与小麦粒长主效QTL连锁的SNP分子标记KASP-BE-kl-sau2及应用
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及作物分子遗传育种技术领域,特别是涉及与小麦粒长主效QTL连锁的SNP分子标记KASP-BE-kl-sau2及应用。
背景技术
普通小麦(Triticum aestivum L.2n=6x=42)是温带地区的主要作物之一,为人类的饮食贡献了必需的氨基酸、矿物质和维生素,以及有益的膳食纤维。由于全球气候变化、人口增长和耕地面积的大量减少,只有提高作物产量潜力,才能满足未来粮食需求。因为粮食产量构成因素,如每穗可育小穗数、千粒重和单位面积有效分蘖数,通常表现出比粮食产量更高的遗传力,针对这些因素进行改良是提高小麦籽粒产量潜力的重要途径。
现代育种模式下小麦品种间遗传多样性的降低导致小麦改良的遗传基础日益狭窄。与祖先小麦品种相比,现代种质库中籽粒性状的表型变异明显减少。小麦的单株籽粒产量由每株穗数、每穗粒数和粒重构成。前人的研究表明粒长、粒宽以及粒厚都与粒重呈显著相关,并且可以直接影响小麦产量和品质。因此,在育种计划中增加籽粒长度可能是增加粒重的有效策略。小麦粒长是复杂的受多基因控制的数量性状,且对环境因素也很敏感。小麦基因组庞大而复杂,重复核苷酸序列较多,且缺乏注释基因组序列。分子标记辅助育种,不依赖于表型选择,即不受环境、基因互作、基因与环境互作等因素的影响,而是直接对基因型进行选择,因而能大大提高育种效率。
SNP(Single Nucleotide Polymorphism)标记是指在核苷酸序列中,某一处特定的位置单核苷酸位点A、T、G或C发生变异,使DNA序列改变而出现多态性标记。SNP在植物基因组中分布广泛、数量较多,基因的编码区和非编码区均存在。对于基因组较简单的生物来说,SNP常被用于全基因组扫描,构建高密度遗传图谱,进行重要性状的QTL检测和分析;对于基因组较复杂的小麦来说,SNP常常被用于跟基因芯片结合使用,例如9K、55K和660K SNP芯片,用来检测目标性状相关的基因组区域,促进育种进程。
竞争性等位基因特异性PCR(Kompetitive Allele-Specific PCR,KASP)技术就是现代随着科技发展而出现的一种新型SNP检测技术,它的工作原理是对SNP位点进行特异性引物设计,通过SNP的特异性来进行标记分型和检测,可应用于广泛的基因组DNA,它的Master Mix通常是在普通PCR的基础上,使用由两种特殊荧光基团和猝灭基团做互补探针而构成的。而在之前也有一些分子标记,例如SSR、AFLP等,这些在成本、标记密度、实验流程复杂程度、结果准确性等方面有一些弊端;KASP技术具有通量高、结果准确、成本低、操作简单、无需电泳经检测等特点,很好地解决了其他标记在应用上的缺点。
此前部分学者对小麦粒长进行了QTL定位,在小麦中几乎所有的21条染色体上均有控制粒长的QTL被检测到过。然而目前与小麦粒长性状相关且可用于实际分子育种的紧密连锁的分子标记却并不多。因此研究获得有关粒长的QTL或基因,利用分子生物学技术,选择合适的粒长小麦植株,对于育种工作中产量的提升是非常有必要的。
发明内容
本发明的目的是提供与小麦粒长主效QTL连锁的SNP分子标记KASP-BE-kl-sau2及应用,以解决上述现有技术存在的问题,该分子标记KASP-BE-kl-sau2与粒长QTL Qkl.sau-BE-4A极显著相关,呈现紧密连锁标记特征,用于分子标记辅助选择的准确性高,可显著提高不同环境下粒长较长小麦品种的选择鉴定效率,且成功率高。
基于以上目的,申请人利用小麦品种‘BLS1’为父本,以小麦品系‘99E18’为母本杂交,得到杂种F1,F1代单株自交获得F2,在F2使用单粒传法加代到F3代,获得含有238个单株的群体,构成遗传作图群体。对F3群体粒长进行表型鉴定,将混合群体分离分析法(BSA,Bulk Segregant Analysis)与小麦660K SNP芯片结合,分析2个亲本和2个极端性状混池的差异SNP。通过以下步骤,在两个相对极端混合池中各选取30个极端株系:(1)BLE18的KL表型数据在三种环境中的排列顺序为先降后升。分别取3个环境中最大值和最小值的40个株系,记录其编号。