高速大容量聚合式交叉节点输出联合排队的交换系统
文献发布时间:2024-01-17 01:14:25
技术领域
本发明属于分组交换架构技术领域,具体涉及一种高速大容量聚合式交叉节点输出联合排队的交换系统。
背景技术
当前交换结构可以按照排队策略分为输入排队(Input Queued,IQ)、输出排队(Out Queued,OQ)、输入输出联合排队(Combined Input and Output Queued,CIOQ)以及输入交叉节点联合排队结构(Combined Input and Crosspoint Queued,CICQ)。
输入排队结构(IQ)就是在Crossbar交换网络前的输入端口处设置缓存,先将输入的数据分组存放在缓存内,然后再通过特定的队列调度算法来调度数据分组出队,经过Crossbar结构传输到输出端口处。由于Crossbar交换网络每条输出通道所连接的输出端口的输出速率是有限的,且输出端口处和Crossbar节点不设置排队缓存,需要在输出端口空闲时才能让各输入缓存的队列调度数据分组出队,因此对于Crossbar网络的单条通道来说,通道传输速率只需与输出端口的输出速率相同即可。此时该结构加速比(交换结构内部速率与端口速率比值)为1,对于交换结构内部速率与缓存写入读取速率没有太高要求,可扩展性较好。输入排队结构在输入缓存只有单个先入先出(FIFO:First-In-First-Out)队列时,会存在排头阻塞(Head of Line,HOL)阻塞问题,当端口数较多时,会严重降低交换容量,比如所有输出端口均匀分布的Bernoulli业务下,该结构只有58.6%的吞吐率。对于该问题,可以通过虚拟输出队列(Virtual Output Queue,VOQ)技术在输入缓存处按照输出端口设置队列,以区别不同去向的数据分组。不过因为要区分多个队列,类似于共享缓存结构,为了保障队列之间的公平性,也自然要为每个队列分配一定的缓存,如果端口数提升导致划分队列数增多,那么每个输入端口处对于缓存资源的要求也会变高。
输出排队结构(OQ)则是在输出端口处设置排队缓存,输入的数据分组先经过Crossbar交换网络交换到对应输出端口,然后再进入缓存排队。由于该结构在输入处和Crossbar网络内部均不设置排队缓存,当所有N个输入端口同时输入去向相同输出端口的分组时,为保证此时不出现分组丢失,输出排队处的接收带宽需要达到输入端口的至少N倍线速(输入端口速率相同),即加速比需要达到N。可以看出,本质上这种结构还是共享缓存,只不过是将单通道的共享缓存拆成了多条通道、分布式的共享缓存交换,自然也就继承了共享缓存的缺点。
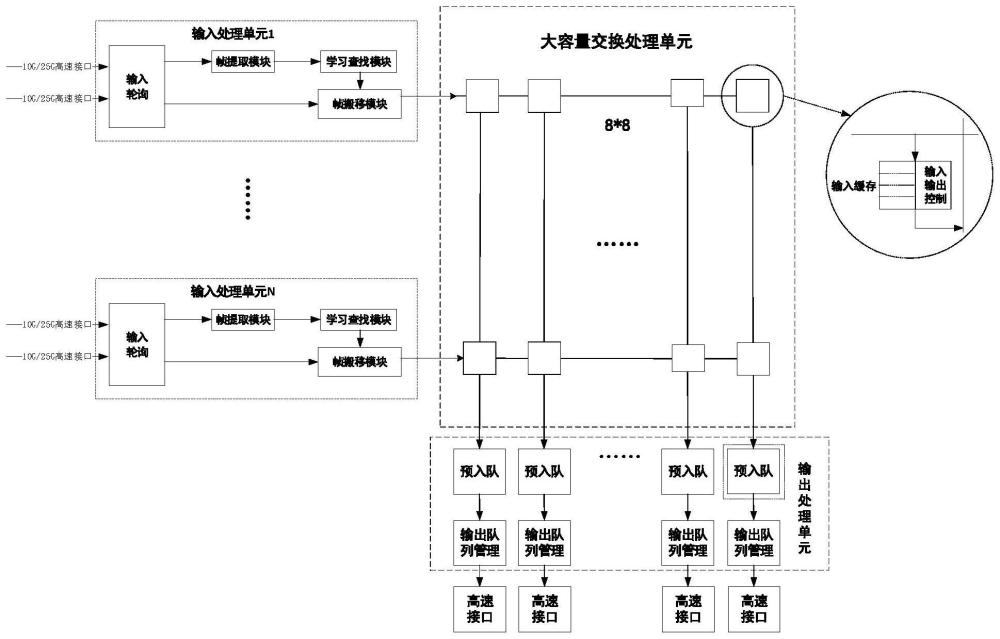
输入输出联合排队结构(CIOQ)算是输入排队和输出排队的折衷,在输入端口和输出端口处同时设置缓存,并且设置Crossbar交换网络具有一定的加速比s。输入端口缓存的设置可以解决输出排队结构N倍加速比的问题,可以使1 输入交叉节点联合排队结构(CICQ)是输入排队(IQ)和交叉节点带缓存排队(Crosspoint Queued,CQ)的结合,与输入排队的区别主要是在交叉节点上设置了用于排队的一定数量缓存。这种方法有效隔离了输入端和输出端,尤其是在进一步发展的输入交叉节点输出联合排队结构中,交叉节点的缓存隔离了输入和输出的队列调度,使得输入和输出可以分别采用不同的调度算法,降低了单个算法的复杂度,而且分布式的结构也很适合用于多片FPGA联合实现。随着端口数目的增加,该结构下对于缓存资源的依赖也越来越高,输入排队和交叉节点处的缓存均与端口数目N存在着O(N 通过以上分析,现有技术存在的问题及缺陷为: (1)现有易于FPGA实现的交换架构技术,如输入排队结构(IQ)、输入交叉节点联合排队结构(CICQ)和输出排队结构(OQ),都存在随着端口数目、端口速率、端口位宽的增加,对缓存资源的依赖也越来越高。 (2)输入输出联合排队结构(CIOQ)可以解决输入排队结构VOQ机制对缓存资源需求大的问题,但该结构上调度算法要同时处理输入和输出排队的队列,复杂性较高,不利于FPGA实现。 (3)现有易于FPGA实现的交换架构技术,如输出排队结构(OQ),当所有N个输入端口同时输入去向相同输出端口的分组时,为保证此时不出现分组丢失,输出排队处的接收带宽需要达到输入端口的至少N倍线速,即加速比需要达到N。 (4)现有易于FPGA实现的交换架构技术,只适用于低速、小位宽、小交换容量,对于高速大容量交换实用性不高。 发明内容 为了解决现有技术中存在的上述问题,本发明提供了一种高速大容量聚合式交叉节点输出联合排队的交换系统。本发明要解决的技术问题通过以下技术方案实现: 本发明提供了一种高速大容量聚合式交叉节点输出联合排队的交换系统包括:输入处理模块、大容量交换处理单元和输出处理模块; 所述输入模块,用于对输入的所有以太网帧数据进行聚合轮询,并查找和学习与以太网帧数据匹配的帧信息,从而将以太网帧数据写入大容量交换处理单元中对应的交叉节点; 所述大容量交换处理单元,用于对写入的以太网帧数据按照优先级进行仲裁以及调度,以产生入队请求; 所述输出处理模块,用于根据入队请求决定调度出的以太网帧数据是否入队还是丢弃,并且当自身队列有以太网帧数据时进行出队。 本发明提供了一种高速大容量聚合式交叉节点输出联合排队的交换系统,由输入处理、大容量交换处理单元Crossbar中的交叉节点和输出队列管理组成。输入处理模块采用流水线结构,可以保证每个时钟都可以传输数据,可以聚合更多的端口,减少大容量交换处理单元Crossbar缓存占用和输出队列数。大容量交换处理单元中的交叉节点采用Fifo形式,可以提高缓存利用率;交叉节点仲裁时设置数量阈值,可以在减少缓存的同时为高优先级提供更好的Qos,此外本发明用缓存隔离大容量交换处理单元和输出队列管理,可以使大容量交换处理单元和输出队列管理,处理效率更高,采用输出队列管理,可以大大减少队列数。 以下将结合附图及实施例对本发明做进一步详细说明。 附图说明 图1是本发明实施例提供的高速大容量聚合式交叉节点输出联合排队的交换系统的结构图; 图2是本发明实施例提供的多路分组进行聚合轮询的流程图; 图3是本发明实施例提供的输入处理中学习查表模块4级流水线结构图; 图4是本发明实施例提供的输入处理中学习查表模块4级流水线流程图; 图5是本发明实施例提供的输入处理中帧搬移模块3级流水线结构图; 图6是本发明实施例提供的输入处理中帧搬移模块3级流水线流程图; 图7是本发明实施例提供的大容量交换处理单元Crossbar中的交叉节点的结构图; 图8是本发明实施例提供的大容量交换处理单元Crossbar中的交叉节点和输出队列管理Outstanding流程图。 具体实施方式 下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。 如图1所示,本发明提供了一种高速大容量聚合式交叉节点输出联合排队的交换系统,包括:输入处理模块、大容量交换处理单元和输出处理模块; 所述输入模块,用于对输入的所有以太网帧数据进行聚合轮询,并查找和学习与以太网帧数据匹配的帧信息,从而将以太网帧数据写入大容量交换处理单元中对应的交叉节点; 值得说明的是:聚合是指将多个端口合并成一条总线,可以降低大容量交换处理单元Crossbar节点占用的缓存资源,提高总线利用率。聚合端口采用LocalLink格式,当端口有分组时会提前拉高send_data_flag标志信号,表示该端口有分组需要进入输入处理。