数据处理方法和装置、服务器及存储介质
文献发布时间:2023-06-19 10:38:35
技术领域
本申请涉及数据处理技术领域,具体而言,涉及一种数据处理方法和装置、服务器及存储介质。
背景技术
目前,SaaS应用的数量逐渐增多,应用商店包含众多的SaaS应用。现有技术在实现SaaS应用部署时,通过基于Jenkins的DevOps将SaaS应用部署到Kubernetes。然而,其没有考虑为用户选择最优应用组合的问题,从而存在着应用分配的效率低的问题。
发明内容
有鉴于此,本申请的目的在于提供一种数据处理方法和装置、服务器及存储介质,以改善现有技术中存在的问题。
为实现上述目的,本申请实施例采用如下技术方案:
第一方面,本发明提供一种数据处理方法,包括:
获取至少一个待分配SaaS应用的标签数据和用户的历史数据;
通过预设推荐算法对所述至少一个待分配SaaS应用的标签数据和用户的历史数据进行推荐处理,得到所述用户对应的SaaS应用;
对所述用户对应的SaaS应用进行部署。
在可选的实施方式中,所述通过预设推荐算法对所述至少一个待分配SaaS应用的标签数据和用户的历史数据进行推荐处理,得到所述用户对应的SaaS应用的步骤,包括:
根据至少一个所述待分配SaaS应用的标签数据提取得到各所述待分配SaaS应用的特征向量,根据所述用户的历史数据提取得到所述用户的特征向量;
根据各所述待分配SaaS应用的特征向量和所述用户的特征向量计算得到各所述待分配SaaS应用与所述用户之间的匹配度;
根据所述匹配度从至少一个所述待分配SaaS应用中得到所述用户对应的SaaS应用。
在可选的实施方式中,所述根据各所述待分配SaaS应用的特征向量和所述用户的特征向量计算得到各所述待分配SaaS应用与所述用户之间的匹配度的步骤,包括:
针对每一个待分配SaaS应用,根据该待分配SaaS应用的特征向量计算得到该待分配SaaS应用的词频向量;
根据所述用户的特征向量计算得到所述用户的词频向量;
根据该待分配SaaS应用的词频向量和所述用户的词频向量计算得到该待分配SaaS应用与所述用户之间的匹配度。
在可选的实施方式中,所述根据所述匹配度从至少一个所述待分配SaaS应用中得到所述用户对应的SaaS应用的步骤,包括:
根据所述匹配度对至少一个所述待分配SaaS应用进行排序处理,将匹配度最高的待分配SaaS应用作为所述用户对应的SaaS应用。
在可选的实施方式中,所述对所述用户对应的SaaS应用进行部署的步骤,包括:
根据所述用户的至少一个目标主机的可分配资源数据和所述SaaS应用的资源需求数据计算得到各所述目标主机与所述SaaS应用之间的匹配度;
根据所述匹配度将所述SaaS应用部署到对应的目标主机。
在可选的实施方式中,所述数据处理方法还包括获取所述用户的至少一个目标主机的步骤,该步骤包括:
获取所述用户的所有主机;
根据所述SaaS应用的资源需求数据对所述所有主机进行筛选处理,得到至少一个目标主机。
在可选的实施方式中,所述根据所述匹配度将所述SaaS应用部署到对应的目标主机的步骤,包括:
根据所述匹配度对所述至少一个目标主机进行排序处理,将所述SaaS应用部署到匹配度最高的目标主机。
第二方面,本发明提供一种数据处理装置,包括:
数据获取模块,用于获取至少一个待分配SaaS应用的标签数据和用户的历史数据;
数据处理模块,用于通过预设推荐算法对所述至少一个待分配SaaS应用的标签数据和用户的历史数据进行推荐处理,得到所述用户对应的SaaS应用;
应用部署模块,用于对所述用户对应的SaaS应用进行部署。
