一种基于深度学习的视频编辑系统
文献发布时间:2023-06-19 13:29:16
技术领域
本发明涉及视频编辑领域,具体涉及一种基于深度学习的视频编辑系统。
背景技术
视频编辑是指先用摄影机摄录下预期的影像,再在电脑上用视频编辑软件将影像制作成碟片的编辑过程,视频编辑过程中会使用到视频编辑系统,视频编辑系统是对视频源进行非线性编辑的系统,系统通过对加入的图片、背景音乐、特效、场景等素材与视频进行重混合,对视频源进行切割、合并,通过二次编码,生成具有不同表现力的新视频。
现有的视频编辑系系统,需要用户进行手动编辑,编辑后的视频容易被盗用,给视频编辑系统的使用带来了一定的影响,因此,提出一种基于深度学习的视频编辑系统。
发明内容
本发明所要解决的技术问题在于:如何解决现有的视频编辑系系统,需要用户进行手动编辑,编辑后的视频容易被盗用,给视频编辑系统的使用带来了一定的影响的问题,提供了一种基于深度学习的视频编辑系统。
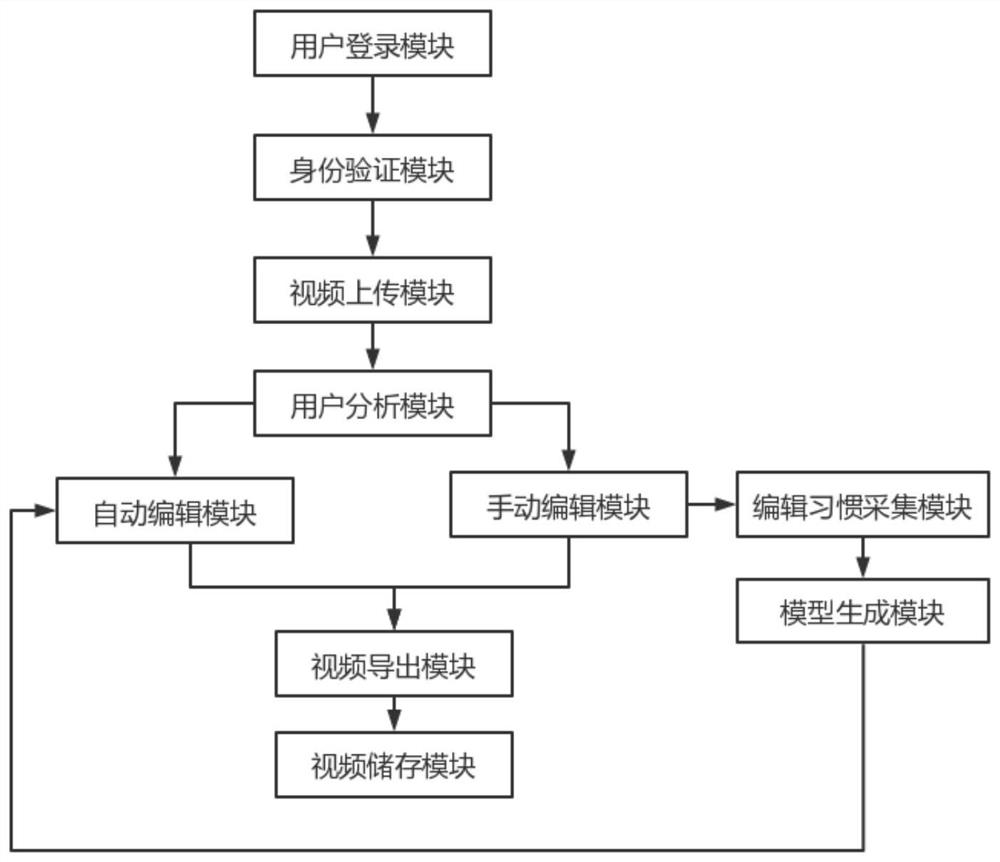
本发明是通过以下技术方案解决上述技术问题的,本发明包括用户登录模块、身份验证模块、视频上传模块、用户分析模块、自动编辑模块、手动编辑模块、编辑习惯采集模块、模型生成模块、视频导出模块与视频储存模块;
所述用户登录模块用于采集用户登录系统时的实时登录信息,所述实时登录信息包括人脸影像信息与账号密码信息;
所述身份验证模块内储存者允许登录用户的身份信息,实时登录信息被发送到身份验证模块,身份验证模块对实时登录信息进行验证验证通过后用户即允许使用视频上传模块进行视频上传;
所述视频上传模块用于用户上传待编辑的视频,所述用户分析模块用于对用户编辑次数的历史信息进行分析,将用户分为信息新用户与老用户;
当用户为新用户时,其导入的待编辑视频被发送到手动编辑模块,所述手动编辑模块用于用户进行手动的视频编辑处理,所述编辑习惯采集模块用于采集用户的编辑习惯信息,并将编辑习惯信息发送到模型生成模块,生成自动编辑模型信息,用户每使用手动编辑视频预设次数后,自动编辑模型即进行更新;
当用户信息为老用户时,即生成自动编辑推荐信息,自动编辑推荐信息被发送给用户,用户回复确认后,待编辑视频即被发送到自动编辑模块,所述自动编模块根据模型生成模块生成的自动编辑模型进行视频编辑;
所述自动编辑模块与手动编辑模块编辑完成的视频均通过视频倒出模块倒导出,所述视频导出模块将视频导入视频储存模块中进行出,经过身份验证的用户允许提取出视频储存模块中的视频。
进一步在于,所述身份验证模块的验证方式包括人脸信息验证与账号密码验证,当人脸信息验证与账号密码验证中的任意一个验证通过时,即允许该用户登录系统提取视频和编辑视频。
进一步在于,所述人脸信息验证的具体过程如下:
步骤一:提取出采集到的用户的登录时的实时人脸影像信息,从中进行特点的提取获取到第一特征区域与第二特征区域;
步骤二:获取到第一特征区域与第二特征区域后,计算出到第一特征区域与第二特征区的面积得第一验证参数M1与第二验证参数M2;
步骤三:通过公式(M1+M2)/(M1-M2)/(M1/M2)=M
步骤四:提取出预存的用户验证参数M
进一步在于,所述第一特征区域与第二特征区域的提取穿过如下:
步骤(1):提取出采集到的实时人脸影像信息,从中提取出一张清晰度最高的包含人脸五官的照片;
步骤(2):将两个眼睛的外眼角标记为点A1和点A2,将两个嘴角分别标记为垫A3和点A4,将鼻尖点标记为点A5,将两个耳垂的最低点标记为点A6和点A7,其中点A1和点A6在同一侧,点A2和点A7在同一侧;
步骤(3):将A1和点A2连线得到线段L1,将点A1和点6连线得到线段L2,将点A6和点A7连线得到线段L3,将点A7和点A2连线得到线段L4,线段L1、L2、L3和L4围成梯形Mm1,即第一特征区域;
