数据结构化方法、装置、计算机设备及存储介质
文献发布时间:2023-06-19 11:45:49
技术领域
本申请涉及数据处理技术领域,特别涉及数据结构化方法、装置、计算机设备及存储介质。
背景技术
数据结构化是指将非结构化的文本输入,或者以及半结构化的文本输入,通过结构化后输出有利于数据分析以及挖掘的数据形式。
在相关技术中,在对非结构化或半结构化的文本进行数据结构化处理时,通常基于文本相似度的匹配方法,或者,基于现有的语言模型进行标准化表达,来达到对数据进行结构化的目的。
然而,上述进行数据结构化的方法,在进行数据结构化的过程中仅依赖于实体对应的文字内容进行相似度的匹配,数据利用率较低,各个实体之间的关系较为模糊,从而使得数据结构化的准确性较低,可解释性较差。
发明内容
本申请实施例提供了一种数据结构化方法、装置、计算机设备及存储介质,可以提高数据结构化的准确性以及可解释性,该技术方案如下。
一方面,提供了一种数据结构化方法,所述方法包括:
获取待处理数据,所述待处理数据用以描述目标对象对应的指定类型事件;
获取所述待处理数据中的至少两个时间节点,以及至少两个所述时间节点各自对应的至少一个实体;所述实体是在对应的所述时间节点上发生的所述指定类型事件的命名实体;
基于至少两个所述时间节点,以及至少两个所述时间节点各自对应的至少一个所述实体,确定至少一条实体转移路径;同一所述实体转移路径中的各个所述实体对应的所述时间节点不同;
获取至少一条所述实体转移路径对应的路径概率;所述路径概率用以指示所述实体转移路径中的各个所述实体对应的所述指定类型事件依次发生的概率;
基于至少一条所述实体转移路径对应的路径概率,生成所述待处理数据对应的结构化文本。
另一方面,提供了一种数据结构化装置,所述装置包括:
第一获取模块,用于获取待处理数据,所述待处理数据用以描述目标对象对应的指定类型事件;
第二获取模块,用于获取所述待处理数据中的至少两个时间节点,以及至少两个所述时间节点各自对应的至少一个实体;所述实体是在对应的所述时间节点上发生的所述指定类型事件的命名实体;
实体转移路径确定模块,用于基于至少两个所述时间节点,以及至少两个所述时间节点各自对应的至少一个所述实体,确定至少一条实体转移路径;同一所述实体转移路径中的各个所述实体对应的所述时间节点不同;
路径概率获取模块,用于获取至少一条所述实体转移路径对应的路径概率;所述路径概率用以指示所述实体转移路径中的各个所述实体对应的所述指定类型事件依次发生的概率;
结构化文本生成模块,用于基于至少一条所述实体转移路径对应的路径概率,生成所述待处理数据对应的结构化文本。
在一种可能的实现方式中,所述实体转移路径确定模块,包括:
时间序列建立子模块,用于基于至少两个所述时间节点,以及至少两个所述时间节点各自对应的至少一个所述实体,建立时间序列;所述时间序列用以记录各个所述时间节点对应的所述实体;
实体转移路径确定子模块,用于基于所述时间序列,确定至少一条所述实体转移路径。
在一种可能的实现方式中,所述实体转移路径确定子模块,包括:
目标实体获取单元,用于从至少两个所述时间节点各自对应的至少一个实体中,分别获取一个目标实体;
目标实体转移路径构建单元,用于基于至少两个所述时间节点各自对应的所述目标实体,构建目标实体转移路径,所述目标实体转移路径是至少一条所述实体转移路径中的任意一条。
在一种可能的实现方式中,所述时间序列建立子模块,包括:
术语标准化单元,用于对至少一个所述实体进行术语标准化处理,获得至少一个术语标准化后的所述实体;
时间节点转化单元,用于将至少一个所述实体对应的所述时间节点转化为时序时间节点;
时间序列建立单元,用于基于至少一个术语标准化后的所述实体,以及至少一个所述实体对应的所述时序时间节点,建立所述时间序列。
在一种可能的实现方式中,所述时间节点转化单元,用于获取所述时间节点的记载形式;
对应于所述记载形式,将至少一个所述实体对应的所述时间节点转化为所述时序时间节点。
在一种可能的实现方式中,响应于所述记载形式为时间戳形式,所述时间节点转化单元,用于基于至少一个所述实体对应的所述时间节点进行绝对化时间标记,获得所述时序时间节点。
在一种可能的实现方式中,响应于所述记载形式为非时间戳形式,所述时间节点转化单元,用于获取至少一个所述时间节点中的一个时间节点为参考时间节点;
基于所述参考时间节点,以及其他时间节点与所述参考时间节点之间的时间差,对至少一个所述实体对应的所述时间信息进行相对数字化标记,获得所述时序时间,所述其他时间节点为至少一个所述时间节点中除所述参考时间节点之外的节点。
在一种可能的实现方式中,所述参考时间节点是至少一个所述时间节点中与当前时间节点之间的时间差最长的时间节点;
或者,所述参考时间节点是至少一个所述时间节点中与当前时间节点的时间差最短的时间节点。
在一种可能的实现方式中,所述装置还包括:
时间区间获取模块,用于响应于所述待处理数据中未记载第一实体对应的时间节点,获取对应于所述第一实体的所述指定类型事件所处的时间区间;
时间节点获取模块,用于以实体均匀分布为标准,基于所述时间区间,获取所述第一实体对应的时间节点。
在一种可能的实现方式中,所述时间节点获取模块,包括:
生成顺序获取子模块,用于获取所述第一实体在所述时间区间中的生成顺序;
时间节点获取子模块,用于以实体均匀分布为标准,基于所述时间区间以及所述生成顺序,获取所述第一实体对应的时间节点。
在一种可能的实现方式中,所述路径概率获取模块,包括:
转移概率获取子模块,用于基于目标时间节点之间的时间间隔,获取所述目标实体转移路径中,每m个连续的所述目标实体之间的转移概率;所述转移概率用以指示在m个连续的所述目标实体中,前m-1个目标实体存在的前提下,第m个目标实体对应的所述指定类型事件发生的概率;m为正整数,且m≥2;所述目标时间节点是组成所述目标实体转移路径的所述目标实体对应的所述时间节点;
路径概率获取子模块,用于基于所述转移概率,获取所述目标实体转移路径对应的所述路径概率。
在一种可能的实现方式中,路径概率获取子模块,包括:
出现概率计算单元,用于以所述目标实体转移路径中,已出现前n-1个目标实体为条件,基于所述转移概率,计算第n个目标实体的出现概率;所述出现概率用以指示第n个目标实体对应的所述指定类型事件发生的概率;
路径概率获取单元,用于响应于第n个目标实体为所述目标实体转移路径中最后一个目标实体,将第n个目标实体的所述出现概率,获取为所述目标实体转移路径对应的所述路径概率,n为正整数,且n≥2。
另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储由至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现上述数据结构化方法。
