用于治疗某些自身免疫病症的CD6靶向性嵌合抗原受体
文献发布时间:2023-06-19 10:32:14
发明背景
1型糖尿病(T1D)因胰腺β细胞的自身免疫攻击,从而导致功能性β细胞团的丧失引起。功能性β细胞团受到增加β细胞数量和大小的过程的正面影响,而受到消减细胞数量的过程(即凋亡、坏死和其他细胞死亡方式)的负面影响。另外,β细胞分泌功能和能力是功能性β细胞团的重要决定因素。
在T1D患者中,成人和人类胰岛的增殖和再生潜力较低。因此,重要的是防止或延迟自身免疫攻击和由此导致的对β细胞的破坏,并建立促进β细胞团扩充,增加β细胞存活和/或增强现有/剩余β细胞功能的方法,包括参与细胞修复机制以恢复功能性β细胞团。然而,旨在同时靶向胰岛浸润淋巴细胞以及保护和补充功能性β细胞团的治疗策略是有限的。本文提供了本领域中针对这些和其他问题的解决方案。
发明概述
本文描述了靶向CD6的嵌合抗原受体(CAR)。CD6 CAR在调节性T细胞(Treg)中表达以靶向在1型糖尿病(T1D)患者的促炎性T细胞中过度表达的CD6分子。该方法与靶向β细胞抗原(可能诱导对胰岛的另外的损害的方法)形成对比。在一些情况下,当前的方法采用CAR,其包括衍生自伊利组单抗(Itolizumab,一种免疫调节性抗CD6单克隆抗体(US 6,572,857))的scFv。CD6CAR使用CD152(CTLA-4)细胞质域(除CD3 zeta外)来驱动转导的宿主细胞中的抑制性信号传导并增强CAR-Treg的免疫调节活性。在一些情况下,CD6对CD6的亲和力相对较低。这可以避免过继转移的细胞过度活化并延长其寿命。在一些情况下,CAR在Treg的CD6低/-亚组中表达。因此,在一些情况下,CD6 CAR在CD4+、CD25hi、CD127低/-、CD6低/-T细胞中表达。在一些情况下,与T效应细胞(Teff)中表达的CAR相比,Treg中表达的CD6 CAR可以具有更好的安全性,因为它们不太可能引发不良的细胞因子释放综合征。此外,Treg可以产生抗炎分子,如IDO、TGF-beta和IL-10。在一些情况下,Treg中表达的CD6 CAR不太易受淋巴细胞耗竭,从而导致其持久性延长,从而提高了过继免疫疗法的疗效。
本文尤其提供了用于自身免疫疾病的细胞、核酸、蛋白质、方法和组合物。在实施方案中,自身免疫疾病与胰岛细胞(例如,β细胞)的功能、生存力或存活降低有关。在实施方案中,自身免疫疾病包括受试者的免疫系统攻击受试者的胰岛细胞(例如,β细胞)。本文还尤其提供了可用于治疗某些自身免疫疾病的组合物。在实施方案中,本文提供了靶向人CD6分子的新的CAR-T细胞。在实施方案中,通过在不同类型的人T细胞(包括T调节性细胞(Treg))中的遗传工程表达对CD6分子具有不同亲和力范围的嵌合抗原受体(CAR)。
在一方面,提供了分离的核酸,其编码包括靶向CD6的单链可变片段(scFv)和跨膜域的蛋白质。
在一方面,提供了载体,其包括本文提供的核酸,包括其实施方案。
在一方面,提供了T淋巴细胞,优选地Treg细胞,其包括本文提供的载体,包括其实施方案。
在一方面,提供了重组蛋白,其包括靶向CD6的单链可变片段(scFv)和跨膜域,包括其实施方案。
在一方面,提供了T淋巴细胞,优选地Treg细胞,其包括本文提供的重组蛋白,包括其实施方案。
在一方面,提供了一种治疗自身免疫疾病的方法。在实施方案中,该方法包括向有此需要的受试者施用有效量的T淋巴细胞,优选Treg细胞,如本文所述,包括其实施方案。
附图说明
图1:由pF03496-CD6scFvop(VH_VL)-IgG4(L235E,N297Q)op-CTLA4-Zetaop表达的CD6 CAR的氨基酸序列,标记了各个域。缺少信号序列(MLLLVTSLLLCELPHPAFLLIP;SEQ IDNO:70)的成熟CAR是SEQ ID NO:83。未成熟序列是SEQ ID NO:84。
图2:由pF03497-CD6scFvop(VL_VH)-IgG4(L235E,N297Q)op-CTLA4-Zetaop表达的CD6 CAR的氨基酸序列,标记了各个域。缺少信号序列(MLLLVTSLLLCELPHPAFLLIP;SEQ IDNO:70)的成熟CAR是SEQ ID NO:85。未成熟序列是SEQ ID NO:86。
图3:由pF03488-CD6scFv(VH-VL)-IgG4op(L235E,N297Q)-41BB-Zetaop表达的CD6CAR的氨基酸序列,标记了各个域。缺少信号序列(MLLLVTSLLLCELPHPAFLLIP;SEQ ID NO:70)的成熟CAR是SEQ ID NO:87。未成熟序列是SEQ ID NO:88。
图4:由pF03491-CD6scFv(VL-VH)-IgG4op(L235E,N297Q)-41BB-Zetaop表达的CD6CAR的氨基酸序列,标记了各个域。缺少信号序列(MLLLVTSLLLCELPHPAFLLIP;SEQ ID NO:70)的成熟CAR是SEQ ID NO:89。未成熟序列是SEQ ID NO:90。
图5:是Treg的制备的示意图。从PBMC分离CD25+细胞。然后使用FACS分选来富集CD4
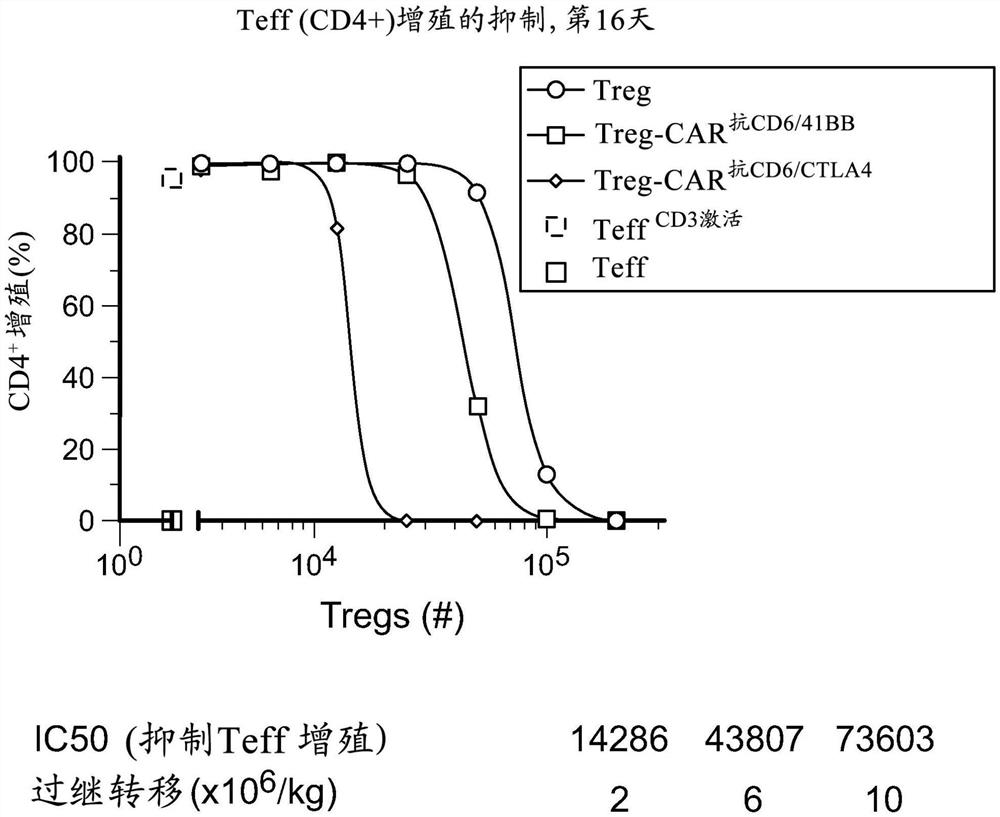
图6:是描绘通过在常规CD4+CD25hiCD127低/-T调节性细胞(Treg)宿主中表达的抗CD6 CAR抑制效应T细胞(Teff)增殖(IC50)的图,所述抗CD6 CAR含有CD137(4-1BB)或CD152(CTLA-4)细胞质域。圆圈,常规Treg-MOCK:Teff-MOCK(IC50=73603);正方形,常规Treg-CAR(抗CD6/41BB):Teff-MOCK(IC50=43807);和菱形,常规Treg-CAR(抗CD6/CTLA4):Teff-MOCK(IC50=14286)。深色单个空正方形,在无刺激物情况下的Teff-MOCK以及浅色单个空正方形,在有刺激物(抗CD3 OKT3 mAb)情况下的Teff-MOCK。
图7:描绘了显示某些CD6 CAR对Teff增殖的影响的实验结果。
图8:描绘了检查由表达某些CD6 CAR的Treg进行的细胞因子表达的研究结果。
图9:描绘了研究结果,其表明表达具有CTLA4信号传导域的CD6 CAR的Treg可以在Teff的存在下在表达相对较低水平的耗竭标志物的情况下培养。
图10:用于本文所述的CAR中的替代CD6 scFv的氨基酸序列(SEQ ID NO:73),显示了域和突变。
发明详述
令人惊讶地,具有低亲和力的CAR减慢、延迟或减少了所接种的CAR-T细胞的耗竭,从而导致更长的半衰期并改善了过继免疫疗法的功效。在实施方案中,本文提供的组合物包括靶向受影响的器官(例如,在T1D的情况下为胰腺)中的CD6+T-和B-淋巴细胞的CAR-T细胞。在实施方案中,本文提供的CAR对CD6分子(即蛋白质)具有亲和力,例如KD为130nM或更高。预期本文提供的CAR-T细胞与人类自身免疫疾病(例如1型糖尿病、多发性硬化症、炎性肠病或移植物抗宿主病)的治疗有关。
尽管在本文中示出和描述了本发明的各种实施方案和方面,但是对于本领域技术人员显而易见的是,此类实施方案和方面仅以示例的方式提供。在不脱离本发明的情况下,本领域技术人员现在将想到许多变形、变化和替换。应当理解的是,本文描述的本发明的实施方案的各种替代方案可以用于实施本发明。
除非另有定义,否则本文中使用的技术和科学术语具有与本领域普通技术人员通常理解的相同含义。参见,例如,Singleton et al.,DICTIONARY OF MICROBIOLOGY ANDMOLECULAR BIOLOGY 2nd ed.,J.Wiley&Sons(New York,NY 1994);Sambrook et al.,MOLECULAR CLONING,A LABORATORY MANUAL,Cold Springs Harbor Press(Cold SpringsHarbor,NY 1989)。与本文所述相似或等同的任何方法、装置和材料均可以用于本发明的实践中。提供以下定义以促进对本文中经常使用的某些术语的理解,并且其不意味着限制本公开的范围。本文使用的缩写在化学和生物学领域具有其常规含义。本文使用的章节标题仅用于组织目的,而不应解释为限制所描述的主题。本申请中引用的所有文件或文件的一部分,包括但不限于专利、专利申请、文章、书籍、手册和专著,均出于任何目的通过引用全文明确地并入本文。
如本文所用,术语“约”意指包括指定值的值的范围,本领域普通技术人员将认为该范围合理地类似于指定值。在实施方案中,术语“约”意指使用本领域通常可接受的测量得到的标准偏差内。在实施方案中,约意指范围扩展到指定值的+/-10%。在实施方案中,约意指指定值。
如本文所用,术语“一个”或“一种”意指一个或多个。
与“包括”、“含有”或“特征在于”同义的过渡术语“包含”是包容性的或开放式的,并且不排除其他未叙述的要素(如方法步骤或成分)。相反,过渡短语“由……组成”排除权利要求中未指定的任何要素。过渡短语“基本上由……组成”将权利要求的范围限制为指定的材料或步骤“以及实质上不影响要求保护的发明的基本和新颖特征的那些”。在使用过渡术语“包含”公开方法和组合物的情况下,应理解的是,还公开了具有过渡术语“由……组成”和“基本上由……组成”的相应方法和组合物。
在提供参数范围的情况下,本发明还提供该范围内的所有整数及其十分之一。例如,“0.2-5mg”是公开0.2mg,0.3mg,0.4mg,0.5mg,0.6mg等直至5.0mg(并包括5.0mg)。
在本文的说明书中和权利要求书中,短语如“至少一个”或“一个或多个”可以随后出现要素或特征的组合列表。术语“和/或”也可以出现在两个或更多个要素或特征的列表中。除非与使用短语的上下文隐含或显著地矛盾,否则此类短语旨在表示单独列出的任何要素或特征,或者与其他任何叙述的要素或特征组合使用任何叙述的要素或特征。例如,短语“A和B中的至少一个;”“A和B中的一个或多个;”和“A和/或B”分别旨在表示“单独的A,单独的B或一起的A和B”。类似的解释也适用于包含三个或更多个项目的列表。例如,短语“A、B和C中的至少一个;”“A、B和C中的一个或多个;”和“A、B和/或C”分别旨在表示“单独的A、单独的B、单独的C、一起的A和B、一起的A和C、一起的B和C或一起的A和B和C”。
“核酸”是指单链或双链形式的脱氧核糖核苷酸或核糖核苷酸及其聚合物及其互补物。术语“多核苷酸”是指核苷酸的线性序列。术语“核苷酸”通常是指多核苷酸的单个单元,即单体。核苷酸可以是核糖核苷酸、脱氧核糖核苷酸或其修饰形式。本文考虑的多核苷酸的实例包括单链和双链DNA,单链和双链RNA(包括siRNA),以及具有单链和双链DNA和RNA的混合物的杂合分子。如本文所用的核酸还指具有与天然存在的核酸相同的基本化学结构的核酸。此类类似物具有修饰的糖和/或修饰的环取代基,但是保留了与天然存在的核酸相同的基本化学结构。核酸模拟物是指具有与核酸的一般化学结构不同的结构但以类似于天然存在的核酸的方式起作用的化合物。此类类似物的实例包括但不限于硫代磷酸酯、氨基磷酸酯、膦酸甲酯、手性膦酸甲酯、2-O-甲基核糖核苷酸和肽核酸(PNA)。
术语“氨基酸”是指天然存在的和合成的氨基酸,以及以类似于天然存在的氨基酸的方式起作用的氨基酸类似物和氨基酸模拟物。天然存在的氨基酸是由遗传密码编码的那些氨基酸,以及后来被修饰的那些氨基酸,例如羟脯氨酸、γ-羧基谷氨酸和O-磷酸丝氨酸。氨基酸类似物是指具有与天然存在的氨基酸相同的基本化学结构(即与氢、羧基、氨基和R基团结合的α碳)的化合物,例如高丝氨酸、正亮氨酸、甲硫氨酸亚砜,甲硫氨酸甲基锍。此类类似物具有修饰的R基团(例如正亮氨酸)或修饰的肽主链,但是保留了与天然存在的氨基酸相同的基本化学结构。氨基酸模拟物是指具有与氨基酸的一般化学结构不同的结构但以类似于天然存在的氨基酸的方式起作用的化合物。
氨基酸在本文中可以用它们通常已知的三个字母符号或IUPAC-IUB生化命名委员会推荐的一个字母符号来指代。同样,核苷酸可以用它们普遍接受的单字母代码来指代。
当将术语“分离的”应用于核酸或蛋白质时,表示该核酸或蛋白质基本上不含在天然状态下与其相关的其他细胞组分。它可以例如处于均质状态并且可以处于干燥或水溶液中。纯度和均质性通常使用分析化学技术(如聚丙烯酰胺凝胶电泳或高效液相色谱法)确定。基本上纯化了制剂中存在的主要种类的蛋白质。
“保守修饰的变体”适用于氨基酸和核酸序列两者。关于特定的核酸序列,保守修饰的变体是指编码相同或基本相同的氨基酸序列的那些核酸,或在核酸不编码氨基酸序列的情况下指基本相同的序列。由于遗传密码的简并性,大量功能相同的核酸序列编码任何给定的氨基酸残基。例如,密码子GCA、GCC、GCG和GCU均编码氨基酸丙氨酸。因此,在密码子指定丙氨酸的每个位置,可以将密码子改变为任何所述相应密码子,而不改变所编码的多肽。此类核酸变异是“沉默变异”,其是保守修饰的变异的一种。本文中编码多肽的每个核酸序列也描述了核酸的每个可能的沉默变异。本领域技术人员将认识到,可以修饰核酸中的每个密码子(通常作为甲硫氨酸的唯一密码子的AUG和通常作为色氨酸的唯一密码子的TGG除外)以产生功能相同的分子。因此,编码多肽的核酸的每个沉默变异就表达产物而言而不是就实际探针序列而言隐含在每个所述序列中。
关于氨基酸序列,本领域技术人员将认识到,改变、添加或缺失编码序列中的单个氨基酸或小百分比氨基酸的核酸、肽、多肽或蛋白质序列的个别取代、缺失或添加是“保守修饰的变体”。在实施方案中,所述改变导致氨基酸被化学相似的氨基酸取代。提供功能上相似的氨基酸的保守取代表是本领域众所周知的。此类保守修饰的变体在本发明的多态变体、种间同系物和等位基因外,并且不排除本发明的多态变体、种间同系物和等位基因。
以下八个基团各自含有作为彼此保守取代的氨基酸:1)丙氨酸(A)、甘氨酸(G);2)天冬氨酸(D)、谷氨酸(E);3)天冬酰胺(N)、谷氨酰胺(Q);4)精氨酸(R)、赖氨酸(K);5)异亮氨酸(I)、亮氨酸(L)、甲硫氨酸(M)、缬氨酸(V);6)苯丙氨酸(F)、酪氨酸(Y)、色氨酸(W);7)丝氨酸(S)、苏氨酸(T);和8)半胱氨酸(C)、甲硫氨酸(M)(参见例如,Creighton,Proteins(1984))。
氨基酸或核苷酸碱基的“位置”由数字表示,该数字基于其相对于N端(或5’末端)的位置顺序识别参考序列中的每个氨基酸(或核苷酸碱基)。由于在确定最佳比对时可能考虑到缺失、插入、截短、融合等,因此通常仅通过从N端进行计数而确定的测试序列中的氨基酸残基数目不一定与参考序列中其对应位置的编号相同。例如,在变体相对于比对的参考序列具有缺失的情况下,变体中将不存在与参考序列中缺失位点的位置处相对应的氨基酸。在比对的参考序列中存在插入的情况下,该插入将不对应于参考序列中的编号的氨基酸位置。在截短或融合的情况下,参考序列或比对序列中可能存在不对应于相应序列中任何氨基酸的氨基酸段。
当在给定氨基酸或多核苷酸序列编号的上下文中使用时,术语“参考……编号”或“对应于”是指当将给定的氨基酸或多核苷酸序列与参考序列进行比较时,指定参考序列的残基的编号。当蛋白质中的氨基酸残基在蛋白质中与给定残基占据相同的基本结构位置时,它“对应”于给定残基。例如,当所选择的残基占据如在Kabat位置40处的轻链的苏氨酸相同的基本空间或其他结构的关系时,在所选择的抗体(或抗原结合域)中所选残基对应于Kabat位置40处的轻链的苏氨酸。在一些实施方案中,在选择的蛋白质与抗体(或抗原结合域)的轻链进行最大程度的同源性比对的情况下,在比对的选择的蛋白质中与苏氨酸40比对的位置被称为对应于苏氨酸40。除了一级序列比对,还可以使用三维结构比对,例如,其中所选蛋白质的结构与Kabat位置40处轻链苏氨酸进行最大对应比对,并比较了总体结构。在这种情况下,在结构模型中占据与苏氨酸40相同的基本位置的氨基酸被称为对应于苏氨酸40残基。
“序列同一性的百分比”是通过在比较窗口中比较两个最佳比对的序列来确定的,其中与参考序列(不包含添加或缺失)相比,比较窗口中多核苷酸或多肽序列的部分可以包含添加或缺失(即空位),以使两个序列最佳比对。通过如下计算百分比:确定两个序列中出现相同核酸碱基或氨基酸残基的位置数以产生匹配位置数,将匹配位置数除以比较窗口中的位置总数,然后将结果乘以100,以产生序列同一性的百分比。
在两个或多个核酸或多肽序列的上下文中,术语“相同”或“同一性”百分数是指在如使用序列比较算法或通过手动比对和目测检查所测量的比较窗口或指定区域上针对最大对应进行比较和比对时,两个或更多个相同或具有指定百分比的相同氨基酸残基或核苷酸的序列或子序列(即,在指定区域,例如本发明的全部多肽序列或本发明的多肽的各个域的指定区域50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、98%或99%的同一性)。至少约80%相同的此类序列被称为“基本上相同”。在一些实施方案中,两个序列是100%相同的。在某些实施方案中,两个序列在序列之一(例如,在序列具有不同长度的情况下,两个序列中较短的一个)的整个长度上是100%相同的。在各种实施方案中,同一性可以指测试序列的互补物。在一些实施方案中,同一性存在于长度为至少约10至约100、约20至约75、约30至约50个氨基酸或核苷酸的区域上。在某些实施方案中,同一性存在于长度为约10个核苷酸的区域上,或更优选地存在于长度为20至50、100至500或1000或更多个核苷酸的区域上。在某些实施方案中,同一性存在于长度为至少约50个氨基酸的区域上,或更优选地存在于100至500、100至200、150至200、175至200、175至225、175至250、200至225、200至250或更多个氨基酸的区域上。
为了进行序列比较,通常一个序列充当参考序列,将其与测试序列进行比较。当使用序列比较算法时,将测试序列和参考序列输入计算机,必要时指定子序列坐标,并指定序列算法程序参数。优选地,可以使用默认程序参数,或者可以指定替代参数。然后,序列比较算法基于程序参数计算测试序列相对于参考序列的序列同一性百分比。
“比较窗口”是指多个连续位置中的任何一个的区段(例如,至少约10至约100、约20至约75、约30至约50、100至500、100至200、150至200、175至200、175至225、175至250、200至225、200至250),其中在将两个序列进行最佳比对后,可以将序列与相同数目的连续位置的参考序列进行比较。在各种实施方案中,比较窗口是两个比对序列之一或两者的全长。在一些实施方案中,被比较的两个序列包括不同的长度,并且比较窗口是两个序列中较长或较短者的整个长度。在涉及不同长度的两个序列的某些实施方案中,比较窗口包括两个序列中的较短者的整个长度。在涉及不同长度的两个序列的一些实施方案中,比较窗口包括两个序列中的较长者的整个长度。
用于比较的序列比对的方法是本领域众所周知的。用于比较的序列的最佳比对可以例如通过Smith and Waterman(1970)Adv.Appl.Math.2:482c局部同源性算法,通过Needleman and Wunsch(1970)J.Mol.Biol.48:443的同源性比对算法,通过Pearson andLipman(1988)Proc.Nat’l.Acad.Sci.USA 85:2444的搜索相似性方法,通过这些算法的计算机化实现(Wisconsin Genetics软件包中的GAP、BESTFIT、FASTA和TFASTA,GeneticsComputer Group,575Science Dr.,Madison,WI),或者通过手动比对和目测检查(参见例如,Ausubel et al.,Current Protocols in Molecular Biology(1995supplement))。