第三方面,本发明提供一种服务器,包括存储器和处理器,所述处理器用于执行所述存储器中存储的可执行的计算机程序,以实现前述实施方式任意一项所述的数据处理方法。
第四方面,本发明提供一种存储介质,其上存储有计算机程序,该程序被执行时实现前述实施方式任意一项所述数据处理方法的步骤。
本申请实施例提供的数据处理方法和装置、服务器及存储介质,通过预设推荐算法进行推荐处理,得到用户对应的SaaS应用,对SaaS应用进行部署,实现了自动为用户推荐最优SaaS应用,改善了现有技术中没有考虑为用户选择最优应用的问题,所导致的应用分配的效率低的问题。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本申请实施例提供的数据处理系统的结构框图。
图2为本申请实施例提供的数据处理方法的流程示意图。
图3为本申请实施例提供的数据处理方法的另一流程示意图。
图4为本申请实施例提供的数据处理方法的另一流程示意图。
图5为本申请实施例提供的数据处理方法的另一流程示意图。
图6为本申请实施例提供的数据处理装置的结构框图。
图标:10-数据处理系统;100-服务器;200-工业设备;600-数据处理装置;610-数据获取模块;620-数据处理模块;630-应用部署模块。
具体实施方式
在工业互联网环境之下,用户通常不希望面临复杂的开发、测试过程,而是能够根据业务按需快速批量部署自己的SaaS应用,实现自己的功能,所以SaaS应用的部署就具有以下特征:
1、按需选择SaaS应用,提供商需提供常用的SaaS应用并且用户根据业务选择需要的SaaS应用,如微服务架构Spring Cloud在技术上支撑功能的更细粒度化,给用户更细粒度化的按需选择。
2、快速部署SaaS应用,用户能够快速完成部署SaaS应用,如采用Docker、Kubernetes、DevOps等技术实现SaaS应用的快速部署。
3、批量部署SaaS应用,用户一般会有多种功能需求,需要同时部署多个SaaS应用,只需Web页面勾选,就能批量部署。
4、SaaS应用的用户级别隔离,不同用户的SaaS应用相互之间不影响。
现有技术中提供了一种基于容器的SaaS应用部署方案,其先根据产品需求设计业务逻辑获得各种SaaS应用功能设计;基于Jenkins CICD和容器的方式完成SaaS应用的开发、测试,并将测试合格的镜像保存;当用户需要某个SaaS应用的功能时,拉取测试成功的镜像,部署SaaS应用到Kubernetes;分配能够访问SaaS应用的域名;将部署结果返回给用户。
然而,现有技术中的技术方案没有考虑为用户选择最优应用组合的问题和SaaS应用调度到最合适主机的问题。目前,SaaS应用的应用商店包含众多的SaaS应用,用户在部署时急需一种机制,帮助用户选择最合适的应用组合。并且,如果没有好的调度机制,应用将会被调度到资源匮乏或类型不匹配的主机,导致SaaS应用始终无法正确启动。
为了改善本申请所提出的上述至少一种技术问题,本申请实施例提供一种数据处理方法和装置、服务器及存储介质,下面通过可能的实现方式对本申请的技术方案进行说明。
针对以上方案所存在的缺陷,均是发明人在经过实践并仔细研究后得出的结果,因此,上述问题的发现过程以及本申请针对上述问题所提出的解决方案,都应该是发明人在本申请过程中对本申请做出的贡献。
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
图1为本申请实施例提供的数据处理系统10的结构框图,其提供了一种数据处理系统10可能的实现方式,参见图1,该数据处理系统10可以包括服务器100、工业设备200中的一种或多种。
