强可解释性和时空不变性的智能法条推荐系统
文献发布时间:2023-06-19 09:55:50
技术领域
本发明属于司法庭审辅助系统领域,尤其是强可解释性和时空不变性的智能法条推荐系统。
背景技术
法学领域对人工智能的研究大致分为两类,一类是关于人工智能本身所涉及的法学理论问题,另一类是关于人工智能在审判活动中的实际运用。现有的许多智能法条推荐系统作为人工智能在审判活动中的实际运用,往往缺少了对法学理论的探讨,所用的算法像一个黑盒,其内部的运算过程难以被解读,而包括法条推荐在内的众多司法人工智能任务对算法的可解释性有严格要求,可解释性是指人类能够理解决策原因的程度,算法的可解释性越好,其结果就越容易被理解和接受,让可解释性差的黑盒模型决定一个人犯什么罪,判多少年在法学理论上是站不住脚的;另外,由于不同地区可能有不同的地方性法规,或随着司法建设的完善使法律条文发生了变化,导致同样案件的判决结果随空间或时间变化而不同。因此,具有强可解释性和时空不变性的智能化审判辅助系统不仅对法官审理案件有着重要的意义,也有利于人工智能在司法工作中合理地位的确立。本发明在申请号为2019113331151,名称为基于FastText算法的智能法条推荐辅助系统的基础上新增了要素集、法条集和要素法条对应关系的整理以及对法律文本进行要素标注几个重要环节,要素集中包含如已满十六周岁、冒充国家机关工作人员等即使没有专业法律知识的人也能理解的要素,同时要素随时间和空间变化很小,相比前一发明直接从法律文本到法条的模式,本发明从文本到要素再到法条,兼具可解释性和时空不变性,可以方便地在不同地区推广,并能轻松地适应司法建设的完善。
发明内容
本发明通过设计强可解释性和时空不变性的智能法条推荐系统,解决的技术问题是:针对案情描述文本,通过具有强可解释性和时空不变性的人工智能算法对现有案件事实进行分析,然后实时地为法官提供准确、全面的适用法条、司法解释和地方量刑意见,辅助法官审理案件。
本发明解决其技术问题的解决方案是:
强可解释性和时空不变性的智能法条推荐系统,包括裁判文书数据集、词向量文本库、法律词向量、文档向量文本库、要素集、法条集、要素法条对应关系、文本要素模型;所述裁判文书数据集用于存储裁判文书;所述词向量文本库用于储存文段类别,所述文档向量文本库用于储存文段类别;所述文段类别是裁判文书中的内容;所述法律词向量由预训练的通用词向量作为起始向量,再使用FastText无监督学习算法在词向量文本库上训练得到的;所述要素集由法学专家对不同案件类型中影响判案的法律情形进行归纳整理得到,要素集是由要素构成的集合[要素1,要素2,...],得到的要素作为文档向量文本库经文本要素模型后输出的结果;所述要素集由法学专家对不同案件类型中影响判案的法律情形进行归纳整理得到,要素集是由要素构成的集合[要素1,要素2,...],得到的要素作为文档向量文本库经文本要素模型后输出的结果;所述法条集由法学专家对不同案件类型的法律条文归纳整理得到,包括法条、司法解释和地方量刑意见;所述要素法条对应关系由法学专家对各要素整理其对应的若干法条构成,相当于[(要素1,要素1对应的法条),(要素2,要素2对应的法条),...];所述文本要素模型是将训练好的法律词向量作为起始向量,文本要素模型表示对输入文本输出相关要素的模型,再使用FastText监督学习算法在文档向量文本库上进行文本分类得到的。