适用于确定百分比序列同一性和序列相似性的算法的实例是BLAST和BLAST 2.0算法,其分别描述于Altschul et al.(1977)Nuc.Acids Res.25:3389-3402和Altschul etal.(1990)J.Mol.Biol.215:403-410中。可以使用具有本文描述的参数的BLAST和BLAST2.0来确定核酸和蛋白质的序列同一性百分比。如本领域已知的,可通过国家生物技术信息中心(NCBI)公开获得用于进行BLAST分析的软件。可通过国家生物技术信息中心(ncbi.nlm.nih.gov/)公开获得进行BLAST分析的软件。该算法涉及首先通过识别查询序列中长度W的短单词来识别高分序列对(HSP),当其在与数据库序列中相同长度的单词比对时匹配或满足一些正值阈值得分T。T称为邻近单词分数阈值(Altschul等人,同上)。这些最初的邻近单词命中(hit)充当启动搜索以查找包含它们的较长HSP的种子。单词命中沿着每个序列在两个方向上延伸,直到可以增加累积比对得分为止。对于核苷酸序列,使用参数M(一对匹配残基的奖励分数;始终>0)和N(错配残基的罚分;始终<0)来计算累积得分。对于氨基酸序列,使用得分矩阵来计算累积得分。在以下情况下,将停止单词命中在每个方向上的延伸:累积比对得分从其最大实现值下降了数量X;由于一个或多个负得分残基比对的累积,累积得分变为零或更低;或到达任一序列的末端。BLAST算法参数W、T和X确定比对的灵敏度和速度。在某些实施方案中,使用NCBI BLASTN或BLASTP程序比对序列。在某些实施方案中,BLASTN或BLASTP程序使用NCBI使用的默认值。在某些实施方案中,BLASTN程序(用于核苷酸序列)使用以下作为默认值:字长(W)为28;期望阈值(E)为10;查询范围内的最大匹配设置为0;匹配/不匹配得分为1,-2;线性空位成本;使用低复杂度区域的过滤器;和仅用于查找表的掩码。在某些实施方案中,BLASTP程序(用于氨基酸序列)使用以下作为默认值:字长(W)为3;期望阈值(E)为10;查询范围内的最大匹配数设置为0;BLOSUM62矩阵(参见Henikoff&Henikoff,Proc.Natl.Acad.Sci.USA89:10915(1992));存在的空位成本:11和延伸:1;和条件成分得分矩阵调整。
BLAST算法还对两个序列之间的相似性进行统计分析(参见例如,Karlin andAltschul(1993)Proc.Natl.Acad.Sci.USA 90:5873-5787)。BLAST算法提供的一种相似性度量是最小总和概率(P(N)),其表示偶然发生两个核苷酸或氨基酸序列匹配的概率。例如,如果在测试核酸与参考核酸的比较中最小总和概率小于约0.2,更优选小于约0.01,且最优选小于约0.001,则认为核酸与参考序列相似。
在某些实施方案中,两个核酸序列或多肽基本上相同的指示是,由第一核酸编码的多肽与针对由第二核酸编码的多肽产生的抗体发生免疫交叉反应,如以下所述。因此,多肽通常与第二多肽基本相同,例如,在两个肽仅通过保守取代而不同的情况下。如下所述,两个核酸序列基本相同的另一个指示是两个分子或其互补物在严格条件下彼此杂交。两个核酸序列基本相同的又一个指示是可以使用相同的引物来扩增序列。
术语“多肽”、“肽”和“蛋白质”在本文可互换使用,是指氨基酸残基的聚合物,其中该聚合物可以任选地缀合至不由氨基酸组成的部分。该术语适用于其中一个或多个氨基酸残基是相应天然存在的氨基酸的人工化学模拟物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物和非天然存在的氨基酸聚合物。“融合蛋白”是指编码两个或更多个单独的蛋白质序列的嵌合蛋白,所述两个或更多个单独的蛋白质序列重组表达为单个部分。
“标记物”或“可检测部分”是可通过光谱、光化学、生物化学、免疫化学、化学或其他物理手段检测的组合物。例如,有用的标记物包括
“标记的蛋白质或多肽”是通过接头或化学键共价结合,或通过离子、范德华力、静电或氢键非共价结合至标记物以使得可以通过检测与标记的蛋白质或多肽结合的标记物的存在来检测标记的蛋白质或多肽的存在的标记的蛋白质或多肽。或者,使用高亲和力相互作用的方法可以实现相同的结果,其中一对结合配偶体中的一个与另一个例如生物素、链霉抗生物素蛋白结合。
“抗体”是指包含来自免疫球蛋白基因或其片段的框架区的多肽,其特异性结合并识别抗原。公认的免疫球蛋白基因包括κ、λ、α、γ、δ、ε和μ恒定区基因,以及无数免疫球蛋白可变区基因。轻链分类为κ或λ。重链分类为γ、μ、α、δ或ε,其依次定义了免疫球蛋白类别,分别为IgG、IgM、IgA、IgD和IgE。通常,抗体的抗原结合区在确定结合的特异性和亲和力中起重要作用。在一些实施方案中,抗体或抗体片段可以衍生自不同生物体,包括人、小鼠、大鼠、仓鼠、骆驼等。本发明的抗体可以包括已在一个或多个氨基酸位置处经修饰或突变的抗体,以改善或调节抗体的所期望功能(例如糖基化、表达、抗原识别、效应子功能、抗原结合、特异性等)。
抗体是具有复杂内部结构的大的复杂分子(分子量约为150,000或约1320个氨基酸)。天然抗体分子包含两对相同的多肽链,每对具有一条轻链和一条重链。每条轻链和重链又由两个区域组成:参与结合靶抗原的可变(“V”)区域,和与免疫系统其他组分相互作用的恒定(“C”)区域。轻链和重链可变区在3维空间中汇聚在一起以形成结合抗原的可变区(例如,细胞表面上的受体)。在每条轻链或重链可变区内,有三个短区段(平均长度为10个氨基酸),称为互补决定区(“CDR”)。抗体可变域中的六个CDR(三个来自轻链,三个来自重链)在3维空间中折叠在一起以形成对接在靶抗原上的实际抗体结合位点。CDR的位置和长度已由Kabat,E.et al.,Sequences of Proteins of Immunological Interest,U.S.Department of Health and Human Services,1983,1987精确定义。CDR中未包含的可变区的部分称为框架(“FR”),其形成CDR的环境。
示例性的免疫球蛋白(抗体)结构单元包含四聚体。每个四聚体由两对相同的多肽链组成,每对具有一条“轻”(约25kD)和一条“重”链(约50-70kD)。每条链的N端定义了主要负责抗原识别的约100至110个或更多个氨基酸的可变区。术语可变轻链(VL)和可变重链(VH)分别是指这些轻链和重链。Fc(即片段可结晶区域)是免疫球蛋白的“基部”或“尾部”,并且通常由两条重链组成,所述两条重链根据抗体的种类贡献两个或三个恒定域。通过与特定蛋白质结合,Fc区确保每种抗体针对给定的抗原产生适当的免疫反应。Fc区还结合各种细胞受体,如Fc受体和其他免疫分子,如补体蛋白。
本文提供的术语“抗原”是指能够结合抗体结合位点的分子。
抗体例如作为完整的免疫球蛋白存在,或者作为通过用各种肽酶消化产生的许多充分表征的片段存在。因此,例如,胃蛋白酶消化铰链区中二硫化物连接下方的抗体以产生F(ab)’2,这是Fab的二聚体,它本身是一条通过二硫键与VH-CH1接合的轻链。F(ab)’2可以在温和条件下还原,以破坏铰链区中的二硫化物连接,从而将F(ab)’2二聚体转化为Fab’单体。Fab’单体本质上是具有部分铰链区的抗原结合部分(参见Fundamental Immunology(Paul ed.,3d ed.1993))。虽然根据完整抗体的消化定义各种抗体片段,但是本领域技术人员应当理解,此类片段可以以化学方式或通过使用重组DNA方法从头合成。因此,本文所用的术语抗体还包括通过修饰整个抗体产生的抗体片段,或使用重组DNA方法从头合成的抗体片段(例如单链Fv),或使用噬菌体展示文库鉴定的抗体片段(参见例如McCafferty etal.,Nature 348:552-554(1990))。
单链可变片段(scFv)通常是免疫球蛋白的重链(VH)和轻链(VL)的可变区的融合蛋白,其用接头肽(例如10至约25个氨基酸的短接头肽)连接。在实施方案中,接头富含甘氨酸以获得柔性,以及富含丝氨酸或苏氨酸以获得溶解度。接头可以将VH的N端与VL的C端相连,反之亦然。
mAb的表位是其与mAb结合的抗原的区域。如果每种抗体竞争性地抑制(阻断)另一种抗体与抗原的结合,则两种抗体与相同或重叠的表位结合。也就是说,如在竞争性结合测定中所测量的,一种抗体的1x、5x、10x、20x或100x过量抑制另一种抗体的结合达至少30%,但优选50%、75%、90%或甚至99%(参见例如,Junghans et al.,Cancer Res.50:1495,1990)。或者,如果抗原中基本上所有减少或消除一种抗体的结合的氨基酸突变都减少或消除了另一种抗体的结合,则两种抗体具有相同的表位。如果一些减少或消除一种抗体结合的氨基酸突变减少或消除了另一种抗体的结合,则两种抗体具有重叠的表位。
为了制备合适的抗体,可以使用本领域已知的许多技术(参见例如,Kohler&Milstein,Nature 256:495-497(1975);Kozbor et al.,Immunology Today 4:72(1983);Cole et al.,pp.77-96in Monoclonal Antibodies and Cancer Therapy,Alan R.Liss,Inc.(1985);Coligan,Current Protocols in Immunology(1991);Harlow&Lane,Antibodies,A Laboratory Manual(1988);和Goding,Monoclonal Antibodies:Principles and Practice(2d ed.1986))。可以从细胞中克隆编码感兴趣的抗体的重链和轻链的基因,例如,可以从杂交瘤中克隆编码单克隆抗体的基因,并用于产生重组单克隆抗体。编码单克隆抗体的重链和轻链的基因文库也可以从杂交瘤或浆细胞中制备。重链和轻链基因产物的随机组合产生大量具有不同抗原特异性的抗体(参见例如,Kuby,Immunology(3rd ed.1997))。产生单链抗体或重组抗体的技术(美国专利4,946,778,美国专利4,816,567)可以适于产生针对本发明的多肽的抗体。同样,转基因小鼠或其他生物体,如其他哺乳动物,可以用于表达人源化或人抗体(参见例如,美国专利号5,545,807;5,545,806;5,569,825;5,625,126;5,633,425;5,661,016,Marks et al.,Bio/Technology 10:779-783(1992);Lonberg et al.,Nature368:856-859(1994);Morrison,Nature 368:812-13(1994);Fishwild et al.,Nature Biotechnology 14:845-51(1996);Neuberger,NatureBiotechnology 14:826(1996);和Lonberg&Huszar,Intern.Rev.Immunol.13:65-93(1995))。或者,噬菌体展示技术可以用于鉴定特异性结合所选抗原的抗体和异聚化Fab片段(参见例如,McCafferty et al.,Nature 348:552-554(1990);Marks et al.,Biotechnology 10:779-783(1992))。也可以将抗体制成双特异性的,即能够识别两种不同的抗原(参见例如,WO 93/08829,Traunecker et al.,EMBO J.10:3655-3659(1991);和Suresh et al.,Methods in Enzymology 121:210(1986))。抗体也可以是异源缀合物,例如两种共价接合的抗体或免疫毒素(参见例如,美国专利号4,676,980,WO 91/00360;WO92/200373;和EP 03089)。
用于使非人抗体或scFv人源化或灵长类化(primatize)的方法是本领域众所周知的(例如,美国专利号4,816,567;5,530,101;5,859,205;5,585,089;5,693,761;5,693,762;5,777,085;6,180,370;6,210,671;和6,329,511;WO 87/02671;欧洲专利申请0173494;Jones et al.(1986)Nature 321:522;和Verhoyen et al.(1988)Science 239:1534)。人源化抗体进一步描述于例如Winter and Milstein(1991)Nature 349:293中。通常,人源化抗体具有从非人源引入的一个或多个氨基酸残基。这些非人氨基酸残基通常称为输入残基,其通常取自输入可变域。可以基本上按照Winter及其同事的方法进行人源化(参见例如,Morrison et al.,PNAS USA,81:6851-6855(1984),Jones et al.,Nature321:522-525(1986);Riechmann et al.,Nature 332:323-327(1988);Morrison and Oi,Adv.Immunol.,44:65-92(1988),Verhoeyen et al.,Science239:1534-1536(1988)和Presta,Curr.Op.Struct.Biol.2:593-596(1992),Padlan,Molec.Immun.,28:489-498(1991);Padlan,Molec.Immun.,31(3):169-217(1994)),通过用啮齿动物CDR或CDR序列取代人抗体的相应序列。因此,此类人源化抗体是嵌合抗体(美国专利号4,816,567),其中基本上少于完整的人可变域已被来自非人物种的相应序列取代。在实践中,人源化抗体通常是下述人抗体,其中一些CDR残基和可能一些FR残基被啮齿动物抗体中类似位点的残基取代。例如,可以以合成方式或通过组合适当的cDNA和基因组DNA区段来产生包含编码人源化免疫球蛋白框架区的第一序列和编码所期望的免疫球蛋白互补性决定区的第二序列组的多核苷酸。可以根据众所周知的程序从多种人细胞中分离人恒定区DNA序列。
“嵌合抗体”是下述抗体分子,其中(a)恒定区或其一部分被改变、替换或交换,使得抗原结合位点(可变区)连接至不同或改变的类别,效应子功能和/或种类的恒定区,或赋予嵌合抗体新特性的完全不同的分子,例如酶、毒素、激素、生长因子、药物等;或(b)用具有不同或改变的抗原特异性的可变区改变、替换或交换可变区或其一部分。根据本发明使用的优选抗体包括人源化和/或嵌合单克隆抗体。
如本文提供的“治疗性抗体”是指用于治疗癌症、自身免疫疾病、移植排斥、心血管疾病或其他疾病或病状(如本文所述的那些)的任何抗体或其功能片段。
使治疗剂与抗体缀合的技术是众所周知的(参见例如,Arnon et al.,"Monoclonal Antibodies For Immunotargeting Of Drugs In Cancer Therapy",inMonoclonal Antibodies And Cancer Therapy,Reisfeld et al.(eds.),pp.243-56(AlanR.Liss,Inc.1985);Hellstrom et al.,"Antibodies For Drug Delivery"in ControlledDrug Delivery(2
如本文所用,术语“抗CD6抗体”是指能够通过抗体CDR序列结合CD6的抗体。因此,抗CD6抗体包括由特异性结合CD6的CDR(例如,VL-CDRl、VL-CDR2、VL-CDR3、VH-CDRl、VH-CDR2、VH-CDR3)组成的抗体结合位点。
如本文所指,“CD6”,也称为TP120,包括分化簇6(CD6)的任何重组或天然存在形式,或维持CD6活性(例如与CD6相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在各方面中,与天然存在的CD6蛋白质相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD6蛋白与由UniProt参考号P30203标识的蛋白质或与其具有实质同一性的变体或同源物实质上相同。在一些情况下,CD6是人CD6蛋白。在一些情况下,与天然存在的CD6蛋白相比,CD6蛋白的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD6蛋白相比,CD6蛋白的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD6蛋白相比,CD6蛋白的变体或突变体不包括缺失。在一些情况下,与天然存在的CD6蛋白相比,CD6蛋白的变体或突变体不包括插入。在一些情况下,与天然存在的CD6蛋白相比,CD6蛋白的变体或突变体包括作为保守取代的取代。在一些情况下,CD6是由NCBI序列参考NP_006716.3标识的蛋白质或其同等型或天然存在的突变体或变体。在一些情况下,CD6是由NCBI序列参考NP_001241679.1标识的蛋白质或其同等型或天然存在的突变体或变体。在一些情况下,CD6是由NCBI序列参考NP_001241680.1标识的蛋白质或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CD6氨基酸序列的非限制性实例如下:
NP_001241679.1
NP_001241680.1
如本文提供的术语“CD28跨膜域”包括CD28的跨膜域的任何重组或天然存在形式,或维持CD28跨膜域活性(例如与CD28跨膜域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些情况下,与天然存在的CD28跨膜域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD28跨膜域是人CD28跨膜域蛋白质。在一些情况下,与天然存在的CD28跨膜域蛋白质相比,CD28跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD28跨膜域蛋白质相比,CD28跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD28跨膜域蛋白质相比,CD28跨膜域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD28跨膜域蛋白质相比,CD28跨膜域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD28跨膜域蛋白质相比,CD28跨膜域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD28跨膜域包括由NCBI序列参考NP_001230006.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD28跨膜域包括由NCBI序列参考NP_001230007.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD28跨膜域包括由NCBI序列参考NP_006130.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD28跨膜域氨基酸序列包括RSKRSRGGHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(SEQ ID NO:7)的序列。在一些情况下,CD28跨膜域氨基酸序列是SEQ ID NO:7的序列。在一些情况下,CD28跨膜域氨基酸序列包括RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(SEQ ID NO:8)的序列。在一些情况下,CD28跨膜域氨基酸序列是SEQ ID NO:8的序列。在NCBI序列参考下可获得的人CD28氨基酸序列的非限制性实例如下:
MP_001230006.1
NP_001230007.1
NP_006130.1
