一种面向遥感图像语义分割的深度学习模型的训练方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及遥感图像解译技术领域,尤其是涉及一种面向遥感图像语义分割的深度学习模型的训练方法。
背景技术
遥感图像是自然资源调查、监测和管理的重要数据源。基于深度学习的遥感图像语义分割能够大幅提升遥感解译的精度和效率,为提升自然资源调查监管决策能力,建立高效、完善的自然资源遥感监测服务体系能够提供更为先进的技术手段。
相比传统语义分割方法如纹理基元森林和随机森林,现有的基于深度学习的语义分割方法能够得到高精度、高效率、自动化的提取结果。然而,深度学习模型的预测效果往往和所提供的样本质量和训练过程中的调参以及优化息息相关。一方面,深度学习算法工程师需要提供经过精细化标注的样本给模型训练,然而遥感图像具有信息量大、像素关联性大、不易评判等特点,导致针对遥感图像的标注结果容易受到标注人员主观性的影响,因此,遥感图像精细化的样本标注成本往往比较高昂,不易获取;第二方面,在训练过程中为了使模型达到更好的精度和泛化能力,需要算法工程师全程跟踪训练进度以及时调整参数使得神经网络在不过度浪费资源的情况下能够及时收敛并停止训练,这样的模型训练过程往往耗时耗力;最后一方面,使用一个模型对目标图像预测时,如果目标图像数据和样本数据不在一个数据领域,往往会因为单一模型的泛化能力有限,导致预测结果不佳。
发明内容
本发明所要解决的技术问题是提供一种面向遥感图像语义分割的深度学习模型的训练方法,该方法能够简化深度学习模型的搭建流程、加快深度学习模型训练的速度、增加模型的泛化能力以及减少深度学习算法工程师在训练过程中的调参工作,尤其适用于遥感图像训练样本标注质量低的情况。
本发明所采用的技术方案是,一种面向遥感图像语义分割的深度学习模型的训练方法,该方法包括下列步骤:
S1. 裁剪遥感图像以及对应的标签,生成训练样本集;
S2. 构建基于编码器-解码器的深度学习模型架构;
S3. 通过所述深度学习模型架构在所述训练样本集上训练出一个样本过滤模型;
S4. 使用所述样本过滤模型来对训练样本集中的样本进行预测,得到训练样本集中样本的预测结果,通过将所述训练样本集中样本的预测结果和训练样本集中样本对应的标签进行对比,挑选出训练样本集中标注质量高的优质样本,并形成优质样本集;
S5. 使用所述深度学习模型架构来交替训练所述训练样本集和所述优质样本集,使用特定的学习率调整方案和优化器,来得到经过训练的预测模型;
S6. 重复步骤S4~S5,得到多个经过训练的预测模型,并将这些经过训练的预测模型组成模型池;
S7. 获取任意一张目标遥感图像,将该目标遥感图像输入到所述模型池中,基于模型池使用模型并行集成的方式预测出目标遥感图像中的要素,并采用平均法得到目标遥感图像的二值图结果。
本发明的有益效果是:上述面向遥感图像语义分割的深度学习模型的训练方法,简化了深度学习模型的搭建流程,加快深度学习模型训练的速度,增加模型的泛化能力以及减少深度学习算法工程师在训练过程中的调参工作,尤其适用于遥感图像训练样本标注质量低的情况。
作为优选,在步骤S2中,基于编码器-解码器的深度学习模型架构由编码器和解码器构成。编码器为在拥有若干样本的训练样本集上训练得到的预训练模型,因此在模型迁移上有比较好的泛化性。所述模型迁移是迁移学习的一种,能够把预训练模型在原数据域学习到的权重应用在数据量较小的目标域数据上,实现权重初始化,加快模型在目标域数据上的训练速度。
解码器为卷积神经网络,可以利用编码器提取的特征来生成高维度的输出序列,进而得到二值图结果。
作为优选,在步骤S3中,在训练样本过滤模型的过程中,使用了若干个数据增强方案,这样能够提高模型的泛化能力,并且避免模型过拟合。
