一种基于回译的文本三元组标注样本增强方法
文献发布时间:2023-06-19 09:55:50
技术领域
本发明涉及自然语言处理技术领域,一种基于回译的文本三元组标注样本增强方法。
背景技术
目前文本关系抽取模型,能够抽取文本中特定类型的关系,是提高人们对于文本信息挖掘能力的重要方法。为了训练这类模型,需要大量三元组标注文本样本。
在现有技术条件下,为了获得大量三元组标注文本样本,需要耗费大量人工。并且较其他一般常见类型的文本标注,三元组标注对标注人员的要求更高,人工信息处理难度更大。此外,现有的自动文本增强方法,还以同义词替换为主,难以生成多样化的句式,这样生成的样本会减少模型的鲁棒性。
发明内容
本发明的主要目的是提出一种基于回译的文本三元组标注样本增强方法,旨在减少人工标注复杂度,增加三元组标注数据的样本量和句式多样性。
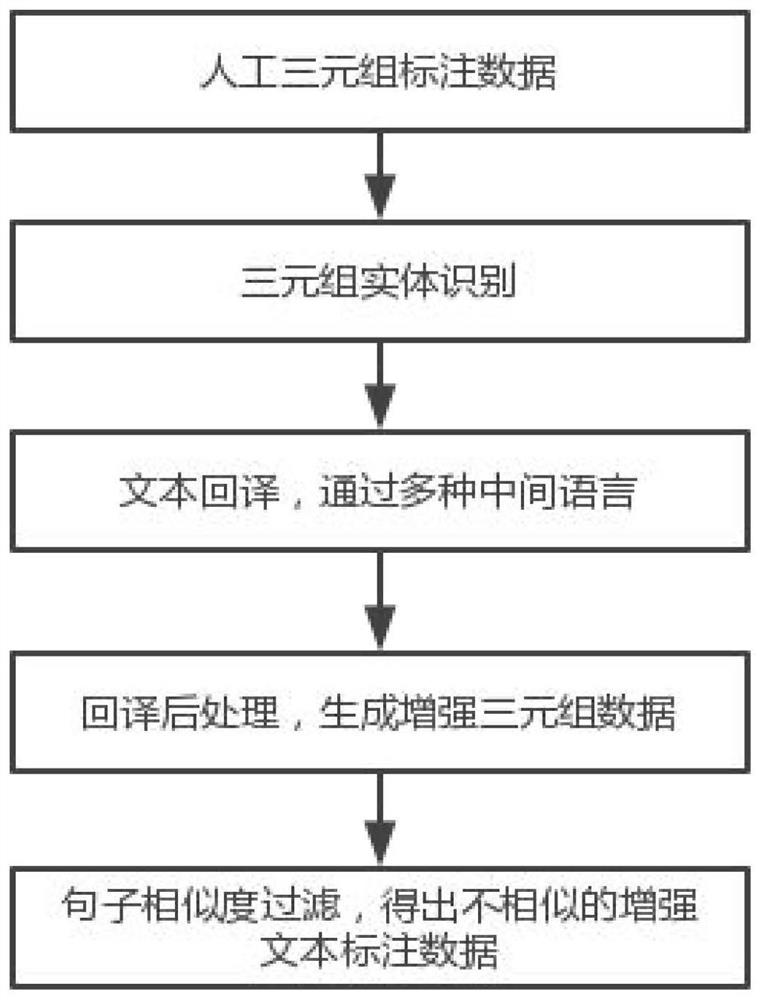
为实现上述目的,本发明提出了一种基于回译的文本三元组标注样本增强方法,包括以下步骤:
S1.对文本标注三元组进行识别与处理,得到带命名实体类型标注的三元组标注样本;
S2.对三元组标注样本进行数据预处理,在三元组标注样本中提取命名实体间嵌套关系;在原始文本中为三元组各命名实体添加标识标签,或者进行命名实体替换;
S3.将预处理后的三元组标注样本按字串长度限制,通过分隔符组成一个预处理批次;
S4.对一个预处理文本批次进行多语言回译,通过各中间语言得到回译后的长文本,从中分割出各个样本对应的预处理文本的回译结果,对每个样本的回译结果进一步进行命名实体识别或还原;
S5.根据原始文本中三元组各命名实体的标识标签,将回译后的文本中多样化的命名实体及其添加的标识标签,还原成原命名实体或替换为其他同类型命名实体;同时,也将回译后句子和三元组标注的对应部分做相同操作,以得到增强样本;
S6.通过对比增强样本和原始文本中句子的相似度,按阈值过滤掉相似度过高的句子,保留句子的多样性。
进一步地,在步骤S1中,将输入的文本标注三元组提供给命名实体标注模块,根据三元组和三元组关系类型构造命名实体关系短句,以实体关系短句作为基础命名实体识别模块的输入;
将实体关系短句作为输入提供给基础命名实体识别模块,基础命名实体识别模块判断三元组谓语对应的subject和object对应的类型,获得实体关系短句的基础命名实体标注;
根据命名实体构词规则和基础命名实体标注,及二者组合特点,生成带命名实体类型标注的三元组标注样本。
进一步地,所述基础命名实体识别模块通过以下方式进行构造:采用Bidirectional Encoder Representation from Transformers模型,并加载中文预训练语料,最后采用crf(条件随机场)模型进行命名实体识别,构建命名实体识别模块。
进一步地,构造命名实体关系短句时,结合三元组谓词特点和命名实体的搭配规律来实现。
进一步地,将输入的文本标注三元组提供给命名实体标注模块,用命名实体识别模块判断三元组谓语对应的subject和object对应的类型;
首先,根据标注样本的三元组来构造短句,让其互为上下文内容;
然后,将构造的短句提供给基础命名实体识别模块,得出句子各部分的基础命名实体标注,在谓词前后对象类型的选择范围内,根据目标对象的构词规则和基础命名实体标注,合并基础命名实体,判断命名实体类型;
最后得出带命名实体类型的三元组标注样本。
进一步地,在步骤S4中,根据特定回译中间语言特点,对预处理文本的标注命名实体打上标识标签和/或做命名实体替换,生成预回译文本。
进一步地,在步骤S5中,通过多语言回译预回译样本,原命名实体标签在多语言回译结果中保持有可标识性;
回译生成新文本,根据之前的标识标签和嵌套关系,提取新文本对应的标注三元组,做相应的同类词替换,生成新标注样本。
进一步地,在步骤S6中句子相似度计算使用Jaccard系数;
给定两个句子A、B,Jaccard系数定义为A与B交集的大小与A与B并集的大小的比值,定义如下:
与现有技术相比,本申请公开的技术方案主要有以下有益效果:
在本申请实例中,通过标注三元组构造短句,为命名实体添加了必要的上下文,同时避免了原句命名实体上下文的复杂性,增加了基础命名实体识别的准确性,结合三元组命名实体构词规律,和词后缀来生成命名实体关系类型,保障三元组命名实体类型标注的准确性,让三元组关系类型中同一谓词能够对应多种类型的subject和object,有利于减少后续三元组关系抽取模型的关系分类数,有利于减少标注人员的标注复杂度,增加了标注工作的效率。