步骤(4),将点A3、点A4、点A5按照顺序依次连线得到线段W1、W2和W3,线段W1、W2和W3围成三角形Mm2,即第二特征区域Mm2;
步骤(5):测量出线段L1的长度、线段L3的长度和线段L1与线段L3之间的距离后,再将线段L1标记为H,通过公式(L+L2)*H/2=M1,计算出第一验证参数M1;
步骤(6):以点A3为端点做一条垂直与线段W2的线段W4,测量出线段W4的长度和线段W2的长度,再通过公式(W4+W2)/2=M2,计算出第二验证参数M2。
进一步在于,所述账号密码验证的具体过程如下:提取出用户输入的账号密码,用户在输入其账号密码的同时系统记录下了其输入账号密码的总时长,将其标记为T
进一步在于,所述编辑习惯采集模块用于采集用户每次进行视频编辑时使用各项功能的次数信息和参数信息,将功能标记为的种类数量标记为G,将参数信息的数量标记为Y,当任意一项功能和参数的使用次数大于预设值时,即将该项功能提取,并将标记为Gi和Yi,i=1……n,将所有使用次数大于预设值时的功能和参数进行整个即得到用户编辑习惯信息;
所述自动编辑模型为用户编辑习惯信息整合后生成的指令。
进一步在于,所述新用户与老用户的具体区分过程如下:当用户使用该系统的次数小于要预设值时,其即为信息用户,反之即为老用户。
本发明相比现有技术具有以下优点:该基于深度学习的视频编辑系统,能够根据用户的编辑视频习惯为用户推送出自动编辑模式,能够大大的加快视频的编辑速度,并且根据用户每次使用习惯的不同,自动编辑模式也随其变化,保证了自动编辑出的视频符合用户预估目标,同时该系统登录使用和视频提取时,都需进行严格的身份验证,身份验证的设置能够有效减少编辑后的视频被盗用的状况发生,并且两种验证方法的设置,能够避免单次验证失败导致的无法使用该系统或无法提取编辑后的视频的状况发生,让该系统更加值得推广使用。
附图说明
图1是本发明的系统框图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1所示,本实施例提供一种技术方案:一种基于深度学习的视频编辑系统,包括用户登录模块、身份验证模块、视频上传模块、用户分析模块、自动编辑模块、手动编辑模块、编辑习惯采集模块、模型生成模块、视频导出模块与视频储存模块;
所述用户登录模块用于采集用户登录系统时的实时登录信息,所述实时登录信息包括人脸影像信息与账号密码信息;
所述身份验证模块内储存者允许登录用户的身份信息,实时登录信息被发送到身份验证模块,身份验证模块对实时登录信息进行验证验证通过后用户即允许使用视频上传模块进行视频上传;
所述视频上传模块用于用户上传待编辑的视频,所述用户分析模块用于对用户编辑次数的历史信息进行分析,将用户分为信息新用户与老用户;
当用户为新用户时,其导入的待编辑视频被发送到手动编辑模块,所述手动编辑模块用于用户进行手动的视频编辑处理,所述编辑习惯采集模块用于采集用户的编辑习惯信息,并将编辑习惯信息发送到模型生成模块,生成自动编辑模型信息,用户每使用手动编辑视频预设次数后,自动编辑模型即进行更新;
当用户信息为老用户时,即生成自动编辑推荐信息,自动编辑推荐信息被发送给用户,用户回复确认后,待编辑视频即被发送到自动编辑模块,所述自动编模块根据模型生成模块生成的自动编辑模型进行视频编辑;
所述自动编辑模块与手动编辑模块编辑完成的视频均通过视频倒出模块倒导出,所述视频导出模块将视频导入视频储存模块中进行出,经过身份验证的用户允许提取出视频储存模块中的视频。
所述身份验证模块的验证方式包括人脸信息验证与账号密码验证,当人脸信息验证与账号密码验证中的任意一个验证通过时,即允许该用户登录系统提取视频和编辑视频;
两种验证方法的设置,能够避免单次验证失败导致的无法使用该系统或无法提取编辑后的视频的状况发生。
进一步在于,所述人脸信息验证的具体过程如下:
步骤一:提取出采集到的用户的登录时的实时人脸影像信息,从中进行特点的提取获取到第一特征区域与第二特征区域;
步骤二:获取到第一特征区域与第二特征区域后,计算出到第一特征区域与第二特征区的面积得第一验证参数M1与第二验证参数M2;
步骤三:通过公式(M1+M2)/(M1-M2)/(M1/M2)=M
步骤四:提取出预存的用户验证参数M
所述第一特征区域与第二特征区域的提取穿过如下:
步骤(1):提取出采集到的实时人脸影像信息,从中提取出一张清晰度最高的包含人脸五官的照片;
步骤(2):将两个眼睛的外眼角标记为点A1和点A2,将两个嘴角分别标记为垫A3和点A4,将鼻尖点标记为点A5,将两个耳垂的最低点标记为点A6和点A7,其中点A1和点A6在同一侧,点A2和点A7在同一侧;
步骤(3):将A1和点A2连线得到线段L1,将点A1和点6连线得到线段L2,将点A6和点A7连线得到线段L3,将点A7和点A2连线得到线段L4,线段L1、L2、L3和L4围成梯形Mm1,即第一特征区域;
步骤(4),将点A3、点A4、点A5按照顺序依次连线得到线段W1、W2和W3,线段W1、W2和W3围成三角形Mm2,即第二特征区域Mm2;
步骤(5):测量出线段L1的长度、线段L3的长度和线段L1与线段L3之间的距离后,再将线段L1标记为H,通过公式(L+L2)*H/2=M1,计算出第一验证参数M1;
步骤(6):以点A3为端点做一条垂直与线段W2的线段W4,测量出线段W4的长度和线段W2的长度,再通过公式(W4+W2)/2=M2,计算出第二验证参数M2;
通过上述过程能够获取到更好的验证参数信息从而进行更加准确的身份验证。
所述账号密码验证的具体过程如下:提取出用户输入的账号密码,用户在输入其账号密码的同时系统记录下了其输入账号密码的总时长,将其标记为T
所述编辑习惯采集模块用于采集用户每次进行视频编辑时使用各项功能的次数信息和参数信息,将功能标记为的种类数量标记为G,将参数信息的数量标记为Y,当任意一项功能和参数的使用次数大于预设值时,即将该项功能提取,并将标记为Gi和Yi,i=1……n,将所有使用次数大于预设值时的功能和参数进行整个即得到用户编辑习惯信息;
所述自动编辑模型为用户编辑习惯信息整合后生成的指令;
通过上述过程能够更好采集用户的使用习惯信息,使得编辑出的使用模型能够更加符合用户预期。
所述新用户与老用户的具体区分过程如下:当用户使用该系统的次数小于要预设值时,其即为信息用户,反之即为老用户。
综上,本发明在使用时,用户登录模块采集用户登录系统时的实时登录信息,实时登录信息包括人脸影像信息与账号密码信息,身份验证模块内储存者允许登录用户的身份信息,实时登录信息被发送到身份验证模块,身份验证模块对实时登录信息进行验证验证通过后用户即允许使用视频上传模块进行视频上传,视频上传模块用户上传待编辑的视频,用户分析模块对用户编辑次数的历史信息进行分析,将用户分为信息新用户与老用户,当用户为新用户时,其导入的待编辑视频被发送到手动编辑模块,手动编辑模块用户进行手动的视频编辑处理,编辑习惯采集模块采集用户的编辑习惯信息,并将编辑习惯信息发送到模型生成模块,生成自动编辑模型信息,用户每使用手动编辑视频预设次数后,自动编辑模型即进行更新,当用户信息为老用户时,即生成自动编辑推荐信息,自动编辑推荐信息被发送给用户,用户回复确认后,待编辑视频即被发送到自动编辑模块,自动编模块根据模型生成模块生成的自动编辑模型进行视频编辑,自动编辑模块与手动编辑模块编辑完成的视频均通过视频倒出模块倒导出,视频导出模块将视频导入视频储存模块中进行出,经过身份验证的用户允许提取出视频储存模块中的视频。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种基于深度学习的视频编辑系统
- 一种基于UE4的视频编辑系统