一种面向多模态特征语义关联特征的暴力视频识别系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及识别技术领域,具体涉及一种面向多模态特征语义关联特征的暴力视频识别系统。
背景技术
随着视频网络技术的快速发展,人们就会接触到各种视频,同时也会接触到暴力视频。暴力视频的存在影响着人们的身心健康,因此在人们观看在线视频或者工作人员在监测监控视频时,需要对存在的暴力视频进行搜索以及检测,对暴力视频的搜索往往就需要视频识别。在识别暴力视频时,通常需要在识别前对视频进行准备,目前暴力视频识别模式较为单一,识别文件和识别环境的准备较为复杂,无法精准的识别暴力视频,导致对暴力视频的识别较为困难。
因此,急需对提出一种面向多模态特征语义关联特征的暴力视频系统,解决以上问题。
发明内容
有鉴于此,本发明提供一种面向多模态特征语义关联特征的暴力视频识别系统,以解决上述技术问题。
为实现上述目的,本发明提供如下技术方案:
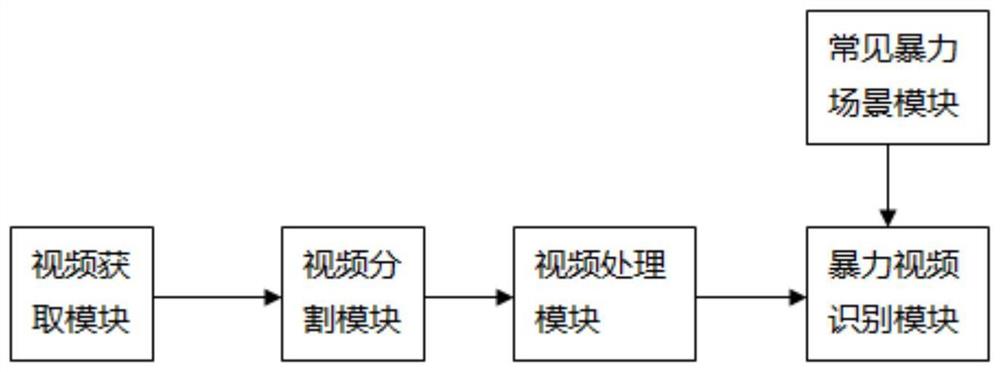
一种面向多模态特征语义关联特征的暴力视频识别系统,包括:视频获取模块、视频分割模块、视频处理模块和暴力视频识别模块,所述视频获取模块、所述视频分割模块、所述视频处理模块和所述暴力视频识别模块依次相连接;
所述视频获取模块用于获取视频信息,所述视频信息包括暴力视频信息和非暴力视频信息;
所述视频分割模块用于根据视频分割技术对所述视频获取模块获得的视频信息分割成若干个视频镜头,对所述每个视频镜头提取相关的视觉特征、音频特征和文本特征获得相对应的待识别图像信息、待识别音频信息和待识别文本信息;
所述视频处理模块用于对分割的多个视频镜头进行视频预处理,所述视频处理模块包括图像处理模块、音频处理模块和文本处理模块;
所述暴力视频识别模块用于判断所述视频处理模块处理后的视频信息是否属于暴力视频信息,所述暴力视频识别模块包括暴力音频判断模块、暴力图像判断模块和暴力文本判断模块。
进一步地,该面向多模态特征语义关联特征的暴力视频识别系统还包括用于存储存储暴力场景模板的常见暴力场景模块,所述常见暴力场景模块与所述暴力视频识别模块相连接。
更进一步地,所述常见暴力场景模板包括常见暴力场景音频特征信息、常见暴力场景图像特征信息和常见暴力场景文本特征信息。
进一步地,所述图像处理模块用于对所述视频镜头中的图像进行预处理,所述图像处理模块包括图像去重模块、图像灰度计算模块和图像对比增强模块,所述图像去重模块用于对所述视频镜头中的图像信息去除重叠信息,所述灰度值计算模块用于计算图像灰度值,所述图像对比度增强模块用于将图像的灰度值加强,所述图像去重模块、所述图像灰度计算模块和所述图像对比增强模块依次连接。
进一步地,所述音频处理模块用于对所述视频镜头模块中的音频信息进行预处理,所述音频处理模块包括低频滤波模块,所述低频滤波模块用于去除所述视频镜头中音频信息中的低频。
进一步地,所述文本处理模块用于对所述视频镜头中的文本信息进行预处理,所述文本处理模块包括文本去燥模块,所述文本去燥模块用于去除所述视频镜头中文本信息中多余的噪音。
进一步地,所述暴力音频判断模块的判断方法为:首先将处理后的音频特征信息与常见暴力场景的音频特征相融合,得到处理后的融合音频特征信息;其次利用分类器对常见的暴力场景的音频特征信息和处理后的音频特征信息进行比较判断,将与常见的暴力场景音频信息匹配的处理后的音频特征信息标记为暴力音频信息;所述暴力图像判断模块和所述暴力文本模块的判断方法与所述暴力音频判断模块的判断方法相同。
