在Linux系统上实现ARM64位浮点模拟器的方法
文献发布时间:2024-01-17 01:12:29
技术领域
本发明是关于一种在Linux系统上实现ARM64位浮点模拟器的方法。
背景技术
ARM(Advanced RISC Machine)架构广泛地应用于嵌入式系统。ARM针对浮点(floating point)运算的支持包括下列几种:
第一种支持是硬件实现的浮点协处理器(coprocessor)是由编译器将代码直接编译成浮点协处理器可识别的指令,在执行这种指令时,ARM核直接将它交给浮点协处理器去执行。浮点协处理器通常有一组额外寄存器来完成浮点参数传递及运算。新一代的ARM64是ARM架构的64位(64-bit)的扩展(extension),它为了支持浮点运算,添加了浮点协处理器,并定义了浮点指令集,但若缺乏实际的硬件,则指令会被拦截而改由浮点模拟器来执行。
第二种支持是软件实现的软浮点库。软浮点库支持是交叉工具链(crosstoolchain)所提供的功能,而与Linux内核无关。当使用交叉工具链编译浮点操作时,编译器会以内联的软浮点库取代浮点操作,如此生成的机器代码(machine code)完全不含浮点指4EE4,却可正确地完成浮点操作。然而,公知的主流交叉工具链均未提供相应ARM64的软浮点库。
第三种支持是软件实现的浮点模拟器。在早期,ARM并没有协处理器,浮点运算是由软件通过CPU来模拟的,即浮点模拟器,其主要通过未定义指令处理器(undefinedinstruction handler)来实现。然而,它会造成极频繁的异常(exception),因而大幅增加中断延迟,降低系统实时性。此外,公知的Linux内核不支持ARM64位浮点模拟器。
目前,Linux只有ARM32位(32-bit)浮点模拟器,而没有ARM64位浮点模拟器。
一般而言,嵌入式系统都需要进行浮点运算,在公知的Linux内核不支持ARM64位浮点模拟器的情形下,ARM64位浮点协处理器的功能被裁剪,无法进行浮点运算操作,这时,只可将ARM64降级为ARM32来运用。因此,亟须提出一种在Linux系统上实现ARM64的浮点运算的方法,以解决上述问题。
发明内容
有鉴于此,本发明提出一种在Linux系统上实现ARM64位浮点模拟器的方法,其包括:在所述Linux系统上运行ARM64位指令;通过将指令分类器应用至所述ARM64位指令指出的机器代码中的第一特征代码,判断所述ARM64位指令是否为ARM64位浮点指令;以及因应于所述ARM64位指令是ARM64位浮点指令的事件,通过将所述指令分类器应用至所述ARM64位指令指出的所述机器代码中的第二特征代码,识别出所述ARM64位浮点指令为特定ARM64位浮点指令。
可选地,或较佳地,当所述ARM64位指令是所述ARM64位浮点指令时,陷入ARM64位异常,其中在所述陷入所述ARM64位异常时,保存所述ARM64位异常现场并且处理所述ARM64位浮点指令;而在所述处理所述ARM64位浮点指令完成后,退出所述ARM64位异常。
可选地,或较佳地,所述处理所述ARM64位浮点指令还包括:定义浮点寄存器及状态结构体,以保存所述处理所述ARM64位浮点指令的浮点运算过程中的一或多个数据。
可选地,或较佳地,所述指令分类器是配置成根据ARM64针对浮点类指令的编码规则来进行单层解析或逐层解析,以决定所述ARM64位浮点指令的类别及所述特定ARM64位浮点指令。
可选地,或较佳地,所述指令分类器是配置成将所述ARM64位浮点指令表示为二进制表示,共32位,自最高位至最低位依序定义为第31位至第0位。
