基于YOLOV5模型的人脸识别方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及一种基于YOLOV5模型的人脸识别方法。
背景技术
人脸识别技术是提取人的脸部特征信息进行身份识别的一种生物识别技术。现有人脸识别一般分为人脸检测、人脸识别、活体检测三个步骤,当输入一帧图像后,人脸检测模块检测出人脸在图像中的坐标位置,接着人脸识别模块提出人脸的特征向量,一般为256维、512维或者1024维,根据这个特征向量与人脸底库存储的人脸特征向量进行对比,判断是否为某一个人。最后通过活体检测模块判断是否为真人或者是使用了图片、视频的人脸。
现有的人脸检测算法模型往往无法兼顾性能和小目标人脸检测,当能够识别到人脸像素小于30x30时,算法性能下降比较快,而当提高算法性能时,小目标人脸往往又检测不到。
同时,在人脸识别模块,当获取一帧图像后,通过深度网络模型提取人脸的特征向量,然后与人脸底库中的特征向量进行比对,判断是否为同一个人,接着再运行活体检测网络判断输入图像是真人还是图像、视频攻击的人脸。这需要运行两个模型,极大的影响系统性能。
发明内容
本发明提供了一种基于YOLOV5模型的人脸识别方法,采用如下的技术方案:
一种基于YOLOV5模型的人脸识别方法,包含以下步骤:
获取若干第一训练图像;
对第一训练图像进行标定;
通过标定好的第一训练图像对YOLOV5模型进行训练;
通过图像采集设备采集若干第二训练图像;
对第二训练图像进行标定;
通过标定好的第二训练图像对FaceNet模型进行训练;
通过图像采集设备采集若干注册用户的人脸图像输入至训练好的YOLOV5模型和FaceNet模型得到若干注册用户的第一人脸特征向量并保存至数据库;
通过图像采集设备采集待识别用户的人脸图像并输入至训练好的YOLOV5模型和FaceNet模型得到该待识别用户的第二人脸特征向量;
将第二人脸特征向量和数据库中的保存的第一人脸特征向量进行相似度匹配,当相似度大于预设阈值时表明该待识别用户是注册用户。
进一步地,在通过标定好的第一训练图像对YOLOV5模型进行训练之前,基于YOLOV5模型的人脸识别方法还包括:
对标定后的第一训练图像进行预处理;
对预处理后的第一训练图像进行Mosaic图像增强操作;
将图像增强后的第一训练图像缩放为统一尺寸。
进一步地,Mosaic图像增强操作包括图像随机缩放、图像随机裁剪和图像随机排布。
进一步地,YOLOV5模型包含依次连接的Focus层、第一Conv层、第一CSP层、第二Conv层、第二CSP层、第三Conv层、第三CSP层、第四Conv层、SPP层和第一CSP层。
进一步地,Focus层的卷积核的数量为1;
第一Conv层的卷积核的数量为1;
第一CSP层的卷积核的数量为3;
第二Conv层的卷积核的数量为1;
第二CSP层的卷积核的数量为9;
