一种光谱技术和深度学习技术结合的TOC快速检测算法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及水质检测技术领域,特别是一种光谱技术和深度学习技术结合的TOC快速检测算法。
背景技术
总有机碳(Total Organic Carbon,TOC)是一个常用的环境监测指标,用于测量和评估水体、土壤和其他环境样品中的有机碳含量。有机碳是指化学上含有碳元素的有机化合物,它们可以来自生物体的遗骸、废弃物、植物和动物的分解产物等。总有机碳则是指样品中所有有机碳的总含量,TOC的测量结果可以提供有关环境样品中有机物含量和有机碳污染程度的信息。它在环境监测、水质评估、土壤质量评估、污染控制和处理过程监测等领域具有广泛的应用。
近红外光谱(near infrared spectroscopy,NIR)作为一种无损分析方法,具有快速、非破坏性、无污染等特点。在近红外光谱的基础上,建立了传统的化学计量学方法对水质中的污染物进行定量分析。然而,传统的化学计量法测定获得的光谱具有数千个特征波长,这给化学计量学方法带来了挑战,出现了如“维度爆炸”等问题。
发明内容
有鉴于此,本发明的目的在于提供一种光谱技术和深度学习技术结合的TOC快速检测算法,有利于提高实际水体水质检测的速度和准确性。
为实现上述目的,本发明采用如下技术方案:一种光谱技术和深度学习技术结合的TOC快速检测算法,包括以下步骤:
步骤1)配制标准水质样品,获得具有不同TOC浓度的多个水质样品;
步骤2)利用近红外光谱仪采集所有水质样品的近红外光谱数据并进行预处理,而后形成近红外光谱数据集,并分为训练集和测试集;
步骤3)构建基于卷积神经网络的水质指标定量检测模型,通过训练集和测试集对水质指标定量检测模型进行训练和测试,得到训练好的水质指标定量检测模型;
步骤4)采集实际水体样本并分为两部分,一部分通过化学计量法来获取其关键指标数据,另一部分通过所建立的水质指标定量检测模型来预测其关键指标数据,通过比较验证所建立模型的精确性和可靠性;若模型的精确性和可靠性不满足要求,则返回步骤3)重新进行模型的训练;
步骤5)利用得到的水质指标定量检测模型对待检测的水质TOC指标进行检测。
在一较佳的实施例中,步骤1)中,配制的水质样品为不同浓度梯度的TOC样品,浓度范围为1-60mg/L;浓度间隔取1mg/L。
在一较佳的实施例中,所述TOC样品的制备方法为:将已知纯度的邻苯二甲酸氢钾溶解在去离子水中,得到储备溶液;然后将配置好的储备溶液用去离子水稀释,制备得到60个不同浓度的TOC溶液样品;制备完成后,将各TOC溶液样品保存在试管中保存并标记浓度。
在一较佳的实施例中,步骤2)中,对每个浓度的TOC样品各采集10次光谱,得到600个光谱数据。
在一较佳的实施例中,步骤2)中,对采集的近红外光谱数据进行归一化和主成分分析法,进而对原始的近红外光谱数据进行特征筛选,构建近红外光谱数据集;主成分分析法的计算公式如下:
A=φDφ
其中A为一个对称的半正定矩阵,φ是A的特征向量组成的矩阵,φ
D是由特征值λ
在一较佳的实施例中,步骤3)中,采用Inception结构的一维卷积神经网络模型来构建水质指标定量检测模型,以进行光谱特征的提取以及回归预测;模型通过Inception模块增强神经网络的特征感受野,并降低模型复杂性;所述神经网络模型由三个卷积层、Inception模块、BN正则化机制、Relu激活函数、连接层、maxpooling层、flatten层、全连接层和输出层组成,通过1*1、3*3、5*5不同大小的的卷积核并行来提高提取特征的能力,并简化模型结构,减少计算量。
在一较佳的实施例中,步骤3)中,在模型的训练和测试过程中,通过R2、MAE、RMSE指标来评估水质指标定量检测模型的预测结果;
