一种最小化无用动作的节能性无人车路径导航方法
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及一种最小化无用动作的节能性无人车路径导航方法,属于自主导航领域。
背景技术
自主导航是机器人技术研究的一个长期领域,它为移动机器人在人类日常相同环境中执行一系列任务提供了必不可少的功能。传统的基于视觉的导航方法通常会构建环境地图,然后使用路径规划来达到目标。它们通常依赖精确,高质量的立体摄像机和其他传感器(例如激光测距仪),并且通常对计算要求很高。
传统的导航方法通常需要解决许多组件的问题,包括地图构建,运动规划和机器人低层控制。传统导航方法中运动规划对高质量几何地图、规划轨迹、以及完美定位的依赖,导致了这些方法复杂而繁琐,并且泛化能力差,必须针对特定环境进行调整。近年来,基于强化学习的方法已证明能够直接端到端的将原始传感器数据映射到控制命令。这种端到端的方法降低了实现的复杂性,并有效地利用了来自不同传感器(例如,深度相机,激光器)的输入数据,从而降低了成本,功耗和计算时间。另一个优点是输入数据和控制输出之间的端到端关系可以使用任意的非线性复杂模型,这在不同的控制问题(例如车道跟踪,自动驾驶和无人机控制)都可以产生很好的效果。
但是,使用强化学习的方法得到的控制策略,在导航的时候可能会产生较多的无用多余动作,例如在原地不断摇摆左右旋转以获取更多的局部地图信息,这会导致机器人在导航的过程中效率变低,并会消耗额外的能量。
现有的自主导航技术,通常用以下两种方法来解决:
1、SLAM:
同时解决定位和地图构建问题。对于室内导航机器人来说,定位即了解自己在房间里的具体位置,建图即了解整个房间的结构信息,在有了这些信息后即可进行传统的路径规划算法,以最短的距离到达目的地。机器人在未知的环境某个地点出发,通过传感器观测周围的环境信息,利用相机信息估算机器人的位置,姿态和运动轨迹,并根据位姿构建地图,从而实现同时定位和建图。首先通过传感器获取环境信息,主要根据图像提取特征点,通过特征点的变换计算出相机的位姿,同时进行闭环检测,判断机器人是否到达先前经过的地方,在后端通过对位姿进行优化,得到全局最优状态。最后根据每一时刻相机的位姿和空间中目标信息建立地图。
2、强化学习导航:
强化学习导航的方法主要通过机器人Agent与环境Env进行交互,学习一个策略网络Policy,以端到端的方式直接将观测映射为机器人的控制指令,不需要构建全局地图。强化学习通过设置reward函数,在交互的过程中来对机器人执行的动作进行打分(例如碰撞会对agent产生惩罚,向目标前进会给予奖励),Agent的目标是得到更多的reward,因此它会根据奖惩机制学习到一种使期望奖励最大化的策略。在导航任务中Agent通过学习得到策略网络以实现一种避开障碍的能力同时驶向给定的目标点。
但他们也存在着各自的缺点:
1、SLAM的缺点:
基构建出的地图是稀疏点云图,只保留了图像中特征点的一部分作为关键点,固定在空间中进行定位,很难描绘地图中的障碍物的存在。初始化时要保持低速运动,对准特征和几何纹理丰富的物体,旋转时比较容易丢帧,特别是对于纯旋转噪声敏感不具备尺度不变性。由于环境结构是会发生变化的,因此构建的地图可能不匹配当前环境的状态,因此仍需重新构建地图。另外SLAM由大量模块组成,复杂繁琐并且误差会在模块间累计,导致方法不精确缺少泛化能力,并且需要依赖精度高的传感器。
2、强化学习导航的缺点:
强化学习进行导航的方法由于缺少动力模型以及全局的信息,直接通过端到端预测出机器人执行的动作,会导致机器人有时产生无用多余的动作(例如当机器人在穿过门的过程中,经常会产生大量的左右摇摆动作以获取更多的局部地图信息),进一步导致导航的效率变低,因此也会产生额外的能量消耗。
