一种基于张量分解的知识推理方法、装置、设备
文献发布时间:2023-06-19 11:39:06
技术领域
本申请实施例涉及数据处理技术领域,具体而言,涉及一种基于张量分解 的知识推理方法、装置、设备。
背景技术
近年来,知识推理任务是一项较为重要的研究任务,在知识图谱补全、搜 索系统、问答系统以及推荐系统中都有重要的作用。现有技术中,主要是通过 对知识图谱进行三元组建模,完成对三元组中缺失实体的推理预测,同时为了 表达出知识的时序性,研究人员在静态知识推理方法的基础上将时序信息和实 体或关系进行关联,以进行时序知识推理工作。
现有技术中在进行知识推理工作时,依赖于静态知识图谱,而静态知识图 谱中有一部分的知识的时效性会随时间发生改变,即它只在某一个时间段内或 者某个时间节点有效,而现有技术中进行推理工作时假设知识图谱中的知识一 直是正确的,忽略了对推理知识至关重要的知识的有效时间范围,因此导致推 理的准确率较低。
发明内容
本申请实施例提供一种基于张量分解的知识推理方法、装置、设备,旨在 提高时序知识推理任务的准确率。
本申请实施例第一方面提供一种基于张量分解的知识推理方法,所述方法 包括:
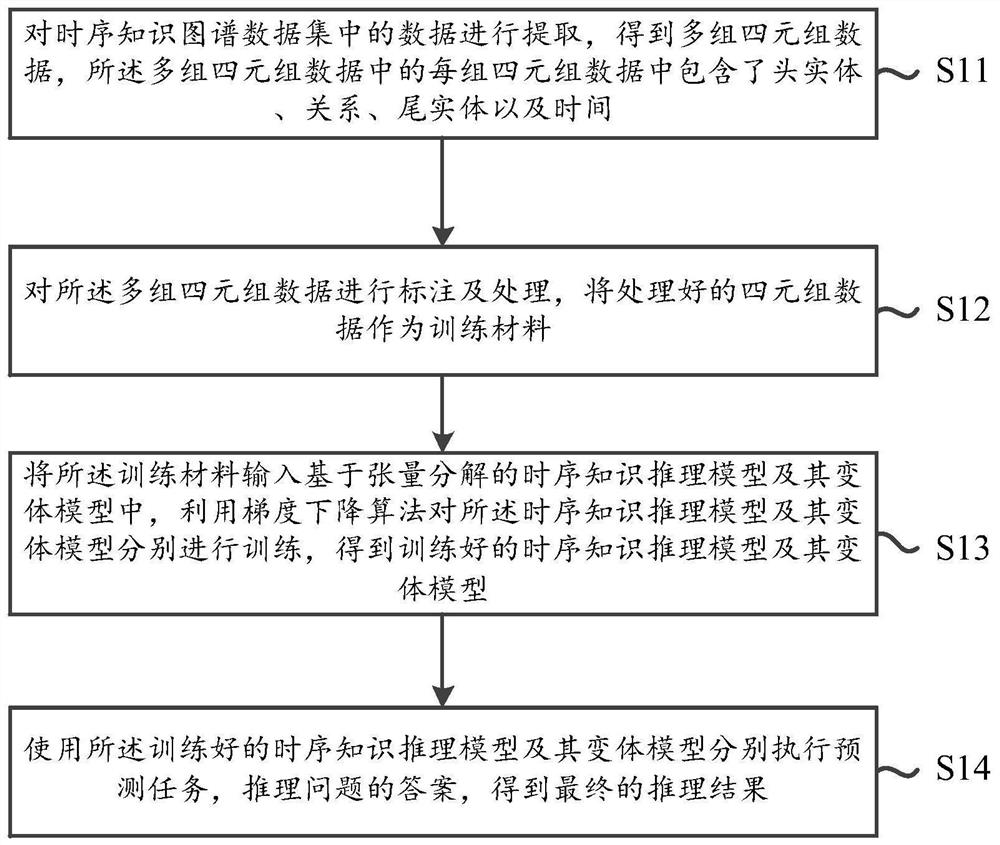
对时序知识图谱数据集中的数据进行提取,得到多组四元组数据,所述多 组四元组数据中的每组四元组数据中包含了头实体、关系、尾实体以及时间;
对所述多组四元组数据进行标注及处理,将处理好的四元组数据作为训练 材料;
将所述训练材料输入基于张量分解的时序知识推理模型及其变体模型中, 利用梯度下降算法对所述时序知识推理模型及其变体模型分别进行训练,得到 训练好的时序知识推理模型及其变体模型;
使用所述训练好的时序知识推理模型及其变体模型分别执行预测任务,推 理问题的答案,得到最终的推理结果。
可选地,对时序知识图谱数据集中的数据进行提取,得到多个四元组数据, 包括:
对所述时序知识图谱数据集中的实体集、关系集以及时间集进行提取;
由所述实体集、关系集以及时间集组成所述多组四元组数据,所述多组四 元组数据中的每组四元组数据为:头实体,关系,尾实体,时间;
为所述多组四元组数据中的每组四元组数据增加其逆关系的四元组数据, 其中,所述逆关系的四元组数据为:尾实体,关系
可选地,对所述多组四元组数据进行标注及处理,将处理好的四元组数据 作为训练材料,包括:
将所述多组四元组数据中的每组四元组数据及其逆关系的四元组数据中 的任一元素进行标注,作为标签元素;
将所述多组四元组数据中的每组四元组数据及其逆关系的四元组数据中 的头实体、时序关系、尾实体和时序信息进行初始化表示;
计算所述多组四元组数据中的每组四元组数据及其逆关系的四元组数据 中的核心张量以及非时序关系,将所述核心张量以及非时序关系进行初始化表 示,得到处理好的四元组数据。
可选地,将所述训练材料输入基于张量分解的时序知识推理模型及其变体 模型中,利用梯度下降算法对所述时序知识推理模型及其变体模型分别进行训 练,得到训练好的时序知识推理模型及其变体模型,所述基于张量分解的时序 知识推理模型及其变体模型的构建及训练过程包括:
对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进而得到所 述时序知识推理模型及其变体模型的初始形式;
将所述时序知识推理模型及其变体模型中的时序信息与关系进行关联表 达出三元组的时序性,得到所述时序知识推理模型及其变体模型的最终形式;
根据目标函数对所述时序知识推理模型及其变体模型分别进行训练,得到 所述训练好的时序知识推理模型及其变体模型。
可选地,对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进 而得到所述时序知识推理模型及其变体模型的初始形式,是按照以下公式实现 的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理 模型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是 non-temporal(非时序信息)的缩写,
可选地,其特征在于将所述时序知识推理模型及其变体模型中的时序信 息与关系进行关联表达出三元组的时序性,得到所述时序知识推理模型及其 变体模型的最终形式,是按照以下公式实现的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推 理模型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是 non-temporal(非时序信息)的缩写,
