一种基于K-CNN--N-GRU的煤矿机械电机状态预测方法
文献发布时间:2023-06-19 18:46:07
技术领域
本发明涉及电机状态预测技术领域,具体涉及一种基于K-CNN--N-GRU的煤矿机械电机状态预测方法。
背景技术
露天煤矿机械设备具有典型的低速重载、运行环境恶劣且多变等特点,带式输送机作为煤矿串联式生产线中运输煤炭的关键设备,其安全高效运行直接影响煤矿企业的生产效益。其中异步电机作为带式输送机的主要动力来源,其运行可靠性直接影响整个系统的稳定运转,一旦发生故障停机,将威胁到整个生产系统的安全,造成极大的经济损失。
露天煤矿电机长期暴露在复杂恶劣环境中,电机的状态变量受环境因素和负载变化扰动较大,频繁出现单一状态变量瞬时超限的误报警。常用的基于深度学习的特征提取方法为端到端式,即在开始时输入参数,在最后一层输出特征结果,提取的特征往往不够显著。
名称为“一种基于混合神经网络的风力发电机故障识别方法”,专利号为[CN202110488921.7]的专利,提供了一种基于混合神经网络的风力发电机故障识别方法,具体包括采集齿轮箱时域波形数据,建立原始样本数据,并为数据打标签;提取波形数据中振幅的最小值、振动速度和峭度指标作为特征;将提取的故障和正常特征值输入到混合网络1D-CNN-Bi-GRU中,混合网络串联了1D-CNN和Bi-GRU,首先利用1D-CNN作为初级网络提取序列局部特征,然后将1D-CNN的输出作为Bi-GRU的输入,利用Bi-GRU的特性,同时获得正向来自过去和反向的来自未来的累积依赖信息,进一步提取序列的长期依赖特征来进行故障诊断;保存模型,将待分析的数据输入到模型中,输出故障分类结果。
由于现有故障识别方法采用先提取电机状态的浅层特征或深层特征,后采用时间序列模型预测深层特征的变化趋势,以预测残差值来表征电机的状态,未能综合提取电机状态的不同维度特征,因此存在电机状态特征提取不全面,状态预测的精度较低等缺点。
发明内容
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于K-CNN--N-GRU的煤矿机械电机状态预测方法,通过分析异步电机大量历史数据,对未来某一时间段异步电机运行状态进行预测,并对预测后的状态进行评估,可检测异步电机潜在的异常状态,并在故障进一步恶化之前合理安排维护措施,具有提高电机可靠性、降低维护成本的特点。
为实现上述目的,本发明采取的技术方案是:
一种基于K-CNN--N-GRU的煤矿机械电机状态预测方法,包括以下步骤:
步骤一:采集煤矿机械电机数据,所述的煤矿机械电机数据包括电流、前轴温度、后轴温度、绕组温度、环境温度、皮带秤瞬时量6个状态参数;并将这6个状态参数作为样本数据集;
步骤二:将步骤一的样本数据集进行预处理,剔除非正常项后进行最小最大值归一化处理;
步骤三:将步骤二预处理后的数据进行皮尔逊相关系数Pearson分析,得到相关性系数,以相关性系数作为各参数的加权系数,通过加权系数实现数据融合,得到一维融合参数D;
步骤四:对经典卷积神经网络CNN架构进行三组特征提取,利用核主成分分析KPCA将三组特征提取的结果降为一维,得到K-CNN模型;
步骤五:将步骤三得到的一维融合参数D输入到步骤四得到的K-CNN模型,得到特征提取结果,将得到的特征提取结果划分训练集和测试集;
步骤六:将训练集输入到门控循环单元GRU模型中,GRU模型输出预测值,将输出的预测值,使用均方误差函数作为损失函数来计算实际值与预测值之间的误差,并使用优化器优化目标函数,调整模型参数使得目标函数达到最小值,此时训练所得模型的性能最佳,模型训练好后,将测试集输入到门控循环单元GRU模型中,模型输出预测后的值及均方根误差RMSE;
步骤七:利用神经网络架构搜索NAS,改进并优化门控循环单元GRU算法,得到N-GRU模型;
