一种基于SUMO的多智能体强化学习自主开发接口
文献发布时间:2023-06-19 19:28:50
技术领域
本申请属于智能交通规划决策以及强化学习算法领域,具体涉及一种基于SUMO的多智能体强化学习自主开发接口。
背景技术
在目前的智能交通规划与决策领域,对于车辆规划与决策的研究往往停留于单智能体层面,即在算法评估的环节只涉及个体的利益得失,这种研究可以实现个体利益的最优化,但是如果推广到交通的高交互性场景中会暴露出群体效益不足的问题,往往会形成零和博弈的局面,即某一个体的最优化意味着其他个体利益受损的情况。
因此,对于智能交通系统来说,研究多智能体的协同规划决策是必要的。多智能体的协同控制可以通过个体之间的合作实现更高的群体收益,例如在拥堵的路口如果添加统筹管理的交警会显著提高群体车流的通过效率。强化学习是目前主流采取的规划决策研究方法,其与基于规则的算法相比具有显著的探索性强、理解性强等优点,而且可以充分利用大数据技术的优势。但是考虑到强化学习算法在学习过程中具有明显的不稳定性,因此无法通过实车试验的方式实行,需要依托于成熟的仿真平台进行。
SUMO是目前公开可用并广受研究者选取进行多智能体规划决策研究的智能化交通仿真平台。目前场景的构建目前主要基于flow库函数通过代码行的形式进行,这样构建的场景更容易与强化学习算法结合。但是该种方式存在明显的弊端,即基于flow库的SUMO场景构建完全基于代码行的方式进行,使用者在构建场景的过程中对于场景的观察是不直接的,也是不直观的,从而导致场景构建难度较高并且容易出现程序报错。
SUMO官方提供了一种构建场景地图的方式,通过可视化界面进行场景的自由构建,并能生成对应的场景.xml文件。但是该文件无法直接与python进行关联,与强化学习的结合也更加困难。
发明内容
本申请提出了一种基于SUMO的多智能体强化学习自主开发接口,旨在解决场景构建便利性与强化学习程序实现无法同时实现的矛盾,为广大研究者提供一个便利的程序接口进行基于SUMO自构建场景的强化学习相关研究。
为实现上述目的,本申请提供了如下方案:
一种基于SUMO的多智能体强化学习自主开发接口,包括以下步骤:
搭建main函数主体;
基于所述main函数主体,搭建强化学习网络模型构建软件包;
基于所述强化学习网络模型构建软件包,搭建强化学习模型构建软件包;
基于所述main函数主体,构建SUMO环境软件包;
基于所述SUMO环境软件包,搭建SUMO环境更新软件包;
基于所述SUMO环境更新软件包,搭建状态处理软件包;
基于所述main函数主体,搭建奖励函数软件包。
优选的,所述main函数主体主要由强化学习的主进程组成,其中包括基本超参数的设置、场景加载、强化学习模型初始化以及强化学习主循环-次循环进程。
优选的,所述强化学习模型初始化包括:网络以及buffer的初始化构建,为后续的学习过程提供数据承载点。
优选的,所述搭建强化学习网络模型构建软件包储存的是网络构建函数,可以根据实际需求对网络的每一层以及每一层的节点数量进行编辑,同时也可以定义网络层的类型。
优选的,所述搭建强化学习模型构建软件包包括:优化器的设定、replay_buffer的设定以及探索性算法的设定,最后定义了网络的更新方式。
优选的,所述构建SUMO环境软件包包括:以SUMO场景构建伴随生成的.xml文件为数据源,在python项目进程中形成仿真数据环境。
优选的,所述搭建SUMO环境更新软件包包括:通过check_state函数对于SUMO仿真平台内的状态进行提取,在状态提取过程中结合了SUMO自带的traci库函数,将所需的所有参数进行打包、存储以及更新。
优选的,所述搭建状态处理软件包包括:通过get_step函数对于状态空间进行整体排布,最终形成两个矩阵量——特征矩阵以及邻接矩阵,分别表征场景内多智能体的状态信息以及相互间的关联信息。
优选的,所述搭建奖励函数软件包的方法包括:
R
(δ为速度奖励增幅系数),计算获得速度奖励
(v
计算获得碰撞奖励
(μ为加速度奖励增幅系数),计算获得舒适性奖励
(a
其中,ω
本申请的有益效果为:
本申请为多智能体强化学习算法在智能交通场景上的应用提供了新的研究方式,为研究者自主设计场景的建立提供了可视化、便捷化的软件接口,同时保证了新场景能够与基于强化学习的算法结构相连通,本技术方案的优点以及积极效果具体如下:
利用现有的SUMO软件构建场景过程中伴随产生的.xml文件,将其与python代码结构相结合,通过自主编写的程序对文件信息进行读取并同步到python进程内,从而同时实现可视化的场景建立及其与主程序的连通性。通过该方面的优点,研究者可以在可视化软件窗格内自由构建所需的场景内容,后续仅需要将原项目的相关文件进行替换即可实现场景的自助构建及转变。
为python强化学习项目提供了强化学习模型构建软件包,目前的模型基于dqn进行开发,研究者可在此基础上进行扩充,构建其他的变种算法,最后只需在函数调用环节进行替换即可实现算法的转换;
将强化学习的网络结构构建函数单独分离出软件包进行封装从而便于进行网络结构的编辑改进,该结构使得整个修改自适应过程更加便捷直观;
传统的基于flow库的相关调用函数结构较为复杂,不利于研究者进行相关修改。本申请基于SUMO与python的原有traci接口,编写了相关的状态采集函数,可以对于SUMO仿真内部的相关状态信息进行实时采集并生成状态矩阵可以作为网络模型的输入;
通过一个main函数将上述所有的模块进行集成,研究者可以对于整个强化学习过程进行整体的修改,便于进行自主研究的开展。
附图说明
为了更清楚地说明本申请的技术方案,下面对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例的整体流程示意图;
图2为本申请实施例的强化学习主循环-次循环进程示意图;
图3为本申请实施例的项目文件统计示意图;
图4为本申请实施例的SUMO环境更新示意图;
图5为本申请实施例的状态处理流程示意图;
图6为本申请实施例的场景创建难易程度对比示意图;
图7为本申请实施例的其中一种车道地图示意图;
图8为本申请实施例的实时地图真实场景构建流程示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。
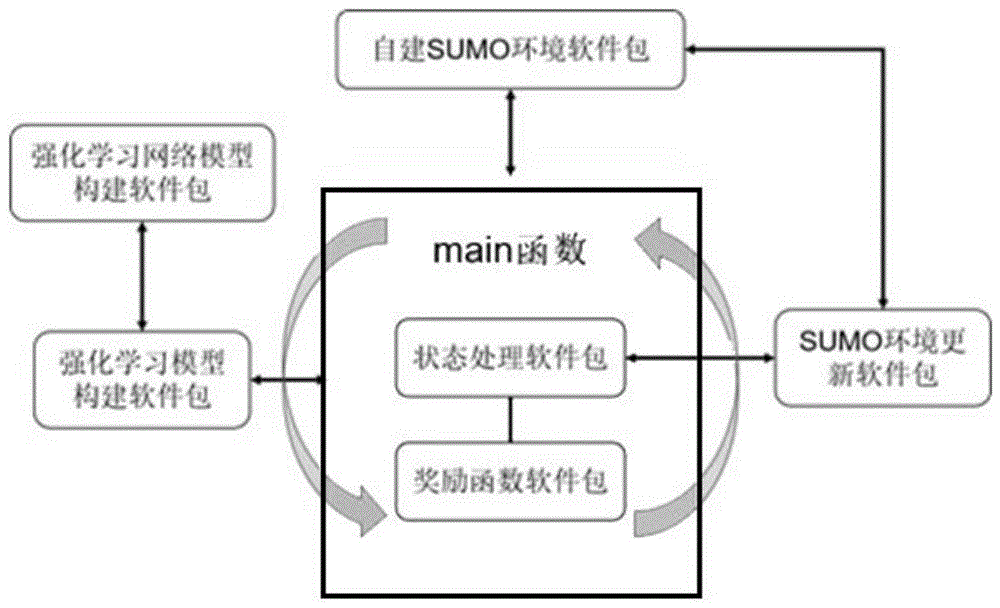
如图1所示,为本申请实施例的整体流程示意图;本申请以项目内的main函数为主体,将相关的功能组件分体封装在不同的自编软件包内,整个项目由以下几部分组成:
强化学习网络模型构建软件包;强化学习模型构建软件包;自建SUMO环境软件包;SUMO环境更新软件包;状态处理软件包;奖励函数软件包;
包括以下步骤:搭建main函数主体;main函数主体主要由强化学习的主进程组成,其中主要包括基本超参数的设置、场景加载、强化学习模型初始化以及强化学习主循环-次循环进程。
其中,基本超参数主要由表1组成。
表1
其次是模型的初始化进程,主要包括网络以及buffer的初始化构建,为后续的学习过程提供数据承载点。接着是强化学习主循环-次循环进程,具体如附图2所示。最后是模型以及相关表征数据的保存。
基于main函数主体,搭建强化学习网络模型构建软件包;强化学习的网络模型构建软件包主要储存的是网络构建函数,可以根据实际需求对网络的每一层以及每一层的节点数量进行编辑,同时也可以定义网络层的类型。
在实际调用过程中,通过python的import功能进行函数导入即可,目前提供可选的几种网络结构有:DQN使用的离散性全连接层网络结构、PG算法使用的连续性全连接层网络结构以及DuelingDQN使用的对应网络结构等等,使用者可以根据需求参照现有模型进行网络修改。
基于强化学习网络模型构建软件包,搭建强化学习模型构建软件包;该部分主要进行强化学习主体部分的定义,其中包括:优化器的设定、replay_buffer的设定以及探索性算法的设定,最后定义了网络的更新方式。
通过调用该函数,可以生成完整的强化学习网络模型,可以直接执行经验回放的储存以及学习(参数更新)过程。
本部分提供了传统的DQN算法样例,使用者可以参考样例结构进行算法的编辑更新,通过修改调用信息即可保证更新后的算法可以直接运行,大大提高研究的实验效率。