可选地,根据目标函数对所述时序知识推理模型及其变体模型分别进行 训练,得到所述训练好的时序知识推理模型及其变体模型,所述目标函数为:
其中,(s,r,o,t)为正样本,(s,r,o′,t)为负样本,
可选地,使用所述训练好的时序知识推理模型及其变体模型分别执行 预测任务,推理问题的答案,得到最终的推理结果,包括:
将需要进行推理的四元组数据分别输入训练好的时序知识推理模型及 其变体模型中,所述需要进行推理的四元组数据中的任意一项元素是未知 的;
将时序知识图谱中的备选结果带入所述时序知识推理模型及其变体模 型进行评分,选取分数最高的候选结果作为所述最终的推理结果。
本申请实施例第二方面提供一种基于张量分解的知识推理装置,所述装置 包括:
四元组数据提取模块,用于对时序知识图谱数据集中的数据进行提取,得 到多组四元组数据,所述多组四元组数据中的每组四元组数据中包含了头实 体、关系、尾实体以及时间;
数据处理模块,用于对所述多组四元组数据进行标注及处理,将处理好的 四元组数据作为训练材料;
模型训练模块,用于将所述训练材料输入基于张量分解的时序知识推理模 型及其变体模型中,利用梯度下降算法对所述时序知识推理模型及其变体模型 分别进行训练,得到训练好的时序知识推理模型及其变体模型;
推理任务执行模块,用于使用所述训练好的时序知识推理模型及其变体模 型分别执行预测任务,推理问题的答案,得到最终的推理结果。
可选地,所述四元组数据提取模块包括:
数据提取子模块,用于对所述时序知识图谱数据集中的实体集、关系集以 及时间集进行提取;
四元组数据组成子模块,用于由所述实体集、关系集以及时间集组成所述 多组四元组数据,所述多组四元组数据中的每组四元组数据为:头实体,关系, 尾实体,时间;
逆关系添加子模块,用于为所述多组四元组数据中的每组四元组数据增加 其逆关系的四元组数据,其中,所述逆关系的四元组数据为:尾实体,关系
可选地,所述数据处理模块包括:
数据标注子模块,用于将所述多组四元组数据中的每组四元组数据及其逆 关系的四元组数据中的任一元素进行标注,作为标签元素;
第一初始化表示子模块,用于将所述多组四元组数据中的每组四元组数据 及其逆关系的四元组数据中的头实体、时序关系、尾实体和时序信息进行初始 化表示;
第二初始化表示子模块,用于计算所述多组四元组数据中的每组四元组数 据及其逆关系的四元组数据中的核心张量以及非时序关系,将所述核心张量以 及非时序关系进行初始化表示,得到处理好的四元组数据。
可选地,将所述训练材料输入基于张量分解的时序知识推理模型及其变体 模型中,利用梯度下降算法对所述时序知识推理模型及其变体模型分别进行训 练,得到训练好的时序知识推理模型及其变体模型,所述基于张量分解的时序 知识推理模型及其变体模型的构建及训练过程包括:
对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进而得到所 述时序知识推理模型及其变体模型的初始形式;
将所述时序知识推理模型及其变体模型中的时序信息与关系进行关联表 达出三元组的时序性,得到所述时序知识推理模型及其变体模型的最终形式;
根据目标函数对所述时序知识推理模型及其变体模型分别进行训练,得到 所述训练好的时序知识推理模型及其变体模型。
可选地,对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进 而得到所述时序知识推理模型及其变体模型的初始形式,是按照以下公式实现 的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理模 型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是non-temporal (非时序信息)的缩写,
可选地,将所述时序知识推理模型及其变体模型中的时序信息与关系进 行关联表达出三元组的时序性,得到所述时序知识推理模型及其变体模型的 最终形式,是按照以下公式实现的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理模 型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是non-temporal (非时序信息)的缩写,