在一些情况下,CD28跨膜域由NCBI序列参考NM_001243077.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD28跨膜域由NCBI序列参考NM_001243078.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD28跨膜域由NCBI序列参考NM_006139.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD28跨膜域核酸序列相比,CD28跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD28跨膜域核酸序列相比,CD28跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD28跨膜域核酸序列相比,CD28跨膜域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD28跨膜域核酸序列相比,CD28跨膜域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD28跨膜域核酸序列相比,CD28跨膜域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CD4跨膜域”包括CD4的跨膜域的任何重组或天然存在形式,或维持CD4跨膜域活性(例如与CD4跨膜域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CD4跨膜域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD4跨膜域氨基酸序列包括MALIVLGGVAGLLLFIGLGIFF(SEQ ID NO:23)的序列。在一些情况下,CD4跨膜域氨基酸序列是SEQ ID NO:23的序列。编码CD4跨膜域的核苷酸序列的非限制性实例为ATGGCCCTGATTGTGCTGGGGGGCGTCGCCGGCCTCCTGCTTTTCATTGGGCTAGGCATCTTCTTC(SEQ ID NO:24)。在一些情况下,CD4跨膜域是人CD4跨膜域蛋白质。在一些情况下,与天然存在的CD4跨膜域蛋白质相比,CD4跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD4跨膜域蛋白质相比,CD4跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD4跨膜域蛋白质相比,CD4跨膜域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD4跨膜域蛋白质相比,CD4跨膜域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD4跨膜域蛋白质相比,CD4跨膜域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD4跨膜域包括由NCBI序列参考NP_000607.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD4跨膜域包括由NCBI序列参考NP_001181943.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD4跨膜域包括由NCBI序列参考NP_001181944.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD4跨膜域包括由NCBI序列参考NP_001181945.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD4跨膜域包括由NCBI序列参考NP_001181946.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CD4氨基酸序列的非限制性实例如下:NP_000607.1
NP_001181943.1
NP_001181944.1
NP_001181945.1
NP_001181946.1
在一些情况下,CD4跨膜域由NCBI序列参考NM_000616.4标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD4跨膜域由NCBI序列参考NM_001195014.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD4跨膜域由NCBI序列参考NM_001195015.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD4跨膜域由NCBI序列参考NM_001195016.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD4跨膜域由NCBI序列参考NM_001195017.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD4跨膜域核酸序列相比,CD4跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD4跨膜域核酸序列相比,CD4跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD4跨膜域核酸序列相比,CD4跨膜域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD4跨膜域核酸序列相比,CD4跨膜域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD4跨膜域核酸序列相比,CD4跨膜域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CD8跨膜域”包括CD8的跨膜域的任何重组或天然存在形式,或维持CD8跨膜域活性(例如与CD8跨膜域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CD8跨膜域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD8跨膜域氨基酸序列包括IYIWAPLAGTCGVLLLSLVIT(SEQ ID NO:25)的序列。在一些情况下,CD8跨膜域氨基酸序列是SEQ ID NO:25的序列。在一些情况下,CD8跨膜域是CD8A跨膜域。在一些情况下,CD8跨膜域是CD8B跨膜域。在一些情况下,CD8跨膜域是人CD8跨膜域蛋白质。在一些情况下,与天然存在的CD8跨膜域蛋白质相比,CD8跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD8跨膜域蛋白质相比,CD8跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD8跨膜域蛋白质相比,CD8跨膜域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD8跨膜域蛋白质相比,CD8跨膜域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD8跨膜域蛋白质相比,CD8跨膜域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001139345.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001181943.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001181944.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001181945.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_741969.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001759.3标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考XP_011531466.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_001171571.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_757362.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_742100.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_742099.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD8跨膜域包括由NCBI序列参考NP_004922.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CD8氨基酸序列的非限制性实例如下:
NP_001139345.1
NP_741969.1
NP_001759.3
XP_011531466.1
NP_001171571.1
NP_757362.1
NP_742100.1
NP_742099.1
NP_004922.1
在一些情况下,CD8跨膜域由NCBI序列参考NR_027353.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_001145873.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_001768.6标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_171827.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考XM_011533164.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_001178100.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_004931.4标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_172102.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_172101.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD8跨膜域由NCBI序列参考NM_172213.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD8跨膜域核酸序列相比,CD8跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD8跨膜域核酸序列相比,CD8跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD8跨膜域核酸序列相比,CD8跨膜域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD8跨膜域核酸序列相比,CD8跨膜域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD8跨膜域核酸序列相比,CD8跨膜域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CD3-zeta跨膜域”包括CD3-zeta的跨膜域的任何重组或天然存在形式,或维持CD3-zeta跨膜域活性(例如与CD3-zeta跨膜域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CD3-zeta跨膜域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD3-zeta跨膜域是人CD3-zeta跨膜域蛋白质。在一些情况下,与天然存在的CD3-zeta跨膜域蛋白质相比,CD3-zeta跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD3-zeta跨膜域蛋白质相比,CD3-zeta跨膜域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD3-zeta跨膜域蛋白质相比,CD3-zeta跨膜域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD3-zeta跨膜域蛋白质相比,CD3-zeta跨膜域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD3-zeta跨膜域蛋白质相比,CD3-zeta跨膜域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD3-zeta跨膜域包括由NCBI序列参考NP_000725.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD3-zeta跨膜域包括由NCBI序列参考NP_932170.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CD3-zeta氨基酸序列的非限制性实例如下:
NP_000725.1
NP_932170.1
在一些情况下,CD3-zeta跨膜域由NCBI序列参考NM_000734.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD3-zeta跨膜域由NCBI序列参考NM_198053.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD3-zeta跨膜域核酸序列相比,CD3-zeta跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD3-zeta跨膜域核酸序列相比,CD3-zeta跨膜域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD3-zeta跨膜域核酸序列相比,CD3-zeta跨膜域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD3-zeta跨膜域核酸序列相比,CD3-zeta跨膜域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD3-zeta跨膜域核酸序列相比,CD3-zeta跨膜域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CD28共刺激域”包括CD28的共刺激域的任何重组或天然存在形式,或维持CD28共刺激域活性(例如与CD28共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CD28共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD28共刺激域氨基酸序列包括RSKRSRGGHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(SEQID NO:7)的序列。在一些情况下,CD28共刺激域氨基酸序列是RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS(SEQ ID NO:8)的序列。
在一些情况下,CD28共刺激域是人CD28共刺激域蛋白质。在一些情况下,与天然存在的CD28共刺激域蛋白质相比,CD28共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD28共刺激域蛋白质相比,CD28共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD28共刺激域蛋白质相比,CD28共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD28共刺激域蛋白质相比,CD28共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD28共刺激域蛋白质相比,CD28共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD28共刺激域包括由NCBI序列参考NP_001230006.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD28共刺激域包括由NCBI序列参考NP_001230007.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD28共刺激域包括由NCBI序列参考NP_006130.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CD28氨基酸序列的非限制性实例如下:
NP_001230006.1
NP_001230007.1
NP_006130.1
在一些情况下,CD28共刺激域由NCBI序列参考NM_001243077.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD28共刺激域由NCBI序列参考NM_001243078.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD28共刺激域由NCBI序列参考NM_006139.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD28共刺激域核酸序列相比,CD28共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD28共刺激域核酸序列相比,CD28共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD28共刺激域核酸序列相比,CD28共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD28共刺激域核酸序列相比,CD28共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD28共刺激域核酸序列相比,CD28共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“4-1BB共刺激域”包括4-1BB的共刺激域的任何重组或天然存在形式,或维持4-1BB共刺激域活性(例如与4-1BB共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的4-1BB共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,4-1BB共刺激域是人4-1BB共刺激域蛋白质。在一些情况下,与天然存在的4-1BB共刺激域蛋白质相比,4-1BB共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的4-1BB共刺激域蛋白质相比,4-1BB共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的4-1BB共刺激域蛋白质相比,4-1BB共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的4-1BB共刺激域蛋白质相比,4-1BB共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的4-1BB共刺激域蛋白质相比,4-1BB共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,4-1BB共刺激域蛋白质包括氨基酸序列KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL(SEQ ID NO:14)。在一些情况下,4-1BB共刺激域蛋白质氨基酸序列与SEQ ID NO:14具有至少或约50%、60%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性。在一些情况下,4-1BB共刺激域包括由NCBI序列参考NP_001552.2标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人4-1BB氨基酸序列的非限制性实例如下:
