一种利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法
文献发布时间:2023-06-19 10:36:57
技术领域
本发明涉及一种利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法,属于植物分子生物学技术领域。
背景技术
转录因子在动植物生长和发育的过程中都发挥着重要的作用,转录因子通过结合目标基因启动子上的顺式作用元件实现对目标基因的调控。研究显示,多种棉花转录因子参与棉花的纤维发育和抗逆反应,如GhWRKY34、GhWRKY6-like、GhATAF1、GhABF2等转录因子可以提高转基因植株的耐盐性,GhMYB25、GhHOX3、GhTCP14等转录因子可以调节棉花纤维发育。然后针对棉花转录因子下游结合元件位点的鉴定较难,难以实现解析棉花转录因子的相关调控机制,造成相关研究比较滞后,DNase I超敏感位点(DNaseI hypersensitivesite,DHS)是鉴定基因组功能元件(启动子、增强子、绝缘子等)的金标准,利用特异发育时期的DHS-seq数据,有利于鉴定转录因子下游结合元件。
现如今转录因子下游鉴定方法多为染色质免疫共沉淀测序(ChIP-seq)。进行染色质免疫共沉淀有两种主要的方法:第一种,直接获取所需要材料的细胞核后,进行染色质免疫共沉淀后测序,然而该方法需要获得该转录因子的特异抗体进行实验,而生物体内转录因子往往存在家族,获取某一成员的特异抗体较难,往往会造成很大的背景干扰,导致结果准确性降低;第二种,对该转录因子加上已知的功能域的标签构建融合表达载体后进行转基因,但是棉花的遗传转化周期过程需要6-8个月,后续还要进行转基因纯合系筛选后,才能染色质免疫共沉淀实验,耗时费力,成本也高。现有针对棉花纤维发育时期的转录因子调控位点研究,多采用转基因的方法,耗时费力,且花费高昂(Shan C M,et al.,2014,5(5519):5519.),普通的DAP-seq方法,未有考虑特异发育时期DNA甲基化作用,没有进行特异发育时期染色质开放状态分析,所得转录因子结合位点较多(宁丽华等,科学通报,2019,v.64(24):81-92.),加重了后续分析功能性位点的筛选难度。
因此,亟需一种具有快速、准确、经济、省力的棉花纤维发育时期转录因子下游结合元件的鉴定方法。
发明内容
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供一种用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
一种用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法,其包括如下步骤:
S1、提取棉花纤维发育时期的基因组DNA后,将棉花纤维基因组DNA随机打断获得DNA片段,并修复、连接构建获得具有Illumina测序接头的Index-DNA文库;
S2、棉花转录因子与标签基因融合后进行表达与蛋白纯化,获得带有标签的融合蛋白;
S3、将带有标签的融合蛋白与Index-DNA文库在体外孵育使两者充分结合,并提取与该融合蛋白特异结合的Index-DNA;
S4、将步骤S3获得的Index-DNA进行扩增后测序,将所得数据进行匹配到棉花基因组上,并与棉花纤维发育时期的DHS位点相互印证后,识别确认所得结合元件序列。
如上所述的方法,优选地,在步骤S1中,所述棉花纤维基因组DNA采用凯杰植物DNA提取试剂盒提取,所述随机打断采用超声波破碎仪打断,获得200bp左右的DNA片段。
提取的为棉花纤维基因组DNA,避免由于棉花不同组织间DNA甲基化差异对转录因子结合位点元件的误判。
进一步优选地,在步骤S1中,所述超声波打断为Bioruptor pico的超声波破碎仪设定Time ON 30s Time OFF 30s,Cycle Num 13,最后可得到200bp左右的DNA片段。
如上所述的方法,优选地,在步骤S1中,对获得的DNA片段采用Enzyme进行末端修复,之后加入dATP和Klenow酶进行加A尾获得A-tailed DNA,再加入Illumina测序接头进行连接,获得Index-DNA片段。
进一步优选地,Illumina测序接头为Annealed TruSeq Adaptor。
如上所述的方法,优选地,在步骤S2中,所述棉花转录因子的基因序列如SEQ IDNO.1所示,所述标签为GST标签、His标签、Flag标签或GFP标签。
如上所述的方法,优选地,在步骤S3中,所述体外孵育采用Incubation Buffer溶液,并在室温转动摇动1h,并加入标签多克隆抗体孵育过夜,最后加入rProtain A琼脂糖珠4℃孵育3~4h,经过洗涤后,利用洗脱液将rProtain A琼脂糖珠和标签多克隆抗体-带有标签的融合蛋白-Index-DNA片段复合物分离开来,最后利用酚氯仿抽提复合物中的Index-DNA片段。
如上所述的方法,优选地,所述Incubation Buffer溶液中含有终浓度为0.05MNaCl,0.02M Tris-HCl,0.005M EDTA,0.0002M PMSF,Complete Mini(Roche)。
rProtain A琼脂糖珠为白色固体小颗粒,在进行离心后,沉淀即为rProtain A琼脂糖珠-标签多克隆抗体-带有标签的融合蛋白和-Index-DNA片段复合物。