可选地,根据目标函数对所述时序知识推理模型及其变体模型分别进行 训练,得到所述训练好的时序知识推理模型及其变体模型,所述目标函数为:
其中,(s,r,o,t)为正样本,(s,r,o′,t)为负样本,
可选地,所述推理任务执行模块包括:
四元组数据输入子模块,用于将需要进行推理的四元组数据分别输入 训练好的时序知识推理模型及其变体模型中,所述需要进行推理的四元组 数据中的任意一项元素是未知的;
结果获得子模块,用于将时序知识图谱中的备选结果带入所述时序知 识推理模型及其变体模型进行评分,选取分数最高的候选结果作为所述最 终的推理结果。
本申请实施例第三方面提供一种电子设备,包括存储器、处理器及存储在 存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序 时,实现本申请第一方面所述的方法的步骤。
采用本申请提供的基于张量分解的知识推理方法,首先对时序知识图谱数 据集中数据进行提取,得到多组四元组数据,其中每组四元组数据中包含了头 实体、关系、尾实体以及时间,对这多组四元组数据进行标注及处理,得到处 理好的四元组数据,将处理好的四元组数据作为训练材料输入基于张量分解的 时序知识推理模型及其变体模型中,利用梯度下降算法对时序知识推理模型及 其变体模型分别进行训练,得到训练好的时序知识推理模型及其变体模型,使 用训练好的时序知识推理模型及其变体模型分别执行预测任务,推理问题的答 案,得到最终的推理结果。本申请中从知识图谱数据集中提取出了四元组数据, 利用四元组数据训练时序知识推理模型及其变体模型,以实现时序知识推理任务,本申请提出了时序知识推理模型及其变体模型,可以适应不同情况下的时 序知识推理任务,另外本申请提出的推理模型及其变体模型够早了时序光滑约 束和正则化项,使得模型具有了较强的表达能力且可避免模型过拟合,从而提 高模型对四元组的辨别能力,进而提升了时序知识推理任务的准确率。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例的描 述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是 本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性 的前提下,还可以根据这些附图获得其他的附图。
图1是本申请一实施例提出的一种基于张量分解的知识推理方法的流程 图;
图2是本申请一实施例提出的模型评分结果图;
图3是本申请一实施例提出的一种基于张量分解的知识推理装置的示意 图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清 楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部 的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳 动前提下所获得的所有其他实施例,都属于本申请保护的范围。
参考图1,图1是本申请一实施例提出的基于张量分解的知识推理方法的 流程图。如图1所示,该方法包括以下步骤:
S11:对时序知识图谱数据集中的数据进行提取,得到多组四元组数据, 所述多组四元组数据中的每组四元组数据中包含了头实体、关系、尾实体以及 时间。
本实施例中,知识图谱是将各种知识通过可视化图谱展示出来的一种方 式,知识图谱中包含了各种实体和实体之间的关系,时序知识图谱中还包含了 各个实体与关系对应的时间信息,时序知识图谱数据集就是时序知识图谱中包 含的数据的集合。
本实施例中,对时序知识图谱数据集中的数据进行提取,得到多组四元组 数据,所述多组四元组数据中的每组四元组数据中包含了头实体、关系、尾实 体以及时间的具体步骤为:
S11-1:对所述时序知识图谱数据集中的实体集、关系集以及时间集进行 提取。
本实施例中,时序知识图谱数据集中包含了实体集、关系集以及时间集, 实体集中包含了各个命名实体,关系集中包含了各个命名实体之间的关系,时 间集中包含了与各个命名实体,关系对应的时间信息。根据知识图谱中表示出 的各个实体之间的关系以及其对应的时间,从实体集、关系集以及时间集中提 取出相应的实体,关系以及对应的时间。
示例地,实体可以是地名、人名、职业、身份等,关系可以是从属关系、 亲属关系、位置关系等,时间可以是一个年份,也可以具体到月份,具体到谋 日甚至某个时刻,可以自行设定。
