一种面向医疗图像处理的医疗机构协作关系识别方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及一种面向医疗图像处理的医疗机构协作关系识别方法,基于分散在各医疗机构的数据,为每个医疗机构检测其协作伙伴,能够自适应的将具有相似协作伙伴的医疗机构进行分组构建优质医疗图像处理模型,使得各个机构都能受益于他方机构不同数据带来的增益,应用于图像处理技术领域。
背景技术
基于机器学习技术的医学图像处理系统可以在短时间内对大量医疗图像与数字病理数据进行汇聚和分析,医疗图像处理系统在辅助医疗图像分类方面有着巨大的应用价值。
然而,医疗图像数据通常分散在不同机构、不同科室的图像储存系统内,形成一个个缺乏有效互通的“数据孤岛”,同时每个医疗机构拥有的数据相对较少。尽管机器学习技术在医学应用中展现出很好的效果,但其高度依赖训练数据的数量和多样性,而由于医疗图像数据数量或病理类型等原因,训练高性能医疗图像分类模型所需的训练数据可能无法在单个医疗机构中获取。作为一种新型的机器学习理念,协作学习可以通过利用分散的数据来构建性能强大的机器学习模型,从而实现多源数据的价值共享。
目前的协作学习范式主要分为个性化协作学习和集中式协作学习两种方式。其中,个性化协作学习允许为不同的机构提供不同的模型,而集中式协作学习要求为所有的机构提供相同的模型。在许多实际应用中,来自不同机构的数据通常是异质的,因此单一的集中式协作学习模型不可避免的在某些机构的数据上性能不佳。在数据异质的协作学习情形下,对每个机构而言,最理想的方式是为每个机构定制个性化的模型,然而当机构数量庞大时,这种做法面临难以承受的计算开销。因此,在数据异质的协作环境下,如何兼顾模型性能和计算开销是非常关键的技术,对于协作学习在包括医疗领域在内的实际应用中的落地有着重要的意义。
发明内容
发明目的:针对现有技术中存在的问题与不足,本发明提供一种面向医疗图像处理的医疗机构协作关系识别方法。
本发明基于分散在各医疗机构的医疗图像数据,通过为每个医疗机构检测其协作伙伴,能够自适应的将具有相似协作伙伴的医疗机构进行分组构建医疗图像处理模型,以充分挖掘多机构数据的潜能和深层价值,使得各个机构都能受益于他方机构不同向医疗图像数据带来的增益,从而学习到泛化能力较强的优质医疗图像处理模型;此外,本发明通过标记不满足预设条件的医疗机构,使得通过分组构建的机器学习模型与具有最优性能的个性化模型性能相当,而本发明的计算开销远小于训练个性化模型需要的计算开销,极大的提高了协作学习在实际应用中的效率。
技术方案:一种面向医疗图像处理的医疗机构协作关系识别方法,包括以下如下内容:
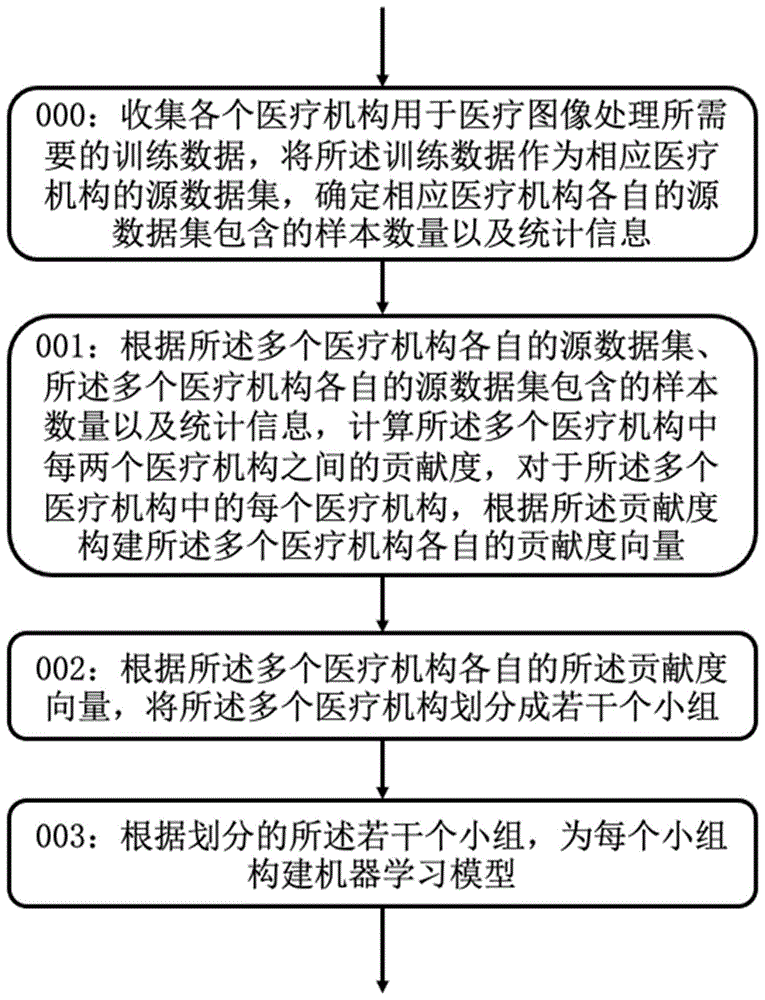
(一)收集各个医疗机构用于医疗图像分类处理所需要的训练数据,将所述训练数据作为相应医疗机构的源数据集,确定相应医疗机构各自的源数据集包含的样本数量以及统计信息;
(二)根据所述多个医疗机构各自的源数据集、所述多个医疗机构各自的源数据集包含的样本数量以及统计信息,计算所述多个医疗机构中每两个医疗机构之间的贡献度,对于所述多个医疗机构中的每个医疗机构,根据所述贡献度构建所述多个医疗机构各自的贡献度向量;所述多个医疗机构各自的所述贡献度向量设置为一个多维向量,用于表征所述多个医疗机构在最优的协作状态中对该医疗机构的贡献程度;
(三)根据所述多个医疗机构各自的所述贡献度向量,将所述多个医疗机构划分成若干个小组。
进一步地,所述(一)中,收集各个医疗机构用于医疗图像处理所需要的训练数据,将所述训练数据作为相应医疗机构的源数据集,确定相应医疗机构各自的源数据集包含的样本数量以及统计信息,包括以下具体步骤:
100、确定所述多个医疗机构在具体协作学习任务中指代的目标群体以及医疗机构的数量;
