一种快速定量检测抹茶掺假物的方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于激光光谱技术领域,尤其涉及一种快速定量检测抹茶掺假物的方法。
背景技术
抹茶是指采用覆盖栽培的茶树鲜叶经蒸汽(或热风)后、干燥制成的叶片为原料,经研磨加工而成的微粉状茶产品。抹茶具有较高的营养价值,是一种能增强情绪认知和减压抗焦虑、提高机体的抵抗力减缓衰老的绿色健康食品。抹茶需求量在逐年增加,市场需求大,具有较大的发展空间。如何检测抹茶的品质成为需求。
激光诱导击穿光谱技术(laser-induced breakdown spectroscopy,称LIBS)是一种原子发射光谱技术,可以对固体、液体、气体样品中的元素组成进行定性和定量分析。它具体是利用脉冲激光产生的等离子体烧蚀并激发样品中的物质,并通过光谱仪获取光谱,以此识别样品中的元素组成部分。目前,由于LIBS具有简单的样品预处理、快速检测和实时分析等优点,激光诱导击穿技术已经广泛运用于地质勘探、制药、环境检测、食品质量检测等不同领域。
由于抹茶样品的形态,粉末容易飞溅,会影响光谱信息的采集,而大多数粉末掺假检测研究都是将样品直接压片法压制成片状颗粒来减少粉末飞溅的影响但样品的制备过程繁琐,效率低。此外,由于激光能量与试验环境等因素的影响,LIBS光谱是不稳定的,这些波动会影响定量分析的性能,这可能会限制LIBS在食品掺假中的进一步推广。
发明内容
本发明目的在于提供一种快速定量检测抹茶掺假物的方法,以解决上述的技术问题。
为解决上述技术问题,本发明的一种快速定量检测抹茶掺假物的方法的具体技术方案如下:
一种快速定量分析抹茶掺假的方法,包括如下步骤:
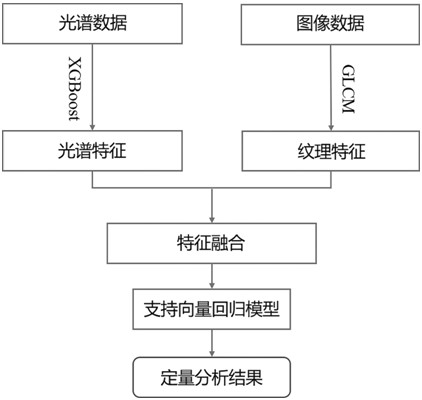
步骤1:制备不同掺假浓度的抹茶样本,采集样品的光谱图像和烧蚀图像信息,并将样本划分训练集和预测集;
步骤2:将收集到的LIBS光谱和烧蚀图像数据进行预处理,降低噪声及无关因素造成的干扰;
步骤3:利用XGBoost提取LIBS光谱图像特征,利用灰度共生矩阵GLCM提取图像纹理特征,光谱特征记为W
步骤4:将提取出的光谱特征和图像特征进行特征融合,融合后的信息作为样品的新特征,记为W;
步骤5:将融合后的特征信息作为输入,并给不同掺假浓度的抹茶贴上数据标签,建立基于LIBS光谱和烧蚀图像的抹茶掺假程度定量分析模型,实现抹茶掺假浓度的预测。
进一步地,所述步骤1中的样品具体是将抹茶和掺假物按比例混合,并使用混匀仪进行均质处理,每个样品总质量为X g;样本总数为M+N,训练组数为M,预测集组数为N。
进一步地,所述步骤1中,从每个样品中称取适量抹茶混合物,并在室温下溶解于蒸馏水中,两者比例为0.005-0.01;使用磁力搅拌器将溶液充分搅拌,抹茶颗粒在溶液中悬浮均匀;使用移液器量取Yμl溶液转移至抽滤装置中;抽滤装置包括真空泵、滤杯和滤瓶;经过抽滤得到最后用来检测的样品。
进一步地,所述步骤1中,采集光谱信号的仪器参数为:激光脉冲能量为80mJ;脉冲频率为1Hz;延迟时间为2μs;积分时间为10μs;并在320-428nm范围内获取样品的光谱信息。
进一步地,所述步骤1中,先将从抽滤装置获得到的样品静置3-5min,然后对每个样品在方形区域采集n×n个点,每个点间隔1mm,每个点由激光击打1次并收集光谱;使用自行设计的LIBS快速检测系统的相机采集样品的图像。
进一步地,所述步骤2包括如下具体步骤:
步骤2.1:先对每个样品所采集的n×n个点的光谱进行平均处理后来代表该样品的光谱信息;
步骤2.2:对M+N组样品的光谱信息进行标准归一化处理,得到光谱矩阵信息,记为α(α
步骤2.3:对图像进行感兴趣区域提取,即选择包含样品及所有烧蚀坑区域的范围,感兴趣区域大小为m×m像素。
进一步地,所述步骤3包括如下具体步骤:
步骤3.1:使用XGBoost根据重要性值的大小在全谱范围内选择特征变量,通过十则交互验证来调整参数确定可以使模型性能达到最优的特征变量数量并得到光谱特征W
