增值税发票的检测方法、装置和可读存储介质
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及检测技术领域,具体而言,涉及一种增值税发票的检测方法、装置和可读存储介质。
背景技术
增值税发票洗票企业检测是指对涉嫌增值税专用发票洗票行为的一般纳税实体(企业)进行检测和甄别。
在实现本发明的过程中,本发明的发明人发现:相关方案在增值税专用发票洗票企业检测时,存在着检测准确率较低、检测方案泛化性能较差以及检测方案可扩展性较差等不足,难以满足税务稽查、风控等部门的实际业务需求等问题。
发明内容
本发明旨在解决上述技术问题的至少之一。
为此,本发明的第一目的在于提供一种增值税发票的检测方法。
本发明的第二目的在于提供一种增值税发票的检测装置。
本发明的第三目的在于提供一种可读存储介质。
为实现本发明的第一目的,本发明的技术方案提供了一种增值税发票的检测方法,包括:获取数据,数据包括增值税发票数据、企业申报数据和企业变更数据,对数据进行数据处理,得到清洁数据;基于清洁数据,提取第一特征向量,获取第一特征向量集合;基于第一特征向量集合,采用第一风险量化模型进行检测,得到第一风险量化值;获取企业关联数据,构建企业关联关系拓扑图;基于企业关联关系拓扑图,获取风险扩散变量;基于风险扩散变量和第一风险量化值,计算第二特征向量,获取第二特征向量集合;基于第二特征向量集合,采用第二风险量化模型进行检测,获取第二风险量化值。
本实施例提出了洗票风险扩散机制,对洗票风险在企业之间的扩散过程进行建模,实现了企业间风险扩散行为的精确捕获与计算,同时清晰地区分了正常企业与洗票嫌疑企业。
另外,本发明提供的技术方案还可以具有如下附加技术特征:
上述技术方案中,在获取数据之前还包括:建立梯度提升树模型;获取历史稽查数据集合,将历史稽查数据集合划分为训练数据集合、测试数据集合和验证数据集合;分别获取训练数据集合、测试数据集合和验证数据集合的第一特征向量集合;基于训练数据集合、测试数据集合和验证数据集合的第一特征向量集合,采用交叉验证方式,对梯度提升树模型进行训练和参数调整,得到第一风险量化模型。
本实施例中,采用梯度提升树模型作为最终的检测算法,可以显著提高洗票企业检测的精确率以及召回率,在提高洗票企业检测效率的同时确保稽查工作的有效开展。
上述任一技术方案中,对数据进行数据处理,具体包括:对数据进行缺失值处理、异常值处理、量纲处理、去重处理和/或噪声处理。
本实施例中,通过对数据进行预处理,实现数据的标准化,使预处理后的数据符合机器学习算法的要求,降低数据因素对检测模型推理性能的影响。
上述任一技术方案中,基于清洁数据,提取第一特征向量,获取第一特征向量集合,具体包括:根据清洁数据,抽取企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、抽取企业变更特征和企业申报特征;获取第一特征向量集合,第一特征向量集合包括企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、企业变更特征和企业申报特征。
本实施例中,第一特征向量集合可以有效的反映出企业是否存在洗票行为。
上述任一技术方案中,企业进销数量特征为:
其中,
企业进销金额特征为:
其中,
企业集中开票特征为:
其中,
企业顶额开票特征为:
其中,
企业开票金额变化特征为:
其中,
企业变更特征为:根据清洁数据中的企业变更数据,判定企业是否发生变更行为;
企业申报特征为:根据清洁数据中的企业申报数据,判定企业是否发生交税行为。
本实施例中,给出企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、企业变更特征和企业申报特征的具体获取方法,使得第一风险量化模型可以准确的得到的第一风险量化值。