可选地,或较佳地,所述指令分类器是配置成根据所述ARM64针对浮点类指令的编码规则,定义所述二进制表示的第31位为标签sf,第29位为标签S,第22至23位为标签type,第19至20位为标签rmode,第16至18位为标签opcode,而根据type、rmode或opcode之中的值来决定所述ARM64位浮点指令的所述类别。
可选地,或较佳地,将所述ARM64位浮点指令分类为转换类指令、比较类指令或运算类指令。
可选地,或较佳地,所述逐层解析包括在多次分类的其中一次分类中,将所述标签type作为所述第二特征代码,基于所述标签type进行分类而将所述ARM64位浮点指令分类为转换类指令、比较类指令或运算类指令。
可选地,或较佳地,所述处理所述ARM64位浮点指令还包括:按照所述指令分类器所决定的所述ARM64位浮点指令的类别及所述特定ARM64位浮点指令,分派相应的浮点库函数,来执行所述处理所述ARM64位浮点指令的浮点运算。
可选地,或较佳地,本发明的在Linux系统上实现ARM64位浮点模拟器的方法还包括在所述处理所述ARM64位浮点指令完成后,且在退出所述ARM64位异常前,判断所述下一个ARM64位指令是否为另一个ARM64位浮点指令;若判断所述下一个ARM64位指令仍然是另一个ARM64位浮点指令,则不退出所述ARM64位异常,并处理所述下一个ARM64位指令;若判断所述下一个ARM64位指令不是另一个ARM64位浮点指令,则退出所述ARM64位异常。
下文将配合图式并详细说明,使本发明的其他目的、优点及新颖特征更明显。
附图说明
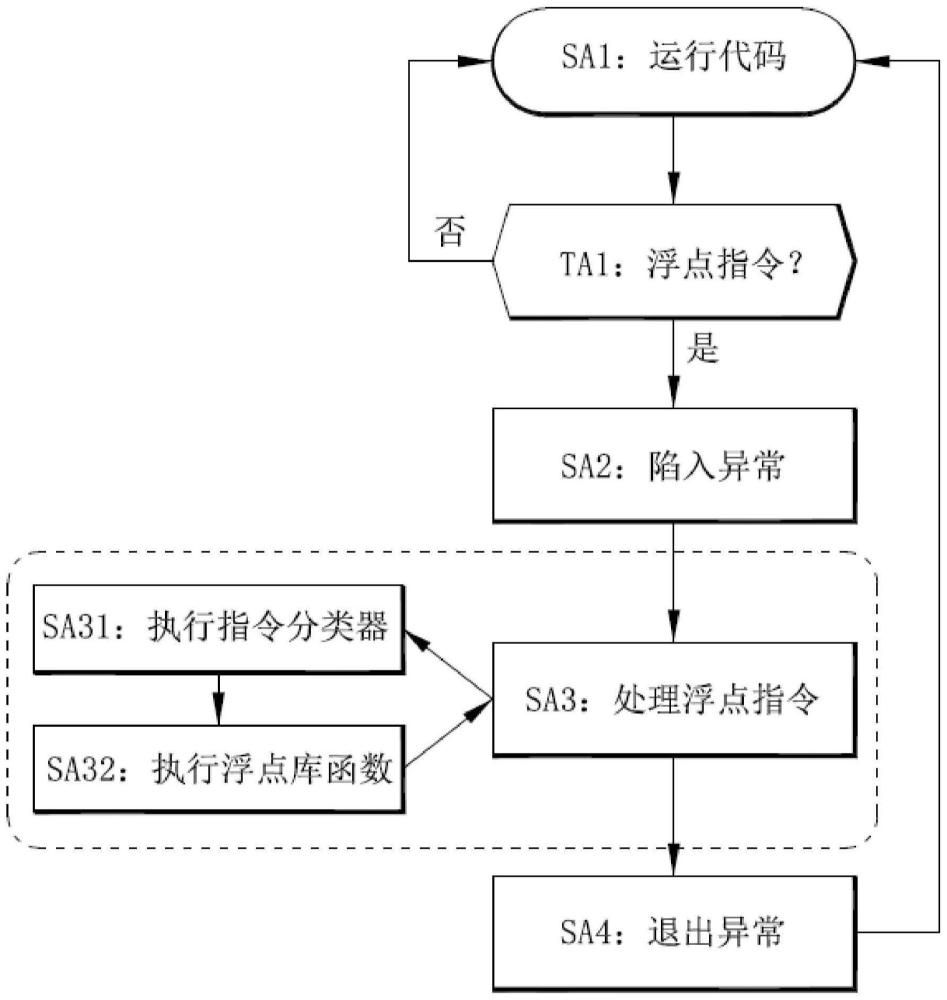
图1显示本发明的一个实施例的在Linux系统上实现ARM64位浮点模拟器的方法的流程图。
图2A、图2B、图2C及图2D显示本发明的指令分类器执行逐层分类的具体例子。
图3显示本发明的另一个实施例的基于SEMI来优化针对ARM64的浮点模拟器的方法的流程图。
【附图标记说明】
SA1-运行代码的步骤;
SA2-陷入ARM64位异常的步骤;
SA3-处理ARM64位浮点指令的步骤;
SA31-执行指令分类器的步骤;
SA32-执行浮点库函数的步骤;
SA4-退出ARM64位异常的步骤;
TA1-判断是否为ARM64位浮点指令的步骤;
TB2-判断下一个指令是否仍然是ARM64位浮点指令的步骤;
SB1-运行代码的步骤;
SB2-陷入ARM64位异常的步骤;
SB3-处理ARM64位浮点指令的步骤;
SB4-退出ARM64位异常的步骤;
TA1-判断是否为ARM64位浮点指令的步骤;
TB1-判断是否为ARM64位浮点指令的步骤;
TB2-判断下一个指令是否仍然是ARM64位浮点指令的步骤。
具体实施方式
以下提供本发明的不同实施例。这些实施例是用于说明本发明的技术内容,而非用于限制本发明的权利范围。一实施例的一特征可通过合适的修饰、置换、组合、分离以应用于其他实施例。
应注意的是,在本文中,除了特别指明者之外,具备“一”组件不限于具备单一的所述组件,而可具备一或更多的所述组件。
此外,在本文中,除了特别指明者之外,“第一”、“第二”等序数,只是用于区别具有相同名称的多个组件,并不表示它们之间存在位阶、层级、执行顺序或制程顺序。一“第一”组件与一“第二”组件可能一起出现在同一构件中,或分别出现在不同构件中。序数较大的一组件的存在不必然表示序数较小的另一组件的存在。
所谓的“包括”、“包含”、“具有”、“含有”,是指包括但不限于此。
一种现有的实现方式是使用浮点协处理器来判断ARM64位指令是否为ARM64位浮点指令,并在确认是ARM64位浮点指令后进行浮点运算。一旦缺少浮点协处理器,就无法进行判断,因而无法进行后续的浮点运算。一种可能的替代方式是使用浮点模拟器。然而,Linux缺少用于ARM架构处理器(ARM64)的浮点模拟器。因此,本发明提出一种方法,能够在缺少浮点协处理器及浮点模拟器的情况下进行浮点的模拟运算。