当轮询输出总线空闲时只有一路send_data_flag标志拉高,这种情况就输出总线占用权给这一路端口分组,在输出总线繁忙的时候总线占用权不变。在总线空闲的时候有多路send_data_flag信号拉高,通过拉高LocalLink的ready信号来表示轮询输出总线交给哪个端口。为了公平性,采用RR轮询的方式。 所述大容量交换处理单元,用于对写入的以太网帧数据按照优先级进行仲裁以及调度,以产生入队请求; 所述输出处理模块,用于根据入队请求决定调度出的以太网帧数据是否入队还是丢弃,并且当自身队列有以太网帧数据时进行出队。 参考图1,本发明中的所述输入处理模块包括输入轮询模块、帧提取模块、学习查找模块和帧搬移模块;所述输出处理模块包括预入队模块和输出队列管理模块; 所述输入轮询模块,用于通过多路并行高速端口接收以太网帧数据,每路的以太网帧数据表示一个分组,将多路并行的分组进行聚合轮询从而形成一路串行的分组,之后存入所述帧搬移模块的RAM中; 参考图2,图2展示了本发明中高速端口、分组、以太网帧数据、聚合轮询细节,从图2中可以看出多路分组最终形成了一路串行的分组。轮询的分组存储在所述帧搬移模块的RAM中,RAM分为9段,每段容纳一个最长帧,当查找到目的端口号就根据目的端口号进入大容量交换处理单元Crossbar对应节点。 帧提取模块,用于提取分组的源MAC、目的MAC、源端口号,供学习查找模块进行学习和查找; 学习查找模块,用于根据源MAC、目的MAC以及源端口号,均利用四级流水的方式进行查找和学习,从而从查找表和学习表中找到符合的帧信息; 其中,帧信息包括目的端口、分组优先级、帧长、帧类型; 帧搬移模块,用于从自身的RAM中读出对应的分组,将该分组根据帧信息写入所述大容量交换处理单元的交叉节点中; 大容量交换处理单元,用于对自身交叉节点写入的分组按照优先级进行仲裁,从而决定是存入自身的单播缓存fifo还是多播缓存fifo中; 预入队模块,用于缓存交叉节点列仲裁后的分组,并隔离大容量交换处理单元和输出队列管理,并将分组搬移到总线上; 输出队列管理模块,用于采用共享缓存的形式从总线上读取分组,并缓存,对分组进行逻辑入队、物理入队、逻辑出队和物理出队中至少一项操作。 聚合式联合交叉节点和输出排队交换架构,这种架构相比于输入队列管理大大降低了队列管理的队列数和缓存数,降低了对缓存的依赖。 输入处理模块整体采用流水线和Outstanding架构,可以更加适配高速大容量的需求,满足搬移总线每个时钟都可以传输数据,端口聚合程度可以更高。高聚合下可以减少总线数量,交叉节点数量为总线数目的平方,即减少总线数量就可以减少交叉节点数目,降低缓存占用。 大容量交换处理单元Crossbar中的交叉节点内设置阈值,可以保证高优先级的Qos,列仲裁采用多级列仲裁的形式,可以避免布线拥塞;输出处理中用预入队模块隔离输出队列管理和大容量交换处理单元Crossbar中的交叉节点,使队列管理和大容量交换处理单元Crossbar中的交叉节点Outstanding,减少调度复杂度,提高调度效率。 如图3所示,本发明实施例提供了一种在高速大容量下四级流水线学习查找过程的示意图。如图4所示,左图为查找四级流水线流程图,右图为学习四级流水线流程图。四级流水线第一级为哈希、第二级为查表、第三级为对结果进行处理、第四级为写回。 所述学习查找模块中利用四级流水的方式进查找的步骤包括: 当收到有效源MAC地址时,流水线开始工作; 流水线第一级用于对源MAC和目的MAC进行哈希操作; 流水线第二级用于根据源MAC的哈希结果去读查找表; 流水线第三级用于对从查找表中读取的结果进行处理,处理过程包括:比较查找表读出的结果中源MAC地址和本次目的MAC地址是否一样,如果一样则目的端口就是查找表读出结果中源端口号;如果不一样,则将该分组广播,发往每个端口; 流水线第四级用于将源MAC作为查询地址,并将源MAC、源端口号、当前时间作为数据,按照查询地址将数据写入进查找表中。 