步骤3.2:通过GLCM分析提取对比度、均匀性、能量、相关性、角二阶矩六个纹理特征,并将这些纹理特征的值整合成一个代表样本纹理特征的矩阵信息,然后得到所有样本的图像特征W
进一步地,所述步骤4中,将光谱特征W
进一步地,所述步骤5中,获得基于融合信息为输入的模型结果,并且比较基于不同输入的回归模型的性能,获得相应掺假浓度指标的最佳定量分析模型。
进一步地,所述步骤5中,以相关系数和均方根误差作为评价模型性能的指标,R值度量预测的掺假含量与实际值之间的关系,RMSE值度量预测误差。
本发明的一种快速定量检测抹茶掺假物的方法具有以下优点:
(1)实现了抹茶掺假的快速定量检测。
(2)提出了一个粉末样品制备方法,该方法具有成本低,操作简单、效率高等特点;避免了压片制样方法操作繁琐的特点。特别地,本发明提出的样品制备可以仅使用0.1g的抹茶原料制成,而压片制样大概需要0.5g抹茶原料。
(3)同时采集被测样品的光谱信息和图像信息,多层次地获取样品的特征信息,以此更好的保证模型的准确性与可靠性。
(4)基于LIBS的谱图融合建模方法可以对食品质量检测领域提供帮助,并且在其他领域也具有潜在的实际应用价值。
附图说明
图1为本发明基于LIBS谱图融合的抹茶掺假快速定量分析的流程图;
图2为抹茶和掺假物的平均光谱图;
图3(a)为基于全光谱的福鼎抹茶掺杂物含量定量分析结果图;
图3(b)为基于全光谱的鸠坑抹茶掺杂物含量定量分析结果图;
图3(c)为基于光谱特征的福鼎抹茶掺杂物含量定量分析结果图;
图3(d)为基于光谱特征的鸠坑抹茶掺杂物含量定量分析结果图;
图3(e)为基于光谱特征和图像纹理特征融合的福鼎抹茶掺杂物含量定量分析结果图;
图3(f)为基于光谱特征和图像纹理特征融合的鸠坑抹茶掺杂物含量定量分析结果图。
具体实施方式
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种快速定量检测抹茶掺假物的方法做进一步详细的描述。
如图1所示,一种基于LIBS光谱和图像融合的快速定量分析抹茶掺假的方法,包括步骤:
步骤1:制备不同掺假浓度的抹茶样本,采集样品的光谱图像和烧蚀图像信息,并将样本划分训练集和预测集;
采集光谱信号的仪器参数为:激光脉冲能量为80mJ;脉冲频率为1Hz;延迟时间为2μs;积分时间为10μs;并在320-428nm范围内获取样品的光谱信息。
样品具体是通过将抹茶和掺假物混合样品进行溶解、离心搅拌、抽滤等过程制备而成:首先,用电子天平称量每个混合样品的0.1g,并将其溶解在20g蒸馏水中;然后用磁力搅拌器充分搅拌;用移液器吸取400μl的溶液转移到抽滤装置中;抽滤后在直径25mm的滤膜上获得抹茶沉淀;将得到的沉淀物放置在一个25mm×25mm的平板上静置3-5min,然后放置在X-Y-Z移动平台上。特别地,本发明提出的样品制备方法平均2分钟可制备一组样品。样本总数为M+N,训练集组数为M,预测集组数为N。对每个样品在方形区域采集n×n个点,每个点间隔1mm,每个点由激光击打1次并收集光谱;使用自行设计的LIBS快速检测系统的相机采集样品的图像。
步骤2:将收集到的LIBS光谱和烧蚀图像数据进行预处理,以降低噪声及无关因素造成的干扰;预处理方法包括:
步骤2.1:对每个样品采集的所有点的光谱进行平均处理来代表该样品的光谱信息;
步骤2.2:对所有样品的光谱信息进行标准归一化处理,得到全谱信息;
步骤2.3:对烧蚀图像进行感兴趣区域提取(ROI),即选择包含样品及所有烧蚀坑区域的范围。
步骤3:利用XGBoost提取LIBS光谱图像特征,利用灰度共生矩阵(GLCM)提取图像纹理特征,光谱特征记为W
利用XGBoost和GLCM分别对LIBS光谱和烧蚀图像进行特征提取。
步骤3.1:使用XGBoost根据重要性值的大小在全谱范围内选择特征变量,通过十则交互验证来调整参数确定可以使模型性能达到最优的特征变量数量并得到光谱特征W
