方案中,每个锚蛋白重复结构域包含与SEQ SEQ ID:1至9、31至38和55至57中的任一者具有至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%同一性的氨基酸序列,并且其中任选地倒数第二个位置处的A被L取代,和/或最后一个位置处的A被N取代,或者其中任选地倒数第二个位置处的L被A取代,和/或最后一个位置处的N被A取代。在一个示例性实施方案中,每个锚蛋白重复结构域包含与SEQID NO:1至9、31至37和55至57中的任一者具有至少90%同一性的氨基酸序列,并且其中任选地倒数第二个位置处的A被L取代,和/或最后一个位置处的A被N取代。此外,本发明的结合蛋白中包含的任何锚蛋白重复结构域的序列可任选地在其N-末端包含G、S或GS(参见下文)。
此外,本发明的重组结合蛋白中包含的每个锚蛋白重复结构域可任选地在其N-末端包含“G”、“S”或“GS”序列。因此,在一些实施方案中,每个锚蛋白重复结构域包含与SEQID NO:1至9、31至38和55至57中的任一者具有至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或100%同一性的氨基酸序列,并且在其N-末端还包含GS(如例如SEQ ID NO:42中所示)或者仅包含G或S而不是GS。
结合亲和力
在某些实施方案中,重组结合蛋白和其靶标(即,人CD123)之间的亲和力以K
在示例性实施方案中,重组结合蛋白以等于或小于以下的K
在一个方面,重组结合蛋白以小于以下的EC
其他多肽
在一个方面,本发明的重组结合蛋白还包含多肽标签。多肽标签为附接到多肽/蛋白质的氨基酸序列,其中所述氨基酸序列可用于纯化、检测或靶向所述多肽/蛋白质,或者其中所述氨基酸序列改善多肽/蛋白质的物理化学行为,或者其中所述氨基酸序列具有效应子功能。重组结合蛋白的各个多肽标签可直接或经由肽接头连接到重组结合蛋白的其他部分。多肽标签在本领域中是众所周知的,并且是本领域技术人员完全可用的。多肽标签的示例为小的多肽序列,例如His、HA、myc、FLAG或Strep标签;或多肽,诸如允许检测所述多肽/蛋白质的酶(例如,碱性磷酸酶)或可用于靶向的多肽(诸如,免疫球蛋白或其片段)和/或可用作效应分子的多肽。
在一个方面,本发明的重组结合蛋白还包含肽接头。肽接头为能够连接例如两个蛋白质结构域、多肽标签和蛋白质结构域、蛋白质结构域和非蛋白质类化合物或聚合物(诸如聚乙二醇)、蛋白质结构域和生物活性分子、蛋白质结构域和定位剂、或两个序列标签的氨基酸序列。肽接头是本领域技术人员已知的。示例的列表在专利申请WO2002/020565的说明书中提供。在一个方面,用于本发明的肽接头具有1个至50个氨基酸的长度。在另一个方面,用于本发明的肽接头具有约5个至约40个氨基酸的长度。在另一个方面,用于本发明的肽接头具有约10个至约30个氨基酸的长度。
肽接头的具体示例为具有可变长度的甘氨酸-丝氨酸接头和富含脯氨酸-苏氨酸的接头。在本发明的上下文中,富含脯氨酸-苏氨酸的接头在其氨基酸序列中包含至少约20%的脯氨酸残基和至少约20%的苏氨酸残基。甘氨酸-丝氨酸接头的示例为氨基酸序列GS和SEQ ID NO:45的氨基酸序列,并且富含脯氨酸-苏氨酸的接头的示例为SEQ ID NO:43和44的氨基酸序列。
N末端和C末端封盖序列
本文所公开的重组结合蛋白的锚蛋白重复结构域可包含N-末端或C-末端封端序列。封端序列是指融合到锚蛋白重复序列基序的N-末端或C-末端的附加多肽序列,其中所述封端序列与锚蛋白重复序列基序形成紧密的三级相互作用(即,三级结构相互作用),从而提供保护一侧的锚蛋白重复结构域的疏水核免于暴露于溶剂的盖。
N末端和/或C末端封盖序列可来源于存在于邻近重复单元的天然存在的重复蛋白质中的封盖单元或其他结构单元。封端序列的示例在国际专利公开号WO 2002/020565和WO2012/069655、美国专利公开号US 2013/0296221以及Interlandi等人,J Mol Biol.2008年1月18日;375(3):837-54。N-末端锚蛋白封端模块(即,N-末端封端重复)的示例包括SEQ IDNO:47至50,并且锚蛋白C-末端封端模块(即,C-末端封端重复)的示例包括SEQ ID NO:51至54。
核酸和方法
在另一个方面,本发明涉及编码本发明的重组结合蛋白的氨基酸序列的核酸。在一个方面,本发明涉及编码本发明的重组蛋白的氨基酸序列的核酸。此外,本发明涉及包含本发明的任何核酸的载体。核酸是本领域技术人员熟知的。在实施例中,使用核酸在大肠杆菌中产生本发明的经设计的锚蛋白重复结构域或重组结合蛋白。
组合物、用途和治疗方法
在一个方面,本发明涉及一种药物组合物,该药物组合物包含本发明的重组结合蛋白和/或经设计的锚蛋白重复结构域,和/或编码本发明的重组结合蛋白和/或经设计的锚蛋白重复结构域的核酸,以及任选地药学上可接受的载剂和/或稀释剂。
在一个方面,本发明涉及包含重组结合蛋白或编码本发明的重组结合蛋白的核酸以及任选地药学上可接受的载剂和/或稀释剂的药物组合物。
药学上可接受的载剂和/或稀释剂是本领域技术人员已知的,并且将在下文更详细地说明。
药物组合物包含本文所述的重组结合蛋白和/或经设计的锚蛋白重复结构域和/或核酸,优选地重组结合蛋白和/或核酸,以及药学上可接受的载剂、赋形剂或稳定剂,例如如Remington's Pharmaceutical Sciences,第16版,Osol,A.编辑,1980中所述。
本领域技术人员已知的合适载剂、稀释剂、赋形剂或稳定剂包括例如盐水、林格氏溶液、右旋糖溶液、汉克氏溶液、固定油,油酸乙酯、5%右旋糖盐水、增强等渗性和化学稳定性的物质、缓冲液和防腐剂。其他合适载剂包括本身不诱导产生对接受组合物的个体有害的抗体的任何载剂,诸如蛋白质、多糖、聚乳酸、聚乙醇酸、聚合氨基酸和氨基酸共聚物。药物组合物还可以是组合制剂,其包含另外的活性剂,诸如抗癌剂或抗血管生成剂,或另外的生物活性化合物。待用于体内给药的组合物必须是无菌的或经过消毒的。这很容易通过无菌过滤膜过滤实现。
在一个方面,药物组合物包含至少一种如本文所述的重组结合蛋白以及洗涤剂诸如非离子洗涤剂、缓冲液诸如磷酸盐缓冲液和糖诸如蔗糖。在一个方面,这样的组合物包含如上所述的重组蛋白以及PBS。
在另一个方面,本发明提供了一种在包括人在内的哺乳动物中肿瘤定位激活T细胞的方法,该方法包括向所述哺乳动物施用本发明的重组蛋白、本发明的核酸或本发明的药物组合物的步骤。
在另一方面,本发明提供了一种治疗医学病症的方法,该方法包括向有需要的患者施用治疗有效量的本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物的步骤。
在另一方面,本发明提供了一种治疗医学病症的方法,该方法包括向有需要的患者施用治疗有效量的本发明重组结合蛋白的步骤,该重组结合蛋白还包含对疾病相关抗原具有结合特异性的结合剂、编码所述重组结合蛋白的核酸或包含所述结合蛋白的药物组合物。
在一个方面,本发明涉及将根据本发明的药物组合物、重组结合蛋白或核酸用于治疗疾病。为此目的,向有需要的患者施用治疗有效量的根据本发明的药物组合物、核酸或重组结合蛋白。给药可包括局部给药、口服给药和肠胃外给药。典型的给药途径是肠胃外给药。在肠胃外给药中,本发明的药物组合物将与上述药学上可接受的赋形剂联合被配制成单位剂量可注射形式,诸如溶液、混悬液或乳液。给药的剂量和模式将取决于待治疗的个体和疾病。
另外,考虑将上文提到的药物组合物、核酸或重组蛋白中的任一种用于治疗病症。
在一个方面,静脉内施用所述重组蛋白或本文所述的其他此类药物组合物。对于肠胃外应用,重组结合蛋白或所述药物组合物可以治疗有效量快速推注或通过缓慢输注来注射。
在一个方面,本发明涉及本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物作为用于治疗疾病的药物的用途。在一个方面,本发明涉及本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物用于制造药物的用途。在一个方面,本发明涉及本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物用于制造用于治疗疾病的药物的用途。在一个方面,本发明涉及用于制造用于治疗疾病的药物的方法,其中本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物是该药物的活性成分。在一个方面,本发明涉及一种使用本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物治疗疾病的方法。
在一个方面,本发明还提供了这样的重组结合蛋白用于治疗有需要的受试者的医学病症的用途。
如本文所用,所述医学病症或疾病是癌症,优选地液体肿瘤,更优选地白血病,甚至更优选地急性髓性白血病(AML)。
本发明的重组结合蛋白、本发明的核酸或本发明的药物组合物还可与本领域已知的一种或多种其他疗法结合使用。如本文所用的术语“与……结合使用”应指在给定方案下进行的共同施用。这包括不同化合物的同步施用以及不同化合物的错时施用(例如,将化合物A给予一次,之后将化合物B给予多次,反之亦然,或者两种化合物同步给予并且其中一种化合物在后续阶段中也给予)。
在一个方面,本发明涉及一种包括本发明的重组结合蛋白的试剂盒。在一个方面,本发明涉及包含编码本发明的重组结合蛋白的核酸的试剂盒。在一个方面,本发明涉及包含本发明的药物组合物的试剂盒。在一个方面,本发明涉及试剂盒,该试剂盒包含本发明的重组蛋白、和/或本发明的核酸、和/或本发明的药物组合物。在一个方面,本发明涉及一种试剂盒,该试剂盒包括:重组蛋白,该重组蛋白包含本发明的对CD123具有结合特异性的锚蛋白重复结构域,例如SEQ ID NO:1至9和55至57;和/或核酸,该核酸编码包含具有对CD123具有结合特异性的锚蛋白重复结构域的重组蛋白,例如SEQ ID NO:1至9和55至57;和/或药物组合物,该药物组合物包含具有对CD123具有结合特异性的锚蛋白重复结构域的重组蛋白,例如SEQ ID NO:1至9和55至57。在一个方面,本发明涉及试剂盒,该试剂盒包含含有SEQID NO:1至30和55至64的氨基酸序列中的任一者的重组蛋白、和/或编码所述重组蛋白的核酸、和/或包含重组蛋白的药物组合物。
在一个方面,本发明涉及用于产生本发明的重组蛋白的方法。在一个方面,本发明提供了用于产生重组结合蛋白(例如,包含SEQ ID NO:1至30和55至64中的任一者的氨基酸序列的重组蛋白)的方法,该方法包括以下步骤:(i)在合适的宿主细胞(例如,细菌)中表达所述重组结合蛋白,以及(ii)(例如,使用色谱法)纯化所述重组结合蛋白。所述方法可包括附加步骤。此类产生本发明的重组结合蛋白的方法描述于实施例1中。
本发明不限于实施例中所描述的具体方面。本说明书涉及在所附序列表中公开的许多氨基酸序列、核酸序列和SEQ ID NO,该序列表全文以引用方式并入本文。
定义
除非本文另有定义,否则本文所用的所有技术和科学术语应具有本发明所属领域的普通技术人员通常理解的含义。此外,除非上下文另外要求,否则单数术语应包括复数,并且复数术语应包括单数。一般来讲,结合本文所述的细胞和组织培养、分子生物学、免疫学、微生物学、遗传学以及蛋白质和核酸化学使用的命名法以及其技术是本领域熟知的和常用的那些。
除非另外说明,否则术语“包含”、“具有”、“包括”和“含有”应被理解为开放式术语。如果本发明的各方面被描述为“包含”特征,则还设想到“由该特征组成”或“基本上由该特征组成”的方面。除非另外提出权利要求,否则本文所提供的任何和全部实例或示例性语言(例如“诸如”)仅仅旨在更好地举例说明本公开,并且并不用来限制本公开的范围。说明书中的任何语言都不应理解为表示任何不受权利要求书保护的要素是实施本公开所必需的。除了在操作示例中,或在另外指明的情况下,本文所用的表示成分或反应条件的量的所有数字在所有情况下均应理解为由相关领域的技术人员将理解的术语“约”修饰。除非另有说明,否则如本文所用的术语“约”等同于给定数值的±10%。
除非本文另外说明,否则本文对值的范围的表述仅旨在用作单独提及落入该范围内的每个单独值和每个端点的简略方法,并且每个单独值和端点并入本说明书中,如同其在本文中被单独地表述一样。