更进一步地,所述暴力视频信息包括标记暴力音频特征信息、标记暴力图像特征信息和标记暴力文本特征信息中至少一种特征信息。
进一步地,该面向多模态特征语义关联特征的暴力视频识别系统还包括定时启动模块,所述定时启动模块用于定时启动视频系统进行暴力视频识别,所述定时启动模块与所述视频获取模块相连接。
从上述的技术方案可以看出,本发明的优点是:
1.通过视频分割技术将视频分割成若干个视频镜头,每个镜头视频中均包含待识别图像模块、待识别音频模块和待识别文本模块,对每个镜头进行视频处理以及识别,以达到精准识别的目的;
2.通过图像、音频和文本相结合的方式对视频镜头中的特征进行提取,对视频进行多模态特征暴力视频进行联合识别,使暴力视频的识别更加准确,提高其实用性。
3.通过设置定时启动模块,能够实现在一定的时间打开或者关闭暴力视频识别系统,不需要人工手动操作,即可完成智能打开或者关闭暴力视频识别系统。
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
在附图中:
图1为本发明的一种面向多模态特征语义关联特征的暴力视频识别系统的组成结构示意图。
图2为本发明的一种面向多模态特征语义关联特征的暴力视频识别系统中视频分割技术的步骤图。
图3为本发明的一种面向多模态特征语义关联特征的暴力视频识别系统中视获取清晰的视频镜头的步骤图。
图4为发明的一种面向多模态特征语义关联特征的暴力视频识别系统中视频镜头的组成结构图。
图5为本发明的一种面向多模态特征语义关联特征的暴力视频特征的暴力识别系统的步骤示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示的一种面向多模态特征语义关联特征的暴力视频识别系统,该面向多模态特征语义关联特征的暴力视频系统,包括定时启动模块、视频获取模块、视频分割模块、视频处理模块、常见暴力场景模块和暴力视频识别模块,所述定时启动模块定时启动该视频识别系统,所述视频分割模块将接收到所述视频获取模块的视频信息分割成视频镜头,所述视频处理模块将接收到的视频镜头进行视频进行处理,所述暴力视频识别模块通过与所述场景暴力场景模块进行比对确定所述视频处理模块是否属于暴力视频,所述定时启动模块、所述视频获取模块、所述视频分割模块、所述视频处理模块和所述暴力视频识别模块均相连接,所述常见暴力场景模块与所述暴力视频识别模块相连接。
所述定时启动模块用于定时启动所述视频获取模块,所述定时启动模块与所述视频获取模块相连接。
具体的,定时启动模块包括定时启动器,定时启动器控制暴力识别系统的开关。在达到设定的定时启动时间时,根据定时启动时间打开所述视频获取模块来获取视频信息。
所述视频获取模块可以采用多个全景摄像头同时对视频数据和音频数据进行采集,获取视频信息,获取的视频信息包括暴力视频信息和非暴力视频信息。
具体的,当定时启动模块打开,接收视频获取请求时,多个全景摄像头来获取视频信息。为保证视频的清晰度,本发明中的全景摄像头的视频采集范围为5m。
所述视频分割模块用于根据视频分割技术对所述视频获取模块获得的视频信息分割成若干个视频镜头。
具体的,如图2所示,视频分割的实现包括以下两个步骤:
第一步:将获取的视频信息的连续性进行判断;
第二步:根据判断结果将镜头分为若干个视频镜头,若视频信息连续,则为当前视频镜头,若视频信息不连续,则为下一个视频镜头。