如上所述的方法,优选地,所述洗涤为分别依次加入Buffer A-50mM NaCl、BufferA-100mM NaCl、Buffer A-150mM NaCl溶液进行,即先加入Buffer A与NaCl的溶液后颠倒混匀1分钟,常温下5000rpm离心1分钟,冰上放置1分钟,去除尽可能多的上清液;Buffer A为含0.05M pH值为7.5的Tris-HCl,0.01M pH值为8.0的EDTA,50mM NaCl、100mM NaCl、150mMNaCl表示在Buffer A中的终浓度;
所述洗脱液为预热的Elution buffer,预热温度为42℃,Elution buffer为终浓度含有0.05M的NaCl,0.02M pH值为7.5的Tris-HCl,0.005M pH值为8.0的EDTA,1%的SDS,洗脱两次,并置于65℃水浴15min,每5min颠倒混匀一次。
如上所述的方法,优选地,在步骤S4中,所述扩增采用的50μL体系为DAP-DNA 14μL,2×Kapa HiFi HotStart Ready Mix 25μL,0.25μM的TruSeq PCR primer cocktail 1μL,ddH
如上所述的方法,优选地,在步骤S4中,所述识别确认所得结合元件序列先用bowtie软件将所得的测序的数据比对到棉花基因组上,利用Popera软件进行峰值鉴定,最后利用BED Tools软件确定正确的peaks位置,针对peaks进行motif分析、peaks下游基因启动子鉴定并与棉花纤维发育时期DHS数据进行交叠绘制韦恩图,三者均有的即为该转录因子下游的结合元件。
进一步优选的,与棉花纤维发育时期DHS图谱进行交叠绘制韦恩图,该DHS图谱包含棉花纤维发育时期的绝大多数活跃的功能元件,避免出现非活跃DNA元件位点的误判。
(三)有益效果
本发明的有益效果是:
本发明提供的用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法,采用体外原核表达带有标签的棉花转录因子融合蛋白,调取棉花纤维基因组DNA中的亲和片段后,构建Illumina测序文库进行测序,针对peaks进行motif分析,利用BED Tools软件peaks下游基因启动子鉴定并与棉花纤维发育时期DHS数据进行交叠绘制韦恩图确定正确的DNA元件序列域位置。用这种方法不经遗传转化,可以迅速准确的鉴定出棉花转录因子下游结合位点,具有更强的实践利用价值和意义。
本发明利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法有如下优点:
1、快速。利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法,实验周期为3天,相对于棉花遗传转化6-8月,该方法大大缩短了实验周期。
2、准确。利用该方法的GhWRKY70所得到的结果与拟南芥中的同源基因结合位点基本一致。
3、经济。该方法利用融合蛋白中确认的GST标签,进行相应抗体的选择,无需经过繁琐的特异抗体筛选过程,以及特异抗体制作与购买的时间与经济上的浪费。
4、便捷。实验结果易重复,适合应用于已经进行DHS测序的多数植物的组织,可直接用于鉴定功能性DNA元件的核心区域。
附图说明
图1为超声波打断棉花纤维发育时期基因组DNA电泳检测;
图2为PGEX-4T-1-GhWRKY70载体图;
图3为Western Blot检测原核表达蛋白;
图4为胶回收纯化构建的Illumina测序文库;
图5为GhWRKY70下游结合位点分析与鉴定。
具体实施方式
转录因子可以特异结合下游靶基因的顺式调控元件DNA上,进而调控靶基因的表达,然而在进行转录因子下游结合位点研究时,对于非模式植物棉花来说,研究棉花纤维发育特定时期的转录因子结合位点更加困难。
本发明经大量实验研究发现,采用DNA亲和蛋白测序(DAP-seq)的方法,利用转录因子自身的特性,将其融合表达一个带有特异标签(GST、Flag、GFP等)的融合蛋白,进而可以选用商业化的标准抗体,来鉴定后该融合蛋白,避免了制作转录因子抗体的高昂花费与时间的浪费;进一步的采用棉花纤维发育时期的基因组DNA,有效的利用了的DNA甲基化阻碍转录因子与靶位点的结合的特性,使最后结合的位点是纤维特异时期的DNA元件;最后利用棉花纤维发育时期的DHS图谱与DAP-seq所得数据进行相互印证,排除非活跃性位点的结合,得出在棉花纤维染色质开放区的转录因子结合DNA元件即为该转录因子在棉花纤维发育时的特异结合位点,该位点下游基因基因该转录因子的靶基因。本发明方法通过多重验证最终高效、准确的得到棉花纤维发育时期转录因子结合元件。为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
实施例1
一种利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法,具体采用如下步骤:
S1、棉花基因组DNA随机打断与具有Illumina测序接头连接构建获得Index-DNA文库
1、棉花基因组DNA随机打断
(1)用DNeasy Plant Mini Kit(50)植物DNA提取试剂盒提取棉花纤维发育时期的基因组DNA并检测。提取步骤及检测不在此赘述,将提取获得的基因组DNA用TE稀释成20ng/μL,取300μl转移到Covaris microTUBE中,并使用Bioruptor pico的超声波破碎仪设定Time ON 30s Time OFF 30s,Cycle Num 13进行随机打断,经电泳检测后,结果如图1所示,图中M代表DNA marker,泳道1,2均为打断后的棉花纤维DNA。电泳检测结果说明,程序设定的正确,获得棉花纤维DNA片段刚好是200bp左右,时间越短,片段越大,反之越小。超声条件是经大量实验摸索之后获得的合适条件。
