一种结合注意力互斥正则的图像分类方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及图像处理技术领域,具体涉及一种结合注意力互斥正则的图像分类方法。
背景技术
图像分类是根据不同类别图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。目前的图像分类方法,通常采用神经网络模型作为手段,但是在神经网络模型的训练过程中,神经网络模型对图片多个目标区域的关注仍不够理想,例如图3中的第二列模型只关注单个区域等,模型性能有待优化。
发明内容
为了解决以上问题的一个或多个,提供一种结合注意力互斥正则的图像分类方法。
根据本发明的一个方面,提供了一种结合注意力互斥正则的图像分类方法,包括:
导入图像;
提取图像特征;
对图像特征进行分类;
所述对图像特征进行分类包括利用图像分类模型的最终损失函数更新模型参数。其有益效果是:结合注意力互斥正则的图像分类方法的训练阶段同时也是构建图像分类模型的过程,而在测试阶段,图像输入该模型后,可以得知所输入的图像类别。
在一些实施方式中,所述导入图像包括将用于训练的图像数据集输入图像分类模型中。所导入的训练图像数据集需包括不同类别的训练图像。其有益效果是:让图像分类模型在训练阶段学习不同类别的训练图像模式。
在一些实施方式中,所述提取图像特征包括将一张训练图像通过CNN网络提取图像特征,从而得到特征图。由于需根据所提取的图像特征进行区分不同类别的训练图像。其有益效果是:有助于区分不同类别的训练图像。
在一些实施方式中,所述提取图像特征包括先将所述特征图转为注意力图,挑选注意力图中指定数目的注意力通道。注意力图对应的是关注训练图像上的哪些区域。其有益效果是:有利于体现对训练图像不同区域的关注。
在一些实施方式中,所述提取图像特征还包括:
判断注意力通道是否为候选关键通道和限制候选关键注意力通道关注互不重叠的区域。其有益效果是:可以更好地根据图像特征来对图像进行分类。
在一些实施方式中,所述判断注意力通道是否为候选关键通道包括:
选取一个值作为阈值,若注意力通道的权重大于该阈值,则判断该注意力通道为候选关键通道。注意力通道所对应的权重越大说明注意力通道对应的训练图像区域越重要。其有益效果是:有助于选取候选关键区域。
在一些实施方式中,所述限制注意力通道关注互不重叠的区域包括:
计算注意力互斥正则损失函数,所述注意力互斥正则损失函数根据以下公式进行计算:
其中,L
在一些实施方式中,所述对图像特征进行分类还包括:
对所述注意力图和特征图执行特征融合操作得到图像的最终特征;
对图像的最终特征执行多分类操作,得到输入图像的类别;
计算图像分类模型的最终损失函数。其有益效果是:根据所得到的图像特征对图像分类。
在一些实施方式中,图像分类模型的最终损失函数包括注意力互斥正则损失函数和交叉熵损失函数。其有益效果是:计算总损失函数可以用于更新图像分类模型的参数。
根据本申请的另一个方面,提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时所述的一种结合注意力互斥正则的图像分类方法的步骤。其有益效果是:运用所述计算机程序对训练图像进行分类。
本发明的结合注意力互斥正则的图像分类方法,模型关注到图像目标的不同区域,通过限制模型关注各注意力通道互不重叠的多个关键候选区域,并整合各候选关键区域的信息,提高模型的性能,继而提高图像分类的准确性。
附图说明
图1为本发明一实施方式的结合注意力互斥正则的图像分类方法的训练流程示意图;