为在导航过程中引入一些额外信息,在视觉中加入了光流图像。使用光流可以引入额外的一些视觉运动信息。光流可以表示前后两张图像的一种运动关系,它代表的是图像中的像素点在x,y轴上的移动。在动作识别中大量使用了光流作为神经网络的输入,因为它可以很好代表了图像中物体的运动状态。通常该任务中神经网络结构使用了双分支的结构,输入当前的RGB图像以及视频多个帧之间的光流序列以预测当前图像中人做的是何种动作。目前大部分光流动作识别任务中,是基于对第三人称的视频进行动作识别,主要识别的是视频中人物的动作。在机器人导航中加入光流预测动作是进行第一人称的动作识别,光流图像会有所差别,因为在第三人称动作识别中相机基本是不动的而物体会产生移动,在机器人导航过程中第一人称动作识别时背景基本是不动的而相机会进行移动。同时机器人由于执行动作的过程中会存在惯性因素,导致无法立刻转变动作状态,因此会使光流图像不准确,导致动作识别的精确率下降。
发明内容
本发明的目的是提出一种最小化无用动作的节能性无人车路径导航方法,以解决现有技术中存在的问题。
一种最小化无用动作的节能性无人车路径导航方法,节能性无人车路径导航方法包括以下步骤:
步骤一、根据光流图像以及动作前一张光流图像预测出机器人执行的对应动作;
步骤二、设置新的reward函数,根据过去前n个step长度范围内的机器人动作序列,即前几个时间步通过光流图像预测出的动作,以及当前的观测,预测出机器人目前应执行的动作从而进行躲避障碍,并在导航的同时减少多余无用的左右摇摆转向动作,其中,n≤10。
进一步的,在步骤一中,具体包括以下步骤:
步骤一一、机器人获取当前帧的RGB观测图像和上一帧的RGB观测图像;
步骤一二、基于所述当前帧的RGB观测图像和上一帧的RGB观测图像,通过LiteFlowNet来预测稠密光流;
步骤一三、在仿真环境中让机器人不断地做动作,保存计算得到的光流图像以及对应执行的动作类型标签生成训练数据集;
步骤一四、构建神经网络分类器,将数据集中的光流图像输入神经网络分类器中,预测出动作类型标签,并用监督学习的方式训练出一个动作分类器;
步骤一五、将上一次执行动作后得到的光流图像和上一帧光流观测图像输入至分类器中,得到当前动作预测结果。
进一步的,所述分类器由多层卷积层和全连接层构成,所述动作类型标签为光流图像对应的动作的类型。
进一步的,在步骤二中,具体包括以下步骤:
步骤二一、机器人在当前时刻t得到观测s
步骤二二、在Policy网络中,加入光流分支预测机器人上一次的动作,并将其加入到一个过去动作序列中用来计算新的reward函数;
步骤二三、将通过RGB-D分支卷积层提取得到的RGB-D图像特征向量、光流分支预测的动作嵌入向量以及目标位置信息连接到一起,并将连接到一起的信息输入到动作决策网络中预测出当前应当执行的动作;
步骤二四、根据新的惩罚reward函数继续训练Policy网络,使其构建起当前预测动作与过去一段时间内动作的联系,使得机器人减少多余无用的转动摇摆动作。
进一步的,在步骤二一至步骤二二中,具体的:当前预测出的动作应根据机器人摇摆的程度得到额外的惩罚,即reward的计算公式如下:
其中,第一项为每个时间步所受的惩罚,第二项为机器人碰撞时的惩罚,第三项为额外引入的reward项,对机器人做出的摇摆动作进行惩罚,swing_count为摇摆程度,根据所述过去动作序列内左右转动作的次数得到,第四项为机器人完成导航所受的奖励,最后一项为机器人与目标距离接近时获得的奖励,当机器人远离时会受到惩罚,其中