(2)将超声处理的样品转移到干净的1.5mL试管中。加入30μL 3M NaOAc(0.1倍体积)和600μL冷的100%乙醇(2倍体积),涡旋混合。
(3)在冰上或在-20℃下孵育至少15分钟,但不要超过24小时。
(4)在4℃下以最大速度(20,000g)离心20分钟,倾析弃去上清液。
(5)用1mL 70%乙醇洗涤沉淀,在4℃下以最大速度(20,000g)离心10分钟,倾析弃去上清液。
(6)以3000g的速度快速旋转5秒钟,然后移液除去所有残留的乙醇,注意不要干扰DNA沉淀。
(7)在室温(22℃)下将沉淀干燥10-15分钟,或在37℃下干燥5-10分钟。重悬浮之前,请确保沉淀完全干燥。让沉淀物干燥太久可能会使重悬更加困难,但不应损害DNA。
(8)将DNA沉淀重悬于30-40μL TE中。在37℃放置5分钟以帮助溶解DNA,用于下面反应。
2、末端修复并制作Index-DNA文库:
(1)1.5mL的PCR离心管中配制如下混合液采用50μL体系:(End-itTM试剂盒(Lucigen),用前在冰上融化、离心,抽吸混匀后加入,避免气泡产生)。
需要注意的是:在1.5mL离心管中,按照顺序加入,每次更换枪头,做好标记,免出错。指弹混匀,离心后,常温放置45min。
(2)加入5μL 3M NaOAc(0.1倍体积)和100μL冷的100%乙醇(2倍体积),涡旋混合。
(3)在冰上或在-20℃下孵育至少15分钟,但不要超过24小时。
(4)在4℃下以最大速度(20,000g)离心20分钟,倾析弃去上清液。
(5)用1mL 70%乙醇洗涤沉淀,在4℃下以最大速度(20,000g)离心10分钟,倾析弃去上清液。
(6)以3000g的速度快速旋转5秒钟,然后移液除去所有残留的乙醇,注意不要干扰DNA沉淀。
(7)在室温(22℃)下将沉淀干燥10-15分钟,或在37℃下干燥5-10分钟。重悬浮之前,请确保沉淀完全干燥。让沉淀物干燥太久可能会使重悬更加困难,但不应损害DNA。
(8)将DNA沉淀重悬于41.5μL EB中,在37℃放置5分钟以帮助溶解DNA。
3、加A尾,配置如下:
(1)轻弹管壁,混匀液体,离心后置于PCR仪中,37℃温浴30min,取出后立即置于冰上。
(2)加入5μL 3M NaOAc(0.1倍体积)和100μL冷的100%乙醇(2倍体积),涡旋混合。
(3)在冰上或在-20℃下孵育至少15分钟,但不要超过24小时。
(4)在4℃下以最大速度(20,000g)离心20分钟,倾析弃去上清液。
(5)用1mL 70%乙醇洗涤沉淀,在4℃下以最大速度(20,000g)离心10分钟,倾析弃去上清液。
(6)以3000g的速度快速旋转5秒钟,然后移液除去所有残留的乙醇,注意不要干扰DNA沉淀。
(7)在室温(22℃)下将沉淀干燥10-15分钟,或在37℃下干燥5-10分钟。重悬浮之前,请确保沉淀完全干燥,让沉淀物干燥太久可能会使重悬更加困难,但不应损害DNA。
(8)将DNA沉淀重悬于20μL EB中,在37℃放置5分钟以帮助溶解DNA,获得A-tailedDNA。
4、Index接头连接
此步可以根据样品数量,加不同的Index接头,也可以只用一个Index接头,所有的蛋白共用一个文库,注意测序的时候写清楚Index信息,避免混淆,本实施例中采用的是Annealed TruSeq Adaptor的Index为(SEQ ID NO.2)ATCACG(TruSeq Universal Adapter(SEQ ID NO.3):AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATC*T和TruSeq Adapter Index 1(SEQ ID NO.4):*GATCGGAAGAGCACACGTCTGAACTCCAGTCACATCACGATCTCGTATGCCGTCTTCTGCTTG,*代表磷酸化)连接,配制如下:
合计50μL手指弹匀后,离心,室温放置15min。
Annealed TruSeq Adaptor制作方法:用Annealing buffer溶解Adapter,10mMTris pH 8.0,50mM NaCl,1mM EDTA,TruSeq Universal Adapter(100μM)10μL;TruSeqAdapter Index 1(100μM)10μL,将二者混匀后,按照75℃15min,60℃10min,50℃10min,40℃10min,25℃30min后,-20℃保存。(1)加入5μL 3M NaOAc(0.1倍体积)和100μL冷的100%乙醇(2倍体积),涡旋混合。
(2)在冰上或在-20℃下孵育至少15分钟,但不要超过24小时。
(3)在4℃下以最大速度(20,000g)离心20分钟,倾析弃去上清液。
(4)用1mL 70%乙醇洗涤沉淀,在4℃下以最大速度(20,000g)离心10分钟。倾析弃去上清液。
(5)以3000g的速度快速旋转5秒钟,然后移液除去所有残留的乙醇,注意不要干扰DNA沉淀。
(6)在室温(22℃)下将沉淀干燥10-15分钟,或在37℃下干燥5-10分钟。重悬浮之前,请确保沉淀完全干燥。让沉淀物干燥太久可能会使重悬更加困难,但不应损害DNA。
(7)将DNA沉淀重悬于31-50μL EB中。在37℃放置5分钟以帮助溶解DNA。
(8)-20℃保存,长期保存放-80℃。
S2、棉花转录因子GhWRKY70的原核表达与蛋白纯化
1、GST标签融合蛋白表达
