一种核糖体σ因子及其突变体和编码得到的蛋白在提升利普司他汀产量中的应用
文献发布时间:2023-06-19 09:51:02
技术领域
本发明属于微生物基因工程技术领域,具体涉及一种核糖体σ因子及其突变体和编码得到的蛋白在提升利普司他汀产量中的应用。
背景技术
利普司他汀的四氢衍生物-奥利司他作为目前通过美国FDA、欧盟EMA和中国SFDA认证的不抑制食欲,不作用于中枢神经系统的肥胖症治疗药物,全球超过4千万人服用并成功减重,是目前最畅销的减肥产品。作为长效的特异性胰脂肪酶抑制剂,能阻止甘油三酯水解为可被小肠粘膜吸收的游离脂肪酸和单酰基甘油,从而减少热量摄入,控制体重。而利普司他汀最初是从链霉菌Streptomyces toxytricini中分离得到,具有β-丙内酯结构单元,其2,3位分别被6碳烷基烃链和13碳烷基烃链所取代,13碳烷基烃链C5位上的羟基则和N-甲酸基-L-亮氨酸形成酯键。由于利普司他汀分子结构复杂,化学合成工艺复杂,需消耗大量的人力与物力。目前利普司他汀的生产主要采用半生物发酵工艺,相比化学方法减少了有毒溶媒的使用,大大减少了对环境造成污染,以及毒性物质残留。
目前,国内外对利普司他汀产生菌合成利普司他汀的研究主要采用单因素试验和正交设计实验相结合的方法,优化发酵培养基和发酵参数,如添加生物素和ATP对脂类和利普司他汀合成的影响(董惠钧等,添加生物素和ATP对毒三链霉菌脂类和利普司他汀合成的影响,中国医药工业杂志,2014,01期,第19-24页)。
核糖体σ转录因子是RNA聚合酶的重要组成部分,在原核生物的转录过程中发挥重要的作用。如在Streptomyces avermitilis中过表达frr会增加阿维菌素的产量(Li L etal,(2010)Over expression of ribosome recycling factor causes increasedproduction of avermectin in Streptomyces avermitilis strains.J Ind MicrobiolBiotechnol 37(7):673–679),但目前影响利普司他汀合成的核糖体σ转录因子未见报道。
发明内容
针对现有技术中的上述不足,本发明提供一种核糖体σ因子及其突变体和编码得到的蛋白在提升利普司他汀产量中的应用,本发明通过基因组测序及生物信息学分析对其核糖体因子进行比较分析,发现15个不同的核糖体因子,后通过评价,发现在Streptomycestoxytricini中过表达核糖体σ转录因子A和B能提高利普司他汀的产量,并提供两个核糖体σ转录因子A和B的突变体,及其在利普司他汀生产中的应用。
为实现上述目的,本发明解决其技术问题所采用的技术方案是:
一种核糖体σ因子在提升利普司他汀产量中的应用,该核糖体σ因子为核糖体σ因子A或核糖体σ因子B。
进一步地,核糖体σ因子A的核苷酸序列如SEQ ID NO.5所示,其编码的蛋白质的氨基酸序列如SEQ ID NO.6所示。
进一步地,核糖体σ因子B的核苷酸序列如SEQ ID NO.7所示,其编码的蛋白质的氨基酸序列如SEQ ID NO.8所示。
一种如上述所述的核糖体σ因子A的突变体,该突变体的核苷酸序列如SEQ IDNO.1所示。
进一步地,核苷酸编码的蛋白质的氨基酸序列如SEQ ID NO.2所示,与正常的核糖体σ因子A氨基酸序列相比,其第19位氨基酸替换为R,第327位氨基酸替换为G,第338位氨基酸替换为G,第344位氨基酸替换为F,第347位氨基酸替换为S,第538位氨基酸替换为T。
一种如上述所述的核糖体σ因子B的突变体,该突变体的核苷酸序列如SEQ IDNO.3所示。
进一步地,核苷酸编码的蛋白质的氨基酸序列如SEQ ID NO.4所示,与正常的核糖体σ因子B氨基酸序列相比,其第95位氨基酸替换为T,第274位氨基酸替换为S,第275位氨基酸替换为T,第351位氨基酸替换为V,第411位氨基酸替换为D。
上述核糖体σ因子A的突变体或其编码的蛋白质在提升利普司他汀产量中的应用。
上述的核糖体σ因子B的突变体或其编码的蛋白质在提升利普司他汀产量中的应用。
一种质粒,包括上述核糖体σ因子、核糖体σ因子A的突变体,或核糖体σ因子B的突变体。
一种转基因细胞系,包括上述核糖体σ因子、核糖体σ因子A的突变体,或核糖体σ因子B的突变体。
一种工程菌,包括上述核糖体σ因子、核糖体σ因子A的突变体,或核糖体σ因子B的突变体。
进一步地,通过将含有所述编码基因的表达载体导入链霉菌Streptomycestoxytricini中进行过表达。
进一步地,该基因或突变基因位于质粒或染色体中。
本发明的有益效果为:
通过对10个核糖体因子的筛选研究,表明其中核糖体σ因子A和B及其突变体基因在链霉菌Streptomyces toxytricini过表达,不仅对基因工程菌生物安全(在菌内过表达未对菌体的生长造成影响),同时可以有效的提高链霉菌Streptomyces toxytricini生产利普司他汀的能力。实验数据表明其中对于原始基因在Streptomyces toxytricini过表达提高产利普司他汀的能力,尤其是它们的突变体基因过表达能更进一步提高产利普司他汀的能力。
附图说明
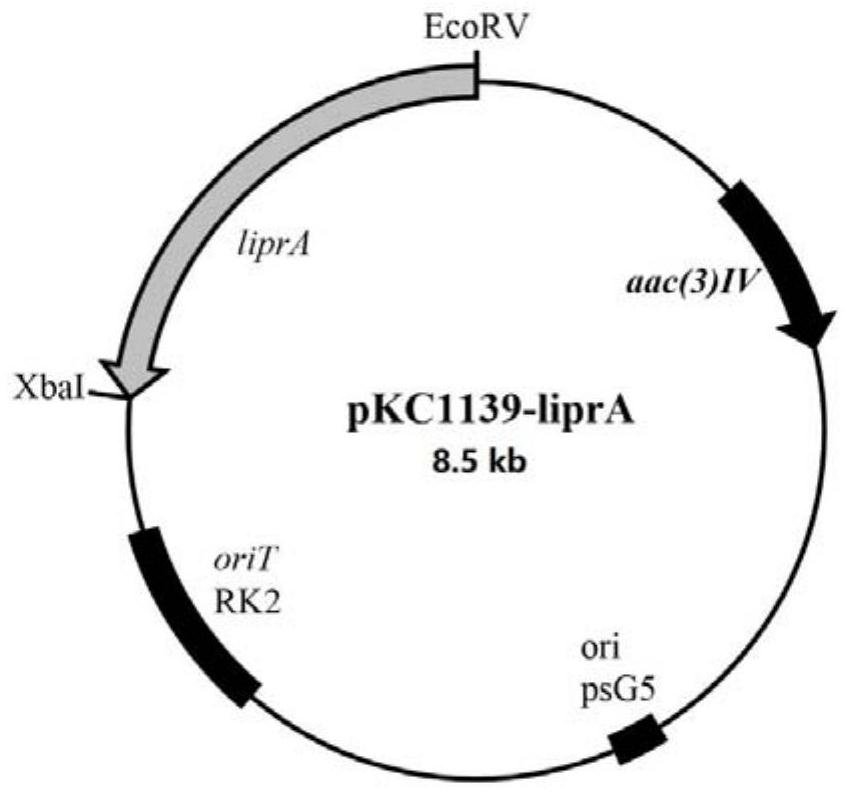
图1为质粒载体pKC1139-liprA的图谱、
图2为质粒载体pKC1139-liprB的图谱、
图3为质粒载体pKC1139-liprA-mut的图谱、
图4为质粒载体pKC1139-liprB-mut的图谱、
图5为利普司他汀浓度标准曲线。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
1、材料
Streptomyces toxytricini作为典型的链霉菌,其基内菌丝分枝,气生菌丝稍粗,部分气生菌丝分化为螺旋形的孢子丝,具有典型的链霉菌属的特征。
培养基配方:
种子培养基:10g of soya bean flour、5g of Bacto soytone、5mL ofglycerol、10mL of soya oil、and 2mL of Triton X-100[pH 6.5]per liter。
发酵培养:30g of soya bean flour、14mL of glycerol、1g of Bacto soytone、1mL of Triton X-100、and 60mL of soya oil[pH 7.0]per liter。
