一种深度强化学习的高效学习方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及无人车路径规划技术领域,具体涉及一种深度强化学习的高效学习方法。
背景技术
近年来,深度强化学习(Deep Reinforcement Learning,DRL)得到了广泛发展。有研究表明DRL具有解决复杂高维状态空间上决策问题的能力。DeepMind公司提出的AlphaGo在围棋领域取得了巨大胜利,将DRL的研究推向了一个新的高度。DRL在视频游戏、机器人、智能驾驶、推荐系统等诸多领域得到了广泛的研究。同时DRL已经被验证在解决NP-hard问题方面具有巨大的潜力,如旅行商问题(TSP)。
路径规划作为典型的NP-hard问题也受到越来越多学者的广泛关注。但是,基于DRL的路径规划方法在规划较大尺寸地图时,存在网络学习效率低,收敛困难等问题。
发明内容
有鉴于此,本发明实施例提供了一种深度强化学习的高效学习方法,以解决现有技术中采用基于DRL的路径规划方法在规划较大尺寸地图时,存在网络学习效率低和收敛困难的问题。
本发明实施例提供了一种深度强化学习的高效学习方法,包括:
将全局地图观测信息输入至动态全局通道;
将局部地图观测信息输入至动态局部通道;
通过多目标奖励函数对无人车的能耗和行驶时间进行评价;
在每个训练过程中,从经验缓冲池中提取到达目标位置的若干历史经验数据作为训练集;
其中,动态全局通道与动态局部通道为深度强化学习模型的两个并联输入通道;动态全局通道的输入层设置为三层图像输入;第一层图像输入用于存放当前规划点的位置信息;第二层图像输入用于存放目标位置信息;第三层图像输入用于存放三维地图数据;动态局部通道的输入层设置为一层图像输入;以当前规划点为中心向外扩展10个单位步长,形成的矩形在原始地图中截取的部分即为局部地图观测信息;深度强化学习模型采用基于优先经验重播的深度强化学习探索策略。
可选地,动态全局通道的卷积主干层由第一卷积层和第二卷积层组成;在第一卷积层和第二卷积层之间设置一个最大池化;
动态局部通道的卷积主干层由第三卷积层和第四卷积层组成。
可选地,动态全局通道的输入大小为100*100*3;第一卷积层的卷积核大小为8*(3*3*3),第二卷积层的卷积核的大小为16*(3*3*8);最大池化的池化核尺寸为2*2,步长设置为3;
动态局部通道的输入大小为20*20*1;第三卷积层的卷积核的大小为4*(3*3*1),第四卷积层的卷积核的大小为10*(3*3*4);
第一卷积层、第二卷积层、第三卷积层和第四卷积层的激活函数均采用ReLu函数。
可选地,在动态全局通道的卷积主干层的输出和动态局部通道的卷积主干层的输出通过全连接层进行拼接后,引出第一分支输出和第二分支输出;将第一分支输出和第二分支输出线性连接,形成的输出节点用于表示各个方位动作的Q值;
其中,第一分支输出的第一层设置128个节点;第一分支输出的第二层设置8个节点;第一分支输出用于评价8个方位的动作质量;第二分支输出的第一层设置128个节点;第二分支输出的第二层设置1个节点;第二分支输出用于预测状态价值;第一分支输出的第一层和第二分支的第一层的激活函数采用ReLu函数;第一分支输出的第二层和第二分支的第二层的激活函数采用线性函数。