克隆棉花转录因子基因的全长序列,即棉花转录因子GhWRKY70的CDS序列见SEQID NO.1所示,利用同源重组法构建带有GST标签的原核表达载体pGEX-4T-1-GhWRKY70(如图2所示,可购自丰晖生物)(也可根据自己实验室选择合适的标签,如Flag、GFP和His-tag等),并转化大肠杆菌DH5α,菌落PCR检测阳性克隆,并对所构建的载体进行测序验证基因的准确性,提取测序正确的质粒(序列如SEQ ID NO.5所示,可记为PGEX-4T-GST-GhWRKY70),将正确的质粒和空载质粒转化大肠杆菌表达菌株BL21(DE3),并进行菌落PCR筛选阳性克隆,同时转化空载质粒并筛选阳性克隆。利用1mM IPTG进行诱导蛋白质表达,收集细菌裂解液并进行SDS-聚丙烯酰胺电泳检测,待染色后选择合适的诱导浓度的细菌裂解液,用GST磁珠进行GhWRKY70-GST融合蛋白和GST标签蛋白纯化,将纯化后的蛋白进行Western Blot检测。用SDS-PAGE电泳纯化到的融合蛋白,如图3所示,其中M代表蛋白质marker,泳道1为待测融合蛋白GhWRKY70-GST为61kDa(36kDa+25kDa)。检测正确后,将获得的带有GhWRKY70-GST融合蛋白和GST标签蛋白分成5-10μg/管(约20-30μL/管)后放置于-80冰箱备用。
S3、获取转录因子亲和DNA片段
1、取出一管上步获得的GhWRKY70-GST融合蛋白(约20-30μL/管)(同时以GST标签蛋白作为对照),向其中加入Incubation Buffer,使总体积为500μL。
Incubation buffer配置如下(10mL)
2、向其中加入50-100ng的DAP文库,室温转动(15转/分钟)摇动1h。
3、分别加入4μL(4-8μg)的抗体(GST多克隆抗体(购自上海生工生物,NO.D110271)),用paraflm封住管口,4℃翻转摇动过夜。
4、配制Incubation buffer放置冰上,取40μL/管/样的rProtein A-sepharose琼脂糖珠(rPAS),5000rpm,离心1min,去除上清液。
5、用500μL Incubation Buffer洗涤珠子。放在磁铁上并吸出上清液。5000rpm,离心1min,冰上1min,去除上清液。重复三遍,获得rPAS。
6、均匀加入rProtein A-sepharose(rPAS)至步骤3中与抗体结合的样品管中,paraflm封住管口,4℃下转动(15转/分钟)3小时。
7、准备Buffer A(50mM-1mL/样、100mM-1mL/样、150mM-1mL/样NaCl)和ElutionBuffer(1mL/样)配置如下:
Buffer A-50mM NaCl(10mL)
Buffer A-100mM NaCl(10mL)
Buffer A-150mM NaCl(10mL)
Elution buffer(10mL)
8、常温下13000rpm离心1分钟,冰上放置1分钟,仔细去除上清液。
9、加入1mL的Buffer A-50mM NaCl中,颠倒混匀1分钟。
10、常温下5000rpm离心1分钟,冰上放置1分钟,去除尽可能多的上清液。
11、加入1mL的Buffer A-100mM NaCl中,颠倒混匀1分钟。
12、常温下5000rpm离心1分钟,冰上放置1分钟,去除尽可能多的上清液。
13、加入1mL的Buffer A-150mM NaCl中,颠倒混匀1分钟。
14、常温下5000rpm离心1分钟,冰上放置1分钟,去除尽可能多的上清液(尽量吸尽上清液,可用最细枪头吸下)。
15、加入400μL预热的Elution buffer(42℃),颠倒混匀(此步珠子和核小体分离,注意封口严实)
16、置于65℃水浴15min,每五分钟颠倒混匀一次。
17、13000rpm,1分钟,常温静置1分钟。吸取上清液到另一个新标记的2mL离心管中。
18、原管中再加入400μL预热的Elution buffer(42℃),颠倒混匀。
19、置于65℃水浴15min,每5min颠倒混匀一次
20、13000rpm,1分钟,常温静置1分钟。吸取上清液到上面新标记置于冰上的离心管中,颠倒混匀,共计约800μL液体。
21、加入400μL酚和400μL的氯仿,此步Index-DNA片段和Protein分开。
22、涡旋20秒钟,常温下13000pm离心4分钟。转移上层液到新的1.5mL的离心管中。
23、加入2μL的糖原,80μL的3M的醋酸钠和480μL100%的异丙醇,混匀后常温放置10分钟。
24、13000rpm,4℃,离心10分钟,弃上清液。
25、加人500μL 70%的酒精,颠倒混匀1分钟,洗涤沉淀。
26、常温下13000rpm,离心2-3分钟,倒除上清夜,检查沉淀。在室温(22℃)下将沉淀干燥10-15分钟,或在37℃下干燥5-10分钟。重悬浮之前,请确保沉淀完全干燥。让沉淀物干燥太久可能会使重悬更加困难,但不应损害DNA。(上述将融合蛋白洗脱掉了,只剩下Index-DNA)
27、将DNA沉淀(此DNA即为加有特异Index的DAP-Index-DNA)重悬于15μL TE中。在37℃放置5分钟以帮助溶解DNA。样品可以保存-20℃下。长期保存需放置于-80℃。
S4、将Index-DNA片段进行扩增后测序,将所得数据进行匹配到棉花基因组上,并与棉花纤维发育时期的DHS位点相互对应后,识别确认所得结合元件序列。
其中,1、PCR扩增,配制如下:
手指弹匀后,离心,于下列程序中扩增:45sec at 98,;11个循环的15sec at 98℃,30sec at 63℃,30sec at 72℃;1min at 72℃;Hold at 4℃。(3-22个循环均可,本实施例的GhWRKY70-GST采用了11个循环。)
2、准备1%的琼脂糖胶,用1X TAE+EB配制。
3、加入100bp Marker 4μL,6×loading dye 4μL,样品位于Marker两侧,相邻样品之间隔一个泳道,避免污染。
4、100V,20min,电泳。
5、利用凯杰胶回收试剂盒回收300bp左右的片段。
6、最后加入31μL洗脱液,RT,5min后,13200rpm离心1min。
7、将样本送至测序公司,利用Illumina测序平台PE150测序策略进行测序,获得原始数据,结果如下:
S5、DAP-seq数据分析
1、利用bowtie2 v2.3.5绘图软件将测序获得的FASTQ文件与棉花参考基因组对齐。根据数据质量和参考基因组,进行修整和质量/重复读序过滤。选择具有唯一比对率的读序进行深入分析。
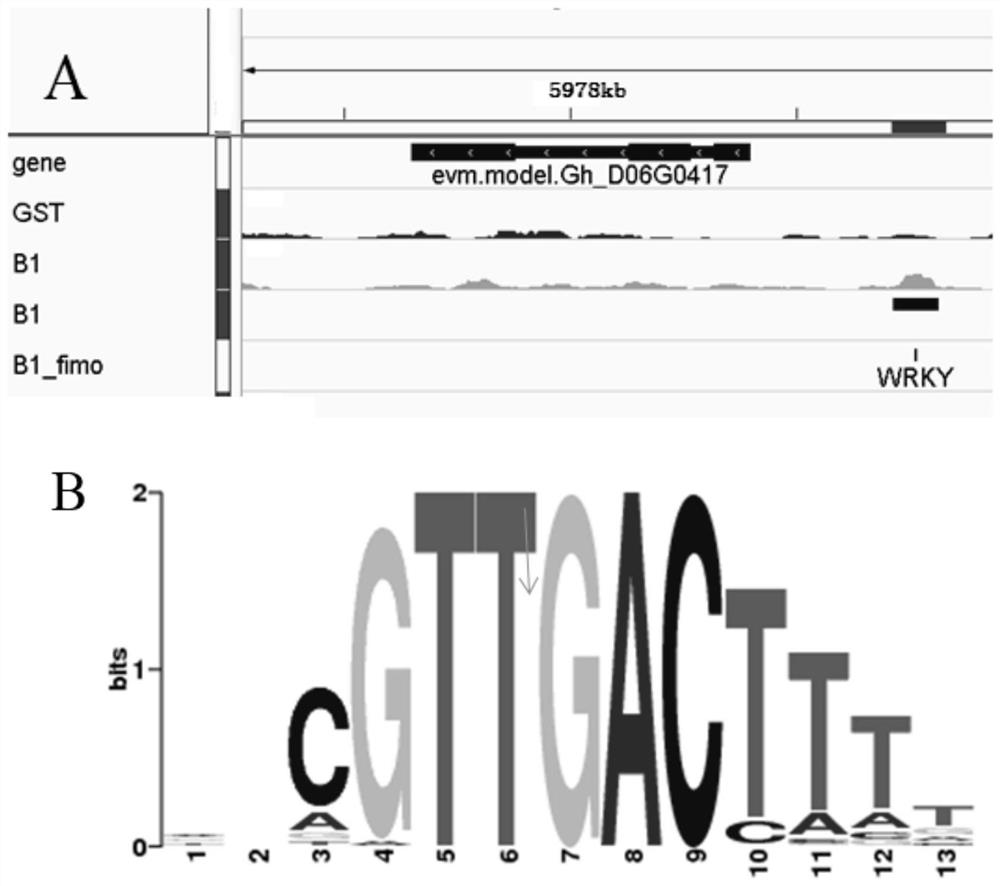
2、利用GEM v3.4软件,以GST的读序作为负对照,控制背景。设置参数--k_min 6--k_max 13--fold 2--outBED识别目标转录因子的特异读序作为DAP的峰值数据。3、利用Popera软件进行峰值鉴定,最后利用BED Tools软件确定正确的peaks位置,针对peaks进行motif分析、peaks下游基因启动子鉴定并与棉花纤维发育时期DHS数据进行交叠绘制韦恩图。三者均有的为该转录因子下游的结合元件,结果见图5,图中,A为igv位点展示图,红色线条(右侧上面短横杆)为棉花纤维发育时期DHS开放的位点,GST棕色线条为GST蛋白测序后与棉花基因组的匹配结果,绿色线条B1为GhWRKY70-GST融合蛋白调取的亲和DNA片段测序后与棉花基因组的匹配结果,蓝色线条(右侧下面短横杆)为识别出可以作为结合位点peak。B为A中蓝色线条位点的功能元件序列CGTTCAC。最后所得到结果与本实验室做的棉花纤维发育DHS图谱相呼应,最终确定的了棉花GhWRKY70可以结合在GhNAC基因上游的启动子区CGTTCAC的位置,进而调控GhNAC基因的表达。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明做其它形式的限制,任何本领域技术人员可以利用上述公开的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
序列表
<110> 安阳工学院
郑州大学
<120> 一种利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法
<160> 5
<170> SIPOSequenceListing 1.0
<210> 1
<211> 828
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
atggatactc tttatccatg gcctgaacct gaaacactat caagcaacaa gaaaagggta 60
atacaaaaac ttgtggaagg tcaacagtgt gctactgagc ttcaagttat tgtactccac 120
aacaacaagc cccctcaaca agctgaggag cttgtgcaaa agatcttgtg gtcatttaat 180
cagacacttt ctatgctagc tgaagctggt catcatgatg aagtgatttc ccagaatcag 240
gcaacttgta atgatgattg taagtctcaa gattctagtg agagcagcaa gagatcactt 300
tcagcattcg ttaaggataa gaggggctgt tacaagagaa agaggtttgc tcaaacaaag 360
atagtggtgt ctgataaaat agaagatggg catgcatgga gaaaatatgg acaaaaaaat 420
atcttacatt ctaaacatcc aaggagttac ttcaggtgca gtcacaagca tgatcaaggc 480
tgtagtgcta tcaaacaagt tcaaagaatg gaagatgatg cccaaatgta ccacatcaca 540
tacattggta cccacacttg cagagaccag tactcatcca tggctacacc acgaatcgac 600
agtccgagtc cgatattaaa actcgaatcc gaggaacaag cgacgacacc aagcaatgtt 660
acggatttgg attcgatgac catgtggacg gatgtaatga tgggtggtgt tggttttgaa 720
actgatgtgg tgtccaacat gtattcatgc actgaaatca cttgtctgga tttagaacct 780
gttgagcttg aaaatggttt gctgtttgat gacactgatt ttgcttag 828
<210> 2
<211> 6
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atcacg 6
<210> 3
<211> 58
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
