一种3D结构光人脸识别方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明属于人脸识别技术领域,特别涉及一种3D结构光人脸识别方法。
背景技术
3D结构光人脸识别是在红外的基础上,增加一个红外点阵发射器,输出的图包括一张红外IR图和一张深度图,不管是深度图还是IR图都是利用红外光的光源,因此可以在在黑暗环境中使用,并且不易被自然光环境干扰。3D结构光的人脸识别的活体检测这块,是通过引入深度图,是使用IR和深度两个人脸图像进行3D的活体检测。而且可以在红外人脸识别防范的攻击算法基础上,加入的深度图携芾深度信息,能够有效防范平面攻击,比如说照片、视频、纸张面具弯曲等材质的攻击,还可以结合红外IR图对表面材质的检测,能防范大部分的普通材质的面具、模型等攻击。
现有结构光人脸识别已经应用于多个领域例如唇语识别、人脸建模等;其中唇语识别的应用较为空白,这是因为现有唇语识别研究多专注于提高识别精度、研究多模态输入特征等方面,对提高唇部视觉特征的有效性关注不多。现有技术将结构光应用于唇语识别的如现有技术1“CN201510837127.3一种基于可穿戴设备的唇语识别方法及系统”其采用结构光建立人脸三维模型,通过三维模型提取唇部特征进而通过特征进行训练获得唇语信息,但其缺点也较为明显,唇部视觉特征的准确有效的识别是现有技术较难以实现,单纯通过三维的嘴部特征实现唇语识别还是有难度的,其原因在于每个人的口音、强调不同发声时调动唇部的肌肉并不相同,因此此方法建立的唇语系统及方法的精度较低;又如现有技术2“CN201611076396.3基于唇语的交互方法以及交互装置”相较于现有技术1而言,现有技术2采用深度、红外、彩色三种模态的图像进行融合,通过多模态融合提高识别精度,但其问题依然在于唇部视觉特征的准确有效的识别是现有技术较难以实现;
同时唇语识别多用于聋哑人辅助,而聋哑人分为聋、哑和聋哑三种,上述的现有技术仅针对单纯的视觉特征进行识别精度较低,所采用的的手段也仅仅是从视觉的角度出发,难以满足所有聋哑人的需求;因此必须通过其他模态信息建立完整的唇语识别方法,提高唇语识别的精度。
发明内容
(一)要解决的技术问题
提供一种多模态融合的方法提高唇语识别的精度,解决现有技术中单一视觉特征识别精度低的问题。
(二)技术方案
本发明通过如下技术方案实现:一种3D结构光人脸识别方法;
步骤100:向目标用户上半部分肢体投射结构光,通过传感器接收上半部分肢体信息及音频信息;
步骤200:上半部分肢体信息预处理,获取动作时的嘴部信息、手部信息;
步骤300:音频数据预处理,基于音频数据进行语音识别;
步骤400:依据动作时的获取动作时的嘴部信息、手部信息及音频数据进行特征融合处理,实现人脸唇语识别。
作为上述方案的进一步说明,所述步骤100的投射结构光采用的是正向投射方式;
所述步骤100的上半部分肢体信息包括彩色图像数据及深度数据。
作为上述方案的进一步说明,所述步骤200上半部分肢体信息预处理包括如下流程:
步骤210:利用深度数据构建人脸轮廓模型;
步骤220:三维人脸分割算法提取嘴部特征;
步骤230:基于嘴部特征获取唇语信息。
作为上述方案的进一步说明,所述步骤210具体的包括如下步骤:
步骤211:彩色图像数据及深度数据进行配准;
步骤212:对深度图像进行降噪滤波;
步骤213:面部检测及脸部特征点提取;
步骤214:人脸轮廓模型数据归一化。
作为上述方案的进一步说明,所述步骤220具体的包括如下步骤:
步骤221:彩色图像数据及深度数据进行配准、映射;
步骤222:基于脸部特征点构建嘴部轮廓线;