其中,服务器100通过预设推荐算法从至少一个待分配SaaS应用中得到用户对应的SaaS应用,将用户对应的SaaS应用部署到用户的工业设备200。
对于服务器100,需要说明的是,在一些实施例中,服务器100可以是单个服务器设备,也可以是服务器组。服务器组可以是集中式的,也可以是分布式的(例如,服务器100可以是分布式系统)。在一些实施例中,服务器100相对于工业设备200,可以是本地的、也可以是远程的。例如,服务器100可以经由网络访问存储在工业设备200中的信息和/或数据。作为另一示例,服务器100可以直接连接到工业设备200,以访问存储的信息和/或数据。在一些实施例中,服务器100可以在云平台上实现。仅作为示例,云平台可以包括私有云、公有云、混合云、弹性云、社区云(community cloud)、分布式云、跨云(inter-cloud)、多云(multi-cloud)等,或者它们的任意组合。在一些实施例中,服务器100可以在工业设备200上实现。
在一些实施例中,服务器100可以包括处理器。处理器可以处理工业设备200发送的信息和/或数据,以执行本申请中描述的一个或多个功能。
服务器100中可以包括数据库,数据库可以存储数据和/或指令。在一些实施例中,数据库可以存储从工业设备200获得的数据。在一些实施例中,数据库可以存储本申请中描述的示例性方法的数据和/或指令。在一些实施例中,数据库可以在云平台上实现。仅作为示例,云平台可以包括私有云、公有云、混合云、社区云、分布式云、跨云、多云、弹性云或者其它类似的等,或其任意组合。
在一些实施例中,数据库可以连接到网络以与数据处理系统10(例如,服务器100和工业设备200)中的一个或多个组件通信。数据处理系统10中的一个或多个组件可以经由网络访问存储在数据库中的数据或指令。在一些实施例中,数据库可以直接连接到数据处理系统10中的一个或多个组件(例如,服务器100和工业设备200)。或者,在一些实施例中,数据库也可以是服务器100的一部分。在一些实施例中,数据处理系统10中的一个或多个组件(例如,服务器100和工业设备200)可以具有访问数据库的权限。
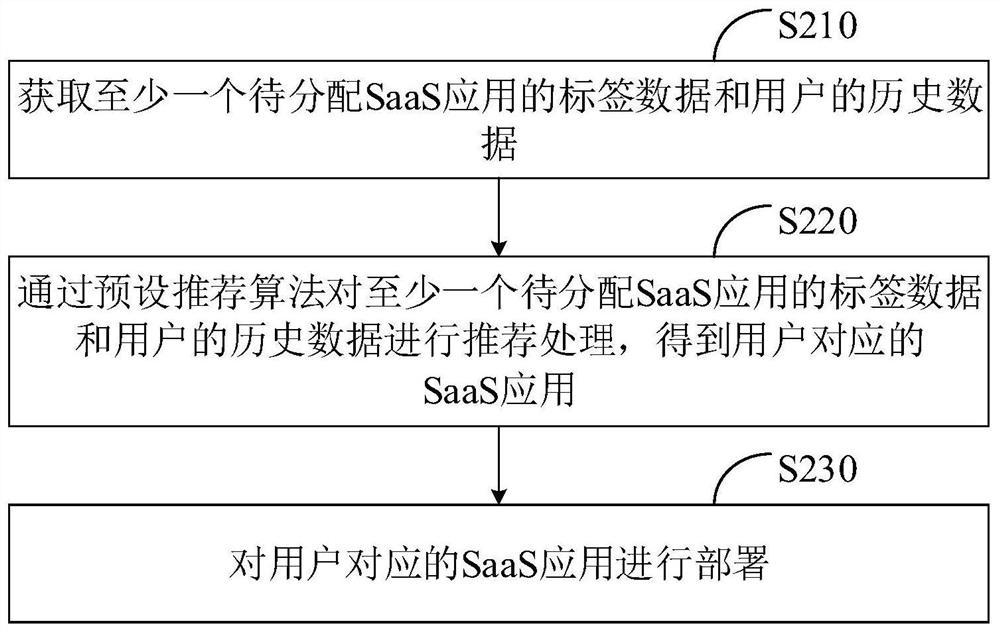
图2示出了本申请实施例所提供的数据处理方法的流程图之一,该方法可应用于图1所示的服务器100,由图1中的服务器100执行。应当理解,在其他实施例中,本实施例的数据处理方法中的部分步骤的顺序可以根据实际需要相互交换,或者其中的部分步骤也可以省略或删除。下面对图2所示的数据处理方法的流程进行详细描述。
步骤S210,获取至少一个待分配SaaS应用的标签数据和用户的历史数据。
步骤S220,通过预设推荐算法对至少一个待分配SaaS应用的标签数据和用户的历史数据进行推荐处理,得到用户对应的SaaS应用。
步骤S230,对用户对应的SaaS应用进行部署。
上述方法通过预设推荐算法进行推荐处理,得到用户对应的SaaS应用,对SaaS应用进行部署,实现了自动为用户推荐最优SaaS应用,改善了现有技术中没有考虑为用户选择最优应用的问题,所导致的应用分配的效率低的问题。
需要说明的是,可以在步骤S210之前对应用商店的所有待分配SaaS应用按照{应用名,类型,功能标签,平均分,资源配置,偏好,应用介绍}的格式打上标签。其中,功能标签是一个大类,是应用的分类标签,表明应用的用途,比如生产设备的监控功能标签下面可以对应很多个类似的应用,只是适应不同的行业,例如,监控功能标签可以对应汽车制造业设备监控、纺织业设备监控等应用。资源配置可以包括GPU、CPU、内存资源的配置,分低、中、高三种类型,每种类型的GPU、CPU、内存资源的配置逐渐增大。用户也可以根据需求修改默认值,指定应用需要的资源多一些,例如,图像识别的应用就会需要GPU资源和更多的内存,可以给图像识别的应用资源配置设置为高,就会将GPU资源和内存配置更多。
