一种基于互监督的标注激发和基于相似度的标签汇聚方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明涉及众包标注领域,更具体地说,涉及一种标注过程控制和标签获取的方法。
背景技术
深度学习领域的一个关键挑战是获得大量数据的可靠标注,专家标注的方法既费时又昂贵,因此众包标注方法已经成为解决这一难题的主要手段。然而,在众包标注过程中,由于无法保证标注者对任务的理解水平、标注过程中的专注程度等,使得最终整体标注质量较差。此外,由于标注者可能会给出低质量的答案,因此基于冗余的方法被广泛采用,它首先将每个样本分配给多个标注者,然后根据分配的标注者的标注推断出样本的最终标签,而推断方法是决定最终标签质量的另一关键因素。
现有面向众包的标注质量控制方法主要分为三类:预筛选,后处理和实时监督。标注前对标注者预筛选的方法往往通过精心设计的任务对标注者对任务的标注能力进行测评,根据测评结果决定能否参与正式标注;标注后对标注数据后处理的方法是在正式标注结束后,根据标注者标注过程中的行为(如标注速度过快等)或与多数标注者的标注一致性等剔除部分标注者的标注数据;标注过程中对标注质量实时监督的方法则是使用专家标注等方法预先标注一小部分数据作为“金标准”数据,并将这些数据随机插入到正式标注过程中,根据标注者在“金标准”数据上的表现对其标注质量进行实时评估,当标注质量低于某一预先设定的阈值时,给予标注者即时反馈。
首先,标注前预筛选可以淘汰部分对任务不具备合格标注能力的标注者,但它对正式标注过程中可能出现的标注者疲乏、不专注等问题无能为力。其次,标注后对标注数据后处理的方法剔除部分质量较差的标注数据的同时,损失了大量标注成本。此外,标注过程中实时监督的方法可以在标注过程中评估标注者的标注质量并给予即时反馈,但是“金标准”数据需要额外的标注开销而且数量往往较少(不超过全部数据的5%),因而难以准确评估标注者在全体数据上的标注质量。
现有标签获取方法中最常用的是多数投票(MajorityVoting,MV)方法,将被标注次数最多的类别选作最终标签。此外,在众包领域还有基于概率图模型和优化方法的标签获取方法。概率图形模型(Probabilistic Graphical Model,PGM)是一种表示随机变量(由节点表示)之间的条件依赖结构(以边表示)的图,基于概率图模型的方法将样本标签和标注者可信度先验概率、标注者给出的标注数据视作已知,将样本最终标签和标注者可信度视作隐变量,构建概率图,并借助期望最大化(Expectation Maximization,EM)算法估计出最终样本标签和标注者可信度。优化方法的基本思想是建立一个能反映标注者可信度与样本标签之间关系的自定义优化函数,然后推导出一个迭代方法来共同计算这两组参数。
首先,众包标注过程中,不同标注者的标注质量存在较大差异,而MV方法忽略了这一差异,存在明显的不合理性。其次,基于概率图模型的方法将样本标签的先验概率视作已知,在不同类别样本数量不均衡,尤其个别类别样本数量很少的情况下性能受到显著影响。此外,前人研究表明,基于优化函数的标签获取方法多数情况下性能相对欠佳。
发明内容
针对现有标注过程控制和标签获取方法存在的不足,本发明拟解决的技术问题如下:
1、“金标准”数据的获取带来较大额外标注开销,而且“金标准”数量较少无法准确估计标注者对全体数据的标注质量;
2、标注者可信度的估计受到不同类别样本数量不均衡的影响。
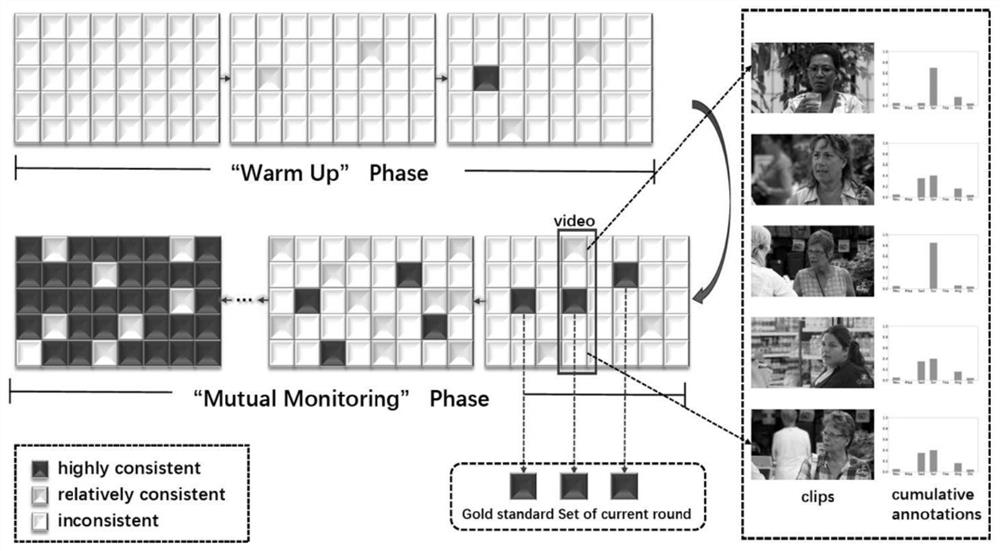
针对技术问题1,本发明提出了基于标注者互监督的标注过程控制方法。本发明首先将整体标注过程划分为多个“轮次”,将之前“轮次”中标注一致性较高的样本作为后续标注的“金标准”数据,对标注者在这些数据上的标注质量进行评估并给予即时反馈,在每个“轮次”结束时更新“金标准”数据。相比于现有标注过程控制方法,本发明通过相互监督“激发”个体标注能力,同时避免了“金标准”数据获取所需的额外标注成本,并且大大增加了“金标准”数据的数量。
针对技术问题2,本发明提出了基于标注相似性的可信度估计方法。本发明将每个标注者与全体标注者意见的一致性作为其可信度的评价指标,根据每个样本的具体标注情况估计标注者对于该样本的可信度,避免了不同类别样本数量不均衡带来的影响。