数据增强方案包括四周镜像填充、随机裁切、随机亮度和对比度、随机伽马、随机信息丢失、运动模糊、中值模糊、高斯模糊、高斯噪声、水平翻转、竖直翻转以及随机缩放旋转。
作为优选,在步骤S4中,优质样本的挑选是根据训练样本集中的样本与其对应的预测结果之间的交并比来进行挑选的,一个优质样本必须满足训练样本集中的样本与其对应的预测结果之间的交并比大于既定阈值。
作为优选,在步骤S5中,使用深度学习模型架构来交替训练训练样本集和优质样本集的过程中使用了若干个数据增强方案,通过使用数据增强方案可以提高模型的泛化能力,避免模型过拟合。
作为优选,在步骤S5中,学习率调整方案为基于余弦退火的学习率调整方案,使用学习率调整方案和优化器来得到经过训练的预测模型的具体步骤包括:
SA1.设置最大学习率和最小学习率,以13轮为半个周期,进行1.5个周期的学习,共39轮;
SA2.调整最大学习率为其最大值的五分之一,使用线性预热的学习率调整方式训练,共1轮;
SA3.使用余弦退火的学习率调整方案训练半个周期,共13轮。
所述优化器为Lookahead优化器,该优化器的内部优化器为Adam,该优化器使模型能够更快地收敛、具有更好的泛化性能,且对超参数改变的鲁棒性更强。
作为优选,在步骤S5中,使用所述深度学习模型架构来交替训练训练样本集和优质样本集的具体步骤为:
SB1.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为384*384,重复5轮;
SB2.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为384*384,重复2轮;
SB3.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为480*480,重复2轮;
SB4.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为512*512,重复2轮;
SB5.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为480*480,重复1轮;
SB6.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为512*512,重复1轮;
这种交替训练配合随机裁切的数据增强方案能够有效地增强模型的泛化能力,加快模型的
训练速度。
作为优选,在步骤S7中,平均法平均了模型池中的各模型在目标遥感图像上的表示,能够减小单个预测模型的预测结果的偏置,从而提升并行集成后的模型在目标遥感图像上的交并比。
附图说明
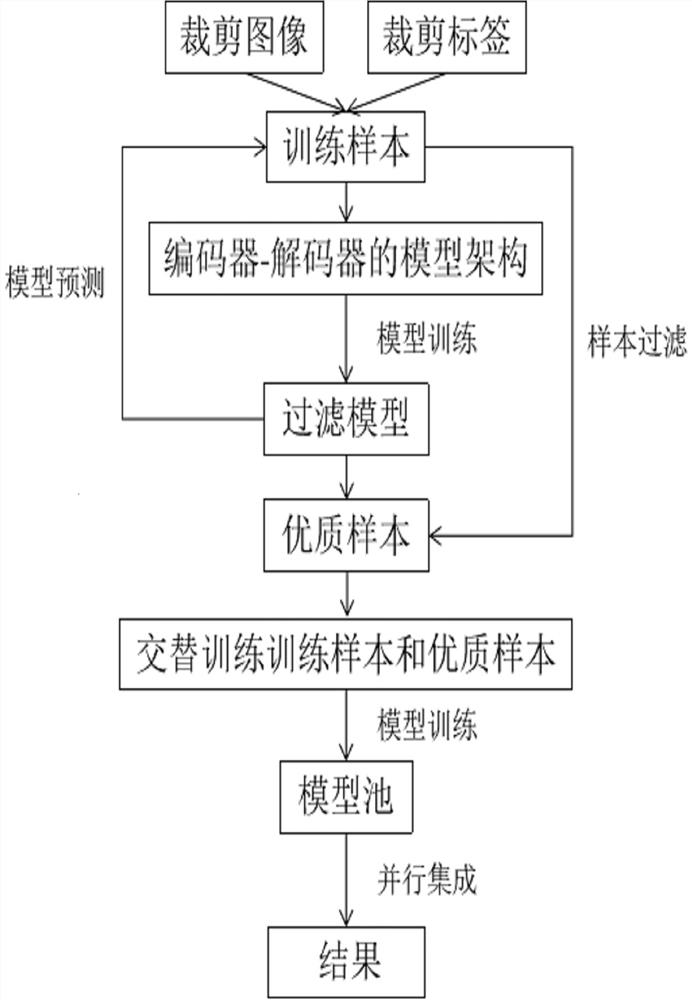
图1为本发明一种面向遥感图像语义分割的深度学习模型的训练方法的流程图;
图2为本发明中基于编码器-解码器的深度学习模型架构的结构示意图;
图3为本发明中学习率调整方案的学习率示意图;
图4为本发明中使用深度学习模型架构交替训练训练样本集和优质样本集的训练方法示意图。
具体实施方式
以下参照附图并结合具体实施方式来进一步描述发明,以令本领域技术人员参照说明书文字能够据以实施,本发明保护范围并不受限于该具体实施方式。
本领域技术人员应理解的是,在本发明的公开中,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底” “内”、“外”等指示的方位或位置关系是基于附图所示的方位或位置关系,其仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此上述术语不能理解为对本发明的限制。
本发明涉及一种面向遥感图像语义分割的深度学习模型的训练方法,如图1所示,该方法包括下列步骤:
S1.裁剪遥感图像以及对应的标签,生成训练样本集;
S2.构建基于编码器-解码器的深度学习模型架构;
S3.通过采用步骤S2中的深度学习模型架构在步骤S1中得到的训练样本集上训练出一个样本过滤模型;
S4.使用步骤S3中的样本过滤模型来对步骤S1中的训练样本集中的样本进行预测,得到训练样本集中样本的预测结果,通过将所述训练样本集中样本的预测结果和训练样本集中样本的对应标签进行对比,挑选出训练样本集中标注质量高的优质样本,并形成优质样本集;
S5.使用步骤S2中的深度学习模型架构来交替训练步骤S1中的训练样本集和步骤S4中的优质样本集,使用学习率调整方案和优化器,来得到经过训练的预测模型;
S6.重复步骤S4~S5,得到多个经过训练的预测模型,并将这些经过训练的预测模型组成模型池;
S7.获取任意一张目标遥感图像,基于模型池使用模型并行集成的方式预测出目标遥感图像中的要素,并采用平均法得到目标遥感图像的二值图结果。
在步骤S2中,基于编码器-解码器的深度学习模型架构由编码器和解码器构成,编码器为在拥有大量样本的数据集上训练得到的预训练模型,因此在模型迁移上有比较好的泛化性。模型迁移是迁移学习的一种,能够把预训练模型在原数据域学习到的权重应用在数据量较小的目标域数据上,实现权重初始化,加快模型在目标域数据上的训练速度。
解码器为卷积神经网络,它可以利用编码器提取的特征来生成高维度的输出序列,进而得到二值图结果。
在步骤S3中,在训练样本过滤模型的过程中,使用了大量的数据增强方案,这样能够提高模型的泛化能力,并且避免模型过拟合。
数据增强方案包括四周镜像填充、随机裁切、随机锐化、随机亮度和对比度、随机伽马、随机信息丢失、运动模糊、中值模糊、高斯模糊、高斯噪声、水平翻转、竖直翻转以及随机缩放旋转。
在步骤S4中,优质样本的挑选是基于训练样本集中的样本与其对应的预测结果间的交并比来进行的,一个优质样本必须满足交并比大于既定阈值。
在步骤S5中,使用深度学习模型架构交替训练的过程中使用了数据增强方案,通过使用数据增强方案可以提高模型的泛化能力、避免模型过拟合。
作为优选,在步骤S5中,学习率调整方案为基于余弦退火的学习率调整方案,使用学习率调整方案和优化器来得到经过训练的预测模型的具体步骤包括:
SA1.设置最大学习率和最小学习率,以13轮为半个周期,进行1.5个周期的学习,共39轮;
SA2.调整最大学习率为其最大值的五分之一,使用线性预热的学习率调整方式训练,共1轮;
SA3.使用余弦退火的学习率调整方案训练半个周期,共13轮。
优化器为Lookahead优化器,其内部优化器为Adam,该优化器使模型能够更快地收敛、具有更好的泛化性能,且对超参数改变的鲁棒性更强。
作为优选,在步骤S5中,使用深度学习模型架构来交替训练训练样本集和优质样本集的具体步骤包括:
SB1.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为384*384,重复5轮;
SB2.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为384*384,重复2轮;
SB3.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为480*480,重复2轮;
SB4.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为512*512,重复2轮;
SB5.训练训练样本集并应用随机裁切的数据增强方案,裁切大小为480*480,重复1轮;
SB6.训练优质样本集并应用随机裁切的数据增强方案,裁切大小为512*512,重复1轮,合计13轮为半个周期。
这种交替训练配合随机裁切的数据增强方案能够有效地增强模型的泛化能力,加快模型的训练速度。