上述任一技术方案中,获取企业关联数据,构建企业关联关系拓扑图,具体包括:
构建节点
其中,
本实施例给出了构建企业关联关系拓扑图的具体方法,通过构建企业关联关系拓扑图,考虑企业之间的漂流关系(即企业之间的交易关系),可以更好的实现对企业洗票风险的精确量化。
上述任一技术方案中,基于企业关联关系拓扑图,获取风险扩散变量,具体包括:
获取风险接受度:
其中:
获取风险输出度:
其中:
获取风险差分变量:
其中:
本实施例中,给出风险接受度、风险输出度和风险差分变量的具体公式,通过上述公式,可以准确的得出风险扩散变量,进而实现对企业洗票风险的再量化。
上述任一技术方案中,获取数据之前还包括:建立逻辑斯蒂回归模型;获取历史稽查数据集合;根据历史稽查数据集合,获取历史稽查数据集合的第二特征向量集合;基于历史稽查数据集合的第二特征向量集合,对逻辑斯蒂回归模型进行训练,得到第二风险量化模型。
本实施例中,基于构见的第二特征向量集合,对逻辑斯蒂回归模型进行训练,构建第二风险量化模型,通过第二风险量化模型对第一风险量化值进行再量化,利用企业风险传播结果实现对企业洗票风险的动态评估和再量化,提高了洗票企业风险量化的精确性。
为实现本发明的第二目的,本发明的技术方案提供了一种增值税发票的检测装置,包括:存储器和处理器,存储器存储有程序或指令,处理器执行程序或指令,其中,处理器在执行程序或指令时,实现如本发明任一技术方案的增值税发票的检测方法的步骤。
本技术方案提供的增值税发票的检测装置实现如本发明任一技术方案的增值税发票的检测方法的步骤,因而其具有如本发明任一技术方案的增值税发票的检测方法的全部有益效果,在此不再赘述。
为实现本发明的第三目的,本发明的技术方案提供了一种可读存储介质,可读存储介质存储有程序或指令,程序或指令被执行时,实现上述任一技术方案的增值税发票的检测方法的步骤。
本技术方案提供的可读存储介质实现如本发明任一技术方案的增值税发票的检测方法的步骤,因而其具有如本发明任一技术方案的增值税发票的检测方法的全部有益效果,在此不再赘述。
本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为本发明一个实施例的增值税发票的检测方法流程示意图之一;
图2为本发明一个实施例的增值税发票的检测方法流程示意图之二;
图3为本发明一个实施例的增值税发票的检测方法流程示意图之三;
图4为本发明一个实施例的增值税发票的检测方法流程示意图之四;
图5为本发明一个实施例的增值税发票的检测方法流程示意图之五;
图6为本发明一个实施例的增值税发票的检测装置组成示意图;
图7为本发明一个实施例的增值税发票的检测方法方案示意图;
其中,图6和图7中附图标记与部件名称之间的对应关系为:
100:数据获取及预处理,102:原始数据,104:缺失值处理,106:异常值处理,108:量纲处理,110:噪声处理,112:去重处理,114:清洁数据,116:特征工程,120:企业交易特征,122:企业抽取变更特征,124:企业抽取申报特征,126:特征向量集合,130:模型训练,132:风险量化模型,134:税务数据,136:企业洗票风险初次量化值,138:基于拓扑信息的风险在量化,140:企业拓扑结构数据,142:风险扩散因子计算,144:企业风险再量化特征,146:逻辑斯蒂回归模型,200:增值税发票的检测装置,210:存储器,220:处理器。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
下面参照图1至图7描述本发明一些实施例的增值税发票的检测方法、装置和可读存储介质。