S11-2:由所述实体集、关系集以及时间集组成所述多组四元组数据,所 述多组四元组数据中的每组四元组数据为:头实体,关系,尾实体,时间。
本实施例中,实体,关系以及时间可以组成多组四元组数据,四元组数据 的结构是(头实体,关系,尾实体,时间),这多组四元组数据是根据时序知 识图谱中的信息进行组合的。
示例地,时序知识图谱中有显示了2008年至2016年之间阳光中学的校长 是张三,则可通过该知识得到四元组数据(张三,校长,阳光中学,2008-2016)。
S11-3:为所述多组四元组数据中的每组四元组数据增加其逆关系的四元 组数据,其中,所述逆关系的四元组数据为:尾实体,关系
本实施例中,关系
示例地,若原四元组数据为(李梅,领导,王东,2010-2013),该四元 组数据的逆关系的四元组数据为(王东,被领导,李梅,2010-2013)。
S12:对所述多组四元组数据进行标注及处理,将处理好的四元组数据作 为训练材料。
本实施例中,对提取到的四元组数据进行预处理的具体步骤为:
S12-1:将所述多组四元组数据中的每组四元组数据及其逆关系的四元组 数据中的任一元素进行标注,作为标签元素。
本实施例中,需要对四元组数据及其逆关系的四元组数据中的任一元素进 行标注,标注方式可以自行设定,被标注的元素成为标签元素。四元组数据中 的头实体、关系、尾实体、时间都可以作为标签元素。
示例地,可以将四元组数据标注为(头实体,关系,尾实体*,时间), 这个四元组数据中的尾实体就是标签元素。
S12-2:将所述多组四元组数据中的每组四元组数据及其逆关系的四元组 数据中的头实体、时序关系、尾实体和时序信息进行初始化表示。
本实施例中,初始化表示,就是将这些数据转化为向量的形式,这样就可 以输入模型中,对模型进训练。时序关系是会随着时间变化的关系,例如一个 人不同时期的职业,一个国家不同时期的领导人等。时序信息是就是各个实体 和关系对应的时间信息。
S12-3:计算所述多组四元组数据中的每组四元组数据及其逆关系的四元 组数据中的核心张量以及非时序关系,将所述核心张量以及非时序关系进行初 始化表示,得到处理好的四元组数据。
本实施例中,核心张量具体来说是核心张量参数,每一组四元组数据都有 一个核心张量参数,不同的四元组数据的核心张量参数是不同的。非时序关系 是不随着时间变化而改变的关系。
示例地,核心张量参数可以使用Tucker分解进行计算,Tucker分解是一 种常用的张量分解方法,分解出的核心张量参数可记为
S13:将所述训练材料输入基于张量分解的时序知识推理模型及其变体模 型中,利用梯度下降算法对所述时序知识推理模型及其变体模型分别进行训 练,得到训练好的时序知识推理模型及其变体模型。
本实施例中,将所述训练材料输入基于张量分解的时序知识推理模型及其 变体模型中,利用梯度下降算法对所述时序知识推理模型及其变体模型分别进 行训练,得到训练好的时序知识推理模型及其变体模型的具体步骤为:
S13-1:对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进 而得到所述时序知识推理模型及其变体模型的初始形式。
本实施例中,Tucker分解是一种常用的张量分解方法,对Tucker分解进 行扩展,得到对时序四元组的Tucker分解,进而得到所述时序知识推理模型 及其变体模型的初始形式是按照以下公式实现的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理 模型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是 non-temporal(非时序信息)的缩写,
本实施例中,该公式的具体推导步骤为:
首先在普通的Tucker分解中加入时序信息以进行扩展,得到对时序四元 组的Tucker分解,可以表示为:
其中E代表实体,R代表关系,T代表时间信息。
进而根据该式得到推理模型的具体形式,即TuckerT模型:
时序知识图谱中除了时序知识以外,可能还有部分静态知识即非时序信 息,为了将这些静态知识融入模型中,可在对时序四元组的Tucker分解中 加入静态知识,可表示为:
其中,1代表非时序信息。
进而根据该式得到变体模型TuckerTNT的具体形式:
S13-2:将所述时序知识推理模型及其变体模型中的时序信息与关系进行 关联表达出三元组的时序性,得到所述时序知识推理模型及其变体模型的最终 形式。