NP_001552.2
在一些情况下,4-1BB共刺激域由NCBI序列参考NM_001561.5标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的4-1BB共刺激域核酸序列相比,4-1BB共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的4-1BB共刺激域核酸序列相比,4-1BB共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的4-1BB共刺激域核酸序列相比,4-1BB共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的4-1BB共刺激域核酸序列相比,4-1BB共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的4-1BB共刺激域核酸序列相比,4-1BB共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“ICOS共刺激域”包括ICOS的共刺激域的任何重组或天然存在形式,或维持ICOS共刺激域活性(例如与ICOS共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的ICOS共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,ICOS共刺激域氨基酸序列包括CWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL(SEQ ID NO:31)的序列。在一些情况下,ICOS共刺激域是人ICOS共刺激域蛋白质。在一些情况下,与天然存在的ICOS共刺激域蛋白质相比,ICOS共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的ICOS共刺激域蛋白质相比,ICOS共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的ICOS共刺激域蛋白质相比,ICOS共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的ICOS共刺激域蛋白质相比,ICOS共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的ICOS共刺激域蛋白质相比,ICOS共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,ICOS共刺激域包括由NCBI序列参考NP_036224.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人ICOS氨基酸序列的非限制性实例如下:
NP_036224.1
在一些情况下,ICOS共刺激域由NCBI序列参考NM_012092.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的ICOS共刺激域核酸序列相比,ICOS共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的ICOS共刺激域核酸序列相比,ICOS共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的ICOS共刺激域核酸序列相比,ICOS共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的ICOS共刺激域核酸序列相比,ICOS共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的ICOS共刺激域核酸序列相比,ICOS共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“OX-40共刺激域”包括OX-40的共刺激域的任何重组或天然存在形式,或维持OX-40共刺激域活性(例如与OX-40共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的OX-40共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,OX-40共刺激域氨基酸序列包括ALYLLRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKI(SEQ ID NO:32)的序列。在一些情况下,OX-40共刺激域是人OX-40共刺激域蛋白质。在一些情况下,与天然存在的OX-40共刺激域蛋白质相比,OX-40共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的OX-40共刺激域蛋白质相比,OX-40共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的OX-40共刺激域蛋白质相比,OX-40共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的OX-40共刺激域蛋白质相比,OX-40共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的OX-40共刺激域蛋白质相比,OX-40共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,OX-40共刺激域包括由NCBI序列参考NP_003318.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人OX-40氨基酸序列的非限制性实例如下:NP_003318.1
在一些情况下,OX-40共刺激域由NCBI序列参考NM_003327.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的OX-40共刺激域核酸序列相比,OX-40共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的OX-40共刺激域核酸序列相比,OX-40共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的OX-40共刺激域核酸序列相比,OX-40共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的OX-40共刺激域核酸序列相比,OX-40共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的OX-40共刺激域核酸序列相比,OX-40共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CTLA-4共刺激域”包括CTLA-4的共刺激域的任何重组或天然存在形式,或维持CTLA-4共刺激域活性(例如与CTLA-4共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CTLA-4共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CTLA-4共刺激域蛋白质是人CTLA-4共刺激域蛋白质。在一些情况下,CTLA-4共刺激域包括不超过5、4、3、2或1个缺失。在一些情况下,CTLA-4共刺激域蛋白质包括不超过5、4、3、2或1个插入。在一些情况下,CTLA-4共刺激域蛋白质不包括缺失。在一些情况下,CTLA-4共刺激域蛋白质不包括插入。在一些情况下,CTLA-4共刺激域蛋白质包括作为保守取代的取代。在一些情况下,CTLA-4共刺激域蛋白质包括序列AVSLSKMLKKRSPLTTGVYVKMPPTEPECEKQFQPYFIPIN(SEQ ID NO:17)。在一些情况下,4-1BB共刺激域蛋白质是序列SEQ ID NO:17。在一些情况下,4-1BB共刺激域氨基酸序列与SEQ ID NO:17具有至少或约50%、60%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性。在一些情况下,CTLA-4共刺激域是人CTLA-4共刺激域蛋白质。在一些情况下,与天然存在的CTLA-4共刺激域蛋白质相比,CTLA-4共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CTLA-4共刺激域蛋白质相比,CTLA-4共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CTLA-4共刺激域蛋白质相比,CTLA-4共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CTLA-4共刺激域蛋白质相比,CTLA-4共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CTLA-4共刺激域蛋白质相比,CTLA-4共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CTLA-4共刺激域包括由NCBI序列参考NP_001032720.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CTLA-4共刺激域包括由NCBI序列参考NP_005205.2标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人CTLA-4氨基酸序列的非限制性实例如下:
NP_001032720.1
NP_005205.2
在一些情况下,CTLA-4共刺激域由NCBI序列参考NM_001037631.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CTLA-4共刺激域由NCBI序列参考NM_005214.5标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CTLA-4共刺激域核酸序列相比,CTLA-4共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CTLA-4共刺激域核酸序列相比,CTLA-4共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CTLA-4共刺激域核酸序列相比,CTLA-4共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CTLA-4共刺激域核酸序列相比,CTLA-4共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CTLA-4共刺激域核酸序列相比,CTLA-4共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“PD-1共刺激域”包括PD-1的共刺激域的任何重组或天然存在形式,或维持PD-1共刺激域活性(例如与PD-1共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的PD-1共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,PD-1共刺激域氨基酸序列包括CSRAARGTIGARRTGQPLKEDPSAVPVFSVDYGELDFQWREKTPEPPVPCVPEQTEYATIVFPSGMGTSSPARRGSADGPRSAQPLRPEDGHCSWPL(SEQ ID NO:33)的序列。在一些情况下,PD-1共刺激域是人PD-1共刺激域蛋白质。在一些情况下,与天然存在的PD-1共刺激域蛋白质相比,PD-1共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的PD-1共刺激域蛋白质相比,PD-1共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的PD-1共刺激域蛋白质相比,PD-1共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的PD-1共刺激域蛋白质相比,PD-1共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的PD-1共刺激域蛋白质相比,PD-1共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,PD-1共刺激域包括由NCBI序列参考NP_005009.2标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人PD-1氨基酸序列的非限制性实例如下:
NP_005009.2
在一些情况下,PD-1共刺激域由NCBI序列参考NM_005018.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的PD-1共刺激域核酸序列相比,PD-1共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的PD-1共刺激域核酸序列相比,PD-1共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的PD-1共刺激域核酸序列相比,PD-1共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的PD-1共刺激域核酸序列相比,PD-1共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的PD-1共刺激域核酸序列相比,PD-1共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“GITR共刺激域”包括GITR的共刺激域的任何重组或天然存在形式,或维持GITR共刺激域活性(例如与GITR共刺激域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的GITR共刺激域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,GITR共刺激域氨基酸序列包括QLGLHIWQLRSQCMWPRETQLLLEVPPSTEDARSCQFPEEERGERSAE EKGRLGDLWV(SEQ ID NO:67)的序列。在一些情况下,GITR共刺激域是人GITR共刺激域蛋白质。在一些情况下,与天然存在的GITR共刺激域蛋白质相比,GITR共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的GITR共刺激域蛋白质相比,GITR共刺激域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的GITR共刺激域蛋白质相比,GITR共刺激域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的GITR共刺激域蛋白质相比,GITR共刺激域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的GITR共刺激域蛋白质相比,GITR共刺激域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,GITR共刺激域包括由NCBI序列参考NP_004186.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,GITR共刺激域包括由NCBI序列参考NP_683699.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,GITR共刺激域包括由NCBI序列参考NP_683700.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在NCBI序列参考下可获得的人GITR氨基酸序列的非限制性实例如下:NP_004186.1
NP_683699.1
NP_683700.1
在一些情况下,GITR共刺激域由NCBI序列参考NM_148902.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,GITR共刺激域由NCBI序列参考NM_004195.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,GITR共刺激域由NCBI序列参考NM_148901.1标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的GITR共刺激域核酸序列相比,GITR共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的GITR共刺激域核酸序列相比,GITR共刺激域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的GITR共刺激域核酸序列相比,GITR共刺激域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的GITR共刺激域核酸序列相比,GITR共刺激域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的GITR共刺激域核酸序列相比,GITR共刺激域核酸序列的变体或突变体包括作为保守取代的取代。