图2为本发明一实施方式的结合注意力互斥正则的图像分类方法的测试流程示意图;
图3为运用本发明方法与现有技术对相同原始图像得出的注意力热区域图的对比图。
具体实施方式
下面结合附图对本发明作进一步详细的说明。
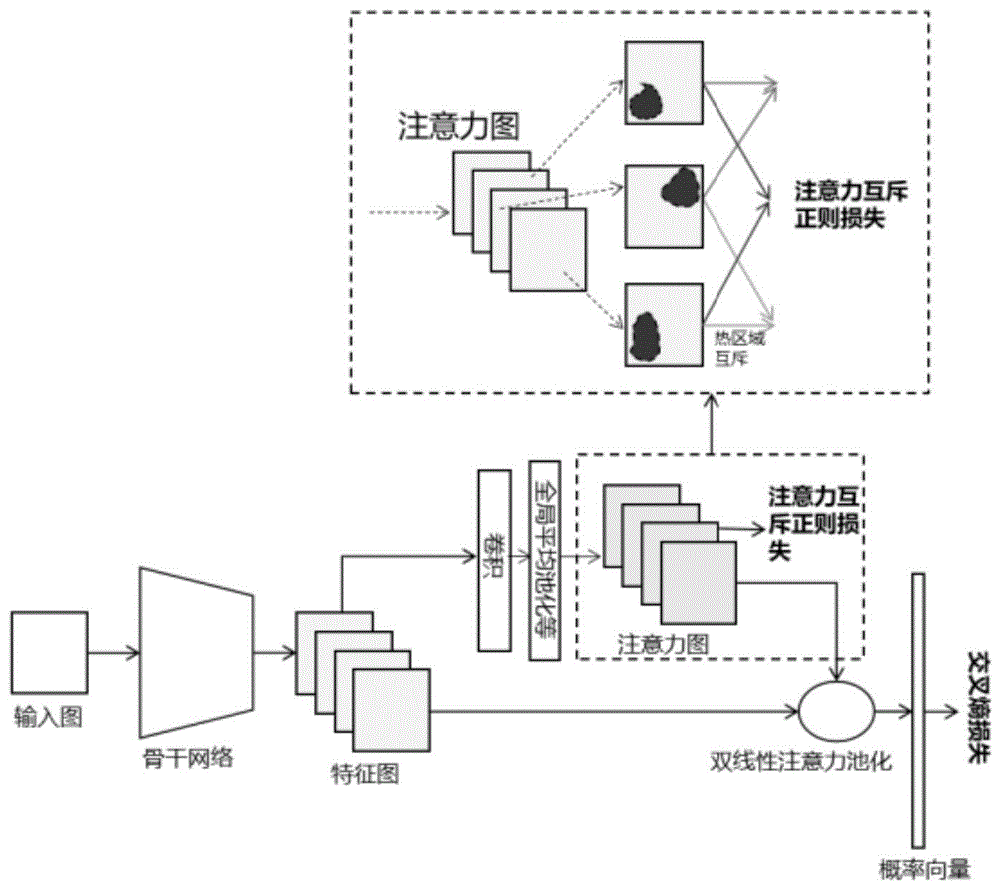
图1-2示意性地显示了根据本发明的一种实施方式的结合注意力互斥正则的图像分类方法。如图所示,该方法包括:
导入图像;
提取图像特征;
提取图像特征包括挑选注意力图中指定数目的若干注意力通道;
对图像特征进行分类;
对图像特征进行分类包括利用图像分类模型的最终损失函数更新模型参数。
导入图像为将筛选好的图像数据集导入训练模型。图像数据集的类别包括但不限于:汽车类、鸟类和飞机类图像。
提取图像特征为将图像数据集里的其中一张图像通过骨干网络提取特征,得到特征图。可选的,骨干网络可以为VGG网络或Resnet网络或其他CNN网络。
本实施例中训练图像尺寸为200×200,由于图像为RGB格式,因此图像在模型训练过程时实则是200×200×3的矩阵。
由于图像所对应的矩阵计算量较大,因此通过层层卷积操作压缩成尺寸较小的特征图。压缩后特征图所对应的矩阵大小为图像所对应矩阵大小的
挑选注意力图中指定数目的若干注意力通道包括:
将特征图依次经过卷积层和RELU激活函数层得到注意力图。卷积层的卷积核的步幅为1,数目为64,卷积核的尺寸为3×3。
注意力图所对应的实则为一个三维矩阵,三维矩阵具有长度、宽度和高度。注意力图通道数目为注意力图所对应三维矩阵的高度。
将注意力图的各个注意力通道权重作为概率,挑选指定数目的若干注意力通道。所挑选的注意力通道数目需小于特征图的通道数目。注意力通道数目取值范围为3至10,所选取的数值必须为整数。各注意力通道体现为训练图像的不同区域。若注意力通道权重越大说明该注意力通道越重要。
提取图像特征还包括判断注意力通道是否为候选关键通道和限制候选关键注意力通道关注互不重叠的区域。
判断注意力通道是否为候选关键通道进一步包括:从所设定的范围内选取一个值作为阈值,若注意力通道的权重大于该阈值,则判断该注意力通道为候选关键通道。
具体的,按照以下公式进行判断:
其中,A
本实施例中,阈值从所设定的范围为[0.5,0.8]中挑选。注意力通道的权重最大值为1,最小值为0。而数值越大说明该矩阵对应的注意力通道越重要。注意力通道实则对应的是训练图像的候选关键区域。因此,阈值的具体数值需大于0.5。可选的,阈值也可以从[0.5,0.9]中挑选。
首先从范围[0.5,0.8]里选择一个随机数值作为阈值,然后判断注意力通道的权重是否大于阈值,若是,说明大于阈值的通道是候选关键通道。
限制注意力通道关注互不重叠的区域进一步包括:
计算注意力互斥正则损失函数。
注意力互斥正则损失函数根据以下公式进行计算:
其中,L
其中,
注意力互斥正则损失函数可用于更新图像分类模型的参数。注意力互斥正则损失函数为两个注意力通道上不重叠区域的程度值,该数值越小代表不同区域之间越不重叠,数值越大就代表不同区域之间越重叠。
对图像特征进行分类还包括:
将注意力图和特征图融合得到最终的图像特征。
本实施例中,将注意力图和特征图融合得到最终图像特征所运用的方法为现有技术中的双线性注意力池化操作。
对图像的最终特征执行多分类操作,得到输入图像的类别。其中,多分类操作包括计算交叉熵损失函数。
其中,本实施例中的对图像的最终特征执行多分类操作,实际将图像的最终特征通过softmax分类器进行分类,得出不同类别。
计算图像分类模型的最终损失函数。