本实施例中,四元组中的实体和关系都包含着时序信息,因此将具有时序 性的关系可以分解成关系和时序信息,或将具有时序性的实体分解成实体和时 序信息,具体可以表示为:
其中
因此,在具体的实施过程中,采用分解的逆过程,将时序信息与实体或关 系关联来表达出四元组的时序性,及推理模型及变体模型的最终形式:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推 理模型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是 non-temporal(非时序信息)的缩写,
S13-3:根据目标函数对所述时序知识推理模型及其变体模型分别进行训 练,得到所述训练好的时序知识推理模型及其变体模型。
本实施例中,根据目标函数对所述时序知识推理模型及其变体模型分别 进行训练,得到所述训练好的时序知识推理模型及其变体模型,所述目标函 数为:
其中,(s,r,o,t)为正样本,(s,r,o′,t)为负样本,
本目标函数中包含有四元组的分数函数,用于为模型识别四元组的结果 进行打分,还包括了对时序信息的光滑约束,还包括了对实体、关系和时序信 息施加的正则化约束。
其中,四元组的分数函数为:
其中,
时序信息光滑约束表示为:
其中,
本实施例中,相邻的时间节点具有相似的浅层表示,通过对时序信息施 加光滑约束,可以保证模型的稳定性,提高模型的识别准确率。
正则化约束函数为:
其中,
本实施例中,在分解出的实体、关系和时序信息上施加正则化约束,可以 避免过拟合的发生。
S14:使用所述训练好的时序知识推理模型及其变体模型分别执行预测任 务,推理问题的答案,得到最终的推理结果。
本实施例中,得到S13中训练好的时序知识推理模型及其变体模型之后, 就可以使用这两个模型执行预测任务,具体的步骤是:
S13-1:将需要进行推理的四元组数据分别输入训练好的时序知识推理 模型及其变体模型中,所述需要进行推理的四元组数据中的任意一项元素 是未知的。
本实施例中,将缺失了任意一项元素的四元组数据输入到训练好的时 序知识推理模型及其变体模型中,即可进行推理任务。
示例地,当训练数据中的四元组数据为(头实体,关系,尾实体*,时 间)时,可以见得,尾实体上有标注,为标签数据,利用该类型的四元组 数据训练好了时序知识推理模型及其变体模型之后,输入新的四元组数据 (头实体,关系,x,时间),此时时序知识推理模型及其变体模型就可以 推理出x代表的元素内容。
S13-2:将时序知识图谱中的备选结果带入所述时序知识推理模型及其 变体模型进行评分,选取分数最高的候选结果作为所述最终的推理结果。
本实施例中,在输入需要预测结果的四元组数据时,训练好的时序知 识推理模型及其变体模型会根据四元组数据的信息从时序知识图谱中获得 备选的结果,对这些备选结果进行打分,得到最终的推理结果。
示例地,输入(阳光中学,校长,x,2008-2016),上述模型从时序知识 图谱中得到了两个备选结果:张三,李四,上述模型对这两个候选结果进行打 分,张三的得分较高,则可以根据头实体,关系和时间推理出x为张三。上述 模型可以根据训练中标注的元素不同而推理新输入四元组数据中不同的元素。 例如将头实体标注为标签元素,就可推理出四元组数据中缺失的头实体。
本实施例的另一个方面中,在训练好了时序知识推理模型及其变体模型之 后,可以评价两个模型的推理性能。
具体的,利用MRR和Hits@n,n=1,3,10来评价模型的推理性能,MRR和 Hits@n,n=1,3,10是评价模型性能的方法。
其相应的表达式为:
MRR:
Hits@n:
其中,其中,k
如图2所示,本实施例在ICEWS14和ICEWS05-15两个时序知识图谱数据 集上,进行本发明所提出的模型与现有的知识推理模型De-SimplE和 TNTComplEx的对比实验,结果展示出模型TuckERT和TuckERTNT在时序知识 推理任务上得到的评分都都高于现有的De-SimplE和TNTComplEx模型。
基于同一发明构思,本申请一实施例提供一种基于张量分解的知识推理装 置。参考图3,图3是本申请一实施例提出的基于张量分解的知识推理装置300 的示意图。如图3所示,该装置包括:
四元组数据提取模块301,用于对时序知识图谱数据集中的数据进行提 取,得到多组四元组数据,所述多组四元组数据中的每组四元组数据中包含了 头实体、关系、尾实体以及时间;
数据处理模块302,用于对所述多组四元组数据进行标注及处理,将处理 好的四元组数据作为训练材料;