如图3所示,基于main函数主体,构建SUMO环境软件包;即以SUMO场景构建伴随生成的.xml文件为数据源,在python项目进程中形成仿真数据环境,本部分软件包由以下部分组成:
第一个文件以.net.xml结尾,是SUMO软件伴随生成的场景信息文件,基于本文件可以生成交通场景的仿真环境;
第二个文件以.rou.xml结尾,是可以自由编辑的用于定义车流信息的文件,其中可以对于车辆类别、外观、数量、出现频率、轨迹、以及附加属性进行定义,基于本文件可以生成交通场景内运行的交通车流;
第三个文件以.sumocfg结尾,是SUMO仿真平台的初始配置文件,可以对于仿真环境的相关信息进行设定,同时沟通之前的两个文件,配合python部分加载仿真数据进程,是SUMO场景底层文件与python项目的链接文件。
基于SUMO环境软件包,搭建SUMO环境更新软件包;通过check_state函数对于SUMO仿真平台内的状态进行提取,在状态提取过程中结合了SUMO自带的traci库函数,将所需的所有参数进行打包、存储以及更新,整个软件包的具体流程如图4所示。
基于SUMO环境更新软件包,搭建状态处理软件包;经过SUMO环境更新软件包提取得到的仿真信息无法直接输入到强化学习算法内,因此通过get_step函数对于状态空间进行整体排布,最终形成两个矩阵量——特征矩阵以及邻接矩阵,分别表征场景内多智能体的状态信息以及相互间的关联信息,整个软件包的处理流程如图5所示。
基于main函数主体,搭建奖励函数软件包。针对强化学习算法,需要配备特定的奖励函数达到预期的训练目标,本申请为研究者提供了一种较为基本的奖励函数机制,可以作为后续扩充改进的基础,也可以参考此函数进行奖励函数的自主设计,本申请提供的奖励函数样例主要考虑了交通效率、安全性以及稳定性几个基本指标。
具体的计算如下所示:
R
(δ为速度奖励增幅系数),计算获得速度奖励
(v
计算获得碰撞奖励
(μ为加速度奖励增幅系数),计算获得舒适性奖励。
(a
如图6所示,通过图中对比可知,原始的场景创建方法(左侧)建立较为简单的交通场景即需要使用较多的人工编写的代码资源,过程较为繁琐,面对较为复杂的场景构建需求不现实;而本申请提出的场景构建方式(右侧)简单快捷,借助相关自生成文件大大降低了人力成本,过程简单有效,适用于所有的场景构建需求。
传统的场景创建方法需要通过代码行的方式规定一系列的路口、节点、道路等信息,虽然经过缜密的计算理论上可以实现对于任何场景的构建,但是其构建时间随着场景复杂度的增加会呈指数形式增长,在该种编辑模式下,构建仅有几条车道的地图还好,如图7所示。但是如果场景需求稍微提高,车道数量超过10,且车道方向不再是横平竖直的,通过代码构建的时间成本是研究者无法承受的。
本申请的最大亮点是可以直接利用自动生成的xml文件进行场景构建,该xml文件的获取方式有三种:
第一种是通过代码行的方式手工生成,借用flow库函数,即传统的场景构建模式,十分费时;
第二种是通过场景设计编辑软件设计生成,可以通过绘图的方式自定义道路位置、坐标、联通方式等等信息,随后设计好的道路可以自动生成SUMO可以识别的xml数据文件形式,该种方式设计生成图7所示的场景只需要在软件中拖动生成如图几条道路即可,大约需耗费5min时间,相比于第一种方式具有突出的优势;
第三种是通过网络在线地图工具生成xml文件,该种方式需要用到在线地图软件进行区域划定,再经过SUMO内部插件OSM Web Wizard即可生成对应的xml文件供本申请算法架构使用,该种构建方式也是本申请的一大特点之一,对于真实交通场景下的相关研究具有重大意义。结合本申请,研究者可以根据自身需求划定研究的具体区域(真实区域)并进行相关的强化学习研究,该目标的实现对于传统的地图场景构建方式是完全不现实的。而依托于本申请,可以方便地完成该场景构建工作如图8所示。
以上所述的实施例仅是对本申请优选方式进行的描述,并非对本申请的范围进行限定,在不脱离本申请设计精神的前提下,本领域普通技术人员对本申请的技术方案做出的各种变形和改进,均应落入本申请权利要求书确定的保护范围内。