(2)计算并记录三个环境每个株系表型数据的平均值。(3)对(1)和(2)得到的编号进行交集筛选,最终选取最大值和最小值各30个株系。采用CTAB法提取粒长最短的30个株系(每株系10粒)、粒长最长的30个株系(每株系10粒)和2个亲本的等量DNA用于小麦660K SNP芯片分析,并对该群体进行图谱构建,从而定位粒长QTL。小麦660K芯片是由中国农业科学院作物研究所的贾继增课题组开发的一款小麦多倍体二倍体化的高密度SNP芯片,共含有630518个SNP标记。与90K芯片相比,660K芯片中SNP的数量显着增加,是适合于一般的种质资源多样性分析、一般的遗传作图、新基因发现、比较基因组分析与品种注册与鉴别等的SNP芯片,能服务于接下来的标记开发和精细定位工作。
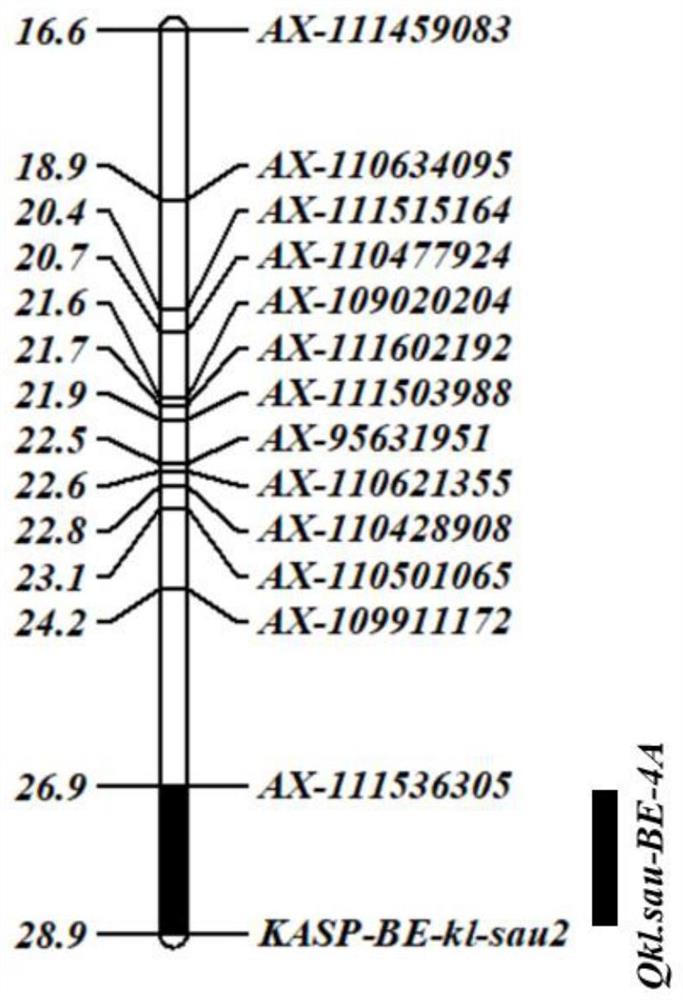
根据660K SNP芯片数据,在目标染色体的候选区段内开发KASP标记对群体进行基因分型,利用JoinMap4.0构建遗传图谱。结合群体的粒长表型数据,用QTL IciMapping 4.0中的完备区间作图法(Inclusive Composite Interval Mapping,ICIM),设置阀值LOD≥2.5的条件下,用2020年3个生态点及3个生态点粒长的BLUP(最佳线性无偏预测,bestlinear unbiased prediction)值来检测QTL,在4A染色体短臂上的2cM区间定位出稳定表达的小麦粒长主效QTL Qkl.sau-BE-4A,开发分子标记,最终得到标记KASP-BE-kl-sau2与粒长QTL Qkl.sau-BE-4A紧密连锁。
本发明所述的小麦粒长QTL Qkl.sau-BE-4A,来自父本‘BLS1’,该QTL位于小麦染色体4A短臂上,在RefSeqv2.0基因组版本的物理位置为101.7-109.2Mbp。本发明提供了上述小麦粒长QTL Qkl.sau-BE-4A在调控小麦籽粒性状中的应用。所述小麦粒长QTLQkl.sau-BE-4A显著增加小麦籽粒长度,平均LOD值为5.06,解释约10.87-19.30%的表型变异。
为实现上述目的,本发明提供了如下方案:
本发明提供一种与小麦粒长QTL Qkl.sau-BE-4A连锁的SNP分子标记KASP-BE-kl-sau2,其多态性为C/T,所述KASP-BE-kl-sau2与小麦粒长QTL Qkl.sau-BE-4A共定位于小麦4A染色体短臂上,且位于QTL Qkl.sau-BE-4A区间内。
本发明提供一种引物组,包括用于扩增所述KASP-BE-kl-sau2的两条特异性引物和一条通用引物,两条所述特异性性引物的核苷酸序列如SEQ ID NO:4-5所示,所述通用引物的核苷酸序列如SEQ ID NO:6所示。
本发明一种检测小麦全基因或其基因片段的芯片,包括所述的KASP-BE-kl-sau2或所述的引物组。
本发明还提供一种检测小麦全基因或其基因片段的试剂盒,包括所述的KASP-BE-kl-sau2或所述的引物组。
本发明化提供一种所述的KASP-BE-kl-sau2或所述的引物组或所述的芯片或所述的试剂盒的应用,用于如下任一项应用中:
(1)筛选具有合适粒长的小麦品种或品系;
(2)调控小麦粒长性状;
(3)提高小麦产量;
(4)小麦粒长基因遗传分析或遗传精细定位。
本发明还提供一种筛选含有粒长QTL Qkl.sau-BE-4A的小麦株系方法,包括以下步骤:
以待测植株样品的基因组DNA作为模板,利用所述的引物组对模板进行荧光定量PCR扩增,利用扩增结果进行基因型分型。
优选的是,荧光定量PCR扩增反应体系为:7.5μL Master Mix、2.1μL混合引物、6ng模板DNA、双蒸水加至总量为15μL;其中,所述混合引物是由如SEQ ID NO:4-SEQ ID NO:6所示引物均按照10ng/μL的浓度,分别加入120μL、120μL和300μL,并添加460μL ddH
优选的是,荧光定量PCR扩增反应程序为:94℃预变性15min;94℃变性20s、60℃复性/延伸50s,共8个循环;94℃变性20s、55℃复性/延伸60s,共28个循环。
本发明还提供所述的方法在小麦分子育种、培育转基因小麦和小麦种质资源改良中应用。
