一种预测高原病的方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 09:58:59
技术领域
本申请涉及计算机领域,具体而言,涉及一种预测高原病的方法、装置、计算机设备和存储介质。
背景技术
我国高原主要分布在西藏、青海和新疆,海拔3000m以上的高原和高山地区占我国国土面积的1/6,西部大开发以来,大量内地平原人员需进入高原地区。然而,高原恶劣的低压、低氧等自然地理环境因素严重影响急进高原地区人员的身心健康,其中,人们进入高原后出现的高原病成为了制约高海拔地区发展和国防建设的主要因素。
现阶段,人们只有在进入到了高原地区之后,根据自己的身体情况才能确定出自己是否产生了高原病,在没有进入高原之前,是无法判断自己是否会产生高原病,这种不确定性因素,会阻止不能产生高原病的人进入高原,也促进了可能产生高原病的人进入高原,这样就导致了产生高原病的人增多,也限制了高原的发展和建设。
发明内容
有鉴于此,本申请的目的在于提供一种预测高原病的方法、装置、计算机设备和存储介质。用于解决现有技术中不能对高原病进行预测的问题。
第一方面,本申请实施例提供了一种预测高原病的方法,包括:
获取待检测人员的待检测数据;其中,所述待检测数据包括以下数据中的任意一种或多种:生理数据、生化数据和遗传数据;
将所述待检测数据输入至训练好的高原病预测模型,得到所述待检测人员的预测结果;
根据所述预测结果,生成针对所述待检测人员的调整信息;
将所述调整信息显示在所述待检测人员的显示终端。
可选的,所述高原病预测模型通过如下步骤训练得到:
获取高原病训练样本集合;所述高原病训练样本集合中包括至少一个高原病训练样本;所述高原病训练样本中包括正样本和负样本;其中,所述正样本是待采集信息人员在未去高原前的第一检测数据,所述负样本是待采集信息人员在去高原后的第二检测数据;
针对每一个高原病训练样本,将所述高原病训练样本中的正样本输入至待训练的高原病预测模型,将所述高原病训练样本中的负样本输入至待训练的高原病预测模型,对待训练的高原病预测模型进行训练。
可选的,所述高原病训练样本集合通过如下步骤确定:
对获取到的各个待采集信息人员在未去高原前的第一候选检测数据进行筛选处理,得到各个待采集信息人员的所述第一检测数据;
对获取到的各个待采集信息人员在去高原后的第二候选检测数据进行筛选处理,得到各个待采集信息人员的所述第二检测数据;
基于各个待采集信息人员所对应的所述第一检测数据和所述第二检测数据生成所述高原病训练样本集合。
可选的,所述方法还包括:
获取多个待检测人员的预测结果和真实结果;
基于每个待检测人员的预测结果和真实结果生成受试者工作特征曲线;
根据所述工作特征曲线验证所述训练好的高原病预测模型的准确率;
根据所述准确率对所述训练好的高原病预测模型重新进行训练。
可选的,所述调整信息包括以下信息中的任意一种或两种:
高原缺氧训练信息和预防高原疾病的药物信息。
第二方面,本申请实施例提供了一种预测高原病的装置,包括:
获取模块,用于获取待检测人员的待检测数据;其中,所述待检测数据包括以下数据中的任意一种或多种:生理数据、生化数据和遗传数据;
预测模块,用于将所述待检测数据输入至训练好的高原病预测模型,得到所述待检测人员的预测结果;
生成模块,用于根据所述预测结果,生成针对所述待检测人员的调整信息;
显示模块,用于将所述调整信息显示在所述待检测人员的显示终端。
可选的,所述装置还包括:
样本集合获取模块,用于获取高原病训练样本集合;所述高原病训练样本集合中包括至少一个高原病训练样本;所述高原病训练样本中包括正样本和负样本;其中,所述正样本是待采集信息人员在未去高原前的第一检测数据,所述负样本是待采集信息人员在去高原后的第二检测数据;
训练模块,用于针对每一个高原病训练样本,将所述高原病训练样本中的正样本输入至待训练的高原病预测模型,将所述高原病训练样本中的负样本输入至待训练的高原病预测模型,对待训练的高原病预测模型进行训练。
可选的,所述装置还包括:
第一采集单元,用于对获取到的各个待采集信息人员在未去高原前的第一候选检测数据进行筛选处理,得到各个待采集信息人员的所述第一检测数据;
第二采集单元,用于对获取到的各个待采集信息人员在去高原后的第二候选检测数据进行筛选处理,得到各个待采集信息人员的所述第二检测数据;
生成单元,用于基于各个待采集信息人员所对应的所述第一检测数据和所述第二检测数据生成所述高原病训练样本集合。
第三方面,本申请实施例提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述所述的方法的步骤。
第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述所述的方法的步骤。
本申请实施例所提供的预测高原病的方法,首先,获取待检测人员的待检测数据;其中,所述待检测数据包括以下数据中的任意一种或多种:生理数据、生化数据和遗传数据;其次,将所述待检测数据输入至训练好的高原病预测模型,得到所述待检测人员的预测结果;再次,根据所述预测结果,生成针对所述待检测人员的调整信息;最后,将所述调整信息显示在所述待检测人员的显示终端。
在某些实施例中,在对待检测人员的高原病进行预测之前,需要获取到待检测人员的生理数据、生化数据和遗传数据,根据上述数据对待检测人员的高原病进行预测,不仅考虑到了待检测人员的身体素质,还考虑到了待检测人员的遗产因素,基于全面的信息对高原病进行预测,提高了预测高原病的准确性。并且,将高原病的预测结果显示在待检测人员的显示终端中,可以及时有效的让待检测人员对自己的身体情况有所了解,针对性的调整信息可以提高待检测人员对之后的计划进行调整的效率,节约了待检测人员的时间。
为使本申请的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本申请实施例提供的一种预测高原病的方法的流程示意图;
图2为本申请实施例提供的一种调整高原预测模型的方法的流程示意图;
图3为本申请实施例提供的一种预测高原病的装置的结构示意图;
图4为本申请实施例提供的一种计算机设备的结构示意图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
我国高原主要分布在西藏、青海和新疆,海拔3000m以上的高原和高山地区占我国国土面积的1/6,尤其是西部大开发以来,大量内地平原人员需进入高原地区开展科研、旅游、经商、驻训等活动。然而,高原恶劣的低压、低氧等自然地理环境因素严重影响急进高原地区人员的身心健康,其中最主要的问题是急性高原病。高原病是由平原进入高原或由高原进入更高海拔地区,在短期内(数小时至数日)发生的各种临床症候群,分为急性轻症高原病、高原肺水肿和高原脑水肿,是高原特发病之一,是制约高海拔地区发展和国防建设的主要因素。
平原人进入高原后会对高原低压、低氧等环境的变化产生一种适应性反应,而这种反应存在明显的个体差异,若能找到区分这些差异的某种或一类特质,则能够筛选和识别出高原耐低氧人群,从“源头”上控制高原病发生的人群,可以以保障急进高原人群的身心健康,加快完善实施西部高原地区国防建设。