所述学习查找模块中利用四级流水的方式进行学习的步骤包括: 当收到有效MAC地址时,流水线开始工作; 流水线第一级用于对源MAC和目的MAC进行哈希操作; 流水线第二级用于利用源MAC的哈希结果去读学习表; 流水线第三级用于对从查找表中读取的结果进行处理,处理过程包括:比较学习表读出的结果中源端口号与本次源端口号是否一样,如果不一样且冲突检测开启,那么就学习失败,记录冲突端口与源MAC,流水线结果;如果不一样但是冲突检测没有开启,则进入流水线第四级; 流水线第四级用于将源MAC作为查询地址作为学习表的地址,将源MAC、源端口号、当前时间作为数据,按照查询地址将数据写入进学习表中。 学习查表的四级流水有两个旁路:邻级旁路和隔级旁路。邻级旁路是指查表的地址和上一级查表的地址一样,那么把上级对结果处理的内容作为当前查表得到的结果进行处理。隔级旁路是指上上级的写回地址和当前查表地址一样,那么把上上级写回的内容作为当前查表得到的结果进行处理。 如图5所示,本发明实施例提供了一种在高速大容量下三级流水线帧搬移模块的示意图。如图6所示,本发明的帧搬移模块采用三级流水线形式,具体步骤如下: 当分组进行帧信息提取和学习查找时,轮询模块轮询出的分组会先进入帧搬移模块进行缓存。缓存为一块4KB的RAM,分为10段,每段是否空闲用一bit标识,所以维护一个10bit的ram_seg_valid信号,当每个bit对应段空闲时,对应bit就会置1,否则置0。当其中一段的数据被搬走一个clk时,就可以把对应ram_seg_valid的bit位置1.寻找ram_seg_valid第一个1,也就是寻找第一个可以存数据的段。寻找第一个1是组合逻辑,类似于2分法,当接收到数据时就可以知道该数据存储到哪一段。当查找到目的MAC时,会把源端口号、输出端口号、多播标志、帧优先级、数据帧存在哪一段、帧长、帧类型写进帧信息fifo中。当fifo不空时,且搬移总线空闲时,根据帧信息fifo数据去组帧tag:目的端口、帧优先级、帧长、帧类型。同时根据帧长和段数去读数据帧,将帧tag加到对应帧头部。当帧正在传输时,在帧搬移结束前一个钟组tag,读数据,目的在于在高速端口线速情况下每个钟都可以传输数据,提高带宽利用率。如果一个帧存放一个RAM中,例如256位宽,支持1522B长度,一个RAM就需要4个36Kbit。如果每个RAM独立分开,资源浪费90.8%。所以存储RAM需要合在一起用一个RAM,然后对地址进行分段。256位宽,512深度,可以支持10个最长帧,也就是可以分成10段,这样资源浪费7.11%。所以这样对RAM进行分段可以提高资源利用率。 当收到学习查表模块有的目的端口号,将目的端口号、源端口号、多播标志、优先级、存储段号、帧长、帧类型作为帧信息;帧信息fifo采用First-word-Fall-Through形式; 将帧信息存入自身的帧信息fifo中; 当帧信息fifo不空时,根据帧信息fifo中的帧长和分组RAM对应段计算分组存储的起始地址和帧长,同时读帧信息fifo,得到下一个分组的帧信息; 根据分组的起始地址和帧长去读自身的RAM从而得到分组; 给读取到的分组设置标签tag; 其中,标签tag包括:目的端口号、优先级、帧长、帧类型; 将携带标签tag的分组分给对应的交叉节点。 本发明将tag和数据拼起来,tag放到帧前面,然后一起搬移到总线上。tag信息用于大容量交换处理单元Crossbar列仲裁后根据tag信息去产生入队帧信息,请求入队。 