一种税务系统的智能风险识别方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及风险识别领域,具体涉及一种税务系统的智能风险识别方法。
背景技术
税务系统是一种用于监测纳税人、企业、个体户纳税情况,当前税务系统风险识别的主要方式是通过设置税务指标并设置阈值来筛选可能的风险纳税人;
但是现有的税务系统的智能风险识别方法虽然符合业务规律,但是存在着一下不足:
1、税务数据十分庞大且复杂,数据加工耗时耗力;
2、税务业务日新月异经常更新,导致涉及指标需要不断更新;
3、各地区各行业针对每个指标风险敏感度不同,需要根据不同地区不同行业不同时间段设置不同的值,导致指标系统尤为复杂;
4、设置指标是建立在税务人员经验基础之上,无法穷尽所有风险可能;5、风险应对结果对指标体系的建立没有建立反馈机制。
发明内容
本发明的主要目的在于提供一种税务系统的智能风险识别方法,可以有效解决背景技术中:现有的税务系统的智能风险识别方法虽然符合业务规律,但是存在着税务数据十分庞大且复杂,数据加工耗时耗力;税务业务日新月异经常更新,导致涉及指标需要不断更新;各地区各行业针对每个指标风险敏感度不同,需要根据不同地区不同行业不同时间段设置不同的值,导致指标系统尤为复杂;设置指标是建立在税务人员经验基础之上,无法穷尽所有风险可能;风险应对结果对指标体系的建立没有建立反馈机制的不足之处。
为实现上述目的,本发明采取的技术方案为:
一种税务系统的智能风险识别方法,该方法具体包括如下步骤:
步骤一:该方法具体包括如下步骤:
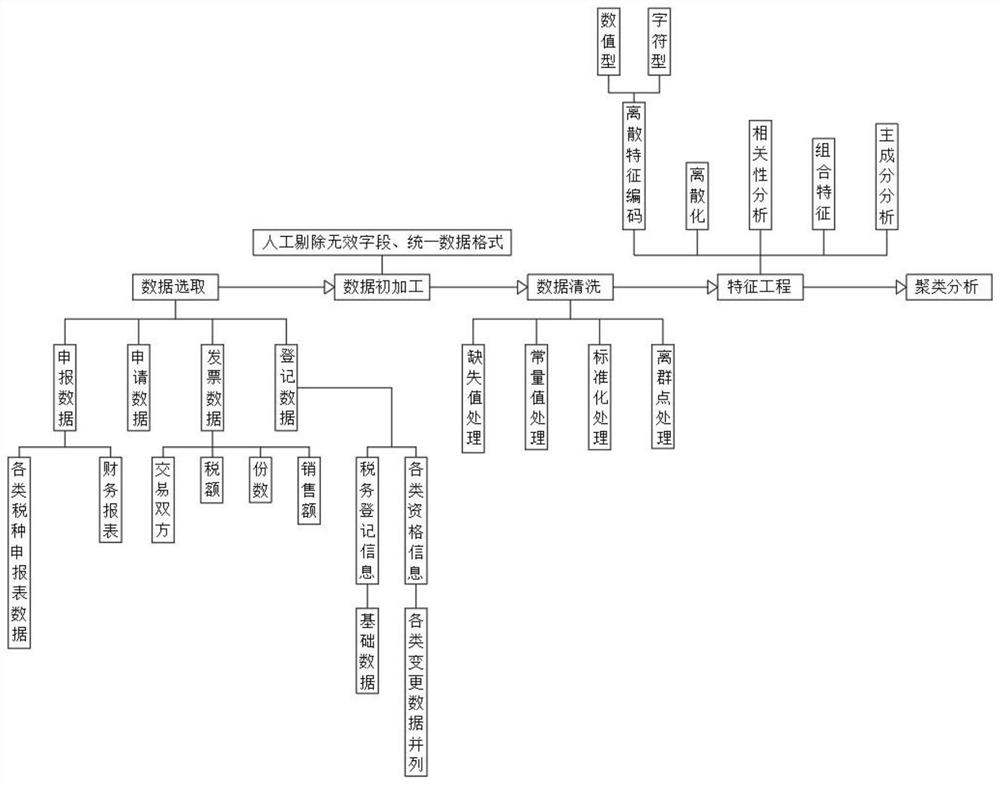
步骤一:数据选取,首先对税务数据根据业务域进行划分,大体分为如下:申报数据、申请数据、发票数据、登记信息数据;
步骤二:数据初加工,剔除掉无效字段,如:各类人员代码等,进行统一、格式化的数据初加工;
步骤三:数据清洗,通过各类算法对数据进行各类处理,如:空值处理与填充、常量值处理、标准化处理、离群点处理,把所有无效数据近一步处理;
步骤四:特征工程,对数据进行有效解析,如:离散特征编码、离散化、相关性分析、组合特征、主成分分析;
步骤五:聚类分析,对所有代表纳税人特征的数据项进行聚类分析,根据唯一标识符进行聚类,然后根据聚类结果进行数据重新分析。
作为本发明的进一步方案,所述步骤一中:
申报数据包括:企业所得税申报数据、增值税申报数据、财务报表申报数据、以及其他各类税种申报表数据,每个税种的申报表分为主表和多张附表,主表和多张附表延伸出数据分叉;
申请数据为根据各类申请事项区分各自不同的业务表和关联方式;
发票数据是根据销货方与购货方的发票开具记录、税额、份数、销售额等等再细分;
登记数据区分为税务登记信息、各类资格信息等,税务登记信息、各类资格信息再细分为基础数据和各类变更记录。
