一种地下柴油铲运机循环工况的识别方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及地下柴油铲运机工况分析技术领域,特别是指一种地下柴油铲运机循环工况的识别方法。
背景技术
工况,是指装备在不同条件下发挥其功能,是装备在和其动作有直接关系的条件下的工作状态。根据实际地下铲运机的工作情况,可以发现,地下铲运机总是在循环往复的工作,且一个工作循环中的铲运机工况状态变化特征代表了其运行状态。由于地下铲运机在工作时有不同的工况,不同工况下可能出现的故障状态也不同。
研究表明,基于工况的故障诊断有利于提高对地下铲运机的健康状态的诊断和预测的识别精度,避免不必要的维修,合理安排资源。基于此,还有利于进一步开展对地下铲运机的智能控制和科学管控。因此研究地下铲运机的运行工况识别方法,为后续建立地下铲运机健康诊断评判体系,实现对其健康状态的评估和监测以及故障的诊断和预测具有重要的指导作用。
随着互联网技术、物联网技术、计算机技术的发展,地下铲运机在不同的部位都安装了相应的满足一定精度要求的传感器,因此在生产过程中,能够产生实时反映铲运机工作状态的传感器数据,并存储于服务器当中,借助一定的计算机技术,可以获取这些数据对铲运机的工况进行分析。
发明内容
本发明要解决的技术问题是提供一种地下柴油铲运机循环工况的识别方法,用以解决现有技术中无法对地下柴油铲运机循环工况进行快速有效的识别,为后续基于工况的故障诊断、健康智能管理和智能管控提供指导意义。
该方法首先获取地下柴油铲运机循环工况运行数据以及工况变换时间记录表,然后将地下柴油铲运机循环工况类别分为空载行驶、装载、重载运输和卸载四类工况,并对所述历史数据进行人工工况标定,再对所述历史数据进行数据清洗、滤波处理,利用ReliefF算法对所述滤波处理后的数据进行特征选择,确定工况识别特征参数,得到最终的样本集,最后训练工况识别随机森林模型,将所述铲运机的实时生产数据输入所述随机森林模型,以实现实时工况的识别。
具体包括步骤如下:
(1)获取地下柴油铲运机循环工况运行数据以及工况变换时间记录表;
(2)将地下柴油铲运机循环工况类别分为空载行驶、装载、重载运输和卸载四类工况,并对步骤(1)中获取的数据进行工况标定;
(3)对步骤(1)中获取的数据进行数据清洗、滤波处理;
(4)利用ReliefF算法对滤波处理后的数据进行特征选择,确定工况识别特征参数,得到最终的样本集;
(5)训练工况识别随机森林模型;
(6)将铲运机的实时生产数据输入随机森林模型,以实现实时工况的识别。
其中,步骤(1)中地下柴油铲运机循环工况运行数据,包括铲运机的发动机油温、发动机油压、发动机进气歧管温度、发动机进气歧管压力、发动机冷却液温度、变速箱油温、变速箱油压、液压油温、制动液压油温、制动回路充气压力、大臂与铲斗压力、前轴制动压力、后轴制动压力、车速、转向泵压力、发动机转速、发动机扭矩、发动机燃油率、发动机负载、油门踏板位置、实时档位;工况变换时间记录表,包括铲运机循环工况实验时每个循环工况中空载行驶、装载、重载运输和卸载的发生时刻。
步骤(2)中结合铲运机的机理分析和运行数据分析,将循环工况分为空载行驶、装载、重载运输和卸载,既减小了算法难度,提高识别精度,又满足后续基于工况的故障诊断等其他研究的需求;对数据进行人工工况标定,即在历史数据后增加一列反映实时工况的标签数据。
步骤(3)中数据清洗包括空缺值和异常值的处理:针对空缺值,根据机理分析判断此时是否为空挡时间,空挡时间直接删除,非空挡时间出现的空缺值进行插值处理;针对异常值,即采集的数据只有发动机油温、发动机冷却液温度、变速箱油温、变速箱油压、液压油温和制动液压油温这几维数据未发生丢失,或者发动机油温、发动机冷却液温度为0等不符合生产实际和逻辑的数据,可直接删除;数据滤波处理,即对实验数据中的每个维度的传感器数据进行10次以上的加权平均滤波处理,在保留数据本身变化趋势的基础上,对数据进行平滑化。