在本发明的上下文中,术语“蛋白质”是指包含多肽的分子,其中多肽的至少一部分通过在单个多肽链内和/或多个多肽链之间形成二级、三级和/或四级结构而具有或能够获得限定的三维排列。如果蛋白质包含两个或更多个多肽链,则单个多肽链可例如通过两个多肽之间的二硫键非共价连接或共价连接。通过形成二级和/或三级结构而单独具有或能够获得限定的三维排列的蛋白质部分被称为“蛋白质结构域”。这种蛋白质结构域是本领域技术人员熟知的。
在重组蛋白、重组多肽等中使用的术语“重组”是指所述蛋白质或多肽是通过使用本领域技术人员熟知的重组DNA技术产生的。例如,可将编码多肽的重组DNA分子(例如,通过基因合成产生)克隆到细菌表达质粒(例如,pQE30,QIAgen公司)、酵母表达质粒、哺乳动物表达质粒或植物表达质粒,或者能够体外表达的DNA中。如果例如将此类重组细菌表达质粒插入适当的细菌(例如,大肠杆菌(Escherichia coli))中,则这些细菌可产生由该重组DNA编码的多肽。对应产生的多肽或蛋白质被称为重组多肽或重组蛋白。
在本发明的上下文中,术语“结合蛋白”是指包含结合结构域的蛋白质。结合蛋白还可包含两个、三个、四个、五个或更多个结合结构域。优选地,所述结合蛋白是重组结合蛋白。本发明的结合蛋白包含对CD123具有结合特异性的锚蛋白重复结构域。
此外,任何此类结合蛋白可包含另外的多肽(例如,多肽标签、肽接头、融合至其他具有结合特异性的蛋白质结构域、细胞因子、激素或拮抗剂)、或本领域技术人员熟知的化学修饰(诸如偶联到聚乙二醇、毒素(例如,来自Immunogen的DM1)、小分子、抗生素等)。本发明的结合蛋白可包含定位剂分子。
术语“结合结构域”意指对靶标表现出结合特异性的蛋白质结构域。优选地,所述结合结构域是重组结合结构域。
如本文所用,术语“靶标”是指单个分子,诸如核酸分子、多肽或蛋白质、碳水化合物或任何其他天然存在的分子,包括此类单个分子的任何部分,或者两种或更多种此类分子的复合物,或整个细胞或组织样品,或任何非天然化合物。优选地,靶标是CD123。更优选地,靶标是人CD123。
在本发明的上下文中,术语“多肽”涉及由多个(即两个或更多个)经由肽键连接的氨基酸的链组成的分子。优选地,多肽由八个以上经由肽键连接的氨基酸组成。术语“多肽”还包括通过半胱氨酸的S-S桥连接在一起的氨基酸的多个链。多肽是本领域技术人员熟知的。
专利申请WO2002/020565和Forrer等人,2003(Forrer,P.,Stumpp,M.T.,Binz,H.K.,Plückthun,A.,2003.FEBS Letters 539,2-6)包含重复蛋白特征和重复结构域特征、技术和应用的一般描述。术语“重复蛋白”是指包含一个或多个重复结构域的蛋白质。优选地,重复蛋白包含一个、两个、三个、四个、五个或六个重复结构域。此外,所述重复蛋白可包含附加的非重复蛋白质结构域、多肽标签和/或肽接头。重复结构域可以是结合结构域。
术语“重复结构域”是指包含两个或更多个连续重复模块作为结构单元的蛋白质结构域,其中所述重复模块具有结构和序列同源性。优选地,重复结构域还包含N末端和/或C末端封端模块。为了清楚起见,封端模块可以是重复模块。这种重复结构域、重复模块和封端模块、序列基序以及结构同源性和序列同源性是本领域技术人员根据以下各项的示例所熟知的:锚蛋白重复结构域(WO2002/020565)、富含亮氨酸的重复结构域(WO2002/020565)、三十四肽重复结构域(Main,E.R.,Xiong,Y.,Cocco,M.J.,D'Andrea,L.,Regan,L.,Structure 11(5),497-508,2003)和犰狳重复结构域(WO2009/040338)。本领域技术人员还熟知,此类重复结构域不同于包含重复氨基酸序列的蛋白质,其中每个重复氨基酸序列能够形成单个结构域(例如纤连蛋白的FN3结构域)。
术语“锚蛋白重复结构域”是指包含两个或更多个连续的锚蛋白重复模块作为结构单元的重复结构域。可使用标准重组DNA技术(参见例如Forrer,P.等人,FEBS letters,第539卷,第2页-第6页,2003,WO2002/020565、WO2016/156596、WO2018/054971),将锚蛋白重复结构域模块化地组装成较大锚蛋白重复蛋白,任选地具有半衰期延长结构域。
如在经设计的重复蛋白、经设计的重复结构域等中所用,术语“经设计的”是指此类重复蛋白和重复结构域分别是人造的并且在自然界中不存在的性质。本发明的结合蛋白是经设计的重复蛋白,并且它们包含至少一个经设计的锚蛋白重复结构域。优选地,该经设计的重复结构域是经设计的锚蛋白重复结构域。
术语“靶标相互作用残基”是指有助于与靶标直接相互作用的重复模块的氨基酸残基。
术语“框架残基”是指重复模块的氨基酸残基,其有助于折叠拓扑结构,即有助于所述重复模块的折叠或有助于与相邻模块的相互作用。此类贡献可为与重复模块中其他残基的相互作用,或是对如α-螺旋或β-片层中存在的多肽主链构象的影响,或是参与形成直链多肽或环的氨基酸延伸。此类框架和靶标相互作用残基可通过分析由物理化学方法(诸如X射线晶体学、NMR和/或CD光谱)获得的结构数据,或通过与结构生物学和/或生物信息学领域从业者熟知的已知和相关结构信息进行比较来鉴定。
术语“重复模块”是指经设计的重复结构域的重复氨基酸序列和结构单元,其最初来源于天然存在的重复蛋白的重复单元。包含在重复结构域中的每个重复模块来源于天然存在的重复蛋白家族或亚家族(例如锚蛋白重复蛋白家族)的一个或多个重复单元。此外,重复结构域中包含的每个重复模块可包含从同源重复模块导出的“重复序列基序”,该同源重复模块从靶标上选择的重复结构域获得,例如如实施例1中所述,并且具有相同的靶标特异性。
因此,术语“锚蛋白重复模块”是指最初来源于天然存在的锚蛋白重复蛋白的重复单元的重复模块。锚蛋白重复蛋白是本领域技术人员熟知的。经设计的锚蛋白重复蛋白先前已有描述;参见,例如,国际专利公开号WO2002/020565、WO2010/060748、WO2011/135067、WO2012/069654、WO2012/069655、WO2014/001442、WO2014/191574、WO2014/083208、WO2016/156596和WO2018/054971,所有这些均全文以引用方式并入。通常,锚蛋白重复模块包含约31个至33个氨基酸残基,这些氨基酸残基形成由环隔开的两个α螺旋。
重复模块可包含具有为了选择靶标特异性重复结构域而在文库中未被随机化的氨基酸残基的位置(“非随机化位置”)和具有为了选择靶标特异性重复结构域而在文库中已被随机化的氨基酸残基的位置(“随机化位置”)。非随机化位置包含框架残基。随机化位置包含靶标相互作用残基。“已被随机化”意指在重复模块的氨基酸位置处允许两个或更多个氨基酸,例如,其中允许通常二十种天然存在的氨基酸中的任一种,或者其中允许二十种天然存在的氨基酸中的大多数,诸如除半胱氨酸之外的氨基酸,或除甘氨酸、半胱氨酸和脯氨酸之外的氨基酸。
术语“重复序列基序”是指从一个或多个重复模块导出的氨基酸序列。优选地,所述重复模块来自对相同靶标具有结合特异性的重复结构域。此类重复序列基序包含框架残基位置和靶标相互作用残基位置。所述框架残基位置对应于重复模块的框架残基位置。同样,所述靶标相互作用残基位置对应于重复模块的靶标相互作用残基的位置。重复序列基序包含非随机化位置和随机化位置。
术语“重复单元”是指包含一种或多种天然存在的蛋白质的序列基序的氨基酸序列,其中所述“重复单元”存在于多个拷贝中,并且表现出确定蛋白质折叠的所有所述基序共有的限定的折叠拓扑结构。此类重复单元的示例包括富含亮氨酸的重复单元、锚蛋白重复单元、犰狳重复单元、三十四肽重复单元、HEAT重复单元和富含亮氨酸的变体重复单元。
术语“对靶标具有结合特异性”、“特异性结合靶标”、“以高特异性结合靶标”、“特异于靶标”、“靶标特异性”或“特异性结合”等意指结合蛋白或结合结构域在PBS中以比其结合不相关的蛋白质(诸如大肠杆菌麦芽糖结合蛋白(MBP))更低的解离常数结合靶标(即,其以更高的亲和力结合)。优选地,靶标在PBS中的解离常数(“K
术语“结合剂”或“结合部分”是指能够特异性结合靶分子的任何分子。结合剂包括例如抗体、抗体片段、适体、肽(例如,Williams等人,JBiol Chem 266:5182-5190(1991))、替代性支架、抗体模拟物、重复蛋白(例如,经设计的锚蛋白重复蛋白)、受体蛋白和靶分子的任何其他天然存在的相互作用配偶体,并且可包括天然蛋白和经修饰或经遗传工程化(例如以包含非天然残基和/或以缺少天然残基)的蛋白。
术语“PBS”意指含有137mM NaCl、10mM磷酸盐和2.7mM KCl并且pH为7.4的磷酸盐缓冲水溶液。
优选地,在哺乳动物,更优选小鼠和/或食蟹猴,更优选食蟹猴中评估清除率和/或暴露率和/或终末半衰期。优选地,当在小鼠中测量清除率/或暴露率和/或终末半衰期时,考虑注射后至多48小时的数据来进行评估。更优选地,在小鼠中评估终末半衰期时,用从24小时至48小时的数据进行计算。优选地,当在食蟹猴中测量清除率和/或暴露率和/或终末半衰期时,考虑注射后至多第7天的数据进行评估。更优选地,在食蟹猴中评估终末半衰期时,用从第1天至第5天的数据进行计算。本领域的技术人员还能够识别诸如靶标介导的清除等效应,并且在计算终末半衰期时考虑它们。药物(诸如,本发明的重组结合蛋白)的术语“终末半衰期”是指达到伪平衡后药物血浆浓度达到施加于哺乳动物的该药物浓度的一半所需的时间(例如,在小鼠中用从24小时至48小时的数据进行计算,或者在食蟹猴中用从第1天至第5天的数据进行计算)。并未将终末半衰期定义为施用给哺乳动物的药物剂量消除一半所需的时间。术语“终末半衰期”是本领域技术人员熟知的。优选地,药代动力学比较以任何剂量,更优选地以当量剂量(即相同的mg/kg剂量)或等摩尔剂量(即相同的mol/kg剂量),更优选地以等摩尔剂量(即相同的mol/kg剂量)进行。本领域技术人员应当理解,动物中当量和/或等摩尔给药的实验剂量变化为至少约20%,更优选地约30%、约40%、约50%、约60%、约70%、约80%、约90%或约100%。优选地,用于药代动力学测量的剂量选自约0.001mg/kg至约1000mg/kg,更优选地约0.01mg/kg至约100mg/kg,更优选地约0.1mg/kg至约50mg/kg,更优选地约0.5mg/kg至约10mg/kg。
术语“CD3”或“分化簇3”是指由组装成三对(εγ、εδ、ζζ)的四个不同多肽链epsilon(ε)、gamma(γ)和zeta(ζ)组成的多聚体蛋白复合物。CD3复合物充当与T细胞受体非共价缔合的T细胞共受体。它可以指任何形式的CD3,以及其保留至少一部分CD3活性的变体、同种型和物种同源物。因此,如本文所定义和公开的结合蛋白也可结合来自除人以外的物种的CD3。在其他情况下,结合蛋白可完全特异于人CD3,并且可不表现出物种或其他类型的交叉反应性。除非另有说明,否则诸如通过具体参考人CD3,CD3包括天然序列CD3的所有哺乳动物种类,例如人、犬、猫、马和牛。人CD3γ、δ和ζ链的氨基酸序列分别示于NCBI(www.ncbi.nlm.nih.gov/)Ref.Seq.NP_000064.1、NP_000723.1和NP_932170.1中。
如本文所用,术语“表达CD3的细胞”是指在细胞表面上表达CD3(分化簇3)的任何细胞,包括但不限于T细胞诸如细胞毒性T细胞(CD8+T细胞)和T辅助细胞(CD4+T细胞)。
术语“CD123”是指白介素-3受体亚单位α。这是白介素-3的受体。人CD123(hCD123)的氨基酸序列示于UniProt(www.uniprot.org)参考号P26951中。
术语“T细胞的肿瘤定位激活”意指与非肿瘤组织相比,T细胞优先在肿瘤组织中被激活。
此外,术语“肽”还涵盖通过例如糖基化修饰的肽,以及包含两条或更多条各自长度为4个至600个氨基酸长、通过例如二硫键交联的多肽链的蛋白质,诸如例如胰岛素和免疫球蛋白。术语“化学或生物化学剂”旨在包括可施用于接受者的任何天然存在的或合成的化合物。在优选的方面,定位剂是靶标特异性锚蛋白重复结构域。
