一种广义最小误差熵卡尔曼的水下无人航行器定位方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及无人航行器定位技术领域,具体而言,涉及一种广义最小误差熵卡尔曼的水下无人航行器定位方法。
背景技术
随着海洋勘探的发展,水下无人航行器的应用也愈加广泛,同时水下无人航行器的高精度水声定位技术正在吸引更多的关注。在一个实际的海洋环境中,水下无人航行器的水声定位系统往往使用声波信号来进行测量和定位,但是由于复杂的水下环境以及来往船舶产生的噪声干扰,通常会导致水下无人航行器的水声定位系统产生异常测量。而由海洋环境和过往船舶产生的噪声一般都属于非高斯噪声,这些未知分布的非高斯噪声会严重影响无人航行器水声定位系统的精度,对水下无人航行器定位造成极大的负面影响。
现有进行水声定位常用的原始卡尔曼滤波算法(KF)只适用于高斯噪声条件。为了解决非高斯噪声对状态估计(水声定位)的影响:(1)最近,信息理论学习(ITL)中的最大相关熵准则(MCC)考虑了高阶统计量,是一种很好的非高斯噪声状态估计(水声定位)方法,并提出了一种新的基于MCC的KF算法,称为最大相关熵KF(MCKF),该方法也扩展到非线性系统的状态估计(水声定位)。此外,还开发了一些基于修正的相关熵准则的KF。(2)ITL中的最小误差熵(MEE)准则在处理具有多峰分布的复杂非高斯噪声方面优于MCC。为了进一步提高KF算法处理非高斯噪声的能力,提出了一些基于MEE准则的新型卡尔曼滤波算法。然而,无论是MCC还是MEE,其误差熵的形状都不能自由改变,因为它的核函数是高斯函数,这使得基于最大相关熵和误差熵的算法只能处理某些特定类型的噪声。这些分布未知的非高斯噪声将不可避免地降低系统水声定位的估计精度。
发明内容
针对现有技术中的上述不足,本发明提供的一种广义最小误差熵卡尔曼的水下无人航行器定位方法解决了现有针对非高斯噪声的滤波方法只能处理某些特定类型的噪声,非高斯噪声无法被完全滤除,造成水声定位的估计精度低的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种广义最小误差熵卡尔曼的水下无人航行器定位方法,包括以下步骤:
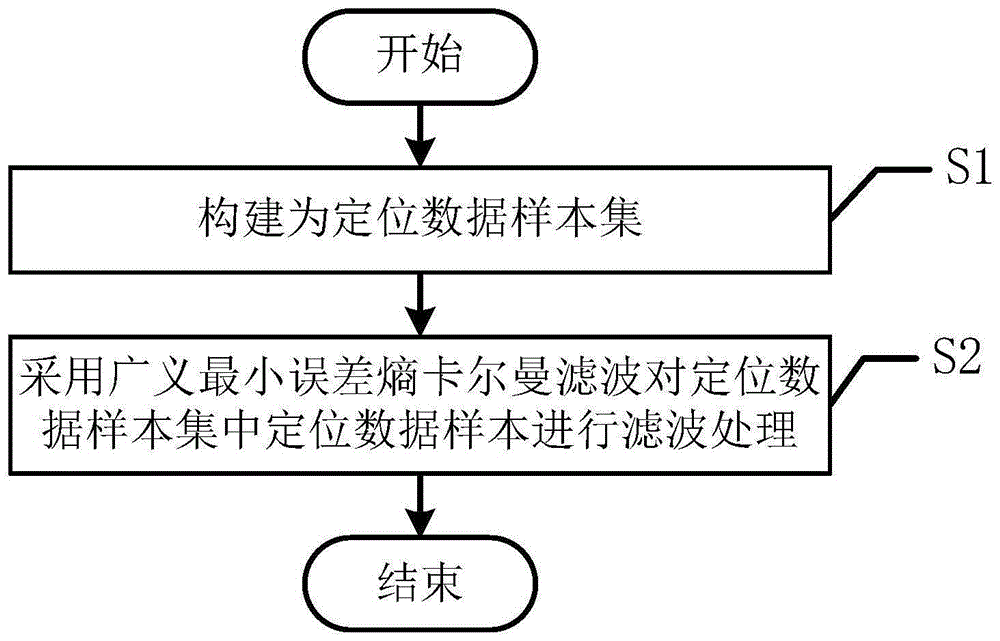
S1、采集水下无人航行器的位置和速度数据,构建为定位数据样本集;
S2、采用广义最小误差熵卡尔曼滤波对定位数据样本集中定位数据样本进行滤波处理,得到修正定位数据。
进一步地,所述步骤S2包括以下分步骤:
S21、将定位数据样本初始值带入预测方程,得到定位数据样本预测值;
S22、根据定位数据样本预测值和定位数据样本集中定位数据样本,计算定位数据样本误差值;
S23、根据定位数据样本误差值和增广噪声矩阵,计算增广噪声矩阵的协方差矩阵的分量;
S24、根据增广噪声矩阵的协方差矩阵的分量和定位数据样本预测值,构建广义最小误差熵卡尔曼滤波模型;
S25、根据广义最小误差熵卡尔曼滤波模型,对估计定位数据样本进行更新,得到更新估计定位数据样本;
S26、判断更新估计定位数据样本是否满足误差条件,若是,则更新估计定位数据样本为修正定位数据,若否,直接跳转至步骤S25中。
进一步地,所述步骤S21中预测方程为:
其中,
进一步地,所述步骤S22中计算定位数据样本误差值的公式为:
其中,ε
进一步地,所述步骤S23包括以下分步骤:
S231、根据定位数据样本误差值,计算定位数据样本的增广噪声矩阵;
S232、根据定位数据样本的增广噪声矩阵,计算增广噪声矩阵的协方差矩阵的分量。
进一步地,所述步骤S231中计算定位数据样本的增广噪声矩阵的公式为:
其中,μ
进一步地,所述步骤S232中计算增广噪声矩阵的协方差矩阵的分量的公式为:
其中,Θ
进一步地,所述步骤S24中广义最小误差熵卡尔曼滤波模型为:
其中,
对D
L=m+n
将
将Θ
则:
其中,