步骤223:基于轮廓线对嘴部特征进行分割,并将分割结果映射至人脸轮廓模型实现人脸轮廓模型嘴部特征的切割。
作为上述方案的进一步说明,所述步骤200上半部分肢体信息预处理还包括如下流程:
步骤240:构建人体上半身骨骼关键点图
步骤250:基于彩色图像数据、深度数据及上半身骨骼关键点图进行帧间配对;
步骤260:区域分割提取手臂、手部的动作信息;
步骤270:基于手臂、手部的动作信息获取手语信息。
作为上述方案的进一步说明,所述步骤260具体包括如下步骤:
步骤261:根据上半身骨骼关键点提取右手腕、右手、左手腕、左手的轨迹二维坐标;
步骤262:将二维坐标转化为三维点云信息,并归一化,提取手臂、手部的轨迹特征形成轨迹图;
步骤263:基于手势分割算法提取手势关键帧;
步骤264:轨迹与手势关键帧进行融合学习。
作为上述方案的进一步说明,所述步骤400具体的包括如下步骤:
步骤410:输入嘴部信息、手部信息及音频数据输出的特征;
步骤420:特征融合;
步骤430:输出结果。
作为上述方案的进一步说明,所述步骤430输出结果指的是基于识别到当前人脸的目标用户所要表达语言。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
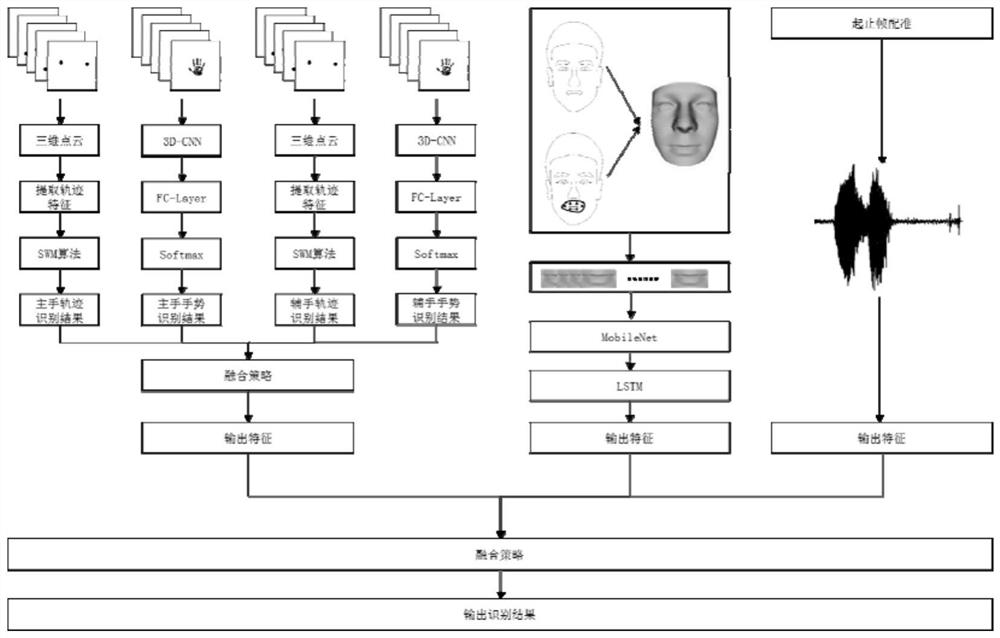
图1为本发明实施例的整体算法模型总体框图;
图中3D-CNN表示3D卷积神经网络;FC-Layer表示3D卷积神经网络中的全连接层;MobileNet表示MobileNet神经网络;LSTM表示长短时记忆网络结构;Softmax表示Softmax分类器。
(三)有益效果
本发明相对于现有技术,具有以下有益效果:本发明通过结构光的人脸识别及语音实现手语、语音、唇语三种模态信息的融合,提供一种具备聋、哑和聋哑三种人士的多元辅助的融合方法;解决了在唇部运动过程中如何产生更好地反映说话人视觉信息的特征的问题,进一步提高了识别的准确率;从不同模态到视位的映射,解决视觉歧义问题;同时多模态的融合也解决了单模态无法识别时,无法输出结果的问题,最大程度保证了方法在实际应用中的可行性。
具体实施方式
实施例,请参阅图1
步骤100:向目标用户上半部分肢体投射结构光,通过传感器接收上半部分肢体信息及音频信息;步骤100的投射结构光采用的是正向投射方式;所述步骤100的上半部分肢体信息包括彩色图像数据及深度数据。
需要进一步说明的是本实施例采用KinectV1进行结构光的投射及数据的提取;其原理在于KinectV1自带的红外发射器通过光栅不断辐射光至目标用户,在目标用户的上半部分肢体投射随机的散斑,再利用其自带的红外摄像头记录空间中散斑的分布,进而实现深度数据的获取;同时KinectV1自带RGB摄像头,可以同步提取彩色图像数据;需要进一步说明的是在本实施例中为了方便阐述只采用Kinect设备进行实验,也可采用其他方法代替组合,如奥比中光的3D传感摄像头;
步骤200:上半部分肢体信息预处理,获取动作时的嘴部信息、手部信息;
具体的包括如下流程:
步骤210:利用深度数据构建人脸轮廓模型;
由于Kinect摄像头的红外摄像头与RGB摄像头并非同轴拍摄,因而从目标用户身上提取到的深度数据和彩色图像数据并不匹配,所以需要对彩色图像数据及深度数据进行配准;在本实施例中采用投影变换公式进行计算,具体的投影变换公式如下:
(x,y,z)
式中,R为旋转矩阵,T为平移矩阵,(x,y,z)
步骤212:对深度图像进行降噪滤波;