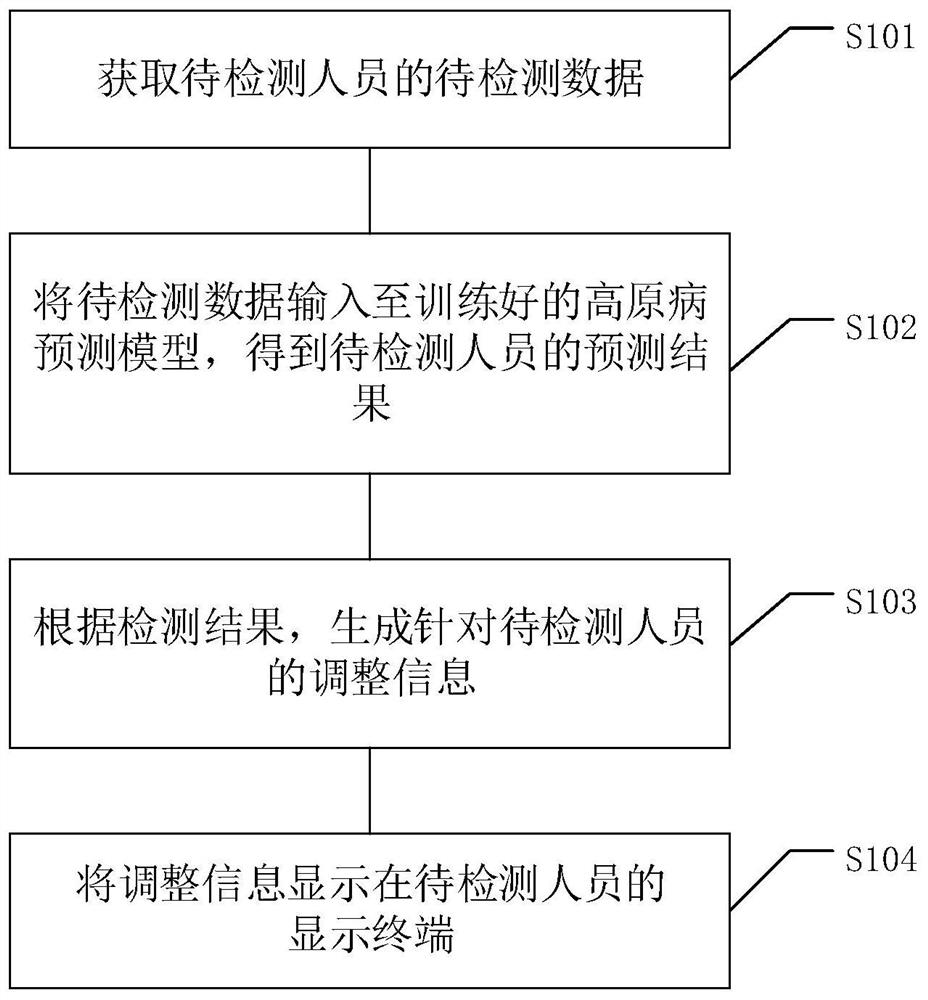
基于上述原因,本申请实施例提供了一种预测高原病的方法,如图1所示,包括以下步骤:
S101,获取待检测人员的待检测数据;其中,所述待检测数据包括以下数据中的任意一种或多种:生理数据、生化数据和遗传数据;
S102,将所述待检测数据输入至训练好的高原病预测模型,得到所述待检测人员的预测结果;
S103,根据所述检测结果,生成针对所述待检测人员的调整信息;
S104,将所述调整信息显示在所述待检测人员的显示终端。
在上述步骤S101中,待检测人员指的是可能需要进入高原地区的人员。待检测数据包括待检测人员的生理数据、待检测人员的生化数据和待检测人员的遗传数据。其中,生理数据包括:体质指数、肺活量;生化数据包括:血红蛋白、红细胞压积、红细胞计数;遗传数据包括:EPAS1基因SNP位点rs13419896,rs1868092,rs4953354,EGLN1基因SNP位点rs12097901,rs2790859,PPARA基因SNP位点rs7292407,rs6520015,以及EPAS1,EGLN1和PPARA基因表达水平。
在上述步骤S102中,高原病预测模型用于根据待检测人员的待检测数据预测导检测人员是否会产生高原病。预测结果包括待检测人员会产生高原病,或高检测人员不会产生高原病。
在上述步骤S103中,调整信息用于对待检测人员进入高原前的准备进行调整。调整信息包括以下信息中的任意一种或多种:预防高原疾病的药物信息、高原缺氧训练信息、劝退信息。劝退信息指的是建议待检测人员不去高原的信息。
在上述步骤S104中,生成的调整信息需要给待检测人员进行提醒,因此,调整信息需要展示在待检测人员的显示终端中。
在本申请所提供的方案中,在对待检测人员的高原病进行预测之前,需要获取到待检测人员的生理数据、生化数据和遗传数据,根据上述数据对待检测人员的高原病进行预测,不仅考虑到了待检测人员的身体素质,还考虑到了待检测人员的遗产因素,基于全面的信息对高原病进行预测,提高了预测高原病的准确性。并且,将高原病的预测结果显示在待检测人员的显示终端中,可以及时有效的让待检测人员对自己的身体情况有所了解,针对性的调整信息可以提高待检测人员对之后的计划进行调整的效率,节约了待检测人员的时间。
训练好的高原病预测模型是通过大量数据训练得到的,训练过程包括以下步骤:
S105,获取高原病训练样本集合;所述高原病训练样本集合中包括至少一个高原病训练样本;所述高原病训练样本中包括正样本和负样本;其中,所述正样本是待采集信息人员在未去高原前的第一检测数据,所述负样本是待采集信息人员在去高原后的第二检测数据;
S106,针对每一个高原病训练样本,将所述高原病训练样本中的正样本输入至待训练的高原病预测模型,将所述高原病训练样本中的负样本输入至待训练的高原病预测模型,对待训练的高原病预测模型进行训练。
在上述步骤S105中,高原病训练样本集合用于存储高原病训练样本,高原病训练样本集合中包括至少一个高原病训练样本。高原病训练样本中包括正样本和负样本;其中,所述正样本是待采集信息人员在未去高原前的第一检测数据,所述负样本是待采集信息人员在去高原后的第二检测数据。第一检测数据包括待采集信息人员在未去高原前的生理数据、生化数据和遗产数据。第二检测数据包括待采集信息人员在去高原后的生理数据、生化数据和遗产数据。