本发明还提供一种小麦KASP-BE-kl-sau2分子标记或粒长基因QTL Qkl.sau-BE-4A在调控小麦粒长性状中的应用。
本发明公开了以下技术效果:
(1)本发明首次公开了来自小麦‘BLS1’的粒长QTL Qkl.sau-BE-4A,位于小麦4A染色体短臂上,显著增加小麦粒长。该QTL在小麦产量(调控粒长)育种中具有较高的利用价值。
(2)本发明公开了基于荧光定量PCR平台精确检测小麦‘BLS1’的粒长QTLQkl.sau-BE-4A的分子标记KASP-BE-kl-sau2,检测准确高效、扩增方便稳定。
(3)本发明公开的分子标记KASP-BE-kl-sau2与粒长QTL Qkl.sau-BE-4A极显著相关,呈现紧密连锁标记特征,用于分子标记辅助选择的准确性高,可显著提高适应不同环境的小麦较长籽粒品种的选择鉴定效率,且成功率高。
(4)本发明公开了位于小麦4A染色体上的与小麦粒长连锁的分子标记KASP-BE-kl-sau2,该分子标记是小麦4A染色体短臂上粒长QTL Qkl.sau-BE-4A的侧翼标记,连锁度高。该标记可用来检测小麦4A染色体上的粒长QTL,快速筛选具有该位点的植株,进而方便进行高产小麦的分子辅助育种。
(5)本发明提供的分子标记KASP-BE-kl-sau2与小麦4A上的粒长QTL Qkl.sau-BE-4A紧密连锁,可用来对小麦粒长这一性状进行定位,从而在育种过程中淘汰较短籽粒的植株,提高育种工作效率,并为小麦粒长基因的研究提供基础。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例1中小麦粒长QTL Qkl.sau-BE-4A在4A染色体上的定位;
图2为本发明实施例1中,小麦‘BLS1’ב99E18’F3验证群体的株系植株分子标记Qkl.sau-BE-4A检测的荧光读值结果;其中,FAM(圆形,‘99E18’)荧光为有较短籽粒的株系,HAX(正方形,‘BLS1’)荧光为较长籽粒株系;黑色菱形荧光为空白对照;
图3为本发明实施例2中,小麦‘BLS1’בSumai3’F3验证群体的株系植株分子标记Qkl.sau-BE-4A检测的荧光读值结果;其中,FAM(圆形,‘Sumai3’)荧光为有较短籽粒的株系,HAX(正方形,‘BLS1’)荧光为较长籽粒株系;黑色菱形荧光为空白对照。
具体实施方式
现详细说明本发明的多种示例性实施方式,该详细说明不应认为是对本发明的限制,而应理解为是对本发明的某些方面、特性和实施方案的更详细的描述。
应理解本发明中所述的术语仅仅是为描述特别的实施方式,并非用于限制本发明。另外,对于本发明中的数值范围,应理解为还具体公开了该范围的上限和下限之间的每个中间值。在任何陈述值或陈述范围内的中间值以及任何其他陈述值或在所述范围内的中间值之间的每个较小的范围也包括在本发明内。这些较小范围的上限和下限可独立地包括或排除在范围内。
除非另有说明,否则本文使用的所有技术和科学术语具有本发明所述领域的常规技术人员通常理解的相同含义。虽然本发明仅描述了优选的方法和材料,但是在本发明的实施或测试中也可以使用与本文所述相似或等同的任何方法和材料。本说明书中提到的所有文献通过引用并入,用以公开和描述与所述文献相关的方法和/或材料。在与任何并入的文献冲突时,以本说明书的内容为准。
在不背离本发明的范围或精神的情况下,可对本发明说明书的具体实施方式做多种改进和变化,这对本领域技术人员而言是显而易见的。由本发明的说明书得到的其他实施方式对技术人员而言是显而易见的。本申请说明书和实施例仅是示例性的。
关于本文中所使用的“包含”、“包括”、“具有”、“含有”等等,均为开放性的用语,即意指包含但不限于。
以下实施例中小麦品系‘99E18’由四川省农科院作物所朱华忠研究员提供,四川农业大学小麦所保存;‘BLS1’由孟加拉国库尔拉大学Ahsan Habib教授提供,四川农业大学小麦所保存;‘Sumai3’由四川农业大学小麦所保存和提供。
实施例1小麦粒长QTL Qkl.sau-BE-4A及其分子标记KASP-BE-kl-sau2的获得
(1)利用小麦品系‘99E18’为母本,以小麦品种‘BLS1’为父本杂交,得到杂种F1,F1代单株自交获得F2,在F2使用单粒传法到F3代,获得含有238个单株的重组自交系,构成遗传作图群体。