在机器人与环境交互的过程中,不断收集观测和对应动作标签以及生成的reward序列存入到buffer当中,当收集到一定数量的steps后,根据强化学习policy gradient方法,使用如下函数取出序列,计算目标函数J(π
其中,A函数为用于计算在s
为解决policy gradient中采样效率低的问题,在训练中使用了PPO强化学习方法,通过固定参数的策略网络进行采样所述观测和对应动作序列和reward序列,然后根据当前策略网络与采样时所用的策略网络分布的差异进行调整计算得到梯度,以实现通过采样网络计算出当前网络reward的期望,提高数据的利用率,即通过下述所示的函数中分数形式的项:
其中θ’为当前网络的参数,p
在多次迭代更新后,将采样网络的参数也进行更新,即使用此时的策略网络参数,同时在目标函数中加入了惩罚因子,即公式中的最后一项,当两个网络参数差别较大时给予较大的惩罚,控制了网络更新的速度,
其中KL(θ,θ
在利用强化学习训练Policy网络时,首先不加入光流分支单独训练导航能力,即使用上述reward函数中除第三项以外的reward,之后引入光流动作分类器,冻结光流与RGB-D分支以及光流分支的参数,只更新后面的动作决策网络参数。
本发明的有以下优点:本发明的一种最小化无用动作的节能性无人车路径导航方法,通过在强化学习当中设置新的reward,引入光流信息判断机器人的动作类型,并与其他观测信息结合输入至动作决策网络中只通过视觉信息预测出当前机器人应执行的导航动作,避免了传统SLAM方法中复杂繁琐的流程,可以减少机器人决策过程中做出多余无用的摆动动作,从而提高导航的效率同时减少多余能量的消耗。
附图说明
图1为机器人执行动作时产生的光流图像;
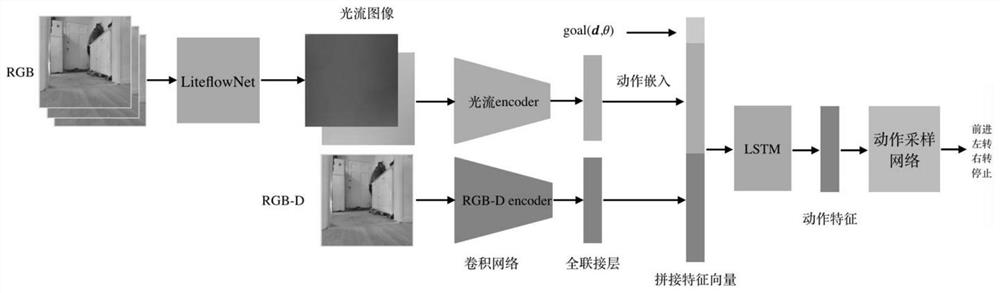
图2为Policy网络结构图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参照图2所示,其中,图像特征提取网络部分由两个分支组。光流分支首先通过RGB图像和LiteFlowNet预测出对应的光流图像,然后通过分类器网络得到动作类型并将其转换为嵌入向量。RGB-D分支通过卷积网络和全连接层提取出特征向量。将两个向量与相对目标拼接得到新的向量作为网络后面动作策略网络的输入,最终采样出应执行的动作。
一种最小化无用动作的节能性无人车路径导航方法,节能性无人车路径导航方法包括以下步骤:
步骤一、根据光流图像以及动作前一张光流图像预测出机器人执行的对应动作;
步骤二、设置新的reward函数,根据过去前n个step长度范围内的机器人动作序列,即前几个时间步通过光流图像预测出的动作,以及当前的观测,预测出机器人目前应执行的动作从而进行躲避障碍,并在导航的同时减少多余无用的左右摇摆转向动作,其中,n≤10。
进一步的,在步骤一中,具体包括以下步骤:
步骤一一、机器人获取当前帧的RGB观测图像和上一帧的RGB观测图像;
步骤一二、基于当前帧的RGB观测图像和上一帧的RGB观测图像,通过LiteFlowNet来预测稠密光流;
步骤一三、在仿真环境中让机器人不断地做动作,保存计算得到的光流图像以及对应执行的动作类型标签生成训练数据集;
步骤一四、构建神经网络分类器,将数据集中的光流图像输入神经网络分类器中,预测出动作类型标签,并用监督学习的方式训练出一个动作分类器;
步骤一五、将上一次执行动作后得到的光流图像和上一帧光流观测图像输入至分类器中,得到当前动作预测结果。