降噪滤波的方法有多种,在本实施例中采用多帧中值滤波算法进行滤波降噪,其优点在于中值滤波是图像处理中的一个常用步骤,它对于斑点噪声和椒盐噪声来说尤其有用,该方法利用直方图可以高效地获得图像中亮度、对比度、最大亮度、最小亮度及亮度中值,基于此可以快速平滑移除由KINECT传感器产生的噪声曲面,并且对称填充。需要进一步说明的是本实施例所用的降噪滤波只是其中之一,其他算法也可以实现;如平滑重采样算法等;
步骤213:面部检测及脸部特征点提取;
Kinect辐射的面为目标用户的上半部分肢体,而非直接采用面部图像数据;因此需要对人脸及上半肢体躯干的区分,实现人脸的追踪;而Kinect骨骼追踪技术可以很好的建立人体骨骼的空间坐标,区分头部及上半肢体躯干的每个空间坐标,通过这一方法可以实现脸部与上半肢体躯干的区分;区分完成后Kinect可以实现面部的追踪;追踪完成后对面部的数据进行进一步的提取,在本实施例中采用常规的鼻尖定位法,进而判断面部的轮廓数据,通过AAM算法进行特征点定位及提取。
步骤214:人脸轮廓模型数据归一化。归一化的目的在于减轻目标用户与Kinect之间的距离对数据产生的影响。
步骤220:三维人脸分割算法提取嘴部特征;
具体的包括如下流程:
步骤221:彩色图像数据及深度数据进行配准、映射;
步骤222:基于脸部特征点构建嘴部轮廓线;
步骤223:基于轮廓线对嘴部特征进行分割,并将分割结果映射至人脸轮廓模型实现人脸轮廓模型嘴部特征的切割。
此步骤的原理Kinect可以同步采集深度数据和彩色图像数据,通过采用投影变换公式可以实现两种数据的匹配和映射,此时只需要通过步骤213提取的面部特征点,利用特征点确定嘴部的坐标,在基于坐标对构建嘴部的轮廓线;轮廓线建立完成后通过轮廓线的坐标映射至人脸轮廓模型,对人脸轮廓模型进行分割提取嘴部的信息;
步骤230:基于嘴部特征获取唇语信息。
需要进一步说明的是此步骤是为了完成基于人脸识别后唇语识别,采用的是MobileNet神经网络及LSTM长短时记忆网络结构进行完成;此处不再赘述;
步骤240:构建人体上半身骨骼关键点图;此步骤采用的是Kinect带的骨骼追踪算法进行实现,上文已有阐述;
步骤250:基于彩色图像数据、深度数据及上半身骨骼关键点图进行帧间配对;帧间配对的目的在于Kinect获得的数据为时域数据,而彩色图像数据、深度数据及上半身骨骼关键点图是分开进行处理,需要将三种个数据配对,保证每种数据的特征在时间上都能得到一一对应;
步骤260:区域分割提取手臂、手部的动作信息;
具体包括如下步骤:
步骤261:根据上半身骨骼关键点提取右手腕、右手、左手腕、左手的轨迹二维坐标;
步骤262:将二维坐标转化为三维点云信息,并归一化,提取手臂、手部的轨迹特征形成轨迹图;
步骤263:基于手势分割算法提取手势关键帧;
步骤264:轨迹与手势关键帧进行融合学习。
需要进一步说明的是,本实施例手势部分仅仅识别中国手语,中国手语的特点在于一只手作为主要,另一只手作为辅助;基于Kinect可以获得手及手肘的空间坐标,基于空间坐标建立三维点云,通过点云的信息可以提取手及手肘两个部分的轨迹特征,通过SVM分类算法可以得到主手轨迹识别结果、辅手轨迹识别结果;具体的SVM分类算法采用的流程为:建立双手手语数据集—SVM算法训练识别—获得手部轨迹识别结果,SVM算法适用范围较广,案例较多此处不再对流程的具体步骤进行展开赘述;
步骤270:基于手臂、手部的动作信息获取手语信息。
需要进一步说明的是后获取手语信息是轨迹与手势进行数据融合,其融合方案如下:
A主手轨迹识别结果,主手手势识别结果,辅手轨迹识别结果,辅手手势识别结果,四类结果都有效识别了,即网络及SVM分类算法都有效识别了,此时根据四类样本的具体情况估计出识别结果的置信度,依据置信度计算权值,通过自适应权值分配策略分配权值,在基于加权平均模型获得最后的结果,公式如下:
R=w
式中R代表最终结果,w代表权值,f代表网络或SVM分类算法的输出;a1代表主手轨迹,a2代表辅手轨迹,b1代表主手手势,b2代表辅手手势;
B主手轨迹识别结果,主手手势识别结果,辅手轨迹识别结果,辅手手势识别结果,四类结果都无法识别了,则输出无法识别结果;
C主手轨迹识别结果,主手手势识别结果,即主手效识别了,则输出概率最大的主手类型作为最终输出的结果;
D辅手轨迹识别结果,辅手手势识别结果,即辅手有效识别了,则输出概率最大的辅手类型作为最终输出的结果;
E主手轨迹识别结果,主手手势识别结果,辅手轨迹识别结果,辅手手势识别结果,四类结果中若未识别到有效轨迹,即主手辅手的轨迹无法识别,则输出概率最大的主手辅手手势类型作为最终输出的结果;
F主手轨迹识别结果,主手手势识别结果,辅手轨迹识别结果,辅手手势识别结果,四类结果中若未识别到有效手势,则输出无法识别结果;
G主手轨迹识别结果,主手手势识别结果,辅手轨迹识别结果,辅手手势识别结果,四类结果中只识别到主手轨迹识别结果/辅手手势识别结果、主手手势识别结果/辅手轨迹识别结果,则输出无法识别结果;
需要进一步说明的是上述融合策略采用的是决策融合仅是对本实施例进行阐述,并非对融合策略部分的进一步限定;
步骤300:音频数据预处理,基于音频数据进行语音识别;
需要进一步说明的是语音识别应用范围较广,案例较多此步骤不再做过多的赘述,其语音识别的结果以文本方式进行输出;同时本实施例的音频数据采集是基于Kinect自带的语音模块进行同步采集。
步骤400:依据动作时的获取动作时的嘴部信息、手部信息及音频数据进行特征融合处理,实现人脸唇语识别。
具体的还包括如下步骤:
步骤410:输入嘴部信息、手部信息及音频数据输出的特征;
步骤420:特征融合;
步骤430:输出结果。输出结果指的是基于识别到当前人脸的目标用户所要表达语言。
需要进一步说明的是,特征融合部分依然采用决策融合的方式进行融合,仅是对本实施例进行阐述,并非对融合策略部分的进一步限定;
其融合方案如下:
A嘴部信息、手部信息及音频数据都有效识别了,此时根据四类样本的具体情况估计出特征的置信度,依据置信度计算权值,通过自适应权值分配策略分配权值,在基于加权平均模型获得最后的结果,公式如下:
R=w
式中R代表最终结果,w代表权值,f代表输出特征;
B若音频数据未有效识别或手部信息未有效识别,其他两个特征有效识别,此时根据两类样本的具体情况估计出特征的置信度,依据置信度计算权值,通过自适应权值分配策略分配权值,在基于加权平均模型获得最后的结果,公式如下:
R=w
式中R代表最终结果,w代表权值,f代表输出特征;
C若音频数据未有效识别和手部信息未有效识别,则输出结果中概率最大的嘴部信息作为最终输出的结果;
D若嘴部信息未有效识别,则输出概率最大的音频数据作为最终输出结果。
本发明通过结构光的人脸识别及语音实现手语、语音、唇语三种模态信息的融合,提供一种具备聋、哑和聋哑三种人士的多元辅助的融合方法;解决了在唇部运动过程中如何产生更好地反映说话人视觉信息的特征的问题,进一步提高了识别的准确率;从不同模态到视位的映射,解决视觉歧义问题;同时多模态的融合也解决了单模态无法识别时,无法输出结果的问题,最大程度保证了方法在实际应用中的可行性。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 结合3D结构光、红外光及可见光的人脸识别方法及系统
- 一种3D结构光人脸识别方法