(2)F3群体粒长表型鉴定:小麦成熟期对F3群体株系进行收获,脱粒,烘干并进行籽粒性状表型鉴定,每个株系进行30个籽粒长度重复值的测量,并得出平均值,代表该株系的粒长。
(3)运用混合群体分离分析法(BSA),构建两个亲本池,并在F3群体中选取两组分别具有30个极端粒长差异的株系分别构建混池。
(4)660K SNP芯片分析
a)DNA提取:用CTAB法提取亲本‘99E18’、‘BLS1’和F
b)使用超微量分光光度计对提取的DNA进行质量检测,合格后送样至公司进行基因型分析,在本研究中双亲和作图群体的基因型分析由北京博奥晶典生物技术有限公司(http://www.capitalbio tech.com)与贾继增课题组合作开发的660K SNP芯片完成,该芯片市售可得。
c)通过筛选两个极端混池之间有差异的SNP,并将这些差异SNP位点整合到小麦的21条染色体上,结果表明,在4A染色体上含量最多,因此初步确定在4A染色体上可能存在着控制粒长的位点。并且在4A染色体90-160Mbp之间差异SNP的集中度最高,将这一段被选为候选区段。
d)连锁图谱的构建:根据660K SNP芯片数据,在目标染色体的候选区段及其周围,开发可用的KASP标记对BLE18群体进行基因分型,利用JoinMap4.0构建遗传图谱。结合群体的粒长表型数据,用QTL IciMapping 4.0中的完备区间作图法,设置阀值LOD≥2.5的条件下,用2020年共3个生态点及3个生态点粒长的BLUP(最佳线性无偏预测,best linearunbiased prediction)值来检测QTL,定位出小麦粒长QTL Qkl.sau-BE-4A,并计算QTLQkl.sau-BE-4A的位置和分子标记之间的遗传距离。
e)粒长位点的比较以及分子标记的获得:Huang等人利用多对近等基因系对3个与粒重相关的QTL(QGw.nau-2D、QGw.nau-4B和QGw.nau-5A)进行研究,验证了这3个QTL对粒长、粒宽和粒厚均有影响(Huang et al.2015,Theoretical and Applied Genetics,128:2437-2445)。Brinton等人利用Charger×Badger对粒长相关QTL有更深入的研究,在检测到主效QTL的同时对QTL的分子机制进行了一定的研究。其检测到一个位于5A的主效QTL,该QTL通过增加种皮细胞的长度从而增加粒长,达到增加粒重的目的(Brinton et al.2017,New Phytologist,215:1026-1038)。Zhang等人也发现水稻OsGS3的同源基因TaGS-D1与普通小麦的粒重和粒长有关,TaGS-D1位于7DS染色体上,可以增加粒长和粒重(Zhang etal.2014,Molecular Breeding,34:1097-1107)。Su利用重组自交系分析了7AL上一个与粒长相关的QTL,发现一个SNP与其紧密连锁(Su et al.2016,Molecular Breeding 36:15)。位于4A上的QTL很少且都与Qkl.sau-BE-4A的距离很远,这表明Qkl.sau-BE-4A是一个新的稳定的QTL。
为了进一步获得与粒长QTL Qkl.sau-BE-4A紧密连锁的分子标记,利用660K SNP芯片数据定位结果对侧翼标记进行物理定位并筛选位于区间内的基因。开发获得高效的KASP分子标记,需要如下多个步骤:
(I)设计扩增特定小麦基因型目标同源染色体(4A)候选基因序列的引物。虽然目前已有六倍体小麦‘中国春’参考基因组,但是因为小麦进化过程中可能有染色体结构变异(Ma J,Stiller J,Wei Y,Zheng Y-L,Devos KM,
(II)利用特异引物对目标小麦基因型进行扩增。在进行扩增时,需要凭借熟练的分子生物学技术对扩增条件进行优化,进一步克隆测序。以获得目标区域的基因序列。
(III)目标同源染色体候选基因序列多态性位点的获得。在获得两个亲本候选基因序列后,需要进一步对序列进行详细分析,检测是否有多态性位点,如果没有,则需要重新回到第I步,选择其他可能的候选区域进行分离克隆。
