COStream中用于实现前馈神经网络的sequential结构及其编译方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明属于计算机编译技术领域,更具体地,涉及COStream中用于实现前馈神经网络的sequential结构及其编译方法。
背景技术
COStream是一种数据流编程语言和编译器,在C++语法基础上扩展了数据流相关语法Operator、Composite、Stream等。其中,Operator是用于定义初始化、执行代码和数据流流速的基本计算节点,Composite是能够声明并调用Operator或直接调用其他Composite的compositeNode,Stream是用于计算节点通信的数据流。COStream还提供Pipeline、Splitjoin结构简化构造过程,其中Pipeline顺序连接结构内的计算节点,利用阶段差实现流水线并行;Splitjoin将数据复制或切片分发给结构内的计算节点,并将数据合并,能实现数据并行。这种基于数据流编程模型的语言,由编译器根据底层的多核架构为计算分配资源,并生成高效的可执行代码,将提升编程人员开发并行程序的效率。
前馈神经网络是深度学习领域内一种常见的模型。目前深度学习框架中有一些框架本身是通用的数学表达式库,虽然能减少模型的执行时间和开发时间,但编写和调试代码的学习曲线相对陡峭。迭代训练模型的过程,实际上是大规模数据流经程序中的一系列数学变换的过程,把这些数学变换抽象成独立的计算,形成恒定的数据流图,符合数据流模型特点。因此基于数据流编程模型开发前馈神经网络这类计算密集型应用,能将充分利用多核架构中的计算资源,提升训练速度。但现有COStream文法难以快速构建深度学习模型。
发明内容
针对现有技术的缺陷和改进需求,本发明提供了COStream中用于实现前馈神经网络的sequential结构及其编译方法,其目的在于实现支持COStream快速构建前馈神经网络的文法,使其在与现有文法风格一致的基础上,符合数据流编程语法的语义;在新增文法基础上,对其编译方法进行研究,实现将描述深度学习架构的语句映射到其在训练阶段的数据流图、实现生成前馈神经网络层在正向、反向传播对应的计算节点。以此增加COStream对深度学习的支持、减少代码量、提高用户友好性。
为实现上述目的,按照本发明的第一方面,提供了一种COStream中用于实现前馈神经网络的sequential结构,所述sequential结构由sequential的头部和sequential的主体组成;
所述sequential的头部包括两个部分:第一部分是训练前馈神经网络模型时的输入流列表,列表中依次是由用于训练整个前馈神经网络模型的训练数据集和训练标签集构成的数据流;第二部分是配置前馈神经网络模型训练过程的参数列表,依次对应输入数据的大小、学习率、批量数、损失函数、参数初始化方式;
所述sequential的主体内是操作语句,采用add关键字按前馈神经网络内神经网络层的顺序添加不同类型的神经网络层到sequential结构,从而确定顺序模型内神经网络层的类型、配置参数以及它们线性堆叠的顺序。
为实现上述目的,按照本发明的第二方面,提供了一种COStream中用于实现前馈神经网络的sequential结构的编译方法,该方法包括:
词法分析阶段:解析输入的字符串,将其拆分成词法元素,并传递给语法分析阶段,其中,sequential表示sequential结构,层词法元素包括:Dense表示全连接层,Conv2D表示二维卷积层,MaxPooling2D表示二维最大池化层,AveragePooling2D表示二维平均池化层,Activation表示激活层,Dropout表示Dropout层;