所述交叉熵损失函数根据以下公式计算得到:
其中,L
结合注意力互斥正则损失函数和交叉熵损失函数得到图像分类模型的最终损失函数。
图像分类模型的最终损失函数根据以下公式进行计算得到:
L=αL
上述均为如图1所示的图像分类模型的训练阶段,如图2为图像分类模型的测试阶段。
在图像分类模型的测试阶段中,只需输入图像,就可以得到属于各个类别的概率,进而得到输入的图像属于哪个类别。
以下表格为根据公开数据集Stanford cars测试集作为本发明模型及现有技术输入,得到的测试准确率。
表1
Stanford Cars测试集的数据来源为:Krause J,Stark M,Deng J,et al.3dobject representations for fine-grained categorization[C]//Proceedings of theIEEE international conference on computer vision workshops.2013:554-561。
表1中的B-CNN方法的数据来源为:Lin T Y,RoyChowdhury A,Maji S.BilinearCNN models for fine-grained visual recognition[C]//Proceedings of the IEEEinternational conference on computer vision.2015:1449-1457。
表1中的OSME方法的数据来源为:张文轩,吴秦.基于多分支注意力增强的细粒度图像分类[J].计算机科学,49(5):105-112。
表1中的WS-DAN方法的数据来源为:Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer visionand pattern recognition.2018:7132-7141。
表1中的CSE方法的数据来源为:Sun M,Yuan Y,Zhou F,et al.Multi-attentionmulti-class constraint for fine-grained image recognition[C]//Proceedings ofthe European Conference on Computer Vision(ECCV).2018:805-821。
表1中的Resnet50方法的数据来源为:He K,Zhang X,Ren S,et al.Deepresidual learning for image recognition[C]//Proceedings of the IEEEconference on computer vision and pattern recognition.2016:770-778。
本实施例运用本发明方法将公开数据集Stanford cars中的测试集作为输入进行测试,得到如表1的准确率。如表1所示,运用本发明方法的准确率高于运用现有技术中的其他方法的准确率。其中,本发明方法的注意力通道数目指定为三。
图3示意性地显示了运用本发明方法与现有技术中的其他方法对相同原始图像得出的注意力热区域图的对比图。同时,如图3可以看到,第一列为原始的目标类图像,第二列为现有技术中的注意力热区域图,第三列为使用本发明方法的注意力热区域图。可以看出本发明方法让模型关注到目标类图像的不同区域。
以上所述的仅是本发明的一些实施方式。对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。