MAE的计算公式为:
其中,y表示真实值,
RMSE的计算公式为:
其中,N表示值的个数,y
R
其中,SS
与现有技术相比,本发明具有以下有益效果:提供了一种TOC快速检测算法,该方法解决了化学计量方法对水质TOC指标检测耗时长、精度不足的问题,在保证检测准确性和可靠性的前提下,实现了TOC指标的快速测定,大大节约了时间成本和人力成本。
附图说明
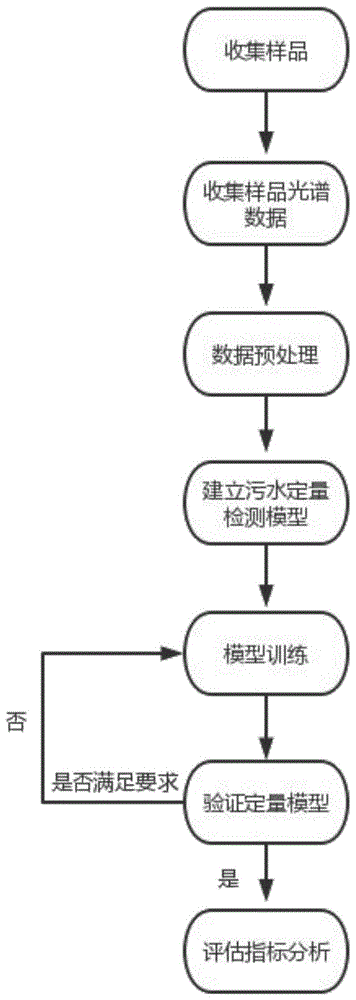
图1是本发明优选实施例的方法实现流程图;
图2是本发明优选实施例中采集的TOC原始光谱数据集;
图3是本发明优选实施例中经过预处理后的TOC光谱数据集;
图4是本发明优选实施例中模型训练后预测值和真实值的拟合曲线图;
图5是本发明优选实施例中MAE的变化曲线;
图6是本发明优选实施例中R2的变化曲线;
图7是本发明优选实施例中RMSE的变化曲线。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式;如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1-7所示,本实施例提供了一种TOC快速检测算法,包括以下步骤:
1)配制标准水质样品,获得具有不同TOC浓度的多个水质样品。
2)利用近红外光谱仪采集所有水质样品的近红外光谱数据并进行预处理,而后形成近红外光谱数据集,并分为训练集和测试集。
3)构建基于卷积神经网络的指标定量检测模型,通过训练集和测试集对水质指标定量检测模型进行训练和测试,得到训练好的水质指标定量检测模型。
4)采集实际水体样本并分为两部分,一部分通过化学计量法来获取其关键指标数据,另一部分通过所建立的TOC指标定量检测模型来预测其关键指标数据,通过比较验证所建立模型的精确性和可靠性;若模型的精确性和可靠性不满足要求,则返回步骤3)重新进行模型的训练。
5)利用得到的TOC指标定量检测模型对待检测的水质样品进行检测。
步骤1)中,配制的水质样品为不同浓度梯度的TOC样品,浓度范围为1-60mg/L;浓度间隔取1mg/L;
其中,TOC样品的制备方法为:将已知纯度的邻苯二甲酸氢钾(KHC8O4H4)溶解在去离子水中,得到储备溶液;然后将配置好的储备溶液用去离子水稀释,制备得到60个不同浓度的TOC溶液样品;制备完成后,将各TOC溶液样品保存在试管中保存并标记浓度。
在本实施例中,对每个浓度的TOC样品各采集10次光谱,得到600个光谱数据。其中120个光谱数据作为训练集样本,浓度范围为1-60mg/L,均值为29.41mg/L,标准差为17.22mg/L;480个光谱数据作为预测集样本,浓度范围为1-60mg/L,均值为29.85mg/L,标准差为17.70mg/L。
本实施例中采用奥谱天成ATP8000微型近红外光谱仪采集近红外光谱信息波段:900-1700nm,积分时间为5ms,采样间隔为500ms,平均扫描次数为10次,背景选择为空气,有效像素为512,在室温25摄氏度的干燥环境下进行。
光谱仪在使用前必须进行校准,该校准是通过获取背景光谱进行的。背景光谱是在没有光源的情况下在光谱仪的阵列上记录的光谱,扣除背景光谱对于减少由背景环境光产生的影响至关重要。
设置透射模式采集光谱,空气作参比,每个样品光谱在900-1700nm的范围内扫描,平均扫描次数为10次,积分时间为5ms,采样间隔为500ms。
本实施例中采集的TOC原始光谱如图2所示。
步骤2)中,对近红外光谱数据进行预处理的具体方法为:
对采集的近红外光谱数据进行归一化和主成分分析法,进而提取水质样品的特征谱峰信息,构建近红外光谱数据集。