在上述步骤S106中,在模型训练过程中,针对每一个高原病训练样本,将正样本输入至待训练的高原病预测模型后会得到一个预测结果,将得到的预测结果与负样本进行比较,如果比较结果存在差异则对待训练的高原病预测模型中的参数进行调整。
高原病训练样本集合通过大量的人员采集信息得到的,采集到的信息可能存在重复、残缺、异常等情况,需要经过筛选才能得到比较精确的数据,用精确数据训练的高原病预测模型得到的预测结果才会更准确。因此,高原病训练样本集合通过如下步骤确定:
步骤1051,对获取到的各个待采集信息人员在未去高原前的第一候选检测数据进行筛选处理,得到各个待采集信息人员的所述第一检测数据;
步骤1052,对获取到的各个待采集信息人员在去高原后的第二候选检测数据进行筛选处理,得到各个待采集信息人员的所述第二检测数据;
步骤1053,基于各个待采集信息人员所对应的所述第一检测数据和所述第二检测数据生成所述高原病训练样本集合。
在上述步骤1051中,第一候选检测数据的筛选处理包括以下处理方式:
遍历每一个第一候选检测数据,在存在重复情况的第一候选检测数据中保留其中一个第一候选检测数据;
遍历每一个第一候选检测数据,删除数据不完整的第一候选检测数据;
遍历每一个第一候选检测数据,删除数据异常的第一候选检测数据。
数据不完整的第一候选检测数据指的是第一候选检测数据中的任意一项或几项的数据为空值。数据异常的第一候选检测数据指的是第一候选检测数据中任意一项或几项的数据不符合正常现象的数值,比如,人的体温为100摄氏度。
第一候选检测数据经过上述筛选处理后可以得到第一检测数据。
在上述步骤1052中,第二候选检测数据的筛选处理包括以下处理方式:
遍历每一个第二候选检测数据,在存在重复情况的第二候选检测数据中保留其中一个第二候选检测数据;
遍历每一个第二候选检测数据,删除数据不完整的第二候选检测数据;
遍历每一个第二候选检测数据,删除数据异常的第二候选检测数据。
数据不完整的第二候选检测数据指的是第二候选检测数据中的任意一项或几项的数据为空值。数据异常的第二候选检测数据指的是第二候选检测数据中任意一项或几项的数据不符合正常现象的数值,比如,人的体温为100摄氏度。
第二候选检测数据经过上述筛选处理后可以得到第二检测数据。
在上述步骤1053中,每个待采集信息人员会对应一个第一检测数据和第二检测数据,相对应的第一检测数据和第二检测数据会组成一个训练样本,其中,第一检测数据是高原病训练样本中的正样本,第二检测数据是高原病训练样本中的负样本。将存在第一检测数据和第二检测数据的高原病训练样本组合成高原病训练样本集合。
对高原病预测模型进行训练的数据虽然对,但可能并不能包含所有情况对应的数据,认为每一个人本身就是不同的,不同的个体之间肯定会存在差异,因此,利用训练好的高原病预测模型预测得到的预测结果也并不是百分之百准确的,为了提高高原病预测模型预测的准确性,需要该高原病预测模型应用的过程中,调整上述高原病预测模型的预测精度,如图3所示,包括:
S111,获取多个待检测人员的预测结果和真实结果;
S112,基于每个待检测人员的预测结果和真实结果生成受试者工作特征曲线;
S113,根据所述工作特征曲线验证所述训练好的高原病预测模型的准确率;
S114,根据所述准确率对所述训练好的高原病预测模型重新进行训练。
在上述步骤111中,待检测人员的预测结果指的是高原预测模型根据待检测人员的待检测数据预测得到的结果,待检测人员的真实结果指的是待检测人员在进入高原后的预设时间段内出现高原病的结果。少数待检测人员所对应的数据计算得到的高原病预测模型的准确率是不准确的,因此,需要获取多个取待检测人员的预测结果和真实结果。