(IV)多态性位点上下游KASP引物的设计。在获得多态性位点之后,需要设计KASP特异引物。由如前所述,小麦为异源六倍体植物,则仍然要凭借熟练的生物信息学技术对ABD染色体序列进行分析,从而获得特异于目标染色体的KASP引物。
(V)KASP引物扩增条件的优化。引物合成之后,需要凭借经验进一步对引物扩增条件进行调试优化,以便能达到在亲本之间能够显著区分的效果。
综上所述,虽然KASP标记技术已经广泛应用于二倍体物种,但是要想在六倍体小麦中获得高效的KASP标记时,对本领域技术人员而言绝非易事。
最终经过多次KASP标记开发,引物设计和扩增,共设计KASP引物7对,最终得到标记KASP-BE-kl-sau2(多态性为C/T)与粒长QTL Qkl.sau-BE-4A紧密连锁(表1)。
表1 KASP引物序列
设计的7对KASP引物中最终得到了1个分子标记KASP-BE-kl-sau2,其与粒长QTLQkl.sau-BE-4A紧密连锁,结果见图1-2。
实施例2分子标记KASP-BE-kl-sau2在选择控制粒长QTL Qkl.sau-BE-4A上的应用
(1)利用较长粒长的普通小麦品‘BLS1’为父本,普通小麦品系‘Sumai3’为母本构建F
(2)对所获得的183个株系进行KASP-BE-kl-sau2标记检测,具体方法为:提取183个株系的DNA;将其作为模板,以分子标记KASP-BE-kl-sau2的特异性引物对为引物进行PCR扩增并进行荧光读值,所述引物为:
FAM标签上引物:(下划线部分为FAM标签序列)5’-
HEX标签上引物:(下划线部分为HEX标签序列)5’-
通用下游引物:5’-AAGGGGAAGGTCAGCTGCTG-3’(SEQ ID NO:6)
PCR扩增的扩增体系为:7.5μL Master Mix、混合引物2.1μL、6ng模板DNA、双蒸水加至总量为15μL,其中,混合引物是由SEQ ID NO:4-SEQ ID NO:6所示引物均按照10ng/μL的浓度,分别加入120μL,120μL和300μL并添加ddH
PCR扩增的反应程序为:94℃预变性15min;94℃变性20s、60℃复性/延伸50s,共8个循环;94℃变性20s、55℃复性/延伸60s,共28个循环;完成后进行荧光读值。
荧光读值结果如图3所示,将检测到与‘Suami3’一致的FAM荧光的植株基因型记为B,为粒长较短的株系,同‘BLS1’一样表现为HAX荧光的植株基因型记为A,为粒长较长的株系。各个株系基因型与粒长的表型值如表2所示。
表2‘BLS1’בSumai3’F3群体KASP-BE-kl-sau2基因型与表型对应结果
由表2可见,与含有粒长QTL Qkl.sau-BE-4A的‘BLS1’类型相同的植株平均粒长为8.3mm,极显著高于与‘Sumai3’类型的植株平均粒长(7.9mm)。实际结果与预期结果一致,说明本发明的粒长QTL Qkl.sau-BE-4A确实有显著增加粒长的作用;同时本发明的分子标记KASP-BE-kl-sau2可以用于跟踪鉴定粒长QTL Qkl.sau-BE-4A。
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
序列表
<110> 四川农业大学
<120> 与小麦粒长主效QTL连锁的SNP分子标记KASP-BE-kl-sau2及应用
<160> 21
<170> SIPOSequenceListing 1.0
<210> 1
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
gaaggtgacc aagttcatgc ttagtaaaac agaagaggga 40
<210> 2
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
gaaggtcgga gtcaacggat ttagtaaaac agaagagggg 40
<210> 3
<211> 18
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
ctaatgaacc cctgcaac 18
<210> 4
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gaaggtgacc aagttcatgc tccagccggc aggtggaatg cc 42