为实现上述目的,本发明提供了如下技术方案:一种基于标注者互监督的标注过程控制和基于标注相似度的标签获取方法,包括以下步骤:
S1:标注过程设计与划分:
S1-1:将标注过程划分为N个标注“轮次”;
S1-2:将全部数据划分为N个数据子集;
S1-3:标注推进过程中,任务发布者在每个标注“轮次”为每位标注者分配一个数据子集。不同标注者标注不同数据子集,所有标注者在每个标注“轮次”共同完成全体数据的一次标注。
S2:构建“金标准”数据子集:
S2-1:在标注前对标注者进行预筛选和预训练,使得标注者基本可信,进而保证多名标注者的一致意见具有足够的可信度;
S2-2:经过定量分析,本发明设计了“金标准”数据的筛选标准,以确保选取的“金标准”数据具有足够的可靠性。“金标准”数据筛选依据标注一致性,在标注者基本可信的前提下,标注一致性与标签可靠性呈正向关系,因此可以选取具有较高标注一致性的样本作为“金标准”数据。具体地,本发明使用dominance和margin量化标注一致性,并针对两个指标分别设置阈值,满足筛选条件的样本将被选取为“金标准”数据,dominance和margin的具体定义如下:
margin=max(v
其中,v
S2-3:将整个标注过程分为两个阶段——“预热”阶段(前几个标注“轮次”)和“相互监督”阶段(后续标注“轮次”)。在“预热”阶段,每个样本累计标注次数较少,因而只累积标注数据而不进行监督;在“相互监督”阶段继续累积标注数据,同时使用当前“轮次”的“金标准”数据监督标注质量,并在每个“轮次”结束后更新“金标准”数据。
S3:给予标注者即时反馈。每标注一小部分数据,标注系统向标注者提供本阶段的标注质量报告,展示标注质量评分和具体的典型样例。
S3-1:本发明设计了基于信息熵的标注质量评价指标,依据该指标计算每一阶段的标注质量评分,并即时反馈给标注者。本发明设计的标注质量评价指标综合考虑了两方面因素:标注正确性与样本标注难度。标注正确性在与“金标准”数据的标签对比中获得,标注样本难度则采用信息熵进行量化。信息熵往往用于衡量分布离散程度,而在标注者基本可信的前提下,标注的离散程度与样本标注难度正相关。标注质量指标S设计如下:
其中,S
每标注一小部分数据,将标注者在“金标准”数据上的平均标注质量得分作为该阶段综合标注质量评分。
S3-2:典型样例展示。在反馈阶段,除了使用标注质量评分提醒标注者保持专注外,还将标注得分最高和最低的样例展示给标注者。样例展示本质上使得每位标注者对其他标注者们的意见保持某种意义的“可见”,进而对可能存在的对任务的理解偏差及时调整,在标注过程中提升标注能力。
S4:基于标注相似性估计标注者可信度。在标注者基本可信的前提下,多数标注者的一致意见往往具有相对较高的可靠性,然而由于样本标注难度不一,难度较大的样本往往难以形成一致性较高的标注意见。针对上述问题,本发明提出了使用基于标注相似性的标注者可信度评估指标R:
其中,R
第i个标注者的整体可信度
S5:基于标注者可信度的投票方法获得标签。由S4获得每个标注者的标注可信度后,本发明使用基于可信度的多数投票方式获得每个样本的标签,即每个标注者投出的票数是其对应的可信度,而不是1。具体地,第j个样本在第k个类别上的标注结果
本发明与现有技术相比所具有的有益效果在于:
本发明采用标注者之间互相监督的方式,无需额外标注开销;
本发明在确保“金标准”数据具有高可靠性的情况下,大大增加了其数量,可以更加准确地估计出标注者在全体数据上的标注质量;
本发明在给予标注者的即时反馈中,利用展示典型样本的方式,达到了标注者之间相互“指导”的效果,“激发”了标注者的个体标注能力,进而改善了整体标注质量,真正发挥出了“群智”的作用。
本发明提出基于标注相似性估计标注者可信度,并采用可信度投票的标签“汇聚”方法。基于标注相似度的标注者可信度估计方法充分利用了多名基本可信标注者的前提,同时综合考虑了样本标注难度差异,在不同类别样本数量不均衡的条件下稳定提升标签准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,可以根据这些附图获得其他的附图。其中:
图1是本发明的标注过程控制整体示意图;
图2是本发明在反馈阶段生成的标注质量报告示意图;
图3是个体标注者的标注质量变化展示图(其中右图为使用本发明时不同标注者标注质量变化情况,左图为对照组);
图4是每个“轮次”获得的整体标注质量变化展示图(其中前3个“轮次”为“预热”阶段,从第4个“轮次”开始为“相互监督”阶段);
图5是不同标签获得方法的性能对比图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
采用人类情感视频数据集作为实验数据,样本总数为15936。
S1:标注过程设计与划分:
S1-1:雇佣高校学生作为标注者(作为常用的标注者群体之一,高校学生诚信度较好),随后对标注者进行预培训,培训内容包括对任务的基本理解与标注工具的使用;
S1-2:将标注者分为实验组和对照组,用于验证标注过程控制方法的作用;
S1-3:划分标注过程和数据。每个样本将被独立重复标注8次,进而将标注过程划分为8个“轮次”,全部数据划分为8个子集,每个“轮次”每个标注者标注一个数据子集,不同标注者在同一“轮次“标注不同子集,进而保证每个标注“轮次”所有数据被标注一次。
S2:设定筛选标准选取“金标准”数据与对应标注阶段划分:
S2-1:经过定量分析,本实验将筛选标准设定为:dominance>0.5且margin≥3;
S2-2:对应的,前3个“轮次”没有符合筛选标准的数据,被划分为“预热”阶段;后续5个“轮次”为“相互监督”阶段,具体标注过程如图1所示。
S3:标注质量评估指标具体参数指定及具体反馈机制:
标注质量评估指标依据公式(3),为保证标注正确时获得高分(正向反馈),本实验中α取值为0.8;
待标注样本为约800段长视频中截取出的视频片段,每标注完一段长视频中的所有片段,生成标注报告并向标注者反馈。反馈报告中包含设计如图2所示,包含该阶段标注整体得分和典型样例展示;
S4:标注者可信度估计与标签产生:
S4-1:在标注过程全部结束后,依据获得的标注数据和公式(4)计算每个标注者的可信度;
S4-2:依据标注可信度进行多数投票,得到每个样本的最终标签。
实验结果分析:
因为缺乏标签的真值(groundtruth),众包标注往往使用多次独立标注的整体一致性衡量整体标注质量。本实验采用最常用的一致性度量指标之一Fleiss’Kappa系数定量评价标注质量。首先,对照组和实验组的Fleiss’Kappa系数分别为0.389和0.576,证明了本发明提出的标注过程控制方法的有效性。其次,在“相互监督”阶段(第4到第8个“轮次”),“金标准”数据占比分别为44.9%,40.8%,64.8%,68.0%和76.4%,相比于其他方法,“金标准”数据量大大增加。
此外,图3中展示了对照组和实验组中每个标注者标注质量的变化,图4展示了每个“轮次”实验组所有标注者整体标注质量的变化,两幅图中横坐标Round均为不同的标注“轮次”,纵坐标accuracy是基于所有标注数据得到的标签计算出的准确率,表明本发明提出的标注质量控制方法可以在标注过程中提升标注者的标注能力。
同样,因为缺乏标签的真值,但每个样本被标注次数越多,得到的标签可信度越高,实验组和对照组对每个样本共收集了16次标注,以使用全部标注数据得到的标签作为“金标准”,使用不同数量的标注数据得到的标签与“金标准”的差异来衡量标签获取方法的有效性,使用均方误差(MeanSquareError,MSE)作为衡量指标。MSE可以分解为两部分,即偏差(bias)和方差(variance),分别衡量与“金标准”的差异和自身预测的稳定性。实验结果如图5所示,横坐标为每个使用标注数据的数量,每次由全部标注数据中随机采样,图中实验结果为100次实验的平均值,实验结果表明,本发明提出的标签获取方法优于现有其他方法(其中DS和LFC为基于PGM的方法,PM为基于优化函数的方法)。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于互监督的标注激发和基于相似度的标签汇聚方法
- 一种基于事件远程监督的多标签人物关系自动标注方法