(在Linux系统上实现ARM64位浮点模拟器的方法)
图1显示本发明的一个实施例的在Linux系统上实现ARM64位浮点模拟器的方法的流程图。本方法可由软件(software)、计算机程序(computer program)、计算机可读存储介质(computer readable storage medium)或计算机程序产品来实现。本方法包括下列步骤:
本方法开始自步骤SA1:在Linux系统上运行低阶代码,例如,机器代码。一个机器代码对应一个汇编代码(assembly code),并且代表一个ARM64位指令。机器代码是基于ARM编码规则而实现,例如是1e220000、52876c81、72a824a1、1e270021、1e212800、1e380000及d65f03c0。上述机器代码对应的汇编代码例如是scvtf、mov、movk、fmov、fadd、fcvtzs及ret。
判断机制TA1是执行指令分类器,以将指令分类器应用至机器代码。指令分类器用于判断运行中的机器代码指出的ARM64位指令是否为ARM64位浮点指令。若判断机制TA1判断运行中的ARM64位指令不是ARM64位浮点指令,则本方法回到步骤SA1以继续执行下一个ARM64位指令。相反地,若判断机制TA1判断运行中的ARM64位指令是ARM64位浮点指令,则本方法须先保存ARM64位异常现场,并进入步骤SA2。
步骤SA2为陷入ARM64位异常。值得注意的是,异常的情形有很多种,而本发明特别关注ARM64位“未定义指令”异常,因为本发明旨在解决公知的Linux内核不支持ARM64位浮点模拟器所导致的问题。
在步骤SA2后,进入步骤SA3:处理ARM64位浮点指令。在步骤SA3中,可定义浮点寄存器及状态结构体,以保存浮点运算过程中的一或多个数据(例如,中间结果)。步骤SA3可还包括二个子步骤SA31及SA32。
步骤SA31是执行指令分类器。指令分类器是配置成解析ARM64位浮点指令,较佳是根据ARM64针对浮点类指令的编码规则来进行逐层解析,先决定是哪类ARM64位浮点指令,再决定具体是哪个ARM64位浮点指令。
具体而言,每个ARM64位指令可对应唯一一个机器代码。通过指令分类器的逐层匹配,可分辨ARM64位指令是否为ARM64位浮点指令。接着,若分辨ARM64位指令是ARM64位浮点指令,由于所有ARM64位浮点指令都有相应的类别,则指令分类器即可根据指令编码格式来分层分类ARM64位指令;其中,ARM64位浮点指令包括几种类别:第一类是“转换类指令”,包括浮点与定点(fixed point)互转、浮点与整数(integer)互转,但不限于此;第二类是“比较类指令”,包括比较指令与条件比较指令,但不限于此;第三类是“运算类指令”,包括加、减、乘、除、乘加(乘加是指先乘后加,例如,针对四个参数Rd、Rn、Rm、Ra,FMADD Rd,Rn,Rm,Ra这个指令是进行Rd=Ra+Rn*Rm这样的运算)、乘减(乘减是指先乘后减,例如,针对四个参数Rd、Rn、Rm、Ra,FMSUB Rd,Rn,Rm,Ra这个指令是进行Rd=Ra-Rn*Rm这样的运算),但不限于此。如此,指令分类器即可将ARM64位指令分类,并匹配到具体的唯一一个ARM64位浮点指令。
步骤SA32是执行浮点库函数。由于每个ARM64位浮点指令定义有相应的浮点库函数,通过指令分类器,可按照不同ARM64指令分派(dispatch)不同浮点库函数来执行ARM64位浮点的模拟运算。例如,若须进行浮点转换,则需要调用浮点转换函数;若须进行浮点加减等运算,则需要调用浮点运算函数。浮点运算可能需要先得到多个中间结果,再将所述多个中间结果运算得到最终结果,而所述多个中间结果可保存在浮点寄存器中,当需要参与运算时,再自浮点寄存器中读取出来。