对于步骤S210,需要说明的是,在一种可以替代的示例中,待分配SaaS应用的标签数据可以为{“应用名”:“SaaS应用1”,“类型”:“Python”,“功能标签”:“图像识别”,“平均分”:“5”,“资源配置”:“中”,“偏好”:[“GPU”,“内存”],“应用介绍”:“这是一款图像识别应用,用于识别机器的LED读数”}。
可选地,用户的历史数据可以包括,但不限于用户的行业背景、网站上的浏览习惯、用户勾选或输入的功能标签等数据。也就是说,在获取用户勾选或输入需要的多个功能标签关键词之后,服务器100上包括的DevOps平台可以根据用户的行业背景、网站上的浏览习惯、用户勾选或输入的功能标签,结合基于用户的协同过滤算法(即预设推荐算法),推荐最合适的应用组合,用户可以点击一键批量部署并能看到每个应用的部署进度。
对于步骤S220,需要说明的是,进行推荐处理的具体方式不受限制,可以根据实际应用需求进行设置。例如,在一种可以替代的示例中,步骤S220可以包括根据匹配度进行分配的步骤。因此,在图2的基础上,图3为本申请实施例提供的另一种数据处理方法的流程示意图,参见图3,步骤S220可以包括:
步骤S221,根据至少一个待分配SaaS应用的标签数据提取得到各待分配SaaS应用的特征向量,根据用户的历史数据提取得到用户的特征向量。
步骤S222,根据各待分配SaaS应用的特征向量和用户的特征向量计算得到各待分配SaaS应用与用户之间的匹配度。
步骤S223,根据匹配度从至少一个待分配SaaS应用中得到用户对应的SaaS应用。
对于步骤S221,需要说明的是,在一种可以替代的示例中,用户的特征向量可以为Customer=[行业背景,网站上的浏览习惯,用户勾选、输入的功能标签],待分配SaaS应用的特征向量可以为App=[应用名,功能标签,应用介绍]。
对于步骤S222,需要说明的是,计算匹配度的具体方式不受限制,可以根据实际应用需求进行设置。例如,在一种可以替代的示例中,步骤S222可以包括根据词频向量计算匹配度的步骤。也就是说,可以将用户的特征向量和待分配SaaS应用的特征向量进行分词处理,放入一个词袋,计算词频,然后计算用户和待分配SaaS应用词频向量的余弦距离,获得相似度匹配,匹配度越高,越被推荐。因此,在图3的基础上,图4为本申请实施例提供的另一种数据处理方法的流程示意图,参见图4,步骤S222可以包括:
步骤S2221,针对每一个待分配SaaS应用,根据该待分配SaaS应用的特征向量计算得到该待分配SaaS应用的词频向量。
步骤S2222,根据用户的特征向量计算得到用户的词频向量。
步骤S2223,根据该待分配SaaS应用的词频向量和用户的词频向量计算得到该待分配SaaS应用与用户之间的匹配度。
详细地,在用户特征向量=[“汽车制造业”,“设备监控”,“汽车”,“电热恒温干燥箱”],待分配SaaS应用特征向量=[“汽车电热恒温干燥箱温湿度监控”,“设备监控”,“监控电热恒温干燥箱的温湿度”]时,词库={“汽车”,“制造业”,“设备”,“监控”,“电热”,“恒温”,“干燥箱”,“温湿度”,“的”},用户词频={“汽车”*2,“制造业”*1,“设备”*1,“监控”*1,“电热”*1,“恒温”*1,“干燥箱”*1,“温湿度”*0,“的”*0},待分配SaaS应用词频=={“汽车”*1,“制造业”*0,“设备”*1,“监控”*3,“电热”*2,“恒温”*2,“干燥箱”*2,“温湿度”*2,“的”*1},用户词频向量=[2,1,1,1,1,1,1,0,0],待分配SaaS应用词频向量=[1,0,1,3,2,2,2,2,1]。根据待分配SaaS应用的词频向量和用户的词频向量计算得到匹配度:
对于步骤S223,需要说明的是,得到用户对应的SaaS应用的具体方式不受限制,可以根据实际应用需求进行设置。例如,在一种可以替代的示例中,用户对应的SaaS应用的数量为一个,步骤S223可以包括以下子步骤:
根据匹配度对至少一个待分配SaaS应用进行排序处理,将匹配度最高的待分配SaaS应用作为用户对应的SaaS应用。
在另一种可以替代的示例中,用户对应的SaaS应用的数量可以为多个(一组应用列表)。例如,用户注册时选择汽车制造业背景,平时浏览的工业应用都是汽车制造业的,关键词是设备监控,用户选择了一个设备监控应用,则通过基于用户的协同过滤算法的计算,可以推荐其他用户评分好并且和汽车制造相关的工业应用给当前用户。用户通过选择不同的应用,获得一组应用列表,提交给DevOps平台。用户在体验应用之后,提示用户对使用过的应用评分,方便以后DevOps平台为其他用户进行应用推荐。
进一步地,DevOps平台可以创建批量SaaS应用的部署请求对象,即Kubernetes的Custom Resource Definition(CRD),以保存用户的部署请求。
对于步骤S230,需要说明的是,本申请实施例的工业设备200可以包括主机,进行部署的具体方式不受限制,可以根据实际应用需求进行设置。例如,在一种可以替代的示例中,步骤S230可以包括根据匹配度进行部署的步骤。因此,在图2的基础上,图5为本申请实施例提供的另一种数据处理方法的流程示意图,参见图5,步骤S230可以包括:
步骤S231,根据用户的至少一个目标主机的可分配资源数据和SaaS应用的资源需求数据计算得到各目标主机与SaaS应用之间的匹配度。
步骤S232,根据匹配度将SaaS应用部署到对应的目标主机。
在步骤S231之前,需要说明的是,本申请实施例提供的数据处理方法还可以包括获取用户的至少一个目标主机的步骤,该步骤可以包括以下子步骤:
获取用户的所有主机;
根据SaaS应用的资源需求数据对所有主机进行筛选处理,得到至少一个目标主机。
详细地,Kubernetes自定义资源控制器可以通过Watch-List机制,监测有新的SaaS批量部署请求CRD对象,触发部署流程。资源需求数据可以包括功能标签、资源类型和资源大小,也就是说,可以根据SaaS批量部署请求CRD对象获取每个SaaS应用的功能标签、资源类型和资源大小。根据每个SaaS应用的功能标签和资源类型,从Kubernetes集群用户的所有主机中获取符合条件的候选主机组List1={host1,host2,host3…}和其可分配的GPU、CPU、内存资源,根据每个SaaS应用的功能标签和对资源类型的需求,筛选主机类型,获取符合条件的主机列表。优先选择具有匹配资源的主机,如需要图像处理的应用,优先部署到GPU主机,如果没有GPU资源的主机,则应用部署到普通CPU主机。在主机组List1的基础上,根据应用的资源大小,筛选符合部署的TopN主机,得到目标主机列表List2。
对于步骤S231,需要说明的是,获取目标主机列表List2中每个目标主机的可分配资源量{Rcpu_rest,Rgpu_rest,Rmem_rest}和每个SaaS应用所需各种资源量{Rcpu_app,Rgpu_app,Rmem_app},并通过匹配度公式计算每个SaaS应用部署到一台目标主机的匹配度:
其中,*表示GPU、CPU、内存资源中的一种,内存资源的单位为GB,α、β及γ为权重且三个权重的和为1。可以根据每个SaaS应用对不同资源的偏重,配置不同的α、β及γ权重,如需要使用CPU的应用,α和γ的值会配置比较大,β值会比较小。
对于步骤S232,需要说明的是,根据匹配度进行部署的具体方式不受限制,可以根据实际应用需求进行设置。例如,在一种可以替代的示例中,部署的目标主机的数量为一个时,步骤S232可以包括以下子步骤:
根据匹配度对至少一个目标主机进行排序处理,将SaaS应用部署到匹配度最高的目标主机。
又例如,在另一种可以替代的示例中,部署的目标主机的数量为多个时,可以根据匹配度,获取排名靠前的TopN主机。然后,根据每个SaaS应用的功能标签、资源类型、资源大小和部署的TopN主机渲染每个SaaS应用的部署脚本,再将每个SaaS应用的部署脚本发送给Kubernetes。Kubernetes根据每个SaaS应用的部署脚本在自己的TopN主机中尝试部署,先部署在Top1主机,如果部署不成功,则尝试部署在Top2主机,直到尝试完N个主机,如果部署尝试都失败,则提示此应用部署失败,否则部署成功。
进一步地,在部署成功之后,可以更新批量部署记录,包括此次批量部署的SaaS应用和其配置,下次有相同批量部署,则直接进行再次部署。对部署失败的SaaS应用置为失败,并提示用户查看日志以进行重新部署,用户可以进入不同的SaaS应用,查看其日志和监控指标。
结合图6,本申请实施例还提供了一种数据处理装置600,该数据处理装置600实现的功能对应上述方法执行的步骤。该数据处理装置600可以理解为上述服务器100的处理器,也可以理解为独立于上述服务器100或处理器之外的在服务器100控制下实现本申请功能的组件。其中,数据处理装置600可以包括数据获取模块610、数据处理模块620和应用部署模块630。
数据获取模块610,用于获取至少一个待分配SaaS应用的标签数据和用户的历史数据。在本申请实施例中,数据获取模块610可以用于执行图2所示的步骤S210,关于数据获取模块610的相关内容可以参照前文对步骤S210的描述。
数据处理模块620,用于通过预设推荐算法对至少一个待分配SaaS应用的标签数据和用户的历史数据进行推荐处理,得到用户对应的SaaS应用。在本申请实施例中,数据处理模块620可以用于执行图2所示的步骤S220,关于数据处理模块620的相关内容可以参照前文对步骤S220的描述。
应用部署模块630,用于对用户对应的SaaS应用进行部署。在本申请实施例中,应用部署模块630可以用于执行图2所示的步骤S230,关于应用部署模块630的相关内容可以参照前文对步骤S230的描述。
此外,本申请实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述数据处理方法的步骤。
本申请实施例所提供的数据处理方法的计算机程序产品,包括存储了程序代码的计算机可读存储介质,程序代码包括的指令可用于执行上述方法实施例中的数据处理方法的步骤,具体可参见上述方法实施例,在此不再赘述。
综上所述,本申请实施例提供的数据处理方法和装置、服务器及存储介质,通过预设推荐算法进行推荐处理,得到用户对应的SaaS应用,对SaaS应用进行部署,实现了自动为用户推荐最优SaaS应用,改善了现有技术中没有考虑为用户选择最优应用的问题,所导致的应用分配的效率低的问题。
以上仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 一种数据处理方法、第一服务器、第二服务器与存储介质
- 数据处理方法、装置、服务器及存储介质