一种基于HTML结构特征的端到端色情网站侦测方法
文献发布时间:2023-06-19 18:53:06
技术领域
本发明涉及侦测搜索技术领域,具体是一种基于HTML结构特征的端到端色情网站侦测方法。
背景技术
近年来,随着互联网的快速发展,人们的生活越来越依赖于互联网,无论是从网络上获取各种信息还是人们日常的衣食住行,都呈现出向互联网靠拢的趋势。与此同时,诸如色情、暴力、博彩等不良网站也屡禁不止,严重影响了儿童和青少年的身心健康。深入研究色情网站识别方法,提出相应的侦测和防范措施,具有重要的理论研究和实际应用价值。
HTML网页源代码一般分为head头部和body主体两部分,其中head部分描述了文档的各种属性和信息,主要有meta标签、title标签、style标签等。body部分用于放置网页中的所有内容,如文字、图片、链接、表格等,Head部分的title标签虽然刻画了网页的标题,但很多色情网站会对其进行伪装。本文对2万多条数据进行分析,构建爬虫模型获取title标签,经去重操作,还剩17806条数据,其中以域名或者URL作为标题的有5934条,有872条数据是以**公司为标题,如眉山**信息科技有限公司、朝阳**影院有限公司等,两者占比接近40%。此外,还有诸如“首页”、“主页”等不能刻画色情信息的文本作为标题。因此title标签的色情语义信息量不高。
Body部分涵盖了网页的文本信息,单色情网站不同于一般的正常网站,色情网站的body部分通常具有:1、网页内图片较多,文本相对较少,2、与赌博类网站相互关联,含赌博类文本,3、除了不良文本,还有非色情文本,因此,依据网页内容来判定色情语义信息量并不精准,无法准确刻画网站类型。
Head部分的meta标签是网页源代码中非常重要的标签,用来描述一个网站的属性,如作者、日期、网页描述、网站关键词、页面刷新等,能提高网站的点击率和转化率,进而提高网站的排名。meta标签可以提供有关页面的元信息,这些元数据将服务于搜索引擎,便于搜索引擎机器人的抓取。meta标签有name属性和http-equiv属性,name属性的主要作用是描述网页,其重要的参数是description和keywords。keywords是分类关键词,向搜索引擎说明网站的类别,便于搜索引擎对网站进行分类。description是网站的描述,通常为网页内容的摘要,与网页标题、网页主体内容有高度的相关性,会尽可能准确的描述网页的核心内容,搜索引擎会通过description获取网站的主要内容。
基于此,现在提供一种基于HTML结构特征的端到端色情网站侦测方法,可以消除现有装置存在的弊端。
发明内容
本发明的目的在于提供一种基于HTML结构特征的端到端色情网站侦测方法,以解决背景技术中的问题。
为实现上述目的,本发明提供如下技术方案:
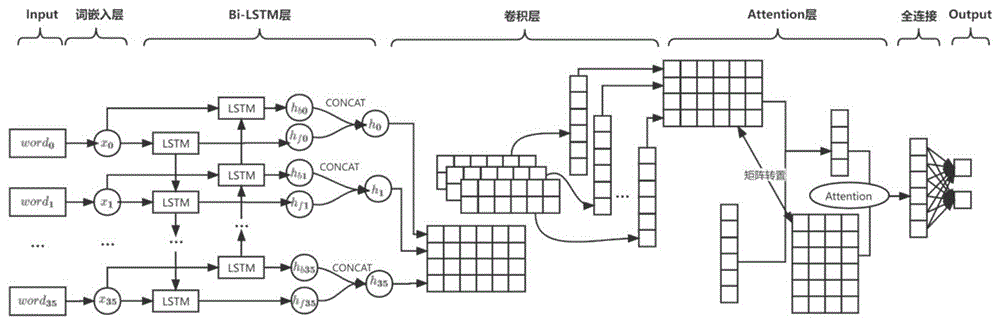
一种基于HTML结构特征的端到端色情网站侦测方法,包括词嵌入层、Bi-LSTM层、卷积层、Attention层;
词嵌入层:构建只有一个隐藏层的神经网络,对one-hot编码的向量进行大规模训练,得到带有语义信息的低维向量;
word2vec包含skip-gram和CBOW两种训练方式,CBOW算法是给定上下文来预测当前词,skip-gram算法是通过当前词预测周围的词。由于skip-gram每个词都受到周围词的影响,在作为中心词时要进行多次的预测、调整,因此对于偏僻词来说,使用skip-gram算法相对来说更加准确。因此本文选择word2vec中skip-gram算法对文本进行编码;
Bi-LSTM层;
循环神经网络(RNN)非常适合处理序列化数据,故构建循环神经网络用于色情网站侦测,基于细胞状态和门结构的LSTM模型,有效解决了RNN模型存在梯度消失和梯度爆炸的问题,且可以捕捉文本的长距离依赖信息,因此采用LSTM模型;
卷积层:
TextCNN可以利用多个大小不同的卷积核来提取文本的局部特征,从而能更好的捕捉局部的相关性;
Attention层:
经过Bi-LSTM层和卷积层,捕捉了文本的整体和局部语义信息,为了突出文本的重点信息,本文在卷积层后增加了Attention层。Attention机制可以捕捉同一个句子内部不同位置的信息依赖,让模型对重要信息重点关注。
在上述技术方案的基础上,本发明还提供以下可选技术方案:
在一种可选方案中:词嵌入层中首先用HanLP分词工具将文本按词划分并在word2vec向量字典中进行匹配。然后对无法匹配的词继续分词并尝试匹配,具体步骤如下;
Step1.读取基于skip-gram算法训练的word2vec文件并制作成向量字典,在字典中填充