2、检测方法
(1)样品预处理
取发酵液1mL置于10mL离心管中,加入9mL的甲醇,置于漩涡混和器混匀,超声处理30min,离心(12000rpm,5min)后用0.22μm滤器过滤,取滤液(20μL)用于HPLC分析。
(2)标准品的制备
配置利普司他汀标准品(0.125g/L,0.25g/L,0.5g/L,1g/L,2g/L)
(3)HPLC检测条件
色谱柱:YMC-Pack ODS-A;检测波长:205nm;流动相:乙腈:水=90:10;流速:1.0mL/min;柱温:40℃。
(4)利普司他汀标准曲线的绘制
将不同浓度的标准品按上述条件进行HPLC检测,绘制峰面积利普司他汀浓度标准曲线。以测得的峰面积A为纵坐标,利普司他汀质量浓度C(g/L)记为横坐标,绘制利普司他汀标准曲线。见图5,得回归方程y=5E+6x+101960,R
实施例1菌株的获得
将冻存的菌株稀释涂布于ISP3平板培养基上,放置在30摄氏度水合培养箱中倒置培养,待菌落长出,挑出单菌落重新培养并传至2代。取一个长好的新鲜平板,用10mL无菌水洗下表面孢子,置于装有玻璃珠的三角瓶中,28摄氏度,200r/min振荡培养2~3h,过滤后系列稀释,制成孢子浓度约1×10
实施例2菌株基因组分析
将菌株Streptomyces toxytricini送华大基因公司进行全基因组测序,通过基因组测序及生物信息学分析对其核糖体因子进行比较分析,发现15个不同的核糖体因子,通过筛选发现,过表达核糖体σ转录因子A和B能提高利普司他汀的产量。
基于筛选得到的核糖体σ转录因子A和B,通过核苷酸的取代,分别得到核糖体σ因子A的突变体基因和核糖体σ因子B的突变体基因,其核苷酸序列分别如SEQ ID NO.1和SEQID NO.3所示;
同时得到相应的氨基酸突变体,具体为:
核糖体σ因子A的突变体:核糖体σ转录因子A编码的氨基酸序列的第19位氨基酸替换为R,第327位氨基酸替换为G,第338位氨基酸替换为G,第344位氨基酸替换为F,第347位氨基酸替换为S,第538位氨基酸替换为T。
核糖体σ因子B的突变体:核糖体σ转录因子B编码的氨基酸序列的第95位氨基酸替换为T,第274位氨基酸替换为S,第275位氨基酸替换为T,第351位氨基酸替换为V,第411位氨基酸替换为D。
再分别验证经取代后的突变体在菌株中过表达对利普司他汀产量的影响。
实施例3质粒的构建
1、pKC1139-liprA的构建
分别利用表1的引物对liprA-XbaI-F和liprA-EcoRV-R,以Streptomycestoxytricini基因组为模板,通过PCR扩增,引入XbaI和EcoRV酶切位点,得到liprA片段,经电泳验证,DpnI酶法处理,电泳胶回收后,得到纯化的liprA片段。liprA基因序列如SEQ IDNo.5所示,其编码的氨基酸序列如SEQ ID No.6所示。
将上述纯化的liprA片段和pKC1139质粒分别用XbaI和EcoRV进行双酶切,将liprA片段的双酶切产物与pKC1139质粒双酶切的产物经过T4连接酶4℃过夜连接。将连接产物转化入大肠杆菌DH5α中,涂布于含有50mg/L阿泊拉霉素的LB固体平板上,培养16h后进行菌落PCR检测,送金唯智测序,测序正确后,将得到的阳性菌命名为E.coli/pKC1139-liprA。用质粒试剂盒提取质粒pKC1139-liprA备用,质粒图谱如图1所示。
2、pKC1139-liprA-mut:
以核苷酸序列如SEQ ID NO:1所示的基因为模板,获得liprA-mut片段,按照pKC1139-liprA的构建过程用相同的引物进行构建以获得质粒pKC1139-liprA-mut。质粒图谱如图3所示。
3、pKC1139-liprB的构建:
分别利用表1的引物对liprB-XbaI-F和liprB-EcoRV-R,以Streptomycestoxytricini基因组为模板,通过PCR扩增,引入XbaI和EcoRV酶切位点,得到liprB片段,经电泳验证,DpnI酶法处理,电泳胶回收后,得到纯化的liprB片段。liprB基因序列如SEQ IDNo.7所示,其编码的氨基酸序列如SEQ ID No.8所示。
将上述纯化的liprB片段和pKC1139质粒分别用XbaI和EcoRV进行双酶切,将liprB片段的双酶切产物与pKC1139质粒双酶切的产物经过T4连接酶4℃过夜连接。将连接产物转化入大肠杆菌DH5α中,涂布于含有50mg/L阿泊拉霉素的LB固体平板上,培养16h后进行菌落PCR检测,送金唯智测序,测序正确后,将得到的阳性菌命名为E.coli/pKC1139-liprB。用质粒试剂盒提取质粒pKC1139-liprB备用,质粒图谱如图2所示。
4、pKC1139-liprB-mut:
以核苷酸序列如SEQ ID NO:3所示的基因为模板,获得liprB-mut片段,按照pKC1139-liprB的构建过程用相同的引物进行构建以获得质粒pKC1139-liprB-mut。质粒图谱如图4所示。
表1引物
实施例4含质粒载体菌株的构建
1、含外源质粒大肠杆菌ET12567/pUZ8002的准备
将构建好的质粒转化大肠杆菌ET12567/pUZ8002,得到含有重组质粒的供体菌。供体菌接种于5mL的LB培养基中(含25μg/mL Km、Cm和50μg/mL Am),37℃培养过夜,按1:50~100转种至10mL LB培养基中(含25μg/mL Km、Cm和50μg/mL Am),37℃培养至OD
2、异源表达菌株孢子的处理
Streptomyces toxytricini培养大约7d左右,取2个平板用5mL 10%甘油洗下孢子,放入50mL的试管中,振荡混匀后脱脂棉过滤在干净的试管中,3500rpm离心10min,加入1mL的2×YT,50℃热激活10min。
3、大肠杆菌ET12567/pUZ8002与Streptomyces toxytricini菌株接合转移及菌株的分离鉴定
分别0.5mL取等量链霉菌孢子液和大肠杆菌菌液混匀涂布含10mM MgCl
实施例5不同菌株评价
将对照菌与SK1、SK2、SK3、SK4进行摇瓶发酵,每个进行3次平行,然后进行利普司他汀的测定和比价,结果如表2所示。根据表2的检测结果可知,发现实验组菌相比对照菌生产利普司他汀的能力都有所提高,从而说明了核糖体σ因子A和B及其突变体基因过表达能够提升利普司他汀的产量。