步骤(4)中ReliefF算法是一种针对多类别的特征选择算法,特征参数由ReliefF算法中的阈值来决定,根据阈值大小选择特征权重大于阈值的参数作为特征参数。
步骤(5)中具体为:将标定工况后的实验数据经数据清洗、滤波、ReliefF特征选择后得到的训练样本输入随机森林模型,其中,步骤(1)中获取的运行数据为训练样本的特征,工况类别为训练样本的目标属性。
步骤(6)中具体为:把铲运机日常生产采集的实时传感器数据输入步骤(5)训练所得的随机森林模型中进行铲运机实时工况的识别。
本发明的上述技术方案的有益效果如下:
(1)本发明将地下柴油铲运机循环工况类别分为空载行驶、装载、重载运输和卸载四类,并不区分空载前进或后退,重载前进和后退等工况,既简化了程序,提高了识别精度,又满足了后续故障诊断、智能控制等研究的要求;
(2)本发明采用多次加权平均滤波处理,实现了数据的平滑化,提高了工况识别的精度;
(3)本发明采用ReliefF算法进行特征选择,能获取与工况类别最相关的特征属性,降低了数据的冗余度,减少了算法的计算量,提高了工况识别的速度。除此,此算法不依赖于铲运机动力学模型,摆脱了对专家知识的依赖性,可拓展性强;
(4)本发明能够为基于工况的铲运机故障诊断、智能控制、科学管控提供指导,具有重大意义。
附图说明
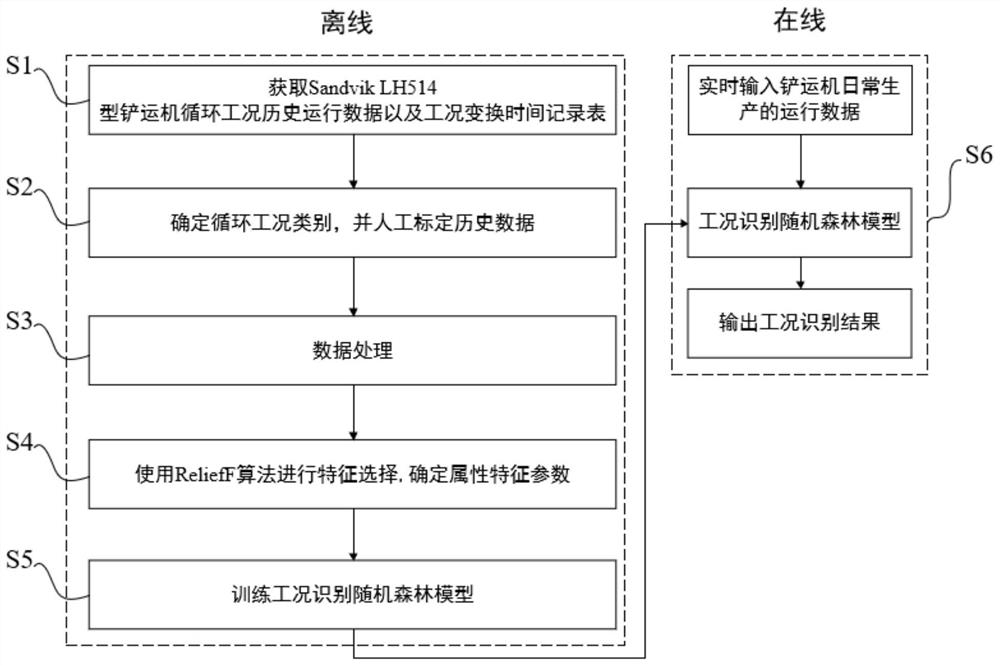
图1为本发明实施例提供的Sandvik LH514型铲运机的循环工况识别方法的流程示意图;
图2为本发明实施例提供的Sandvik LH514型铲运机数据传输路径;
图3为本发明实施例提供的Sandvik LH514型铲运机作业流程示意图;
图4为本发明实施例提供的Sandvik LH514型铲运机循环工况示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明提供一种地下柴油铲运机循环工况的识别方法。
本方法首先获取地下柴油铲运机循环工况运行数据以及工况变换时间记录表,然后将地下柴油铲运机循环工况类别分为空载行驶、装载、重载运输和卸载四类工况,并对所述历史数据进行人工工况标定,再对所述历史数据进行数据清洗、滤波处理,利用ReliefF算法对所述滤波处理后的数据进行特征选择,确定工况识别特征参数,得到最终的样本集,最后训练工况识别随机森林模型,将所述铲运机的实时生产数据输入所述随机森林模型,以实现实时工况的识别。
下面结合具体实施例予以说明。
实施例1
本发明的一个具体实施例的数据来源是谦比西铜矿某Sandvik LH514型铲运机。以此为例,本发明公开了一种地下柴油铲运机循环工况的识别方法,如图1所示,包括以下步骤:
步骤S1:获取Sandvik LH514型铲运机循环工况历史运行数据以及工况变换时间记录表:
铲运机数据传输路径如图2所示,铲运机在工作产生的数据先由设备上的存储器收集,然后传输至MOM Server服务器中寄存,最后传输到SQL Server服务器中进行保存。其中,传感器数据的采集间隔为5s。在进行工况分析前,需使用Python从SQL Server数据库中提取铲运机循环工况运行数据。
工况变换时间记录表由人工记录,存在以下两点问题,第一,人工记录工况变换存在一定的滞后性;第二,人工记录时间精度为分钟级,与传感器5s的采集间隔相差较大。
步骤S2:将铲运机循环工况类别分为空载行驶、装载、重载运输和卸载四类工况,并对所述历史数据进行人工工况标定。
具体地,循环工况类别的确定是根据以下分析确定的。实际生产过程中,铲运机在地下巷道内往复行驶,通过铲装、运输和卸载等过程完成物料的搬运工作,如图3所示。通过对实际矿山地下铲运机作业过程的实地考察,发现地下铲运机循环工况具有“L”型工作循环特征,如图4所示,可以分为6个部分:
(1)空载前进:铲运机从掉头点出发,转向油缸驱动整车转向后驶向物料点,倾翻油缸动作放下铲斗准备插入料堆。