Step2.输入String类型的词word,在向量字典中查询word;
Step3.如果word存在字典中,则取出其词向量并将c置为1,跳转Step8,否则跳转Step4;
Step4.如果word.length==1,用
Step5.如果word.length%2==0,跳转到Step6,否则跳转到Step7;
Step6.将word.substring(0,word.length/2),word.substring(word.length/2,word.length)的结果分别作为输入词并跳转到Step2;
Step7.word.substring(0,(word.length-1)/2)和
word.substring((word.lengt–1)/2,word.length)记为group1,word.substring(0,word.length/2)和word.substring(word.length/2,word.length)记为group2,将group1和group2中的词分别作为输入词并跳转到Step2,统计group1和group2中的c的数量分别记为c1、c2,将Math.max(c1,c2)所在组的匹配结果作为最终的词向量;
Step8.算法结束。
在一种可选方案中:Bi-LSTM层中,LSTM在t时刻输出h
f
i
o
h
其中,
在一种可选方案中:Bi-LSTM层由两层LSTM组成,能同时捕捉正反两个方向的长距离依赖。第一层LSTM的输入是文本的头部,输出记为
在一种可选方案中:卷积层中,建了含有100个卷积核的卷积神经网络,卷积核的高度h是提取上下h个词的语义信息,卷积核的宽度d与词向量维度一致。第i个卷积核经过卷积操作得到向量
在一种可选方案中:Attention层中,设LSTM层的输出为
α=softmax(M
Att
模型参数:
首先基于selenium构建爬虫模型获取色情和非色情网站的网页源代码。分别提取meta标签、title标签和body标签作为文本数据集,利用HanLP工具对文本分词,分词后通过词嵌入层得到特征矩阵
在一种可选方案中:Bi-LSTM层是两层LSTM结构,两层LSTM中的lstm_units参数均设置为50,即每层LSTM的输出维度为
在一种可选方案中:在卷积层中,卷积核的宽度和词向量维度一致,高度设置为2。为保持输入输出矩阵维度不变,卷积核数量设置为100,滑动步长设置为1,padding参数设为same模式,即采用zero-padding方式填充边界。每个卷积核经过卷积操作得到向量
Attention层计算每个词的注意力权重,将文本的向量表示由
相较于现有技术,本发明的有益效果如下:
本申请针对现有搜索方式的弊端进行改进,基于meta标签的语义表征和色情信息关联性极大,将其作为文本数据并进行色情网站的侦测与判定会取得良好的效果。
附图说明
图1为本发明的模型图。
图2为本发明Bi-LSTM层结构图。
图3为本发明卷积过程示意图。
图4为本发明本文长度折线图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。
在一个实施例中,如图1-图3所示,一种基于HTML结构特征的端到端色情网站侦测方法,包括词嵌入层、Bi-LSTM层、卷积层、Attention层;
词嵌入层:
自然语言处理中第一步需要将文字转化为计算机能读懂的数字,也就是词的向量化。传统的词向量化是one-hot编码,one-hot根据词库的大小,将词编码成1*n维的向量,当词库数据很大时,会产生维度灾难。经过one-hot编码的向量,有一位是1,其余n-1位是0,无法对词的语音信息进行表达,产生语义鸿沟问题。
为了解决以上问题,Mikolov等人于2013年提出了word2vec方法,其主要思想是构建只有一个隐藏层的神经网络,对one-hot编码的向量进行大规模训练,得到带有语义信息的低维向量。word2vec包含skip-gram和CBOW两种训练方式,CBOW算法是给定上下文来预测当前词,skip-gram算法是通过当前词预测周围的词。由于skip-gram每个词都受到周围词的影响,在作为中心词时要进行多次的预测、调整,因此对于偏僻词来说,使用skip-gram算法相对来说更加准确。因此本文选择word2vec中skip-gram算法对文本进行编码。而在实际代码中,由于自己的语料规模相对较小,往往直接使用谷歌基于大数据语料预训练好的word2vec向量字典,该字典能表征常用的字词。
