一种通过目标标签来进行智能串并视频的方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及视频处理,具体地指一种通过目标标签来进行智能串并视频的方法。
背景技术
目前大部分串并视频的过程就是对一张目标画像进行识别处理,提取固定特征后进行撞库比对,满足特征相似度百分比后就认定为串视频或者并视频。这种串并比对方法是目前比较主流的方法之一,优点就是方便快捷,省时省力,能节省大量翻看视频的时间,提高视频处理效率。但是,使用目标画像进行识别,也有一些不足之处,例如:1.人类脸部存在相似性,不同个体之间的区别不大,大部分的人脸的结构相似度较大,在加上化妆的掩盖及双胞胎的天然相似性更增加识别的难度。2.人脸存在易变性,人脸的外形很不稳定,可以通过脸部的变化产生很多表情,而在不同的目标画像也就不同。3.人脸识别还受光照条件、人脸的很多遮盖物、年龄等多方面因素的影响,导致最终识别的特征有差异。4.人脸识别提取特征是程序自定义的算法,人为无法进行有效干扰,如果需要更加细致的特征就需要另外想办法。
发明内容
本发明目的在于克服上述现有技术的不足而提供一种通过目标标签来进行智能串并视频的方法,该方法能够解决因为无法有效利用目标特征进行智能比对串并,出现线索遗漏,从而导致串并视频不完整的问题。
实现本发明目的采用的技术方案是一种通过目标标签结合结构化特征属性来进行智能串并视频的方法,该方法包括如下步骤:
S1:提取主体视频中目标的标签字符串关键字和结构化特征属性;
S2:对标签字符串关键字和结构化特征属性进行算法匹配权重,系统对当前结构化特征属性和标签字符串关键字进行加权,配重;
S3:在目标信息表中进行批量匹配结构化特征属性和标签字符串关键字相似度,只要除当前目标以外的其他任何目标的结构化特征属性相似度和标签字符串关键字匹配程度两个维度都达到一定百分比以上,那么就将该目标加入相似目标池,等待进一步检验;
S4:针对相似目标池中的所有目标,在涉及视图库中匹配每个目标所属视频,检测出当前目标的所有视频;
S5:将检测出来的所有视频设为待串视频,然后根据目标的结构化特征相似度和标签字符串关键字匹配度,再加上目标分别所属的视频性质相似度,根据从大到小的顺序对待串视频列表进行正向排序。
在上述技术方案中,所述标签字符串关键字是系统无法提取的特征,通过人为获取区别于其他目标的特征。
在上述技术方案中,步骤S3中,除当前目标以外的其他任何目标的结构化特征属性相似度和标签字符串关键字匹配程度两个维度都达到30%以上,那么就将该目标加入相似目标池。
在上述技术方案中,步骤S4中,通过匹配出的所有相似目标,对涉及视图库进行批量撞库检索,匹配出每一个相似目标所对应的视频。
在上述技术方案中,步骤S5中,将每个视频的视频类别,视频时间,视频地点,对立目标的属性和主体视频的属性进行比对、筛选、排序和去重,按照目标结构化属性特征相似度和相同目标标签或相似目标标签的匹配程度再加上视频属性相似度从大到小进行正向排序。
本发明方法和现有串并方法不同的方面在于,在串并视频时使用了结构化属性结合标签字符串关键字进行双重匹配机制,利用已有的大数据分析经验,程序内部推演和计算结构化属性和标签权重比例,形成独特的人工智能算法,表现形式上更为智能,视频串并效率更高。现有串并方法存在区域局限性,例如:某地某时发生某种性质视频,而在一段时间后另外一个地区也发生类似性质的视频,两个地区由于存在跨区域性,无法进行有效的联动,而通过本发明方法只要在网内部进行了部署,录入系统的视频都会被有效串并解决了串并视频跨区域性的问题。
本发明具有以下优点:
1、多维度综合视频串并,视频串并更准确更完整。
2、在大数据分析中智能串并,极大减轻一线工作人员工作压力。
3、多个维度进行比对,减少使用人员反复翻看视频时间,提高效率。