模型训练模块303,用于将所述训练材料输入基于张量分解的时序知识推 理模型及其变体模型中,利用梯度下降算法对所述时序知识推理模型及其变体 模型分别进行训练,得到训练好的时序知识推理模型及其变体模型;
推理任务执行模块304,用于使用所述训练好的时序知识推理模型及其变 体模型分别执行预测任务,推理问题的答案,得到最终的推理结果。
可选地,所述四元组数据提取模块包括:
数据提取子模块,用于对所述时序知识图谱数据集中的实体集、关系集以 及时间集进行提取;
四元组数据组成子模块,用于由所述实体集、关系集以及时间集组成所述 多组四元组数据,所述多组四元组数据中的每组四元组数据为:头实体,关系, 尾实体,时间;
逆关系添加子模块,用于为所述多组四元组数据中的每组四元组数据增加 其逆关系的四元组数据,其中,所述逆关系的四元组数据为:尾实体,关系
可选地,所述数据处理模块包括:
数据标注子模块,用于将所述多组四元组数据中的每组四元组数据及其逆 关系的四元组数据中的任一元素进行标注,作为标签元素;
第一初始化表示子模块,用于将所述多组四元组数据中的每组四元组数据 及其逆关系的四元组数据中的头实体、时序关系、尾实体和时序信息进行初始 化表示;
第二初始化表示子模块,用于计算所述多组四元组数据中的每组四元组数 据及其逆关系的四元组数据中的核心张量以及非时序关系,将所述核心张量以 及非时序关系进行初始化表示,得到处理好的四元组数据。
可选地,将所述训练材料输入基于张量分解的时序知识推理模型及其变体 模型中,利用梯度下降算法对所述时序知识推理模型及其变体模型分别进行训 练,得到训练好的时序知识推理模型及其变体模型,所述基于张量分解的时序 知识推理模型及其变体模型的构建及训练过程包括:
对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进而得到所 述时序知识推理模型及其变体模型的初始形式;
将所述时序知识推理模型及其变体模型中的时序信息与关系进行关联表 达出三元组的时序性,得到所述时序知识推理模型及其变体模型的最终形式;
根据目标函数对所述时序知识推理模型及其变体模型分别进行训练,得到 所述训练好的时序知识推理模型及其变体模型。
可选地,对Tucker分解进行扩展,得到对时序四元组的Tucker分解,进 而得到所述时序知识推理模型及其变体模型的初始形式,是按照以下公式实现 的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理模 型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是non-temporal (非时序信息)的缩写,
可选地,将所述时序知识推理模型及其变体模型中的时序信息与关系进 行关联表达出三元组的时序性,得到所述时序知识推理模型及其变体模型的 最终形式,是按照以下公式实现的:
TuckERT:
TuckERTNT:
其中,TuckERT表示时序知识推理模型,TuckERTNT表示时序知识推理模 型的变体模型,E表示实体,R表示关系,T表示时间信息,NT是non-temporal 的缩写,表示非时序信息,
可选地,根据目标函数对所述时序知识推理模型及其变体模型分别进行 训练,得到所述训练好的时序知识推理模型及其变体模型,所述目标函数为:
其中,(s,r,o,t)为正样本,(s,r,o′,t)为负样本,
可选地,所述推理任务执行模块包括:
四元组数据输入子模块,用于将需要进行推理的四元组数据分别输入 训练好的时序知识推理模型及其变体模型中,所述需要进行推理的四元组 数据中的任意一项元素是未知的;
结果获得子模块,用于将时序知识图谱中的备选结果带入所述时序知识推 理模型及其变体模型进行评分,选取分数最高的候选结果作为所述最终的推理 结果。
基于同一发明构思,本申请另一实施例提供一种电子设备,包括存储器、 处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行 时实现本申请上述任一实施例所述的一种基于张量分解的知识推理方法中的 步骤。
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简 单,相关之处参见方法实施例的部分说明即可。
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的 都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即 可。
本领域内的技术人员应明白,本申请实施例的实施例可提供为方法、装置、 或计算机程序产品。因此,本申请实施例可采用完全硬件实施例、完全软件实 施例、或结合软件和硬件方面的实施例的形式。而且,本申请实施例可采用在 一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不 限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请实施例是参照根据本申请实施例的方法、终端设备(系统)、和计算 机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现 流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流 程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、 嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得 通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实 现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功 能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终 端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储 器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或 多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备 上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机 实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现 在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能 的步骤。
尽管已描述了本申请实施例的优选实施例,但本领域内的技术人员一旦得 知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附 权利要求意欲解释为包括优选实施例以及落入本申请实施例范围的所有变更 和修改。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅 仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者 暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包 括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括 一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括 没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设 备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的 要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另 外的相同要素。
以上对本申请所提供的一种基于张量分解的知识推理方法、装置、设备, 进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐 述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时, 对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围 上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 一种基于张量分解的知识推理方法、装置、设备
- 一种基于知识图谱的疾病推理方法、装置、设备及储存介质