一般来说,电视、电影或者由全景摄像头从现场获取的视频信息均是通过若干个镜头拍摄组成的,通常情况下同一个视频镜头的视频信息是连续的,而两个镜头之间的视频信息是不连续的,因此这些视频信息大多数由若干个视频镜头组成。
优选的,对获取的若干个视频镜头的清晰度进行判断并提取清晰度较高的视频镜头,如图3所示,具体包括以下步骤:
步骤1:对获取视频信息的视频镜头截取视频流信息。
具体的,可以利用计算机将连续的视频流截取出来从而获得图像,再将图像进行分析。
步骤2:判断视频流是否是YUV格式,如果是,则执行步骤3,如果不是则执行步骤4。
步骤3:对截取的视频流的图像区域进行分析。
具体的,去除视频流中出现的地点和时间的因素,保留图像中间部分的矩形区域。
步骤4:计算视频流的清晰度的评价函数。
具体的,对保留的中间部分的矩形区域计算锐利点的梯度总和以及所有像素的梯度总和,并根据锐利点的梯度总和和所有像素的梯度总和的比值来判断清晰度评价函数。
步骤5:判断特定时间内的图像清晰与否。
具体的,特定时间可以是单位时间。在单位时间内统计视频清晰度异常的视频帧数,若超过单位时间内视频图像的总帧数的某一比值,则获取的视频镜头清晰度异常,否则获取的视频镜头清晰度正常。
步骤6:获取清晰较高的视频镜头信息。
如图4所示,对每一个清晰的所述视频镜头通过深度学习神经网络模型提取相关的视觉特征、音频特征和文本特征获得相对应的待识别图像信息、待识别音频信息和待识别文本信息。通过采用图像、音频和文本三种模态对视频镜头的特征进行提取,所述视频镜头包括图像模块、音频模块和文本模块,所述图像模块用于存储图像信息,所述音频模块用于存储音频信息,所述文本模块用于存储文本信息。
所述视频处理模块用于对分割的多个视频镜头进行视频预处理,所述视频处理模块包括图像处理模块、音频处理模块和文本处理模块。
所述图像处理模块包括图像去重模块、图像灰度计算模块和图像对比增强模块,所述图像去重模块用于对所述视频镜头中的图像信息进行去除重叠信息,所述灰度值计算模块用于计算图像灰度值,所述图像对比度增强模块用于将图像的灰度值加强,便于提高图像的可辨识度。
具体的,将每个镜头中的图像信息根据图像面积大小来去重叠的图像信息,保留面积大的图像信息;将得到的去重叠的图像信息根据图像二值化计算出图像灰度值范围,求出灰度最小值min和灰度最大值max;将得到的图像的灰度值拉伸到[0,255]的区间内,用以增强图像的辨识度。根据图像处理模块对图像模块进行预处理,得到质量较好、较为清晰地图像信息,便于与所述常见暴力场景模块中的图像信息进行比较。
所述音频处理模块用于对所述视频镜头中的音频信息进行处理,所述音频处理模块包括低频滤波模块,所述低频滤波模块用于将所述视频镜头中的音频信息中的低频进行去除,便于增强音频的质量,得到质量的音频信息。
所述文本处理模块用于对所述镜头视频中的文本信息进行处理,所述文本处理模块包括文本去燥模块;所述文本去燥模块用于去除文本信息中的无关噪声。
所述常见暴力场景模块是待识别视频识别暴力视频的模板,所述常见暴力场景模块与所述暴力视频识别模块相连接。所述暴力图像常见暴力场景音频特征信息、常见暴力场景图像特征信息和常见暴力场景文本特征信息。
所述常见暴力场景音频特征信息的提取包括:音频能量特征信息、短时平均能量强度、基因频率和音频能量熵等特征信息。
具体的,可以定义常见暴力场景音频信息包括尖叫、嘶吼和爆炸等音频信息。对常见暴力场景音频提取步骤为:从常见暴力场景模板中通过高通滤波器提取音频信号,将音频信息转换为声谱图,经神经网络正向分析,提取出暴力音频信息,将该声谱图作为比对模板。