归一化的主要目的在于:一是把数据变成(0,1)或者(-1,1)之间的小数。把数据映射到0~1范围之内处理,更加便捷快速。二是把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。本实施例采用极大值极小值归一化方法(Min-MaxNormalization),其计算公式如下:
主成分分析是一种常用的数据降维和特征提取技术。它通过线性变换将原始数据转换为新的一组变量,称为主成分,其中每个主成分都是原始特征的线性组合。主成分按照方差的大小排序,因此,前几个主成分能够捕捉到原始数据中最重要的信息。主成分分析法的计算过程如下:
A=φDφ
其中A为一个对称的半正定矩阵,φ是A的特征向量组成的矩阵,φ
D是由特征值λ
本实施例中经过预处理后的TOC光谱如图所示。
步骤3)中,采用Inception结构的一维卷积神经网络模型来构建水质指标定量检测模型,以进行光谱特征的提取以及回归预测;模型通过Inception模块增强神经网络的特征感受野,并降低模型复杂性;所述神经网络模型由三个卷积层、Inception模块、BN正则化机制、Relu激活函数、连接层、maxpooling层、flatten层、全连接层和输出层组成,通过1*1、3*3、5*5等不同大小的卷积核并行来提高提取特征的能力,并简化模型结构,减少计算量。
在模型的训练和测试过程中,通过R2、MAE、RMSE指标来评估水质指标定量检测模型的预测结果。MAE的计算公式为:
其中,y表示真实值,
RMSE的计算公式为:
其中,N表示值的个数,y
R
其中,SS
本实施例中,基于卷积神经网络结合Inception模块改进进行回归分析,建立水质指标定量检测模型,其主要步骤如下:
步骤一、将获得的光谱数据集先进行多元散射校正,校正后的光谱数据集如图3所示,然后通过SPXY算法划分为测试集和训练集,SPXY算法是在KS算法上改进而来的,SPXY算法同时考虑了x变量和y变量,其公式如下:
其中N为样品总数,d
步骤二、通过归一化和主成分分析法来进行光谱预处理,该算法简要步骤如下数据标准化:
1.对原始数据进行归一化处理,确保每个特征在PCA中具有相同的重要性。
2.计算协方差矩阵:对标准化后的数据计算协方差矩阵,用于衡量不同特征之间的相关性。协方差矩阵的元素Cov(X
3.计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示每个主成分(特征向量)的方差,特征向量表示每个主成分的方向。
4.选择主成分:根据特征值的大小,选择保留的主成分数量。通常选择特征值较大的前k个主成分,这些主成分对应的特征向量称为主成分系数。
5.数据投影:将原始数据投影到选定的主成分上,得到降维后的数据。新的特征向量表示原始数据在新的特征空间中的表示。
步骤三、将处理后的训练集输入改进的卷积神经网络中进行训练。
步骤四、向前传播计算损失值。
步骤五、通过损失值来调整卷积的超参数,通过使用Pytorch中的optimizer.step()、scheduler.step()函数来进行滚动优化和权重迭代更新。其中optimizer.step()根据反向传播的梯度信息来更新网络参数,以降低损失值;scheduler.step()函数以epoch为单位来更新优化器的学习率。
步骤六、计算RMSE、MAE、R
步骤七,通过训练好的模型对划分出的测试集进行回归预测,判断其可靠性和精确性。
模型训练后预测值和真实值的拟合曲线如图4所示,评价指标如图5、图6、图7所示。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 一种基于高光谱成像技术结合波长选择算法串联策略的调理牛排新鲜度快速检测的方法
- 一种基于表面增强拉曼光谱结合分子衍生化技术的地沟油中辣椒碱快速超灵敏检测方法