一种索引树的创建方法及终端
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及数据库数据处理领域,尤其涉及一种索引树的创建方法及终端。
背景技术
目前,所有的系统都有存储数据的需求,因此都需要依赖数据库。在数据库的种类中,也存在关系型数据库以及非关系型数据库,而随着数据量的增加,对于数据查询也有较高的要求。通常数据库中已经自带了各种的索引,能够快速提供数据查询。以mysql为例,其使用innodb作为数据库索引结构,innodb使用B+树作为索引存储的数据结构,B+树的特性为,非叶子节点用来存储索引数据,叶子节点用来存储具体数据,并且采用前后指针的方式进行数据之间的关联,可以有效提升范围查询的效率。索引树作为innodb的重要数据机构,提供了索引快速查询的功能,可是通常情况下,创建索引树又是一个耗时的操作。其主要通过逐条的扫描数据,根据每条数据中的索引字段,放置到索引树中进行排序,根据排序的结果,整颗的索引树中会进行树枝的变更以及分裂,即新加入索引至索引树中可能会导致整颗索引树的变更,此过程会消耗较多的时间。
发明内容
本发明所要解决的技术问题是:提供一种索引树的创建方法及终端,能够提高索引树创建的效率。
为了解决上述技术问题,本发明采用的一种技术方案为:
一种索引树的创建方法,包括:
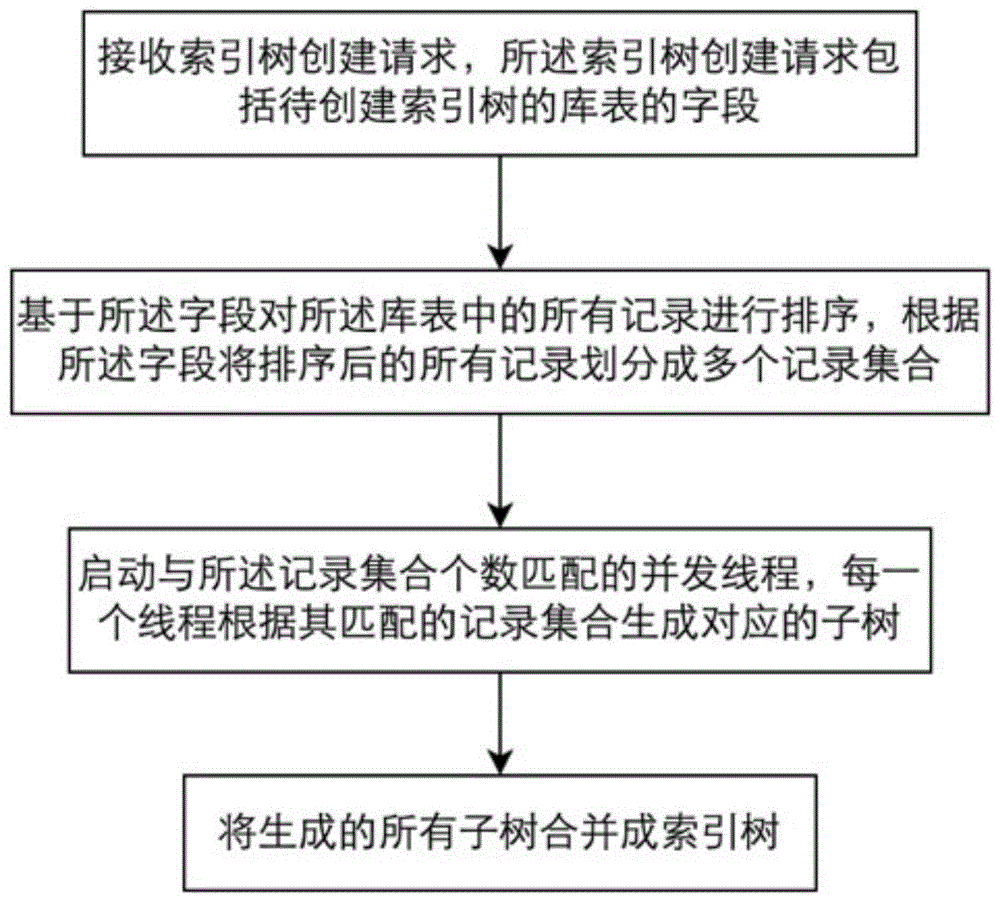
接收索引树创建请求,所述索引树创建请求包括待创建索引树的库表的字段;
基于所述字段对所述库表中的所有记录进行排序,根据所述字段将排序后的所有记录划分成多个记录集合;
启动与所述记录集合个数匹配的并发线程,每一个线程根据其匹配的记录集合生成对应的子树;
将生成的所有子树合并成索引树。
为了解决上述技术问题,本发明采用的另一种技术方案为:
一种索引树的创建终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如下步骤:
接收索引树创建请求,所述索引树创建请求包括待创建索引树的库表的字段;
基于所述字段对所述库表中的所有记录进行排序,根据所述字段将排序后的所有记录划分成多个记录集合;
启动与所述记录集合个数匹配的并发线程,每一个线程根据其匹配的记录集合生成对应的子树;
将生成的所有子树合并成索引树。
本发明的有益效果在于:在进行索引树的创建时,针对需要添加索引的库表字段内容进行排序操作,接着根据排序结果对于库表的整体数据进行多个数据范围的划分,然后针对不同数据范围的数据通过对应数量的并发进程进行子树的创建,最终根据多个子树进行最终索引树的组装,通过这种排序后,并发创建子树的方式,能够很大程度上减少整颗索引树的创建耗时,大大提高索引树的创建效率。
附图说明
图1为本发明实施例的一种索引树的创建方法的步骤流程图;
图2为本发明实施例的一种索引树的创建终端的结构示意图;
图3为本发明实施例的一种索引树的创建方法中所构建的索引树的示意图。
具体实施方式
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
请参照图1,一种索引树的创建方法,包括:
接收索引树创建请求,所述索引树创建请求包括待创建索引树的库表的字段;
基于所述字段对所述库表中的所有记录进行排序,根据所述字段将排序后的所有记录划分成多个记录集合;
启动与所述记录集合个数匹配的并发线程,每一个线程根据其匹配的记录集合生成对应的子树;
将生成的所有子树合并成索引树。
由上述描述可知,本发明的有益效果在于:在进行索引树的创建时,针对需要添加索引的库表字段内容进行排序操作,接着根据排序结果对于库表的整体数据进行多个数据范围的划分,然后针对不同数据范围的数据通过对应数量的并发进程进行子树的创建,最终根据多个子树进行最终索引树的组装,通过这种排序后,并发创建子树的方式,能够很大程度上减少整颗索引树的创建耗时,大大提高索引树的创建效率。
进一步地,所述根据所述字段将排序后的所有记录划分成多个记录集合包括:
采用二分法根据所述字段将排序后的所有记录划分成多个记录集合。
由上述描述可知,通过二分法对排序后的库表中的所有记录进行划分,一方面能够提高划分效率,另一方面也简化了划分操作,方便快捷。
进一步地,所述将生成的所有子树合并成索引树包括:
确定所述多个记录集合对应的划分节点;
将生成的所有子树按照其对应的字段进行排序,构成子树队列;
以两棵子树为一组依次从所述子树队列中按序取出对应的子树,对于取出的每一组子树,确定它们对应的划分节点,作为每一组子树对应的目标划分节点,将所述目标划分节点确定为每一组子树的父节点,父节点存储的是所述目标划分节点对应的字段的值;
在确定出所有子树的父节点后,将当前确定的父节点按照其对应的字段进行排序,构成父节点队列;
以两个父节点为一组依次从所述父节点队列中按序取出对应的父节点,对于取出的每一组父节点,确定它们对应的划分节点,作为每一组父节点对应的目标划分节点,将所述目标划分节点确定为每一组父节点的上一级父节点,上一级父节点存储的是所述目标划分节点对应的字段的值;
返回执行将当前确定的父节点按照其对应的字段进行排序的步骤直至到达根节点。
由上述描述可知,在通过二分法根据索引字段将排序后的所有记录划分成多个记录集合,各个记录集合并发生成对应的索引子树的基础上,在根据子树合并成索引树时,从叶子节点到根节点的方向上,以两个数据对象为一组,依次往上迭代生成每一级的父节点直至根节点,从而完成整棵索引树的合并,操作简单,方便快捷。
进一步地,所述将生成的所有子树合并成索引树包括:
确定所述多个记录集合对应的划分节点;
将所述划分节点按照其对应的字段排序,构成划分节点队列;
将所述划分节点队列中排在中间位置的划分节点确定为根节点,所述根节点存储的是所确定的划分节点对应的字段的值;
将所述根节点加入参考节点集合,根据所述参考节点集合将由所述字段组成的字段队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述根节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
将所述子节点加入参考节点集合,根据所述参考节点集合将所述字段队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述子节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
返回执行将所述子节点加入参考节点集合的步骤直至到达子树。
由上述描述可知,在通过二分法根据索引字段将排序后的所有记录划分成多个记录集合,各个记录集合并发生成对应的索引子树的基础上,在根据子树合并成索引树时,从根节点到叶子节点的方向上,不断通过二分法,依次往下迭代生成每一级的子节点直至叶子节点,从而完成整棵索引树的合并,操作简单,方便快捷。
进一步地,所述索引树为B+树。
由上述描述可知,通过构建B+树作为索引树,索引树中非叶子节点存储的是索引值,即键值,叶子节点存储的是索引值及其对应的数据值,即记录,并且叶子节点之间使用链表进行关联,从而能够缩小数据查询时的范围,提高查询效率。
请参照图2,一种索引树的创建终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如下步骤:
接收索引树创建请求,所述索引树创建请求包括待创建索引树的库表的字段;
基于所述字段对所述库表中的所有记录进行排序,根据所述字段将排序后的所有记录划分成多个记录集合;
启动与所述记录集合个数匹配的并发线程,每一个线程根据其匹配的记录集合生成对应的子树;
将生成的所有子树合并成索引树。
由上述描述可知,本发明的有益效果在于:在进行索引树的创建时,针对需要添加索引的库表字段内容进行排序操作,接着根据排序结果对于库表的整体数据进行多个数据范围的划分,然后针对不同数据范围的数据通过对应数量的并发进程进行子树的创建,最终根据多个子树进行最终索引树的组装,通过这种排序后,并发创建子树的方式,能够很大程度上减少整颗索引树的创建耗时,大大提高索引树的创建效率。