增值税发票洗票企业检测是指对涉嫌增值税专用发票洗票行为的一般纳税实体(企业)进行检测和甄别。从而实现对涉税违法企业的税法遵从风险预警,有效提高税收征管和稽查工作的效率。
鉴于增值税专用发票洗票企业检测任务对于税务稽查和征管等涉税业务的开展具有举足轻重的意义,该问题吸引了大量的学者以及税务从业者的注意力,并产出了一系列工作成果。目前关于增值税专用发票洗票检测问题的主要解决方案是基于专家评价指标体系的检测方案。现有方案在增值税专用发票洗票企业检测方面取得的一定的成效,同时也存在着一些局限和不足:
首先,基于评价指标体系的检测方案的检测性能取决于评价指标的选取、指标权重的设定以及风险定性阈值的设定等三项工作,但是评价指标的选取、指标权重和风险定性阈值的设定工作非常依赖税务专家的领域经验。因此,基于评价指标体系的检测方案存在泛化性能较差以及检测方案的可扩展性较差等局限。
其次,基于专家评价指标体系的洗票企业检测方案中的指标阈值的确定是基于专家经验的,是一个固定数值。上述阈值设定策略难以适应作案手法的变化更新,导致检测方案对于新型作案手法的适应性较差。
最后,已有相关解决方案的指标选取和特征工程工作均没有充分考虑一般纳税实体之间的拓扑结构信息,忽略了纳税实体之间的关联关系(交易关系、投资关系、同法人关系等)中蕴含的隐含信息,导致检测方案的精确性较差。
综上所述,本实施例的目的在于解决以上问题的至少之一,提出了融合企业之间拓扑结构信息与梯度提升树的增值税专用发票洗票企业检测解决方案。以期在海量注册纳税实体数据增值税专用发票洗票检测任务中可以更加精准稳定地检测出涉嫌增值税专用发票洗票行为的纳税实体,同时实现对洗票团伙的有效发现,缩短洗票企业检测的时间延迟,提高税务稽查以及风控部门对涉税风险预警响应的时效性和敏捷性。
实施例1:
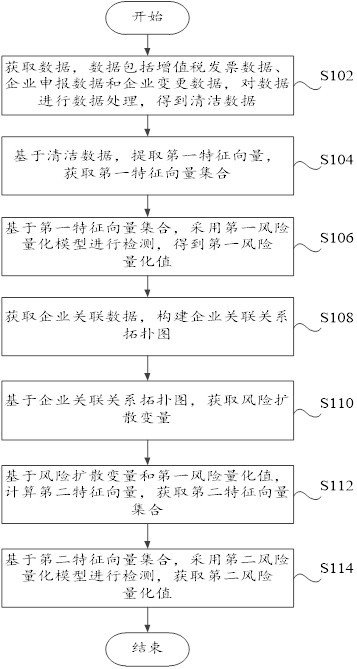
如图1所示,本实施例提供了一种增值税发票的检测方法,包括以下步骤:
步骤S102,获取数据,数据包括增值税发票数据、企业申报数据和企业变更数据,对数据进行数据处理,得到清洁数据;
步骤S104,基于清洁数据,提取第一特征向量,获取第一特征向量集合;
步骤S106,基于第一特征向量集合,采用第一风险量化模型进行检测,得到第一风险量化值;
步骤S108,获取企业关联数据,构建企业关联关系拓扑图;
步骤S110,基于企业关联关系拓扑图,获取风险扩散变量;
步骤S112,基于风险扩散变量和第一风险量化值,计算第二特征向量,获取第二特征向量集合;
步骤S114,基于第二特征向量集合,采用第二风险量化模型进行检测,获取第二风险量化值。
本实施例中,通过第一风险量化模型和第二风险量化模型,最终得到第二风险量化值,通过第二风险量化值判断企业是否发生洗票行为,本实施例提出了洗票风险扩散机制,对洗票风险在企业之间的扩散过程进行建模,实现了企业间风险扩散行为的精确捕获与计算,同时清晰地区分了正常企业与洗票嫌疑企业。
本实施例中,通过构建企业关联关系拓扑图,综合考虑了企业之间的关联关系数据,结合企业开票行为数据可以实现更加精细的刻画洗票企业的特点。
本实施例提出了企业洗票风险再量化策略,通过第二风险量化模型,对第一风险量化值进行再量化,利用企业风险传播结果实现对企业洗票风险的动态评估和再量化,提高了洗票企业风险量化的精确性。
本实施例中,通过第一风险量化模型和第二风险量化模型,进而实现风险两阶段量化策略,对企业洗票风险量化任务采用“分而治之”的策略降低了风险量化评估任务的复杂度,提升了风险量化框架的有效性和稳健性。
实施例2:
如图2所示,本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