另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条计算机程序,所述计算机程序由处理器加载并执行以实现上述数据结构化方法。
另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述各种可选实现方式中提供的数据结构化方法。
本申请提供的技术方案可以包括以下有益效果:
在数据结构化的过程中,通过引入时间节点信息,基于待处理数据中的实体构建多条实体转移路径,用以且每条实体转移路径中的各个实体对应的时间节点均不同,并基于用于指示实体转移路径中实体对应事件依次发生的概率,对生成对应的结构化文本进行指导,以生成待处理数据对应的结构化文本,从而使得在数据结构化过程中,能够提高待处理数据中的信息利用率,可以充分结合各个实体之间的时序联系,以对用于生成结构化文本的实体进行组织或者筛选,从而提高了生成的结构化文本的准确性,同时,由于时间维度信息的引入,提高了数据结构化的可解释性。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
图1示出了本申请一示例性实施例提供的用数据结构化方法的系统架构的示意图;
图2示出了本申请一示例性实施例示出的数据结构化方法的流程图;
图3示出了本申请一示例性实施例示出的数据结构化方法的流程图;
图4示出了本申请一示例性实施例示出的时间序列的示意图;
图5示出了本申请一示例性实施例示出的数据结构化方法的示意图;
图6示出了本申请一示例性实施例示出的数据数据结构化装置的方框图;
图7示出了本申请一示例性实施例示出的计算机设备的结构框图;
图8示出了本申请一示例性实施例示出的计算机设备的结构框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
本申请实施例提供了一种数据结构化方法,可以提高数据结构化的准确性以及可解释性。为了便于理解,下面对本申请涉及的几个名词进行解释。
1)人工智能(ArtificialIntelligence,AI)
人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。本申请所示的包含图像采集组件的显示设备主要涉及其中的计算机视觉技术以及机器学习/深度学习等方向。
2)自然语言处理(Nature Language Processing,NLP)
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
3)实体对齐(Entity-Alignment)
实体对齐旨在判断两个或者多个不同信息来源的实体是否指向真实世界中的同一个对象。如果多个实体表征同一个对象,则在这些实体之间构建对齐关系,同时对实体包含的信息进行融合和聚集。
4)句法分析
句法分析是自然语言处理中的基础性工作,它分析句子的句法结果(主谓宾结构)和词汇间的依存关系(并列、从属等)。通过句法分析,协议为语义分析,情感倾向,观点抽取等NLP(Natural Language Processing,自然语言处理)应用场景打下坚实的基础。
句法分析主要分为两类,一类是分析句子的主谓宾、定状补的句法结构;另一类是分析词汇之间的依存关系,如并列、从属、递进等。
5)马尔科夫链(Markov Chain,MC)
马尔科夫链是概率论和数理统计中具有马尔科夫性质的离散时间随机过程。在该过程中,在给定当前指示或信息的情况下,只有当前的状态用来预测奖励,过去(即当前以前的历史状态)对于预测将来(即当前以后的未来状态)是无关的。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做过渡,与不同的状态改变相关的概率叫做过渡概率。
马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,它已成为一种通用的统计工具。
图1示出了本申请一示例性实施例提供的用数据结构化方法的系统架构的示意图,如图1所示,该系统包括:数据处理设备110以及数据采集设备120。
其中,上述数据处理设备110可以实现为终端或服务器,当该数据处理设备110实现为服务器时,该数据处理设备110可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、CDN(Content Delivery Network,内容分发网络)、区块链网络以及大数据和人工智能平台等基础云计算服务的云服务器。当该数据处理设备110实现为终端时,该数据处理设备110可以是智能手机、平板电脑、膝上型便携计算机和台式计算机等等。
上述数据采集设备120为具有数据采集以及存储功能的设备,用以获取待处理数据并将该待处理数据发送给数据处理设备110,以使得数据处理设备110对该待处理数据进行数据结构化处理,其中,该数据采集设备120可以实现为终端或者服务器。
可选的,上述系统中包含一个或者多个数据处理备110,以及一个或多个数据采集设备120。本申请实施例对于数据处理设备110和数据采集设备120的个数不做限制。
数据采集设备120以及数据处理设备110通过通信网络相连。可选的,通信网络是有线网络或无线网络。
可选的,上述的无线网络或有线网络使用标准通信技术和/或协议。网络通常为因特网、但也可以是任何网络,包括但不限于局域网(Local Area Network,LAN)、城域网(Metropolitan Area Network,MAN)、广域网(Wide Area Network,WAN)、移动、有线或者无线网络、专用网络或者虚拟专用网络的任何组合。在一些实施例中,使用包括超文本标记语言(Hyper Text Mark-up Language,HTML)、可扩展标记语言(Extensible MarkupLanguage,XML)等的技术和/或格式来代表通过网络交换的数据。此外还可以使用诸如安全套接字层(Secure Socket Layer,SSL)、传输层安全(Transport Layer Security,TLS)、虚拟专用网络(Virtual Private Network,VPN)、网际协议安全(Internet ProtocolSecurity,IPsec)等常规加密技术来加密所有或者一些链路。在另一些实施例中,还可以使用定制和/或专用数据通信技术取代或者补充上述数据通信技术。本申请在此不做限制。
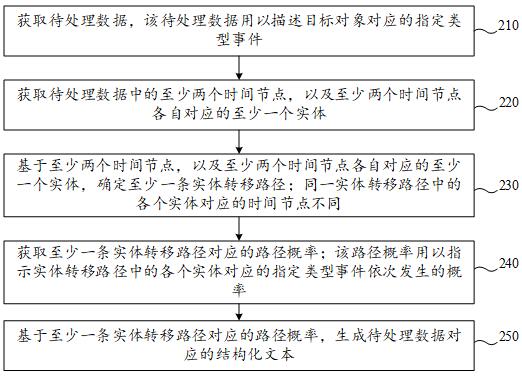