输入处理整体采用流水线和Outstanding架构,可以更加适配高速大容量的需求。输入处理采用流水线和Outstanding架构,可以满足搬移总线每个时钟都可以传输数据,端口聚合程度可以更高。高聚合下可以减少总线数量,交叉节点数量为总线数目的平方,即减少总线数量就可以减少交叉节点数目,降低缓存占用。 如图7示,本发明实施例提供了一种在高速大容量下大容量交换处理单元Crossbar中的交叉节点的示意图,对应列仲裁为多级列仲裁,使布线资源更加均匀,在高速大位宽下,减缓布线拥塞。交叉节点中有单播和多播缓存fifo,每个缓存fifo为16KB。大容量交换处理单元包括多行多列,每一列存在一个列仲裁模块,行与列交叉形成交叉节点; 交叉节点为了在高速大容量下减少对缓存的依赖,这里不区分优先级。但为了提供更好的QoS,在交叉节点这里设置一个阈值,当交叉节点容量大于这个阈值时,只允许高优先级进入交叉节点,低优先级会被丢掉,低于这个阈值时,高优先级和低优先级都可以进入交叉节点,这样会为高优先级提供更好QoS。当大容量交换处理单元Crossbar对应列节点有数据时,会采用RR调度的形式对大容量交换处理单元Crossbar对应列进行列仲裁。在高速大容量大位宽下,为了减少布局布线拥塞,采用多级仲裁形式,将布局布线资源分布得更加均匀。 每个交叉节点,用于: 当收到分组后,判断该分组是单播还是多播,如果是单播则需要判断单播缓存fifo的存储数据量是否超过设定的数量阈值,如果超过了数量阈值,则根据标签tag的优先级将高优先级分组存入;如果没有超过这个设定的数量阈值,则高优先级和低优先级都允许进入单播缓存fifo; 如果分组是多播,则直接存入多播fifo中;当分组进入缓存fifo时,则根据帧长维护多播缓存fifo的剩余数据量;当多播缓存fifo有数据则会向列仲裁模块发出请求,该请求表示交叉节点有数据需要转发; 列仲裁模块,用于根据对应列交叉节点发出的请求进行RR轮询调度,调度的同时根据分组的标签tag生成入队请求,将入队请求发给输出队列管理;并将不带标签的分组送入预入队模块缓存。 本发明在单播缓存fifo中设置阈值,可以在高速大容量低缓存下保证高优先级分组的Qos,同时列仲裁为多级列仲裁,可以使布线资源更加均匀,在高速大位宽下,减缓布线拥塞。 如图8所示,本发明实施例提供了一种在高速大容量下预入队模块的过程示意图。大容量交换处理单元Crossbar的列仲裁调度方式和入队调度方式可以通过预入队模块进行隔离,分组的入队搬移和丢弃操作在该模块进行,不会影响大容量交换处理单元Crossbar列仲裁和入队调度的执行过程,减少调度复杂度,提高调度效率。在高速大容量下通过预入队模块使大容量交换处理单元Crossbar和输出队列管理Outstanding的具体步骤如下: 当收到列仲裁后的分组时,将分组写入自身数据缓存fifo中,同时将分组的帧长写入自身帧长fifo中; 帧长用于在读数据缓存或者丢弃分组时做一个偏移; 当收到入队ready信号,则根据帧长读数据缓存fifo,当对应分组读完时,会去读帧长fifo,得到下一个分组帧长信息;该帧长fifo采用First-word-Fall-Through方式,可以省去读fifo的时间;并将读出的分组搬移到总线上; 当收到入队失败信号,则会根据帧长对数据缓存做偏移,将对应分组丢弃。 预入队模块用来隔离列仲裁和入队调度,这样列仲裁和入队调度可以Outstanding,入队结果并不会影响列仲裁的处理带宽,分组处理效率会更高。 本发明中的队列管理的入队采用的是共享BD的形式进行。入队分为逻辑入队和物理入队。