在获取数据之前还包括以下步骤:
步骤S202,建立梯度提升树模型;
步骤S204,获取历史稽查数据集合,将历史稽查数据集合划分为训练数据集合、测试数据集合和验证数据集合;
步骤S206,分别获取训练数据集合、测试数据集合和验证数据集合的第一特征向量集合;
步骤S208,基于训练数据集合、测试数据集合和验证数据集合的第一特征向量集合,采用交叉验证方式,对梯度提升树模型进行训练和参数调整,得到第一风险量化模型。
本实施例中,采用梯度提升树模型作为最终的检测算法,可以显著提高洗票企业检测的精确率以及召回率,在提高洗票企业检测效率的同时确保稽查工作的有效开展。
本实施例中,对于历史稽查数据集合可以进行数据预处理,即对数据的数据格式进行的标准化处理,可以包括缺失值处理、异常值处理、量纲处理、去重处理、噪声处理等数据预处理步骤,实现数据的标准使之符合机器学习算法的要求,降低数据因素对检测模型推理性能的影响。
本实施例中,基于历史稽查数据构建训练数据集合,按照7:2:1的比例将数据集合划分为训练数据集合、测试数据集合和验证数据集合。基于训练数据集合和验证数据集合采用交叉验证方式进行模型训练和参数调整,获得洗票企业风险量化模型并进行本地化。
实施例3:
如图3所示,本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
对数据进行数据处理,具体包括以下步骤:
步骤S302,对数据进行缺失值处理、异常值处理、量纲处理、去重处理和/或噪声处理。
本实施例中,通过对数据进行预处理,实现数据的标准化,使预处理后后的数据符合机器学习算法的要求,降低数据因素对检测模型推理性能的影响。
实施例4:
如图4所示,本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
基于清洁数据,提取第一特征向量,获取第一特征向量集合,具体包括以下步骤:
步骤S402,根据清洁数据,抽取企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、抽取企业变更特征和企业申报特征;
步骤S404,获取第一特征向量集合,第一特征向量集合包括企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、企业变更特征和企业申报特征。
本实施例中,第一特征向量采取企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、抽取企业变更特征和企业申报特征,上述特征通过第一风险量化模型可以有效的反映出企业是否存在洗票行为。
实施例5:
本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
企业进销数量特征为:
其中,
企业进销金额特征为:
其中,
企业集中开票特征为:
其中,
企业顶额开票特征为:
其中,
企业开票金额变化特征为:
其中,
企业变更特征为:根据清洁数据中的企业变更数据,判定企业是否发生变更行为;
企业申报特征为:根据清洁数据中的企业申报数据,判定企业是否发生交税行为。
本实施例中,给出企业进销数量特征、企业进销金额特征、企业集中开票特征、企业顶额开票特征、企业开票金额变化特征、企业变更特征和企业申报特征的具体获取方法,使得第一风险量化模型可以准确地得到的第一风险量化值。
实施例6:
本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
获取企业关联数据,构建企业关联关系拓扑图,具体包括:
构建节点
其中,
本实施例给出了构建企业关联关系拓扑图的具体方法,通过构建企业关联关系拓扑图,考虑企业之间的漂流关系(即企业之间的交易关系),可以更好的实现对企业洗票风险的精确量化。