表2不同菌株的利普司他汀产量
序列表
<110> 四川轻化工大学
<120> 一种核糖体σ因子及其突变体和编码得到的蛋白在提升利普司他汀产量中的应用
<160> 12
<170> SIPOSequenceListing 1.0
<210> 1
<211> 2061
<212> DNA
<213> 链霉菌(Streptomyces sp.)
<400> 1
atgacttcag agcacacggc agagctggtc gcggcggccc gcgcgggaga cctccgcgcg 60
caggacgagc tggtcagcgc gtatctgccg ctggtctaca acatcgtcgg gcgcgccatg 120
aacggctccg tcgacgtgga cgacgtcgtg caggacacga tgctgcgggc cctcgacggc 180
ctcggcaccc tccgttcgga cgacagcttc cgctcgtggt tggtggccat cgcgatgaac 240
cgggtgcggg cgtactggca ggcccggcgc accgctcccg gcgagagcgg tctggaggcc 300
gcctgggagc tcgccgaccc gggggcggac ttcgtcgacc tgaccgtcgt ccggctggcc 360
ctggaggggc agcgccgcga gacggcgcgc gccacccgct ggctggagcc ggacgaccgg 420
gcgctgctgt cgctgtggtg gctggagtgc gcgggggagc tgacccgggg cgaggtggcc 480
gcggcgctgg agctgacgcc gcagcacacg gccgtgcggg tgcagcggat gaaggcgcag 540
ctggagtccg cgcgcgtcgt ggagggggcg ctggcggcgc agccgccgtg cgaggcgctg 600
gccgcggtga cggcctcctg ggacggccag ccgtccactc tgtggcgcaa gcgaatagcc 660
cggcacgccc gcgagtgcct gcggtgcgcc gggctgtgga acggtctgct cccggcggag 720
gggctgctgg cgggcctggc gctcgtcccg gtgtcggcgg cgctgctggc cggggtgcgg 780
tcggccgccg cgggcggttt cgcccccgcg ggcgcggcgt acgcggcggg cgtgcccgca 840
gacggccagg cggtgtccgc cggctgggcg cccgccgacg gccaggcggc atccggcggc 900
tggacgcccg cgtacgaagc accgcccggc ggcacgggcg gcggcggcca cggcttcgcc 960
ggcggtaccg gtacggacgg cggcaacggc ttggcttccg gtgcaagtgc gggtgacggc 1020
ggcagcggct tcggcgccgg tgccgggccg cacggcggcg gcaacggctt cgcttccggt 1080
gcgggtgacg gcggcaacgg cttggcttcc ggtgcaagtg cgggtgacgg cggcagcggc 1140
cccggcgccg gtacgcgcag tggcgacgac ggtttcggcg ccggggcgca cgggggcggc 1200
agcggcttcg gcggcggtga cggcggtccg ggtggcggcg aggccgtggc ccggcttgtg 1260
ccggccggtt ccgcggaggg aggtgccgat ggcgcggcgg gcggcggccg gagcgcgttg 1320
cgcaagcggc ggcgcagtcg gcggcgggcc gtcgggggtg ccgtgctcgc cgcctgcgtc 1380
gcgggcggcg gcctcgccta cctgggcggc ttccccggct ccgccggcga ggacggcgga 1440
gccgccccgg cagctccgct gaacgcgctg tccgcaggcg agtccgccgg cccgtcgccg 1500
agcggcccgg cccagccgtc cgcgtccgct tcggcctcgc cgtccccgtc ggccaccgcg 1560
tcgccctcgg tgtcggcgtc ggcgagccct tccggcgcgg gcaaggcgtc cactggcgcg 1620
ccgaccccgt ccccgtccgc gccgcgcccc gcgtcgccgg ccccggtgcc cgccccgcag 1680
ggaccggtgg gccaggtcgt cgccctcgtc aacgccgagc gggcgaaggc gggctgcggc 1740
ccgctgaagg acgacgcgca gctgcggaag gccgcgcagc ggcactccga ggacatggcg 1800
agccggaact tcttctcgca cacggccccg gacggctccg acccgggcga gcggacgacg 1860
gccgccggct accggtgggc gacgtacggc gagaacatag cgcgcgggca gagcaccgcc 1920
gagtcggtca tgaactcgtg gatgaacagc gacggccacc gcgcgaacat cctgaactgc 1980
tccttcaagg acataggcgt cggactccac cagggccccg gcggcccgtg gtggacgcag 2040
aacttcggcg cccgcatgtg a 2061
<210> 2
<211> 686
<212> PRT
<213> 链霉菌(Streptomyces sp.)