语法分析和语法树生成阶段:根据巴科斯范式规则对拆分后的词法元素归约,在每次归约后产生相应的语法树节点,并通过链表将该节点插入到抽象语法树中;其中,layerNode节点是各类神经网络层的基类,由arg_list属性保存层的配置参数,由prevLayer、nextLayer属性分别保存指向前、后层layerNode的指针;sequentialNode节点保存sequential结构的输入、输出流,输入数据的尺寸,模型的训练过程配置参数,layerNode列表以及经过编译该sequential结构转化出的composite,同时提供访问模型配置参数的方式;
sequential结构展开阶段:从Main Composite遍历整棵语法树,当遍历到类型为sequential的节点时,构建一个新的compositeNode,该compositeNode的主体内是模型的训练过程;
静态数据流图生成阶段:将语法树转化为静态数据流图。
优选地,所述根据巴科斯范式规则对拆分后的词法元素归约,在每次归约后产生相应的语法树节点,具体为:层词法单元后接由小括号包裹的参数列表被规约并产生一个layerNode,继续与add词法单元规约并产生一个addNode,中括号内的所有add语句经规约产生一个addNode列表,即sequential结构的主体,最后sequential词法单元、两个由小括号包裹的参数列表、sequential结构主体经规约产生一个sequentialNode。
优选地,sequentialNode构建compositeNode,具体包括:
(1)在将语法生成树转化到数据流图的过程中,遍历到sequentialNode时,遍历sequentialNode中的layerNode列表,通过双向链表建立层上下文,并根据层上下文依次解析每一层,并包含参数的层中的权值矩阵声明为全局数组;
(2)生成用于复制数据流的计算节点copy,将传入整个sequential结构的训练数据集,复制后分发给第一层在正向、反向传播中对应的计算节点;
(3)顺序遍历layerNode列表,根据layerNode中存储的层信息和层上下文,生成层在正向传播中对应的计算节点;若该层为第一层,则其输入流为经copy计算节点复制生成的由训练数据集构成的数据流,否则为上一层在正向传播中对应的计算节点的输出流;由编译器根据层上下文,确定在反向传播中,是否有计算节点依赖于当前计算结果,有则生成copy计算节点,将输出流复制成两份;
(4)根据sequential第二个参数列表中设置的损失函数类型以及层上下文,生成loss计算节点,其两个输入流分别是最后一层在正向传播对应的计算节点的输出流与由传入sequential结构的训练标签集构成数据流;
(5)逆序遍历layerNode列表,根据layerNode中存储的信息和层上下文,生成层在反向传播中对应的计算节点;根据链式求导法则,在计算损失函数关于该层输入的梯度时,依赖于该层数学变换关于输入的Jacobian矩阵与反向传递到该层的梯度;根据上述数据依赖关系,用数据流连接计算节点;
(6)根据sequential结构暴露出的数据依赖关系,编译器声明数据流并用它们连接生成的正向、反向传播对应的计算节点、copy计算节点、loss计算节点,将上述计算节点的调用作为新构建的compositeNode的主体,并用该compositeNode替换语法生成树节点中的sequentialNode。
优选地,生成前馈神经网络层在正向、反向传播对应计算节点过程中,
对于全连接层,在正向传播计算节点中,根据同一层内各神经元之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成小的、与层内神经元数量一致的计算节点,实现数据并行;在反向传播计算节点中,由编译器生成能将反向传入的梯度数据流复制成份数与上一层神经元数量一致的split的duplicate计算节点,和将正向传入的输入数据流切片分成份数与上一层神经元数量一致的split的roundrobin计算节点,再由编译器将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