实施例7:
本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
基于企业关联关系拓扑图,获取风险扩散变量,具体包括:
获取风险接受度:
其中:
获取风险输出度:
其中:
获取风险差分变量:
其中:
本实施例中,给出风险接受度、风险输出度和风险差分变量的具体公式,通过上述公式,可以准确得出风险扩散变量,进而实现对企业洗票风险的再量化。
实施例8:
如图5所示,本实施例提供了一种增值税发票的检测方法,除上述实施例的技术特征以外,本实施例进一步地包括了以下技术特征:
获取数据之前还包括以下步骤:
步骤S502,建立逻辑斯蒂回归模型;
步骤S504,获取历史稽查数据集合;
步骤S506,根据历史稽查数据集合,获取历史稽查数据集合的第二特征向量集合;
步骤S508,基于历史稽查数据集合的第二特征向量集合,对逻辑斯蒂回归模型进行训练,得到第二风险量化模型。
本实施例中,基于构见的第二特征向量集合,对逻辑斯蒂回归模型进行训练,构建第二风险量化模型,通过第二风险量化模型对第一风险量化值进行再量化,利用企业风险传播结果实现对企业洗票风险的动态评估和再量化,提高了洗票企业风险量化的精确性。
实施例9:
如图6所示,本实施例提供了一种增值税发票的检测装置200,包括:存储器210和处理器220,存储器210存储有程序或指令,处理器220执行程序或指令;其中,处理器220在执行程序或指令时,实现如本发明任一实施例的增值税发票的检测方法的步骤。
实施例10:
本实施例提供了一种可读存储介质,可读存储介质存储有程序或指令,程序或指令被处理器220执行时,实现上述任一实施例的增值税发票的检测方法的步骤。
实施例11:
本实施例的增值税发票的检测方法,主要包括4个方面:数据获取与预处理、纳税实体开票行为特征抽取、基于梯度提升树模型的洗票企业检测和基于企业拓扑结构信息的风险再量化。
第一、数据获取与预处理
首先基于税务大数据平台获取纳税实体固定时间期限内的开票数据以及进票数据等数据,为降低发票数据中存在的偶然性,在本实施例中将时间期限设定为3个月。获取纳税企业的进项发票金额、进项发票开票时间、进项企业名称、销项发票金额、销项发票开票时间等数据。同时获取纳税实体(企业)之间的拓扑结构化关系数据,选取上述设定的时间期限内企业之间的票流关系数据,基于上述票流关系数据构筑企业之间的关联关系图。对上述的数据的数据格式进行的标准化处理,对缺失值进行处理。
第二、纳税实体开票行为特征抽取
本实施例依据增值税专用发票洗票违法行为的特点抽取了进销项数量之比、进销项金额之比、集中开票、顶额开票、开票金额变化、是否申报、是否变更等特征。
进销项数量之比反映出了纳税实体的进销项货物数量差异,是纳税实体洗票增值税发票的特征之一,其计算公式定义如下:
其中,
进销项金额之比从另外一个维度反映了企业的进销状况,是增值税发票洗票的主要特征之一,其计算公式定义如下:
其中,
集中开票是指违法企业在极短时间内大量洗票增值税专用发票,因此本实施例抽取该特征用于检测洗票企业,集中开票计算公式定义如下:
其中,
顶额开票是洗票企业重要特征表示企业开票金额是否是顶额开具的,顶额开票特征计算公式定义如下:
其中,
开票金额变化小是洗票企业在发票开具行为中比较明显的特点,本实施例对纳税实体所开具发票的金额的变化幅度进行了抽取,开票金额变化计算公式定义如下:
其中,
企业变更特征为:根据清洁数据中的企业变更数据,判定企业是否发生变更行为。本实施例中,是否申报是判断该纳税实体是否对应纳税额进行了申报,是判定企业是否偷逃税的重要指标。
