一种解决数据仓库账务日切测试数据采集的方法及系统
文献发布时间:2023-06-19 13:45:04
技术领域
本发明属于数据处理技术领域,具体涉及一种解决数据仓库账务日切测试数据采集的方法及系统。
背景技术
在主流的商业银行中,与数据仓库交互主要是通过业务系统卸文件。互联网银行以大数据技术Sqoop MapReduce主动采集业务系统数据。虽说主流商业银行系统通过文件交互进行解耦,将数据进行落地,数据仓库主动获取数据文件,然后将数据加载入数据仓库。然而整体运算效率比直接通过大数据技术进行数据采集慢了许些。但是在使用大数据技术进行数据采集时同时遇到了一些问题,在生产环境业务系统按日正常日切,能获取到正确的数据。在测试环境,主流商业银行业务系统日切的同时,系统时间一并进行了日切,因测试场景需要,一个自然日多次切日,以满足不同的业务场景测试需要,主流商业银行完全能满足这样的业务场景,但在互联网银行,以容器化部署微服务,一台物理机可以容器化多个应用,如果在业务日切的同时将机器系统时间一并进行修改,那势必会影响到其他应用使用系统时间。本专利是解决在互联网银行,一天经历多次日切,表里last_update_time是同一天,怎么识别出日切后有效增量数据的问题。
互联网银行数据仓库建设中,没有“文件交换平台”,采用Sqoop MapReduce主动采集业务系统数据,然后将数据装载到贴源层。在增量采集的情况下,一般以last_update_time为增量条件作为采集数据的WHERE条件。但是,业务系统在测试时,同一自然日多次切日,last_update_time的值为同一天,日切后的采集数据中含有之前日切数据(除第一次切日数据),因为last_update_time为同一天,这样会导致无法识别真实增量数据,为后续的数据检证、特别是账务检证带来更多的不确定性。
为了获取真实增量数据,有必要提出一种解决数据仓库账务日切测试数据采集的方法及系统。
发明内容
针对现有技术中,一日多次日切或多日一次日切得到的数据重复,本发明提供了一种解决数据仓库账务日切测试数据采集的方法及系统,能有效识别真实增量数据,为后续的数据验证,特别是财务检证带来方便。
一方面,本发明提供了一种解决数据仓库账务日切测试数据采集的方法,包括以下步骤:
S1、在测试环境的系统中设置第一日期参数和第二日期参数,在存储模块中分别建立第一日期参数和第二日期参数对应的存储空间及相应的存储结构;
其中,第一日期参数表示一个自然日中第一次日切的时间,第二日期参数表示每次日切后的数据在存储介质中对应的存储区域;
S2、在测试环境的系统中通过源系统表名参数获取用于日期的数据采集配置信息;
S3、根据步骤S2中的数据采集配置信息对数据库中的数据进行日切,将日切的数据存储在对应的第二日期参数的存储空间后,根据当前自然日的第二日期参数的数量和采集的数据量,判断本次采集的数据的类型,如果为全量数据,则将该全量数据保存在系统对应的目录中,如果为增量数据,则将数据进行比较和去重,得到实增数据,并将该实增数据保存在系统对应的目录中。
优选的,步骤S1中还包括,
在测试环境的系统中设置第三日期参数,在存储模块中建立第三日期参数对应的存储空间及相应的存储结构;
其中,第三日期参数表示表示与上一个日切时间在同一个日切日、且与上一个日切时间在不同的自然日里的时间。
优选的,第三日期参数为可选参数。
优选的,步骤S3中,去重的具体方法如下,
比较当前采集的数据和上一第二日期参数对应存储空间中的数据,删除当前采集的数据和上一第二日期参数中重复的数据,得到实增数据。
另一方面,本发明还提供了一种解决数据仓库账务日切测试数据采集的系统,包括,采集模块:用于采集配置信息、增量数据和全量数据;
存储模块:用于储存日切后的数据并创建对应的存储区域;
去重模块:用于去除多个日切数据的相同数据,得到实增数据。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.整体方案解决了以微服务容器化部署业务系统,在不同的日切场景下,为了满足数据仓库数据测试需求而设计;
2.在大数据技术的背景下,使用Sqoop MapReduce的采集效率相比主流商业银行采集文件与数据仓库交互性能有明显提高;
3.在多个自然日进行一次日切,通过设置可选参数确定数据范围;
4.在大数据环境下运行数据采集,原有增量采集的条件与存储模块上的分区目录进行拆分,同一日日切多次,采集的条件不变,可落在存储模块中不同的分区,从而装载贴源层数据表时不同的分区里;