<400> 2
Met Thr Ser Glu His Thr Ala Glu Leu Val Ala Ala Ala Arg Ala Gly
1 5 10 15
Asp Leu Arg Ala Gln Asp Glu Leu Val Ser Ala Tyr Leu Pro Leu Val
20 25 30
Tyr Asn Ile Val Gly Arg Ala Met Asn Gly Ser Val Asp Val Asp Asp
35 40 45
Val Val Gln Asp Thr Met Leu Arg Ala Leu Asp Gly Leu Gly Thr Leu
50 55 60
Arg Ser Asp Asp Ser Phe Arg Ser Trp Leu Val Ala Ile Ala Met Asn
65 70 75 80
Arg Val Arg Ala Tyr Trp Gln Ala Arg Arg Thr Ala Pro Gly Glu Ser
85 90 95
Gly Leu Glu Ala Ala Trp Glu Leu Ala Asp Pro Gly Ala Asp Phe Val
100 105 110
Asp Leu Thr Val Val Arg Leu Ala Leu Glu Gly Gln Arg Arg Glu Thr
115 120 125
Ala Arg Ala Thr Arg Trp Leu Glu Pro Asp Asp Arg Ala Leu Leu Ser
130 135 140
Leu Trp Trp Leu Glu Cys Ala Gly Glu Leu Thr Arg Gly Glu Val Ala
145 150 155 160
Ala Ala Leu Glu Leu Thr Pro Gln His Thr Ala Val Arg Val Gln Arg
165 170 175
Met Lys Ala Gln Leu Glu Ser Ala Arg Val Val Glu Gly Ala Leu Ala
180 185 190
Ala Gln Pro Pro Cys Glu Ala Leu Ala Ala Val Thr Ala Ser Trp Asp
195 200 205
Gly Gln Pro Ser Thr Leu Trp Arg Lys Arg Ile Ala Arg His Ala Arg
210 215 220
Glu Cys Leu Arg Cys Ala Gly Leu Trp Asn Gly Leu Leu Pro Ala Glu
225 230 235 240
Gly Leu Leu Ala Gly Leu Ala Leu Val Pro Val Ser Ala Ala Leu Leu
245 250 255
Ala Gly Val Arg Ser Ala Ala Ala Gly Gly Phe Ala Pro Ala Gly Ala
260 265 270
Ala Tyr Ala Ala Gly Val Pro Ala Asp Gly Gln Ala Val Ser Ala Gly
275 280 285
Trp Ala Pro Ala Asp Gly Gln Ala Ala Ser Gly Gly Trp Thr Pro Ala
290 295 300
Tyr Glu Ala Pro Pro Gly Gly Thr Gly Gly Gly Gly His Gly Phe Ala
305 310 315 320
Gly Gly Thr Gly Thr Asp Gly Gly Asn Gly Leu Ala Ser Gly Ala Ser
325 330 335
Ala Gly Asp Gly Gly Ser Gly Phe Gly Ala Gly Ala Gly Pro His Gly
340 345 350
Gly Gly Asn Gly Phe Ala Ser Gly Ala Gly Asp Gly Gly Asn Gly Leu
355 360 365
Ala Ser Gly Ala Ser Ala Gly Asp Gly Gly Ser Gly Pro Gly Ala Gly
370 375 380
Thr Arg Ser Gly Asp Asp Gly Phe Gly Ala Gly Ala His Gly Gly Gly
385 390 395 400
Ser Gly Phe Gly Gly Gly Asp Gly Gly Pro Gly Gly Gly Glu Ala Val
405 410 415
Ala Arg Leu Val Pro Ala Gly Ser Ala Glu Gly Gly Ala Asp Gly Ala
420 425 430
Ala Gly Gly Gly Arg Ser Ala Leu Arg Lys Arg Arg Arg Ser Arg Arg
435 440 445
Arg Ala Val Gly Gly Ala Val Leu Ala Ala Cys Val Ala Gly Gly Gly
450 455 460
Leu Ala Tyr Leu Gly Gly Phe Pro Gly Ser Ala Gly Glu Asp Gly Gly
465 470 475 480
Ala Ala Pro Ala Ala Pro Leu Asn Ala Leu Ser Ala Gly Glu Ser Ala
485 490 495
Gly Pro Ser Pro Ser Gly Pro Ala Gln Pro Ser Ala Ser Ala Ser Ala
500 505 510
Ser Pro Ser Pro Ser Ala Thr Ala Ser Pro Ser Val Ser Ala Ser Ala
515 520 525
Ser Pro Ser Gly Ala Gly Lys Ala Ser Thr Gly Ala Pro Thr Pro Ser
530 535 540
Pro Ser Ala Pro Arg Pro Ala Ser Pro Ala Pro Val Pro Ala Pro Gln
545 550 555 560
Gly Pro Val Gly Gln Val Val Ala Leu Val Asn Ala Glu Arg Ala Lys
565 570 575
Ala Gly Cys Gly Pro Leu Lys Asp Asp Ala Gln Leu Arg Lys Ala Ala
580 585 590
Gln Arg His Ser Glu Asp Met Ala Ser Arg Asn Phe Phe Ser His Thr
595 600 605
Ala Pro Asp Gly Ser Asp Pro Gly Glu Arg Thr Thr Ala Ala Gly Tyr
610 615 620
Arg Trp Ala Thr Tyr Gly Glu Asn Ile Ala Arg Gly Gln Ser Thr Ala
625 630 635 640
Glu Ser Val Met Asn Ser Trp Met Asn Ser Asp Gly His Arg Ala Asn
645 650 655
Ile Leu Asn Cys Ser Phe Lys Asp Ile Gly Val Gly Leu His Gln Gly
660 665 670
Pro Gly Gly Pro Trp Trp Thr Gln Asn Phe Gly Ala Arg Met
675 680 685
<210> 3
<211> 1566
<212> DNA
<213> 链霉菌(Streptomyces sp.)