术语“医学病症”(或障碍或疾病)包括自身免疫性障碍、炎性障碍、视网膜病变(特别是增殖性视网膜病变)、神经退行性障碍、感染、代谢疾病和肿瘤疾病。本文所述的重组结合蛋白中的任一种可用于制备用于治疗这样的障碍(特别是诸如肿瘤疾病的障碍)的药物。“医学病症”可能是以不适当的细胞增殖为特征的病症。医学病症可能是过度增生病症。本发明具体涉及治疗医学病症的方法,该方法包括向需要这种治疗的患者施用治疗有效量的本发明的重组结合蛋白或所述药物组合物的步骤。在一个优选的方面,所述医学病症是肿瘤疾病。如本文所用,术语“肿瘤性疾病”是指以细胞生长或肿瘤快速增殖为特征的细胞或组织的异常状态或病症。在一个方面,所述医学病症是恶性肿瘤疾病。在一个方面,所述医学病症是癌症,优选地白血病,更优选地急性髓性白血病。术语“治疗有效量”是指足以对患者产生期望效应的量。
术语“抗体”不仅意指完整的抗体分子,而且意指保留免疫原结合能力的抗体分子的任何片段和变体。此类片段和变体也是本领域熟知的,并且经常在体外和体内使用。因此,术语“抗体”涵盖完整免疫球蛋白分子、抗体片段(诸如例如Fab、Fab'、F(ab')
术语“癌症”和“癌性”在本文中用来指或描述哺乳动物中通常以未受调控的细胞生长为特征的生理状况。癌症涵盖实体瘤和液体瘤,以及原发性肿瘤和转移。“肿瘤”包含一个或多个癌细胞。实体瘤通常还包含肿瘤基质。癌症的示例包括但不限于原发性和转移性癌、淋巴瘤、母细胞瘤、肉瘤和白血病,以及任何其他上皮和淋巴恶性肿瘤。此类癌症的更具体示例包括脑癌、膀胱癌、乳腺癌、卵巢癌、透明细胞肾癌、头/颈鳞状细胞癌、肺腺癌、肺鳞状细胞癌、恶性黑素瘤、非小细胞肺癌(NSCLC)、卵巢癌、胰腺癌、前列腺癌、肾细胞癌、小细胞肺癌(SCLC)、三阴性乳腺癌、急性成淋巴细胞性白血病(ALL)、急性髓性白血病(AML)、慢性淋巴细胞性白血病(CLL)、慢性髓性白血病(CML)、弥漫性大B细胞淋巴瘤(DLBCL)、滤泡性淋巴瘤、霍奇金淋巴瘤(HL)、套细胞淋巴瘤(MCL)、多发性骨髓瘤(MM)、骨髓增生异常综合征(MDS)、非霍奇金淋巴瘤(NHL)、头颈鳞状细胞癌(SCCHN)、慢性髓性白血病(CML)、小淋巴细胞淋巴瘤(SLL)、恶性间皮瘤、结直肠癌或胃癌。
实施例
下文公开的起始材料和试剂是本领域技术人员已知的,是可商购获得的和/或可使用熟知的技术制备。
材料
化学品购自Sigma-Aldrich(USA)。寡核苷酸来自Microsynth(Switzerland)。除非另有说明,否则DNA聚合酶、限制酶和缓冲液来自New England Biolabs(USA)或Fermentas/Thermo Fisher Scientific(USA)。诱导型大肠杆菌表达菌株用于克隆和蛋白质产生,例如大肠杆菌XL1-blue(Stratagene,USA)或BL21(Novagen,USA)。
分子生物学
除非另有说明,否则根据已知方案执行方法(参见例如Sambrook J.、FritschE.F.和Maniatis T.,Molecular Cloning:A Laboratory Manual,Cold Spring HarborLaboratory 1989,New York)。
经设计的锚蛋白重复蛋白文库
用于产生经设计的锚蛋白重复蛋白文库的方法已经描述于以下文献中:例如,美国专利号7,417,130;Binz等人,J.Mol.Biol.332,489–503,2003;Binz等人2004,同前。通过此类方法,可构建具有随机化锚蛋白重复模块和/或随机化封端模块的经设计的锚蛋白重复蛋白文库。例如,此类文库可以因此基于固定的N-末端封端模块(例如SEQ ID NO:47、48或49的N-末端封端模块)或随机化N-末端封端模块(例如根据SEQ ID NO:50)、以及固定的C-末端封端模块(例如SEQ ID NO:51、52或53的C-末端封端模块)或随机化C-末端封端模块(例如根据SEQ ID NO:54)进行组装。优选地,此类文库被组装成在重复或封端模块的随机化位置处不具有氨基酸C、G、M、N(在G残基前面)和P中的任一者。
此外,此类文库中的此类随机化模块可包含具有随机化氨基酸位置的附加的多肽环插入。此类多肽环插入的示例是抗体的互补决定区(CDR)环文库或从头生成的肽文库。例如,可以使用人核糖核酸酶L的N末端锚蛋白重复结构域的结构(Tanaka,N.,Nakanishi,M,Kusakabe,Y,Goto,Y.,Kitade,Y,Nakamura,K.T.,EMBO J.23(30),3929-3938,2004)作为指导来设计这种环插入。类似于其中将十个氨基酸插入在靠近两个锚蛋白重复的边界存在的β-转角中的这种锚蛋白重复结构域,锚蛋白重复蛋白文库可以含有插入锚蛋白重复结构域的一个或多个β-转角中的可变长度(例如,1个至20个氨基酸)的随机化环(具有固定位置和随机化位置)。锚蛋白重复蛋白文库的任何这种N-末端封端模块优选地具有RILLAA、RILLKA或RELLKA基序(例如,存在于SEQ ID NO:1中的位置19至24),并且锚蛋白重复蛋白文库的任何这种C-末端封端模块优选地具有KLN、KLA或KAA基序(例如,存在于SEQ ID NO:1中的最后三个氨基酸处)。SEQ ID NO:47至49提供了包含RILLAA、RILLKA或RELLKA基序的N-末端封端模块的示例,并且SEQ ID NO:51至53提供了包含KLN、KLA或KAA基序的C-末端封端模块的示例。
此类锚蛋白重复蛋白文库的设计可由与靶标相互作用的锚蛋白重复结构域的已知结构来指导。由其蛋白质数据库(PDB)唯一登录号或识别码(PDB-ID)识别的此类结构的示例为1WDY、3V31、3V30、3V2X、3V2O、3UXG、3TWQ-3TWX、1N11、1S70和2ZGD。
已经描述了经设计的锚蛋白重复蛋白文库(诸如N2C和N3C经设计的锚蛋白重复蛋白文库)的示例(美国专利号7,417,130;Binz等人,2003,同前;Binz等人,2004,同前)。N2C和N3C中的数字描述了存在于N末端和C末端封端模块之间的随机化重复模块的数量。
用于定义重复单元和模块内部的位置的命名法基于Binz等人,2004(同前),修改之处在于,锚蛋白重复模块和锚蛋白重复单元的边界移位一个氨基酸位置。例如,Binz等人2004(同前)的锚蛋白重复模块的位置1对应于本公开的锚蛋白重复模块的位置2,因而Binz等人2004(同前)的锚蛋白重复模块的位置33对应于本公开的以下锚蛋白重复模块的位置1。
实施例1:
使用核糖体展示(Hanes,J.和Plückthun,A.,PNAS 94,4937-42,1997),从与如Binz等人2004(同前)所述相似的
通过核糖体展示选择CD123特异性锚蛋白重复蛋白
使用人CD123的生物素化胞外结构域(SEQ ID NO:39)作为靶蛋白、如上所述的锚蛋白重复蛋白文库和已确立的方案(参见例如Zahnd,C.、Amstutz,P.和Plückthun,A.,Nat.Methods 4,69-79,2007)通过核糖体展示技术(Hanes和Plückthun,同前)进行hCD123特异性锚蛋白重复蛋白的选择。CD123靶标(Evitria)含有C末端Fc标签和Avi标签,并且使用酶BirA-GST生物素化。采用总共四轮的标准核糖体选择,使用降低靶标浓度和增加洗涤严格性来增加从第1轮到第4轮的选择压力(Binz等人,2004,同前)。通过使用链霉亲和素和中性抗生物素蛋白珠,在每一轮中应用去选择策略。每轮选择后,逆转录(RT)-PCR循环数不断从45减少至28,从而由于结合物的富集而调整收率。
为了富集高亲和力CD123特异性锚蛋白重复蛋白,使来自第四轮标准核糖体展示选择(上文)的输出经受选择严格性增加的解离率选择轮次(Zahnd,2007,同前)。在解离率选择轮次后进行最终的标准选择轮次,以扩增和回收解离率选择的结合蛋白。在第5轮和第6轮中,RT-PCR循环数分别为30和35。
另外,紧接着标准方法(如上文所述)进行两种另外的选择方法,以通过应用使用结合CD123的T细胞接合物(专利US9822181B2–7G3表位)的竞争性洗脱步骤或者通过在进行选择之前将hCD123特异性锚蛋白重复蛋白(具有与抗体7G3不同的表位)与CD123靶标一起共同温育来扩大潜在表位空间。从每种应用的方法中,产生针对CD123的结合物。
如粗提取物HTRF所示所选择的克隆特异性结合人CD123
使用标准方案,使用表达锚蛋白重复蛋白的大肠杆菌细胞的粗提取物,通过均相时间分辨荧光(HTRF)测定来鉴定溶液中特异性结合至hCD123的各个选择的锚蛋白重复蛋白。通过核糖体展示选择的锚蛋白重复蛋白克隆被克隆到pQE30(Qiagen)表达载体(pMPDV045)的衍生物(其含有C-末端CD3特异性锚蛋白重复结构域和随后的Flag标签)中,将该衍生物转化到大肠杆菌XL1-Blue(Stratagene)中,将该大肠杆菌铺板在LB-琼脂(含有1%葡萄糖和50μg/ml氨苄青霉素)上,然后在37℃温育过夜。将单个菌落挑取到含有160μl生长培养基(含有1%葡萄糖和50μg/ml氨苄青霉素的TB)的96孔板中(每个克隆在单个孔中),并以800rpm振荡在37℃处温育过夜。将含50μg/ml氨苄青霉素的150μl新鲜TB培养基与8.5μl过夜培养物一起接种于新鲜的96孔板中。在37℃和700rpm温育120分钟后,用IPTG(0.5mM最终浓度)诱导表达并持续4小时。收获细胞,并将沉淀物在-20℃冷冻过夜,然后重悬于8μl B-PERII(Thermo Scientific)中,并在室温振荡(900rpm)温育1小时。然后,添加160μl PBS,并通过离心(3220g持续15min)去除细胞碎片。
将每个裂解克隆的提取物作为PBSTB(补充有0.1% Tween
蛋白质#1(SEQ ID NO:1);
蛋白质#2(SEQ ID NO:2);
蛋白质#3(SEQ ID NO:3);
蛋白质#4(SEQ ID NO:4);
蛋白质#5(SEQ ID NO:5);
蛋白质#6(SEQ ID NO:6);
蛋白质#7(SEQ ID NO:7);
蛋白质#8(SEQ ID NO:8);以及
蛋白质#9(SEQ ID NO:9)。
这些
对hCD123具有结合特异性的另外的锚蛋白重复蛋白的工程化
SEQ ID NO:2基于SEQ ID NO:1的序列进行工程化。修饰序列以改变表面电荷。在N末端封端模块中,天冬氨酸(位置18)被亮氨酸替代,并且在C末端封端模块中,谷氨酸(位置18)被谷氨酰胺替代。
CD123特异性锚蛋白重复蛋白的表达
为了进一步分析,在大肠杆菌细胞中表达如上文所述的在粗细胞提取物HTRF中显示特异性人CD123结合的所选择的克隆,其中His标签(SEQ ID NO:66)融合至它们的N-末端,以便纯化。根据标准方案来纯化表达的蛋白质。使用0.11ml固定过夜培养物(TB,1%葡萄糖、50mg/l的氨苄青霉素;37℃)接种0.99ml培养物于96深孔板中(TB,50mg/l氨苄青霉素,37℃)。在37℃(700rpm)温育2小时之后,用0.5mM IPTG诱导培养物,并在37℃振荡(900rpm)温育6h。收获细胞,并将沉淀物在-20℃冷冻过夜,然后重悬于补充有DNA酶I(200单位/毫升)和Lysozyme(0.4mg/ml)的50μl B-PERII(Thermo Scientific)中,并在室温振荡(900rpm)温育一小时。然后,添加60μl低盐磷酸钠缓冲液,并通过离心(3220g持续15min)去除细胞碎片。在通过离心(3,200g,在4℃持续60min)去除细胞碎片之前,合并总共8个单独的表达。使用MultiScreen过滤板(Millipore)过滤上清液,然后使用96孔Thermo HisPur钴离心板纯化,并使用96孔Thermo Zeba离心脱盐板在PBS中重新缓冲蛋白质溶液。在Agilent 1200HPLC系统上使用标准Sephadex 150/5柱纯化的蛋白质在PBS中是可溶的和单体的。
生成具有hCD123结合特异性的亲和力成熟的CD123特异性结合蛋白
在最初鉴定的CD123特异性结合蛋白的进一步开发中,使用亲和力成熟产生对靶蛋白具有非常高的亲和力和/或从靶蛋白具有非常低的解离速率的变体。因此,选择一种最初鉴定的结合蛋白