进一步地,强可解释性和时空不变性的智能法条推荐系统,其特征在于,所述的裁判文书包含诈骗罪、抢劫、经济犯罪或离婚纠纷案件的裁判文书;所述裁判文书是一个四列的表,每列依次表示标识符、文段类别号、段落序号和文本。
进一步地,所述文段类别包括判决书名称、案号、当事人信息、案件审理信息、原告诉称、被告辩称、法院认定事实、法院说理部分、裁判依据、案件受理费、上诉法院、文书尾部、第三人述称、法院名称、文书类型、裁判结果和证据。
强可解释性和时空不变性的智能法条推荐系统的训练方法,包含以下步骤:
A、整理裁判文书,将每份裁判文书排列成四列的表,每列依次表示标识符、文段类别号、段落序号和文本,文段类别号分别是1到17的不间断的自然数,自然数的序号代表的文段类别依次包括判决书名称、案号、当事人信息、案件审理信息、原告诉称、被告辩称、法院认定事实、法院说理部分、裁判依据、案件受理费、上诉法院、文书尾部、第三人述称、法院名称、文书类型、裁判结果和证据,将文段类别号为5、6、7、8、16,裁判文书类别为原告诉称、被告辩称、法院认定事实、法院说理部分、裁判依据、裁判结果,提取到词向量文本库中,将文段类别号为7,裁判文书类别为法院认定事实部分提取到文档向量文本库中;
B、整理要素集、法条集和要素法条对应关系。要素集由法学专家对不同案件类型中影响判案的法律情形进行归纳整理得到;法条集由法学专家对不同案件类型的法律条文归纳整理得到,包括法条、司法解释和地方量刑意见;要素法条对应关系由法学专家对各要素整理其对应的若干法条构成;
C、对词向量文本库和文档向量文本库中的句子进行分词,即在相邻词之间插入空格,然后再删去包括“了、吧、的”等无实意停用词;
D、从文段类别号为3的法律文段中提取当事人信息,将词向量文本库和文档向量文本库中对应行的姓名字符串替换成对应的原被告字符串;法学专家对文档向量文本库中的法律文段标注相关联的要素,每个要素字符串前添加相同的识别前缀字符串,再将合成的字符串添加到文档向量文本库对应行的行首,合成的字符串分别用空格分隔开;
E、以预训练的通用词向量作为起始向量,使用FastText无监督学习算法在词向量文本库上训练法律词向量;
F、以步骤E中训练好的法律词向量作为起始向量,使用FastText监督学习算法在文档向量文本库上进行文本分类,并得到文本要素模型,文本要素模型的输出是要素,通过要素法条对应关系得到法条;
G、将训练好的文本要素模型提供给应用编程接口API供开发者调用,开发者可以得到案情描述文本指定数量的,或置信度高于指定阈值的要素,通过要素法条对应关系得到法条。
进一步地,所述的裁判文书包含诈骗罪、抢劫、经济犯罪或离婚纠纷案件的裁判文书;所述裁判文书是一个四列的表,每列依次表示标识符、文段类别号、段落序号和文本,不同类型的案件建立各自的文本库,文本库中每行包含同一份裁判文书所有被提取内容,因为每份原始裁判文书中的类别5、6、7、8、16等段落不在同一行,这些段落被提取出来预处理后合并成一行放到文本库中,文本库中只要是同一行就是同一个案件,只要不同行就不是同一案件。