第三Conv层的卷积核的数量为1;
第三CSP层的卷积核的数量为9;
第四Conv层的卷积核的数量为1;
SPP层的卷积核的数量为1;
第一CSP层的卷积核的数量为3。
进一步地,YOLOV5模型回归损失采用CIOU计算。
进一步地,图像采集设备为双目摄像头。
进一步地,图像采集设备包含红外摄像头数据和CMOS摄像头。
进一步地,对第一训练图像进行标定的具体方法为:
标定第一训练图像中的人脸坐标和属性信息。
进一步地,属性信息包含用于标示人眼、嘴巴、鼻子和人脸的81个点的坐标。
本发明的有益之处在于所提供的基于YOLOV5模型的人脸识别方法,在识别小目标时能够兼顾性能和目标识别有效性。
本发明的有益之处还在于所提供的基于YOLOV5模型的人脸识别方法,人脸识别和活体检测通过一个模型即可实现,减小了网络的复杂性。
附图说明
图1是本发明的基于YOLOV5模型的人脸识别方法的流程图。
具体实施方式
以下结合附图和具体实施例对本发明作具体的介绍。
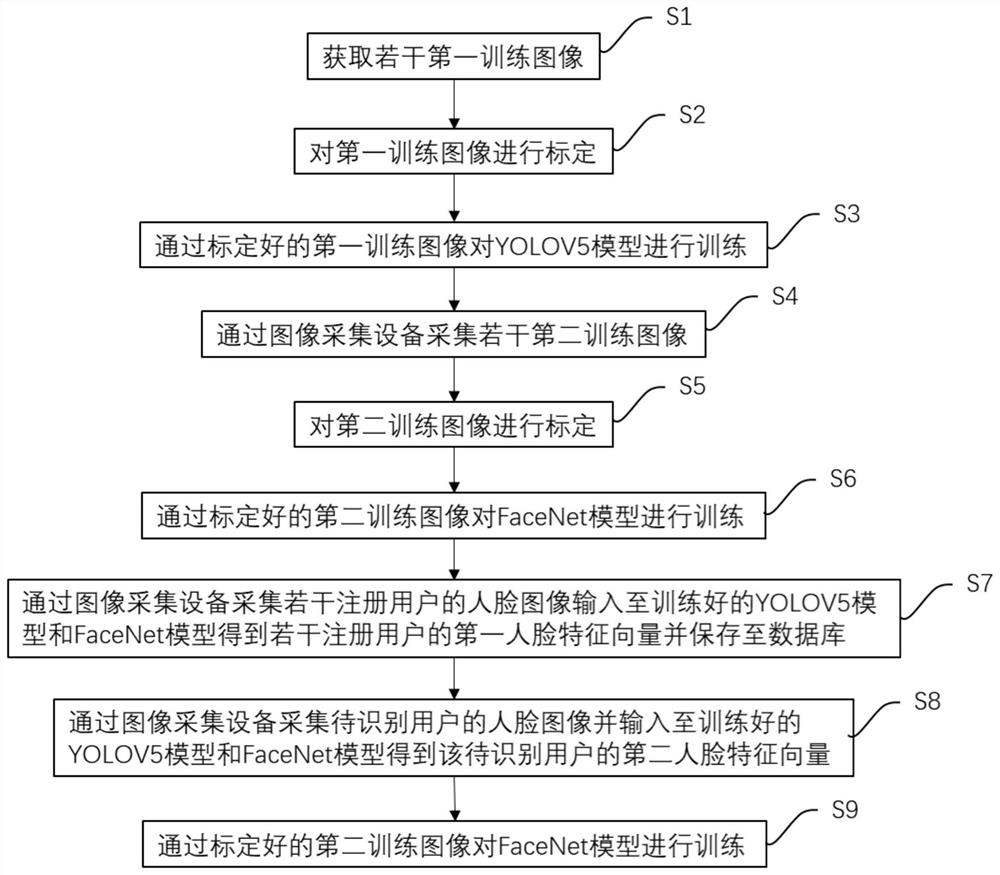
如图1所示为本发明的一种基于YOLOV5模型的人脸识别方法,包含以下步骤:S1:获取若干第一训练图像。S2:对第一训练图像进行标定。S3:通过标定好的第一训练图像对YOLOV5模型进行训练。S4:通过图像采集设备采集若干第二训练图像。S5:对第二训练图像进行标定。S6:通过标定好的第二训练图像对FaceNet模型进行训练。S7:通过图像采集设备采集若干注册用户的人脸图像输入至训练好的YOLOV5模型和FaceNet模型得到若干注册用户的第一人脸特征向量并保存至数据库。S8:通过图像采集设备采集待识别用户的人脸图像并输入至训练好的YOLOV5模型和FaceNet模型得到该待识别用户的第二人脸特征向量。S9:将第二人脸特征向量和数据库中的保存的第一人脸特征向量进行相似度匹配,当相似度大于预设阈值时表明该待识别用户是注册用户。通过以上步骤,简化了识别流程,提高了人脸识别效率。以下对上述步骤进行具体描述。
对于步骤S1:获取若干第一训练图像。
收集开源人脸数据库以及监控视频的数据,找到视频中包含人脸的图像,并保存每一帧包含人脸的图像作为第一训练图像。
对于步骤S2:对第一训练图像进行标定。
对第一训练图像进行标定的具体方法为:
通过人工标定第一训练图像中的人脸矩形框坐标和属性信息,其中,属性信息包含用于标示人眼、嘴巴、鼻子和人脸的81个点的坐标。
对于步骤S3:通过标定好的第一训练图像对YOLOV5模型进行训练。