然后将这种亲和力成熟的CD123特异性结合结构域亚克隆到pQE30(Qiagen)表达载体的衍生物中,产生编码N-末端His标签(SEQ ID NO:66)、随后是CD123特异性结合结构域(SEQ ID NO:56或57)和SEQ ID NO:36的C-末端CD3特异性结合结构域的表达构建体。在大肠杆菌细胞中表达T细胞接合物形式的这些构建体,并根据标准方案使用其His标签纯化。使用从健康供体PBMC中分离的原代T细胞作为效应细胞(E)以及Molm-13-N1肿瘤细胞作为靶细胞(T)(E:T比率为5:1),对蛋白质进行剂量依赖性体外T细胞激活和肿瘤细胞杀伤测定的测试。在大肠杆菌细胞中表达构建体,并根据标准方案使用其His标签纯化。
实施例2:
使用ProteOn仪器(BioRad)分析纯化的锚蛋白重复蛋白对重组人CD123靶标的结合亲和力,并且根据本领域技术人员已知的标准程序进行测量。
使用ProteOn XPR36仪器(BioRad)进行SPR测量。运行缓冲液是含有0.005%Tween
表2a示出了针对TCE形式(即,用CD3特异性锚蛋白重复结构域形式化)列出的
表2a
此外,使用如上述针对DARPin蛋白质#1、#3至#9的程序来测量和分析三个另外的纯化锚蛋白重复蛋白对重组人CD123靶标的结合亲和力。简言之,将中性抗生物素蛋白预涂在GLC芯片(BioRad)上达到6000RU的水平。在第二步中,将bio.hCD123固定至1030RU的水平。使用100nM、33nM、11nM、3.7nM和1.2nM的系列稀释度来测量DARPin蛋白质#12、DARPin蛋白质#13和DARPin蛋白质#14与bio.hCD123的结合。对于所有描述的测量,使用100μl/min的恒定流量进行120s的结合和1200s的解离。用两种不同的条件(10mM甘氨酸pH2.0和4MMgCl2)再生CD123靶标,每种条件应用30秒。信号针对间点和运行缓冲液(PBST-PBS pH7.4,含有0.005% Tween
表2b显示了结合至bio.hCD123全长靶标的本发明的CD123特异性锚蛋白重复蛋白的K
表2b
图1(A-B)显示了结合至人CD123的锚蛋白重复蛋白的表面等离子共振(SPR)分析:图1A
实施例3
为了确定本发明的CD7123特异性锚蛋白重复结构域是否可具有使其可用于开发治疗剂的适当体内血清半衰期,在小鼠中分析
体内施用和样品收集
对于每种锚蛋白重复融合蛋白,如上所述,将用人血清白蛋白特异性锚蛋白重复结构域(SEQ ID NO:32)格式化的
将小鼠分成具有相同数量动物的2组。从每只小鼠收集四个血清样品。在化合物施用后5分钟、4小时、24小时、48小时、76小时、96小时和168小时,从隐静脉收集用于药代动力学研究的血液样品。将血液保持在室温下以允许凝结,随后进行离心和血清收集。
通过ELISA进行生物分析以测量血清样品中的锚蛋白重复蛋白
将每孔一百微升的PBS中的10nM多克隆山羊抗兔IgG抗体(Ab18)在4℃处包被到NUNC Maxisorb ELISA板上过夜。在每孔用300μl PBST(补充有0.1% Tween20的PBS)洗涤五次后,在室温(RT)处将孔用300μl补充有0.25%酪蛋白的PBST(PBST-C)在HeidolphTitramax 1000摇动器(450rpm)上封闭1小时。板如上所述进行洗涤。添加100μl在PBST-C中的5nmol/L兔抗
将一百微升稀释的血清样品(在1:5稀释步骤中1:20-1:312500)或锚蛋白重复蛋白标准曲线样品(在1:3稀释步骤中0nmol/L和50nmol/L-0.0008nmol/L)在室温以450rpm施加振荡2h。板如上所述进行洗涤。
然后将孔与100μl鼠抗RGS-His-HRP IgG(Ab06,PBST-C中1:2000)一起温育,并在室温、450rpm温育1小时。板如上所述进行洗涤。将ELISA使用100μl/孔TMB底物溶液显色5分钟,并通过添加100μl 1mol/LH
药代动力学分析
使用作为Phoenix 64(Pharsight,North Carolina)一部分的WinNonlin程序7.0版,在Molecular Partners处进行药代动力学数据分析。基于经由静脉内推注给药的动物的平均浓度-时间数据的药代动力学参数的计算通过非房室分析(NCA模型200-202、IV推注、线性梯形线性插值)进行。计算药代动力学参数,诸如以下药代动力学参数:
AUCinf、AUClast、AUC_%extrapol、Cmax、Tmax、Cl_pred、Vss_pred、t1/2
最大血清浓度(Cmax)及其发生时间(Tmax)直接从血清浓度-时间曲线获得。血清浓度-时间曲线下面积(AUCinf)通过线性梯形公式直到最后取样点(Tlast)并外推至无穷大(假设终末期单指数下降)来确定。使用Clast/λz进行直至无穷大的外推,其中λz表示通过对数线性回归估计的终点速率常数,并且Clast表示借助于终点对数-线性回归在Tlast处估计的浓度。总血清清除率(Cl_pred)和表观终末半衰期如下计算:Cl_pred=i.v.剂量/AUCinf,并且t1/2=ln2/λz。稳态分布体积Vss由下式确定:Vss=静脉注射剂量·AUMCinf/(AUCinf)2。AUMCinf表示使用与AUCinf计算中所述相同的外推程序外推至无穷大的药物浓度-时间曲线一阶矩下的总面积。为了计算基于以nmol/L给出的浓度的PK参数,通过使用锚蛋白重复蛋白的分子量,将以mg/kg给出的剂量值转换为nmol/kg。表3显示了四种锚蛋白重复蛋白(
表3:两种示例性HSAxCD123特异性锚蛋白重复蛋白的半衰期(t1/2)
总之,本发明的CD123特异性锚蛋白重复结构域可以与半衰期延长部分(例如,血清白蛋白特异性结合结构域)组合,以实现适当的体内血清半衰期,从而使它们可用于治疗剂的开发。
实施例4:
通过荧光激活细胞分选(FACS)流式细胞术来分析本发明的结合蛋白与肿瘤细胞表面上表达的CD123的结合。为此,将表达CD123的肿瘤细胞(Molm-13 N1)以100’000个细胞/孔接种在96孔板中。单特异性形式的DARPin蛋白质#2、DARPin蛋白质#3、DARPin蛋白质#9、DARPin蛋白质#12、DARPin蛋白质#13和DARPin蛋白质#14从2000nM开始以1:5稀释比进行滴定。用稀释的DARPin蛋白质重悬肿瘤细胞,并在4℃温育60分钟。在包含2%胎牛血清、不含人血清白蛋白(HSA)的PBS中进行测定。在用磷酸盐缓冲盐水(PBS)洗涤两次之后,通过以2ug/ml添加未标记的初级抗兔
表4
实施例5:
通过CD8+T细胞上作为激活标记的CD25激活标记的FACS测量在体外短期T细胞激活测定中评估实施例4的前述示例性CD123特异性锚蛋白重复蛋白的特异性和效力。评估双特异性T细胞接合物形式的测试蛋白质、DARPin蛋白质#2、DARPin蛋白质#9、、DARPin蛋白质#12、DARPin蛋白质#13和DARPin蛋白质#14。此类T细胞接合物蛋白质除了上述CD123特异性锚蛋白重复结构域之外,还包含CD3特异性结合结构域(SEQ ID NO:36),并且它们分别显示为DARPin蛋白质#18、DARPin蛋白质#19、、DARPin蛋白质#15、DARPin蛋白质#16和DARPin蛋白质#17。
所以,用所选择的DARPin蛋白的系列稀释液在600μM人血清白蛋白的存在下一式两份地将每孔100,000个纯化的pan-T效应细胞和20,000个Molm-13靶细胞在37℃共温育(E:T比率5:1)48小时。48小时后,洗涤细胞,并将其用1:1,000Live/Dead Green(ThermoFisher)、1:400小鼠抗人CD8 Pacific Blue(BD)和1:100小鼠抗人CD25 PerCP-Cy5.5(eBiosciences)抗体在4℃染色30min。洗涤和固定后,在Attune NxT(ThermoFisher)机器上分析细胞。通过测量Live/Dead阴性和CD8+门控T细胞上的CD25+细胞来评估T细胞激活。使用FlowJo软件分析FACS数据,并使用GraphPad Prism 8对数据作图(3-PL-fit)。图3显示了由DARPin蛋白质#18、DARPin蛋白质#19、DARPin蛋白质#15、、DARPin蛋白质#16和DARPin蛋白质#17触发的短期T细胞激活,如通过激活标记CD25所测量。T细胞接合物形式的所有本发明的测试CD123特异性结合蛋白均能够结合至肿瘤细胞上表达的CD123并激活T细胞。
实施例6:
T细胞接合物形式的本发明的CD123特异性锚蛋白重复蛋白(DARPin蛋白质#2、DARPin蛋白质#9、DARPin蛋白质#12、DARPin蛋白质#13和DARPin蛋白质#14)(即分别DARPin蛋白质#18、DARPin蛋白质#19、DARPin蛋白质#15、DARPin蛋白质#16和DARPin蛋白质#17)的特异性和效力还通过LDH释放的体外短期细胞毒性测定来评估。因此,用所选择的锚蛋白的系列稀释液在600μM人血清白蛋白的存在下一式两份地将每孔100,000个纯化的pan-T效应细胞和20,000个Molm-13靶细胞在37℃共温育(E:T比率5:1)48小时。温育48小时后,将细胞离心,根据制造商方案分析每孔100μl上清液的LDH释放(LDH检测试剂盒;Roche AppliedScience,温育30分钟)。通过TECAN infinite M1000Pro读数器测量492nm-620nm处的吸光度。使用GraphPad Prism 8来绘制OD值。
图4显示了由DARPin蛋白质#18、DARPin蛋白质#19、DARPin蛋白质#15、DARPin蛋白质#16和DARPin蛋白质#17触发的肿瘤细胞杀伤。
T细胞接合物形式的所有本发明的测试CD123特异性结合蛋白均能够结合至肿瘤细胞上表达的CD123并激活T细胞,T细胞进而杀伤肿瘤细胞。
实施例7:
使用截短的CD123靶蛋白以及针对基准对照分子伏妥珠单抗类似物(CD3-CD123特异性
首先,将全长(NTD/D2/D3结构域)和截短的(D2/D3结构域)CD123靶标(购自Evitria)应用于HTRF结合测定,其中将它们与
如图5所示,与全长(图5A)和截短的CD123(图5B)的强结合信号已在
接下来,通过竞争ELISA评估CD123特异性结合蛋白
将人CD123靶标与50倍摩尔过量的伏妥珠单抗类似物和15倍摩尔过量的IL-3一起预温育后,不能竞争与
实施例8:
蛋白#13的示例性多结构域TCE结合蛋白的体内功效评估
在具有肿瘤细胞系MOLM-13的外周血单核细胞(PBMC)人源化小鼠模型中测试
在癌细胞的异种移植前两天给小鼠腹膜内注射hPBMC(5x10
-将
通过卡尺测量来评估肿瘤大小。使用下式计算肿瘤体积:肿瘤体积(mm
如图7(A-B)中可见,在整个实验时间内(图7A)和第一次注射后17天(图7B),多结构域TCE形式的
按照本说明书内引用的参考文献的教导内容最彻底地理解本说明书。本说明书内的各方面提供了对本发明的各方面的说明,并且不应理解为限制本发明的范围。技术人员容易认识到,本发明涵盖许多其他方面。本公开中引用的所有出版物、专利和GenBank序列均全文以引用方式并入。在以引用方式并入的材料与本说明书矛盾或不一致的程度上,本说明书将取代任何此类材料。对本文任何参考文献的引用不是承认此类参考文献是本发明的现有技术。
本领域的技术人员将认识到或能够仅使用常规实验来确定本文描述的本发明的特定方面的许多等同物。此类等同物旨在由以下权利要求涵盖。
/>
/>
/>
/>
/>
/>
序列表
<110> MOLECULAR PARTNERS AG
<120> 基于DARPin的新型CD123接合物
<130> P034
<160> 66
<170> BiSSAP 1.3.6
<210> 1
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质1
<400> 1
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu Gln Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 2
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质2
<400> 2