进一步地,所述步骤S26中误差条件为:
其中,
本发明的有益效果为:本发明构造了广义最小误差熵卡尔曼滤波模型,该模型的核函数形状可变,使得广义最小误差熵卡尔曼滤波模型可以灵活处理不同分布类型的非高斯噪声,提高了水下航行定位的精度,从而提高惯性导航系统的精度。
附图说明
图1为一种广义最小误差熵卡尔曼的水下无人航行器定位方法的流程图;
图2为实验对比图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
如图1所示,一种广义最小误差熵卡尔曼的水下无人航行器定位方法,包括以下步骤:
S1、采集水下无人航行器的位置和速度数据,构建为定位数据样本集;
S2、采用广义最小误差熵卡尔曼滤波对定位数据样本集中定位数据样本进行滤波处理,得到修正定位数据。
所述步骤S2包括以下分步骤:
S21、将定位数据样本初始值带入预测方程,得到定位数据样本预测值;
所述步骤S21中预测方程为:
其中,
S22、根据定位数据样本预测值和定位数据样本集中定位数据样本,计算定位数据样本误差值;
所述步骤S22中计算定位数据样本误差值的公式为:
其中,ε
S23、根据定位数据样本误差值和增广噪声矩阵,计算增广噪声矩阵的协方差矩阵的分量;
所述步骤S23包括以下分步骤:
S231、根据定位数据样本误差值,计算定位数据样本的增广噪声矩阵;
所述步骤S231中计算定位数据样本的增广噪声矩阵的公式为:
其中,μ
S232、根据定位数据样本的增广噪声矩阵,计算增广噪声矩阵的协方差矩阵的分量。
所述步骤S232中计算增广噪声矩阵的协方差矩阵的分量的公式为:
其中,Θ
S24、根据增广噪声矩阵的协方差矩阵的分量和定位数据样本预测值,构建广义最小误差熵卡尔曼滤波模型;
所述步骤S24中广义最小误差熵卡尔曼滤波模型为:
其中,
对D
L=m+n (11)
将
将Θ
则:
其中,
S25、根据广义最小误差熵卡尔曼滤波模型,对估计定位数据样本进行更新,得到更新估计定位数据样本;
S26、判断更新估计定位数据样本是否满足误差条件,若是,则更新估计定位数据样本为修正定位数据,若否,直接跳转至步骤S25中。
所述步骤S26中误差条件为:
其中,
本发明提出的广义最小误差熵卡尔曼滤波模型的广义高斯核函数为公式(18):
其中,G
根据公式(18)可知,当形状参数α的值改变时,广义高斯核函数的形状就会发生明显的变化,从而可以使广义最小误差熵卡尔曼滤波模型能够灵活处理不同非高斯分布的噪声,提高了水下航行定位估计的精度。当形状参数设置为1或2时,广义高斯核函数的分布变成拉普拉斯分布或高斯分布。
在广义最小误差熵准则里,误差e由Renyi’s熵来测量:
其中,μ为Renyi熵的阶数;V
V
其中,p
其中,
当信息势能的阶数为2时,可得:
其中,
实验:
在混合高斯噪声条件下,将本发明中构建的广义最小误差熵卡尔曼滤波模型(GMEEKF)分别与卡尔曼滤波算法(KF)、最大相关熵卡尔曼滤波算法(MCKF)、MEEKF算法、robust student’s t-based卡尔曼滤波算法(RSTKF)进行对比:
混合高斯噪声模型如下:
其中,r为混合高斯噪声,λ为加权系数,
若其分布服从式(23),则称该分布服从混合高斯噪声分布,即r~M(λ,a,μ
在以下的实验中,考虑一个匀速轨迹跟踪模型,定位数据样本方程和轨迹方程如下所示:
其中,x
考虑过程噪声为高斯分布q
由图2可知:广义最小误差熵卡尔曼滤波模型GMEEKF在混合高斯噪声中表现最佳,对水下无人航行器的定位的精度最高。
综上,本发明实施例的效果为:根据公式(18)可知,本发明中的α和β的值可以改变,因此,广义高斯核函数的形状可以灵活变化,使得广义最小误差熵卡尔曼滤波模型可以灵活处理不同分布类型的非高斯噪声,提高了水下航行定位的精度。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。