优选地,生成前馈神经网络层在正向、反向传播对应计算节点过程中,
对于卷积层,在正向传播计算节点中,根据同一层内各卷积核所在的卷积运算之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成与层内卷积核数量一致的,且以卷积核索引为参数的计算节点,实现数据并行;在反向传播计算节点中,由编译器分别生成能将反向传入的梯度数据流和正向传入的输入数据流复制成份数与卷积核通道数数量一致的split的duplicate计算节点,再由编译器将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
优选地,生成前馈神经网络层在正向、反向传播对应计算节点过程中,
对于池化层,在正向传播计算节点中,根据同一层内各通道输入数据上的池化运算之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成与该层输入数据通道数数量一致的子计算节点,实现数据并行;在反向传播计算节点中,生成能将反向传入的梯度数据流和正向传入的输入数据流切片分成份数与通道数数量一致的split的roundrobin计算节点,再将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
优选地,生成前馈神经网络层在正向、反向传播对应计算节点过程中,
对于激活层,其正向传播计算节点中包含两条数据流,其一为输入数据经过激活函数映射后的值,其二是根据激活函数类型,由数学推导总结出的能简化该层在反向传播对应计算节点中梯度计算过程的数据,如输出或输出关于输入的导数。
优选地,生成前馈神经网络层在正向、反向传播对应计算节点过程中,对于Dropout层,由于无法仅根据Dropout层的输入或输出值计算出其Jacobian矩阵,因此正向传播计算节点中在按指定概率丢失输入数据的同时计算输出关于输入的导数,故Dropout层包含有两个输出流。
优选地,组内同步组间异步更新参数实现方法:
(1)采用小批量随机梯度算法训练模型,并设置一个大于COStream编译器划分后阶段数的小批量值;
(2)设置两组参数,在包含参数的层对应的计算节点中,设置标志位和迭代次数变量,在每次迭代完毕后,更新迭代次数,当迭代次数与批量数一致时,重置迭代次数并交替标志位,使得在下一次迭代时,计算节点根据标志位访问另一组参数。
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
(1)本发明结合COStream中已经存在的pipeline结构文法与主流深度学习框架的API设计,设计了基于顺序模型描述深度学习架构、配置学习过程、设置训练数据集以及训练标签集的sequential结构的文法。sequential结构的文法设计,使得用户不再需要基于COStream中基本的数据流图构建语言,逐步构造前馈神经网络的正向传播、反向传播过程中计算节点,有效地避免大量的代码。
(2)本发明在sequential结构文法的基础上,实现了由sequentialNode转换成实际compositeNode;分析前馈神经网络层中存在的并行性,实现了生成数据流图中神经网络层对应的具备数据并行的计算节点;生成前馈神经网络层在正向、反向传播对应计算节点的实现,由于生成计算节点时,充分挖掘了神经网络层中存在的数据并行性,并以合适的粒度将计算划分成多个子计算,避免数据流图中出现单个计算节点的工作量过大,使得COStream编译器对数据流图任务划分及资源分配后,能得到负载均衡的结果。
(3)本发明分析深度学习模型训练程序在流水线并行过程中存在的读写冲突,实现了组内同步组间异步更新参数。组内同步组间异步更新参数的实现,使得前馈神经网络训练程序可以利用数据流编程模型中自然存在的软件流水线并行,提高资源利用率、提升训练速度,而不必担心程序中以全局变量保存的模型参数,可能在并行执行时出现读写冲突的问题。