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu Gln Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 3
<211> 157
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质3
<400> 3
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Tyr Gly Arg Thr Pro Leu His Leu Ala Ala Ile Lys Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Leu Gly Tyr Thr Pro Leu His Leu Ala Ala Val Glu Gly Pro
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Lys Asp Ala Tyr Gly Gln Thr Pro Leu His Ile Ala Ala Ala Trp Gly
100 105 110
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Val Ala Asp Val Asn
115 120 125
Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Arg Ala
130 135 140
Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
145 150 155
<210> 4
<211> 157
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质4
<400> 4
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Glu Tyr Gly Ala Thr Pro Leu His Leu Ala Ala Tyr Ser Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Glu Trp Gly Arg Thr Pro Leu His Val Ala Ala Leu Ser Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Lys Asp His Gln Gly Arg Thr Pro Leu His Leu Ala Ala Leu Trp Gly
100 105 110
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Val Ala Asp Val Asn
115 120 125
Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Arg Ala
130 135 140
Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
145 150 155
<210> 5
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质5
<400> 5
Asp Leu Gly Lys Lys Leu Leu Lys Ala Ala Leu Leu Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Arg Phe Gly Tyr Thr Pro Leu His Leu Ala Ala Trp Thr Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ala Tyr Gly Trp Thr Pro Leu His Ile Ala Ala His Ser Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Glu Gly Glu Thr Pro Ala Asp Leu Ala Ala Ala Gln Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 6
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质6
<400> 6
Asp Leu Gly Glu Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Asp Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ala Ala Gly Gln Thr Pro Ala Asp Leu Ala Ala Ala Leu Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 7
<211> 157
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质7
<400> 7
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Glu Tyr Gly Leu Thr Pro Leu His Leu Ala Ala Glu Phe Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ala Asn Gly His Thr Pro Leu His Leu Ala Ala Ala Tyr Asp His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Lys Asp Thr Ser Gly Lys Thr Pro Leu His Leu Ala Ala Gln Tyr Gly
100 105 110
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
115 120 125
Ala Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Arg Ala
130 135 140
Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
145 150 155
<210> 8
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质8
<400> 8
Asp Leu Gly Lys Lys Leu Leu Asn Ala Ala His Ile Gly Gln Asp Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Ile Val Gly Lys Thr Pro Leu His Ile Ala Ala Trp Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Asp His Gly Trp Thr Pro Leu His Ile Ala Ala His Val Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Asn Ala Gly Asn Thr Pro Ala Asp Leu Val Ala Phe Gln Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 9
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质9
<400> 9
Asp Leu Gly Trp Lys Leu Leu Asp Ala Ala Glu Ile Gly Gln Asp Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Lys Gln Gly Ile Thr Pro Leu His Ile Ala Ala Ala His Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Glu Ile Gly Arg Thr Pro Leu His Leu Ala Ala Phe Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Glu Thr Pro Ala Asp Leu Ala Ala Val Arg Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 10
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质10
<400> 10
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu Gln Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asp Asp Lys Gly Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Gln Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 11
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质11
<400> 11
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu Gln Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asp Asp Lys Gly Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Gln Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 12
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 12
Lys Asp Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 13
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 13
Lys Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 14
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 14
Lys Asp Gln Tyr Gly Arg Thr Pro Leu His Leu Ala Ala Ile Lys Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 15
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 15
Lys Asp Ser Leu Gly Tyr Thr Pro Leu His Leu Ala Ala Val Glu Gly
1 5 1015
Pro Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 16
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 16
Lys Asp Ala Tyr Gly Gln Thr Pro Leu His Ile Ala Ala Ala Trp Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Val Ala Asp Val Asn
202530
Ala
<210> 17
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 17
Lys Asp Glu Tyr Gly Ala Thr Pro Leu His Leu Ala Ala Tyr Ser Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 18