在步骤S7中,平均法平均了模型池中的各模型在目标遥感图像上的表示,能够减小单个预测模型的预测结果的偏置,从而提升并行集成后的模型在目标遥感图像上的交并比。
在下述实施例中,针对具体遥感图像中的要素水体进行识别,数据来源是分辨率为0.5m的高分遥感影像数据,格式是RGB三通道图像。利用本发明的方法提取其中的水体的具体实施步骤如下:
(1).将一张分辨率为10000*10000的遥感图像分割成若干张分辨率为492*492的JPG格式的样本图片,将遥感图像对应的标签转换为单通道的二值图,同样裁剪为492*492的JPG格式的标签图片,且要求该标签图片与对应位置的样本图片的像素对齐;
(2).如图2所示,构建基于编码器-解码器的深度学习模型架构;优选EfficientNet-b4在ImageNet上的预训练模型作为编码器;优选LinkNet卷积神经网络作为解码器;
(3).通过深度学习模型架构在训练样本集上训练出一个样本过滤模型;在训练过程中采用Lookahead优化器并采用图3所示的学习率调整方案训练一个周期,优选最大学习率为0.002,最小学习率为0.0001,一共训练26轮;在每一轮中应用指定发生概率的数据增强方案,优选的数据增强方案包括:
(3-1).在水平翻转、竖直翻转中选其一,概率为100%;
(3-2).随机高斯噪声,概率为20%;
(3-3).在随机亮度和对比度、随机伽马中选其一,概率为100%;
(3-4).在随机锐化、高斯模糊以及动态模糊中选其一,概率为100%;
(3-5).随机信息丢失,概率为20%;
(3-6).随机旋转缩放,概率为100%;
(4).使用样本过滤模型预测所述训练样本集,通过对比训练样本集中样本的预测结果和训练样本集中样本的对应标签,挑选出训练样本集中交并比大于80%的样本加入到优质样本集中;
(5).使用深度学习模型架构在训练样本集和优质样本集上交替训练,交替训练方案如图4所示,具体步骤包括:
(5-1).训练优质样本集并应用随机裁切的数据增强方案,裁切大小优选384*384,批大小为16,重复5轮;
(5-2).训练训练样本集并应用随机裁切的数据增强方案,裁切大小优选384*384,批大小为16,重复2轮;
(5-3).训练优质样本集并应用随机裁切的数据增强方案,裁切大小优选480*480,批大小为16,重复2轮;
(5-4).训练训练样本集并应用随机裁切的数据增强方案,裁切大小优选512*512,批大小为8,重复2轮;
(5-5).训练优质样本集并应用随机裁切的数据增强方案,裁切大小优选480*480,批大小为8,重复1轮;
(5-6).训练训练样本集并应用随机裁切的数据增强方案,裁切大小优选512*512,批大小为8,重复1轮;总共13轮为半个训练周期;
(6).交替训练的过程中使用如图3所示的学习率调整方案,具体步骤包括:
(6-1).优选最大学习率为0.002和最小学习率为0.0001,以13轮为半个训练周期;优选进行1.5个周期的学习,共39轮;
(6-2).调整最大学习率,优选0.0004,使用线性预热的学习率调整方式训练1轮;
(6-3).使用余弦退火的学习率调整方案训练半个周期,共13轮;同时使用Lookahead作为优化器,经过总共53轮的训练后得到经过训练的预测模型;
(7).重复步骤(4)~(6),得到3个经过训练的预测模型,组成模型池;
(8).基于模型池使用模型并行集成的方式对目标遥感图像进行预测并采用平均法得到水体的预测结果。
图4中,训练集为模型输入的训练样本集,其中A为优质样本集,B为训练样本集,图像尺寸为应用随机裁切后的样本尺寸,批大小为模型训练中所需要的样本图片数量。
- 一种面向遥感图像语义分割的深度学习模型的训练方法
- 一种面向遥感图像语义分割的深度学习模型的训练方法