一种多因素风电场发电量预测方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及风电场发电量预测领域,具体涉及一种基于VMD-PCA数据预处理算法的BASO-KSVR多因素风电场发电量预测方法。
背景技术
随着风力发电技术的逐步成熟,风电场发电已经是新能源发电的主要组成部分,风电场发电量预测成为新能源领域的主要研究课题之一,其发电量的准确预测是制定发电、输配电系统的规划和运行策略的关键环节之一,风电厂的机组调度也在很大程度上依赖于对发电量的精确预测。但由于风电场发电量的影响因素众多,比如风速、温度、历史发电量等,导致其发电量的预测比较困难,常见的预测方法有如下不足之处:发电量的预测精准度较低,无法达到理想的预测效果;常见的发电量预测一般是基于历史发电量或者负荷数据,然后通过常见的人工智能预测方法进行预测计算,但这种方法没有考虑风电场发电量变化的内在原因,比如风速、温度等内、外部因素对风电场发电器材和发电效率的影响。针对上述问题,本专利提出一种基于VMD-PCA数据预处理算法的BASO-KSVR多因素风电场发电量预测方法,该方法一方面通过天牛群算法对KSVR预测算法进行优化,提升算法的预测精准度;另一方面,考虑可以对风电场发电量产生影响的各种因素,并对这些因素的历史数据进行VMD处理,接着,使用PCA方法对分解后的数据降维处理,作为历史数据集,输入到预测模型当中,从而对发电量数据进行预测。
发明内容
针对现有技术的不足,本发明提供一种基于VMD-PCA数据预处理算法的BASO-KSVR多因素风电场发电量预测方法,首先VMD算法对影响风电场发电量的关键参数的历史数据进行分解,形成初步数据集;其次,使用主成分分析法对处理后的数据进行数据降维处理,形成最终数据集;再次,针对天牛算法寻优效率低下与粒子群算法寻优参数早熟的问题,将两者优点相结合,形成新的天牛群算法,达到更好的参数寻优效果;然后,针对常规SVR算法预测精度较低,参数选取困难的问题,使用天牛群算法对KSVR的关键参数进行寻优,以提升预测精度;最后,将数据集输入到优化后的算法模型当中,得到预测数据。
本发明是通过以下技术方案解决以上技术问题的:
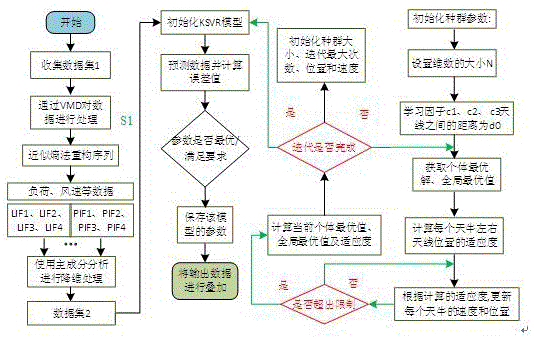
一种基于VMD-PCA数据预处理算法的BASO-KSVR多因素风电场发电量预测方法,其特征在于以下步骤:S1:通过VMD将原始信号(待预测的风电场的历史发电量数据、同周期风电场风速数据、同周期风电场地区温度数据、风电场地区的历史负载数据等)进行数据处理,分别分解为PIF1、PIF2、PIF3、PIF4等;S2:通过近似熵法对分解序列进行序列重构;S3:使用主成分分析方法对S1中的10组数据进行数据降维处理,选取合适维度的主成分数据作为后续的输入数据;S4:构建初始KSVR模型;S5:将降维处理后的数据输入KSVR模型并进行模型的训练;S6:计算发电量的预测数据与结果的误差值;S7:判断KSVR模型的参数是否为最优值或者满足误差要求,若不满足要求,则执行S7的BASO算法对KSVR算法的参数进行调优;S8:利用BASO优化算法对KSVR模型的参数进行寻优处理,并重新对模型进行训练;S9:若KSVR模型的参数为最优参数,保存该模型的参数,对输出数据进行叠加得到预测结果。
收集历史数据,包括待预测风电场的历史发电量数据、同周期风电场风速数据、同周期风电场地区温度数据、待预测风电场地区的历史负载数据等。
S21:通过希尔伯特变换计算收集到的相关数据,得到各阶的模态函数的分量u
S22:调整模态的中心频率,将频谱进行偏移调节,公式如下:
其中,f(t)表示给定的待处理信号,u
S23:为了将约束问题转化为无约束问题,引入拉格朗日算子τ和惩罚项因子α,以简化计算过程,如下所示:
通过不断的优化上式,可以得到模态分量和对应的中心频率公式为:
其中,
S31:将上述所有VMD分解后的数据和原始数据为基础,建立样本初始数据矩阵X;
X=(x
X=(x
式中,X为一个由m×n的VMD处理后的数据构成的样本数据矩阵;n为每个种类的数据的长度;n为不同数据种类的个数,也可以认为是数据的维度。
S32:用归一化方程来标准化处理初始数据矩阵X,标准化后的矩阵Z的公式如式7:
S33:求解相关系数矩阵为:
对相关系数矩阵进行特征值λ和特征向量的求解,每个指标以及累计指标的计算公式如式9:选取使累计方差达到85%的指标作为主成分。