图2示出了本申请一示例性实施例示出的数据结构化方法的流程图,该方法可以由计算机设备执行,该计算机设备可以实现为如图1所示的数据处理设备110,如图2所示,该数据结构化方法可以包括以下步骤。
步骤210,获取待处理数据,该待处理数据用以描述目标对象对应的指定类型事件。
在一种可能的实现方式中,本申请实施例中的待处理数据可以是对应于目标用户的指定类型事件,或者,待处理数据也可以是对应于目标物品的指定类型事件;该指定类型事件可以对应于不同领域的事件,示意性的,当目标对象为目标用户时,该指定类型事件可以是对应于目标用户的医疗领域事件,比如就诊记录,或者,金融领域事件,比如储蓄记录等等;当目标对象为目标物品时,该指定类型时间可以是对应于目标物品的维护记录事件,或者使用记录事件等等。
在一种可能的实现方式中,该待处理数据是包含指定领域术语的文本数据。该指定领域是该指定类型事件对应的领域。
步骤220,获取待处理数据中的至少两个时间节点,以及至少两个时间节点各自对应的至少一个实体;该实体是在对应的时间节点上发生的指定类型事件的命名实体。
在本申请实施例中,该待处理数据是按照时间节点记录各个节点对应的指定类型事件的文本数据;计算机设备可以从待处理数据中提取出其中包含的至少两个时间节点,并基于各个时间节点对应的指定类型事件,获得各个时间节点对应的至少一个实体,该实体是与指定类型事件相对应的。
步骤230,基于至少两个时间节点,以及至少两个时间节点各自对应的至少一个实体,确定至少一条实体转移路径;同一实体转移路径中的各个实体对应的时间节点不同。
在一种可能的实现方式中,每个实体转移路径中包含对应于每个时间节点中的一个实体;也就是说,一条实体转移路径是由对应于各个时间节点的实体生成的;其中,该实体转移路径用以记录随着时间节点的推进,各个实体产生的先后顺序。
步骤240,获取至少一条实体转移路径对应的路径概率;该路径概率用以指示实体转移路径中的各个实体对应的指定类型事件依次发生的概率。
基于每条实体转移路径,可以得到与之对应的路径概率,一条实体转移路径对应的路径概率可以是计算机设备基于该实体转移路径中包含的各个实体之间的转移概率确定的,也就是说,由于不同实体转移路径包含的实体的数量或种类不同,不同实体转移路径之间的路径概率之间可以存在差异。
步骤250,基于至少一条实体转移路径对应的路径概率,生成待处理数据对应的结构化文本。
综上所述,本申请实施例提供的数据结构化方法,在数据结构化的过程中,通过引入时间节点信息,基于待处理数据中的实体构建多条实体转移路径,用以且每条实体转移路径中的各个实体对应的时间节点均不同,并基于用于指示实体转移路径中实体对应事件依次发生的概率,对生成对应的结构化文本进行指导,以生成待处理数据对应的结构化文本,从而使得在数据结构化过程中,能够提高对待处理数据的信息利用率,可以充分结合各个实体之间的时序联系,以对用于生成结构化文本的实体进行组织或者筛选,从而提高了生成的结构化文本的准确性,同时,由于时间维度信息的引入,提高了数据结构化的可解释性。
图3示出了本申请一示例性实施例示出的数据结构化方法的流程图,该方法可以由计算机设备执行,该计算机设备可以实现为如图1所示的终端或者服务器,如图3所示,该数据结构化方法可以包括以下步骤。
步骤310,获取待处理数据,该待处理数据用以描述目标对象对应的指定类型事件。
在一种可能的实现方式中,该待处理数据中可以包括对应于目标对象的结构化数据,半结构化数据以及非结构化数据中的至少两种;当该待处理数据中包含半结构化数据以及非结构化数据中的任意一种时,需要对该待处理数据进行句法分析,以获取该待处理数据中的相关信息;在本申请实施例中,该相关信息包括时间节点以及各个时间节点对应的实体。
其中,结构化数据是指可以使用关系型数据库表示和存储,表现二维形式的数据,通常以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的;
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或者其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层;
非结构化数据是指没有固定结构的数据,比如各种文档、图片、视频/音频等都属于非结构化数据。通常直接整体进行存储,而且一般存储为二进制的数据格式。
本申请实施例中以待处理数据是目标用户在诊疗记录为例,该待处理数据可以包括诊断记录、入院病历、出院小结等;其中,该诊断记录通常为结构化数据,入院病历以及出院小结通常为半结构化数据或者非结构化数据。
步骤320,获取待处理数据中的至少两个时间节点,以及至少两个时间节点各自对应的至少一个实体;该实体是在对应的时间节点上发生的指定类型事件的命名实体。
当待处理数据为目标用户的诊疗记录时,待处理数据中的实体可以包含以下信息:实体类别(如诊断、手术、药品、检验等),实体内容,用以通过实体名称表示具体的内容(如诊断名、手术名、药品名、检验名等),以及事件变化类型,用以表示对应的事件变化情况(如起始、终止、暂停、加重等)。
在一种可能的实现方式中,计算机设备可以通过句法分析方法获取待处理数据中的至少两个时间节点,以及各个时间节点各自对应的至少一个实体。
在一种可能的实现方式中,该句法分析方法可以是LTP(Language TechnologyPlatform,语言技术平台)依存句法;需要说明的是,本申请中使用的句法分析方法仅为示意性的,本申请不对句法分析方法的具体类型进行限制。
示意性的,当待处理数据为“患者20年前去当地社区门诊体检发现血糖升高,诊断为‘糖尿病’,予‘二甲双胍、那格列奈’治疗,血糖稳定。患者于2年前因经济原因自行停药,期间无明显不适。1周前,患者开始出现颜面浮肿,尿泡沫增多,遂至我院门诊就诊,门诊以‘糖尿病并发症’收入院”的文本内容时,基于句法分析获得的时间节点以及各个时间节点对应的实体内容如表1所示:
表1
上述表格内容可以称为时序信息,也就是说,计算机设备从待处理数据中获取时序信息,该时序信息包括至少两个时间节点,以及至少两个时间节点各自对应的至少一个实体,其中,该时序信息可以通过T={(x,t)}表示,其中,x为待处理数据中的实体内容,t为x(实体内容)对应的指定类型事件发生的时间。
步骤330,基于至少两个时间节点,以及至少两个时间节点各自对应的至少一个实体,建立时间序列;该时间序列用以记录各个时间节点对应的实体。
在一种可能的实现方式中,建立时间序列的过程包括:
对至少一个实体进行术语标准化处理,获得至少一个术语标准化后的实体;