通过在回译前对命名实体的预标记规则,保持了在跨多语种回译前后命名实体的可标识性,并且不对文本语义内容构成明显影响,使得命名实体间的语义关系得到较好的保留,保障了标注三元组关系的准确性,增强了三元组标注文本的数据量,有利于减少人工标注工作量,有利于关系抽取模型训练数据不足的问题。通过对回译文本与原文本相似性小于等于阈值,以及命名实体的同类词替换,来进一步保证文本的句式多样性,有利于关系抽取模型的鲁棒性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
图1为本发明一种基于回译的文本三元组标注样本增强方法的简要流程示意图;
图2为本发明一种基于回译的文本三元组标注样本增强方法的流程说明图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
以下结合图1-图2及相关实施例对本发明方案做进一步阐述。
本发明申请属于自然语言处理技术领域,涉及一种基于回译的文本三元组标注样本增强方法,包括以下步骤:
1.依照构词规律和命名实体标注,通过为已有的人工标注三元组样本添加命名实体类型;
2.根据给定语句或段落文本以及文本的三元组样本,通过对句内命名实体添加特殊符号标签以及命名实体替换的综合方法,对文本进行多语言回译(即是将A语言的译文B翻译成A语言),并生成新的文本;
3.根据回译前的特殊符号标记,从回译后的文本中生成三元组及其命名实体类型标注,最后通过同类命名实体替换生成最终增强样本。
具体的,一种基于回译的文本三元组标注样本增强方法,包括以下内容:
将文本及其人工标注三元组提供给S6构建的命名实体识别模块,用命名实体识别模块判断三元组谓语对应的subject(主语)和object(宾语)的实体类型。
首先,根据标注样本的三元组来构造短句,让其互为上下文内容。
然后,将构造短句提供给基础实体识别模块,得出句子各部分的基础命名实体标注,在谓词前后对象类型的选择范围内,根据目标对象的构词规则和基础命名实体标注,合并基础命名实体,判断命名实体类型,最后得出包括命名实体类型标注的三元组标注样本。
将带命名实体类型的三元组标注样本作为输入,根据标注三元组进行数据预处理。预处理包括:
获取命名实体嵌套关系,根据回译语言、翻译工具特点和命名实体类型,在原始文本中,为三元组的各命名实体添加标识标签,来保障回译后命名实体的可标识性,或者进行命名实体替换,以降低语言互译时文本含义的变化。
将预处理文本样本按字串长度限制,通过分隔符组成一个预处理批次。
对一个预处理文本批次用预处理对应的中间语言进行回译,回译使用Googletranslate翻译工具进行,能够最大程度地避免额外符号对翻译结果的干扰。
通过各中间语言得到回译后的文本,并利用分隔符分割出各个短文本样本的回译结果。
对每个样本的回译结果进一步分离出命名实体。
通过原命名实体标签符号,从句子中分离出回译后的命名实体及其添加的标识号。根据原样本三元组标识号,将回译后多样化的命名实体及其添加的标识标签,还原成原命名实体或替换为其他同类型命名实体。同时,也将回译后句子和三元组标注的对应部分做相同操作,得到增强样本。
通过对比增强后的句子,和原句子的相似度,按阀值过滤掉相似句子,保留句子的多样性。
在本申请实例中,通过标注三元组构造短句,为命名实体添加了必要的上下文,避免了原句命名实体上下文的复杂性,增加了基础命名实体识别的准确性;
结合三元组命名实体构词规律和词后缀来生成命名实体关系类型,保障三元组命名实体类型标注的准确性,让三元组关系类型中同一谓词能够对应多种类型的subject(主语)和object(宾语),有利于减少后续三元组关系抽取模型的关系分类数,有利于减少标注人员的标注复杂度,提高了标注工作的效率。
通过在各语言回译前对命名实体的不同预标记标签,保持了在跨多语种回译前后命名实体的可标识性,并且不对文本语义内容构成明显影响,使得命名实体间的语义关系得到较好的保留,保障了标注三元组关系的准确性,增强了三元组标注文本的数据量,有利于减少人工标注工作量,有利于关系抽取模型训练数据不足的问题。通过对回译文本与原文本相似性小于等于阈值,以及命名实体的同类词替换,来进一步保证文本的句式多样性,有利于关系抽取模型的鲁棒性。