aatgatacgg cgaccaccga gatctacact ctttccctac acgacgctct tccgatct 58
<210> 4
<211> 63
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gatcggaaga gcacacgtct gaactccagt cacatcacga tctcgtatgc cgtcttctgc 60
ttg 63
<210> 5
<211> 5789
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
acgttatcga ctgcacggtg caccaatgct tctggcgtca ggcagccatc ggaagctgtg 60
gtatggctgt gcaggtcgta aatcactgca taattcgtgt cgctcaaggc gcactcccgt 120
tctggataat gttttttgcg ccgacatcat aacggttctg gcaaatattc tgaaatgagc 180
tgttgacaat taatcatcgg ctcgtataat gtgtggaatt gtgagcggat aacaatttca 240
cacaggaaac agtattcatg tcccctatac taggttattg gaaaattaag ggccttgtgc 300
aacccactcg acttcttttg gaatatcttg aagaaaaata tgaagagcat ttgtatgagc 360
gcgatgaagg tgataaatgg cgaaacaaaa agtttgaatt gggtttggag tttcccaatc 420
ttccttatta tattgatggt gatgttaaat taacacagtc tatggccatc atacgttata 480
tagctgacaa gcacaacatg ttgggtggtt gtccaaaaga gcgtgcagag atttcaatgc 540
ttgaaggagc ggttttggat attagatacg gtgtttcgag aattgcatat agtaaagact 600
ttgaaactct caaagttgat tttcttagca agctacctga aatgctgaaa atgttcgaag 660
atcgtttatg tcataaaaca tatttaaatg gtgatcatgt aacccatcct gacttcatgt 720
tgtatgacgc tcttgatgtt gttttataca tggacccaat gtgcctggat gcgttcccaa 780
aattagtttg ttttaaaaaa cgtattgaag ctatcccaca aattgataag tacttgaaat 840
ccagcaagta tatagcatgg cctttgcagg gctggcaagc cacgtttggt ggtggcgacc 900
atcctccaaa atcggatctg gttccgcgtg gatccccgga attcccgggt atggatactc 960
tttatccatg gcctgaacct gaaacactat caagcaacaa gaaaagggta atacaaaaac 1020
ttgtggaagg tcaacagtgt gctactgagc ttcaagttat tgtactccac aacaacaagc 1080
cccctcaaca agctgaggag cttgtgcaaa agatcttgtg gtcatttaat cagacacttt 1140
ctatgctagc tgaagctggt catcatgatg aagtgatttc ccagaatcag gcaacttgta 1200
atgatgattg taagtctcaa gattctagtg agagcagcaa gagatcactt tcagcattcg 1260
ttaaggataa gaggggctgt tacaagagaa agaggtttgc tcaaacaaag atagtggtgt 1320
ctgataaaat agaagatggg catgcatgga gaaaatatgg acaaaaaaat atcttacatt 1380
ctaaacatcc aaggagttac ttcaggtgca gtcacaagca tgatcaaggc tgtagtgcta 1440
tcaaacaagt tcaaagaatg gaagatgatg cccaaatgta ccacatcaca tacattggta 1500
cccacacttg cagagaccag tactcatcca tggctacacc acgaatcgac agtccgagtc 1560
cgatattaaa actcgaatcc gaggaacaag cgacgacacc aagcaatgtt acggatttgg 1620
attcgatgac catgtggacg gatgtaatga tgggtggtgt tggttttgaa actgatgtgg 1680
tgtccaacat gtattcatgc actgaaatca cttgtctgga tttagaacct gttgagcttg 1740
aaaatggttt gctgtttgat gacactgatt ttgcttaggc ggccgcatcg tgactgactg 1800