将至少一个实体对应的时间节点转化为时序时间节点;
基于至少一个术语标准化后的实体,以及至少一个实体对应的时序时间节点,建立时间序列。
由于个人语言习惯或者对应领域人员的用语习惯与结构化文本对应的标准化术语的表达方式不同,计算机设备从待处理数据中提取的实体对应的术语与标准化术语之间存在差异,因此,为了实现数据结构化,需要对计算机设备提取的实体对应的术语进行术语标准化;可选的,可以通过实体对齐的方式实现术语标准化,其中,实体对齐旨在判断两个或者多个不同信息来源的实体是否指向真实世界中的同一对象,如果多个实体表征同一个对象,则在这些实体之间构建对齐关系,同时,对实体包含的信息进行融合和聚集,在本申请实施例中,通过实体对齐的方式确定计算机设备提取的实体对应的术语,与术语标准化后的术语表征同一个对象后,即可获得待标准化术语(计算机设备提取的实体对应的术语)对应的标准化后的术语,以表1中的实体内容x为例,术语标准化后的实体内容(X={x})如表2所示:
表2
在一种可能的实现方式中,术语标准化的过程可以通过术语标准化模型实现,该术语标准化模型是基于样本术语以及样本术语对应的标准化术语训练获得的。
在一种可能的实现方式中,上述将至少一个实体对应的时间节点转化为时序时间节点的过程实现为:
获取时间节点的记载形式;
对应于记载形式,将至少一个实体对应的时间节点转化为时序时间节点。
时间节点的不同记载形式可以对应有不同的将时间节点转化为时序时间节点的方法,其中,时序时间节点是对时间节点的标准化表达。
在一种情况下,响应于记载形式为时间戳形式,基于记载形式,将至少一个实体对应的时间节点转化为时序时间节点,包括:
基于至少一个实体对应的时间节点进行绝对化时间标记,获得时序时间节点。
当计算机设备能够从待处理数据中提取到各个实体对应的时间戳时,可基于时间戳进行绝对化时间标记,即相对于格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)而言,该时序时间节点表示为绝对化的年、月、日、时、分、秒的形式,其中,时序时间节点的精确度可以基于用户设置进行调节,即,该时序时间节点可以精确到“秒”,或者,该时序时间节点可以精确到“时”。
以该时序时间节点可以精确到“分”为例,在时序时间节点是基于时间戳进行绝对化时间标记的基础上,获得的时间序列(P={(e,t)})如下所示:
(e(“检验”,“血葡萄糖升高”,“时间点”):t(“2000-12-27 15:30”))
(e(“诊断”,“糖尿病”,“时间点”):t(“2000-12-27 15:31”))
(e(“药品”,“二甲双胍”,“起始”):t(“2000-12-27 15:32”))
(e(“药品”,“那格列奈”,“起始”):t(“2000-12-27 15:32”))
(e(“检验”,“血葡萄糖正常”,“时间点”):t(“2000-12-27 15:33”))
(e(“药品”,“二甲双胍”,“停止”):t(“2017-12-27 15:30”))
(x(“药品”,“那格列奈”,“停止”):t(“2017-12-27 15:30”))
(e(“症状”,“颜面浮肿”,“起始”):t(“2020-12-20 15:30”))
(e(“症状”,“泡沫尿”,“起始”):t(“2020-12-20 15:30”))
(e(“诊断”,“糖尿病伴有并发症”,“时间点”):t(“2020-12-27 15:30”))
其中,e表示实体,且上述时间序列中实体e中包含该实体类型,标准化后的实体内容(X)以及其对应的事件变化类型;该实体类型用以指示该实体内容对应的诊疗类型,示意性的,该实体类型可以是待处理数据中记载的;或者,该实体类型可以通过分类网络模型进行获取,该分类网络模型可以是基于样本实体内容以及对应的实体类型标签训练获得的;或者,该计算机设备中预先设置有实体类型与实体内容之间的映射关系,在获取到实体内容之后,基于该映射关系即可获取到该实体内容对应的实体类型;该事件变化类型可以是基于句法分析获得的各个实体之间的对应关系确定的。响应于实体内容多次出现,基于该实体内容在各个时间节点对应的事件变化情况,获取该实体内容在各个时间节点对应的事件变化类型,比如,在对表1对应的待处理数据进行实体提取的过程中,药品“二甲双胍”出现了两次,基于句法分析可知,第一个“二甲双胍”对应于时间节点“20年前”,对应于动作“给予”,第二个“二甲双胍”对应于时间节点“2年前”,对应于动作“停用”,两个时间节点之间存在起止关系,通过句法分析,基于两者对应的动作内容判断得出前一个时间节点对应的事件变化情况为起始,后一个时间节点对应的事件变化情况为停止,因此,可以提取获得实体内容对应的事件变化类型,以指示当前时间节点所表示的起止信息;而响应于实体内容单次出现,基于该实体内容对应的事件变化情况,获取该实体内容对应的事件变化类型,示意性的,当该实体内容并未对应有事件变化时,可以将其对应的节点类型标注为“时间点”;当待处理数据中包含类似“病情加重”的描述时,可以将对应的事件变化类型标注为“加重”,以指示在该时间节点出现病情加重的情况。
在另一种情况下,响应于记载形式为非时间戳形式,基于记载形式,将至少一个实体对应的时间节点转化为时序时间节点,包括:获取至少一个时间节点中的一个时间节点为参考时间节点;
基于参考时间节点,以及其他时间节点与参考时间节点之间的时间差,对至少一个实体对应的时间信息进行相对数字化标记,获得时序时间,其他时间节点为至少一个时间节点中除参考时间节点之外的节点。
在一种可能的实现方式中,该参考时间节点是至少一个时间节点中与当前时间节点之间的时间差最长的时间节点;
或者,参考时间节点是至少一个时间节点中与当前时间节点的时间差最短的时间节点。
或者,该参考时间节点还可以是用户指定的时间节点中的任意一个节点,本申请对参考时间节点的设定不进行限制。
以参考时间节点是至少一个时间节点中与当前时间节点之间的时间差最长的时间节点,即该参考时间节点待处理数据中最早出现的时间节点为例,如表1所示的时序信息,基于相对数字化标记转化获得的时序时间节点获取的时间序列(P={(e,t)})表示为:
(e(“检验”,“血葡萄糖升高”,“时间点”):t(“t
(e(“诊断”,“糖尿病”,“时间点”):t(“t
(e(“药品”,“二甲双胍”,“起始”):t(“t
(e(“药品”,“那格列奈”,“起始”):t(“t
(e(“检验”,“血葡萄糖正常”,“时间点”):t(“t
(e(“药品”,“二甲双胍”,“停止”):t(“t
(e(“药品”,“那格列奈”,“停止”):t(“t
(e(“症状”,“颜面浮肿”,“起始”):t(“t
(e(“症状”,“泡沫尿”,“起始”):t(“t