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 18
Lys Asp Glu Trp Gly Arg Thr Pro Leu His Val Ala Ala Leu Ser Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 19
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 19
Lys Asp His Gln Gly Arg Thr Pro Leu His Leu Ala Ala Leu Trp Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Val Ala Asp Val Asn
202530
Ala
<210> 20
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 20
Lys Asp Arg Phe Gly Tyr Thr Pro Leu His Leu Ala Ala Trp Thr Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 21
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 21
Lys Asp Ala Tyr Gly Trp Thr Pro Leu His Ile Ala Ala His Ser Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 22
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 22
Lys Asp Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 23
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 23
Lys Asp Ser Ile Asp Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 24
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 24
Lys Asp Glu Tyr Gly Leu Thr Pro Leu His Leu Ala Ala Glu Phe Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 25
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 25
Lys Asp Ala Asn Gly His Thr Pro Leu His Leu Ala Ala Ala Tyr Asp
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 26
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 26
Lys Asp Thr Ser Gly Lys Thr Pro Leu His Leu Ala Ala Gln Tyr Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 27
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 27
Lys Asp Ile Val Gly Lys Thr Pro Leu His Ile Ala Ala Trp Leu Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 28
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 28
Lys Asp Asp His Gly Trp Thr Pro Leu His Ile Ala Ala His Val Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 29
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 29
Lys Asp Lys Gln Gly Ile Thr Pro Leu His Ile Ala Ala Ala His Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 30
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 30
Lys Asp Glu Ile Gly Arg Thr Pro Leu His Leu Ala Ala Phe Lys Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 31
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对人血清白蛋白具有特异性的锚蛋白重复结构域
<400> 31
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly His Leu
354045
Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asn Glu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp Ala Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 32
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对人血清白蛋白具有特异性的锚蛋白重复结构域
<400> 32
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly His Leu
354045
Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Ala Asp Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp Ala Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 33
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对人血清白蛋白具有特异性的锚蛋白重复结构域
<400> 33
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Tyr Phe Ser His Thr Pro Leu His Leu Ala Ala Arg Asn Gly His Leu
354045
Lys Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Phe Ala Gly Lys Thr Pro Leu His Leu Ala Ala Asp Ala Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp Ala Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 34
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对CD3具有特异性的锚蛋白重复结构域
<400> 34
Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Ser Gln Gly Trp Thr Pro Leu His Thr Ala Ala Gln Thr Gly His Leu
354045
Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Asp Lys Gly Val Thr Pro Leu His Leu Ala Ala Ala Leu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala Ala Lys Tyr Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 35
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对CD3具有特异性的锚蛋白重复结构域
<400> 35
Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asn
202530
Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln Thr Gly His Leu
354045
Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Asp Lys Gly Val Thr Pro Leu His Leu Ala Ala Ala Leu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala Ala Lys Tyr Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 36
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对CD3具有特异性的锚蛋白重复结构域
<400> 36
Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asn
202530
Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln Thr Gly His Leu
354045
Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala Ala Leu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala Ala Lys Tyr Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 37
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对CD3具有特异性的锚蛋白重复结构域
<400> 37
Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asn
202530
Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln Thr Gly His Leu
354045
Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Thr Asn Lys Arg Val Thr Pro Leu His Leu Ala Ala Ala Leu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Arg Asp Thr Trp Gly Thr Thr Pro Ala Asp Leu Ala Ala Lys Tyr Gly
100 105 110
His Arg Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 38
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> 对CD3具有特异性的锚蛋白重复结构域
<400> 38
Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala Lys Asn
202530
Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln Thr Gly His Leu
354045
Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala Ala Leu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala Ala Lys Tyr Gly
100 105 110
His Gly Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
115 120
<210> 39
<211> 285
<212> PRT
<213> 人工序列
<220>
<223> CD123靶蛋白(ECD)
<400> 39
Thr Lys Glu Asp Pro Asn Pro Pro Ile Thr Asn Leu Arg Met Lys Ala
1 5 1015
Lys Ala Gln Gln Leu Thr Trp Asp Leu Asn Arg Asn Val Thr Asp Ile
202530
Glu Cys Val Lys Asp Ala Asp Tyr Ser Met Pro Ala Val Asn Asn Ser
354045
Tyr Cys Gln Phe Gly Ala Ile Ser Leu Cys Glu Val Thr Asn Tyr Thr
505560
Val Arg Val Ala Asn Pro Pro Phe Ser Thr Trp Ile Leu Phe Pro Glu
65707580
Asn Ser Gly Lys Pro Trp Ala Gly Ala Glu Asn Leu Thr Cys Trp Ile
859095
His Asp Val Asp Phe Leu Ser Cys Ser Trp Ala Val Gly Pro Gly Ala
100 105 110
Pro Ala Asp Val Gln Tyr Asp Leu Tyr Leu Asn Val Ala Asn Arg Arg
115 120 125
Gln Gln Tyr Glu Cys Leu His Tyr Lys Thr Asp Ala Gln Gly Thr Arg
130 135 140
Ile Gly Cys Arg Phe Asp Asp Ile Ser Arg Leu Ser Ser Gly Ser Gln
145 150 155 160
Ser Ser His Ile Leu Val Arg Gly Arg Ser Ala Ala Phe Gly Ile Pro
165 170 175
Cys Thr Asp Lys Phe Val Val Phe Ser Gln Ile Glu Ile Leu Thr Pro
180 185 190
Pro Asn Met Thr Ala Lys Cys Asn Lys Thr His Ser Phe Met His Trp
195 200 205
Lys Met Arg Ser His Phe Asn Arg Lys Phe Arg Tyr Glu Leu Gln Ile
210 215 220
Gln Lys Arg Met Gln Pro Val Ile Thr Glu Gln Val Arg Asp Arg Thr
225 230 235 240
Ser Phe Gln Leu Leu Asn Pro Gly Thr Tyr Thr Val Gln Ile Arg Ala
245 250 255
Arg Glu Arg Val Tyr Glu Phe Leu Ser Ala Trp Ser Thr Pro Gln Arg
260 265 270
Phe Glu Cys Asp Gln Glu Glu Gly Ala Asn Thr Arg Ala
275 280 285
<210> 40
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<220>
<221> 变体
<222> 1、3、4、6、13、14、15、17、18、19、22、26、27
<223> 其中Xaa表示任何氨基酸(优选地不是半胱氨酸、
甘氨酸或脯氨酸)
<400> 40
Xaa Asp Xaa Xaa Gly Xaa Thr Pro Leu His Leu Ala Xaa Xaa Xaa Gly
1 5 1015
Xaa Xaa Xaa Leu Val Xaa Val Leu Leu Xaa Xaa Gly Ala Asp Val Asn
202530
Ala
<210> 41
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<220>
<221> 变体
<222> 1、3、4、6、14、15
<223> 其中位置1、3、4、6、14、15中的Xaa表示任何氨基酸(优选地不是半胱氨酸、甘氨酸或脯氨酸),并且位置27中的Xaa选自由天冬酰胺、
组氨酸或酪氨酸组成的组。
<400> 41
Xaa Asp Xaa Xaa Gly Xaa Thr Pro Leu His Leu Ala Ala Xaa Xaa Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Xaa Gly Ala Asp Val Asn
202530
Ala
<210> 42
<211> 126
<212> PRT
<213> 人工序列
<220>
<223> 对CD123具有特异性的锚蛋白重复结构域
<400> 42
Gly Ser Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln
1 5 1015
Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
202530
Lys Asp Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly
354045
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
505560
Ala Lys Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys
65707580
Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val
859095
Asn Ala Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu
100 105 110
Gln Gly His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120 125
<210> 43
<211> 24
<212> PRT
<213> 人工序列
<220>
<223> 富含PT的肽接头
<400> 43
Gly Ser Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr
1 5 1015
Pro Thr Pro Thr Pro Thr Gly Ser
20
<210> 44
<211> 22
<212> PRT
<213> 人工序列
<220>
<223> 富含PT的肽接头
<400> 44
Gly Ser Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr
1 5 1015
Pro Thr Pro Thr Pro Thr
20
<210> 45
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 共有GS接头
<220>
<221> 变体
<222> 1..5
<223> [Gly-Gly-Gly-Gly-Ser]n,其中n为1、2、3、4、5或6
<400> 45
Gly Gly Gly Gly Ser
1 5
<210> 46
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> His-标签
<400> 46
Met Arg Gly Ser His His His His His His
1 5 10
<210> 47
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> N-封端
<400> 47
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
202530
<210> 48
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> N-封端
<400> 48
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
202530
<210> 49
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> N-封端
<400> 49
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Arg Ala Gly Gln Leu Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
202530
<210> 50
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> N-封端(随机化)
<220>
<221> 变体
<222> 4、8、11、12
<223> 其中Xaa表示任何氨基酸(优选地不是半胱氨酸、
甘氨酸或脯氨酸)
<400> 50
Asp Leu Gly Xaa Lys Leu Leu Xaa Ala Ala Xaa Xaa Gly Gln Asp Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala
202530
<210> 51
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> C-封端
<400> 51
Gln Asp Lys Phe Gly Lys Thr Pro Ala Asp Ile Ala Ala Asp Asn Gly
1 5 1015
His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
2025
<210> 52
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> C-封端
<400> 52
Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Arg Ala Gly
1 5 1015
His Gln Asp Ile Ala Glu Val Leu Gln Lys Leu Ala
2025
<210> 53
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> C-封端
<400> 53
Gln Asp Ser Ser Gly Phe Thr Pro Ala Asp Leu Ala Ala Leu Val Gly
1 5 1015
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
2025
<210> 54
<211> 28
<212> PRT
<213> 人工序列
<220>
<223> C-封端(随机化)
<220>
<221> 变体
<222> 3、4、6、14、15
<223> 其中Xaa表示任何氨基酸(优选地不是半胱氨酸、
甘氨酸或脯氨酸)
<400> 54
Gln Asp Xaa Xaa Gly Xaa Thr Pro Ala Asp Leu Ala Ala Xaa Xaa Gly