步骤3.2:通过GLCM分析提取对比度、均匀性、能量、相关性、角二阶矩六个纹理特征,并将这些纹理特征的值整合成一个代表样本纹理特征的矩阵信息,然后得到所有样本的图像特征W
步骤4:将提取出的光谱特征和图像特征进行特征融合,融合后的信息作为样品的新特征,记为W;
将光谱特征W
步骤5:将融合后的特征信息作为输入,并给不同掺假浓度的抹茶贴上数据标签,建立基于LIBS光谱和烧蚀图像的抹茶掺假程度定量分析模型,实现抹茶掺假浓度的预测。
获得基于融合信息为输入的模型结果,并且比较基于不同输入的回归模型的性能,获得相应掺假浓度指标的最佳定量分析模型。本发明以相关系数(R)和均方根误差(RMSE)作为评价模型性能的指标,R值度量预测的掺假含量与实际值之间的关系,RMSE值度量预测误差。
实施例:
1.准备了一级抹茶(福鼎)、二级抹茶(鸠坑)和大麦苗粉,并对两种抹茶进行了感官评价。因此,我们将一级抹茶和二级抹茶当作纯抹茶,而大麦苗粉作为掺假物。抹茶掺杂物的制备方法是将大麦苗粉与一级抹茶和二级抹茶混合。为了建立量化掺杂物含量的模型,一级抹茶和二级抹茶分别以21个不同的百分比(0%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、80%、85%、90%、95%和100%)掺入大麦苗粉。此外,用于外部预测的掺假样品按13种不同的掺假率制备,即0%、8%、16%、24%、32%、40%、48%、56%、64%、72%、80%、88%和96%。每个掺假浓度都进行三次重复实验,因此有63个混合样品用于训练校准,39个混合样品用于预测。混合后,所有的样品被放置在离心管中,用可调式混匀仪进行均质处理。由于粉末的物理特性,在激光烧蚀时粉末会飞溅,这可能影响LIBS信号的稳定性。因此,我们提出了一种新颖的LIBS分析的样品制备方法。首先,用电子天平称量每个混合样品的0.1g,并将其溶解在20g蒸馏水中;然后用磁力搅拌器充分搅拌;用移液器吸取400μl的溶液转移到抽滤装置中;抽滤后在直径25mm的滤膜上获得抹茶沉淀;将得到的沉淀物放置在一个25mm×25mm的平板上,该平板被放在一个X-Y-Z移动平台上。
2.每个样品采集8×8规模,共64个点的光谱,并收集样品烧蚀后的图像。
3.对采集到的光谱信息和图像信息进行预处理:将每个样品的64个点的光谱做平均处理得到代表该样品的一条光谱信息,如图2所示,为一级抹茶、二级抹茶和大麦苗粉的平均光谱;将经平均处理后所有样品的光谱进行标准归一化处理,得到所有样品的光谱矩阵信息α(α
4.利用XGBoost和GLCM分别对LIBS光谱和烧蚀图像进行特征提取。1.使用XGBoost根据重要性值的大小在全谱范围内选择特征变量,并通过十则交互验证来调整参数确定可以使模型性能达到最优的特征变量数量为20,两个关键的超参数分别是n_estimators(nt)和learning rate(lr),它们的值分别为100和0.1,经XGBoost提取后的光谱特征为W
表1:利用XGBoost为抹茶掺假分析选择的特征变量。
注:
5.将样品的光谱特征和图像特征进行特征融合,特别地,光谱特征在前,图像特征在后,融合后得到的矩阵W,尺寸规模为102×44。
6.将融合数据W输入到支持向量回归(SVR)模型中,具体为:将训练集数据用于训练建立模型,调整参数,得到一个性能最好的模型,然后用预测集的数据作为评定标准,相关系数(R)和均方根误差(RMSE)作为评价模型性能的指标,R值度量预测的掺假含量与实际值之间的关系,RMSE值度量预测误差。并将以融合数据作为输入的模型性能与仅以光谱数据作为输入的模型进行对比,发现经过特征融合后,SVR模型的性能得到显著提升。图3(a)-3(f)展现了两类抹茶掺假基于不同输入后的模型性能对比。
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本申请的权利要求范围内的实施例都属于本发明所保护的范围内。