(e(“诊断”,“糖尿病伴有并发症”,“时间点”):t(“t
其中,“t
在一种可能的实现方式中,当待处理数据中的相邻两个时间节点之间,存在未记载对应时间节点的实体时,计算机设备可以以实体均匀分布为标准,获取该实体对应的时间节点;其中,实体均匀分布是指,处于同一时间区间内的各个实体对应的指定类型事件的发生时间节点是均匀分布的,该过程可以实现为:
响应于待处理数据中未记载第一实体对应的时间节点,获取对应于第一实体的指定类型事件所处的时间区间;
以实体均匀分布为标准,基于时间区间,获取第一实体对应的时间节点。
在一种可能的实现方式中,该时间区间是基于该实体对应的指定类型事件所处的相邻两个时间节点确定的,即该时间区间为实体对应的指定类型事件所处的相邻两个时间节点之间的时间段。
以实体均匀分布为标准,基于时间区间,获取第一实体对应的时间节点的过程可以实现为:
获取第一实体在时间区间中的生成顺序;
以实体均匀分布为标准,基于时间区间以及生成顺序,获取第一实体对应的时间节点。
示意性的,假设已知实体e
在本申请实施例中,时间序列中同时发生的指定类型事件相互独立,而非同时发生的指定类型事件具有因果关系;示意性的,20年前检验结果为血糖升高,诊断结果为糖尿病以及给予药物二甲双胍和那格列奈(常见的口服降血糖药)并非同时发生,则计算机设备判定不同时间点发生的事件是有因果关系的,而给予药品二甲双胍和那格列奈是同时发生的,则计算机设备判定两事件是相互独立的。
步骤340,基于时间序列,确定至少一条实体转移路径,同一实体转移路径中的各个实体对应的时间节点不同。
其中,同一实体转移路径中的各个实体对应的时间节点可以是连续的时间节点,或者,同一实体转移路径中的各个实体对应的时间节点是非连续的时间节点,本申请对组成同一实体转移路径的各个实体对应的时间节点之间的关系不进行限制。示意性的,在本申请实施例中,以同一实体转移路径中的各个实体对应的时间节点是连续的时间节点为例,对本申请提供的数据结构化方法进行说明。
在一种可能的实现方式中,上述基于时间序列,确定至少一条实体转移路径的过程实现为:
从至少两个时间节点各自对应的至少一个实体中,分别获取一个目标实体;
基于至少两个时间节点各自对应的目标实体,构建目标实体转移路径,该目标实体转移路径是至少一条实体转移路径中的任意一条。
图4示出了本申请一示例性实施例示出的时间序列的示意图,如图4所示,该时间序列中包含至少两个时间节点410,每个时间节点对应有至少一个实体420,从每个时间节点中获取一个实体以构建实体转移路径则可以获取多条实体转移路径,其中,不同实体转移路径包含的实体非完全重合,即,不同实体转移路径中包含的实体可以部分重合,或者不重合。其中,图4中各个实体之间的箭头用以表示各个实体之间的转移关系,不同实体之间的转移概率会由于实体之间对的时间间隔不同而不同;比如,对于实体“肚子疼”与实体“医院”而言,当两者之间的时间间隔为1小时时,两者之间的转移概率为10%;而当两者之间的时间间隔为1天时,两者之间的转移概率为70%,也就是说,“肚子疼”的持续时间越长,该对象执行“去医院”的动作的概率越高,因此,各个实体之间的转移概率不仅与各个实体的实体类型,实体内容相关,还与各个实体之间的时间间隔相关。
在时间序列中,可以通过不同形状表示实体对应的不同实体类型,比如,图4中的椭圆形表示实体类型为诊断,正方形表示实体类型为手术,三角形表示实体类型为药品,十字形表示实体类型为检验。需要说明的是,图4中对实体类型的表示方式仅为示意性的,本申请实施例不对实体类型在时间序列中的表示方式进行限制。
步骤350,获取至少一条实体转移路径对应的路径概率;该路径概率用以指示实体转移路径中的各个实体对应的指定类型事件依次发生的概率。
其中,实体转移路径对应的路径概率由实体之间的转移概率确定,如图4所示的时间序列中包含2*3*2*1*3*2=72条实体转移路径,每条实体转移路径由于经过的实体不同,各个实体之间的转移概率不同,导致各条实体转移路径对应的路径概率不同,示意性的,图4中的实体转移路径1经过实体e
基于目标时间节点之间的时间间隔,获取目标实体转移路径中,每m个连续的目标实体之间的转移概率;该转移概率用以指示在m个连续的目标实体中,前m-1个目标实体存在的前提下,第m个目标实体对应的指定类型事件发生的概率;m为正整数,且m≥2;该目标时间节点是组成目标实体转移路径的目标实体对应的时间节点;
基于转移概率,获取目标实体转移路径对应的路径概率。
当m=2时,表示下一个实体的概率分布只由当前实体决定,与时间序列中当前实体之前的实体均无关,即P(e
当m=3时,表示下一个实体的概率分布由当前实体以及当前实体之前的一个实体决定,与时间序列中的其他实体无关,即P(e
其中,m的取值下限为2,m的取值上限可以基于计算机设备的运行能力或者用户的实际需求进行设定。
在本申请实施例中,该转移概率与目标实体之间的时间间隔相关,以两个实体之间的转移概率为例,在e
在一种可能的实现方式中,基于转移概率,获取目标实体转移路径对应的路径概率的过程可以实现为:
以目标实体转移路径中,已出现前n-1个目标实体为条件,基于转移概率,计算第n个目标实体的出现概率;该出现概率用以指示第n个目标实体对应的指定类型事件发生的概率;
响应于第n个目标实体为目标实体转移路径中最后一个目标实体,将第n个目标实体的出现概率,获取为目标实体转移路径对应的路径概率,n为正整数,且n≥2。
其中,计算第n个目标实体的出现概率的计算公式可以表示为P(e
步骤360,基于至少一条实体转移路径对应的路径概率,生成待处理数据对应的结构化文本。
在一种可能的实现方式中,在获取到至少一条实体转移路径对应的路径概率之后,可以获取对应的路径概率最高的一条或几条实体转移路径为结构化文本对应的实体转移路径。
在一种可能的实现方式中,以结构化文本对应的一条实体转移路径为例,在获取到结构化文本对应实体转移路径的路径概率之后,可以基于该路径概率以及相应的置信度规则获取置信度阈值,该置信度阈值用以判定该实体转移路径中的各个实体是否可信;也就是说,基于该实体转移路径的路径概率获取用于生成结构化文本的实体;基于用于生成结构化文本的实体生成结构化文本;其中,该置信度规则可以由用户基于实际应用进行设置;示意性的,该置信度规则可以指示当路径概率处于指定区间时,该实体转移路径上的各个实体对应的置信度阈值。比如说,实体转移路径1而言,其路径概率P(en|e1……en-1)=P(e