在上述步骤112中基于每一个待检测人员的预测结果和真实结果,生成度量表,度量表中包括四个指标,分别为:真阳、假阳、假阴、真阴。如表1所示,1表示高原病预测模型的输出结果为存在高原病,0表示高原病预测模型的输出结果为不存在高原病;1表示高原病预测模型的输出结果为存在高原病,0表示高原病预测模型的输出结果为不存在高原病;A表示真实存在高原病的待检测人员的数量,B表示真实不存在高原病的待检测人员的数量;A1表示待检测人员中高原病预测模型的输出结果为存在高原病的数量,B1表示待检测人员中高原病预测模型的输出结果为不存在高原病的数量。TA表示真实存在高原病的与预测模型的预测结果一致的数量,即为真阳性的数据量,TB真实不存在高原病的与预测模型的预测结果一致的数量,即为真阴性的数量,FA表示真实存在高原病的与预测模型的预测结果不一致的数量,即为假阳性的数量,FB真实不存在高原病的与预测模型的预测结果不一致的数量,即为假阴性的数量。根据度量表中的值可以确定工作特征曲线(ReceiverOperating Characteristic,简称ROC)曲线的横轴和纵轴。在ROC曲线中假阳性率定义为横轴,真阳性率定义为纵轴。假阳性率指的是实际不存在高原病的待检测人员中被预测为存在高原病的概率,也就是FA/(FA+TB)的值,真阳性率指的是实际存在高原病的待检测人员中也被预测为存在高原病的概率,也就是TA/(TA+FB)的值。根据每一个待检测人员的预测结果和真实结果,在假阳性率为横轴,真阳性率为纵轴的坐标系中生成ROC曲线。
表1
在上述步骤113中,根据ROC曲线基于横轴的面积就可以验证高原病预测模型的准确率。面积越大越接近于1,则高原病预测模型准确率越高;面积越小越接近于0,则高原病预测模型准确率越低。
在上述步骤114中,准确率低的高原预测模型会给人们的生活带来较大的不便,降低对高度地区的开发和建设效率,因此,当检测到高原预测模型的准确率小于预设数值时,可以再次对高原病预测模型重新进行训练,不断提高高原预测模型的预测精度。
本申请实施例提供了一种预测高原病的装置,包括:
获取模块301,用于获取待检测人员的待检测数据;其中,所述待检测数据包括以下数据中的任意一种或多种:生理数据、生化数据和遗传数据;
预测模块302,用于将所述待检测数据输入至训练好的高原病预测模型,得到所述待检测人员的预测结果;
生成模块303,用于根据所述预测结果,生成针对所述待检测人员的调整信息;
显示模块304,用于将所述调整信息显示在所述待检测人员的显示终端。
可选的,所述装置还包括:
样本集合获取模块,用于获取高原病训练样本集合;所述高原病训练样本集合中包括至少一个高原病训练样本;所述高原病训练样本中包括正样本和负样本;其中,所述正样本是待采集信息人员在未去高原前的第一检测数据,所述负样本是待采集信息人员在去高原后的第二检测数据;
训练模块,用于针对每一个高原病训练样本,将所述高原病训练样本中的正样本输入至待训练的高原病预测模型,将所述高原病训练样本中的负样本输入至待训练的高原病预测模型,对待训练的高原病预测模型进行训练。
可选的,所述装置还包括:
第一采集单元,用于对获取到的各个待采集信息人员在未去高原前的第一候选检测数据进行筛选处理,得到各个待采集信息人员的所述第一检测数据;
第二采集单元,用于对获取到的各个待采集信息人员在去高原后的第二候选检测数据进行筛选处理,得到各个待采集信息人员的所述第二检测数据;