如本文提供的术语“CD3ζ细胞内T细胞信号传导域”包括CD3ζ细胞内T细胞信号传导域的任何重组或天然存在形式,或维持CD3ζ细胞内T细胞信号传导域活性(例如与CD3ζ细胞内T细胞信号传导域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的其变体或同源物。在一些方面,与天然存在的CD3ζ细胞内T细胞信号传导域多肽相比,变体或同源物在整个序列或序列的一部分(例如50、100、150或200个连续氨基酸部分)间具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在一些情况下,CD3ζ细胞内T细胞信号传导域是人CD3ζ细胞内T细胞信号传导域蛋白质。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域蛋白质相比,CD3ζ细胞内T细胞信号传导域蛋白质的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域蛋白质相比,CD3ζ细胞内T细胞信号传导域蛋白质的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域蛋白质相比,CD3ζ细胞内T细胞信号传导域蛋白质的变体或突变体不包括缺失。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域蛋白质相比,CD3ζ细胞内T细胞信号传导域蛋白质的变体或突变体不包括插入。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域蛋白质相比,CD3ζ细胞内T细胞信号传导域蛋白质的变体或突变体包括作为保守取代的取代。在一些情况下,CD3ζ细胞内T细胞信号传导域包括由NCBI序列参考NP_000725.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。在一些情况下,CD3ζ细胞内T细胞信号传导域包括由NCBI序列参考NP_932170.1标识的蛋白质的全部或部分,或其同等型或天然存在的突变体或变体。上文标识了在NCBI序列参考下可获得的人CD3-zeta氨基酸序列的非限制性实例。在一些情况下,CD3ζ细胞内T细胞信号传导域由NCBI序列参考NM_000734.3标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,CD3ζ细胞内T细胞信号传导域由NCBI序列参考NM_198053.2标识的核酸序列的全部或部分,或其同等型或天然存在的突变体或变体编码。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域核酸序列相比,CD3ζ细胞内T细胞信号传导域核酸序列的变体或突变体包括不超过5、4、3、2或1个缺失。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域核酸序列相比,CD3ζ细胞内T细胞信号传导域核酸序列的变体或突变体包括不超过5、4、3、2或1个插入。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域核酸序列相比,CD3ζ细胞内T细胞信号传导域核酸序列的变体或突变体不包括缺失。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域核酸序列相比,CD3ζ细胞内T细胞信号传导域核酸序列的变体或突变体不包括插入。在一些情况下,与天然存在的CD3ζ细胞内T细胞信号传导域核酸序列相比,CD3ζ细胞内T细胞信号传导域核酸序列的变体或突变体包括作为保守取代的取代。
当提及蛋白质或肽时,短语“特异性地(或选择性地)与抗体结合”或“特异性地(或选择性地)与……免疫反应”是指通常在蛋白质和其他生物制剂的异质群体中决定蛋白质存在的结合反应。因此,在指定的免疫测定条件下,指定的抗体与特定蛋白质的结合至少是背景的两倍,且更通常是背景的超过10至100倍。在此类条件下与抗体的特异性结合通常需要根据其对特定蛋白质的特异性进行选择的抗体。例如,可以选择多克隆抗体以获得仅与所选抗原而不与其他蛋白质发生特异性免疫反应的抗体的亚组。该选择可以通过减去与其他分子交叉反应的抗体来实现。可以使用多种免疫测定形式来选择与特定蛋白质发生特异性免疫反应的抗体。例如,常规使用固相ELISA免疫测定来选择与蛋白质发生特异性免疫反应的抗体(关于可以用于确定特定免疫反应性的免疫测定形式和条件的描述,参见例如Harlow&Lane,Using Antibodies,A Laboratory Manual(1998))。
“配体”是指能够与受体结合的试剂,例如多肽或其他分子。
当涉及例如细胞、核酸、蛋白质或载体时,术语“重组”表示该细胞、核酸、蛋白质或载体已通过实验室方法修饰或作为实验室方法的结果。因此,例如,重组蛋白包括通过实验室方法产生的蛋白。重组蛋白可以包括在蛋白质的天然(非重组)形式中找不到的氨基酸残基,或者可以包括已经进行修饰例如经标记的氨基酸残基。
当用于指核酸的部分时,术语“异源”表示该核酸包含两个或更多个未在自然界中发现彼此为相同关系的亚序列。例如,核酸通常是重组产生的,具有来自不相关基因的两个或更多个序列,所述两个或更多个序列经排列以制备新的功能核酸,例如,来自一个来源的启动子和来自另一个来源的编码区。类似地,异源蛋白质表示该蛋白质包含两个或更多个在自然界中彼此之间没有相同关系的亚序列(例如,融合蛋白)。
如本文所用,“细胞”是指进行足以保留或复制其基因组DNA的代谢或其他功能的细胞。可以通过本领域众所周知的方法来鉴定细胞,包括例如完整膜的存在,通过特定染料的染色,产生子代的能力,或者在配子的情况下与第二配子结合以产生有活力的后代的能力。细胞可以包括原核和真核细胞。原核细胞包括但不限于细菌。真核细胞包括但不限于酵母细胞和源自植物和动物的细胞,例如哺乳动物(例如人)和昆虫(例如夜盗蛾)细胞。当细胞天然不贴壁或已经处理为不贴壁于表面(例如通过胰蛋白酶消化)时,可能有用。
如本文所使用的关于基因的词“表达”或“表达的”是指该基因的转录和/或翻译产物。DNA分子在细胞中的表达水平可以基于细胞内存在的相应mRNA的量或细胞产生的由所述DNA编码的蛋白质的量来确定。非编码核酸分子(例如,siRNA)的表达水平可以通过本领域公知的标准PCR或Northern印迹方法检测。参见,Sambrook et al.,1989MolecularCloning:A Laboratory Manual,18.1-18.88。
术语“质粒”、“载体”或“表达载体”是指编码基因和/或基因表达所必需的调控元件的核酸分子。来自质粒的基因表达可以顺式或反式发生。如果基因以顺式表达,则该基因和调控元件由同一质粒编码。反式表达是指基因和调控元件由单独的质粒编码的情况。
术语“转染”或“转导”可以互换使用,并且定义为将核酸分子或蛋白质引入细胞的过程。使用基于非病毒或病毒的方法将核酸引入细胞。核酸分子可以是编码完整蛋白质或其功能部分的基因序列。非病毒转染方法包括不使用病毒DNA或病毒颗粒作为将核酸分子引入细胞的递送系统的任何合适的转染方法。示例性的非病毒转染方法包括磷酸钙转染、脂质体转染、核转染、声波穿孔、通过热激转染、磁转染和电穿孔。在一些实施方案中,按照本领域众所周知的标准程序,使用电穿孔将核酸分子引入细胞。对于基于病毒的转染方法,在本文所述的方法中可以使用任何有用的病毒载体。病毒载体的实例包括但不限于逆转录病毒、腺病毒、慢病毒和腺相关病毒载体。在一些实施方案中,按照本领域众所周知的标准程序,使用逆转录病毒载体将核酸分子引入细胞。术语“转染”或“转导”还指从外部环境将蛋白质引入细胞。通常,蛋白质的转导或转染依赖于能够穿越细胞膜的肽或蛋白质与感兴趣的蛋白质的附接。参见例如,Ford et al.(2001)Gene Therapy 8:1-4和Prochiantz(2007)Nat.Methods 4:119-20。
转染的基因的表达可以在细胞中瞬时或稳定地发生。在“瞬时表达”过程中,转染的基因在细胞分裂期间不转移至子细胞。由于其表达仅限于转染的细胞,因此该基因的表达随时间而丢失。相反,当基因与另一种赋予转染细胞选择优势的基因共转染时,可以发生转染基因的稳定表达。此类选择优势可以是针对呈现至细胞的某种毒素的抗性。转染的基因的表达可以进一步通过转座子介导插入宿主基因组来完成。在转座子介导的插入过程中,该基因以可预测的方式位于两个转座子接头序列之间,从而允许插入宿主基因组以及随后的切除。通过用慢病毒载体感染细胞可以进一步实现转染基因的稳定表达,该慢病毒载体在感染后形成细胞基因组的一部分(整合到其中),从而导致基因的稳定表达。
“接触”是按照其普遍的普通含义使用的,并且是指使至少两种不同的种类(例如,包括生物分子或细胞的化学化合物)变得足够近以反应、相互作用或物理触碰的过程。应当理解,所得反应产物可以直接由添加的试剂之间的反应产生,或者由一种或多种可以在反应混合物中产生的添加的试剂的中间体产生。
术语“接触”可以包括允许两个种类反应、相互作用或物理触碰,其中所述两个种类可以是例如,如本文所述的肽化合物和抗原结合位点。
术语“调节”或“调节物”是根据其普遍的普通含义使用的,并且指改变或转变一种或多种特性的动作。“调节物”是指增加或降低靶分子的水平或靶分子的功能或分子的靶标的物理状态的组合物。“调节”是指改变或转变一种或多种特性的过程。例如,当应用于调节物对生物靶标的作用时,调节是指通过增加或降低生物靶标的性质或功能或生物靶标的量来改变。
如本文所定义,关于蛋白质-抑制剂(例如拮抗剂)相互作用的术语“抑制”等意指相对于不存在抑制剂情况下蛋白质的活性或功能,负面影响(例如降低)蛋白质的活性或功能。在一些情况下,抑制是指疾病或疾病症状的减轻。因此,在一些情况下,抑制至少部分包括部分或全部阻断刺激,降低,防止或延迟激活,或失活,脱敏或下调信号转导或酶活性或蛋白质的量。在一些情况下,与不存在拮抗剂情况下的对照相比,抑制的量可以是10%、20%、30%、40%、50%、60%、70%、80%、90%、100%或更少。在一些情况下,抑制比不存在拮抗剂情况下的表达或活性多1.5倍、2倍、3倍、4倍、5倍、10倍或更多。
取决于上下文,涉及蛋白质-激活剂(例如激动剂)相互作用的术语“激活”等意指相对于不存在激活剂(例如本文所述的组合物)情况下蛋白质的活性或功能,正面影响(例如增加)蛋白质的活性或功能。因此,在一些情况下,激活至少部分包括部分或全部增加刺激,增加或启用激活,或激活,敏化或上调信号转导或酶活性或疾病中蛋白质减少的量。与不存在激动剂情况下的对照相比,激活的量可以是10%、20%、30%、40%、50%、60%、70%、80%、90%、100%或更多。在一些情况下,激活比不存在激动剂情况下的表达或活性多1.5倍、2倍、3倍、4倍、5倍、10倍或更多。
如本文所用,术语“异常”是指与正常不同。当用于描述酶活性时,异常是指大于或小于正常对照或正常未患病对照样品的平均值的活性。异常活性可以指导致疾病的活性的量,其中使异常活性恢复到正常或非疾病相关的量(例如,通过使用本文所述的方法),导致疾病或一种或多种疾病症状的减轻。
取决于上下文,术语“生物样品”或“样品”是指获得自或衍生自受试者或患者的材料。在一些情况下,生物样品包括组织切片,如活检和尸检样品,以及用于组织学目的的冷冻切片。样品的非限制性实例包括体液,如血液和血液级分或产物(例如,血清、血浆、血小板、红细胞等),痰,组织,培养的细胞(例如,原代培养物、外植体和转化的细胞),粪便,尿液,滑液,关节组织,滑膜组织,滑膜细胞,成纤维细胞样滑膜细胞,巨噬细胞样滑膜细胞,免疫细胞,造血细胞,成纤维细胞,巨噬细胞,T细胞等。生物样品通常获得自真核生物体,如哺乳动物,如灵长类动物,例如黑猩猩或人类;奶牛;狗;猫;啮齿动物,例如豚鼠,大鼠,小鼠;兔;或鸟;爬行动物;或鱼。在一些情况下,与对照相比,来自受试者的生物样品(例如,如血液)具有异常的CD6表达和/或功能。在一些情况下,来自受试者的生物样品(例如,如血液)具有异常的免疫细胞活性或生长(例如异常数量的CD6+免疫细胞或具有异常活性的CD6+细胞)。
“对照”样品或值是指用作参照物的样品,通常是已知的参照物,用于与测试样品进行比较。例如,可以从测试条件下,例如在存在测试化合物的情况下获取测试样品,并与已知条件下的样品进行比较,例如在不存在测试化合物的情况下(阴性对照)或在存在已知化合物的情况下(阳性对照)。对照也可以代表从多个测试或结果中收集的平均值。本领域技术人员将认识到,可以将对照设计为用于评估任意数量的参数。例如,可以设计对照以基于药理学数据(例如,半衰期)或治疗措施(例如,副作用的比较)来比较治疗益处。本领域技术人员将理解在给定情况下哪些对照是有价值的,并且能够基于与对照值的比较来分析数据。对照对于确定数据的显著性也很有价值。例如,如果给定参数的值在对照中变化很大,则测试样品中的变化将不认为是显著的。
“患者”或“有此需要的受试者”是指患有或可能患有所示病症的动物界的活体成员。在一些情况下,受试者是包括自然患有疾病的个体的物种的成员。在一些情况下,受试者是患有或易于患疾病或病状的活生物体,其可以通过施用本文提供的组合物或药物组合物来治疗。非限制性实例包括人,其他哺乳动物,牛,大鼠,小鼠,狗,猴,山羊,绵羊,奶牛,鹿和其他非哺乳动物动物。在一些实施方案中,患者是人。
术语“疾病”或“病状”是指能够用本文提供的化合物、药物组合物或方法治疗的患者或受试者的状态或健康状况。在一些情况下,疾病是自身免疫疾病(例如,I型糖尿病,移植物抗宿主病)。在一些情况下,
如本文所用,“自身免疫疾病”是指由受试者的免疫系统例如针对通常存在于受试者体内的物质组织和/或细胞的免疫反应改变而引起的疾病或病症。自身免疫疾病包括但不限于关节炎,类风湿性关节炎,银屑病关节炎,幼年特发性关节炎,硬皮病,系统性硬皮病,多发性硬化症,系统性红斑狼疮(SLE),重症肌无力,青少年型糖尿病,1型糖尿病,格林-巴利综合征,桥本脑炎,桥本甲状腺炎,强直性脊柱炎,银屑病,干燥综合征,血管炎,肾小球肾炎,自身免疫性甲状腺炎,白塞氏病,克罗恩病,溃疡性结肠炎,大疱性类天疱疮,结节病,银屑病,鱼鳞病,格雷夫斯眼病,炎性肠病,艾迪生氏病,白癜风,哮喘,移植物抗宿主病和过敏性哮喘。
如本文所用,“炎性疾病”是指与异常或改变的炎症相关的疾病或病症。炎症是作为对病原体、受损细胞或组织或刺激物的响应而作为愈合过程的一部分由免疫系统引发的生物响应。慢性炎症可以导致多种疾病。炎性疾病包括但不限于动脉粥样硬化,过敏,哮喘,类风湿性关节炎,移植排斥,乳糜泻,慢性前列腺炎,炎性肠病,盆腔炎和炎性肌病。
在与疾病(例如自身免疫疾病)相关的物质或物质活性或功能的上下文中,术语“相关”或“与……相关”是指该疾病(全部或部分)是由物质或物质活性或功能引起的,或者疾病症状(全部或部分)是由物质或物质活性或功能引起的。
术语“治疗”是指成功治疗或减轻伤害,疾病,病理或病状的任何标志,包括任何客观或主观参数,如消减;缓解;减轻症状或使患者更耐受伤害,病理或病状;变性或下降的速度减慢;使变性的最终点衰弱减少;改善患者的身心健康。症状的治疗或缓解可以基于客观或主观参数;包括身体检查、神经精神病学检查和/或精神病学评估的结果。术语“治疗”及其词形变化包括预防伤害,病理,病状或疾病。在一些情况下,“治疗”是指自身免疫疾病的治疗。
“有效量”是相对于不存在化合物足以使化合物实现所述目的的量(例如,达到其所施用的效果,治疗疾病,降低酶活性,增加酶活性,减少信号传导途径,或减少一种或多种疾病或病状的症状)。“治疗有效量”的实例是足以有助于治疗,预防或减轻疾病的一种或多种症状的量,其也可以称为“治疗有效量”。一种或多种症状的“减轻”(和该短语的语法等同形式)是指降低症状的严重程度或频率,或消除症状。确切的量将取决于治疗的目的,并且将可由本领域技术人员使用已知技术确定(参见例如,Lieberman,Pharmaceutical DosageForms(vols.1-3,1992);Lloyd,The Art,Science and Technology of PharmaceuticalCompounding(1999);Pickar,Dosage Calculations(1999);和Remington:The Scienceand Practice of Pharmacy,20th Edition,2003,Gennaro,Ed.,Lippincott,Williams&Wilkins)。
“药学上可接受的赋形剂”和“药学上可接受的载体”是指有助于向受试者施用活性剂并有助于受试者吸收的物质,并且可以被包括在本发明的组合物中而不对患者造成明显的不良毒理作用。药学上可接受的赋形剂的非限制性实例包括水,NaCl,生理盐水溶液,乳酸林格氏液,正常蔗糖,正常葡萄糖,粘合剂,填充剂,崩解剂,润滑剂,包衣,甜味剂,调味剂,盐溶液(如林格氏溶液),醇,油,明胶,碳水化合物(如乳糖,直链淀粉或淀粉),脂肪酸酯,羟甲基纤维素,聚乙烯吡咯烷和色素等。可以对此类制剂进行灭菌,并且如果需要,可以与助剂混合,所述助剂如润滑剂,防腐剂,稳定剂,湿润剂,乳化剂,影响渗透压的盐,缓冲剂,着色剂和/或芳香族物质等,其不与本发明的化合物有害地反应。本领域技术人员将认识到其他药物赋形剂可用于本发明。
术语“制剂”旨在包括具有包封材料作为载体的活性化合物的配制剂,其提供了胶囊,其中具有或不具有其他载体的活性成分被载体包围,因此载体与其相关联。类似地,包括扁囊剂和锭剂。片剂,粉末剂,胶囊剂,丸剂,扁囊剂和锭剂可以用作适合口服施用的固体剂型。
在一些情况下,术语“施用”包括对受试者口服施用,作为栓剂施用,局部接触,静脉内,肠胃外,腹膜内,肌内,病灶内,鞘内,鼻内或皮下施用,或植入缓释装置例如微型渗透泵。在一些情况下,可以通过任何途径施用,包括肠胃外和经粘膜的(例如颊,舌下,颚,牙龈,鼻,阴道,直肠或经皮)。肠胃外施用包括例如静脉内,肌内,小动脉内,皮内,皮下,腹膜内,心室内和颅内。其他递送方式包括但不限于使用脂质体配制剂,静脉内输注,透皮贴剂等。
药物组合物可以包括下述组合物,其中以治疗有效量,即有效达到其预期目的的量包含活性成分(例如,本文所述的化合物,包括实施方案或实施例)。对于特定应用有效的实际量将尤其取决于所治疗的病状。当以治疗疾病的方法施用时,此类组合物将包含一定量的有效成分,该活性成分有效地实现期望的结果,例如,调节靶分子的活性,和/或减少、消除或减慢疾病症状的进展。
重组蛋白和CAR T细胞
一方面,本文提供重组蛋白,其包括由本文提供的分离的核酸表达的蛋白质,包括其实施方案。因此,一方面提供了重组蛋白,如嵌合抗原受体(CAR),其包括靶向CD6的单链可变片段(scFv)和跨膜域。一方面,本文提供了不具有跨膜域的靶向CD6的scFv。一方面,本文提供了经工程化以表达CAR的细胞(例如,细胞群体,如免疫效应细胞群体),其中CAR包含抗原结合域和跨膜域。在一些情况下,抗原结合域包含靶向CD6的抗体片段或变体。在一些情况下,抗原结合域是靶向CD6的单链可变片段(scFv)。在一些情况下,CAR进一步包含细胞内信号传导域。在一些情况下,表达CAR的细胞是T淋巴细胞(CAR T细胞)或NK细胞。在一些情况下,表达CAR的细胞是T淋巴细胞(CAR T细胞)或NK细胞。在一些情况下,细胞是CD4+T细胞或CD8+T细胞。在一些情况下,T细胞是调节性T细胞(Treg)。