由于在进行实体提取的过程中,会存在一定的提取误差,获得一些无意义的实体,影响数据结构化的准确度,因此,在一种可能的实现方式中,在基于置信度阈值对实体转移路径中的各个实体是否可信进行判断之前,还需基于路径概率对该实体转移路径中的各个实体的置信度进行统计学分析与修正;示意性的,该过程可以实现为,获取该实体转移路径中各个实体的原始置信度;基于路径概率对各个实体的原始置信度进行加权;之后,基于加权之后获得的各个实体的置信度以及置信度阈值,对实体的置信度指示该实体是否可信进行判断,比如,当加权后的实体的置信度低于0.25(置信度阈值)时,则判断该实体不可信,将该实体从时间序列中删除;当加权后的实体的置信度高于0.25时,则判断该实体可信,在时间序列中保留该实体,以剔除置信度较低的实体,保留置信度较高的实体,以使得基于置信度较高的实体获得的结构化文本的准确度较高。
在一种可能的实现方式中,该结构化文本是基于通过路径概率修正并通过置信度筛选之后获取的实体生成的,即在基于路径概率对各个实体对应的置信度进行修正调整之后,获取置信度高于指定阈值的实体为用于生成结构化文本的实体,进而基于这些实体,以及这些实体之间的时序关系生成结构化文本,示意性的,基于文本“患者20年前去当地社区门诊体检发现血糖升高,诊断为‘糖尿病’,予’二甲双胍、那格列奈’治疗,血糖稳定。患者于2年前因经济原因自行停药,期间无明显不适。1周前,患者开始出现颜面浮肿,尿泡沫增多,遂至我院门诊就诊,门诊以‘糖尿病并发症’收入院”生成的结构化文本可表示为:
2000-12-27 15:30|检验|时间点|血葡萄糖升高
2000-12-27 15:31|诊断|时间点|糖尿病
2000-12-27 15:32|药品|起始|二甲双胍
2000-12-27 15:32|药品|起始|那格列奈
2000-12-27 15:33|检验|时间点|血葡萄糖正常
2017-12-27 15:30|药品|停止|二甲双胍
2017-12-27 15:30|药品|停止|那格列奈
2020-12-20 15:30|症状|起始|颜面浮肿
2020-12-20 15:30|症状|起始|泡沫尿
2020-12-20 15:30|诊断|时间点|糖尿病伴有并发症
需要说明的是,本申请所示的结构化文本的表现形式为示意性的,相关人员可以根据实际需求对结构化文本的生成形式以及包含的内容进行设置,本申请对此不进行限制。
综上所述,本申请实施例提供的数据结构化方法,在数据结构化的过程中,通过引入时间节点信息,基于待处理数据中的实体构建多条实体转移路径,用以且每条实体转移路径中的各个实体对应的时间节点均不同,并基于用于指示实体转移路径中实体对应事件依次发生的概率,对生成对应的结构化文本进行指导,以生成待处理数据对应的结构化文本,从而使得在数据结构化过程中,能够提高待处理数据中的信息利用率,可以充分结合各个实体之间的联系,以对用于生成结构化文本的实体进行组织或者筛选,从而提高了生成的结构化文本的准确性,同时,由于时间维度信息的引入,提高了数据结构化的可解释性。
在一种可能的实现方式中,本申请提供的数据结构化方法可以结合区块链系统进行应用;示意性的,计算机设备可以从区块链系统中获取待处理数据;在基于待处理数据生成结构化文本之后,可以将获得的结构化文本存储到区块链系统中;由于待处理数据是涉及目标对象对应的指定类型事件的相关数据,通过将待处理数据和/或处理后获得的结构化文本存储在区块链系统中,实现对待处理数据的安全保护,保护用户的隐私。
本申请提供的数据结构化方法应用于医疗领域时,该数据结构化方法可以应用于包括但不限于公共卫生统计、医保核保、医疗数据治理,服务与自动问诊、疾病预测等场景中。
其中,公共卫生统计是指传染性疾病的流行性分析,基于本申请提供的数据结构化方法输出的结构化数据,除了可进行传统的周期性分析,还可以通过对患病人群发病前的医疗实体进行相关分析,从而识别出易感人群的特征,有助于疾病防控。
医保核保:医保数据进行时间序列加持的数据结构化后,可得到疾病、药物、手术的趋势,可指导医保政策的制定以及医保支出的优化。
医疗数据治理:通过本申请提供的数据结构化方法,可将病人于不同医院就诊的数据进行整合处理,可形成病人基于时间线的医疗就诊数据。示意性的,在一种可能的应用方式中,基于马尔科夫链模型和隐式马尔科夫链谱(HMM Profile),可对时间序列进行统计学上的判断。如在诊断为糖尿病后使用口服降糖药,血糖回归正常,则提示该糖尿病类型为2型糖尿病的概率较高。另外,在诊断糖尿病20年以及出现颜面浮肿和泡沫尿,前者为肾源性水肿常见的表现,后者为尿蛋白增高的常见表现,提示先前标准后的“糖尿病伴有并发症”为“2型糖尿病伴有肾的并发症”的概率较高,用以辅助医生进行疾病诊断。
服务与自动问诊:对用户的问询耦合时间维度上的信息后,可优化与用户进一步交互中,自动问诊引擎提供的返回结果的对用户之前问询的相关性。
疾病预测:基于症状、体征、检查、检验结果进行的诊断得到时间维度的支持后,一方面可提高预测的准确率,另一方面可提供更强的可解释性。
在一种可能的实现方式中,本申请提供的数据结构化方法应数据结构化模型中,该数据结构化模型可以是基于神经网络训练获得的模型,该数据结构化模型可以包括句法分析模块,标准化模块,时序整理模块以及马尔科夫统计模块。
在一种可能的实现方式中,该数据结构化模型是基于样本数据以及样本数据对应的结构化文本标签训练获得的,该样本数据为同一领域中对应于不同对象的非结构化的文本数据。本申请实施例中的转移概率,置信度阈值的取值等可以实现为该数据结构化模型对应的待优化参数,以在该数据结构化模型的训练过程中,通过优化待优化参数,使得数据结构化模型的预测结果与结构化文本标签相近或相同。
图5示出了本申请一示例性实施例示出的数据结构化方法的示意图,如图5所示,以待处理数据为非结构化的医疗数据为输入为例,该数据结构化模型通过句法分析模块510分别提取待处理数据中的时间节点以及实体,其中,该句法分析模块可以包括至少一个实体提取子模块,在提取实体时,可以使用n-gram候选片段提取的方法来提取多个实体,从而对于句法分析模块510中的每个实体提取子模块来说输入的文本长度是较短的,减少了噪音,同时通过预先设定的n-gram长度来保证信息的完整性,实现对医疗实体的提取;在获取到时间节点以及医疗实体之后,通过标准化模块520分别对时间节点以及医疗实体进行标准化,获得时序时间以及术语标准化后的实体,以满足数据结构化的需求,之后,通过时序整理模块530对获得的时间节点以及医疗实体之间的时序关系进行整理,获得时间序列540;通过马尔科夫统计模块550对获取到的时间序列540进行概率统计分析,获取时间序列540中的至少一条实体转移路径对应的路径概率,以利用该路径概率对各个实体的置信度进行修正,从而基于各个实体的置信度进行实体筛选,并基于筛选后的实体生成并输出待处理数据对应的结构化文本。