本发明的工作原理:本发明首先将要素作为案情描述的标签,每段案情描述可以对应多个要素,这样法律文段分类就化为一个多标签文本分类任务,从而有了数学上的支撑。词向量的训练过程是一个迭代过程,每一次迭代词向量都会被更新,在最开始时词向量是不存在的,所以每个词的词向量在第一次迭代前需要初始化为一个随机的300维词向量,然后开始迭代,为了给案情描述推荐适用法条,首先需要将词初始化为随机的300维向量,发明中提到的词就是组成文本的内容,案情描述文本的段落向量由其中所有词的向量平均得到,然后使用FastText监督学习算法学习段落向量和要素标签之间的对应关系,在学习过程中更新词向量并建立文本要素模型,文本要素模型的输出是要素,通过要素法条对应关系得到相应的法条。此发明将案情描述的适用法条推荐解耦成两个过程:案情描述到要素和要素到法条,得益于由法学专家整理的要素集具有很好的可解释性和时空不变性,本发明的方法可以方便地在不同地区推广,并能轻松地适应司法建设的完善。
上述方案中,为进一步优化FastText监督学习算法的效率和最终的适用法条推荐的效果,本发明采用了预训练的通用词向量作为起始向量,因为随机初始化的词向量并不蕴含语义和语法信息,预训练的通用词向量可以有效克服这一问题,FastText无监督学习算法从通用词向量出发,在词向量文本库上训练得到蕴含法律信息的法律词向量,这些法律词向量可以加快FastText监督学习算法的收敛速度,并提高要素推荐的效果,进而提高法条推荐的效果。
本发明的有益效果:
效果一,针对案情描述全面精准地推荐适用法条,为人工智能提供司法辅助工作开拓新的思路。
效果二,本发明可以针对各类型的犯罪,比如骗罪、抢劫、经济犯罪或离婚纠纷案件分别建立文本要素模型,适用范围广。
效果三,本发明采用的“要素标注+法条对应”模式将机器学习与法学理论解耦,得到的文本要素模型具有可解释性和专业性,有利于人工智能算法被法律从业者接受,推动其在司法工作中合理地位的确立。
效果四,本发明得到的文本要素模型具有时空不变性,法条、司法解释和地方量刑意见在不同地区会有所不同,也会随时间不断完善,但要素不会,当法条、司法解释和地方量刑意见变化时只需重新整理要素法条对应关系,无需重新训练模型即可进行适用法条推荐。
效果四,本发明得到的文本要素模型提供了简洁明了的调用接口,具有易用性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单说明。显然,所描述的附图只是本发明的一部分实施例,而不是全部实施例,本领域的技术人员在不付出创造性劳动的前提下,还可以根据这些附图获得其他设计方案和附图。
图1是一份完整的裁判文书;
图2是预处理后的裁判文书;
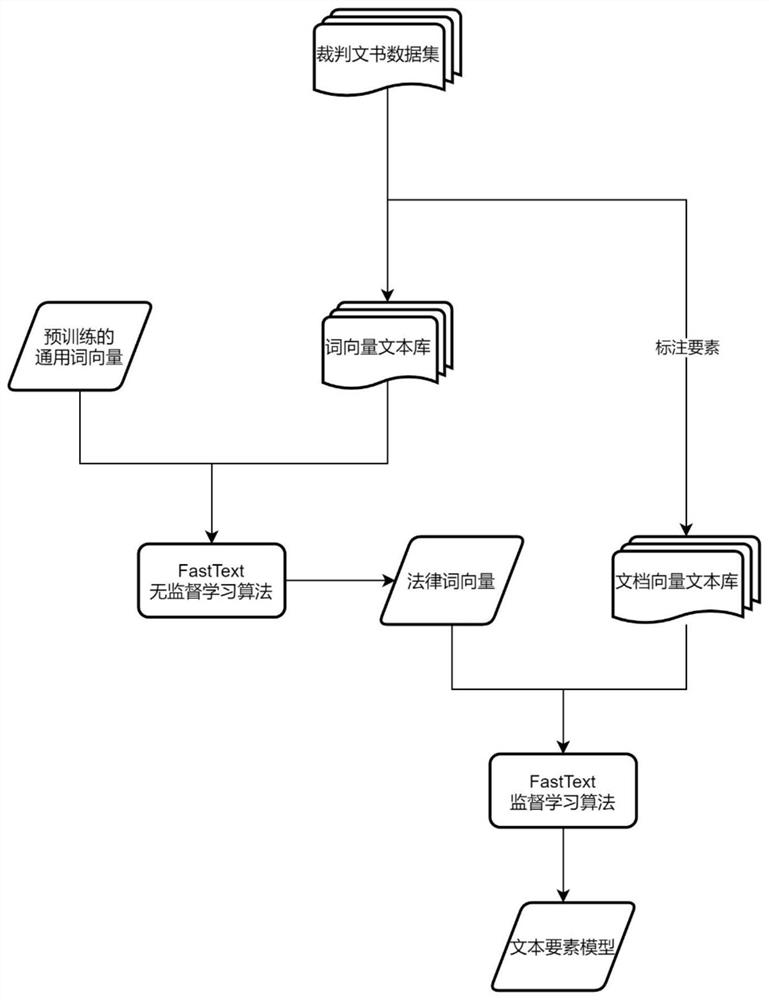
图3是文本要素模型训练过程;
图4是Skip-Gram模型结构示意图;
图5是FastText文本要素模型训练示意图;
图6是文本要素模型调用过程。
具体实施方式
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,文中所提到的所有连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少连接辅件,来组成更优的连接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参照图1至图6,这是本发明的实施例,本发明实施例给出了针对诈骗罪适用法条推荐模型,模型中包含了对应案由的法律词汇信息、法律文本信息以及它们之间的关联,这些法律信息使用向量表示,而关联可以用向量之间的运算得出,除此之外模型还包含要素集、法条集、要素法条对应关系,详见表2和表3。最后,模型还给出了便于开发者调用的接口。
具体地:
给出了一份完整的裁判文书,此文档归为裁判文书数据集,如图1所示的裁判文书的每一行都可分为四部分:标识符、文段类别号、段落序号和文本。其中文段类别号所代表的类别如表1所示,
表格1
筛选类别5(原告诉称)、6(被告辩称)、7(法院认定事实)、8(法院说理部分)和16(裁判结果),对类别5、6、7、8和16中的句子进行分词,即在相邻词之间插入空格,然后再删去包括有“了、吧、的”等的无实义停用词和词条归一化,例如同一个“某某某”在不同裁判文书中的身份可能不同,将其替换成原告或被告,并构建词向量文本库,词向量文本库是用来储存法律文段,其中类别7用于构建文档向量文本库,这里的文档向量文本库也是用来储存法律文段的。
图2给出了图1中的裁判文书预处理后的文本,其中第一行包含类别5、6、7、8和16,第三行以“__”开头的是法学专家标注的要素,剩余部分为类别7。
文本要素模型的完整训练过程如图3所示,基于迁移学习的思想,以FastText预训练的通用词向量为初始向量,预训练的通用词向量的下载链接如下:https://fasttext.cc/docs/en/crawl-vectors.html,使用FastText无监督学习算法在词向量文本库上训练法律词向量,并以此为初始向量,使用FastText监督学习算法在文档向量文本库上要素推荐,得到文本要素模型,文本要素模型输出的要素通过要素法条对应关系得到相应的法条。在使用FastText无监督学习算法时,为加快训练速度并得到更好的收敛结果,以FastText模型预训练的4.2G 300维词向量作为起始向量训练法律词向量。
如图4和图5,在FastText文本要素模型中采用的FastText无监督学习算法名称为Skip-Gram模型,每篇裁判文书的文档向量为其中所有词的向量的平均,经过一个隐藏层和softmax函数后得到了每个要素适用于此文书的条件概率,将条件概率大于一定阈值的要素作为该案件的相关要素,再如图6所示,调用文本要素模型需要两个参数,参数一是案情描述文本,参数二是预期的要素数量k或预期条件概率t。文本要素模型接收到两个参数后通过计算得到各个要素适用于参数一的条件概率,再输出条件概率前k大的要素或所有条件概率大于t的要素,通过要素法条对应关系得到相应的法条。
当条件概率阈值取为0.5时,文本要素模型对图一中裁判文书预测的要素为退赃、退赔,如实供述,诈骗公、私财物行为,自首,被害人谅解,再通过要素法条对应关系得到这些要素对应的法条:《刑法》第266条、第67条,《关于常见犯罪的量刑指导意见》第三部分第4条、第5条、第8条、第9条,《四川省高级人民法院<关于常见犯罪的量刑指导意见>实施细则》第三部分第13条、第15条、第17条、第18条,《关于办理诈骗刑事案件具体应用法律若干问题的解释》第3条。另外,需要说明的是条件概率阈值越大,文本要素模型对一段文本给出的法条越少,但每份所给出的法条适用于此文本的概率都较大;条件概率阈值越小,文本要素模型对一段文本给出的法条越多,但排名靠后的法条适用于此文本的概率较低。
表格2诈骗罪要素及对应法条
表格3离婚纠纷要素及对应法条
以上对本发明的较佳实施方式进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变型或替换,这些等同的变型或替换均包括在本申请权利要求所限定的范围内。
- 强可解释性和时空不变性的智能法条推荐系统
- 自注意力下时空语义间隔感知的POI推荐系统及方法