步骤SA3是在将ARM64位浮点指令处理完毕后,自浮点库函数返回(return);同时,若有最终结果,则将最终结果保存在对应的浮点寄存器中。
这样,即可进入步骤SA4,退出ARM64位异常,同时将前述在判断机制TA1发现ARM64位异常所保存的ARM64位异常现场加以恢复,以便继续运行汇编代码,也即,回到步骤SA1继续执行下一个ARM64位指令。
图2A、图2B、图2C及图2D显示本发明的指令分类器执行逐层分类的具体例子。图2的例子只是示例性的。针对不同ARM64位浮点指令,也可通过本发明的方法来处理。
首先,图2A显示本例子的C代码fp_test的内容:
int fp_test(int_y)
{float xx;xx=10.327;return xx+y;}
上述C代码表示:函数fp_test定义为整数函数,y定义为整数,xx定义为浮点数且xx的值给定为10.327,函数fp_test是配置成执行xx与y的加法运算,由于xx为浮点数,因此上述运算为浮点运算。上述代码只是示例性的。在C代码fp_test输入至编译器后,编译器输出图2B的七个ARM64位指令,这7个ARM64位指令的机器代码为1e220000、52876c81、72a824a1、1e270021、1e212800、1e380000及d65f03c0,其中为了便于识别,机器代码是以十六进制表示,实际上在运算时是以二进制来进行。
参照图2B,其显示上述代码的机器代码,共有1e220000、52876c81、72a824a1、1e270021、1e212800、1e380000及d65f03c0这7个ARM64位指令,其中第一个ARM64位指令的机器代码,以十六进制(hexadecimal)表示为1e220000,而以二进制(binary)表示则为00011110001000100000000000000000,共32位,自最高位(即最左位)至最低位(即最右位)依序定义为第31位至第0位,其中为了方便说明,最高位可说明为Bit31,次高位可说明为Bit30,最低位可说明为Bit0,依此类推。在ARM64处理器上运行Linux操作系统时,所运行的代码是机器代码。
其次,图2C显示将第一个ARM64位指令的机器代码以二进制(binary)表示为00011110001000100000000000000000,由本发明的指令分类器来进行解析。本发明的指令分类器配置成根据ARM64针对浮点类指令的编码规则,定义第31位为标签sf,第29位为标签S,第22至23位为标签type,第19至20位为标签rmode,第16至18位为标签opcode,第5至9位为标签Rn,而第0至4位为标签Rd,如图2C所示。根据sf、S、type、rmode及opcode之中的值,即可将第一个指令分类,并进一步解析其具体是哪个ARM64位浮点指令。在一种实施例中,指令分类器是基于最高位开始的8个Bit(Bit31、Bit30、Bit29、Bit28、Bit27、Bit26、Bit25及Bit24)的数值来判断指令是否为ARM64位浮点指令,这8个Bit的机器代码可视为是第一特征代码。这8个Bit仅是一种范例,在其他实施例中,可使用其他数量或其他位的Bit来判断ARM64位指令是否为ARM64位浮点指令。
最后,图2D显示将第一个指令的机器代码以二进制(binary)表示为00011110001000100000000000000000,由本发明的指令分类器来进行解析。