<400> 3
atggggctca tggacgcgga ccacgcgggc ctggtcgtcg cggctcaggc cggggacgac 60
cgggcgcgcg aagagctgat cgccgcctac ctgccgctgg tctacaacat cgtccggcgg 120
gcgctgagcg cacatgccga cgtcgacgac gtcgtccagg agacgctgtt gcgcgtggtg 180
cgcgaccttc ctgccctgcg cgctcccgac agcttccgct cctggctggt gtcgatcacg 240
ctccgccaga tacagaccca ctggcagcgg cagcgcgcgg tcaccaaccg gaccgccgtc 300
atcgacgagg cgctcgacct gccggatgcc ggcttcgaac ccgaggacgc gacgatcctg 360
cgcctccgtg tgtcggacga gcgccgtcgg atcgccgaag ccggccggtg gctcgacccg 420
gaccaccgcg ccctgctgtc cctctggtgg caggagcacg ccgggctgct gacccgggag 480
gacatcgcgg ccgcgacggg cctcaccgcc gcccacgccg gagtgcgcct gcagcgcatg 540
cgcgagcagc tggacctgag ccggacgatc gtcgccgccc tggaggccca cccgcgatgc 600
ccgcagctgg gcgagaccgt cgccggctgg gacggcctgc gtacctcggt gtggcggaag 660
cggatcgcgc ggcacacccg cgactgcccg gtctgcacgg cgacgacggc gaaccgggtc 720
cctgccgagc agctgctgct cggcctcgcg ccgctggccg tccccgccgg actcctcgcc 780
acgctgaccg ccaagggcct gctgtcgggt tcggccgcga gcaccgccgc gcctgccatg 840
gcgccggtcg cggccggcgc ggcggtgaag gcaggcggtc tgcacggcgc ggcgaccggc 900
aaactccacg cggtgaccgc tcacccgctg gcaagcatcg ccgccggtgc ggtgctcatc 960
accggagccg ccacgtacgc ggcctggccg gagccgacgc cccgggcgcc cggcgtcacc 1020
gccgccccca ccgtcgcccc cacggccgcc gttcccgcgc cggtcccgtc gggcaccccc 1080
acgccggccg caccgccgcc ggcgagtccg tccgccgtcc ccgcgggcac ggttccgctg 1140
ggcgcgcaca cactggagtc cgtcgaccag cccgacctct acctgacgta cgccggcgac 1200
ttcgcgacgc tcggccgggc cgccgactcc gacagcacgc aggcacggca gcgcgtcacg 1260
ttcacggtgg tccgggggct ggccgacggg cggtgcgtca ccttccgcgc ggccgacggc 1320
cgttacctgc ggcaccacta cctgcggctg cggctgagca ccgacgacgg cagcgaactc 1380
ttccggaagg acgcgacctt ctgcccccgc cccggagcgg tcgcggggtc ggtgaccctg 1440
tactcccaca actacccggg atcggtcgtc cgccaccgcg acggcggcat ctggctcgac 1500
ggctccgacg gcacccgggc cttcgccggc caggcctcct tcgtcgtccg caaggcccgg 1560
ccctga 1566
<210> 4
<211> 521
<212> PRT
<213> 链霉菌(Streptomyces sp.)
<400> 4
Met Gly Leu Met Asp Ala Asp His Ala Gly Leu Val Val Ala Ala Gln
1 5 10 15
Ala Gly Asp Asp Arg Ala Arg Glu Glu Leu Ile Ala Ala Tyr Leu Pro
20 25 30
Leu Val Tyr Asn Ile Val Arg Arg Ala Leu Ser Ala His Ala Asp Val
35 40 45
Asp Asp Val Val Gln Glu Thr Leu Leu Arg Val Val Arg Asp Leu Pro
50 55 60
Ala Leu Arg Ala Pro Asp Ser Phe Arg Ser Trp Leu Val Ser Ile Thr
65 70 75 80
Leu Arg Gln Ile Gln Thr His Trp Gln Arg Gln Arg Ala Val Thr Asn
85 90 95
Arg Thr Ala Val Ile Asp Glu Ala Leu Asp Leu Pro Asp Ala Gly Phe
100 105 110
Glu Pro Glu Asp Ala Thr Ile Leu Arg Leu Arg Val Ser Asp Glu Arg
115 120 125
Arg Arg Ile Ala Glu Ala Gly Arg Trp Leu Asp Pro Asp His Arg Ala
130 135 140
Leu Leu Ser Leu Trp Trp Gln Glu His Ala Gly Leu Leu Thr Arg Glu
145 150 155 160
Asp Ile Ala Ala Ala Thr Gly Leu Thr Ala Ala His Ala Gly Val Arg
165 170 175
Leu Gln Arg Met Arg Glu Gln Leu Asp Leu Ser Arg Thr Ile Val Ala
180 185 190
Ala Leu Glu Ala His Pro Arg Cys Pro Gln Leu Gly Glu Thr Val Ala
195 200 205
Gly Trp Asp Gly Leu Arg Thr Ser Val Trp Arg Lys Arg Ile Ala Arg
210 215 220
His Thr Arg Asp Cys Pro Val Cys Thr Ala Thr Thr Ala Asn Arg Val
225 230 235 240
Pro Ala Glu Gln Leu Leu Leu Gly Leu Ala Pro Leu Ala Val Pro Ala
245 250 255
Gly Leu Leu Ala Thr Leu Thr Ala Lys Gly Leu Leu Ser Gly Ser Ala
260 265 270
Ala Ser Thr Ala Ala Pro Ala Met Ala Pro Val Ala Ala Gly Ala Ala
275 280 285
Val Lys Ala Gly Gly Leu His Gly Ala Ala Thr Gly Lys Leu His Ala
290 295 300
Val Thr Ala His Pro Leu Ala Ser Ile Ala Ala Gly Ala Val Leu Ile
305 310 315 320
Thr Gly Ala Ala Thr Tyr Ala Ala Trp Pro Glu Pro Thr Pro Arg Ala
325 330 335
Pro Gly Val Thr Ala Ala Pro Thr Val Ala Pro Thr Ala Ala Val Pro
340 345 350
Ala Pro Val Pro Ser Gly Thr Pro Thr Pro Ala Ala Pro Pro Pro Ala
355 360 365
Ser Pro Ser Ala Val Pro Ala Gly Thr Val Pro Leu Gly Ala His Thr
370 375 380
Leu Glu Ser Val Asp Gln Pro Asp Leu Tyr Leu Thr Tyr Ala Gly Asp
385 390 395 400
Phe Ala Thr Leu Gly Arg Ala Ala Asp Ser Asp Ser Thr Gln Ala Arg
405 410 415
Gln Arg Val Thr Phe Thr Val Val Arg Gly Leu Ala Asp Gly Arg Cys
420 425 430
Val Thr Phe Arg Ala Ala Asp Gly Arg Tyr Leu Arg His His Tyr Leu
435 440 445
Arg Leu Arg Leu Ser Thr Asp Asp Gly Ser Glu Leu Phe Arg Lys Asp
450 455 460
Ala Thr Phe Cys Pro Arg Pro Gly Ala Val Ala Gly Ser Val Thr Leu
465 470 475 480
Tyr Ser His Asn Tyr Pro Gly Ser Val Val Arg His Arg Asp Gly Gly
485 490 495
Ile Trp Leu Asp Gly Ser Asp Gly Thr Arg Ala Phe Ala Gly Gln Ala
500 505 510
Ser Phe Val Val Arg Lys Ala Arg Pro
515 520
<210> 5
<211> 2061
<212> DNA
<213> 链霉菌(Streptomyces sp.)
