一种基于深度学习的加密流量细粒度分类方法
文献发布时间:2024-01-17 01:21:27
技术领域
本发明涉及人工智能网络安全领域,特别涉及一种基于深度学习的加密流量细粒度分类方法。
背景技术
近年来,互联网快速普及和发展,信息技术给人们的生活带来了许多便利。同时,随着网络用户安全隐私意识的不断提升,以及流量加密技术的广泛应用,互联网中加密流量急剧增加。流量加密技术在保护网络数据安全的同时,增加了流量识别的难度,给网络流量规划、网络内容审计和网络安全等领域带来了新的挑战。根据WatchGuard在2021年的调查报告显示恶意软件中91.5%是通过加密连接带来的。加密流量的安全威胁已然是当前面临的一个严峻的安全问题,加密流量分类则是实现加密流量安全威胁分析的重要技术。
传统的网络安全监测分析手段已无法识别基于流量的网络行为,隐匿于加密流量的恶意行为极易逃脱监管,需要对加密流量识别检测技术进行研究,利用新型方法实现加密流量识别和分析。当前传统加密流量算法由于依赖手工提取特征无法实现高效检测,而且存在分类准确率低的问题,尤其是针对加密流量的细粒度分类,例如Chat、Email等流量类型,现有加密流量算法很难对其进行精准分类,究其原因是传统方法无法挖掘数据包深层特征以及相邻字节之间的空间依赖关系。深度学习在图像识别、图像分类、自然语言处理等领域取得了重大的突破。相比于传统人工提取特征进行加密流量分类,基于深度学习的加密流量模型不但能够实现深度特征自动提取,还能极大提高识别准确率,能够有效甄别出通过VPN、Tor等加密技术伪装的流量类型,实现网络安全监测与防护。
发明内容
本发明所要解决的技术问题是如何实现真实复杂网络环境下的加密流量准确分类,针对上述问题提出一种基于深度学习的加密流量细粒度分类方法,首先将pcap格式的流量经过数据预处理转换为同一格式,然后基于一维卷积神经网络(1D CNN)自适应的提取流量数据包的深层特征,并通过训练1D CNN挖掘数据包字节之间的前后空间依赖对流量类型进行分类。该发明旨在解决传统加密算法无法实现端到端分类以及分类准确低的问题。
本发明采用的技术方案为:
一种基于深度学习的加密流量细粒度分类方法,包括以下过程:
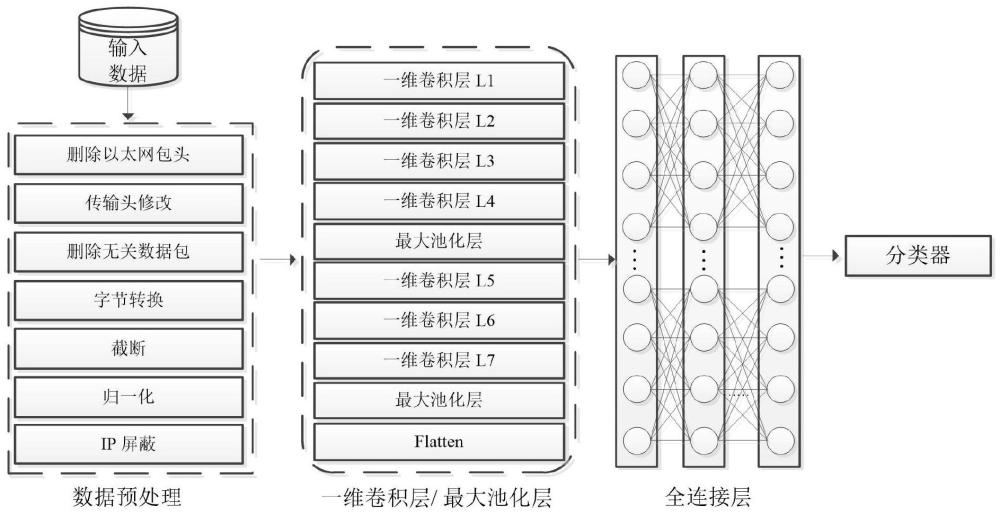
(1)进行数据预处理,包括删除以太网包头、传输头修改、删除不相关的数据包、字节转换、截断、归一化和IP屏蔽;
(2)将预处理后的数据输入一维卷积神经网络中提取数据包深层表征,同时挖掘相邻字节之间的空间依赖关系,并将经过卷积和池化后的二维张量利用Flatten操作压缩为一维向量;其中一维卷积神经网络包括七层卷积层、两层最大池化层和Flatten;
(3)将一维向量输入到堆叠在一起的三层全连接层,将特征表示映射到样本标记空间;
(4)根据加密流量类型数目将映射后的特征表示输入到softmax分类器进行分类,并采用多分类交叉熵作为训练的损失函数。
进一步的,一维卷积神经网络中卷积核尺寸均为5,输出维度分别为200、200、150、150、150、100和100,步长均为1,在Conv1D C4和Conv1D C6层后分别连接一层最大池化层,且池化核均为4,步长为1。
进一步的,三层全连接层神经元个数分别为200、100和50,最后根据加密流量类型总数确定输出维度,并输入到softmax分类器进行分类。
本发明与现有技术相比,取得的有益效果为:
(1)本发明提出一种新颖的加密流量特征提取架构,1D CNN能够从固定长度的数据中提取重要特征,尤其是当特征在数据包的位置相关性不高时,能够提取数据的简单表示,并形成复杂的深层表征用于分类。因此1D CNN相比RNN更适合处理固定长度的序列分类任务。本发明将数据经过预处理后统一为相同长度的字节向量,然后输入到1D CNN中训练,其训练速度更快且性能更好。
(2)本发明能够在保证高分类准确率的前提下实现流量类型的细粒度多分类,通过1D CNN可以捕获网络数据包中相邻字节之间的空间依赖关系,从而找到不同流量类型的区别模式,从而对流量进行准确的分类。