acgatctgcc tcgcgcgttt cggtgatgac ggtgaaaacc tctgacacat gcagctcccg 1860
gagacggtca cagcttgtct gtaagcggat gccgggagca gacaagcccg tcagggcgcg 1920
tcagcgggtg ttggcgggtg tcggggcgca gccatgaccc agtcacgtag cgatagcgga 1980
gtgtataatt cttgaagacg aaagggcctc gtgatacgcc tatttttata ggttaatgtc 2040
atgataataa tggtttctta gacgtcaggt ggcacttttc ggggaaatgt gcgcggaacc 2100
cctatttgtt tatttttcta aatacattca aatatgtatc cgctcatgag acaataaccc 2160
tgataaatgc ttcaataata ttgaaaaagg aagagtatga gtattcaaca tttccgtgtc 2220
gcccttattc ccttttttgc ggcattttgc cttcctgttt ttgctcaccc agaaacgctg 2280
gtgaaagtaa aagatgctga agatcagttg ggtgcacgag tgggttacat cgaactggat 2340
ctcaacagcg gtaagatcct tgagagtttt cgccccgaag aacgttttcc aatgatgagc 2400
acttttaaag ttctgctatg tggcgcggta ttatcccgtg ttgacgccgg gcaagagcaa 2460
ctcggtcgcc gcatacacta ttctcagaat gacttggttg agtactcacc agtcacagaa 2520
aagcatctta cggatggcat gacagtaaga gaattatgca gtgctgccat aaccatgagt 2580
gataacactg cggccaactt acttctgaca acgatcggag gaccgaagga gctaaccgct 2640
tttttgcaca acatggggga tcatgtaact cgccttgatc gttgggaacc ggagctgaat 2700
gaagccatac caaacgacga gcgtgacacc acgatgcctg cagcaatggc aacaacgttg 2760
cgcaaactat taactggcga actacttact ctagcttccc ggcaacaatt aatagactgg 2820
atggaggcgg ataaagttgc aggaccactt ctgcgctcgg cccttccggc tggctggttt 2880
attgctgata aatctggagc cggtgagcgt gggtctcgcg gtatcattgc agcactgggg 2940
ccagatggta agccctcccg tatcgtagtt atctacacga cggggagtca ggcaactatg 3000
gatgaacgaa atagacagat cgctgagata ggtgcctcac tgattaagca ttggtaactg 3060
tcagaccaag tttactcata tatactttag attgatttaa aacttcattt ttaatttaaa 3120
aggatctagg tgaagatcct ttttgataat ctcatgacca aaatccctta acgtgagttt 3180
tcgttccact gagcgtcaga ccccgtagaa aagatcaaag gatcttcttg agatcctttt 3240
tttctgcgcg taatctgctg cttgcaaaca aaaaaaccac cgctaccagc ggtggtttgt 3300
ttgccggatc aagagctacc aactcttttt ccgaaggtaa ctggcttcag cagagcgcag 3360
ataccaaata ctgtccttct agtgtagccg tagttaggcc accacttcaa gaactctgta 3420
gcaccgccta catacctcgc tctgctaatc ctgttaccag tggctgctgc cagtggcgat 3480
aagtcgtgtc ttaccgggtt ggactcaaga cgatagttac cggataaggc gcagcggtcg 3540
ggctgaacgg ggggttcgtg cacacagccc agcttggagc gaacgaccta caccgaactg 3600
agatacctac agcgtgagct atgagaaagc gccacgcttc ccgaagggag aaaggcggac 3660
aggtatccgg taagcggcag ggtcggaaca ggagagcgca cgagggagct tccaggggga 3720
aacgcctggt atctttatag tcctgtcggg tttcgccacc tctgacttga gcgtcgattt 3780
ttgtgatgct cgtcaggggg gcggagccta tggaaaaacg ccagcaacgc ggccttttta 3840