1 5 1015
His Glu Asp Ile Ala Glu Val Leu Gln Lys Leu Asn
2025
<210> 55
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质12
<400> 55
Asp Leu Gly Trp Lys Leu Leu Asp Ala Ala Glu Ile Gly Gln Leu Asp
1 5 1015
Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Lys Gln Gly Ile Thr Pro Leu His Ile Ala Ala Ala His Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Glu Ile Gly Arg Thr Pro Leu His Leu Ala Ala Phe Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Glu Thr Pro Ala Asp Leu Ala Ala Val Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 56
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质13
<400> 56
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Gln Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Gln Thr Pro Ala Asp Leu Ala Ala Gln Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 57
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质14
<400> 57
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Ile Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Gln Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Gln Thr Pro Ala Asp Leu Ala Ala Gln Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 58
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 58
Lys Asp Gln Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 59
<211> 33
<212> PRT
<213> 人工序列
<220>
<223> 锚蛋白重复模块
<400> 59
Lys Asp Ile Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly
1 5 1015
His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn
202530
Ala
<210> 60
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质15
<400> 60
Asp Leu Gly Trp Lys Leu Leu Asp Ala Ala Glu Ile Gly Gln Leu Asp
1 5 1015
Glu Val Arg Ile Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Lys Gln Gly Ile Thr Pro Leu His Ile Ala Ala Ala His Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Glu Ile Gly Arg Thr Pro Leu His Leu Ala Ala Phe Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Glu Thr Pro Ala Asp Leu Ala Ala Val Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 61
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质16
<400> 61
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Gln Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Gln Thr Pro Ala Asp Leu Ala Ala Gln Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 62
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质17
<400> 62
Asp Leu Gly Lys Lys Leu Leu Gln Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Ile Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Gln Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Gln Thr Pro Ala Asp Leu Ala Ala Gln Arg Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 63
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质18
<400> 63
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Leu Glu Gly Gln Leu Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Gln Glu Gly Tyr Thr Pro Leu His Leu Ala Ala Ala Leu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Ser Ile Gly Arg Thr Pro Leu His Leu Ala Ala Tyr Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Leu Leu Gly Glu Thr Pro Ala Asp Leu Ala Ala Glu Gln Gly
100 105 110
His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 64
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质19
<400> 64
Asp Leu Gly Trp Lys Leu Leu Asp Ala Ala Glu Ile Gly Gln Asp Asp
1 5 1015
Glu Val Arg Ile Leu Leu Ala Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Lys Gln Gly Ile Thr Pro Leu His Ile Ala Ala Ala His Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Glu Ile Gly Arg Thr Pro Leu His Leu Ala Ala Phe Lys Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Ile Ile Gly Glu Thr Pro Ala Asp Leu Ala Ala Val Arg Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala Gly Ser Pro Thr
115 120 125
Pro Thr Pro Thr Thr Pro Thr Pro Thr Pro Thr Thr Pro Thr Pro Thr
130 135 140
Pro Thr Gly Ser Asp Leu Gly Gln Lys Leu Leu Glu Ala Ala Trp Ala
145 150 155 160
Gly Gln Asp Asp Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val
165 170 175
Asn Ala Lys Asn Ser Arg Gly Trp Thr Pro Leu His Thr Ala Ala Gln
180 185 190
Thr Gly His Leu Glu Ile Phe Glu Val Leu Leu Lys Ala Gly Ala Asp
195 200 205
Val Asn Ala Lys Asn Asp Lys Arg Val Thr Pro Leu His Leu Ala Ala
210 215 220
Ala Leu Gly His Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala
225 230 235 240
Asp Val Asn Ala Arg Asp Ser Trp Gly Thr Thr Pro Ala Asp Leu Ala
245 250 255
Ala Lys Tyr Gly His Gln Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
260 265 270
<210> 65
<211> 124
<212> PRT
<213> 人工序列
<220>
<223> DARPin蛋白质20
<400> 65
Asp Leu Gly Lys Lys Leu Leu Glu Ala Ala Arg Ala Gly Gln Asp Asp
1 5 1015
Glu Val Arg Glu Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys Asp
202530
Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu Gly His Leu
354045
Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala Lys
505560
Asp Lys Asp Gly Tyr Thr Pro Leu His Leu Ala Ala Arg Glu Gly His
65707580
Leu Glu Ile Val Glu Val Leu Leu Lys Ala Gly Ala Asp Val Asn Ala
859095
Gln Asp Lys Ser Gly Lys Thr Pro Ala Asp Leu Ala Ala Asp Ala Gly
100 105 110
His Glu Asp Ile Ala Glu Val Leu Gln Lys Ala Ala
115 120
<210> 66
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> His-标签
<400> 66
Met Arg Gly Ser His His His His His His Gly Ser
1 5 10
- 基于烷氧基硅烷的单件组合物和使用该组合物接合或包封组件的方法
- 基于烷氧基硅烷的单件组合物和使用该组合物接合或包封组件的方法