101、收集所述多个医疗机构用于医疗图像处理所需要的训练数据,将所述训练数据作为相应医疗机构的源数据集,根据所述多个医疗机构各自的所述源数据集,确定所述多个医疗机构各自的源数据集包含的样本数量;
102、根据所述多个医疗机构各自的源数据集以及样本数量,确定所述多个医疗机构的所述统计信息。
进一步地,所述(二)中,根据所述多个医疗机构各自的源数据集、所述多个医疗机构各自的源数据集包含的样本数量以及统计信息,计算所述多个医疗机构中每两个医疗机构之间的贡献度,对于所述多个医疗机构中的每个医疗机构,根据所述贡献度构建所述多个医疗机构各自的贡献度向量,包括以下具体步骤:
200、根据所述多个医疗机构各自的源数据集对应的统计信息,计算所述多个医疗机构中每两个医疗机构之间的源数据集差异值;
201、对于所述多个医疗机构中的每个医疗机构,将所述多个医疗机构按照与该医疗机构之间的所述源数据集差异值进行升序排列;
202、根据预设权重、所述多个医疗机构各自的源数据集包含的样本数量以及统计信息、每两个医疗机构之间的所述源数据集差异值,确定所述多个医疗机构各自的差异阈值,以及确定所述多个医疗机构各自的协作伙伴;所述多个医疗机构各自的所述协作伙伴用于表征所述多个医疗机构中对该医疗机构有增益的医疗机构群体;
203、根据所述多个医疗机构各自的源数据集包含的样本数量以及统计信息、每两个医疗机构之间的所述源数据集差异值、所述多个医疗机构各自的差异阈值、所述多个医疗机构各自的所述协作伙伴,计算所述多个医疗机构中每两个医疗机构之间的贡献度;
204、对于所述多个医疗机构中的每个医疗机构,根据所述贡献度构建所述多个医疗机构各自的贡献度向量。
进一步地,所述(三)中,根据所述多个医疗机构各自的所述贡献度向量,将所述多个医疗机构划分成若干个小组,包括以下具体步骤:
300、确定具体协作学习任务中需要划分的小组数量;
301、根据所述小组数量,在所述多个医疗机构的所述贡献度向量集合上运行K-Means算法,并确定所述贡献度向量集合的误差平方和值;
302、根据所述误差平方和值,将所述多个医疗机构划分成所述小组数量个小组。
进一步地,根据所述误差平方和值,将所述多个医疗机构划分成所述小组数量个小组,包括:
302-11、在所述误差平方和值小于预设阈值时,根据K-Means算法对于所述贡献度向量集合的划分结果,将所述多个医疗机构划分进入对应的小组;
302-12、根据所述误差平方和值以及预设参数,确定关键距离值;
302-13、根据所述关键距离值,若所述多个医疗机构中的某医疗机构对应的所述贡献度向量与K-Means算法得到的簇中心向量距离大于所述关键距离值,则将该医疗机构进行标记。
进一步地,根据所述误差平方和值,将所述多个医疗机构划分成所述小组数量个小组,包括:
302-21、在所述误差平方和值大于预设阈值时,根据所述多个医疗机构的所述贡献度向量集合构建协作相似度矩阵;所述协作相似度矩阵用于表征所述多个医疗机构中每两个医疗机构之间的协作伙伴相似程度;
302-22、根据所述协作相似度矩阵以及所述小组个数,构建半正定规划问题;
302-23、采用取整算法求解所述半正定规划问题,根据求解结果,将所述多个医疗机构划分进入对应的小组;
302-24、根据所述协作相似度矩阵、所述半正定规划问题求解得到的所述划分结果以及预设参数,确定所述小组内部的弱边;所述弱边用于表征医疗机构之间的弱协作相似度;
302-25、根据所述弱边,标记所述多个医疗机构中满足预设条件的特定医疗机构。
一种基于医疗机构协作关系的医疗图像处理模型的构建方法,根据所述若干个小组,为每个小组构建机器学习模型,用于医疗图像的识别分类。
进一步地,根据划分的所述若干个小组,为每个小组构建机器学习模型,包括以下具体步骤:
600、根据所述多个医疗机构的分组情况以及所述被标记医疗机构,挑选出所述多个医疗机构中未被标记的医疗机构;