cggttcctgg ccttttgctg gccttttgct cacatgttct ttcctgcgtt atcccctgat 3900
tctgtggata accgtattac cgcctttgag tgagctgata ccgctcgccg cagccgaacg 3960
accgagcgca gcgagtcagt gagcgaggaa gcggaagagc gcctgatgcg gtattttctc 4020
cttacgcatc tgtgcggtat ttcacaccgc ataaattccg acaccatcga atggtgcaaa 4080
acctttcgcg gtatggcatg atagcgcccg gaagagagtc aattcagggt ggtgaatgtg 4140
aaaccagtaa cgttatacga tgtcgcagag tatgccggtg tctcttatca gaccgtttcc 4200
cgcgtggtga accaggccag ccacgtttct gcgaaaacgc gggaaaaagt ggaagcggcg 4260
atggcggagc tgaattacat tcccaaccgc gtggcacaac aactggcggg caaacagtcg 4320
ttgctgattg gcgttgccac ctccagtctg gccctgcacg cgccgtcgca aattgtcgcg 4380
gcgattaaat ctcgcgccga tcaactgggt gccagcgtgg tggtgtcgat ggtagaacga 4440
agcggcgtcg aagcctgtaa agcggcggtg cacaatcttc tcgcgcaacg cgtcagtggg 4500
ctgatcatta actatccgct ggatgaccag gatgccattg ctgtggaagc tgcctgcact 4560
aatgttccgg cgttatttct tgatgtctct gaccagacac ccatcaacag tattattttc 4620
tcccatgaag acggtacgcg actgggcgtg gagcatctgg tcgcattggg tcaccagcaa 4680
atcgcgctgt tagcgggccc attaagttct gtctcggcgc gtctgcgtct ggctggctgg 4740
cataaatatc tcactcgcaa tcaaattcag ccgatagcgg aacgggaagg cgactggagt 4800
gccatgtccg gttttcaaca aaccatgcaa atgctgaatg agggcatcgt tcccactgcg 4860
atgctggttg ccaacgatca gatggcgctg ggcgcaatgc gcgccattac cgagtccggg 4920
ctgcgcgttg gtgcggatat ctcggtagtg ggatacgacg ataccgaaga cagctcatgt 4980
tatatcccgc cgttaaccac catcaaacag gattttcgcc tgctggggca aaccagcgtg 5040
gaccgcttgc tgcaactctc tcagggccag gcggtgaagg gcaatcagct gttgcccgtc 5100
tcactggtga aaagaaaaac caccctggcg cccaatacgc aaaccgcctc tccccgcgcg 5160
ttggccgatt cattaatgca gctggcacga caggtttccc gactggaaag cgggcagtga 5220
gcgcaacgca attaatgtga gttagctcac tcattaggca ccccaggctt tacactttat 5280
gcttccggct cgtatgttgt gtggaattgt gagcggataa caatttcaca caggaaacag 5340
ctatgaccat gattacggat tcactggccg tcgttttaca acgtcgtgac tgggaaaacc 5400
ctggcgttac ccaacttaat cgccttgcag cacatccccc tttcgccagc tggcgtaata 5460
gcgaagaggc ccgcaccgat cgcccttccc aacagttgcg cagcctgaat ggcgaatggc 5520
gctttgcctg gtttccggca ccagaagcgg tgccggaaag ctggctggag tgcgatcttc 5580
ctgaggccga tactgtcgtc gtcccctcaa actggcagat gcacggttac gatgcgccca 5640
tctacaccaa cgtaacctat cccattacgg tcaatccgcc gtttgttccc acggagaatc 5700
cgacgggttg ttactcgctc acatttaatg ttgatgaaag ctggctacag gaaggccaga 5760
cgcgaattat ttttgatggc gttggaatt 5789
- 一种利用DNA亲和蛋白测序鉴定棉花纤维发育时期转录因子结合元件的方法
- 一种利用RFLP鉴定蛋白与DNA结合互作的方法