常见的词向量生成有基于字划分和基于词划分两种。基于字划分是将文本按字分割,将每个字转换为嵌入向量。该方法虽然简单易行,但会导致很多词汇丢失部分语义信息,如“在”和“线”两个字显然和“在线”这个词表达的意思不一致。基于词划分是将文本按词分割,然而色情词汇不同于普通的词语,很多色情词在word2vec向量字典无法匹配,无论是直接丢弃还是将其赋值为0向量,都会丢失大量的语义信息。针对上述方法存在的问题,本文提出了一种基于word2vec向量字典的色情词向量生成算法。首先用HanLP分词工具将文本按词划分并在word2vec向量字典中进行匹配。然后对无法匹配的词继续分词并尝试匹配,具体步骤如下:
Step1.读取基于skip-gram算法训练的word2vec文件并制作成向量字典,在字典中填充
Step2.输入String类型的词word,在向量字典中查询word;
Step3.如果word存在字典中,则取出其词向量并将c置为1,跳转Step8,否则跳转Step4;
Step4.如果word.length==1,用
Step5.如果word.length%2==0,跳转到Step6,否则跳转到Step7;
Step6.将word.substring(0,word.length/2),word.substring(word.length/2,word.length)的结果分别作为输入词并跳转到Step2;
Step7.word.substring(0,(word.length-1)/2)和
word.substring((word.lengt–1)/2,word.length)记为group1,word.substring(0,word.length/2)和word.substring(word.length/2,word.length)记为group2,将group1和group2中的词分别作为输入词并跳转到Step2,统计group1和group2中的c的数量分别记为c1、c2,将Math.max(c1,c2)所在组的匹配结果作为最终的词向量;
Step8.算法结束。
例如,HanLP分词工具将“在线视频”划分为一个词,该词在word2vec向量字典中不存在,基于算法1,将其分为“在线”和“视频”两个词,在向量字典中均能查到。实验表明,此算法能够最大程度的保留词的语义信息。本文根据分词结果,将每条文本词的总长度L设为36,若L不足36,则将用0向量填充补齐;若L超过36,则截断到第36个词。
Bi-LSTM层:
循环神经网络(RNN)非常适合处理序列化数据,故构建循环神经网络用于色情网站侦测。基于细胞状态和门结构的LSTM模型,有效解决了RNN模型存在梯度消失和梯度爆炸的问题,且可以捕捉文本的长距离依赖信息,因此采用LSTM模型。LSTM在t时刻输出h
f
i
o
h
其中,
为了更全面的提取文本中语义信息,本文构建了Bi-LSTM层网络,其结构如图3所示,Bi-LSTM层由两层LSTM组成,能同时捕捉正反两个方向的长距离依赖。第一层LSTM的输入是文本的头部,输出记为
卷积层:
Bi-LSTM层关注的是文本的整体语义信息,为了提取局部语义信息,本文在Bi-LSTM层后构建了卷积网络。TextCNN可以利用多个大小不同的卷积核来提取文本的局部特征,从而能更好的捕捉局部的相关性。如图3所示,本文构建了含有100个卷积核的卷积神经网络,卷积核的高度h是提取上下h个词的语义信息,卷积核的宽度d与词向量维度一致。第i个卷积核经过卷积操作得到向量
Attention层:
经过Bi-LSTM层和卷积层,捕捉了文本的整体和局部语义信息,为了突出文本的重点信息,本文在卷积层后增加了Attention层。Attention机制可以捕捉同一个句子内部不同位置的信息依赖,让模型对重要信息重点关注,对信息进行权重分配。
设LSTM层的输出为
α=softmax(Mlstm·W
Att
模型参数:
首先基于selenium构建爬虫模型获取色情和非色情网站的网页源代码。分别提取meta标签、title标签和body标签作为文本数据集,利用HanLP工具对文本分词,分词后通过词嵌入层得到特征矩阵
Bi-LSTM层是两层LSTM结构,两层LSTM中的lstm_units参数均设置为50,即每层LSTM的输出维度为
在卷积层中,卷积核的宽度和词向量维度一致,高度设置为2。为保持输入输出矩阵维度不变,卷积核数量设置为100,滑动步长设置为1,padding参数设为same模式,即采用zero-padding方式填充边界。每个卷积核经过卷积操作得到向量
Attention层计算每个词的注意力权重,将文本的向量表示由
实验:
数据来源:目前在色情网站侦测方面没有公开的数据集,本文通过自建数据集做实验。实验数据中的色情网站由国内某科研机构提供,从Alexa中文排行榜中爬取并标注得到合法网站,两者组合成原始数据集,共包含23530条含标签的样本,其中色情网站11730个,合法网站11800个,二者比例约为1:1。通过爬虫模型获取每个网站的HTML源代码并提取meta标签、title标签和body标签,构建基于meta标签的文本数据集、title标签数据集和body标签数据集;