具体的,参照图1所示,其中,最右侧为像素朝不同方向移动时产生向量对应的颜色图例,左侧红色图像为对应机器人左转动作,像素点向右移动,同理蓝色为右转动作。左侧两张图片出现基本纯色是因为背景是不动的,只有相机是在动的,所以背景的像素是整体变换的。第三张为前进的效果,像素是向四周发散移动的,所以根据像素运动的图例会产生彩色的图像。在使用光流预测动作时,由于机器人的惯性因素导致无法立刻转换动作状态,例如机器人在执行右转动作时得到了左转指令,此时机器人无法立刻转换为左转动作状态会导致仍然右转,得到的光流图像依旧是右转的样子。虽然两个动作状态相同,但是机器人转动的程度一定有所差别,导致两张光流图像有所差别,因此加上前一张光流图像进行预测,尽量减少惯性的影响。
进一步的,分类器由多层卷积层和全连接层构成,动作类型标签为光流图像对应的动作的类型。
进一步的,在步骤二中,具体包括以下步骤:
步骤二一、机器人在当前时刻t得到观测st,根据观测到的RGB-D观测图像,机器人通过Policy网络来预测出当前应执行的动作at,机器人执行at动作与环境进行交互,同时环境反馈给at动作一个reward,并得到新的观测st+1并进行新一轮的动作预测,重复该过程直到机器人到达给定的目标位置点,通过强化学习训练Policy网络,使其预测出的动作获得更多reward,学习导航能力;
步骤二二、在Policy网络中,加入光流分支预测机器人上一次的动作,并将其加入到一个过去动作序列中用来计算新的reward函数;
步骤二三、将通过RGB-D分支卷积层提取得到的RGB-D图像特征向量、光流分支预测的动作嵌入向量以及目标位置信息连接到一起,并将连接到一起的信息输入到动作决策网络中预测出当前应当执行的动作;
步骤二四、根据新的惩罚reward函数继续训练Policy网络,使其构建起当前预测动作与过去一段时间内动作的联系,使得机器人减少多余无用的转动摇摆动作。
进一步的,在步骤二一至步骤二二中,具体的:当前预测出的动作应根据机器人摇摆的程度得到额外的惩罚,即reward的计算公式如下:
其中,第一项为每个时间步所受的惩罚,第二项为机器人碰撞时的惩罚,第三项为额外引入的reward项,对机器人做出的摇摆动作进行惩罚,swing_count为摇摆程度,根据过去动作序列内左右转动作的次数得到,第四项为机器人完成导航所受的奖励,最后一项为机器人与目标距离接近时获得的奖励,当机器人远离时会受到惩罚,其中
在机器人与环境交互的过程中,不断收集观测和对应动作标签以及生成的reward序列存入到buffer当中,当收集到一定数量的steps后,根据强化学习policy gradient方法,使用如下函数取出序列,计算目标函数J(π
其中,A函数为用于计算在s
为解决policy gradient中采样效率低的问题,在训练中使用了PPO强化学习方法,通过固定参数的策略网络进行采样观测和对应动作序列和reward序列,然后根据当前策略网络与采样时所用的策略网络分布的差异进行调整计算得到梯度,以实现通过采样网络计算出当前网络reward的期望,提高数据的利用率,即通过下述所示的函数中分数形式的项:
其中θ’为当前网络的参数,p
在多次迭代更新后,将采样网络的参数也进行更新,即使用此时的策略网络参数,同时在目标函数中加入了惩罚因子,即公式中的最后一项,当两个网络参数差别较大时给予较大的惩罚,控制了网络更新的速度,
其中KL(θ,θ
在利用强化学习训练Policy网络时,首先不加入光流分支单独训练导航能力,即使用上述reward函数中除第三项以外的reward,之后引入光流动作分类器,冻结光流与RGB-D分支以及光流分支的参数,只更新后面的动作决策网络参数。
- 一种最小化无用动作的节能性无人车路径导航方法
- 一种农业无人车导航方法、装置、农业无人车及存储介质