进一步地,所述根据所述字段将排序后的所有记录划分成多个记录集合包括:
采用二分法根据所述字段将排序后的所有记录划分成多个记录集合。
由上述描述可知,通过二分法对排序后的库表中的所有记录进行划分,一方面能够提高划分效率,另一方面也简化了划分操作,方便快捷。
进一步地,所述将生成的所有子树合并成索引树包括:
确定所述多个记录集合对应的划分节点;
将生成的所有子树按照其对应的字段进行排序,构成子树队列;
以两棵子树为一组依次从所述子树队列中按序取出对应的子树,对于取出的每一组子树,确定它们对应的划分节点,作为每一组子树对应的目标划分节点,将所述目标划分节点确定为每一组子树的父节点,父节点存储的是所述目标划分节点对应的字段的值;
在确定出所有子树的父节点后,将当前确定的父节点按照其对应的字段进行排序,构成父节点队列;
以两个父节点为一组依次从所述父节点队列中按序取出对应的父节点,对于取出的每一组父节点,确定它们对应的划分节点,作为每一组父节点对应的目标划分节点,将所述目标划分节点确定为每一组父节点的上一级父节点,上一级父节点存储的是所述目标划分节点对应的字段的值;
返回执行将当前确定的父节点按照其对应的字段进行排序的步骤直至到达根节点。
由上述描述可知,在通过二分法根据索引字段将排序后的所有记录划分成多个记录集合,各个记录集合并发生成对应的索引子树的基础上,在根据子树合并成索引树时,从叶子节点到根节点的方向上,以两个数据对象为一组,依次往上迭代生成每一级的父节点直至根节点,从而完成整棵索引树的合并,操作简单,方便快捷。
进一步地,所述将生成的所有子树合并成索引树包括:
确定所述多个记录集合对应的划分节点;
将所述划分节点按照其对应的字段排序,构成划分节点队列;
将所述划分节点队列中排在中间位置的划分节点确定为根节点,所述根节点存储的是所确定的划分节点对应的字段的值;
将所述根节点加入参考节点集合,根据所述参考节点集合将由所述字段组成的字段队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述根节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
将所述子节点加入参考节点集合,根据所述参考节点集合将所述字段队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述子节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
返回执行将所述子节点加入参考节点集合的步骤直至到达子树。
由上述描述可知,在通过二分法根据索引字段将排序后的所有记录划分成多个记录集合,各个记录集合并发生成对应的索引子树的基础上,在根据子树合并成索引树时,从根节点到叶子节点的方向上,不断通过二分法,依次往下迭代生成每一级的子节点直至叶子节点,从而完成整棵索引树的合并,操作简单,方便快捷。
进一步地,所述索引树为B+树。
由上述描述可知,通过构建B+树作为索引树,索引树中非叶子节点存储的是索引值,即键值,叶子节点存储的是索引值及其对应的数据值,即记录,并且叶子节点之间使用链表进行关联,从而能够缩小数据查询时的范围,提高查询效率。
本申请上述索引树的创建方法及终端,能够适用于需要构建索引树的场景,特别是构建B+树,以下通过具体的实施方式进行说明:
实施例一
请参照图1,一种索引树的创建方法,包括:
接收索引树创建请求,所述索引树创建请求包括待创建索引树的库表的字段;
具体实现时,当接收到针对某一张库表的某个字段进行新增索引的操作时,触发后,可以由一个专门的异步线程进行后续的创建操作;
基于所述字段对所述库表中的所有记录进行排序,根据所述字段将排序后的所有记录划分成多个记录集合;
当触发创建索引操作后,异步线程会进行全库表的扫描,根据索引字段进行全库表排序,比如,可以进行从小到大的升序排序;