一般而言,实体转移路径对应的路径概率越高,该实体转移路径中的各个实体之间的转移概率越高,该实体转移路径中的各个实体对应的置信度越高。
以本申请提供的方法应用于病案结构化的场景中为例,由于时间信息维度的引入,本申请实施例提供的数据结构化方法通过识别并处理医疗实体之间因偶然因素或非医疗相关因素引起的联系,能够减少对医疗实体的误分辨率。并且以时间信息维度为线索,能同时对包括疾病、手术、药物、检验等在内的多种医学实体进行结构化。通过引入条件概率和马尔科夫链,可对医疗实体间进行相关分析,并在时间维度上增强模型的可解释性。最终数据结构化模型在通过上述数据结构化方法进行预测分析以及分析后迭代修正后,生成结构化文本的准确率提升了7.1%。
需要说明的是,本申请实施例中对基于路径概率生成待处理数据对应的结构化文本的说明仅为示意性的,相关人员可以基于不同的应用领域,或者,基于不同的应用需求进行不同的应用。
图6示出了本申请一示例性实施例示出的数据数据结构化装置的方框图,如图6所示,该数据结构化装置包括:
第一获取模块610,用于获取待处理数据,所述待处理数据用以描述目标对象对应的指定类型事件;
第二获取模块620,用于获取所述待处理数据中的至少两个时间节点,以及至少两个所述时间节点各自对应的至少一个实体;所述实体是在对应的所述时间节点上发生的所述指定类型事件的命名实体;
实体转移路径确定模块630,用于基于至少两个所述时间节点,以及至少两个所述时间节点各自对应的至少一个所述实体,确定至少一条实体转移路径;同一所述实体转移路径中的各个所述实体对应的所述时间节点不同;
路径概率获取模块640,用于获取至少一条所述实体转移路径对应的路径概率;所述路径概率用以指示所述实体转移路径中的各个所述实体对应的所述指定类型事件依次发生的概率;
结构化文本生成模块650,用于基于至少一条所述实体转移路径对应的路径概率,生成所述待处理数据对应的结构化文本。
在一种可能的实现方式中,所述实体转移路径确定模块630,包括:
时间序列建立子模块,用于基于至少两个所述时间节点,以及至少两个所述时间节点各自对应的至少一个所述实体,建立时间序列;所述时间序列用以记录各个所述时间节点对应的所述实体;
实体转移路径确定子模块,用于基于所述时间序列,确定至少一条所述实体转移路径。
在一种可能的实现方式中,所述实体转移路径确定子模块,包括:
目标实体获取单元,用于从至少两个所述时间节点各自对应的至少一个实体中,分别获取一个目标实体;
目标实体转移路径构建单元,用于基于至少两个所述时间节点各自对应的所述目标实体,构建目标实体转移路径,所述目标实体转移路径是至少一条所述实体转移路径中的任意一条。
在一种可能的实现方式中,所述时间序列建立子模块,包括:
术语标准化单元,用于对至少一个所述实体进行术语标准化处理,获得至少一个术语标准化后的所述实体;
时间节点转化单元,用于将至少一个所述实体对应的所述时间节点转化为时序时间节点;
时间序列建立单元,用于基于至少一个术语标准化后的所述实体,以及至少一个所述实体对应的所述时序时间节点,建立所述时间序列。
在一种可能的实现方式中,所述时间节点转化单元,用于获取所述时间节点的记载形式;
对应于所述记载形式,将至少一个所述实体对应的所述时间节点转化为所述时序时间节点。
在一种可能的实现方式中,响应于所述记载形式为时间戳形式,所述时间节点转化单元,用于基于至少一个所述实体对应的所述时间节点进行绝对化时间标记,获得所述时序时间节点。
在一种可能的实现方式中,响应于所述记载形式为非时间戳形式,所述时间节点转化单元,用于获取至少一个所述时间节点中的一个时间节点为参考时间节点;
基于所述参考时间节点,以及其他时间节点与所述参考时间节点之间的时间差,对至少一个所述实体对应的所述时间信息进行相对数字化标记,获得所述时序时间,所述其他时间节点为至少一个所述时间节点中除所述参考时间节点之外的节点。
在一种可能的实现方式中,所述参考时间节点是至少一个所述时间节点中与当前时间节点之间的时间差最长的时间节点;
或者,所述参考时间节点是至少一个所述时间节点中与当前时间节点的时间差最短的时间节点。
在一种可能的实现方式中,所述装置还包括:
时间区间获取模块,用于响应于所述待处理数据中未记载第一实体对应的时间节点,获取对应于所述第一实体的所述指定类型事件所处的时间区间;
时间节点获取模块,用于以实体均匀分布为标准,基于所述时间区间,获取所述第一实体对应的时间节点。
在一种可能的实现方式中,所述时间节点获取模块,包括:
生成顺序获取子模块,用于获取所述第一实体在所述时间区间中的生成顺序;
时间节点获取子模块,用于以实体均匀分布为标准,基于所述时间区间以及所述生成顺序,获取所述第一实体对应的时间节点。
在一种可能的实现方式中,所述路径概率获取模块640,包括:
转移概率获取子模块,用于基于目标时间节点之间的时间间隔,获取所述目标实体转移路径中,每m个连续的所述目标实体之间的转移概率;所述转移概率用以指示在m个连续的所述目标实体中,前m-1个目标实体存在的前提下,第m个目标实体对应的所述指定类型事件发生的概率;m为正整数,且m≥2;所述目标时间节点是组成所述目标实体转移路径的所述目标实体对应的所述时间节点;
路径概率获取子模块,用于基于所述转移概率,获取所述目标实体转移路径对应的所述路径概率。
在一种可能的实现方式中,路径概率获取子模块,包括:
出现概率计算单元,用于以所述目标实体转移路径中,已出现前n-1个目标实体为条件,基于所述转移概率,计算第n个目标实体的出现概率;所述出现概率用以指示第n个目标实体对应的所述指定类型事件发生的概率;
路径概率获取单元,用于响应于第n个目标实体为所述目标实体转移路径中最后一个目标实体,将第n个目标实体的所述出现概率,获取为所述目标实体转移路径对应的所述路径概率,n为正整数,且n≥2。
综上所述,本申请实施例提供的数据结构化方法,在数据结构化的过程中,通过引入时间节点信息,基于待处理数据中的实体构建多条实体转移路径,用以且每条实体转移路径中的各个实体对应的时间节点均不同,并基于用于指示实体转移路径中实体对应事件依次发生的概率,对生成对应的结构化文本进行指导,以生成待处理数据对应的结构化文本,从而使得在数据结构化过程中,能够提高待处理数据中的信息利用率,可以充分结合各个实体之间的时序联系,以对用于生成结构化文本的实体进行组织或者筛选,从而提高了生成的结构化文本的准确性,同时,由于时间维度信息的引入,提高了数据结构化的可解释性。