在一些情况下,抗原结合域可以包含单克隆抗体的CDR、单克隆抗体的可变区和/或其抗原结合片段。在一些情况下,片段可以是抗原特异性抗体的任何数量的不同抗原结合域。在一些情况下,抗原结合域包含抗CD6抗体的CD6结合片段。在一些情况下,抗原结合域包含抗CD6抗体的CDR。在一些情况下,抗原结合域包含抗CD6抗体的VH和VL链。在一些情况下,抗原结合域包含scFv,其包含抗CD6抗体的CDR。在一些情况下,抗原结合域包含scFv,其包含抗CD6抗体的VH和VL链。在一些情况下,抗CD6抗体是单克隆抗体。在一些情况下,单克隆抗体是人或人源化单克隆抗体。在一些情况下,单克隆抗体是伊利组单抗。在一些情况下,片段是由针对人密码子使用而优化以在人细胞中表达的序列编码的抗原特异性scFv。在一些情况下,单克隆抗体是嵌合单克隆抗体。在一些情况下,单克隆抗体是伊利组单抗。在一些情况下,单克隆抗体是Tl2.l。在一些情况下,单克隆抗体是UMCD6。在一些情况下,单克隆抗体是MEM98。在一些情况下,单克隆抗体是MT605。在一些情况下,单克隆抗体是Gangemi et al.(1989)J Immunol 143(8):2439-47或美国专利号6,572,857中所述的抗体,其每一个的全部内容通过引用并入本文。在一些情况下,片段是由针对人密码子使用而优化以在人细胞中表达的序列编码的抗原特异性scFv。在一些情况下,抗原结合域包括以下VH序列或其变体:EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS(SEQ ID NO:35)。在一些情况下,抗原结合域包括以下VL序列或其变体:DIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA(SEQ ID NO:34)。在一些情况下,抗原结合域包括以下VH序列或其变体:EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQTPEKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTTLTVSS(SEQ ID NO:68)。在一些情况下,抗原结合域包括以下VL序列或其变体:DIKMTQSPSSMYASLGERVTITCKASRDIRSYLTWYQQKPWKSPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA(SEQ ID NO:69)。在一些情况下,VL包括以下序列或其变体:IQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQ(SEQ ID NO:75)。在一些情况下,VL包括以下序列或其变体:DIQMTQSPSSLSASVGDRVTITCKASRDIRSY(SEQ ID NO:76)。在一些情况下,VL包括以下序列或其变体:LTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFT(SEQ ID NO:77)。在一些情况下,VL包括以下序列或其变体:FGSGTKLEIKRA(SEQ ID NO:78)。在一些情况下,VH包括以下序列或其变体:EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMS(SEQ ID NO:79)。在一些情况下,VH包括以下序列或其变体:WVRQAPGKRLEWVATISSGG(SEQ ID NO:80)。在一些情况下,VH包括以下序列或其变体:SYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDS(SEQ ID NO:81)。在一些情况下,VH包括以下序列或其变体:WGQGTLVTVSS(SEQ ID NO:82)。在一些情况下,本文提供的VH或VL序列的变体与该序列相比具有5、4、3、2、1或0个缺失。在一些情况下,本文提供的VH或VL序列的变体与该序列相比具有5、4、3、2、1或0个插入。在一些情况下,本文提供的VH或VL序列的变体与该序列相比具有5、4、3、2、1或0个取代。在实施方案中,本文提供的VH或VL序列的变体与该序列相比具有10、9、8、7、6、5、4、3、2或1个取代。在一些情况下,一个或多个或所有取代是保守取代。
表1.抗原结合域以及轻链和重链可变区的示例性序列。
在一些情况下,该排列可以是多聚体的,如双抗体(diabody)或多聚体。在一些情况下,最有可能通过将轻链和重链的可变部分交叉配对成所谓的双抗体来形成多聚体。在一些情况下,构建体的铰链部分可以具有多种备选方案,从完全缺失,到维持第一半胱氨酸,到脯氨酸而不是丝氨酸取代,到被截短至第一半胱氨酸。在一些情况下,可以缺失Fc部分。在一些情况下,任何稳定和/或二聚化的蛋白质都可以达到这一目的。在一些情况下,CAR包含Fc域之一,例如来自人免疫球蛋白的CH2或CH3域。在一些情况下,CAR使用已被修饰以改善二聚化的人免疫球蛋白的铰链、CH2和CH3区。在一些情况下,仅使用免疫球蛋白的铰链部分。在一些情况下,当抗原结合域表达时,其包含指导CAR表达至细胞膜的信号肽。在一些情况下,当信号肽在细胞表面上时,其在CAR中不存在。在一些情况下,信号肽与来自具有抗原结合域的CDR的抗体的信号肽相同或不同。
在一些情况下,抗原结合域(例如,作为CAR的一部分的scFv)对CD6具有相对低的亲和力(K
在一些情况下,scFv可以被设计为具有特定的定向(例如,从N端至C端的V
在一些情况下,scFv的V
在一些情况下,本文提供的重组蛋白,包括其实施方案,可以进一步包括CAR的另外的组分。还包括包含此类另外的组分的CAR和表达此类CAR的细胞。
在一些情况下,本文提供的重组蛋白(如CAR)(例如在细胞表面上分离或表达),包括其实施方案,可以进一步包括如本文所述的跨膜域,包括其实施方案,如本文所述的铰链区,包括其实施方案,如本文所述的细胞内信号传导域(如T细胞信号传导域),包括其实施方案,和/或如本文所述的共刺激域,包括其实施方案。
在一些情况下,本文提供的scFv可以直接连接(例如,共价结合)至跨膜域,或者可以通过铰链区连接(例如,共价结合)至跨膜域。
如本文所提供的“铰链区”是将抗原结合位点域(即,scFv)连接至跨膜域的多肽。本文考虑了能够将scFv连接至跨膜域的任何铰链区。在一些情况下,铰链区是多肽铰链区。在一些情况下,多肽铰链区是柔性铰链区。在一些情况下,铰链区包括甘氨酸和/或丝氨酸残基。在一些情况下,铰链区是或包括抗体铰链区或其一部分。在一些情况下,铰链区包括抗体Fc域或其一部分(例如,包含铰链区的部分)。本文考虑的合适铰链区的非限制性实例包括IgG Fc、人IgG Fc、人IgG1 Fc、IgG4 Fc和人IgG4 Fc,或其一部分(即,其包括铰链区的一部分)。在一些情况下,铰链区是IgG Fc或其一部分。在一些情况下,铰链区是人IgG Fc或其一部分。在一些情况下,铰链区是IgG1 Fc或其一部分。在一些情况下,铰链区是人IgG1Fc或其一部分。在一些情况下,铰链区是IgG4 Fc或其一部分。在一些情况下,铰链区是人IgG4 Fc或其一部分。在一些情况下,使用IgG Fc铰链将结合位点域连接至CAR主链。在一些情况下,IgG1或IgG4人Fc或其包含铰链区的部分包括减少或防止与相应Fc受体结合的一个或多个突变。在一些情况下,IgG1或IgG4人Fc或其包含铰链区的部分不包括减少或防止与相应Fc受体结合的突变。在一些情况下,Fc域的一部分的长度可以是229个氨基酸、129个氨基酸或更少。
在一些情况下,铰链区的长度为约229个氨基酸。在一些情况下,铰链区的长度为229个氨基酸。在一些情况下,铰链区的长度为约129个氨基酸。在一些情况下,铰链区的长度为129个氨基酸。在一些情况下,铰链区的长度为约129至约229个氨基酸之间。在一些情况下,铰链区的长度小于约229个氨基酸。在一些情况下,铰链区的长度小于229个氨基酸。在一些情况下,铰链区的长度小于约129个氨基酸。在一些情况下,铰链区的长度小于129个氨基酸。在一些情况下,铰链区的长度为至少22个氨基酸。在一些情况下,铰链区的长度为22个氨基酸。在一些情况下,铰链区的长度为约25、50、75、100、125、150、175、200、225或250个氨基酸。在一些情况下,铰链区的长度为约25个氨基酸。在一些情况下,铰链区的长度为约50个氨基酸。在一些情况下,铰链区的长度为约75个氨基酸。在一些情况下,铰链区的长度为约100个氨基酸。在一些情况下,铰链区的长度为约125个氨基酸。在一些情况下,铰链区的长度为约150个氨基酸。在一些情况下,铰链区的长度为约175个氨基酸。在一些情况下,铰链区的长度为约200个氨基酸。在一些情况下,铰链区的长度为约225个氨基酸。在一些情况下,铰链区的长度为约250个氨基酸。在一些情况下,铰链区的长度为25个氨基酸。在一些情况下,铰链区的长度为50个氨基酸。在一些情况下,铰链区的长度为75个氨基酸。在一些情况下,铰链区的长度为100个氨基酸。在一些情况下,铰链区的长度为125个氨基酸。在一些情况下,铰链区的长度为150个氨基酸。在一些情况下,铰链区的长度为175个氨基酸。在一些情况下,铰链区的长度为200个氨基酸。在一些情况下,铰链区的长度为225个氨基酸。在一些情况下,铰链区的长度为250个氨基酸。
在一些情况下,铰链区的长度为约22至约250个氨基酸之间。在一些情况下,铰链区的长度为约25至约250个氨基酸之间。在一些情况下,铰链区的长度为约50至约250个氨基酸之间。在一些情况下,铰链区的长度为约75至约250个氨基酸之间。在一些情况下,铰链区的长度为约100至约250个氨基酸之间。在一些情况下,铰链区的长度为约125至约250个氨基酸之间。在一些情况下,铰链区的长度为约150至约250个氨基酸之间。在一些情况下,铰链区的长度为约175至约250个氨基酸之间。在一些情况下,铰链区的长度为约200至约250个氨基酸之间。在一些情况下,铰链区的长度为约225至约250个氨基酸之间。在一些情况下,铰链区的长度为约22至约225个氨基酸之间。在一些情况下,铰链区的长度为约22至约200个氨基酸之间。在一些情况下,铰链区的长度为约22至约175个氨基酸之间。在一些情况下,铰链区的长度为约22至约150个氨基酸之间。在一些情况下,铰链区的长度为约22至约125个氨基酸之间。在一些情况下,铰链区的长度为约22至约100个氨基酸之间。在一些情况下,铰链区的长度为约22至约75个氨基酸之间。在一些情况下,铰链区的长度为约22至约50个氨基酸之间。在一些情况下,铰链区的长度为约22至约25个氨基酸之间。
在一些情况下,铰链区包括Fc域。在一些情况下,铰链区包括IgG Fc域。在一些情况下,铰链区是IgG1 Fc或其片段。在一些情况下,铰链区是人IgG1Fc或其片段。在一些情况下,铰链区是IgG4 Fc或其片段。在一些情况下,铰链区是人IgG4 Fc或其片段。
在一些情况下,铰链区可以是突变的铰链区。在一些情况下,突变的铰链区(例如,Fc)可以用于例如防止Fc与其同源Fc受体结合。在一些情况下,铰链区(例如,IgG、人IgGFc、IgG1 Fc、人IgG1 Fc、IgG4 Fc、人IgG4 Fc)包括不超过5、4、3、2或1个缺失。在一些情况下,铰链区(例如,IgG、人IgG Fc、IgG1 Fc、人IgG1 Fc、IgG4 Fc、人IgG4 Fc)包括不超过5、4、3、2或1个插入。在一些情况下,铰链区(例如,IgG、人IgG Fc、IgG1 Fc、人IgG1 Fc、IgG4Fc、人IgG4 Fc)不包括缺失。在一些情况下,铰链区(例如,IgG、人IgG Fc、IgG1 Fc、人IgG1Fc、IgG4 Fc、人IgG4 Fc)不包括插入。在一些情况下,铰链区(例如,IgG、人IgG Fc、IgG1Fc、人IgG1 Fc、IgG4 Fc、人IgG4 Fc)包括作为保守取代的取代。
在一些情况下,如本文提供的跨膜域是指形成生物膜的一部分(例如,跨越生物膜)的多肽。在一些情况下,本文提供的跨膜域能够从膜的一侧通过至膜的另一侧跨越生物膜(例如,细胞膜)。在一些情况下,跨膜域仅跨越膜的一部分,但是足以将抗原结合域锚定至膜。在一些情况下,跨膜域从细胞膜的细胞内侧跨越至细胞外侧。在一些情况下,跨膜域可以包括非极性疏水残基,其将本文提供的蛋白质(包括其实施方案)锚定在生物膜(例如,T细胞的细胞膜)中。考虑了能够锚定本文提供的蛋白质的任何跨膜域,包括其实施方案。跨膜域的非限制性实例包括CD28、CD8、CD4或CD3-zeta(CD3ζ)的跨膜域。
在一些情况下,跨膜域包括CD4跨膜域或其变体、CD8跨膜域或其变体、CD28跨膜域或其变体或CD3ζ跨膜域或其变体。在一些情况下,重组蛋白如CAR(例如表达CAR的细胞)包含细胞内共刺激域和/或细胞内T细胞信号传导域。
在一些情况下,跨膜域包括CD4跨膜域或其变体。在一些情况下,跨膜域包括CD8跨膜域或其变体。在一些情况下,跨膜域包括CD28跨膜域或其变体。在一些情况下,跨膜域包括CD3ζ跨膜域或其变体。
在一些情况下,跨膜域与scFv的重链可变区共价结合。在一些情况下,跨膜域与scFv的轻链可变区共价结合。在一些情况下,跨膜域通过铰链区与scFv的重链可变区共价结合。在一些情况下,跨膜域通过铰链区与scFv的轻链可变区共价结合。在一些情况下,本文提供的重组蛋白(如CAR,例如在细胞表面上)从N末端至C末端包含V
在一些情况下,抗原结合域(例如,scFv)包括伊利组单抗的CDR序列。在一些情况下,CDR包括由SEQ ID NO:28、29、30、31、32和33所示的氨基酸序列。在一些情况下,CDR是由SEQ ID NO:28、29、30、31、32和33所示的氨基酸序列。在一些情况下,CDR特异性结合CD6。在一些情况下,CDR以约1×10
如本文提供的“细胞内共刺激信号传导域”、“共刺激信号传导域”或“细胞内共刺激域”包括能够响应于抗原与本文提供的重组蛋白(例如CAR)的抗原结合域(包括其实施方案)的结合而提供共刺激信号传导的氨基酸序列。在一些情况下,共刺激性信号传导域的信号传导导致细胞因子的产生和表达重组蛋白(例如,CAR)的细胞(例如,T细胞)的增殖。
在一些情况下,共刺激域是CD28细胞内共刺激域或其变体、4-1BB细胞内共刺激域或其变体、ICOS细胞内共刺激信号传导域或其变体、OX-40细胞内共刺激信号传导域或其变体、CTLA-4细胞内共刺激域或其变体、PD-1细胞内共刺激域或其变体或GITR共刺激域或其变体。在一些情况下,共刺激域是CD28细胞内共刺激域(SEQ ID NO:7或8)或其变体。在一些情况下,是4-1BB细胞内共刺激域(SEQ ID NO:14)或其变体。在一些情况下,共刺激域是ICOS细胞内共刺激信号传导域或其变体。在一些情况下,共刺激域是OX-40细胞内共刺激信号传导域或其变体。在一些情况下,共刺激域是CTLA-4细胞内共刺激域(SEQ ID NO:17)或其变体。在一些情况下,共刺激域是PD-1细胞内共刺激域或其变体。在一些情况下,共刺激域是GITR共刺激域或其变体。
在一些情况下,本文提供的重组蛋白(如CAR,例如在细胞表面上)从N末端至C末端包含V
如本文提供的“细胞内T细胞信号传导域”包括能够响应于抗原与本文提供的重组蛋白(例如CAR)的抗原结合域(包括其实施方案)的结合而提供初级信号传导的氨基酸序列,包括其实施方案。在一些情况下,细胞内T细胞信号传导域的信号传导导致表达其的T细胞的活化。在一些情况下,细胞内T细胞信号传导域的信号传导导致表达重组蛋白(例如,CAR)的细胞(例如,T细胞)的增殖(细胞分裂)。在一些情况下,细胞内T细胞信号传导域的信号传导导致T细胞表达本领域已知的活化的T细胞特征性的蛋白质(例如CTLA-4、PD-1、CD28、CD69)。
在一些情况下,细胞内T细胞信号传导域是CD3ζ细胞内T细胞信号传导域。
在一些情况下,本文提供的重组蛋白(如CAR,例如在细胞表面上)从N末端至C末端包含V
在一些情况下,T淋巴细胞是调节性T淋巴细胞(Treg)。效应T细胞的类别很广,其包括主动响应刺激(如共刺激)的各种T细胞类型。效应T细胞包括辅助、杀伤、调节和潜在的其他T细胞类型。调节性T细胞(以前称为抑制性T细胞)是调节免疫系统,维持自身抗原耐受性和预防自身免疫疾病的T细胞亚群。Treg具有免疫抑制作用,并通常抑制或下调效应T细胞的诱导和增殖。在一些情况下,效应T淋巴细胞是辅助性T细胞。在一些情况下,效应T淋巴细胞是杀伤T细胞。在一些情况下,效应T淋巴细胞是Treg。
在一些情况下,Treg是包括CD4阳性-CD25高表达的Treg。在一些情况下,Treg是包括CD4阳性-CD25高-CD127低或阴性表达的Treg。在一些情况下,Treg是包括CD4阳性-CD25高-CD6低或阴性表达的Treg。在一些情况下,Treg是包括CD4阳性-CD25高-CD127低或阴性-CD6低或阴性表达的Treg。在一些情况下,Treg是包括CD3阳性-CD6低或阴性表达的Treg。在一些情况下,Treg是包括CD4阳性-CD6低或阴性表达的Treg。在一些情况下,Treg是包括CD8阳性-CD28低表达的Treg。在一些情况下,Treg是包括CD45RA+表达的Treg。在一些情况下,Treg是不包括CD45RA+表达的Treg。在一些情况下,Treg是包括FOXP3去甲基化的Treg。在一些情况下,Treg是不包括FOXP3去甲基化的Treg。在一些情况下,Treg是可以用任一IL-2和/或雷帕霉素和/或视黄酸扩充的Treg。在一些情况下,Treg是可以用IL-2和/或雷帕霉素和/或视黄酸扩充的Treg。在一些情况下,Treg是可以用IL-2扩充的Treg。在一些情况下,Treg是可以用雷帕霉素扩充的Treg。在一些情况下,Treg是可以用视黄酸扩充的Treg。
确定“高”和“低”表达在本领域中是众所周知的。例如,如上提及的标志物的高和低表达的描述以及如何确定并定量高和低表达可见于Putnam,A.L.,T.M.Brusko,M.R.Lee,W.Liu,G.L.Szot,T.Ghosh,M.A.Atkinson and J.A.Bluestone.Expansion of humanregulatory T-cells from patients with type 1diabetes.Diabetes 58(3):652-662,2009;Bluestone JA,Buckner JH,Fitch M,Gitelman SE,Gupta S,Hellerstein MK,Herold KC,Lares A,Lee MR,Li K,Liu W,Long SA,Masiello LM,Nguyen V,Putnam AL,Rieck M,Sayre PH,Tang Q.Type 1diabetes immunotherapy using polyclonalregulatory T cells.Sci Transl Med.2015Nov 25;7(315):315ra189;Fuchs,A.,M.Gliwinski,N.Grageda,R.Spiering,A.K.Abbas,S.Appel,R.Bacchetta,M.Battaglia,D.Berglund,B.Blazar,J.A.Bluestone,M.Bornhauser,A.Ten Brinke,T.M.Brusko,N.Cools,M.C.Cuturi,E.Geissler,N.Giannoukakis,K.Golab,D.A.Hafler,S.M.van Ham,J.Hester,K.Hippen,M.Di Ianni,N.Ilic,J.Isaacs,F.Issa,D.Iwaszkiewicz-Grzes,E.Jaeckel,I.Joosten,D.Klatzmann,H.Koenen,C.van Kooten,O.Korsgren,K.Kretschmer,M.Levings,N.M.Marek-Trzonkowska,M.Martinez-Llordella,D.Miljkovic,K.H.G.Mills,J.P.Miranda,C.A.Piccirillo,A.L.Putnam,T.Ritter,M.G.Roncarolo,S.Sakaguchi,S.Sanchez-Ramon,B.Sawitzki,L.Sofronic-Milosavljevic,M.Sykes,Q.Tang,M.Vives-Pi,H.Waldmann,P.Witkowski,K.J.Wood,S.Gregori,C.M.U.Hilkens,G.Lombardi,P.Lord,E.M.Martinez-Caceres andP.Trzonkowski.Minimum Information about T Regulatory Cells:A Step towardReproducibility and Standardization.Front Immunol 8:1844,2017;Duggleby,R.,R.D.Danby,J.A.Madrigal and A.Saudemont.Clinical Grade Regulatory CD4(+)TCells(Tregs):Moving Toward Cellular-Based Immunomodulatory Therapies.FrontImmunol 9:252,2018中;其每一篇的全部内容以其整体并出于所有目的通过引用并入本文。
在一些情况下,scFv(例如,CAR的scFv)包括由SEQ ID NO:34所示的轻链可变区。在一些情况下,scFv包括由SEQ ID NO:35所示的重链可变区。在一些情况下,scFv包括由SEQ ID NO:38所示的序列。在一些情况下,scFv包括由SEQ ID NO:39所示的序列。