实验环境:实验是在windows 10操作系统下运行的,编程语言为python,基于selenium构建爬虫模型,深度学习框架为Tensorflow,具体实验运行环境及版本号如表2所示:
评价标准:为了验证侦测方法的有效性,本文采用精确率P、召回率R和F1值作为评价指标,精确率表示预测为色情网站,且实际也是色情网站的概率,召回率则衡量了对色情网站的识别能力,F1值平衡考虑精确率和召回率,能综合评估模型的性能。具体计算公式如下:
其中,TP表示将色情样本预测为色情样本的数目,FP表示将正常样本预测为色情样本的数目,FN表示将色情样本预测为正常样本的数目;
实验分析:实验5.4.1和5.4.2采用五折交叉验证,将样本分为5组,每组中色情文本和正常文本的比例约为1:1,对五组循环实验,依次取其中一组Z作为验证集,其余四组作为训练集,将五次的结果取平均值作为模型的最终结果;
文本数据集对比:为了验证本文提出的meta标签文本以及基于word2vec向量字典的色情词向量生成算法的有效性,本文构建了title标签数据集、meta标签数据集和body标签数据集三种,对title文本和body文本采用基于词划分的词向量生成,对meta文本采用基于字划分的词向量生成(c-Meta)、基于词划分的词向量生成(w-Meta)和基于算法1的词向量生成(s-Meta)。将上述五种数据集分别作为输入数据传入本文模型,实验结果如表3所示:
由表3可知,对比title数据集和body数据集,本文所提的meta文本在精确率、召回率和F1值三个指标上均取得最优结果。因为无论是title文本还是body文本,均包含了一定量的非色情文本,而meta文本的语义表征能够更精准的反映色情网站。对比基于字划分的词向量,基于词划分的词向量所包含的色情语义信息更加充足,因此侦测结果优于前者。本文在实验过程中发现,分词工具对文本的分词结果颗粒度较大,部分词在word2vec向量字典中无法匹配,若直接将其填充为0向量,会丢失大量的语义信息。故提出了基于算法1的词向量生成方法,实验表明,本文所提算法进一步提升了模型的侦测效果,F1值达到了0.9630。
模型对比:
本文选取了5种基准模型,分别是TextCNN模型、Bi-LSTM模型、TextCNN+Bi-LSTM模型、Bi-LSTM+TextCNN模型、Bi-LSTM+Attention模型,实验结果如表4所示:
实验结果显示,TextCNN和Bi-LSTM组合效果优于Bi-LSTM模型和TextCNN模型,而Bi-LSTM+TextCNN组合效果优于TextCNN+Bi-LSTM模型,这表明在Bi-LSTM层之后增加卷积层来捕捉文本的局部特征是有效的。Bi-LSTM和Attention机制组合优于Bi-LSTM模型,这表明增加Attention机制关注文本的重点信息也是有效的。基于Bi-LSTM+TextCNN+Attention的协同模型取得了最佳结果,表明本文构建的Bi-LSTM+TextCNN+Attention协同模型充分发挥了各层网络的优势,在Bi-LSTM层捕捉长距离依赖特征的同时也关注了局部特征与重点信息;
文本总长度L对比:
对色情网站meta标签进行分词、数据清洗并绘制的文本长度折线图,如图4所示,横坐标表示的是文本总长度L,纵坐标表示数量。如L为36时,数量为220,表示有220条文本是36个单词;
由图4可知,L的跨度很大。若将L设置为一个较小的数字,则大量文本会丢失语义信息;若将L设置为一个较大的数字,则大量文本会填充无用信息,因此选择合适的L能增强模型的准确度。当L为36时,文本数量明显下降,当L>80时,文本数量降为个位数,据此本文将L分别设置为8,16,32,36,64,80,128并进行实验。实验结果如表5所示,故本文最终将L设置为36;
表5文本总长度L实验结果:
卷积核高度对比:
在卷积层中,卷积核的高度h表示对前后h个词的局部关注,如h=2表示提取相邻两个词的局部特征。为了选取最佳的h,本文分别将h设置为2,3,4,5,6。实验结果如表6所示,故本文最终将h设置为2。
以上所述,仅为本公开的具体实施方式,但本公开的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本公开的保护范围之内。因此,本公开的保护范围应以权利要求的保护范围为准。
- 基于声学特征与文本情感特征融合的端到端语音合成方法及系统
- 基于声学特征与文本情感特征融合的端到端语音合成方法及系统