在判断属于ARM64位浮点指令后,进行第一次分类。在本实施例中,是基于标签type,即Bit23及Bit22的数值,进行第一次分类,这2个Bit的机器代码可称为第二特征代码。使用标签type进行第一次分类仅是一种范例,在其他实施例中,可使用其他标签来进行第一次分类。举例来说,当标签type的数值为00时,类别为“转换类指令”,其涉及浮点数与整数之间的转换。“转换类指令”在一些实施例中包括浮点指令scvtf、ucvtf、fcvtzs及fcvtzu。ARM64位浮点指令是属于指令scvtf、ucvtf、fcvtzs及fcvtzu中的哪一种,会在后续的分类中得到。
在完成第一次分类后,进入第二次分类。在本实施例中,是基于标签rmode,即Bit20及Bit19的数值,进行第二次分类,这2个Bit的机器代码可称为第三特征代码。使用标签rmode进行第二次分类仅是一种范例,在其他实施例中,可使用其他标签来进行第二次分类。
在完成第二次分类后,进入第三次分类。在本实施例中,是基于标签opcode,即Bit18、Bit17及Bit16的数值,进行第三次分类,这3个Bit的机器代码可称为第四特征代码。使用标签opcode进行第三次分类仅是一种范例,在其他实施例中,可使用其他标签来进行第三次分类。
在完成第三次分类后,即可判断出ARM64位浮点指令是哪一个特定的ARM64位浮点指令,例如,浮点指令scvtf。这样逐层分类,有助于加速判断出特定的ARM64位浮点指令。
在其他实施例中,逐层分类可为多次,例如,二次或二次以上;也可考虑不通过逐层分类,而是直接基于type、rmode、opcode判断出特定的ARM64位浮点指令。
在图2D的实施例中,根据ARM64针对浮点类指令的编码规则,撷取出sf的值为0,S的值为0,type的值为00,rmode的值为00,而opcode的值为010,接着,按照上述分类方式,根据各种标签的数值判断出特定的ARM64位浮点指令,因此,得知其类别为“转换类指令”,其涉及浮点数与整数之间的转换,而其具体的ARM64位浮点指令为scvtf。其中,scvtf(scalar,integer)是将32位的整数integer转换成单精度浮点数scalar。
在得知第一个ARM64位指令的类别为“转换类指令”及具体的ARM64位浮点指令为scvtf后,分派相应的浮点库函数int_to_float()来执行ARM64位浮点的模拟运算,int_to_float()函数可将整数转换成浮点数。
上述为针对图2B所显示的第一个ARM64位指令指出的机器代码1e220000所作的解析与处理。然而,例如,针对图2B所显示的第五个ARM64位指令指出的机器代码1e212800,也可进行类似的解析与处理,仅以文字说明如下。
同理,将第五个ARM64位指令的机器代码1e212800以二进制表示则为00011110001000010010100000000000,由本发明的指令分类器来进行解析,根据ARM64针对浮点类指令的编码规则,撷取出sf的值为0,S的值为0,type的值为00,rmode的值为00,而opcode的值为001,接着,按照上述分类方式,根据各种标签的数值判断出特定的ARM64位浮点指令,因此,得知其类别为“运算类指令”,涉及两个浮点数的相加,而其具体的ARM64位浮点指令为fadd,进而分派相应的浮点库函数float_add()来执行ARM64位浮点的模拟运算,函数float_add()可将两个浮点数相加。
其他ARM64位浮点指令也是以相同方式进行分类及处理。
(基于SEMI来优化针对ARM64的浮点模拟器的方法)
图3显示本发明的再一个实施例的基于SEMI来优化针对ARM64的浮点模拟器的方法的流程图。