(2)联合铲装:铲运机前进插入料堆后,柴油机全油门工作,铲运机保持低速大扭矩前进直至车轮打滑。转向泵与工作泵同时工作为举升缸与倾翻缸提供动力。举升缸与倾翻缸交替动作,直到铲斗装满近似端平。
(3)重载后退转向:铲运机起步后退,从物料点出发,转向油缸工作,转向90°回到掉头点。
(4)重载前进:铲运机从掉头点出发,向前运输至快到卸料点处举升缸工作,大臂举升。
(5)卸料:在卸料点处停车,转向泵与工作泵一起工作为倾翻油缸提供动力,铲斗倾翻卸料后将铲斗收回。
(6)空载后退:铲运机后退,落下大臂,空载后退回到掉头点。
考虑到空载行驶时,区分前进或后退,对后续基于工况的相关研究意义不大,却加大了工况识别的难度,严重影响工况识别的准确性。重载运输时,亦同。因此,将循环工况划分为空载行驶、装载、重载运输和卸载。
具体地,对所述历史数据进行人工工况标定,考虑到人工记录时间的误差,需结合实验数据进行初步分析。经分析表明,在装载和卸载时,铲运机大臂与铲斗压力分别有一次明显的升降过程。再结合铲运机车速、油门踏板位置等数据,修正人工记录的工况转变时间至秒级,进而确定每组数据的对应工况。本发明实施例将工况标签规定为:空载行驶记作1、装载记作2、重载运输记作3、卸载记作4。
步骤S3:对所述历史数据进行数据处理,包括数据清洗和数据滤波:
数据清洗包括异常值和空缺值的处理。
具体地,所述异常值,主要是数据时间节点与采样时间节点不一致的情况,已知传感器采样周期为5s,因此考虑是传感采集系统的问题,可直接剔除此类异常值。
具体地,所述空缺值,主要存在两种情况:一是大面积缺失或全部缺失;二是偶有缺失。对于全部缺失的数据考虑到是因为传感采集系统的问题,所以将这些时间节点的数据直接剔除。此外,由于传感系统的限制,并非所有维度的属性都存在数据,根据数据分类方法的原理,在对数据进行分析之前可以将部分无关数据进行删除处理。对于相对独立且完全随机缺失的数据而言,不能通过和其他参数的相关性间接推导出,则利用数据插值进行填补。经分析发现,变速箱油压、制动液压油温易出现部分缺失,由于压力和温度变化缓慢,遂采用线性插值进行空缺值的填补。
数据滤波方法选用的是加权平均滤波,经实验,对传感器数据进行一次加权平均滤波效果并不明显,数据波形呈现锯齿状,经30次滤波处理后,数据波形实现平滑化。
步骤S4:使用ReliefF算法进行特征选择,设定阈值为0.02时,得到铲运车工况识别的特征参数为以下10维特征:车速、发动机油温、发动机冷却液温度、发动机负载、发动机进气歧管温度、大臂与铲斗压力、制动液压油温、后轴制动压力、发动机扭矩、前轴制动压力。
将对应的工况标签数据作为新的一列存入经上述特征选择后的数据中,得到最终的样本数据。再将上述带有标签的样本数据随机分为两组,其中一组作为训练样本集,另一组作为测试样本集。
步骤S5:使用训练样本集数据对随机森林模型进行训练,得到工况识别随机森林模型;使用测试样本集测试所述工况识别随机森林模型的分类效果,并对模型参数进行优化,最终工况识别的准确率最高可达97%。
步骤S6:将所述铲运机日常生产过程中传感器采集的实时数据输入所述工况识别随机森林模型,进行实时工况识别,输出每个时间节点的工况类别。
综上所述,本发明实施例提出的一种地下柴油铲运机循环工况的识别方法,考虑了传感采集系统的缺陷,对数据进行了异常值和空缺值的处理;为减少数据噪声影响,采用了多次加权平均滤波,实现了数据的平滑化;而后使用ReliefF算法进行特征选择,降低了数据冗余度,提高了算法运算速度;最后训练随机森林模型用以实现循环工况的识别,准确率高达97%。简言之,该方法简单有效,可操作性强,且不依赖于铲运机动力学模型,可拓展性强,对基于工况的铲运机故障诊断、智能控制、科学管控的研究具有重要意义。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种地下柴油铲运机循环工况的识别方法
- 一种地下铲运机转向控制系统及地下铲运机