601、根据所述多个医疗机构的分组情况以及所述未标记的医疗机构,计算每个小组中未标记医疗机构对应的所述贡献度向量的平均贡献度向量;
602、根据每个小组的所述平均贡献度向量,构建加权损失函数;
603、根据所述加权损失函数,为每个小组构建用于医疗图像识别分类的机器学习模型。
一种计算机设备,该计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行上述计算机程序时实现如上所述的面向医疗图像处理的医疗机构协作关系识别方法。
一种计算机可读存储介质,该计算机可读存储介质存储有执行如上所述的面向医疗图像处理的医疗机构协作关系识别方法的计算机程序。
本发明的有益之处在于:
本发明基于分散在各医疗机构的数据,通过为每个医疗机构检测其协作伙伴,能够自适应的将具有相似协作伙伴的医疗机构进行分组构建模型,以充分挖掘多机构数据的潜能和深层价值,使得各个机构都能受益于他方机构不同数据带来的增益,从而学习到泛化能力较强的优质医疗图像处理模型;此外,本发明通过标记不满足预设条件的医疗机构,使得通过分组构建的机器学习模型与具有最优性能的个性化模型性能相当,而本发明的计算开销远小于训练个性化模型需要的计算开销,极大的提高了协作学习在实际应用中的效率,从而能在医生的诊断过程中发挥及时而积极的辅助作用。本发明基于分散在各医疗机构的数据协同建模,兼顾协作学习在医疗图像处理中的模型性能和计算开销,具有重要的临床意义,对于协作学习在包括医疗领域在内的实际应用中的落地有着十分重要的意义。
附图说明
图1是本发明实施例的方法流程图;
图2是本发明实施例中根据多个医疗机构各自的源数据集确定样本数量以及统计信息的流程图;
图3是本发明实施例中计算多个医疗机构中每两个医疗机构之间的贡献度以及构建多个医疗机构各自的贡献度向量的流程图;
图4是本发明实施例中根据多个医疗机构各自的贡献度向量将多个医疗机构划分成若干个小组的流程图;
图5是本发明实施例中当误差平方和值小于预设阈值时将多个医疗机构划分进入若干个小组并且标记特定医疗机构的流程图;
图6是本发明实施例中当误差平方和值大于预设阈值时将多个医疗机构划分进入若干个小组并且标记特定医疗机构的流程图;
图7是本发明实施例中根据多个医疗机构的小组划分情况为每个小组构建机器学习模型的流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种面向医疗图像处理的医疗机构协作关系识别及医疗图像处理模型的构建方法,包括以下步骤:
(一)收集各个医疗机构用于医疗图像处理所需要的医疗图像数据,并医疗图像数据作为训练数据,将训练数据作为相应医疗机构的源数据集,确定相应医疗机构各自的源数据集包含的样本数量以及统计信息;
(二)根据多个医疗机构各自的源数据集、源数据集包含的样本数量以及统计信息,计算多个医疗机构中每两个医疗机构之间的贡献度,对于多个医疗机构中的每个医疗机构,根据贡献度构建多个医疗机构各自的贡献度向量;多个医疗机构各自的贡献度向量设置为一个多维向量,用于表征多个医疗机构在最优的协作状态中对该医疗机构的贡献程度;
(三)根据多个医疗机构各自的贡献度向量,将多个医疗机构划分成若干个小组;
(四)根据若干个小组,为每个小组构建机器学习模型,用于医疗图像的识别分类。
结合图1,收集各个医疗机构用于医疗图像处理所需要的训练数据,将训练数据作为相应医疗机构的源数据集,确定相应医疗机构各自的源数据集包含的样本数量以及统计信息,包括以下具体步骤:
100、确定多个医疗机构在具体协作学习任务中指代的目标群体{C
101、收集多个医疗机构用于医疗图像处理所需要的训练数据,具体而言,医疗机构C
102、根据多个医疗机构各自的源数据集以及样本数量,确定多个医疗机构的所述统计信息,对于医疗机构C
结合图2,根据多个医疗机构各自的源数据集、多个医疗机构各自的源数据集包含的样本数量以及统计信息,计算多个医疗机构中每两个医疗机构之间的贡献度,对于多个医疗机构中的每个医疗机构,根据贡献度构建多个医疗机构各自的贡献度向量,包括以下具体步骤:
200、根据多个医疗机构各自的源数据集对应的统计信息,计算多个医疗机构中每两个医疗机构之间的源数据集差异值,对于任意两个医疗机构C
201、对于多个医疗机构中的每个医疗机构,将多个医疗机构按照与该医疗机构之间的源数据集差异值进行升序排列,对于医疗机构C
202、根据预设权重λ、多个医疗机构各自的源数据集包含的样本数量{m
以及确定所述多个医疗机构各自的协作伙伴,对于医疗机构C
203、根据多个医疗机构各自的源数据集包含的样本数量{m
204、对于多个医疗机构中的每个医疗机构,根据贡献度构建多个医疗机构各自的贡献度向量,具体而言,对于任意医疗机构C
结合图3,根据多个医疗机构各自的所述贡献度向量,将多个医疗机构划分成若干个小组,包括以下具体步骤:
300、确定具体协作学习任务中需要划分的小组数量K,通常1≤K<<N。
301、根据小组数量K,在多个医疗机构的所述贡献度向量集合
302、根据误差平方和值
结合图4,根据误差平方和值,将多个医疗机构划分成小组数量个小组,包括:
400、在误差平方和值小于预设阈值τ时,根据利用K-Means算法对于贡献度向量集合
401、根据误差平方和
402、根据关键距离值d
结合图5,根据误差平方和值,将多个医疗机构划分成所述小组数量个小组,包括:
500、在误差平方和值大于预设阈值τ时,根据多个医疗机构的所述贡献度向量集合
501、根据协作相似度矩阵U以及小组个数K,构建半正定规划问题,具体而言,记w
502、采用取整算法求解半正定规划问题,根据求解结果,将多个医疗机构划分进入对应的小组,具体而言,在K维空间内随机挑选t个平面,利用投影将所述半正定规划问题中的向量集合
503、根据协作相似度矩阵U、半正定规划问题求解得到的所述划分结果以及预设参数η,确定所述小组{G
504、根据弱边,标记多个医疗机构中满足预设条件的特定医疗机构,具体而言,对于任意小组G
结合图6,根据划分的所述若干个小组,为每个小组构建机器学习模型,包括以下具体步骤:
600、根据多个医疗机构的分组情况{P
601、根据多个医疗机构的分组情况以及未标记医疗机构
602、根据每个小组的平均贡献度向量,构建加权损失函数,对于任意小组G
603、根据加权损失函数,为每个小组构建用于医疗图像识别分类的机器学习模型,以训练神经网络为例,对于任意小组G
综上所述,本发明基于分散在各医疗机构的数据,通过为每个医疗机构检测其协作伙伴,能够自适应的将具有相似协作伙伴的医疗机构进行分组构建模型,以充分挖掘多机构数据的潜能和深层价值,使得各个机构都能受益于他方机构不同数据带来的增益,从而学习到泛化能力较强的优质医疗图像处理模型;此外,本发明通过标记不满足预设条件的医疗机构,使得通过分组构建的机器学习模型与具有最优性能的个性化模型性能相当,而本发明的计算开销远小于训练个性化模型需要的计算开销,极大的提高了协作学习在实际应用中的效率,从而能在医生的诊断过程中发挥及时而积极的辅助作用。本发明基于分散在各医疗机构的数据协同建模,兼顾协作学习在医疗图像处理中的模型性能和计算开销,对于协作学习在包括医疗领域在内的实际应用中的落地有着十分重要的意义。
显然,本领域的技术人员应该明白,上述的本发明实施例的基于医疗机构协作关系的医疗图像处理模型的构建方法各步骤或基于医疗机构协作关系的医疗图像处理模型的构建方法各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明实施例不限制于任何特定的硬件和软件结合。
尽管已经出示和描述了本发明的实施例,对于本领域的普通技术人员而言,可以在不脱离本发明的原理和精神的情况下对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。