逻辑入队是指根据入队帧信息去读取相关队列信息,之后用这个队列信息、和门限进行入队判断:已用节点BD数+本次BD消耗数量是否大于最大节点最大门限;队列已用BD数+本次BD消耗数量是否超过队列最大门限;如果已用节点BD数大于节点最小门限,共享缓存区是否溢出;如果已用节点BD数小于节点最小门限,共享缓存区是否溢出。如果根据上述判断可以入队,则申请对应的BD数量,否则就拒绝入队。物理入队是指将对应的分组根据申请到的BD信息去写进对应的缓存中。 队列管理的出队采用的是共享BD的形式进行。出队分为逻辑出队和物理出队。逻辑出队是指根据队列号得到相关队列信息,产生出队调度。物理出队是指根据出队调度信息得到分组对应的存储地址,根据存储地址去取数据放到总线上输出。 本发明在系统上执行以下步骤可以实现系统的应用: S101,输入轮询模块将多个端口聚合,并进行RR公平轮询; S102,帧提取模块提取出分组的源MAC、目的MAC、源端口号; S103,学习查找模块采用流水线的形式进行学习查找; S104,帧搬移模块根据帧长段号读取数据,组tag标签,根据目的端口号把数据搬移到对应交叉节点; S105,列仲裁模块根据对应列交叉节点缓存情况进行RR调度,同时根据调度的分组tag头产生入队请求; S106,调度出来的分组进入预入队模块,等待入队结果,可以入队则进行物理入队,否则丢弃; S107,当队列有数据时进行逻辑出队和物理出队。 以上描述为本发明提供的高速大容量聚合式交叉节点输出联合排队的交换系统的方案细节。在本发明的系统中分组转发是基于聚合式交叉节点输出联合排队交换架构来与交换网络中设备进行数据交互。本发明总体分为输入处理、大容量交换处理单元Crossbar中的交叉节点、输出队列管理三部分。输入处理为了能够满足高速端口聚合下的速率,整体采用流水线的形式:学习查找模块为四级流水,分别为哈希、查表、对结果进行处理、写回。搬移模块为三级流水,分别为得到帧信息、组tag和读数据RAM、把数据搬移到总线,其中学习查找模块和搬移模块Outstanding。输入处理模块这样设计可以保证每个时钟都可以传输数据,可以聚合更多的端口,减少大容量交换处理单元Crossbar缓存占用和输出队列的队列数。 本发明的另一目的在于在高速大容量下,减少缓存的同时,可以保证分组高优先级的Qos,通过多级列仲裁,使布线资源更加均匀,在高速大位宽下,减缓布线拥塞。在大容量交换处理单元Crossbar中设置一个阈值,当大容量交换处理单元Crossbar节点缓存超过这个阈值时,只允许高优先级进入交叉节点缓存,低优先级会被丢掉,低于这个阈值时,高优先级和低优先级都可以进入交叉节点,这样可以保证高优先级的Qos。 本发明的另一目的在于将输入队列管理变成输出队列管理,可以大大降低队列数:设总线数为B,优先级为F,队列输出端口为N,则总的队列数Q=B×F×N。以六条总线,每个总线两个端口聚合为例,输入队列管理队列数=6×8×12,输出队列管理队列数=6×8×2,队列数降低了5倍。且大容量交换处理单元Crossbar和输出队列管理之间用缓存隔离,大容量交换处理单元Crossbar和输出队列管理Outstanding,分组效率更高。 此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。 尽管在此结合各实施例对本申请进行了描述,然而,在实施所要求保护的本申请过程中,本领域技术人员通过查看所述附图、公开内容、以及所附权利要求书,可理解并实现所述公开实施例的其他变化。在权利要求中,“包括”(comprising)一词不排除其他组成部分或步骤,“一”或“一个”不排除多个的情况。 以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 一种基于聚合式交叉节点的网络大容量交换装置
- 一种基于聚合式交叉节点的网络大容量交换装置