如果该字段是数值型数据,则直接按照数字从小到大进行排序,如果是字符型数据,每个字符都对对应一个unicode编码,则按照每个字符的unicode编码进行升序排序;
其中,可以采用二分法根据所述字段将排序后的所有记录划分成多个记录集合;
比如,对于一个索引字段为user ID的创建索引请求,库表中user ID从001到100,则进行二分法划分时,可以划分成索引字段值为001-025,025-050,051-075,076-100四个范围,构成对应的四个记录集合;
启动与所述记录集合个数匹配的并发线程,每一个线程根据其匹配的记录集合生成对应的子树;
以上述划分成四个记录集合为例,此时启动四个并发线程,每一个线程根据对应的记录集合生成对应的子树,四个进程并发执行,其中,每棵子树的生成方式与现有的索引树的生成方式相同;
将生成的所有子树合并成索引树;
当上述四棵子树生成完毕后,此时存在一个等待线程,该等待线程会整理四颗子树,整合为一棵完整的索引树结构;
其中,可选地,所述索引树为B+树。
实施例二
本实施例限定了一种如何将生成的所有子树合并成索引树的方式,具体地:
确定所述多个记录集合对应的划分节点;
将生成的所有子树按照其对应的字段进行排序,构成子树队列;
以两棵子树为一组依次从所述子树队列中按序取出对应的子树,对于取出的每一组子树,确定它们对应的划分节点,作为每一组子树对应的目标划分节点,将所述目标划分节点确定为每一组子树的父节点,父节点存储的是所述目标划分节点对应的字段的值;
在确定出所有子树的父节点后,将当前确定的父节点按照其对应的字段进行排序,构成父节点队列;
以两个父节点为一组依次从所述父节点队列中按序取出对应的父节点,对于取出的每一组父节点,确定它们对应的划分节点,作为每一组父节点对应的目标划分节点,将所述目标划分节点确定为每一组父节点的上一级父节点,上一级父节点存储的是所述目标划分节点对应的字段的值;
返回执行将当前确定的父节点按照其对应的字段进行排序的步骤直至到达根节点;
假设存在一张账户表,其中有100w条的账户激励,现需要根据其中的user ID建立索引;
假设使用二分法,获取到三个划分节点,分别是user ID=50w,user ID=25w,user ID=75w的user ID数据,则此时构建成四棵子树,按照user ID由小到大进行排序得到的子树队列为:user ID范围为[1,25w]的子树,user ID范围为(25w,50w]的子树,userID范围为(50w,75w]的子树以及user ID范围为(75w,100w]的子树。
以两个子树为一组依次从子树队列中按序取出对应的子树,比如,第一次取出的是user ID范围为[1,25w]的子树以及user ID范围为(25w,50w]的子树;第二次取出的是user ID范围为(50w,75w]的子树以及user ID范围为(75w,100w]的子树;
第一组子树的划分节点为user ID=25w,因此,第一组子树的父节点为user ID=25w对应的user ID数据,其中,user ID范围为[1,25w]的子树作为该父节点的左侧,userID范围为(25w,50w]的子树作为该父节点的右侧;
第二组子树的划分节点为user ID=75w,因此,第二组子树的父节点为user ID=75w对应的user ID数据,其中,user ID范围为(50w,75w]的子树作为该父节点的左侧,userID范围为(75w,100w]的子树作为该父节点的右侧;
接着将当前确定的父节点user ID=25w对应的user ID数据以及user ID=75w对应的user ID数据进行排序,构成父节点队列;
然后以两个父节点为一组按序取出父节点,本实施方式中,父节点队列中只有一组父节点:父节点user ID=25w对应的user ID数据以及user ID=75w对应的user ID数据;