作为本发明的进一步方案,所述步骤二中,数据初加工具体步骤为:
步骤1:先人为剔除一些无效字段;
步骤2:将数据格式进行统一,加工成每户一条的格式化数据;
步骤3:每一户都可以筛选出上千维数据,便于下一步的数据清洗。
作为本发明的进一步方案,所述步骤三中:
空值处理与填充的方式是先统一计算所有特征的空值率,如果空值率过高,我们选择剔除此类无效特征,根据空值率的不同和数据格式的不通进行不同操作方式的数据填充;
常量值处理的方式是统计每个特征对应实际数值,如果某个特征对应所有数值基本上全部相等或超过95%相等,即可选择剔除此列特征;
标准化处理的方式是通过标准化处理对数据进行统一格式的转换,避免由于数据差值过大等原因对结果有不可逆的影响;
离群点处理是避免由于部分数据的偏离而对结果有误导影响。
作为本发明的进一步方案,所述步骤四中:
离散特征编码,是对数据类型的区分和转换,由于数据类型多且复杂,有数值型、字符型、码值等,不同的数据格式我们需要用不同的处理方式进行转换,将数据类型转换为统一格式;
离散化,是指根据数据的离散程度进行一定程度的切片处理,根据数据的分布情况和数据情况再进行相对应的转换,避免由于数据的偏离度过高或过低而对结果有偏差;
相关性分析,是在大数据的视角下计算所有特征两两之间的相关度,根据相关度的高或低再进行不同的数据处理;
组合特征,是指将处理后的特征进行一定程度的扩维,通过算法计算扩维后的数据,使其拟合后续算法线性;
主成分分析,是指在扩维的基础上进行重要特征的提取,保留更为重要的特征。
作为本发明的进一步方案,所述步骤五中,聚类分析建立在所有处理完的数据之上,在每一户纳税人所有维度数据相关性的基础上进行户与户的聚类,根据聚类结果再计算户与户之间的距离和覆盖关系,并在其中标注风险户与未知风险户,根据风险户与未知风险户的聚类情况和距离、覆盖关系判断风险的可能。
与现有技术相比,本发明具有如下有益效果:
1、通过算法进行数据处理,只需设置处理规则算法即可对数据进行批量处理,无需人为干预;
2、通过税务大数据分析特征相关性,穷尽所有数据关系,无需更新任何指标;
3、根据行业、地区分别建立分析模型,无需针对每个行业或地区再做数据特殊化处理,根据税务大数据分析出不同情况下的数据特征;
4、通过算法处理并分析数据,可以穷尽所有数据可能;
5、风险应对结果可对模型训练进行补充,实现模型自动迭代。
附图说明
图1为本发明一种税务系统的智能风险识别方法的流程图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
如图1所示,一种税务系统的智能风险识别方法,该方法具体包括如下步骤:
步骤一:数据选取,首先对税务数据根据业务域进行划分,大体分为如下:申报数据、申请数据、发票数据、登记信息数据;
步骤二:数据初加工,剔除掉无效字段,如:各类人员代码等,进行统一、格式化的数据初加工;