步骤八:将步骤五得到的K-CNN模型提取后的特征结果输入到步骤七得到的N-GRU模型做预测,得到未来一周的数据,即K-CNN--N-GRU模型输出结果;
步骤九:计算步骤八得到的K-CNN--N-GRU模型输出结果与真实值之差即预测残差;
步骤十:采用滑动平均滤波法对步骤九得到的进行平滑处理,并保证模型的输出和输入长度相等;
步骤十一:针对步骤十平滑处理后的预测残差数据,使用网格搜索GridSearchCV寻找似然估计最大化时的带宽即最优带宽,通过核密度估计KDE得到概率密度函数,并用辛普森Simpson对概率密度函数求积分到0.95即95%的置信区间,从而得到告警阈值。
所述步骤二中的数据预处理包括:(1)剔除单一状态参数超过告警阈值的数据;(2)参考电机的故障日志,剔除人工停机和故障停机时的数据;(3)通过最小最大值归一化来消除量纲,以线性的方式把数据转换到[0,1]之间,变量α的第i个数据归一化后的值αi*:
式中,αi为变量α的第i个数据归一化前的值,α
所述步骤三中的一维融合参数D,具体过程包括:
皮尔逊相关系数r
式中,X、Y为两组变量;X
权重系数U
式中,U
通过权重系数加权得到一维融合参数D,从而实现数据融合,加权后的一维融合参数D计算:
式中,A
所述步骤四利用核主成分分析KPCA将三组特征提取的结果降为一维过程为:核主成分分析KPCA对原始数据空间R即对CNN架构进行三组特征提取后输出的数据,进行非线性映射Φ:R→F;具体如下:
(1)原始数据xk(k=1,2,.........,N)在特征空间F的映射为Φ(x
式中x
(2)矩阵ST对应的特征方程为:
λV=S
式中,λ为特征值,V为特征向量;
将Φ(x
λ[Φ(x
(3)特征向量V可由Φ(x
式中,a
进一步得:
(4)定义矩阵K∈R
由特征向量a求出S
式中,V
(5)计算M个测试样本在特征空间中前p个轴的投影为:
[Φ(y
式中,y
对映射数据K进行中心化,进而得到:
式中,Q
高斯核函数
所述步骤五得到特征提取结果的过程为:按照故障日志和预测时长来划分练集和测试集,并通过比较时间窗口依次为5、10、15、20时的均方根误差RMSE值,选择均方根误差RMSE值最小时对应的时间窗口。
所述步骤六的调整模型参数使得目标函数达到最小值,此时训练所得模型的性能最佳,过程为:通过比较Epoch依次为4、8、12、16、20时的均方根误差RMSE值,并选择均方根误差RMSE值最小时对应的Epoch,在每次训练迭代时计算损失函数的梯度,进而更新GRU模型的权重和偏置。
所述步骤六所述GRU模型的初始设置为:第一层GRU的优化器为adam,激活函数为tanh函数,用于循环时间步的激活函数为sigmoid函数,神经元个数为5,第二层全连接层Dense的神经元个数为1。
所述步骤七得到N-GRU模型具体如下:
使用四层神经网络来进行时序预测,第一、二层为门控循环单元GRU,第三、四层为全连接层Dense,网络架构为:输入→门控循环单元GRU→门控循环单元GRU→全连接层Dense→全连接层Dense→输出;
搜索空间设置包括:第一层GRU中激活函数为sigmoid函数或tanh函数,神经元个数为4或5或6,用于循环时间步的激活函数为sigmoid函数或tanh函数;第二层GRU中神经元个数为0或4或8或16;第三层Dense中神经元个数为0或4或8或16,第四层神经元个数为1;共包括192个组合;搜索策略为:针对目标函数
其中,L表示数据的样本个数,Fu表示实际数据,Fu′表示预测数据,调用函数对上述192种组合进行多目标搜索,得到所有组合的均方根误差RMSE,通过比较找到RMSE最小的组合,按照该组合进行参数设置,即得N-GRU模型。
所述步骤七构建N-GRU模型时,搜索策略共包含三种,具体为:
(1)强化学习搜索策略
调用policy_gradient函数对上述192种组合进行多目标搜索,得到所有组合的均方根误差RMSE,通过比较找到RMSE最小的组合。强化学习算法中的梯度计算公式为:
式中,π
优化目标函数T(θ)时采用随机梯度上升方法,获得最大的未来累积奖励,计算公式为:
式中,θ为网络参数,κ为学习率;
(2)遗传算法搜索策略
基于进化算法的方法,采用遗传算法,选择算子的公式为:
式中,f
交叉算子是遗传算法中产生新个体的主要方法,因具有全局搜索能力被作为主要算子;而变异算子只是产生新个体的辅助方法,只有局部搜索能力,这里采用单点交叉算子和基本位变异算子;
遗传算法中需要选择确定的运行参数主要有群体大小O、终止代数T、交叉概率P
式中,f
(3)可微分网络架构搜索DARTS
采用可微分网络架构搜索DARTS,DARTS定义的cell共包含7个结点,其中前两个结点为输入结点,分别代表最近临的前两个cell的输出,中间的4个结点,每个都通过有向边与其所有前序结点相连,公式如下:
式中,g
可微分网络架构搜索DARTS在cell中引入了架构参数δ,将离散问题转化为连续参数的优化问题,以架构参数作为权重,构建了加权的混合操作;该算法还使用softmax函数对架构参数进行松弛化操作,把架构参数的值归一化到(0,1)之间;松弛化操作后,上述公式中的混合操作I(H,J)变形为:
式中,
所述步骤十中采用滑动平均滤波法对预测残差进行平滑处理,公式为:
式中,e为原始时间序列,
相对于现有技术,本发明的有益效果为:
1、传统的电机状态预测方法无法体现不同监测参数对状态预测的重要性,本发明采用皮尔逊相关系数Pearson计算电机各监测参数的相关性,并通过相关性系数得到权重系数,加权求和得到一维融合参数,从而实现数据融合,为电机的状态预测提供一维观测指标,加权后的一维融合参数变化趋势较单一状态变量更加稳定,体现出不同监测参数对状态预测的重要性。
2、本发明克服了传统卷积神经网络只提取最深层特征而无法实现特征选择的缺点,采用卷积神经网络的各卷积层提取多维度不同层次的状态特征,然后使用核主成分分析法对多维状态特征进行选择与融合,能够准确表征电动机状态变化的一维特征,更加准确地提取电机状态特征。
3、本发明构建了N-GRU模型,采用神经网络架构搜索(NAS)优化GRU的结构参数,搭建的NAS搜索架构包括三种参数寻优方法,分别为基于强化学习的参数优化,基于进化算法的参数优化以及基于梯度下降的参数优化,该搜索架构根据模型输入数据的特点,自适应选择不同参数寻优方法,提高了网络参数优化的效率和网络模型的预测精度,与传统的基于遗传算法或粒子群算法相比,更具有普适性,提高了GRU网络参数的优化效率,解决了传统GRU算法参数欠优化问题。
附图说明
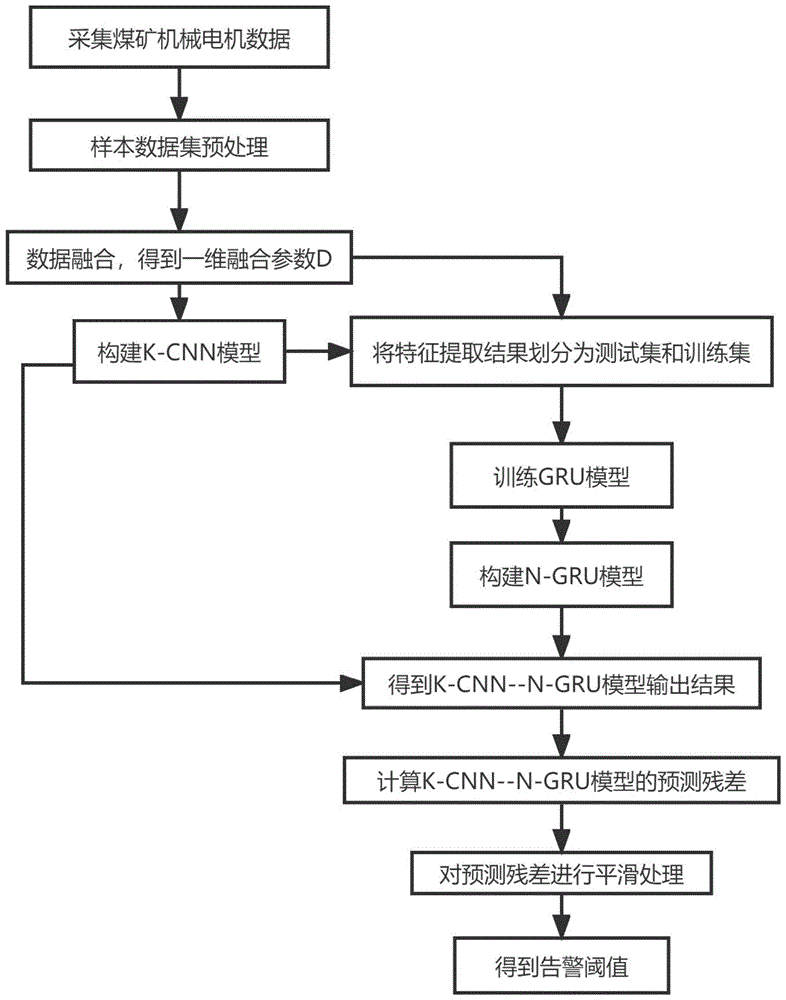
图1是本发明的流程图。
图2本发明K-CNN模型的结构流程图。
图3是本发明K-CNN模型与CNN模型特征提取结果对比图。
图4是本发明N-GRU模型的结构流程图。
图5是本发明多算法预测结果对比图。
图6是本发明多算法预测残差对比图。
图7是本发明核密度估计KDE求得的概率密度函数图。
图8是本发明绕组温度超过告警阈值的趋势图。
图9是本发明预测残差经平滑处理后与阈值的对比图。
具体实施方式
下面结合附图对本发明的工作原理作详细叙述。
如图1所示,一种基于K-CNN--N-GRU的煤矿机械电机状态预测方法,包括以下步骤:
步骤一:采集煤矿机械电机数据,并将其作为样本数据集,样本数据集包括电流、前轴温度、后轴温度、绕组温度、环境温度、皮带秤瞬时量,6个状态参数,这6个状态参数均由安装在电机上的传感器获取;