企业申报特征为:根据清洁数据中的企业申报数据,判定企业是否发生交税行为。本实施例中,是否变更是指在指定时间间隔内纳税实体是否发生过法人变更等行为,对于洗票企业鉴定具有重要的作用。
第三、基于梯度提升树模型的洗票企业检测
通过上述的计算公式可以获得每个纳税实体的特征向量,该特征向量实现了对纳税实体开票行为的精准刻画。本实施例基于上述构造的特征向量利用梯度提升树分类模型对洗票企业检测问题进行建模,利用梯度提升树分类模型所具备的分类准确率高、适用于高维数据、兼容数据缺失问题等优点尝试实现对洗票企业的精准检测和识别。
梯度提升树基于boosting集成策略整合多个决策树模型的分类器,梯度提升树集成全部决策树的分类投票结果,将投票次数最多的类别标签指定为最终的类别标签输出。其输出的类别标签是由个别树输出的类别标签的众数而确定,在拥有较高分类准确率的同时保证了分类过程的鲁棒性。本实施例采用梯度提升树作为最终的检测算法可以显著提高洗票企业检测的精确率以及召回率,在提高洗票企业检测效率的同时确保稽查工作的有效开展。
第四、基于企业拓扑结构信息的风险再量化
基于梯度提升树算法利用企业开票行为信息对企业增值税专用发票洗票行为检测问题进行建模可以实现对企业开票过程中存在的洗票行为的检测和识别。除此之外,依据风险扩散理论目标企业的上下游企业如果洗票风险较高则目标企业存在较大风险的可能性较高,但是上述建模过程中没有考虑企业之间的漂流关系(即企业之间的交易关系),故而上述模型难以实现对企业洗票风险的精确量化。
本实施例在建模过程中引入企业之间的票流关系信息,对企业之间的风险扩散过程进行建模,实现对企业风险的再量化。
首先利用企业关联数据构筑企业交易关系拓扑图:
(1)节点
(2)节点上的数值
(3)节点上的数值
(4)节点之间的边
(5)边上的数值
然后为每一家企业计算接受度ACC和输出度EXP,其中企业
企业
计算第
最后基于上述企业关联关系和企业风险扩散变量对企业洗票风险再量化任务进行建模:
为企业
其中:
将上述构造的风险再量化训练数据集合以及企业洗票违法行为标签输入到逻辑斯蒂回归模型,并进行模型参数估计,进而实现对企业洗票风险的再量化过程。
实施例12:
如图7所示,本实施例的增值税发票的检测方法,包括以下几个方面:
(1)数据获取及预处理100
1)首先获取企业增值税专用发票数据、企业申报数据、企业变更数据,即原始数据102。
2)对上述原始数据102进行缺失值处理104、异常值处理106、量纲处理108、去重处理112、噪声处理110等数据预处理步骤,得到清洁数据114,实现数据的标准使之符合机器学习算法的要求,降低数据因素对检测模型推理性能的影响。
3)获取企业之间在规定时间间隔内的交易关系以及交易数据,基于企业交易关系构筑企业关联关系图G=
(2)纳税实体开票行为特征抽取(即特征工程116)
1)对基于处理后的清洁数据114依据进销数量计算公式为每家企业抽取进销数量特征。
2)对基于处理后的数据依据进销金额计算公式为每家企业抽取进销金额特征。
3)对基于处理后的数据依据集中开票度量计算公式为每家企业抽取集中开票特征。
4)对基于处理后的数据依据顶额开票度量计算公式为每家企业抽取顶额开票特征。
5)对基于处理后的数据依据进开票金额变化度量计算公式为每家企业抽取开票金额变化特征。
6)对基于处理后的数据依据数据中变更时间,判定该企业是否发生变更行为,为每家企业抽取变更特征122。
7)对基于处理后的数据依据申报表数据中的已纳税额数据,判定该企业是否发生交税行为,为每家企业抽取申报特征124。
其中,企业交易特征120包括:进销数量特征、进销金额特征、集中开票特征、顶额开票特征和开票金额变化特征。
基于上述得到的特征,形成特征向量集合126。