可选地,当前规划点用6*6*1大小的图像表示;目标位置用5*5*1大小的图像表示。
可选地,三维地图数据的获取包括:
以当前规划点位置与目标位置的连线作为对角线形成一个矩形区域;将矩形区域内的地图居中,并将地图的各边界分别向外扩展10个单位步长;将扩展后的地图周围用0补边形成100*100*1的地图图像。
可选地,多目标奖励函数包括:能耗奖励函数、耗时奖励函数、撞墙奖励函数和目标位置奖励函数。
可选地,撞墙奖励函数包括:
根据撞墙惩罚的强度因子和撞墙惩罚的敏感值分别对横轴方向和纵轴方向进行惩罚项计算。
可选地,基于优先经验重播的深度强化学习探索策略包括:
获取无人车在三维环境中的训练样本;训练样本为状态动作序列;
将无人车在训练过程中的训练样本存储在第一经验缓冲池中;将到达目标位置的训练样本存储在第二经验缓冲池中;其中,到达目标位置的训练样本的判断条件为:当前训练样本的奖励得分大于0;
当第一经验缓冲池/第二经验缓冲池中的训练样本数量达到上限时,删除最先存储的训练样本数据,并保存最新的训练样本数据;
当第一经验缓冲池中的训练样本数量达到预设值时,开始训练网络。
本发明实施例的有益效果:
本发明实施例提出了一种深度强化学习的高效学习方法,应用于无人车路径规划,通过构建一种新型双通道并联网络模型,该新型双通道并联网络包含两个通道,分别是动态全局通道和动态局部通道。从全局地图和局部地图两个视角,显著提高深度强化学习方法关注三维地形,提高了观测状态与动作奖励的相关性。
附图说明
通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
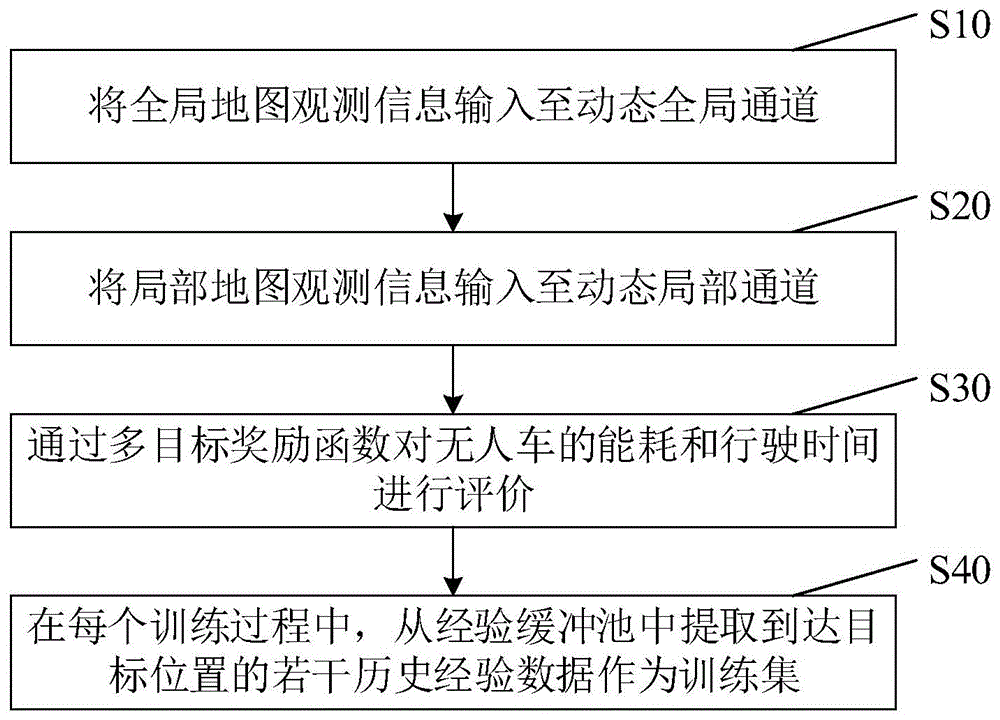
图1示出了本发明实施例中一种深度强化学习的高效学习方法的流程图;
图2示出了本发明实施例中一种深度强化学习的高效学习方法的新型双通道并联网络框架示意图;
图3示出了本发明实施例中一种深度强化学习的高效学习方法的新型双通道并联网络的输入设置示意图;
图4示出了本发明实施例中一种深度强化学习的高效学习方法的经验缓冲池示意图;
图5示出了本发明实施例中一种深度强化学习的高效学习方法的训练策略示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种深度强化学习的高效学习方法,应用于无人车路径规划,如图1所示,包括:
步骤S10,将全局地图观测信息输入至动态全局通道。
步骤S20,将局部地图观测信息输入至动态局部通道。
在本实施例中,构建一种新型双通道并联网络模型,该新型双通道并联网络包含两个通道,分别是动态局部通道和动态全局通道。构建新型双通道并联网络的输入,分别为动态全局通道的全局地图观测信息和动态局部通道的局部地图观测信息,引导深度强化学习方法关注三维地形。
在具体实施例中,动态全局通道与动态局部通道为深度强化学习模型的两个并联输入通道。动态全局通道的输入层设置为三层图像输入:第一层图像输入用于存放当前规划点的位置信息,第二层图像输入用于存放目标位置信息,第三层图像输入用于存放三维地图数据。动态局部通道的输入层设置为一层图像输入。以当前规划点为中心向外扩展10个单位步长,形成的矩形在原始地图中截取的部分即为局部地图观测信息。