5.在同一自然日日切多次,将源系统数据采集放到存储模块中,通过去重模块能快速将两次日切数据去掉出重复数据,形成一个真实的数据增量。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
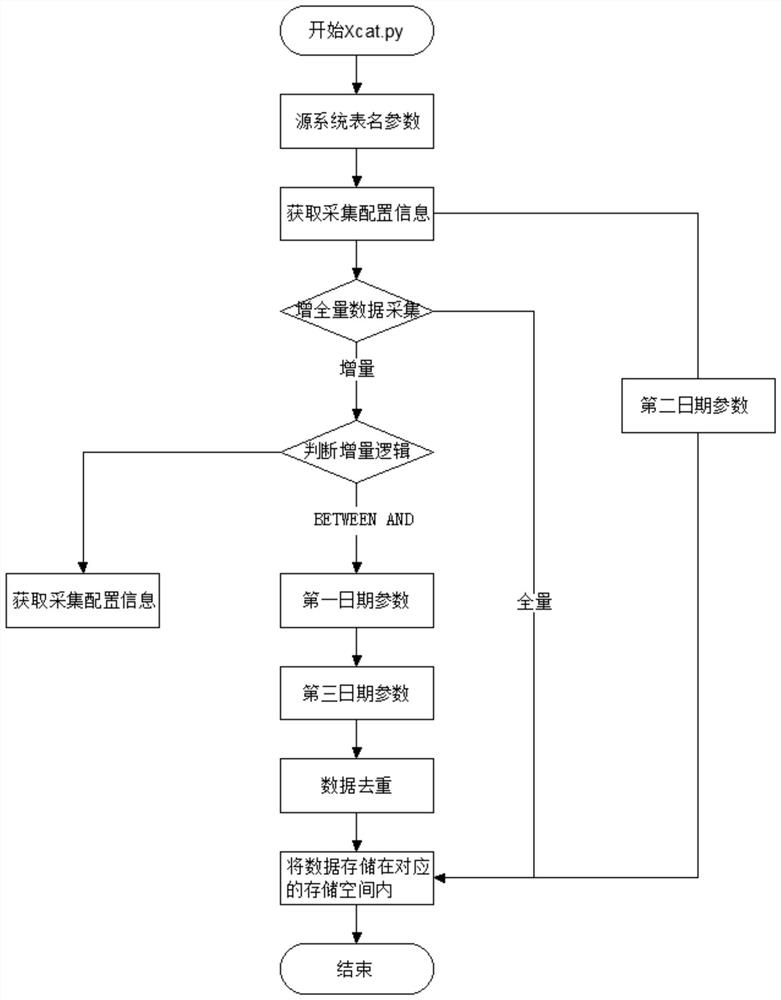
图1是本发明实施例所述解决数据仓库账务日切测试数据采集的方法的流程图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
在本申请实施例的描述中,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
下面结合附图对本发明作详细说明。
如图1所示,一种解决数据仓库账务日切测试数据采集的方法,包括以下步骤:
S1、在测试环境的系统中设置第一日期参数和第二日期参数,在存储模块中分别建立第一日期参数和第二日期参数对应的存储空间及相应的存储结构;
其中,第一日期参数表示一个自然日中第一次日切的时间,第二日期参数表示每次日切后的数据在存储介质中对应的存储区域;
S2、在测试环境的系统中通过源系统表名参数获取用于日期的数据采集配置信息;
S3、根据步骤S2中的数据采集配置信息对数据库中的数据进行日切,将日切的数据存储在对应的第二日期参数的存储空间后,根据当前自然日的第二日期参数的数量和采集的数据量,判断本次采集的数据的类型,如果为全量数据,则将该全量数据保存在系统对应的目录中,如果为增量数据,则将数据进行比较和去重,得到实增数据,并将该实增数据保存在系统对应的目录中。
本实施例中,测试环境在Xcat.py程序中运行。
本实施例中,第一日期参数通常定义为日切日期,表达以该日期作为SQL语句中WHERE条件(WHERE last_update_time>=第一日期参数)采集源系统的数据(last_update_time相当于系统时间),同时该参数作为该表在HDFS上文件分区的位置,加载到贴源层中的该表ETL_DT字段的值;模型层每天跑批量以该ETL_DT作为条件从贴源层获取数据集合;源系统表名参数获取采集源系统的表名;通过Xcat.py程序读取后台配置信息,采集源系统数据。
本实施例中,第二日期参数指定存入HDFS上的分区字段,代替了原有第一日期参数作为HDFS上的分区字段,第一日期参数的功能是作为采集源系统WHERE条件中≥或者BETWEEN第一日期参数AND第一日期参数的参数;第二日期参数解决的问题是,同一天跑多个批次,数据都能准确落在HDFS的不同分区位置,同时在Hive里存储在不同的分区ETL_DT中。
本实施例中,在Xcat.py程序中新增在HDFS上最近两个分区数据去重功能。
在另一个实施例中,步骤S1中还包括,
在测试环境的系统中设置第三日期参数,在存储模块中建立第三日期参数对应的存储空间及相应的存储结构;
其中,第三日期参数表示表示与上一个日切时间在同一个日切日、且与上一个日切时间在不同的自然日里的时间。
本实施例中,测试人员在第一自然日未完成且为日切的数据,在第二自然日继续做测试,并做日切。用第一日期参数不能采集完整的数据,这时新增第三日期参数在增量WHERE条件中BETWEEN第一日期参数AND第二日期参数来达到以增量采量数据需求。
在另一个实施例中,第三日期参数为可选参数。
本实施例中,第三日期参数不局限于第二自然日,可根据日切需求自由选择时间。
在另一个实施例中,步骤S3中,去重的具体方法如下,
比较当前采集的数据和上一第二日期参数对应存储空间中的数据,删除当前采集的数据和上一第二日期参数中重复的数据,得到实增数据。
本实施例中,同一日日切两次,第一次在A时日切,第一日期参数采集到0时至A时的数据,第二次在B时日切,第一日期参数采集到0时至B时的数据,在第二次日切时,没能获得真实的增量数据(A时至B时的数据),将第一次日切与第二次日切去掉重复数据后,识别第二次日切真实增量数据。
在另一个实施例中,一种解决数据仓库账务日切测试数据采集的系统,包括,
采集模块:用于采集配置信息、增量数据和全量数据;
存储模块:用于储存日切后的数据并创建对应的存储区域;
去重模块:用于去除多个日切数据的相同数据,得到实增数据。
以上所述实施例仅表达了本申请的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。