4、准确高效。
5、有效的将目标识别技术、视频智能化分析技术以及查看人员实战经验和知识相结合,从而提供更准确的串并视频信息。
附图说明
图1为本发明一种通过目标标签来进行智能串并视频的方法流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的详细说明。
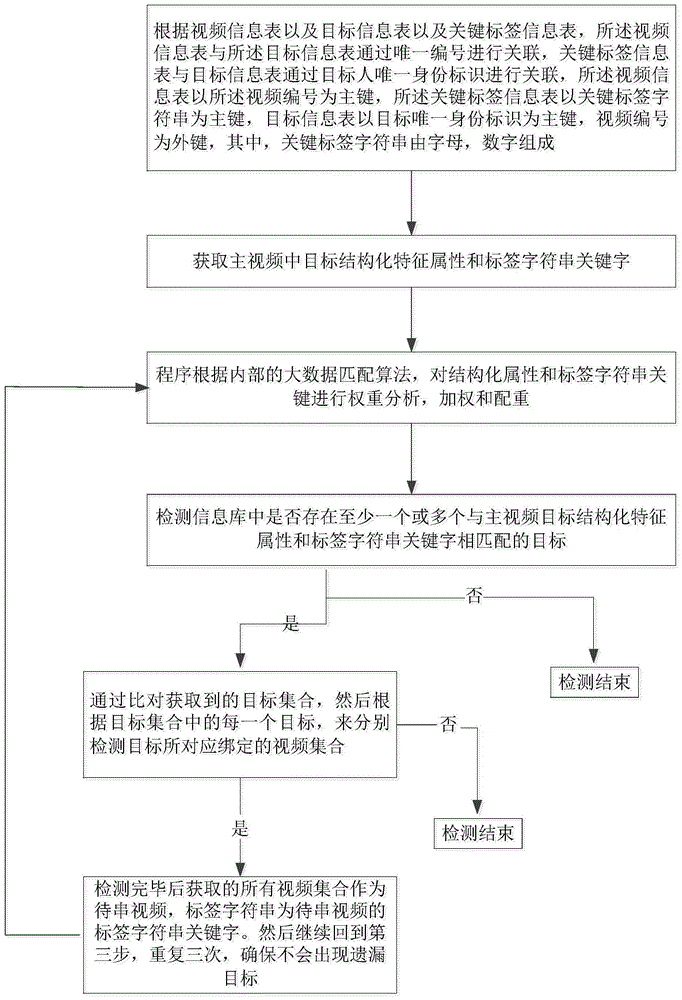
如图1所示,本发明通过目标标签来进行智能串并视频的方法是通过从目标提取的标签字符串关键字,来对视频信息表和目标信息表建立关联关系,具体包括以下步骤:
S1:程序提取主体视频中目标的结构化特征属性和标签字符串关键字。结构化特征属性来源于当前目标进行识别程序后的属性,标签字符串关键字是每一个目标在入库目标信息表时除了系统对当前目标的人脸提取特征之外,人工赋予的一种特殊属性,这种属性一般比较独立和隐晦,不同目标之间重复率较低。
S2:根据大量真实有效的大数据分析经验,通过系统内部人工智能算法对结构化属性和标签字符串关键字进行内部加权和配重。
S3:使用加权后的结构化属性和目标标签字符串关键字,在目标信息表中进行批量模糊匹配标签字符串关键字,当前目标以外的其他任何目标标签字符串关键字部分匹配或者完全匹配,结构化特征属性相似度达到30%以上,两个比对维度取并集,那么就将该目标加入相似目标池,等待进一步检验,在这个过程中,结构化特征属性使用了智能算法相似度查询和标签关键字来进行匹配(有精准匹配,模糊匹配,分词匹配三种方式),所以出来的结果集合是加权后的结构化特征属性和标签字符串关键字的匹配程度由高到低来进行正向排序。
S4:利用相似目标池中的所有目标,在涉及视图库中匹配每个目标所属视频。在这个过程当中,通过匹配出的所有相似目标,对涉及视图库进行批量撞库检索,匹配出每一个相似目标所对应的视频,理论上这些视频和主体视频之间或多或少的存在一些相似性和偶合性。
S5:将检测出来的所有视频,设为待串视频,然后根据每个视频的类别,视频时间,视频地点,对立目标等等属性,和主体视频的属性进行筛选、排序和去重,目标的结构化特征相似度和标签字符串关键字匹配度,再加上目标分别所属的视频性质相似度,根据从大到小的顺序对待串视频列表进行正向排序
S6:系统会默认重复步骤S2-S5循环三次,确保不会出现漏检或误检,从而出现少结果、漏结果
本发明创造提出了一种在识别目标的过程中,手动添加目标特征的方法。本实施例中的标签字符串关键字即为手动添加的特征,手动添加的特征是识别程序无法识别到的特征,程序可以识别出来的特征包括目标上衣类型、上衣颜色、下装类型、下装颜色这些常规属性,如果再有更加细微或者细致的特征,例如:目标脖子上是否戴项链或者吊坠,是否戴耳环,目标的左手或者右手有一根或几根手指头残缺,断指,目标左腿或右腿残疾,行走姿势异常,目标胳膊或者手臂部分是否有纹身,纹身图案是什么,是否有刀伤,是否有残缺,以上的种种人体特征,因为某些特征比较细微,隐藏的比较深,识别系统在进行识别时往往会进行忽略或者无法准确的进行识别,只能通过人员对现场监控视频进行观察或者根据现场目击人员的描述,对目标信息的一种重要补充说明。例如:通过识别程序识别出来的人脸特征对涉及视图库检索出来存在大量的结果,假设这个时候我们还有一个已知的,独立性较高的特征,比如我们需要检索的目标的左眼是个假眼,通过这个"左眼是假眼"这个标签关键字符串,就可以在检索过程中首先进行一层过滤,剔除掉大量不满足条件的结果,”左眼是假眼“这个标签字符串关键字就可以做为当前目标关联其他目标的条件之一。