图7示出了本申请一示例性实施例示出的计算机设备700的结构框图。该计算机设备可以实现为本申请上述方案中的服务器。所述计算机设备700包括中央处理单元(Central Processing Unit,CPU)701、包括随机存取存储器(Random Access Memory,RAM)702和只读存储器(Read-Only Memory,ROM)703的系统存储器704,以及连接系统存储器704和中央处理单元701的系统总线705。所述计算机设备700还包括用于存储操作系统709、应用程序710和其他程序模块711的大容量存储设备706。
所述大容量存储设备706通过连接到系统总线705的大容量存储控制器(未示出)连接到中央处理单元701。所述大容量存储设备706及其相关联的计算机可读介质为计算机设备700提供非易失性存储。也就是说,所述大容量存储设备706可以包括诸如硬盘或者只读光盘(Compact Disc Read-Only Memory,CD-ROM)驱动器之类的计算机可读介质(未示出)。
不失一般性,所述计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括RAM、ROM、可擦除可编程只读寄存器(Erasable Programmable Read Only Memory,EPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-OnlyMemory,EEPROM)闪存或其他固态存储其技术,CD-ROM、数字多功能光盘(DigitalVersatile Disc,DVD)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。上述的系统存储器704和大容量存储设备706可以统称为存储器。
根据本公开的各种实施例,所述计算机设备700还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备700可以通过连接在所述系统总线705上的网络接口单元707连接到网络708,或者说,也可以使用网络接口单元707来连接到其他类型的网络或远程计算机系统(未示出)。
所述存储器还包括至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、至少一段程序、代码集或指令集存储于存储器中,中央处理器701通过执行该至少一条指令、至少一段程序、代码集或指令集来实现上述各个实施例所示的数据结构化方法中的全部或部分步骤。
图8示出了本申请一个示例性实施例提供的计算机设备800的结构框图。该计算机设备800可以实现为上述的终端,比如:智能手机、平板电脑、笔记本电脑或台式电脑。计算机设备800还可能被称为用户设备、便携式终端、膝上型终端、台式终端等其他名称。
通常,计算机设备800包括有:处理器801和存储器802。
处理器801可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器801可以采用DSP(Digital Signal Processing,数字信号处理)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器801也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central ProcessingUnit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器801可以集成有GPU(Graphics Processing Unit,图像处理器),GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器801还可以包括AI(Artificial Intelligence,人工智能)处理器,该AI处理器用于处理有关机器学习的计算操作。
存储器802可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器802还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器802中的非暂态的计算机可读存储介质用于存储至少一个指令,该至少一个指令用于被处理器801所执行以实现本申请中方法实施例提供的数据结构化方法中的全部或部分步骤。
在一些实施例中,计算机设备800还可选包括有:外围设备接口803和至少一个外围设备。处理器801、存储器802和外围设备接口803之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口803相连。具体地,外围设备包括:射频电路804、显示屏805、摄像头组件806、音频电路807、定位组件808和电源809中的至少一种。
外围设备接口803可被用于将I/O(Input/Output,输入/输出)相关的至少一个外围设备连接到处理器801和存储器802。在一些实施例中,处理器801、存储器802和外围设备接口803被集成在同一芯片或电路板上;在一些其他实施例中,处理器801、存储器802和外围设备接口803中的任意一个或两个可以在单独的芯片或电路板上实现,本实施例对此不加以限定。
在一些实施例中,计算机设备800还包括有一个或多个传感器810。该一个或多个传感器810包括但不限于:加速度传感器811、陀螺仪传感器812、压力传感器813、指纹传感器814、光学传感器815以及接近传感器816。
本领域技术人员可以理解,图8中示出的结构并不构成对计算机设备800的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
在一示例性实施例中,还提供了一种计算机可读存储介质,用于存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现上述数据结构化方法中的全部或部分步骤。例如,该计算机可读存储介质可以是只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、只读光盘(Compact Disc Read-Only Memory,CD-ROM)、磁带、软盘和光数据存储设备等。
在一示例性实施例中,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述图2或图3任一实施例所示方法的全部或部分步骤。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。
- 海量数据结构化方法、装置、计算机设备及存储介质
- 数据结构化方法、装置、计算机设备及存储介质