附图说明
图1为本发明一种基于深度学习的加密流量细粒度分类方法流程图。
具体实施方式
下面结合附图对本发明作进一步说明。
针对当前传统加密流量算法由于依赖手工提取特征无法实现高效检测的问题,本发明提出一种基于深度学习的加密流量细粒度分类方法,通过1D CNN提取流量数据包的特征,通过卷积能够得到数据的深层表征的同时可以捕获网络数据包中相邻字节之间的空间依赖关系,进而实现快速精确的加密流量细粒度分类。
本发明分为,1)数据预处理;2)空间依赖特征提取;3)堆叠全连接层;4)加密流量分类器。本发明以ISCX VPN-nonVPN、ISCX Tor-nonTor数据集上的细粒度分类任务为例,每个阶段的工作描述如下:
数据预处理阶段:由于数据集在数据链路层被捕获。因此,它包括了以太网的报头。数据链路头包含关于物理链路的信息,例如媒体访问控制(MAC)地址,这对于转发网络中的帧是必不可少的,但流量分类任务是不需要的。因此,在预处理阶段,首先删除以太网报头。传输层段,特别是传输控制协议(TCP)或用户数据报协议(UDP),其报头长度会有所不同。前者通常具有一个20字节长度的报头,而后者有一个8字节的报头。为了使传输层段均匀,我们在UDP段报头的末端注入零,使它们与TCP头的长度相等。然后将数据包从位转换为字节,这有助于减少神经网络的输入大小。数据集中一些无关的数据包也需要丢弃,例如一些TCP段,其SYN、ACK或FIN标志设置为1,但不包含任何有效负载。此外,在数据集中还有一些域名服务(DNS)段。这些段用于主机名解析,即将URL转换为IP地址。这些段与应用程序标识或流量特性都无关,因此可以从数据集中忽略。数据包长度在数据集中变化很大,而使用神经网络则需要使用固定大小的输入。因此,不可避免地需要在固定长度或零填充处进行截断。为了找到用于截断的固定长度,通过数据包长度的统计数据显示,大约96%的数据包的有效负载长度小于1480字节。因此,保留IP头和每个IP包的前1480字节,最终1500字节向量作为本发明提出的模型的输入。IP有效负载小于1480字节的数据包在最后被零填充。为了获得更好的性能,所有包字节除以255,使得所有输入值都在[0,1]范围内。此外,屏蔽IP数据报报头的IP,避免神经网络学习他们的IP地址对数据包进行分类进而导致过拟合。
空间依赖特征提取:为了提取数据包字节之间的前后空间依赖,本发明使用1DCNN挖掘流量特征的深层表征,具体网络结构如发明书附图所示,该模型共包括7层卷积层和2层最大池化层,分别在C4和C7层后进行一维最大池化,池化核大小为4,步长为1,具体网卷积层结构及其参数如表1所示。
表1
堆叠全连接层:经过7层卷积操作后,通过Flatten将二维张量压缩成一维向量,并送入到3层全连接,3层全连接层分别由200、100和50个神经元组成。
加密流量分类器:最后根据加密流量类别数目添加相应的神经元输出,并输入到softmax分类器进行分类。
如附图所示,本发明包括数据预处理、空间依赖特征提取、堆叠全连接层和加密流量分类器。具体步骤如下:
(1)数据预处理,包括删除以太网包头、传输头修改、删除不相关的数据包、字节转换、截断、归一化和IP屏蔽等;
数据预处理用于处理原始流量特征,包括删除以太网包头以及其他无关数据包,同时为了保证输入神经网络的长度相同,需要对数据进行填充和截断,此外为了消除不同数据之间的差异,保证训练结果的可靠性,需要对数据进行归一化处理。
(2)将将预处理后的1500字节向量输入到一维卷积神经网络(1D CNN)中提取特征,一维卷积神经网络包括7层卷积层,其卷积核尺寸、输出维度和步长如表1所列;其中分别在C4和C7层后添加最大池化操作,池化核尺寸均为4,步长为1;并将经过卷积和池化后的2维张量利用Flatten操作压缩为1维向量;
(3)将1维向量输入到堆叠在一起的3层全连接层,神经元个数分别为200、100和50;
(4)根据加密流量类型总数确定最后输出维度,并输入到softmax分类器进行分类,并采用多分类交叉熵作为训练的损失函数。
完成基于深度学习的加密流量细粒度分类典型流程。