步骤二:将步骤一的样本数据集进行预处理,包括:(1)剔除前轴温度大于90℃的数据,剔除后轴温度大于90℃的数据,剔除绕组温度大于120℃的数据;(2)参考电机的故障日志,剔除人工停机和故障停机时的数据;(3)通过最小最大值归一化来消除量纲,以线性的方式把数据转换到[0,1]之间,公式为:
式中,α
步骤三:经步骤二预处理后样本数据集分别和后轴温度、前轴温度、电流通过皮尔逊相关系数Pearson,得到相关性系数,通过权重分配得到权重系数,如表1、表2、表3所示,具体过程包括:
皮尔逊相关系数r
式中,X、Y为两组变量;X
权重系数U
式中,U
表2前轴温度相关性分析
表3电流相关性分析
根据表1、表2、表3中的权重系数分别加权得到一维融合参数D
式中,A
将得到的一维融合参数D
表4相关性分析
由表4可知,一维融合参数D
如图2所示,步骤四:构建K-CNN模型
对经典卷积神经网络CNN架构进行三组特征提取;核主成分分析KPCA对原始数据空间R即对CNN架构进行三组特征提取后输出的数据进行非线性映射Φ:R→F;
(1)原始数据x
式中,x
(2)矩阵S
λV=S
式中,λ为特征值,V为特征向量
将Φ(x
λ[Φ(x
(3)特征向量V可由Φ(x
式中,a
将式(8)代入式(7)得
(4)定义矩阵K∈R
由特征向量a求出S
式中,V
(5)计算M个测试样本在特征空间中前p个轴的投影为
[Φ(y
式中,y
对映射数据进行中心化,相应K变为
式中,Q
高斯核函数
其中,参数σ
一维融合参数D
将特征提取结果合并为一个整体,总输入维度为[60,491,3],经核主成分分析KPCA降维后输出维度为[60,491,1],此为K-CNN模型的输出结果;
如图3所示,将K-CNN模型和卷积神经网络CNN模型特征提取的结果进行对比,可见K-CNN模型提取后的特征比卷积神经网络CNN更明显,峰值部分更突出,更能表征出数据的变化趋势;
步骤五:数据集划分:故障日志表明电机在2021年12月14日4:23出现电机绕组超温异常,将步骤四K-CNN模型得到的结果前27443个数据作为训练集,后672个数据作为测试集,如表5,以10个步长作为一个时间窗,前9个数据作为模型输入,来预测第10个数据值:
表5不同时间窗口下RMSE值
步骤六:将训练集输入到门控循环单元GRU模型中,输出预测后的值,使用均方误差(RMSE)函数作为损失函数来计算实际值与预测值之间的误差,并使用adam优化器优化目标函数,如表6,取Epoch=12,在每次训练迭代时计算损失函数的梯度,进而更新门控循环单元GRU模型的权重和偏置;
表6不同Epoch下RMSE值
传统门控循环单元GRU模型一般有两层神经网络:第一层为门控循环单元GRU,第二层为全连接层,GRU单元结构可描述为:
z
r
式中,dt为当前层第t个时间步的输入向量,h
GRU模型初始设置:第一层门控循环单元GRU的优化器(optimizer)为adam,激活函数(activation)为tanh函数,用于循环时间步的激活函数(recurrent_activation)为sigmoid函数,神经元个数(neurons1)为5,第二层全连接层Dense的神经元个数为1;
在模型训练好后,将测试集输入到门控循环单元GRU模型中,输出预测后的值及均方根误差RMSE;
如图4所示,步骤七:构建N-GRU模型
利用神经网络架构搜索(NAS),改进并优化传统的门控循环单元GRU算法,得到N-GRU模型,N-GRU模型主要考虑使用最多四层神经网络来进行时序预测,第一、二层为门控循环单元GRU,第三、四层为全连接层Dense,网络架构为:输入→门控循环单元GRU→门控循环单元GRU→全连接层Dense→全连接层Dense→输出;