(3)基于梯度提升树模型的洗票企业检测(即模型训练与风险量化128)
1)模型训练130
基于历史稽查数据构建训练数据集合,按照7:2:1的比例将数据集合划分为训练数据集合、测试数据集合和验证数据集合。基于训练数据集合和验证数据集合采用交叉验证方式进行模型训练和参数调整,获得洗票企业风险量化模型并进行本地化。
本实施例中,通过特征向量集合126和梯度提升算法130,进行模型训练和模型验证,得到基于梯度提升树的风险量化模型132。
2)企业洗票风险量化
基于税务数据134,在真实生产环境中依据模型推理结果中的分类概率作为企业洗票风险值,构成企业洗票风险初次量化值136。
(4)基于拓扑信息的风险在量化138
1)风险扩散因子计算142
利用企业拓扑结构数据140计算企业洗票风险扩散因子,利用计算获得的企业洗票风险扩散因子和企业洗票风险初次量化值136计算企业洗票风险再量化特征向量(即企业风险再量化特征144)。
2)风险再量化模型训练
基于构见的企业洗票风险再量化特征数据集合,对逻辑斯蒂回归模型146进行训练,构建企业洗票风险再量化模型。
3)企业洗票风险再量化
基于上述企业风险再量化模型对注册企业进行洗票行为风险量化工作。
本实施例的优点主要如下:
第一:本实施例综合考虑了企业之间的关联关系数据,结合企业开票行为数据可以实现更加精细的刻画洗票企业的特点。
第二:提出了洗票风险扩散机制,对洗票风险在企业之间的扩散过程进行建模,实现了企业间风险扩散行为的精确捕获与计算,同时清晰地区分了正常企业与洗票嫌疑企业。
第三:本实施例首先提出了企业洗票风险再量化策略,利用企业风险传播结果实现对企业洗票风险的动态评估和再量化,提高了洗票企业风险量化的精确性。
第四:本实施例采用风险两阶段量化策略,对企业洗票风险量化任务采用“分而治之”的策略降低了风险量化评估任务的复杂度,提升了风险量化框架的有效性和稳健性。
综合以上,本实施例相比于传统的基于专家评价指标体系的洗票企业检测方案,本实施例能够准确地提高洗票企业检测和风险量化系统的准确性和鲁棒性。
综上,本发明实施例的有益效果为:
1.本实施例中,通过第一风险量化模型和第二风险量化模型,最终得到第二风险量化值,通过第二风险量化值判断企业是否发生洗票行为,本实施例提出了洗票风险扩散机制,对洗票风险在企业之间的扩散过程进行建模,实现了企业间风险扩散行为的精确捕获与计算,同时清晰地区分了正常企业与洗票嫌疑企业。
2.本实施例中,通过构建企业关联关系拓扑图,综合考虑了企业之间的关联关系数据,结合企业开票行为数据可以实现更加精细地刻画洗票企业的特点。
3.本实施例提出了企业洗票风险再量化策略,通过第二风险量化模型,对第一风险量化值进行再量化,利用企业风险传播结果实现对企业洗票风险的动态评估和再量化,提高了洗票企业风险量化的精确性。
在本发明中,术语“第一”、“第二”、“第三”仅用于描述的目的,而不能理解为指示或暗示相对重要性;术语“多个”则指两个或两个以上,除非另有明确的限定。术语“安装”、“相连”、“连接”、“固定”等术语均应做广义理解,例如,“连接”可以是固定连接,也可以是可拆卸连接,或一体地连接;“相连”可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
本发明的描述中,需要理解的是,术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或单元必须具有特定的方向、以特定的方位构造和操作,因此,不能理解为对本发明的限制。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 增值税发票的检测方法、装置和可读存储介质
- 增值税发票数据的处理方法、装置及计算机可读存储介质