在一些情况下,scFv(例如,CAR的scFv)定向为在N端具有轻链可变区,随后是重链可变区。或者,在一些情况下,scFv定向为在N端具有重链可变区,随后是轻链可变区。
在一些情况下,scFv的轻链可变区(VL)和重链可变区(VH)通过接头分开。在一些情况下,接头包含由SEQ ID NO:36所示的序列。在一些情况下,接头包含由SEQ ID NO:37所示的序列。
在一些情况下,scFv氨基酸序列包括由SEQ ID NO:38所示的序列。在一些情况下,scFv氨基酸序列包括由SEQ ID NO:39所示的序列。在一些情况下,scFv氨基酸序列包括由SEQ ID NO:40所示的序列。在一些情况下,scFv氨基酸序列包括由SEQ ID NO:41所示的序列。
在一些情况下,轻链可变区通过铰链区共价结合至跨膜区。在一些情况下,重链可变区通过铰链区共价结合至跨膜区。
在一些情况下,铰链区是人IgG Fc。在一些情况下,人IgG Fc是人IgG 4Fc。在一些情况下,人IgG Fc是人IgG 1Fc。
在一些情况下,共刺激域是CD28细胞内共刺激域或其变体、4-1BB细胞内共刺激域或其变体、ICOS细胞内共刺激信号传导域或其变体、OX-40细胞内共刺激信号传导域或其变体、CTLA-4细胞内共刺激信号传导域或其变体、PD-1细胞内共刺激信号传导域或其变体或GITR细胞内共刺激信号传导域或其变体。
在一些情况下,细胞内T细胞信号传导域是CD3ζ细胞内T细胞信号传导域。
在一些情况下,scFv包含由SEQ ID NO:28、29、30、31、32和33所示的CDR序列。
在一方面,提供了T淋巴细胞,其包括本文所述的重组蛋白,包括其实施方案。在一些情况下,T淋巴细胞是如本文所述的调节性T淋巴细胞(Treg),包括其实施方案。可以使用本领域众所周知的方法产生CAR T细胞。例如,可以用编码CAR的核酸转导从受试者(例如患者)或供体(例如健康受试者)分离的T淋巴细胞。编码CAR的核酸的引入可以通过如上文所述的病毒或非病毒方法来完成。应当理解,可以使用本领域熟知的基因编辑技术(例如CRISPR)对从供体获得的T淋巴细胞(即同种异体T淋巴细胞)进行基因编辑,以消除免疫原性蛋白质(例如天然T细胞受体)。转导后,可以使用例如人工抗原呈递细胞(APC;例如工程细胞系或抗体包被的磁珠)来活化T淋巴细胞。一旦被活化,可以通过用例如细胞因子的特定混合物处理来诱导T淋巴细胞发展成专门的T细胞亚型(例如T调节细胞)。最后,可以使用本领域众所周知的技术扩充CAR T细胞群体。
在一些情况下,包括本文所述的重组蛋白(包括其实施方案)的T淋巴细胞是自体T淋巴细胞(即,取自受试者)。在一些情况下,包括本文所述的重组蛋白(包括其实施方案)的T淋巴细胞是同种异体T淋巴细胞(即,不是从受试者获得的T淋巴细胞)。在一些情况下,同种异体T淋巴细胞已经过基因编辑。在一些情况下,对同种异体T淋巴细胞进行基因编辑,以消除天然T细胞受体蛋白的表达。
在一方面,提供了编码包括靶向CD6的单链可变片段(scFv)和跨膜域的蛋白质(例如,CAR)的分离的核酸。
在一方面,提供了包括如本文提供的核酸(例如,分离的核酸)(包括其实施方案)的载体。在一些情况下,载体是包含分离的核酸并且可以用于将分离的核酸递送至细胞内部的物质的组合物。许多载体是本领域已知的,包括但不限于线性多核苷酸、与离子或两亲性化合物相关的多核苷酸、质粒和病毒。在一些情况下,载体是自主复制质粒或病毒。在一些情况下,使用促进核酸转移到细胞中的化合物,如例如聚赖氨酸化合物、脂质体等。病毒转移载体的实例包括但不限于腺病毒载体、腺相关病毒载体、逆转录病毒载体、慢病毒载体等。在一些情况下,载体是质粒。在一些情况下,载体是染色体外的。在一些情况下,载体整合到细胞的基因组中。在一些情况下,载体是病毒载体。在一些情况下,病毒是慢病毒或致癌逆转录病毒。在一些情况下,病毒是慢病毒。在一些情况下,病毒是致癌逆转录病毒。考虑了用于将包括本文提供的核酸(例如,分离的核酸)的载体递送至细胞的任何合适的病毒。在一些情况下,载体包含重组多核苷酸,所述重组多核苷酸包含与待表达的核苷酸序列可操作连接的表达控制序列。术语“慢病毒”是指逆转录病毒科的属。慢病毒在逆转录病毒中是独特的,在于其能够感染非分裂细胞;它们可以将大量遗传信息递送至宿主细胞的DNA中,因此它们是基因传递载体中最有效的方法之一。HIV、SIV和FIV都是慢病毒的实例。术语“慢病毒载体”是指源自慢病毒基因组的至少一部分的载体,尤其包括如Milone et al.,Mol.Ther.17(8):1453-1464(2009)中提供的自灭活慢病毒载体。可以在临床中使用的慢病毒载体的其他实例包括但不限于,例如,来自Oxford BioMedica的
在一方面,提供了T淋巴细胞,其包括本文提供的载体,包括其实施方案。
治疗方法
本文提供的组合物,包括其实施方案,被认为是自身免疫疾病的有效治疗方法。因此,一方面,提供了一种治疗自身免疫疾病(例如,I型糖尿病、移植物抗宿主病、狼疮)的方法,该方法包括向有此需要的受试者施用有效量的本文提供的T淋巴细胞(例如,CART细胞),包括其实施方案。
在一些情况下,自身免疫疾病与胰岛细胞(例如,β细胞)功能、生存力或存活降低有关。在一些情况下,自身免疫疾病是I型糖尿病。在一些情况下,自身免疫疾病是移植物抗宿主病。在一些情况下,自身免疫疾病包括受试者的免疫系统攻击受试者的胰岛细胞(例如β细胞)。
在一些情况下,本文提供的T淋巴细胞,包括其实施方案,抑制CD6+T淋巴细胞。在一些情况下,本文提供的T淋巴细胞,包括其实施方案,抑制CD6+B淋巴细胞。
实施例
以下实施例旨在进一步说明本公开的某些实施方案。提出实施例是为了提供给本领域的普通技术人员,而并非意图限制其范围。
实施例1:TREG中表达的CD6靶向性CAR
在图1至图4中描绘了包括衍生自伊利组单抗的scFv的各种CAR。除了在VL或VH定向上的scFv之外,每个还包括衍生自具有某些突变的IgG4的一部分的间隔物、CD4跨膜域、CTLA4或4-1BB信号传导域和CD3 zeta信号传导域。因为酵母表面展示技术先前表明VH-VLscFv对人CD6的亲和力与伊利组单抗相似,而VL-VH scFv对人CD6的亲和力较低(Garner etal.(2018)Immunology 155:273),所以用VH-VL或VL-VH定向的scFv制备CAR。图5是用于分离Treg和CD6
实施例2:CD6靶向性CAR的表达
可以使用慢病毒载体在Treg中表达CD6靶向性CAR。合适的慢病毒载体描述于WO2016/044811中。表达CAR的核苷酸序列可以与编码T2A(LEGGGEGRGSLLTCGDVEENPGPR;SEQID NO:71)的序列和编码截短的CD19受体(MPPPRLLFFLLFLTPMEVRPEEPLVVKVEEGDNAVLQCLKGTSDGPTQQLTWSRESPLKPFLKLSLGLPGLGIHMRPLAIWLFIFNVSQQMGGFYLCQPGPPSEKAWQPGWTVNVEGSGELFRWNVSDLGGLGCGLKNRSSEGPSSPSGKLMSPKLYVWAKDRPEIWEGEPPCVPPRDSLNQSLSQDLTMAPGSTLWLSCGVPPDSVSRGPLSWTHVHPKGPKSLLSLELKDDRPARDMWVMETGLLLPRATAQDAGKYYCHRGNLTMSFHLEITARPVLWHWLLRTGGWKVSAVTLAYLIFCLCSLVGILHLQRALVLRRKR;SEQ ID NO:73)的序列在框内。当以这种方式表达时,CAR与截短的CD19协调表达。这有助于使用容易获得的CD19抗体定量表达CAR的细胞。
图10描绘了可以替代图1-4上描述的任何构建体中的scFv的备选CD6scFv的氨基酸序列。
非正式的部分序列表
SEQ ID NO:1
MWLFFGITGLLTAALSGHPSPAPPDQLNTSSAESELWEPGERLPVRLTNGSSSCSGTVEVRLEASWEPACGALWDSRAAEAVCRALGCGGAEAASQLAPPTPELPPPPAAGNTSVAANATLAGAPALLCSGAEWRLCEVVEHACRSDGRRARVTCAENRALRLVDGGGACAGRVEMLEHGEWGSVCDDTWDLEDAHVVCRQLGCGWAVQALPGLHFTPGRGPIHRDQVNCSGAEAYLWDCPGLPGQHYCGHKEDAGAVCSEHQSWRLTGGADRCEGQVEVHFRGVWNTVCDSEWYPSEAKVLCQSLGCGTAVERPKGLPHSLSGRMYYSCNGEELTLSNCSWRFNNSNLCSQSLAARVLCSASRSLHNLSTPEVPASVQTVTIESSVTVKIENKESRELMLLIPSIVLGILLLGSLIFIAFILLRIKGKYALPVMVNHQHLPTTIPAGSNSYQPVPITIPKEVFMLPIQVQAPPPEDSDSGSDSDYEHYDFSAQPPVALTTFYNSQRHRVTDEEVQQSRFQMPPLEEGLEELHASHIPTANPGHCITDPPSLGPQYHPRSNSESSTSSGEDYCNSPKSKLPPWNPQVFSSERSSFLEQPPNLELAGTQPAFSAGPPADDSSSTSSGEWYQNFQPPPQPPSEEQFGCPGSPSPQPDSTDNDDYDDISAA
SEQ ID NO:2
MWLFFGITGLLTAALSGHPSPAPPD
][=-0987
+LNTSSAESELWEPGERLPVRLTNGSSSCSGTVEVRLEASWEPACGALWDSRAAEAVCRALGCGGAEAASQLAPPTPELPPPPAAGNTSVAANATLAGAPALLCSGAEWRLCEVVEHACRSDGRRARVTCAENRALRLVDGGGACAGRVEMLEHGEWGSVCDDTWDLEDAHVVCRQLGCGWAVQALPGLHFTPGRGPIHRDQVNCSGAEAYLWDCPGLPGQHYCGHKEDAGAVCSEHQSWRLTGGADRCEGQVEVHFRGVWNTVCDSEWYPSEAKVLCQSLGCGTAVERPKGLPHSLSGRMYYSCNGEELTLSNCSWRFNNSNLCSQSLAARVLCSASRSLHNLSTPEVPASVQTVTIESSVTVKIENKESRELMLLIPSIVLGILLLGSLIFIAFILLRIKGKYVFMLPIQVQAPPPEDSDSGSDSDYEHYDFSAQPPVALTTFYNSQRHRVTDEEVQQSRFQMPPLEEGLEELHASHIPTANPGHCITDPPSLGPQYHPRSNSESSTSSGEDYCNSPKSKLPPWNPQVFSSER SSFLEQPPNLELAGTQPAFSGSPSPQPDSTDNDDYDDISAA
SEQ ID NO:3
MWLFFGITGLLTAALSGHPSPAPPDQLNTSSAESELWEPGERLPVRLTNGSSSCSGTVEVRLEASWEPACGALWDSRAAEAVCRALGCGGAEAASQLAPPTPELPPPPAAGNTSVAANATLAGAPALLCSGAEWRLCEVVEHACRSDGRRARVTCAENRALRLVDGGGACAGRVEMLEHGEWGSVCDDTWDLEDAHVVCRQLGCGWAVQALPGLHFTPGRGPIHRDQVNCSGAEAYLWDCPGLPGQHYCGHKEDAGAVCSEHQSWRLTGGADRCEGQVEVHFRGVWNTVCDSEWYPSEAKVLCQSLGCGTAVERPKGLPHSLSGRMYYSCNGEELTLSNCSWRFNNSNLCSQSLAARVLCSASRSLHNLSTPEVPASVQTVTIESSVTVKIENKESRELMLLIPSIVLGILLLGSLIFIAFILLRIKGKYALPVMVNHQHLPTTIPAGSNSYQPVPITIPKEDSQRHRVTDEEVQQSRFQMPPLEEGLEELHASHIPTANPGHCITDPPSLGPQYHPRSNSESSTSSGEDYCNSPKSKLPPWNPQVFSSERSSFLEQPPNLELAGTQPAFSGSPSPQPDSTDNDDYDDISAA
SEQ ID NO:4
MLRLLLALNLFPSIQVTGNKILVKQSPMLVAYDNAVNLSWKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:5
MLRLLLALNLFPSIQVTGNKILVKQSPMLVAYDNAVNLSCKYSYNLFSREFRASLHKGLDSAVEVCVVYGNYSQQLQVYSKTGFNCDGKLGNESVTFYLQNLYVNQTDIYFCKIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:6
MLRLLLALNLFPSIQVTGNKILVKQSPMLVAYDNAVNLSCKYSYNLFSREFRASLHKGLDSAVEVCVVYGNYSQQLQVYSKTGFNCDGKLGNESVTFYLQNLYVNQTDIYFCKIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:7
RSKRSRGGHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:8
RSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:9
MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLTKGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLTLTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSIVYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
SEQ ID NO:10
MPTPLVHPHLPISSPRVSPFPPPAFQKASSIVYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
SEQ ID NO:11
MGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKT
CQCPHRFQKTCSPI
SEQ ID NO:12
MGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKT
CQCPHRFQKTCSPI
SEQ ID NO:13
MGKKLPLHLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAKVSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCVRCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI
SEQ ID NO:14
KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL
SEQ ID NO:15
MGNSCYNIVATLLLVLNFERTRSLQDPCSNCPAGTFCDNNRNQICSPCPPNSFSSAGGQRTCDICRQCKGVFRTRKECSSTSNAECDCTPGFHCLGAGCSMCEQDCKQGQELTKKGCKDCCFGTFNDQKRGICRPWTNCSLDGKSVLVNGTKERDVVCGPSPADLSPGASSVTPPAPAREPGHSPQIISFFLALTSTALLFLLFFLTLRFSVVKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL
SEQ ID NO:16
MKSGLWYFFLFCLRIKVLTGEINGSANYEMFIFHNGGVQILCKYPDIVQQFKMQLLKGGQILCDLTKTKGSGNTVSIKSLKFCHSQLSNNSVSFFLYNLDHSHANYYFCNLSIFDPPPFKVTLTGGYLHIYESQLCCQLKFWLPIGCAAFVVVCILGCILICWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL
SEQ ID NO:17
AVSLSKMLKKRSPLTTGVYVKMPPTEPECEKQFQPYFIPIN
SEQ ID NO:18(VL NA)
GACATCCAAATGACACAAAGTCCTAGCTCTCTCTCAGCAAGTGTTGGCGACCGTGTGACCATCACATGTAAAGCTTCAAGGGATATTCGCAGCTACCTGACTTGGTACCAACAAAAGCCCGGAAAAGCGCCTAAAACGCTTATTTACTATGCCACCAGCCTCGCAGATGGTGTCCCCTCCAGATTTTCTGGATCGGGATCAGGGCAAGATTATAGTCTTACGATATCGAGTCTTGAGTCGGACGATACTGCCACATACTACTGCTTACAGCACGGGGAAAGCCCATTCACATTCGGAAGTGGTACGAAACTCGAGATCAAACGGGCA
SEQ ID NO:19(VH NA)
GAAGTCCAATTGGTCGAGAGCGGAGGTGGGCTTGTTAAACCAGGAGGCAGTTTAAAATTATCATGTGCTGCCTCGGGTTTCAAGTTCTCGCGGTATGCTATGTCCTGGGTACGCCAAGCACCTGGAAAGCGTTTAGAATGGGTGGCCACAATTAGTAGTGGTGGTTCATATATATATTATCCCGACTCCGTCAAAGGAAGGTTCACGATTTCAAGGGACAATGTGAAGAACACCCTCTACTTACAGATGAGTAGTCTGCGTTCTGAGGATACCGCTATGTACTACTGTGCTCGGAGAGATTACGATCTGGATTATTTCGACAGCTGGGGTCAGGGCACACTCGTTACAGTATCCTCG
SEQ ID NO:20(VH CDR1 NA)
GTCCAACTTGTTGAATCAGGTGGGGGGCTGGTCAAACCCGGGGGCTCTCTGAAACTAAGT
SEQ ID NO:21(VH CDR2 NA)
TTCTCTCGGTACGCTATGTCGTGGGTCAGACAAGCGCCCGGCAAA
SEQ ID NO:22(VH CDR3 NA)
CGTGATTATGATCTAGACTACTTTGACTCCTGGGGTCAAGGTACGCTCGTGACGGT
T
SEQ ID NO:23
MALIVLGGVAGLLLFIGLGIFF
SEQ ID NO:24
ATGGCCCTGATTGTGCTGGGGGGCGTCGCCGGCCTCCTGCTTTTCATTGGGCTAGG
CATCTTCTTC
SEQ ID NO:25
IYIWAPLAGTCGVLLLSLVIT
SEQ ID NO:26(接头18NA)
GGGTCAACGTCGGGCGGGGGTTCCGGTGGAGGAAGTGGAGGTGGTGGAAGTTCT
SEQ ID NO:27(接头20NA)
GGCGGCGGCGGAAGTGGCGGCGGCGGCTCAGGCGGGGGGGGTTCTGGGGGCGGC
GGTTCA
SEQ ID NO:28(VH CDR1 AA)
VQLVESGGGLVKPGGSLKLS
SEQ ID NO:29(VH CDR2 AA)
FSRYAMSWVRQAPGK
SEQ ID NO:30(VH CDR3 AA)
RDYDLDYFDSWGQGTLVTV
SEQ ID NO:31(VL CDR1 AA)
CWLTKKKYSSSVHDPNGEYMFMRAVNTAKKSRLTDVTL
SEQ ID NO:32
ALYLLRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKI
SEQ ID NO:33((VL CDR3 AA)
CSRAARGTIGARRTGQPLKEDPSAVPVFSVDYGELDFQWREKTPEPPVPCVPEQTEYATIVFPSGMGTSSP ARRGSADGPRSAQPLRPEDGHCSWPL
SEQ ID NO:34(VL AA)
DIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA
SEQ ID NO:35(VH AA)
EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS
SEQ ID NO:36(接头18AA)
GSTSGGGSGGGSGGGGSS
SEQ ID NO:37(接头20AA)
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO:38(完整scFv(VH-VL)接头18)
EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS
GSTSGGGSGGGSGGGGSSDIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA
SEQ ID NO:39(完整scFv(VH-VL)接头20)
EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS
GGGGSGGGGSGGGGSGGGGSDIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA
SEQ ID NO:40(完整scFv(VL-VH)接头18AA)
DIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRAGSTSGGGSGGGSGGGGSSEVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS
SEQ ID NO:41(完整scFv(VL-VH)接头20AA)
DIQMTQSPSSLSASVGDRVTITCKASRDIRSYLTWYQQKPGKAPKTLIYYATSLADGVPSRFSGSGSGQDYSLTISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRAGGGGSGGGGSGGGGSGGGGSEVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQAPGKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTLVTVSS
SEQ ID NO:42(完整scFv(VH-VL)接头18NA)
GAAGTCCAATTGGTCGAGAGCGGAGGTGGGCTTGTTAAACCAGGAGGCAGTTTAAAATTATCATGTGCTGCCTCGGGTTTCAAGTTCTCGCGGTATGCTATGTCCTGGGTACGCCAAGCACCTGGAAAGCGTTTAGAATGGGTGGCCACAATTAGTAGTGGTGGTTCATATATATATTATCCCGACTCCGTCAAAGGAAGGTTCACGATTTCAAGGGACAATGTGAAGAACACCCTCTACTTACAGATGAGTAGTCTGCGTTCTGAGGATACCGCTATGTACTACTGTGCTCGGAGAGATTACGATCTGGATTATTTCGACAGCTGGGGTCAGGGCACACTCGTTACAGTATCCTCGGGGTCAACGTCGGGCGGGGGTTCCGGTGGAGGAAGTGGAGGTGGTGGAAGTTCTGACATCCAAATGACACAAAGTCCTAGCTCTCTCTCAGCAAGTGTTGGCGACCGTGTGACCATCACATGTAAAGCTTCAAGGGATATTCGCAGCTACCTGACTTGGTACCAACAAAAGCCCGGAAAAGCGCCTAAAACGCTTATTTACTATGCCACCAGCCTCGCAGATGGTGTCCCCTCCAGATTTTCTGGATCGGGATCAGGGCAAGATTATAGTCTTACGATATCGAGTCTTGAGTCGGACGATACTGCCACATACTACTGCTTACAGCACGGGGAAAGCCCATTCACATTCGGAAGTGGTACGAAACTCGAGATCAAACGGGCA
SEQ ID NO:43(完整scFv(VH-VL)接头20NA)
GAAGTCCAATTGGTCGAGAGCGGAGGTGGGCTTGTTAAACCAGGAGGCAGTTTAAAATTATCATGTGCTGCCTCGGGTTTCAAGTTCTCGCGGTATGCTATGTCCTGGGTACGCCAAGCACCTGGAAAGCGTTTAGAATGGGTGGCCACAATTAGTAGTGGTGGTTCATATATATATTATCCCGACTCCGTCAAAGGAAGGTTCACGATTTCAAGGGACAATGTGAAGAACACCCTCTACTTACAGATGAGTAGTCTGCGTTCTGAGGATACCGCTATGTACTACTGTGCTCGGAGAGATTACGATCTGGATTATTTCGACAGCTGGGGTCAGGGCACACTCGTTACAGTATCCTCGGGCGGCGGCGGAAGTGGCGGCGGCGGCTCAGGCGGGGGGGGTTCTGGGGGCGGCGGTTCAGACATCCAAATGACACAAAGTCCTAGCTCTCTCTCAGCAAGTGTTGGCGACCGTGTGACCATCACATGTAAAGCTTCAAGGGATATTCGCAGCTACCTGACTTGGTACCAACAAAAGCCCGGAAAAGCGCCTAAAACGCTTATTTACTATGCCACCAGCCTCGCAGATGGTGTCCCCTCCAGATTTTCTGGATCGGGATCAGGGCAAGATTATAGTCTTACGATATCGAGTCTTGAGTCGGACGATACTGCCACATACTACTGCTTACAGCACGGGGAAAGCCCATTCACATTCGGAAGTGGTACGAAACTCGAGATCAAACGGGCA
SEQ ID NO:44(完整scFv(VL-VH)接头18NA)
GACATCCAAATGACACAAAGTCCTAGCTCTCTCTCAGCAAGTGTTGGCGACCGTGTGACCATCACATGTAAAGCTTCAAGGGATATTCGCAGCTACCTGACTTGGTACCAACAAAAGCCCGGAAAAGCGCCTAAAACGCTTATTTACTATGCCACCAGCCTCGCAGATGGTGTCCCCTCCAGATTTTCTGGATCGGGATCAGGGCAAGATTATAGTCTTACGATATCGAGTCTTGAGTCGGACGATACTGCCACATACTACTGCTTACAGCACGGGGAAAGCCCATTCACATTCGGAAGTGGTACGAAACTCGAGATCAAACGGGCAGGGTCAACGTCGGGCGGGGGTTCCGGTGGAGGAAGTGGAGGTGGTGGAAGTTCTGAAGTCCAATTGGTCGAGAGCGGAGGTGGGCTTGTTAAACCAGGAGGCAGTTTAAAATTATCATGTGCTGCCTCGGGTTTCAAGTTCTCGCGGTATGCTATGTCCTGGGTACGCCAAGCACCTGGAAAGCGTTTAGAATGGGTGGCCACAATTAGTAGTGGTGGTTCATATATATATTATCCCGACTCCGTCAAAGGAAGGTTCACGATTTCAAGGGACAATGTGAAGAACACCCTCTACTTACAGATGAGTAGTCTGCGTTCTGAGGATACCGCTATGTACTACTGTGCTCGGAGAGATTACGATCTGGATTATTTCGACAGCTGGGGTCAGGGCACACTCGTTACAGTATCCTCG
SEQ ID NO:45(完整scFv(VL-VH)接头20NA)
GACATCCAAATGACACAAAGTCCTAGCTCTCTCTCAGCAAGTGTTGGCGACCGTGTGACCATCACATGTAAAGCTTCAAGGGATATTCGCAGCTACCTGACTTGGTACCAACAAAAGCCCGGAAAAGCGCCTAAAACGCTTATTTACTATGCCACCAGCCTCGCAGATGGTGTCCCCTCCAGATTTTCTGGATCGGGATCAGGGCAAGATTATAGTCTTACGATATCGAGTCTTGAGTCGGACGATACTGCCACATACTACTGCTTACAGCACGGGGAAAGCCCATTCACATTCGGAAGTGGTACGAAACTCGAGATCAAACGGGCAGGCGGCGGCGGAAGTGGCGGCGGCGGCTCAGGCGGGGGGGGTTCTGGGGGCGGCGGTTCAGAAGTCCAATTGGTCGAGAGCGGAGGTGGGCTTGTTAAACCAGGAGGCAGTTTAAAATTATCATGTGCTGCCTCGGGTTTCAAGTTCTCGCGGTATGCTATGTCCTGGGTACGCCAAGCACCTGGAAAGCGTTTAGAATGGGTGGCCACAATTAGTAGTGGTGGTTCATATATATATTATCCCGACTCCGTCAAAGGAAGGTTCACGATTTCAAGGGACAATGTGAAGAACACCCTCTACTTACAGATGAGTAGTCTGCGTTCTGAGGATACCGCTATGTACTACTGTGCTCGGAGAGATTACGATCTGGATTATTTCGACAGCTGGGGTCAGGGCACACTCGTTACAGTATCCTCG
SEQ ID NO:46
MALPVTALLLPLALLLHAARPSQFRVSPLDRTWNLGETVELKCQVLLSNPTSGCSWLFQPRGAAASPTFLLYLSQNKPKAAEGLDTQRFSGKRLGDTFVLTLSDFRRENEGYYFCSALSNSIMYFSHFVPVFLPAKPTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVVKSGDKPSLSARYV
SEQ ID NO:47
MALPVTALLLPLALLLHAARPSQFRVSPLDRTWNLGETVELKCQVLLSNPTSGCSWLFQPRGAAASPTFLLYLSQNKPKAAEGLDTQRFSGKRLGDTFVLTLSDFRRENEGYYFCSALSNSIMYFSHFVPVFLPAKPTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAGNRRRVCKCPRPVVKSGDKPSLSARYV
SEQ ID NO:48
MALPVTALLLPLALLLHAARPSQFRVSPLDRTWNLGETVELKCQVLLSNPTSGCSWLFQPRGAAASPTFLLYLSQNKPKAAEGLDTQRFSGKRLGDTFVLTLSDFRRENEGYYFCSALSNSIMYFSHFVPVFLPAKPTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVVKSGDKPSLSARYV
SEQ ID NO:49
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGPLCSPITLGLLVAGVLVLLVSLGVAIHLCCRRRRARLRFMKQKFNIVCLKISGFTTCCCFQILQMSREYGFGVLLQKDIGQ
SEQ ID NO:50
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGLKGKVYQEPLSPNACMDTTAILQPHRSCLTHGS
SEQ ID NO:51
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGPLCSPITLGLLVAGVLVLLVSLGVAIHLCCRRRRARLRFMKQPQGEGISGTFVPQCLHGYYSNTTTSQKLLNPWILKT
SEQ ID NO:52
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGRRRRARLRFMKQPQGEGISGTFVPQCLHGYYSNTTTSQKLLNPWILKT
SEQ ID NO:53
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGPLCSPITLGLLVAGVLVLLVSLGVAIHLCCRRRRARLRFMKQLRLHPLEKCSRMDY
SEQ ID NO:54
MRPRLWLLLAAQLTVLHGNSVLQQTPAYIKVQTNKMVMLSCEAKISLSNMRIYWLRQRQAPSSDSHHEFLALWDSAKGTIHGEEVEQEKIAVFRDASRFILNLTSVKPEDSGIYFCMIVGSPELTFGKGTQLSVVDFLPTTAQPTKKSTLKKRVCRLPRPETQKGPLCSPITLGLLVAGVLVLLVSLGVAIHLCCRRRRARLRFMKQFYK
SEQ ID NO:55
MKWKALFTAAILQAQLPITEAQSFGLLDPKLCYLLDGILFIYGVILTALFLRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
SEQ ID NO:56
MKWKALFTAAILQAQLPITEAQSFGLLDPKLCYLLDGILFIYGVILTALFLRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPQRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
SEQ ID NO:57
MLRLLLALNLFPSIQVTGNKILVKQSPMLVAYDNAVNLSWKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:58
MLRLLLALNLFPSIQVTGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:59
MLRLLLALNLFPSIQVTGNKILVKQSPMLVAYDNAVNLSCKYSYNLFSREFRASLHKGLDSAVEVCVVYGNYSQQLQVYSKTGFNCDGKLGNESVTFYLQNLYVNQTDIYFCKIEVMYPPPYLDNEKSNGTIIHVKGKHLCPSPLFPGPSKPFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:60
MCVGARRLGRGPCAALLLLGLGLSTVTGLHCVGDTYPSNDRCCHECRPGNGMVSRCSRSQNTVCRPCGPGFYNDVVSSKPCKPCTWCNLRSGSERKQLCTATQDTVCRCRAGTQPLDSYKPGVDCAPCPPGHFSPGDNQACKPWTNCTLAGKHTLQPASNSSDAICEDRDPPATQPQETQGPPARPITVQPTEAWPRTSQGPSTRPVEVPGGRAVAAILGLGLVLGLLGPLAILLALYLLRRDQRLPPDAHKPPGGGSFRTPIQEEQADAHSTLAKI
SEQ ID NO:61
MACLGFQRHKAQLNLATRTWPCTLLFFLLFIPVFCKAMHVAQPAVVLASSRGIASFVCEYASPGKATEVRVTVLRQADSQVTEVCAATYMMGNELTFLDDSICTGTSSGNQVNLTIQGLRAMDTGLYICKVELMYPPPYYLGIGNGTQIYVIAKEKKPSYNRGLCENAPNRARM
SEQ ID NO:62
MACLGFQRHKAQLNLATRTWPCTLLFFLLFIPVFCKAMHVAQPAVVLASSRGIASFVCEYASPGKATEVRVTVLRQADSQVTEVCAATYMMGNELTFLDDSICTGTSSGNQVNLTIQGLRAMDTGLYICKVELMYPPPYYLGIGNGTQIYVIDPEPCPDSDFLLWILAAVSSGLFFYSFLLTAVSLSKMLKKRSPLTTGVYVKMPPTEPECEKQFQPYFIPIN
SEQ ID NO:63
MQIPQAPWPVVWAVLQLGWRPGWFLDSPDRPWNPPTFSPALLVVTEGDNATFTCSFSNTSESFVLNWYRMSPSNQTDKLAAFPEDRSQPGQDCRFRVTQLPNGRDFHMSVVRARRNDSGTYLCGAISLAPKAQIKESLRAELRVTERRAEVPTAHPSPSPRPAGQFQTLVVGVVGGLLGSLVLLVWVLAVICSRAARGTIGARRTGQPLKEDPSAVPVFSVDYGELDFQWREKTPEPPVPCVPEQTEYATIVFPSGMGTSSPARRGSADGPRSAQPLRPEDGHCSWPL
SEQ ID NO:64
MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCTQFGFLTVFPGNKTHNAVCVPGSPPAEPLGWLTVVLLAVAACVLLLTSAQLGLHIWQLRSQCMWPRETQLLLEVPPSTEDARSCQFPEEERGERSAEEKGRLGDLWV
SEQ ID NO:65
MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCCWRCRRRPKTPEAASSPRKSGASDRQRRRGGWETCGCEPGRPPGPPTAASPSPGAPQAAGALRSALGRALLPWQQKWVQEGGSDQRPGPCSSAAAAGPCRRERETQSWPPSSLAGP DGVGS
SEQ ID NO:66
MAQHGAMGAFRALCGLALLCALSLGQRPTGGPGCGPGRLLLGTGTDARCCRVHTTRCCRDYPGEECCSEWDCMCVQPEFHCGDPCCTTCRHHPCPPGQGVQSQGKFSFGFQCIDCASGTFSGGHEGHCKPWTDCTQFGFLTVFPGNKTHNAVCVPGSPPAEPLGWLTVVLLAVAACVLLLTSAQLGLHIWQLRKTQLLLEVPPSTEDARSCQFPEEERGERSAEEKGRLGDLWV
SEQ ID NO:67(GITR共刺激域AA)QLGLHIWQLRSQCMWPRETQLLLEVPPSTEDARSCQFPEEERGERSAEEKGRLGDLWV
SEQ ID NO:68(VH AA)
EVQLVESGGGLVKPGGSLKLSCAASGFKFSRYAMSWVRQTPEKRLEWVATISSGGSYIYYPDSVKGRFTISRDNVKNTLYLQMSSLRSEDTAMYYCARRDYDLDYFDSWGQGTTLTVSS
SEQ ID NO:69(VL AA)
DIKMTQSPSSMYASLGERVTITCKASRDIRSYLTWYQQKPWKSPKTLIYYATSLADGVPSRFSGSGSGQDYSL TISSLESDDTATYYCLQHGESPFTFGSGTKLEIKRA
- 用于治疗某些自身免疫病症的CD6靶向性嵌合抗原受体
- 针对表达通用嵌合抗原受体的免疫细胞的靶向模块及其在治疗癌症、感染和自身免疫性病症中的用途