<400> 5
atgacttcag agcacacggc agagctggtc gcggcggccc gcgcgggaga cctccacgcg 60
caggacgagc tggtcagcgc gtatctgccg ctggtctaca acatcgtcgg gcgcgccatg 120
aacggctccg tcgacgtgga cgacgtcgtg caggacacga tgctgcgggc cctcgacggc 180
ctcggcaccc tccgttcgga cgacagcttc cgctcgtggt tggtggccat cgcgatgaac 240
cgggtgcggg cgtactggca ggcccggcgc accgctcccg gtgagagcgg tctggaggcc 300
gcctgggagc tcgccgaccc gggggcggac ttcgtcgacc tgaccgtcgt ccggctggcc 360
ctggaggggc agcgccgcga gacggcgcgc gcgacccgct ggctggagcc ggacgaccgg 420
gcgctgctgt cgctgtggtg gctggagtgc gcgggggagc tgacccgggg cgaggtggcc 480
gcggcgctgg agctgacgcc gcagcacacg gccgtgcggg tgcagcggat gaaggcgcag 540
ctggagtccg cgcgcgtggt ggagggggcg ctggcggcgc agccgccgtg cgaggcgctg 600
gccgcggtga cggcctcctg ggacgggcag ccgtccactc tgtggcgcaa gcgaatagcc 660
cggcacgccc gcgagtgcct gcggtgcgcc gggctgtgga acggtctgct cccggcggag 720
gggctgctgg cgggcctggc gctcgtcccg gtgtcggcgg cgctgctggc cggggtgcgg 780
tcggccgccg cgggcggttt cgcccccgcg ggcgcggcgt acgcggcggg cgtgcccgca 840
gacggccagg cggtgtccgc cggctgggcg cccgccgacg gccaggcggc atccggcggc 900
tggacgcccg cgtacgaagc accgcccggc ggcacgggcg gcggcggcca cggcttcgcc 960
ggcggtaccg gtacggacga cggcaacggc ttggcttccg gtgcaagtgc ggatgacggc 1020
ggcagcggcc tcggcgccgg tgccgggccg cacggcggcg gcaacggctt cgcttccggt 1080
gcgggtgacg gcggcaacgg cttggcttcc ggtgcaagtg cgggtgacgg cggcagcggc 1140
gcgggtgacg gcacgcgcag tggcgacgac ggtttcggcg ccggggcgca cgggggcggc 1200
agcggcttcg gcggcggtga cggcggtccg ggtggcggcg aggccgtggc ccggcttgtg 1260
ccggccggtt ccgcggaggg aggtgccgat ggcgcggcgg gcggcggccg gagcgcgttg 1320
cgcaagcggc ggcgcagtcg gcggcgggcc gtcgggggtg ccgtgctcgc cgcctgcgtc 1380
gcgggcggcg gcctcgccta cctgggcggc ttccccggct ccgccggcga ggacggcgga 1440
gccgccccgg cagctccgct gaacgcgctg tccgcaggcg agtccgccgg cccgtcgccg 1500
agcggcccgg cccagccatc cgcgtccgct tcggcctcgc cgtccccgtc ggccaccgcg 1560
tcgccctcgg tgtcggcgtc ggcgagccct tccggcgcgg gcaaggcgtc cagtggcgcg 1620
ccgaccccgt ccccgtccgc gccgcgcccc gcgtcgccgg ccccggtgcc cgccccgcag 1680
ggaccggtgg gccaggtcgt cgccctcgtc aacgccgagc gggcgaaggc gggctgcggc 1740
ccgctgaagg acgacgcgca gctgcggaag gccgcgcagc ggcactccga ggacatggcg 1800
agccggaact tcttctcgca cacggccccg gacggctccg acccgggcga gcggacgacg 1860
gccgccggct accggtgggc gacgtacggc gagaacatag cgcgcgggca gagcaccgcc 1920
gagtcggtca tgaactcgtg gatgaacagc gacggccacc gcgcgaacat cctgaactgc 1980
tccttcaagg acataggcgt cggactccac cagggccccg gcggcccgtg gtggacgcag 2040
aacttcggcg cccgcatgtg a 2061
<210> 6
<211> 686
<212> PRT
<213> 链霉菌(Streptomyces sp.)