附图说明
图1为本发明实施例提供的COStream新增词法单元;
图2为本发明实施例提供的COStream新增语法生成树节点的UML图;
图3为本发明实施例提供的COStream新增巴科斯范式规则;
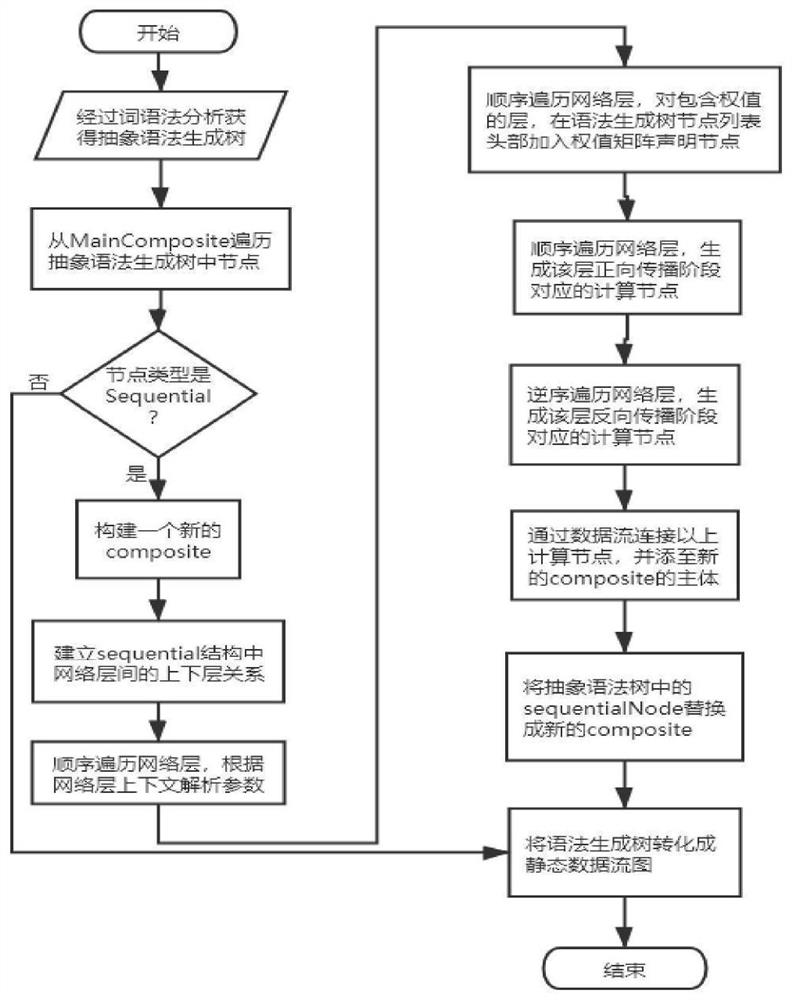
图4本发明实施例提供的COStream sequential结构编译方法流程图;
图5为本发明实施例提供的COStream sequential结构示例及其数据流图,其中,(a)为sequential结构,(b)为sequential结构对应的数据流图;
图6为本发明实施例提供的权值矩阵读写冲突问题说明及组内同步组间异步参数更新实际执行过程,其中,(a)为软件流水并行执行过程,(b)为软件流水并行执行过程权值矩阵存在的读写冲突,(c)为组间同步组间异步参数更新方法的执行过程;
图7为本发明实施例提供的生成的全连接层、卷积层、池化层计算节点示意图,其中,(a)表示全连接层正向传播计算节点,(b)表示全连接层反向传播计算节点,(c)表示卷积层正向传播计算节点,(d)表示卷积层反向传播计算节点,(e)表示池化层正向传播计算节点,(f)表示池化层反向传播计算节点;
图8为本发明实施例提供的激活层数据流优化前后示意图,其中,(a)为优化前数据流图,(b)为优化后数据流图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
COStream编译器包括编译前端、后端两个部分。编译器前端读取COStream源程序,在对其词法、语法分析、语义检查、常量传播优化后得到语法生成树,然后将其转化成静态数据流图。COStream中面向深度学习新增的sequential结构文法,同样遵循上述步骤。
词法分析阶段,由词法分析器Flex解析输入的字符串,将其拆分成词法元素,并返回给语法分析器Bison。如图1所示,新增词法单元包括:sequential表示sequential结构,Dense表示全连接层,Conv2D表示二维卷积层,MaxPooling2D表示二维最大池化层,AveragePooling2D表示二维平均池化层,Activation表示激活层,Dropout表示Dropout层。
语法分析阶段,由语法分析器Bison根据巴科斯范式规则对文法归约,在每次归约后产生相应的语法树节点,并通过链表将该节点插入到抽象语法树中。如图2所示,新增语法树节点类型layerNode和sequentialNode,均继承自基类Node。layerNode是各类层节点的基类,由arg_list属性保存层的配置参数,由prevLayer、nextLayer属性分别保存指向前、后层layerNode的指针。sequentialNode保存sequential结构的输入、输出流,输入数据的尺寸,模型的训练过程配置参数,layerNode列表以及经过编译该sequential结构转化出的composite,同时提供访问模型配置参数的方式。
根据COStream文法规则,结构的调用最终将归约为非终结符exp。为exp新增如图3所示的sequential后缀表达式文法。其中argument.expression.list是已定义的非终结符,表示一组由“,”分割的表达式,用于归约数据流列表或参数列表。新增的非终结符有operator.layer、operator.sequential.add、sequential.statement.list。每归约出operator.layer会创建并返回一个layerNode实例,每归约出sequential.statement.list会创建一个主体语句列表,并将operator.sequential.add中归约得到的addNode加入列表,sequential结构声明语句会被归约成exp,同时创建一个sequentialNode实例,将已归约得到的主体语句列表、输入数据流列表、参数列表赋给该实例,最终返回该sequentialNode实例。