生成单元,用于基于各个待采集信息人员所对应的所述第一检测数据和所述第二检测数据生成所述高原病训练样本集合。
可选的,所述装置还包括:
第二获取模块,用于获取多个待检测人员的预测结果和真实结果;
曲线生成模块,用于基于每个待检测人员的预测结果和真实结果生成受试者工作特征曲线;
计算模块,用于根据所述受试者工作特征曲线验证所述训练好的高原病预测模型的准确率;
重新训练模块,用于根据所述准确率对所述训练好的高原病预测模型重新进行训练。
可选的,所述调整信息包括以下信息中的任意一种或两种:
高原缺氧训练信息和预防疾病的药物信息。
对应于图1中的预测高原病的方法,本申请实施例还提供了一种计算机设备400,如图4所示,该设备包括存储器401、处理器402及存储在该存储器401上并可在该处理器402上运行的计算机程序,其中,上述处理器402执行上述计算机程序时实现上述预测高原病的方法。
具体地,上述存储器401和处理器402能够为通用的存储器和处理器,这里不做具体限定,当处理器402运行存储器401存储的计算机程序时,能够执行上述预测高原病的方法,解决了现有技术中不能对高原病进行预测的问题。
对应于图1中的预测高原病的方法,本申请实施例还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述预测高原病的方法的步骤。
具体地,该存储介质能够为通用的存储介质,如移动磁盘、硬盘等,该存储介质上的计算机程序被运行时,能够执行上述预测高原病的方法,解决了现有技术中不能对高原病进行预测的问题,本申请在对待检测人员的高原病进行预测之前,需要获取到待检测人员的生理数据、生化数据和遗传数据,根据上述数据对待检测人员的高原病进行预测,不仅考虑到了待检测人员的身体素质,还考虑到了待检测人员的遗产因素,基于全面的信息对高原病进行预测,提高了预测高原病的准确性。并且,将高原病的预测结果显示在待检测人员的显示终端中,可以及时有效的让待检测人员对自己的身体情况有所了解,针对性的调整信息可以提高待检测人员对之后的计划进行调整的效率,节约了待检测人员的时间。
在本申请所提供的实施例中,应该理解到,所揭露方法和装置,可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,又例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些通信接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请提供的实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释,此外,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
最后应说明的是:以上所述实施例,仅为本申请的具体实施方式,用以说明本申请的技术方案,而非对其限制,本申请的保护范围并不局限于此,尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本申请实施例技术方案的精神和范围。都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应所述以权利要求的保护范围为准。
- 一种预测高原病的方法、装置、计算机设备和存储介质
- 一种设备使用寿命的预测方法、装置、计算机设备及计算机可读存储介质