确定该组父节点中的划分节点为user ID=50w,因此,它们的父节点为user ID=50w对应的user ID数据,由于此时已经达到根节点,至此,完整的索引树构建完成,构建后的索引树如图3所示,图中,叶子节点除了存储索引字段外,还存储索引字段对应的记录(图中未示出)。
实施例三
本实施例限定了另一种如何将生成的所有子树合并成索引树的方式,具体地:
确定所述多个记录集合对应的划分节点;
将所述划分节点按照其对应的字段排序,构成划分节点队列;
将所述划分节点队列中排在中间位置的划分节点确定为根节点,所述根节点存储的是所确定的划分节点对应的字段的值;
将所述根节点加入参考节点集合,根据所述参考节点集合将由所述字段组成的队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述根节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
将所述子节点加入参考节点集合,根据所述参考节点集合将所述字段队列划分为对应个数的子队列,将每个子队列中排在中间位置的划分节点确定为所述子节点的子节点,所述子节点存储的是所确定的划分节点对应的字段的值;
其中,对于非叶子节点,由两个子节点构成的区间中处于中间位置的划分节点正好是它们的父节点;
返回执行将所述子节点加入参考节点集合的步骤直至到达子树。
假设存在一张账户表,其中有100w条的账户激励,现需要根据其中的user ID建立索引;
假设使用二分法,获取到三个划分节点,分别是user ID=50w,user ID=25w,user ID=75w的user ID数据,则此时构建成四棵子树,按照user ID由小到大进行排序得到的子树队列为:user ID范围为[1,25w]的子树,user ID范围为(25w,50w]的子树,userID范围为(50w,75w]的子树以及user ID范围为(75w,100w]的子树。
将划分节点按照其对应的字段排序,构成划分节点队列:user ID=25w,user ID=50w以及user ID=75w;
将划分节点队列中排在中间位置的划分节点user ID=50w作为根节点,所述根节点存储的是user ID=50w对应的user ID数据;
将所述根节点加入参考节点集合,根据user ID=50w将由user ID组成的字段队列[1,100w]划分成两个子队列[1,50w],(50w,100w];
将上述两个子队列的中间位置对应的划分节点25w以及75w确定为所述根节点的子节点,即25w作为根节点的左子节点,75w作为根节点的右子节点;
此时已经到达子树,因此,终止迭代,直接将user ID范围为[1,25w]的子树作为上述左子节点的左侧,user ID范围为(25w,50w]的子树作为上述左子节点的右侧;
将user ID范围为(50w,75w]的子树作为上述右子节点的左侧,user ID范围为(75w,100w]的子树作为上述右子节点的右侧,至此,完整的索引树构建完成,构建后的索引树如图3所示,图中,叶子节点除了存储索引字段外,还存储索引字段对应的记录(图中未示出)。
实施例四
请参照图2,一种索引树的创建终端,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述实施例一至三中任一个所述的一种索引树的创建方法的各个步骤。
综上所述,本发明提供的一种索引树的创建方法及终端,在进行索引树的创建时,针对需要添加索引的库表字段内容进行排序操作,接着根据排序结果对于库表的整体数据进行多个数据范围的划分,然后针对不同数据范围的数据通过对应数量的并发进程进行子树的创建,最终根据多个子树进行最终索引树的组装,在进行最终的索引树的组装时,既可以从根节点到叶子节点方向,也可以从叶子节点方向向根节点方向,逐级进行迭代以形成最终的索引树,方便灵活,通过这种排序后,并发创建子树的方式,能够很大程度上减少整颗索引树的创建耗时,大大提高索引树的创建效率。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。