SEMI(Single Exception for Multiple Instructions)意指陷入单次异常以处理多个ARM64位浮点指令,针对连续的多个ARM64位浮点指令,采用SEMI可节省陷入多次异常的开销。量化而言,当遇到一个ARM64位浮点指令时,自陷入异常,进行ARM64位浮点指令的模拟运算,直至退出异常所耗费的整体时间,陷入异常及退出异常的开销占所述整体时间的10%,而模拟运算本身占所述整体时间的90%,由此可见,采用SEMI,可节省近10%的开销。
本发明的基于SEMI来优化针对ARM64的浮点模拟器的方法可由软件、计算机程序、计算机可读存储介质或计算机程序产品来实现。本方法包括下列步骤:
本方法开始自步骤SB1:在Linux系统上运行低阶代码,例如,机器代码。步骤SB1类似于图1的步骤SA1,于此不再赘述。
判断机制TB1是用于判断代码中的运行中的ARM64位指令是否为ARM64位浮点指令。若判断机制TB1判断运行中的ARM64位指令不是ARM64位浮点指令,则本方法回到步骤SB1以继续执行下一个ARM64位指令。相反地,若判断机制TB1判断运行中的ARM64位指令是ARM64位浮点指令,则本方法须先保存ARM64位异常现场,并进入步骤SB2:陷入ARM64位异常。
在步骤SB2后,进入步骤SB3:处理ARM64位浮点指令。在步骤SB3中,须定义浮点寄存器及状态结构体,以保存浮点运算过程中的数据(例如,中间结果)。步骤SB3可还包括二个子步骤,即执行指令分类器及执行浮点库函数。关于执行指令分类器可参照图2的实施例的步骤SA31的相关说明,而关于执行浮点库函数可参照图2的实施例的步骤SA32的相关说明,在此不再赘述。步骤SA3是在将ARM64位浮点指令处理完毕后,自浮点库函数返回;同时,若有最终结果,则将最终结果保存在对应的浮点寄存器中。
判断机制TB2是用于判断下一个ARM64位指令是否仍然是ARM64位浮点指令。其判断可参照图2的实施例的步骤SA31的相关说明,由本发明的指令分类器根据ARM64针对浮点类指令的编码规则来进行逐层解析,以迅速判断下一个ARM64位指令是否仍然是ARM64位浮点指令。若判断机制TB2判断下一个ARM64位指令仍然是ARM64位浮点指令,则不必退出ARM64位异常,而将下一个ARM64位指令送入步骤SB3进行处理,此即SEMI机制,可节省陷入多次异常的开销。相反地,若判断机制TB2判断下一个ARM64位指令不是ARM64位浮点指令,则进入步骤SB4。举例来说,回顾以图2B为例,在对第四个机器代码1e270021分派相应的浮点库函数后,接续在第四个机器代码1e270021之后的ARM64位指令(第五个机器代码1e212800)也是ARM64位浮点指令,因此不必退出ARM64位异常,而将下一个ARM64位指令送入步骤SB3进行处理。
步骤SB4为退出ARM64位异常,同时将前述在判断机制TB1发现ARM64位异常所保存的ARM64位异常现场加以恢复,以便继续运行代码,也即,回到步骤SB1继续执行下一个ARM64位指令,且应注意的是,此处的下一个ARM64位指令并非ARM64位浮点指令,因为连续的ARM64位浮点指令会在SEMI机制中连续处理。
综上所述,本发明提出了一种在Linux系统上实现ARM64位浮点模拟器的方法。此外,本发明还提出了一种基于SEMI来优化针对ARM64的浮点模拟器的方法,避免了频繁的异常,大幅减少了中断延迟,提升了系统实时性。
尽管本发明已通过多个实施例来说明,应理解的是,只要不背离本发明的精神及权利要求书所主张者,可作出许多其他可能的修饰及变化。
- 利用32位浮点处理器实现64位浮点处理精度的方法
- 在x86架构上运行ARM APK的模拟器装置和方法