<400> 6
Met Thr Ser Glu His Thr Ala Glu Leu Val Ala Ala Ala Arg Ala Gly
1 5 10 15
Asp Leu His Ala Gln Asp Glu Leu Val Ser Ala Tyr Leu Pro Leu Val
20 25 30
Tyr Asn Ile Val Gly Arg Ala Met Asn Gly Ser Val Asp Val Asp Asp
35 40 45
Val Val Gln Asp Thr Met Leu Arg Ala Leu Asp Gly Leu Gly Thr Leu
50 55 60
Arg Ser Asp Asp Ser Phe Arg Ser Trp Leu Val Ala Ile Ala Met Asn
65 70 75 80
Arg Val Arg Ala Tyr Trp Gln Ala Arg Arg Thr Ala Pro Gly Glu Ser
85 90 95
Gly Leu Glu Ala Ala Trp Glu Leu Ala Asp Pro Gly Ala Asp Phe Val
100 105 110
Asp Leu Thr Val Val Arg Leu Ala Leu Glu Gly Gln Arg Arg Glu Thr
115 120 125
Ala Arg Ala Thr Arg Trp Leu Glu Pro Asp Asp Arg Ala Leu Leu Ser
130 135 140
Leu Trp Trp Leu Glu Cys Ala Gly Glu Leu Thr Arg Gly Glu Val Ala
145 150 155 160
Ala Ala Leu Glu Leu Thr Pro Gln His Thr Ala Val Arg Val Gln Arg
165 170 175
Met Lys Ala Gln Leu Glu Ser Ala Arg Val Val Glu Gly Ala Leu Ala
180 185 190
Ala Gln Pro Pro Cys Glu Ala Leu Ala Ala Val Thr Ala Ser Trp Asp
195 200 205
Gly Gln Pro Ser Thr Leu Trp Arg Lys Arg Ile Ala Arg His Ala Arg
210 215 220
Glu Cys Leu Arg Cys Ala Gly Leu Trp Asn Gly Leu Leu Pro Ala Glu
225 230 235 240
Gly Leu Leu Ala Gly Leu Ala Leu Val Pro Val Ser Ala Ala Leu Leu
245 250 255
Ala Gly Val Arg Ser Ala Ala Ala Gly Gly Phe Ala Pro Ala Gly Ala
260 265 270
Ala Tyr Ala Ala Gly Val Pro Ala Asp Gly Gln Ala Val Ser Ala Gly
275 280 285
Trp Ala Pro Ala Asp Gly Gln Ala Ala Ser Gly Gly Trp Thr Pro Ala
290 295 300
Tyr Glu Ala Pro Pro Gly Gly Thr Gly Gly Gly Gly His Gly Phe Ala
305 310 315 320
Gly Gly Thr Gly Thr Asp Asp Gly Asn Gly Leu Ala Ser Gly Ala Ser
325 330 335
Ala Asp Asp Gly Gly Ser Gly Leu Gly Ala Gly Ala Gly Pro His Gly
340 345 350
Gly Gly Asn Gly Phe Ala Ser Gly Ala Gly Asp Gly Gly Asn Gly Leu
355 360 365
Ala Ser Gly Ala Ser Ala Gly Asp Gly Gly Ser Gly Ala Gly Asp Gly
370 375 380
Thr Arg Ser Gly Asp Asp Gly Phe Gly Ala Gly Ala His Gly Gly Gly
385 390 395 400
Ser Gly Phe Gly Gly Gly Asp Gly Gly Pro Gly Gly Gly Glu Ala Val
405 410 415
Ala Arg Leu Val Pro Ala Gly Ser Ala Glu Gly Gly Ala Asp Gly Ala
420 425 430
Ala Gly Gly Gly Arg Ser Ala Leu Arg Lys Arg Arg Arg Ser Arg Arg
435 440 445
Arg Ala Val Gly Gly Ala Val Leu Ala Ala Cys Val Ala Gly Gly Gly
450 455 460
Leu Ala Tyr Leu Gly Gly Phe Pro Gly Ser Ala Gly Glu Asp Gly Gly
465 470 475 480
Ala Ala Pro Ala Ala Pro Leu Asn Ala Leu Ser Ala Gly Glu Ser Ala
485 490 495
Gly Pro Ser Pro Ser Gly Pro Ala Gln Pro Ser Ala Ser Ala Ser Ala
500 505 510
Ser Pro Ser Pro Ser Ala Thr Ala Ser Pro Ser Val Ser Ala Ser Ala
515 520 525
Ser Pro Ser Gly Ala Gly Lys Ala Ser Ser Gly Ala Pro Thr Pro Ser
530 535 540
Pro Ser Ala Pro Arg Pro Ala Ser Pro Ala Pro Val Pro Ala Pro Gln
545 550 555 560
Gly Pro Val Gly Gln Val Val Ala Leu Val Asn Ala Glu Arg Ala Lys
565 570 575
Ala Gly Cys Gly Pro Leu Lys Asp Asp Ala Gln Leu Arg Lys Ala Ala
580 585 590
Gln Arg His Ser Glu Asp Met Ala Ser Arg Asn Phe Phe Ser His Thr
595 600 605
Ala Pro Asp Gly Ser Asp Pro Gly Glu Arg Thr Thr Ala Ala Gly Tyr
610 615 620
Arg Trp Ala Thr Tyr Gly Glu Asn Ile Ala Arg Gly Gln Ser Thr Ala
625 630 635 640
Glu Ser Val Met Asn Ser Trp Met Asn Ser Asp Gly His Arg Ala Asn
645 650 655
Ile Leu Asn Cys Ser Phe Lys Asp Ile Gly Val Gly Leu His Gln Gly
660 665 670
Pro Gly Gly Pro Trp Trp Thr Gln Asn Phe Gly Ala Arg Met
675 680 685
<210> 7
<211> 1566
<212> DNA
<213> 链霉菌(Streptomyces sp.)