步骤三:数据清洗,通过各类算法对数据进行各类处理,如:空值处理与填充、常量值处理、标准化处理、离群点处理,把所有无效数据近一步处理;
步骤四:特征工程,对数据进行有效解析,如:离散特征编码、离散化、相关性分析、组合特征、主成分分析;
步骤五:聚类分析,对所有代表纳税人特征的数据项进行聚类分析,根据唯一标识符进行聚类,然后根据聚类结果进行数据重新分析。
所述步骤一中:
申报数据包括:企业所得税申报数据、增值税申报数据、财务报表申报数据、以及其他各类税种申报表数据,每个税种的申报表分为主表和多张附表,主表和多张附表延伸出数据分叉;
申请数据为根据各类申请事项区分各自不同的业务表和关联方式;
发票数据是根据销货方与购货方的发票开具记录、税额、份数、销售额等等再细分;
登记数据区分为税务登记信息、各类资格信息等,税务登记信息、各类资格信息再细分为基础数据和各类变更记录。
所述步骤二中,数据初加工具体步骤为:
步骤1:先人为剔除一些无效字段;
步骤2:将数据格式进行统一,加工成每户一条的格式化数据;
步骤3:每一户都可以筛选出上千维数据,便于下一步的数据清洗。
所述步骤三中:
空值处理与填充的方式是先统一计算所有特征的空值率,如果空值率过高,我们选择剔除此类无效特征,根据空值率的不同和数据格式的不通进行不同操作方式的数据填充;
常量值处理的方式是统计每个特征对应实际数值,如果某个特征对应所有数值基本上全部相等或超过95%相等,即可选择剔除此列特征;
标准化处理的方式是通过标准化处理对数据进行统一格式的转换,避免由于数据差值过大等原因对结果有不可逆的影响;
离群点处理是避免由于部分数据的偏离而对结果有误导影响。
所述步骤四中:
离散特征编码,是对数据类型的区分和转换,由于数据类型多且复杂,有数值型、字符型、码值等,不同的数据格式我们需要用不同的处理方式进行转换,将数据类型转换为统一格式;
离散化,是指根据数据的离散程度进行一定程度的切片处理,根据数据的分布情况和数据情况再进行相对应的转换,避免由于数据的偏离度过高或过低而对结果有偏差;
相关性分析,是在大数据的视角下计算所有特征两两之间的相关度,根据相关度的高或低再进行不同的数据处理;
组合特征,是指将处理后的特征进行一定程度的扩维,通过算法计算扩维后的数据,使其拟合后续算法线性;
主成分分析,是指在扩维的基础上进行重要特征的提取,保留更为重要的特征。
所述步骤五中,聚类分析建立在所有处理完的数据之上,在每一户纳税人所有维度数据相关性的基础上进行户与户的聚类,根据聚类结果再计算户与户之间的距离和覆盖关系,并在其中标注风险户与未知风险户,根据风险户与未知风险户的聚类情况和距离、覆盖关系判断风险的可能。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种税务系统的智能风险识别方法
- 一种基于物联网的电力作业安全监测及智能风险识别方法