构建初始KSVR模型,包括选择RBF核函数作为SVR的核函数,设置优化参数C、gamma与其取值范围,将均方根误差作为模型的精度指标。
RBF的核函数公式为:
K(x
式中:κ是核半径。
为充分利用经过PCA降维处理后的数据,使用多核加权线性支持向量回归模型,表达式如下:
式中:μ
优化问题的求解目标为:
其中η为松弛因子。
约束为:
式中:b代表偏置;ο是不敏感损失;ω代表决策平面的权值系数;
决策函数更新为:
式中:y′为误差数值;α表示拉格朗日乘子。
将S33步骤中得到的降维处理后的数据作为新的数据集,输入KSVR模型并进行模型的训练。
计算根据预测模型得到的发电量的预测数据与真实结果的三种类型的误差指标:平均平均误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)。
式中:其中,N为数据点总量,FX
判断KSVR模型的参数是否为最优值或者满足误差要求,若不满足要求,则执行S7的BASO算法对KSVR算法的参数进行调优。
利用BASO优化算法对KSVR模型的参数进行寻优处理,并重新对模型进行训练,包括:
S81:初始化天牛群初始飞行速度、位置;
S82:导入训练样本并应用BASO算法针对优化目标进行迭代优化,设定天牛群算法的种群规模、迭代次数、位置以及活动范围等初始参数。
S83:利用模型上一次的预测结果的MSE作为适应度函数,寻优过程记录每个天牛的运动状态。
S84:根据公式更新天牛的速度、位置、并进行迭代的判断。
惯性权重的更新公式为:
W=W
其中:N、N
个体的速度计算公式:
其中:P
速度的更新公式:
q1、q2、q3是学习因子;r是随机函数;δ
算法更新位置的公式为:
S85:重复S84、S85步骤,达到迭代次数后计算中止,退出并返回天牛群的最优参数,如参数C、gamma最优值。
S86:利用S82得到的最优参数构建新的KSVR模型。
利用KSVR模型的最优参数,对输出数据进行叠加得到预测结果。
针对当前风电场发电量预测算法精度低、预测考虑的因素单一的问题,本发明提出了一种基于VMD-PCA数据预处理算法的BASO-KSVR风电场发电量多因素预测方法,该方法首先考虑了影响风电场发电量的多种因素,利用VMD算法对历史数据进行分解,接着使用PCA算法对分解后的数据进行降维处理,得到待预测的数据集;进一步针对SVR算法预测精度低下的问题,使用天牛群算法对KSVR算法的关键参数进行优化处理,提升算法的预测精度,最后,将VMD-PCA算法处理后的数据集输入到模型中,得到预测数据。
附图说明
图1为本发明实施的策略步骤流程图;
图2是本发明的算法优化效果图;
图3是本发明的不同算法的对比图。
具体实施方式
下面结合附图对本发明进行详细说明:
在本实施例中,为了验证本专利中采用的控制方法的正确性和有效性,本专利选取两个方面的对比:
1、对比本专利的天牛群算法相对粒子群算法和天牛须算法在寻优效果上的优势。
2、对比多因素数据集条件下的本专利算法、BASO-KSVR算法、KSVR算法、SVR算法与仅将历史发电量作为数据集的BASO-KSVR算法与KSVR算法、SVR算法对风电场的发电量预测的各个评价指标数据。
三种算法的寻优运行过程结果如图2所示,
从图2可知,本专利提出的算法在三种算法中的最终适应度函数数值最小,算法整体收敛速度快于其它算法,表明了本专利提出的优化算法具有一定的优势与创新性;
选取某地区的风电场的历史运行数据作为数据集,对比多因素数据集条件下的本专利算法、BASO-KSVR算法、KSVR算法、SVR算法与仅将历史发电量作为数据集的BASO-KSVR算法与KSVR算法、SVR算法对风电场的发电量预测的评价指标数据,如表1和图3所示:
表1、各个算法的三种评价指标对比表
由表1和图3可知,本专利提出的发电量预测方法三种评价指标的数值均为所有方法中的最小值,证明本专利提出的方法相比其它方法在风电场发电量预测方面更有优势。
本发明公开了一种基于VMD-PCA数据预处理算法的BASO-KSVR风电场发电量多因素预测方法,首先,使用VMD对多因素数据集进行分解,得到分解后的数据集;其次,利用PCA方法以累计贡献率前85%的标准对分解后的数据集进行数据的降维处理;再次,为解决天牛算法寻优效率低下与粒子群算法寻优参数早熟的问题,设计天牛群算法,包含两个原始算法的优点,达到更好的参数寻优效果;然后,为了提高常规SVR算法预测精度,利用天牛群算法对KSVR算法的关键参数进行优化处理,提升预测精度;最后,输入数据集到本专利提出的算法模型当中,得到风电场发电量的预测数据。