<400> 7
atggggctca tggacgcgga ccacgcgggc ctggtcgtcg cggctcaggc cggggacgac 60
cgggcgcgcg aagagctgat cgccgcctac ctgccgctgg tctacaacat cgtccggcgg 120
gcgctgagcg cacatgccga cgtcgacgac gtcgtccagg agacgctgtt gcgcgtggtg 180
cgcgaccttc ctgccctgcg cgctcccgac agcttccgct cctggctggt gtcgatcacg 240
ctccgccaga tacagaccca ctggcagcgg cagcgcgcgg tcgccaaccg gaccgccgtc 300
atcgacgagg cgctcgacct gccggatgcc ggcttcgaac ccgaggacgc gacgatcctg 360
cgcctccgtg tgtcggacga gcgccgtcgg atcgccgaag ccggccggtg gctcgacccg 420
gaccaccgcg ccctgctgtc cctctggtgg caggagcacg ccgggctgct gacccgggag 480
gacatcgcgg ccgcgacggg cctcaccgcc gcccacgccg gagtgcgcct gcagcgcatg 540
cgcgagcagc tggacctgag ccggacgatc gtcgccgccc tggaggccca cccgcgatgc 600
ccgcagctgg gcgagaccgt cgccggctgg gacggcctgc gtacctcggt gtggcggaag 660
cggatcgcgc ggcacacccg cgactgcccg gtctgcacgg cgacgacggc gaaccgggtc 720
cctgccgagc agctgctgct cggcctcgcg ccgctggccg tccccgccgg actcctcgcc 780
acgctgaccg ccaagggcct gctgtcgggt tcggccgcgg gcgccgccgc gcctgccatg 840
gcgccggtcg cggccggcgc ggcggtgaag gcaggcggtc tgcacggcgc ggcgaccggc 900
aaactccacg cggtgaccgc tcacccgctg gcaagcatcg ccgccggtgc ggtgctcatc 960
accggagccg cgacgtacgc agcctggccg gagccgacgc cccgggcgcc cggcgtcacc 1020
gccgccccca ccgtcgcgcc cacggccgcc gctcccgcgc cggtcccgtc gggcaccccc 1080
acgccggccg caccgccacc ggcgagtccg tccgccgtcc ccgcgggcac ggttccgctg 1140
ggcgcgcaca cactggagtc cgtcgaccag cccgacctct acctgacgta cgccggcgac 1200
ttcgcgacgc tcggccgggc cgccgactcc ggcagcacgc aggcacggca gcgcgtcacg 1260
ttcacggtgg tccgggggct ggccgacggg cggtgcgtca ccttccgcgc ggccgacggc 1320
cgttacctgc ggcaccacta cctgcggctg cggctgagca ccgacgacgg cagcgaactc 1380
ttccggaagg acgcgacctt ctgcccccgc cccggagcgg tcgcggggtc ggtgaccctg 1440
tactcccaca actacccggg atcggtcgtc cgccaccgcg acggcggcat ctggctcgac 1500
ggctccgacg gcacccgggc cttcgccggc caggcctcct tcgtcgtccg caaggcccgg 1560
ccctga 1566
<210> 8
<211> 521
<212> PRT
<213> 链霉菌(Streptomyces sp.)
<400> 8
Met Gly Leu Met Asp Ala Asp His Ala Gly Leu Val Val Ala Ala Gln
1 5 10 15
Ala Gly Asp Asp Arg Ala Arg Glu Glu Leu Ile Ala Ala Tyr Leu Pro
20 25 30
Leu Val Tyr Asn Ile Val Arg Arg Ala Leu Ser Ala His Ala Asp Val
35 40 45
Asp Asp Val Val Gln Glu Thr Leu Leu Arg Val Val Arg Asp Leu Pro
50 55 60
Ala Leu Arg Ala Pro Asp Ser Phe Arg Ser Trp Leu Val Ser Ile Thr
65 70 75 80
Leu Arg Gln Ile Gln Thr His Trp Gln Arg Gln Arg Ala Val Ala Asn
85 90 95
Arg Thr Ala Val Ile Asp Glu Ala Leu Asp Leu Pro Asp Ala Gly Phe
100 105 110
Glu Pro Glu Asp Ala Thr Ile Leu Arg Leu Arg Val Ser Asp Glu Arg
115 120 125
Arg Arg Ile Ala Glu Ala Gly Arg Trp Leu Asp Pro Asp His Arg Ala
130 135 140
Leu Leu Ser Leu Trp Trp Gln Glu His Ala Gly Leu Leu Thr Arg Glu
145 150 155 160
Asp Ile Ala Ala Ala Thr Gly Leu Thr Ala Ala His Ala Gly Val Arg
165 170 175
Leu Gln Arg Met Arg Glu Gln Leu Asp Leu Ser Arg Thr Ile Val Ala
180 185 190
Ala Leu Glu Ala His Pro Arg Cys Pro Gln Leu Gly Glu Thr Val Ala
195 200 205
Gly Trp Asp Gly Leu Arg Thr Ser Val Trp Arg Lys Arg Ile Ala Arg
210 215 220
His Thr Arg Asp Cys Pro Val Cys Thr Ala Thr Thr Ala Asn Arg Val
225 230 235 240
Pro Ala Glu Gln Leu Leu Leu Gly Leu Ala Pro Leu Ala Val Pro Ala
245 250 255
Gly Leu Leu Ala Thr Leu Thr Ala Lys Gly Leu Leu Ser Gly Ser Ala
260 265 270
Ala Gly Ala Ala Ala Pro Ala Met Ala Pro Val Ala Ala Gly Ala Ala
275 280 285
Val Lys Ala Gly Gly Leu His Gly Ala Ala Thr Gly Lys Leu His Ala
290 295 300
Val Thr Ala His Pro Leu Ala Ser Ile Ala Ala Gly Ala Val Leu Ile
305 310 315 320
Thr Gly Ala Ala Thr Tyr Ala Ala Trp Pro Glu Pro Thr Pro Arg Ala
325 330 335
Pro Gly Val Thr Ala Ala Pro Thr Val Ala Pro Thr Ala Ala Ala Pro
340 345 350
Ala Pro Val Pro Ser Gly Thr Pro Thr Pro Ala Ala Pro Pro Pro Ala
355 360 365
Ser Pro Ser Ala Val Pro Ala Gly Thr Val Pro Leu Gly Ala His Thr
370 375 380
Leu Glu Ser Val Asp Gln Pro Asp Leu Tyr Leu Thr Tyr Ala Gly Asp
385 390 395 400
Phe Ala Thr Leu Gly Arg Ala Ala Asp Ser Gly Ser Thr Gln Ala Arg
405 410 415
Gln Arg Val Thr Phe Thr Val Val Arg Gly Leu Ala Asp Gly Arg Cys
420 425 430
Val Thr Phe Arg Ala Ala Asp Gly Arg Tyr Leu Arg His His Tyr Leu
435 440 445
Arg Leu Arg Leu Ser Thr Asp Asp Gly Ser Glu Leu Phe Arg Lys Asp
450 455 460
Ala Thr Phe Cys Pro Arg Pro Gly Ala Val Ala Gly Ser Val Thr Leu
465 470 475 480
Tyr Ser His Asn Tyr Pro Gly Ser Val Val Arg His Arg Asp Gly Gly
485 490 495
Ile Trp Leu Asp Gly Ser Asp Gly Thr Arg Ala Phe Ala Gly Gln Ala
500 505 510
Ser Phe Val Val Arg Lys Ala Arg Pro
515 520
<210> 9
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
gctctagaat gacttcagag cacacggc 28
<210> 10
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
gcgatatctc acatgcgggc gccgaagt 28
<210> 11
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
gctctagaat ggggctcatg gacgcgga 28
<210> 12
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 12
gcgatatctc agggccgggc cttgcgga 28
- 一种核糖体σ因子及其突变体和编码得到的蛋白在提升利普司他汀产量中的应用
- 一种核糖体σ因子B及其突变体在提升利普司他汀产量中的应用