步骤S30,通过多目标奖励函数对无人车的能耗和行驶时间进行评价。
在本实施例中,综合考虑三维地图中无人车的能耗与行驶时间,设计奖励函数,奖励函数包括四个部分,分别是能耗奖励、耗时奖励、撞墙奖励和目标位置奖励。
步骤S40,在每个训练过程中,从经验缓冲池中提取到达目标位置的若干历史经验数据作为训练集。
在本实施例中,设计基于优先经验重播的深度强化学习探索策略,设计经验缓冲池收集到达目标位置的经验,在每个训练过程中,该并联网络从缓冲池中提取一批经验训练,通过提高有效数据的利用率来促进网络学习。
在本实施例中,通过构建一种新型双通道并联网络模型,该新型双通道并联网络包含两个通道,分别是动态全局通道和动态局部通道。从全局地图和局部地图两个视角,显著提高深度强化学习方法关注三维地形,提高了观测状态与动作奖励的相关性。
作为可选的实施方式,如图2所示,动态全局通道的卷积主干层由第一卷积层和第二卷积层组成;在第一卷积层和第二卷积层之间设置一个最大池化;动态局部通道的卷积主干层由第三卷积层和第四卷积层组成。由于动态局部通道的作用就是为网络提供原始的地形信息,因此动态局部通道不设池化层。
作为可选的实施方式,动态全局通道的输入大小为100*100*3;第一卷积层的卷积核大小为8*(3*3*3),第二卷积层的卷积核的大小为16*(3*3*8);最大池化的池化核尺寸为2*2,步长设置为3。
动态局部通道的输入大小为20*20*1;第三卷积层的卷积核的大小为4*(3*3*1),第四卷积层的卷积核的大小为10*(3*3*4)。
第一卷积层、第二卷积层、第三卷积层和第四卷积层的激活函数均采用ReLu函数。
作为可选的实施方式,在动态全局通道的卷积主干层的输出和动态局部通道的卷积主干层的输出通过全连接层进行拼接后,引出第一分支输出和第二分支输出;将第一分支输出和第二分支输出线性连接,形成的输出节点用于表示各个方位动作的Q值。其中,第一分支输出的第一层设置128个节点;第一分支输出的第二层设置8个节点;第一分支输出用于评价8个方位的动作质量;第二分支输出的第一层设置128个节点;第二分支输出的第二层设置1个节点;第二分支输出用于预测状态价值;第一分支输出的第一层和第二分支的第一层的激活函数采用ReLu函数;第一分支输出的第二层和第二分支的第二层的激活函数采用线性函数。
全连接层有三个部分:第一部分连接两个通道的最后一层,将两个通道的输出拼接,然后将拼接后的结果引出两个分支,每个分支有两层。第一个分支第一层有128个节点,第二层有8个节点,用于评估8个方位的动作好坏;另一个分支用于预测状态价值,第一层有128个节点,第二层有1个节点。两个分组第一层和第二层的激活函数分别为ReLu函数和线性函数。最后,将两个分支线性连接,输出8个节点,表示8个方位动作的Q值。
作为可选的实施方式,当前规划点用6*6*1大小的图像表示;目标位置用5*5*1大小的图像表示。
作为可选的实施方式,如图3所示,三维地图数据的获取包括:
以当前规划点位置与目标位置的连线作为对角线形成一个矩形区域。
将矩形区域内的地图居中,并将地图的各边界分别向外扩展10个单位步长。将扩展后的地图周围用0补边形成100*100*1的地图图像。
将包含当前规划点和目标位置点的100*100*1的两层图像与前述地图图像组成100*100*3的输入图像。随着当前规划点的移动获取全局动态通道的输入图像,直至训练结束。
作为可选的实施方式,多目标奖励函数包括:能耗奖励函数、耗时奖励函数、撞墙奖励函数和目标位置奖励函数。其中,撞墙奖励函数包括:根据撞墙惩罚的强度因子和撞墙惩罚的敏感值分别对横轴方向和纵轴方向进行惩罚项计算。
在本实施例中,计算奖励函数的公式如下:
R=R
式中,R表示无人车从当前位置行驶到相邻位置的总奖励。
R
R
式中,f
式中,H
式中,(x
式中,当z
式中,e
E
E
E
式中,ρ表示滚动摩擦系数,ρ=0.01。
E
式中,C
因此,上坡能耗与平路能耗的比例关系:
当z
/>
式中,e
R
R
式中,f
式中,H
R
r
式中,γ是撞墙惩罚的强度因子,γ=15,分别表示横轴方向的惩罚和纵轴方向的惩罚,各惩罚项的计算公式如下:
式中,s
R
如图4和图5所示,无人车在三维环境中训练采集的数据为状态-动作序列,即四元组(s
S1,获取无人车在三维环境中的训练样本;训练样本为状态动作序列。
S2,将无人车在训练过程中的训练样本存储在第一经验缓冲池中;将到达目标位置的训练样本存储在第二经验缓冲池中;其中,到达目标位置的训练样本的判断条件为:当前训练样本的奖励得分大于0。
在本实施例中,将无人车在训练过程中的训练样本存储在经验缓冲池memory中,并将到达目标位置的训练样本存储在另一个缓冲池memory_d中,到达目标位置的样本判断条件为:
scort>0
式中,scort是无人车在一个训练回合的奖励,由前述的奖励函数可知,能耗奖励、耗时奖励、撞墙奖励均为负数,只有无人车到达目标位置,奖励才是正数。
S3,当第一经验缓冲池/第二经验缓冲池中的训练样本数量达到上限时,删除最先存储的训练样本数据,并保存最新的训练样本数据。
设置两个经验缓冲池的大小为10000,当经验池中的样本数量达到10000时,删除最先存储的样本,并保存新的样本。随着训练的推进,无人车的规划策略会越来越好,因此产生的样本会有更高的奖励。
S4,当第一经验缓冲池中的训练样本数量达到预设值时,开始训练网络。
当缓冲池memory中的样本数量等于500时,开始训练网络,每次训练使用的样本批次大小为N
N
式中,N
为解决现有基于DRL的路径规划方法存在规划大尺寸地图时,网络学习效率低,收敛困难的问题,本发明提供一种用于路径规划的深度强化学习的高效学习方法,通过构建一种新型双通道并联网络模型,该新型双通道并联网络包含两个通道,分别是动态全局通道和动态局部通道。从全局地图和局部地图两个视角,显著提高深度强化学习方法关注三维地形,提高了观测状态与动作奖励的相关性,促进网络高效学习。并将该方法用于三维地形中无人车的路径规划,为该行业的发展提供新的推动力。
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。