图4展示了编译包含sequential结构的COStream源程序的流程图,经词、语法分析获得语法生成树后,编译器从语法生成树中Main Composite对应的compositeNode开始遍历,当遍历到语法树中的sequentialNode,构建一个新的compositeNode。通过双向链表链接sequentialNode中的layerNode,建立层上下文。根据层上下文和对层的参数解析,完成每一层的初始化。对于全连接层、卷积层这类包含参数的层,以全局多维数组类型声明权值矩阵变量,并将声明节点加入语法生成树入口的列表中。顺序地遍历layerNode列表,生成其在正向传播中对应的计算节点。逆序地遍历layerNode列表,生成其在反向传播中对应的计算节点。这些生成的计算节点,将由编译器根据sequential结构对应的数据流图将其用数据流连接起来。因此创建的compositeNode的主体语句是上述数据流的声明语句和按照sequential结构按照正向、反向传播过程对上述计算节点的调用语句。语法生成树中的sequentialNode会被替换成展开后得到的compositeNode,最后利用COStream程序中已有的AST2FlatStaticStreamGraph方法将整个抽象语法树转换成静态数据流图。
sequentialNode转换到实际compositeNode的具体方法为:
(1)在将语法生成树转化到数据流图的过程中,遍历到sequentialNode时,遍历sequentialNode中的layerNode列表,通过双向链表建立层上下文,并根据层上下文依次解析每一层,并包含参数的层中的权值矩阵声明为全局数组。
(2)生成用于复制数据流的计算节点copy,将传入整个sequential结构的训练数据集,复制后分发给第一层在正向、反向传播中对应的计算节点。
(3)顺序遍历layerNode列表,根据layerNode中存储的层信息和层上下文,生成层在正向传播中对应的计算节点。若该层为第一层,则其输入流为经copy计算节点复制生成的由训练数据集构成的数据流,否则为上一层在正向传播中对应的计算节点的输出流。由编译器根据层上下文,确定在反向传播中,是否有计算节点依赖于当前计算结果,有则生成copy计算节点,将输出流复制成两份。
(4)根据sequential第二个参数列表中设置的损失函数类型以及层上下文,生成loss计算节点,其两个输入流分别是最后一层在正向传播对应的计算节点的输出流与由传入sequential结构的训练标签集构成数据流。
(5)逆序遍历layerNode列表,根据layerNode中存储的信息和层上下文,生成层在反向传播中对应的计算节点。根据链式求导法则,在计算损失函数关于该层输入的梯度时,依赖于该层数学变换关于输入的Jacobian矩阵与反向传递到该层的梯度。根据上述数据依赖关系,用数据流连接计算节点。
(6)根据sequential结构暴露出的数据依赖关系,编译器声明数据流并用它们连接生成的正向、反向传播对应的计算节点、copy计算节点、loss计算节点,将上述计算节点的调用作为新构建的compositeNode的主体,并用该compositeNode替换语法生成树节点中的sequentialNode。
生成前馈神经网络层在正向、反向传播对应计算节点的具体方法为:
(1)对于全连接层,在正向传播计算节点中,根据同一层内各神经元之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成小的、与层内神经元数量一致的计算节点,实现数据并行;在反向传播计算节点中,由编译器生成能将反向传入的梯度数据流复制成份数与上一层神经元数量一致的split(duplicate)计算节点,和将正向传入的输入数据流切片分成份数与上一层神经元数量一致的split(roundrobin)计算节点,再由编译器将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