在本发明中,对搭建的YOLOV5模型进行了优化。具体的,YOLOV5模型包含依次连接的Focus层、第一Conv层、第一CSP层、第二Conv层、第二CSP层、第三Conv层、第三CSP层、第四Conv层、SPP层和第一CSP层。其中,Focus层的卷积核的数量为1。第一Conv层的卷积核的数量为1。第一CSP层的卷积核的数量为3。第二Conv层的卷积核的数量为1。第二CSP层的卷积核的数量为9。第三Conv层的卷积核的数量为1。第三CSP层的卷积核的数量为9。第四Conv层的卷积核的数量为1。SPP层的卷积核的数量为1。第一CSP层的卷积核的数量为3。同时,优选的是,本发明的YOLOV5模型的回归损失采用CIOU计算。
作为一种优选的实施方式,在执行步骤S3之前,基于YOLOV5模型的人脸识别方法还包括:对标定后的第一训练图像进行预处理。对预处理后的第一训练图像进行Mosaic图像增强操作。将图像增强后的第一训练图像缩放为统一尺寸。其中,Mosaic图像增强操作包括图像随机缩放、图像随机裁剪和图像随机排布。
通过本发明的YOLOV5模型,在识别小目标时能够兼顾性能和目标识别有效性。
对于步骤S4:通过图像采集设备采集若干第二训练图像。
本发明中,图像采集设备双目摄像头。具体的,图像采集设备包含红外摄像头数据和CMOS摄像头。其中,CMOS摄像头优选为广角CMOS摄像头。红外摄像头可以获取灰度图像,包含一个图像通道,CMOS摄像头可以获取YUV图像,包含Y、U、V三个通道,每秒可以获取30帧图像。CMOS摄像头采集的数据用来做人脸检测和人脸识别,红外摄像头获取的图像用来做人脸识别和人脸活体检测。
对于步骤S5:对第二训练图像进行标定。
即标定图像是活体还是非活体。
对于步骤S6:通过标定好的第二训练图像对FaceNet模型进行训练。
将双目摄像头采集到的红外摄像头数据和CMOS摄像头采集到的YUV数据作为数据的输入源。并且将采集到的数据做预处理,把活体人脸图像和非活体人脸图像(包括图像攻击照片、视频攻击图像、3D模型攻击图像等)作为训练数据集,对FaceNet模型进行训练,非活体人脸图像作为攻击样本,最终输出人脸特征向量。
在本发明中,FaceNet模型能够同时进行人脸识别和活体检测,减小了网络的复杂性。
对于步骤S7:通过图像采集设备采集若干注册用户的人脸图像输入至训练好的YOLOV5模型和FaceNet模型得到若干注册用户的第一人脸特征向量并保存至数据库。
将注册用户的人脸特征保存在数据库中。
对于步骤S8:通过图像采集设备采集待识别用户的人脸图像并输入至训练好的YOLOV5模型和FaceNet模型得到该待识别用户的第二人脸特征向量。
将待识别的用户的人脸特征提取出来。
对于步骤S9:将第二人脸特征向量和数据库中的保存的第一人脸特征向量进行相似度匹配,当相似度大于预设阈值时表明该待识别用户是注册用户。
将提取出的人脸特征和数据库中保存的人脸特征进行相似度匹配,若从数据库中匹配到大于预设阈值的对应的人脸,表明该待识别用户是注册用户。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 基于YOLOV5模型的人脸识别方法
- 一种基于改进yolov5模型的发芽马铃薯图像识别方法