在这个基础上,本发明提出了一种快速,准确的分析出与主要视频中目标人员特征相似或相近的其他所有视频的方法。智能标签串并比对视频,即在目标在被入库时,首先通过识别程序对目标脸部特征提取,做为当前目标唯一识别特征,然后在对现场监控视频查看,或者现场目击人员描述,对目标人信息进行补充,目标人信息包含常规信息和特殊信息,常规信息包含上衣颜色,上衣类型,下衣颜色,下衣类型,特殊信息包含目标性别,目标年龄范围,目测身高区间,秃头,人脸提取的特征数据,长发还是短发这些信息,在这个基础上,本发明引入了一种标签的属性作为特殊信息,标签属性通常是比较细致的地方,例如左手食指残缺,就把“左手食指残缺”这个标签进入入库,这个标签就做为一个比较独立和显著的特点,给当前目标打上一个印记,称作目标标签字符串关键字,后续这个标签字符串关键字,就作为关联不同视频里面不同目标或相似目标的条件之一。人员进行操作的时候,通过识别程序拿到人脸特征,因为大部分人脸存在相似性,导致最终结果和实际需求有差异,通过特征比对后存在大量检索出来的结果,但是这些结果只基于在人脸特征上通过比对相似度大小,超过一定数值的相似度,系统就会认为是相同目标,导致最终串并结果冗余,不准确。本发明引入了目标标签字符串关键字后,在进行目标比对的时候,标签字符串关键字也会做为一个条件参与检索,假设有一种场景,人员在视频现场提取的视频中发现了疑似目标出现的时间点和画面,但是由于现场监控设备覆盖面积小,或者监控设备老旧导致视频画面模糊,这种情况下使用目标画像进行特征提取就会存在识别不准确甚至无法识别的问题,在特征不全或者无特征的情况下,使用目标特征标签关键字后,就可以过滤大部分和当前疑似目标不吻合的目标集合,筛选后的目标,才会和现场监控视频中的疑似目标大致相似,在这个基础上,对目标信息库进行比对后,获取的目标集合才会更加趋向于准确,导致最终串并比对的视频结果集合更加靠近查看人员需要的结果。
本发明从以下三个方面实现区别于现有技术:
1、对常规视频串并的一种补充,标签字符串关键字结合结构化视频串并
常规视频串并,通常利用视频的某一个维度的属性为切入点,进行视频数据匹配,由于视频类别,手段,选择处所,对象等视频信息与视频之间不存在一一对应的关系,所以串并视频的准确率较低,浪费大量的人力和物力,效果也不理想。本发明方法首先会将视频现场采集的监控视频进行批量结构化,对视频中每一个出现的目标进行识别、分析,结构化后的数据为基础数据无法更改,称为源数据。而标签字符串关键字则是在结构化的基础上进行的一种补充,有以下几个目的:1突出当前目标一个非常显著的特征,2对细致,微小特征的一种描述说明,3补充结构化程序某些不足之处。在串并视频过程中,通过源数据和标签字符串关键字来进行智能比对,减少毫无关联的视频匹配率,减少视频遗漏率,提升视频识别效率。
2、标签字符串关键字归一化
标签字符串关键字来源与使用人员的判定,由于使用人员的个体差异,在进行描述标签字符串关键字时会使用不同的方式,例如描述目标人是个左撇子,有的标签字符串关键字为‘左撇子’,有的标签字符串关键字为‘惯用左手’,那么使用人员在输入标签字符串关键字时只要输入‘左’这个字符串,就会将左撇子和惯用左手以及其他所有含有‘左’字符串标签进行匹配查询,避免由于描述上的差异,导致标签无法匹配上,目的为了提高系统便利性,减少描述上的差异,提高研判的准确率。
3、研判权重
系统内部将结构化后的属性和标签字符串关键字进行权重划分,通过已有的大量数据进行分析训练,机器模型会自动学习,将比对维度和出现率较高的结构化特征属性和标签字符串关键字赋予较高的权重,出现频率低的属性赋予较低的权重,智能串并比对时会根据匹配程度,权重高低对视频进行分析排序,优化展示效果,更趋近了使用人员想要的结果。目的是过滤掉毫无关联的视频集合,提高了串并视频的准确性。
- 一种智能终端中进行的线上视频导播方法、装置和智能终端
- 用于对视频目标平面的目标信息进行编码的方法及装置
- 用于对视频目标平面的目标信息进行编码的方法及装置