所述常见暴力场景图像特征信息的提取包括:平均运动强度信息、血腥特征信息和火焰特征信息等特征信息。
具体的,可以定义常见暴力场景图像信息包含流血、刀、枪械、爆炸和动作等图像信息。对常见暴力场景的图像提取步骤为:从常见暴力模板中提取图像信号,经神经网络正向分析,提取出暴力图像信息,将该图像信息作为比对模板。
所述常见暴力场景文本特征信息的提取包括:敏感字信息、敏感词组信息等。
具体的,可以定义常见暴力场景文本信息包括恐怖、暴恐、暴力、血腥和血等文字信息。常见暴力场景文本的提取步骤为:从常见暴力场景模板中提取文本信号,从文本信息中提取常见暴力文本特征,常见暴力文本特征的提取可以采用词袋模型来提取。
所述暴力音频判断模块的判断方法为:首先将处理后的音频特征信息与常见暴力场景的音频特征相融合,得到处理后的融合音频特征信息和常见暴力场景的融合音频特征信息;其次利用分类器对常见的暴力场景的融合音频特征信息和处理后的音频特征信息进行比较判断,将与常见的暴力场景音频信息匹配的处理后的音频特征信息标记为暴力音频信息。
具体的,若某个视频镜头中包含有爆炸的音频信息,将该视频镜头中的音频信息与常见暴力场景的音频信息进行对比判断,若含有爆炸声,则表示含有与常见暴力场景音频信息相对应的音频特征信息,表明该视频镜头中含有暴力音频信息,将该视频镜头标注为暴力音频信息,否则为非暴力音频特征信息,将该视频镜头标注为非暴力音频特征信息。
所述暴力图像判断模块和所述暴力文本模块的判断方法与所述暴力音频判断模块的判断方法相同。
所述暴力视频信息包括所述标记暴力音频特征信息、所述标记暴力图像特征信息和所述标记暴力文本特征信息中至少一种特征信息。
优选的,该面向多模态特征语义关联特征的暴恐识别系统还可以设置暴力视频警示模块,暴力视频警示模块与暴力视频识别模块相连接。当系统识别出视频信息为暴力视频信息时,暴力视频警示模块将进行提醒,告知存在暴力视频。
具体的,暴力视频警示模块可以采用声光报警器通过声音和灯光的方式来实现提醒功能。该暴力视频警示模块的设置,能够实现对识别出来的暴力视频进行提醒,使工作人员更加方便直观的查看识别出来暴力视频。
如图5所示,一种面向多模态特征语义关联特征的暴力视频识别系统的实现步骤如下:
S1:获取视频信息,S2:对获取的视频信息分割若干个视频镜头,S3:对每个视频镜头中的视频信息进行处理,S4:对处理后的视频特征信息与常见暴力场景特征信息进行比对,确定是否是暴力视频信息。
步骤S1:通过全景摄像头等视频获取模块获得视频信息,视频信息包括暴力视频信息和非暴力视频信息。
步骤S2:使用视频分割技术对获取的视频信息进行分割,分割成若干个视频信息,视频镜头信息包括待识别音频信息、待识别图像信息和待识别文本信息。
步骤S3:将待识别音频信息、待识别图像信息和待识别文本信息进行预处理,获得相对应的音频处理信息、图像处理信息和文本处理信息。
步骤S4:将每个视频镜头中的音频处理信息、图像处理信息和文本处理信息与常见暴力场景信息中的音频信息、图像信息和文本信息进行比较,与暴力场景图像特征信息相对应的图像处理信息、与暴力场景音频特征信息对应的音频处理信息和与暴力场景文本特征信息相对应的文本处理信息中至少一种为暴力视频信息。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种面向多模态特征语义关联特征的暴力视频识别系统
- 一种面向公交车的乘客对司机的暴力行为识别系统与方法