(2)对于卷积层,在正向传播计算节点中,根据同一层内各卷积核所在的卷积运算之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成与层内卷积核数量一致的,且以卷积核索引为参数的计算节点,实现数据并行;在反向传播计算节点中,由编译器分别生成能将反向传入的梯度数据流和正向传入的输入数据流复制成份数与卷积核通道数数量一致的split(duplicate)计算节点,再由编译器将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
(3)对于池化层,在正向传播计算节点中,根据同一层内各通道输入数据上的池化运算之间不存在数据依赖关系,利用COStream中的splitjoin结构,将计算拆分成与该层输入数据通道数数量一致的子计算节点,实现数据并行;在反向传播计算节点中,由编译器分别生成能将反向传入的梯度数据流和正向传入的输入数据流切片分成份数与通道数数量一致的split(roundrobin)计算节点,再由编译器将新生成的数据流两两分配给子计算节点,最后由编译器生成join计算节点将子计算的输出流合并。
(4)对于激活层,其正向传播计算节点中包含两条数据流,其一为输入数据经过激活函数映射后的值,其二是根据激活函数类型,由数学推导总结出的能简化该层在反向传播对应计算节点中梯度计算过程的数据,如输出或输出关于输入的导数。
(5)对于Dropout层,由于无法仅根据Dropout层的输入或输出值计算出其Jacobian矩阵,因此正向传播计算节点中在按指定概率丢失输入数据的同时计算输出关于输入的导数,故Dropout层包含有两个输出流。
组内同步组间异步更新参数实现方法:
(1)采用小批量随机梯度算法训练模型,并设置一个大于COStream编译器划分后阶段数的小批量值。
(2)设置两组参数,在包含参数的层对应的计算节点中,设置标志位和迭代次数变量,在每次迭代完毕后,更新迭代次数,当迭代次数与批量数一致时,重置迭代次数并交替标志位,使得在下一次迭代时,计算节点根据标志位访问另一组参数。
图5中(a)展示了一个使用sequential结构构造一个具有两层神经网络层的架构的示例程序,图中的省略号表示省略的模型训练参数以及层的配置参数,该程序经过编译将得到如图5中(b)所示的数据流图。其中data和label分别表示由训练数据集与训练标签集构成的传入整个模型的输入流。data数据流经过CopyComp,复制生成两条相同的数据流,分别流入Layerl在正向传播中对应的计算节点LayerFComp1和在反向传播中对应的计算节点LayerBComp1。LayerFComp1内部Layer1计算结果同样经过CopyComp被复制生成两条相同的数据流,分别流入Layer2在正向传播中对应的计算节点LayerFComp2和在反向传播中对应的计算节点LayerBComp2。LayerFComp2的计算结果即为模型对单条训练数据的预测值,其构成的数据流将直接流入根据损失函数生成的LossComp,除预测值数据流,LossComp的输入流还包括label。经计算LossComp输出损失函数关于预测值的梯度,该数据流流入LayerBComp2。经计算LayerBComp2输出损失函数关于Layer2在正向传播中的输入值的梯度,该数据流流入LayerBComp1。经计算LayerBComp1输出损失函数关于Layer1在正向传播中的输入值的梯度。
为便于说明软件流水线并行执行过程,假设COStream编译器将图5中(b)中的计算节点按照从正向传播到反向传播的计算顺序,依次划分到独立的A~E阶段,阶段间的数据依赖关系如下:A阶段不依赖其他阶段,B阶段依赖于A阶段,C阶段依赖于B阶段,D阶段依赖于C阶段,E阶段依赖于B阶段和D阶段,F阶段依赖于A阶段和E阶段。