<210> 5
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
gaaggtcgga gtcaacggat tccagccggc aggtggaatg ct 42
<210> 6
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 6
aaggggaagg tcagctgctg 20
<210> 7
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
gaaggtgacc aagttcatgc tattcatccc ccatcagcac c 41
<210> 8
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
gaaggtcgga gtcaacggat tattcatccc ccatcagcac t 41
<210> 9
<211> 19
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
agaagctcca tggtcctta 19
<210> 10
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
gaaggtgacc aagttcatgc ttacaatcat ctcacacggc c 41
<210> 11
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
gaaggtcgga gtcaacggat ttacaatcat ctcacacggc t 41
<210> 12
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 12
cagtcaagtc tcatgttcag 20
<210> 13
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 13
gaaggtgacc aagttcatgc tggttccata gacatatctt c 41
<210> 14
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 14
gaaggtcgga gtcaacggat tggttccata gacatatctt g 41
<210> 15
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 15
ttgatgaggg gtttgacaaa 20
<210> 16
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 16
gaaggtgacc aagttcatgc tctataactt tggatcagcc ca 42
<210> 17
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 17
gaaggtcgga gtcaacggat tctataactt tggatcagcc cg 42
<210> 18
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 18
agtcgcgcac ggggcggtcg 20
<210> 19
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 19
gaaggtgacc aagttcatgc ttagggtcac ttcaaagcgc ca 42
<210> 20
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 20
gaaggtcgga gtcaacggat ttagggtcac ttcaaagcgc cg 42
<210> 21
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 21
tctagaggca gtgcacggta 20