搜索空间:第一层门控循环单元GRU中的激活函数为tanh函数或sigmoid函数,2种选择,神经元个数为4或5或6,3种选择,用于循环时间步的激活函数有tanh函数或sigmoid函数,2种选择;第二层门控循环单元GRU的神经元个数为0或4或8或16,4种选择;第三层全连接层Dense中神经元个数为0或4或8或16,4种选择;第四层全连接层Dense中神经元个数为1,1种选择,总共有2×3×2×4×4×1=192个组合;
搜索策略:针对目标函数
其中,L表示数据的样本个数,F
通过基于进化算法的方法,采用遗传算法,选择算子的公式为:
式中,f
遗传算法中需要选择确定的运行参数主要有群体大小O、终止代数T、交叉概率P
式中,f
采用上述遗传算法调用maximize函数对上述192种组合进行多目标搜索,得到所有组合的均方根误差RMSE,通过比较找到均方根误差RMSE最小的组合,按照该组合进行参数设置,即得N-GRU模型;
搜索结果:第一层门控循环单元GRU的神经元个数为4,激活函数为sigmoid函数,用于循环时间步的激活函数为relu函数;第二层门控循环单元GRU的神经元个数为0,第三层全连接层Dense的神经元数量为16,其余参数默认为门控循环单元GRU模型初始设置,最终选择的网络架构去掉第二层门控循环单元GRU,即输入→门控循环单元GRU→全连接层→全连接层→输出,此网络架构即为N-GRU。
如图5所示,步骤八:根据以上步骤分别运用门控循环单元GRU模型和N-GRU模型来预测未来一周的数据,K-CNN--N-GRU模型即先通过K-CNN模型特征提取后采用N-GRU模型做预测,K-CNN--GRU模型即先通过K-CNN模型特征提取,后采用门控循环单元GRU做预测,CNN--GRU模型即先通过卷积神经网络CNN特征提取,后采用门控循环单元GRU做预测,将K-CNN--N-GRU模型与K-CNN--GRU、CNN--GRU的预测结果作对比,选取均方根误差RMSE、平均绝对误差MAE、平均绝对百分比误差MAPE作为误差评价指标,通过这三个指标对各预测模型性能进行比较,如表7
表7误差评价指标
如图6所示,步骤九:得到上述K-CNN--N-GRU与K-CNN--GRU、CNN--GRU模型的预测残差对比图,预测残差即预测值与真实值之差;
步骤十:采用滑动平均滤波法对预测残差进行平滑处理,公式为:
式中,e为原始时间序列,ē为平滑处理后的时间序列,τ为滑动窗口大小,w=τ+1,τ+2,......,ε+1,其中ε为原始时间序列的长度;
滑动窗口为50,mode中有‘full’,‘valid’,‘same’三种模式可选,此处选择‘same’模式,可以保证输出和输入长度相等;
如图7所示,步骤十一:针对训练集的残差数据,使用网格搜索GridSearchCV寻找似然估计最大化时的带宽,即最优带宽,经计算为0.011,通过核密度估计KDE得到概率密度函数,并用辛普森Simpson对概率密度函数求积分到0.95,即95%的置信区间,得到阈值为0.0192。
如图8所示,故障日志表明电机在2021年12月14日4:23分出现电机绕组超温异常,绕组温度在第147.6849h超过告警阈值100,此阈值为企业设定的告警阈值。
如图9所示,可以看出经平滑处理后,总的上升趋势更加明显,线条更加光滑,更能直观地反映未来的变化趋势,因此有必要对预测残差进行平滑处理;K-CNN--N-GRU模型对应的预测残差在第75h后,总的趋势是一直在上升,且在第126.6042h超过告警阈值0.0192,即电机进入异常告警状态,相比实际出现绕组超温异常而言,提前约21h发现异常,便于及时安排维护策略,K-CNN--GRU比实际出现绕组超温异常而言提前约12.7h发现异常,CNN--GRU比实际出现绕组超温异常而言滞后约1h发现异常K-CNN--GRU、CNN--GRU以及实际出现绕组超温异常均比K-CNN--N-GRU模型发现异常时间晚。