其中一个实际应用的实施方式为包括以下步骤:
S1:设定三元组schemas(模式),所有的schemas使用Json文件格式保存,每一个schema包括subject_type、predicate、object_type,格式参照{"object_type":"人物/机构","predicate":"参与/主持","subject_type":"会议/仪式/活动"}和{"object_type":"人物/机构","predicate":"被指代","subject_type":"指代词"};
S2:根据设定的三元组schema,从目标样本文本(句子)中,通过人工标注的方式,将文本(句子)中的三元组关系标注出来,并保存到另一个json文件中,json文件格式参照{'text':'2016年12月,唐山市副市长李晓军落马,在张和担任唐山市长期间,他是唐山市政府办公厅副主任','spo_list':[{'object':'副市长','predicate':'职务','subject':'李晓军'},{'object':'副主任','predicate':'职务','subject':'李晓军'},{'object':'唐山市','predicate':'职务隶属于','subject':'副市长'},{'object':'唐山市政府办公厅','predicate':'职务隶属于','subject':'副主任'},{'object':'他','predicate':'被指代','subject':'李晓军'}]},text是原始的样本文本(格式),spo_list包括句子中的所有三元组关系;
S3:构造命名实体识别模块,命名实体识别采用Bidirectional EncoderRepresentation from Transformers模型,并加载中文预训练语料,最后采用crf(条件随机场)模型进行命名实体识别;
S4:使用已经标注的三元组样本构造短句,短句中包含三元组的所有内容。如样例中的{'object':'他','predicate':'被指代','subject':'李晓军'},可构造短句“李晓军被指代为了他”(例子缺失,如上例子,提取一个三元组来说明,还必须是有多种实体类型的三元组模式);
S5:使用S3步骤构建的命名实体识别模块,对S2步骤已经标注好的三元组样本进行实体类型自动标注,并记录原始样本文本;
S6:对构造的短句进行基础命名实体识别;
S7:根据谓词匹配实体类型范围内目标对象的构词规则和基础实体标注,融合基础实体标签,得出实体类型,subject_type和object_type,如样例中的三元组变为如{'object':'他','predicate':'被指代','subject':'李晓军','subject_type':'人物','object_type':'人物'}的形式;
S8:获取S2中短文本,即json中键为“text”的值中的实体嵌套关系,如样例中标注实体'唐山市政府办公厅'包含了另一个标注实体'唐山市',以{'唐山市':['唐山市政府办公厅']}形式记录(缺样例);
S9:按不同的翻译中间语言,在S5的文本短句中,为三元组各实体添加“标识标签”,或者进行实体替换;
S10:将在S9中已经进行“标识标签”“实体替换”的短文本,按不同的中间语言加入分割字符构建不同回译批次,分批翻译成不同的语言;
S11:将翻译后获取的不同语言的文本,再次使用翻译工具回译成原始语言,此时获得的文本包含了需要的所有三元组信息;
S12:将每种语言批次回译好的文本,按S10中加入的分割符分割,将批次回译文本分割成短文本,短文本数量和回译前一致;
S13:通过实体标签符号,从S12句子中分离出回译后的实体及其“标识标签”;S14:将回译后句子的实体,还原成S9步骤进行前的实体,或替换为其他同类型实体,三元组标注的实体也做相同操作,得到增强样本;S15:S14得到的短句,与S5记录的短句原始文本使用Jaccard系数进行相似性计算,设定相似性阈值,文本过于相似则过滤掉;
S16:经过以上15个步骤后最终生成带有所有三元组信息,句子不相似的三元组标注增强文本。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
- 一种基于回译的文本三元组标注样本增强方法
- 一种基于回译的文本三元组标注样本增强方法