图6中(a)展示了软件流水执行过程,某一阶段得到计算所需的所有数据才执行运算,如此通过阶段差消除同一流水周期中不同阶段在并行执行时的耦合。因此在1~5流水周期中存在等待状态的阶段,这是流水线的填充过程,在第6~10流水周期所有的阶段都会被执行,这是流水线的稳态执行过程,在第11~15流水周期所有阶段逐步执行完毕,这是流水线的排空过程。
图6中(b)展示了软件流水执行过程中权值矩阵变量上的读写冲突。B、C阶段中包含全连接层正向计算节点,其纹理代表访问的权值矩阵版本,E、F阶段中包含全连接层反向计算节点,其纹理代表更新后的权值矩阵版本。由于权值矩阵以全局变量的形式保存在程序中,在第5个流水周期,C阶段访问第二层全连接层的权值矩阵和E阶段更新第二层全连接层的权值矩阵在不同线程上并行运行,造成C阶段访问到初始的和第一次更新后的,两种版本的权值矩阵,得到错误的正向传播结果,造成本次训练迭代整体错误。在图6中(b)中,只有方框圈出的第1、2次训练迭代,在正向传播中不存在访问多个版本的权值矩阵的问题。
图6中(c)展示了组内同步组间异步更新参数的过程,设置训练模型的批量数是7,在第8、9流水周期,阶段B、C分别完成第一次批量迭代,因此在第9,10流水周期,阶段B、C分别开始访问另一组参数。在第11流水周期,阶段E更新第二层的权值矩阵时,其在正向传播过程对应的阶段C已经开始迭代训练另一组权值矩阵,不会出现权值参数版本不一致的问题。同理在第12流水周期,阶段F更新第一层的权值矩阵时,其在正向传播过程对应的阶段B也已经开始迭代训练另一组权值矩阵,不会出现权值参数版本不一致的问题。
图7中(a)展示了全连接层在正向传播中对应的计算节点,该全连接层中包含n个神经元,则计算节点内,由splitjoin结构将输入流复制分配给n个以神经元为单位的计算节点。图7中(b)展示了全连接层在反向传播中对应的计算节点,该全连接层上一层中包含m个神经元,则计算节点内,由编译器生成special_spit(roundrobin)和special_spit(duplicate),分别用于对正向输入流切片和对反向输入复制,并分发给m个以神经元为单位的计算节点。
图7中(c)展示了卷积层在正向传播中对应的计算节点,该卷积层中包含3个卷积核,则计算节点内,由splitjoin结构将输入流复制分配给3个卷积核上卷积运算的计算节点。图7中(d)展示了卷积层在反向传播中对应的计算节点,该卷积层中卷积核的通道数为3。在计算节点内,反向输入流流入负责对其膨胀和扩展的计算节点,由编译器生成两个special_spit(duplicate),分别用于对正向输入流和经膨胀和扩展的反向输入复制,并分发给3个单通道上卷积运算的计算节点。
图7中(e)展示了池化层在正向传播中对应的计算节点,该池化层中输入数据的通道数是3,则计算节点内,由splitjoin结构将输入流切片分配给3个以单通道上池化计算为单位的计算节点。图7中(f)展示了池化层在反向传播中对应的计算节点,该池化层中输入数据的通道数是3,则计算节点内,由编译器生成两个special_spit(roundrobin),分别用于对正向输入流和反向输入切片,并分发给3个单通道上池化运算的计算节点。
通过sequential结构构造前馈神经网络,其架构中依次是全连接层、激活层、全连接层和激活层。若直接通过激活层在正向时的输入值计算其Jacobian矩阵,则其数据流图如图8中(a)所示。假设激活函数为
因此,图8中(b)所示的数据流图中,由激活层在正向传播对应的计算节点输出偏导结果或激活层非线性映射后的结果到其在反向传播对应的计算节点,将减少梯度计算的难度或者避免不必要的计算。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- COStream中用于实现前馈神经网络的sequential结构及其编译方法
- COStream中用于实现前馈神经网络的sequential结构及其编译方法