基于卷积神经网络的移动端轻量级图像超分辨率重建方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及数字图像处理技术领域,特别涉及一种仅依靠卷积神经网络且基于等价转化技术的移动端轻量级图像超分辨率重建方法。
背景技术
图像和视频超分辨率将低清晰度转化为高清晰度,在许多领域都有着广泛的应用,包括医学影像,卫星图像,医学影像等等。例如,某公司使用了基于深度学习的视频超分辨率技术将标清电视(SDTV)提升为高清电视(HDTV)。近年来,随着移动端设备的普及和性能的提升,将现有的图像超分辨率模型进行优化并部署到移动端有非常重要的意义。
图像超分辨率模型分为传统的超分辨率模型,基于插值如双线性插值,双三次插值,实现简单但是效果不佳,基于深度学习的超分辨率模型比较复杂,需要大量的成本和计算资源,超分辨率效果较好。然而,现有的超分辨率模型很少针对于终端设备的硬件进行相关的优化和适配。
卷积神经网络(Convolutional Neural Networks,CNN)一般是由卷积层,池化层以及全连接层组成,可以提取图片特征,将大量参数降维为少量参数。目前,卷积神经网络在图像超分辨率领域有出色的效果。近几年也出现了越来越复杂的卷积网络用于图像超分辨率,(即卷积层数更深更多)伴随着越来越出色的性能。例如,Lim等提出的Multi-scaleDeep Super Resolution(MDSR)(Enhanced Deep Residual Networks for Single ImageSuper-Resolution.2017IEEE Conference on Computer Vision and PatternRecognition Workshops(CVPRW))有160层卷积网络,而最开始提出的Dong等提出的SuperResolution Convolutional Neural Network(SRCNN)(Image Super-Resolution UsingDeep Convolutional Networks.IEEE Transactions on Pattern Analysis and MachineIntelligence,38(2),295–307.
https://doi.org/10.1109/TPAMI.2015.2439281)只有3层卷积网络。其存在的缺陷:
1、大多数基于深度学习的图像超分辨率具有很好的图像恢复的准确度,但是模型训练和预测的复杂度,存储和时间耗费都很高。例如,SwinIR模型基于Swin Transformer(SwinIR:Image Restoration Using Swin Transformer.2021IEEE/CVF InternationalConference on Computer Vision Workshops(ICCVW),1833–1844.https://doi.org/10.1109/ICCVW54120.2021.00210)有较好的图像超分辨率效果,但模型有约12M的参数量,不适用于移动端的情形。
2、一些比较小的卷积神经网络超分辨率网络能够在移动端设备实现接近实时的速度,但以PSNR度量的超分辨率准确度比较有限。
结构重参数化技术是指在训练过程中使用较大的模型,通过参数的等价转化将其转化为另外一组参数用于推理,使得推理时使用的模型较小,消耗更少的资源并且保留大模型的精度。结构重参数化技术在移动端场景有很好的应用场景。例如,Zhang等人提出的Edge-oriented Convolution Block For Real-time Super Resoluion(ECBSR)(Edge-oriented Convolution Block for Real-time Super Resolution on MobileDevices.Proceedings of the 29th ACM International Conference on Multimedia,4034–4043.https://doi.org/10.1145/3474085.3475291)一个适用于超分辨率任务的重参数化模块ECB,将包含3*3,1*1卷积,相关梯度信息在推理时都折叠为一个3*3卷积,从而减小推理时模块的体积,进而加快移动端的推理速度。其存在的缺陷:
1、重参数化技术将几个卷积合并为一个卷积,对于卷积中间存在ReLU等非线性层的情况,并不适用。
2、现有的重参数化技术没有对移动端现有设备算子进行具体分析,因而对于移动端的场景有一些不够适用的情况。例如,对于现有的智能电视平台的int8量化模型没有进行相关优化。
发明内容
本发明的目的是针对现有技术的缺陷,提供了一种基于卷积神经网络的移动端轻量级图像超分辨率重建方法。仅依靠卷积神经网络且基于等价转化技术,模型较小,在有较好的图像恢复质量的同时,训练速度快,适用于移动端的场景。
为了实现以上发明目的,本发明采取的技术方案如下:
一种基于卷积神经网络的移动端轻量级图像超分辨率重建方法,所述方法包括以下步骤:
S1:使用数据集DIV2K,DIV2K数据集包含数百张图片,低分辨率图片通过高分辨率图片双三次下采样生成,得到训练数据集;
S2:构建用于移动端的图像超分辨率网络
S21:构建训练阶段的图像超分辨率网络,该网络包括:
特征提取部分,使用卷积层以及重参数化模块对于图片的特征进行提取;
图像重建部分,使用像素重组对于提取的特征进行重建,并附加全局的残差;最后,将特征使用算子Clip转化到[0,255]范围中以适用于int8量化情形;
S22:将步骤S21的训练阶段的超分辨率网络等价转化,得到推理阶段的图像超分辨率网络即用于移动端的图像超分辨率网络,具体包括:
对于算子repeat,由
则使用卷积核为repeat(I,n)的卷积替换算子repeat,其中x为输入张量,I为单位矩阵,n代表将输入张量重复n次,
对于算子add,在训练阶段的网络中为两个卷积网络,即
将算子add转化如下,即卷积核变为[W
/>
对于算子concat,在训练的网络中为Conv2d_ReLU层,则转化如下,卷积核变为
对于算子clip,根据算子clip与ReLU的等价转化关系为:
clip(x)=ReLU(-ReLU(-x+255)+255)
将算子clip等价转化为两个卷积层,卷积核为-I,偏置为255
S3:训练移动端的图像超分辨率网络
将S1得到的训练数据集输入到构建完成的移动端的图像超分辨率网络中,输出高分辨率图片;数据集中的图片随机旋转和翻转,比较数据集中的原始图片与生成的高分辨率图片的损失,基于损失进行反向传播计算,直至训练结束;损失函数为L1 loss,即MAE
与现有技术相比,本发明的优点在于:
1)在维持较好的峰值信噪比(PSNR)超分辨率准确度的基础上,在移动端设备上有相当快的速度,单张图片可以在30ms以内实现*2,*3倍数的超分辨率,同时可以在移动便携设备上运行本方法。
2)使用峰值信噪比(PSNR)度量的准确度中,本发明相比于之前相同参数量的模型有较大的提升,在Set5数据集的*3倍的测试上,可以实现PNSR为31.1,14.6ms的推理速度,相比于现有的针对于移动端设备进行优化的ECBSR方法即30.8的PSNR和13.3ms的推理速度,由较大的提升。
3)相比于重参数化技术等,本发明对卷积层以及ReLU进行等价转化,转化为模型更简单的推理时候的网络。
4)对于Clip算子进行了优化,即对于当前的智能电视平台的int8量化模型进行了相关优化和适配。
附图说明
图1是本发明的流程图;
图2是本发明图像超分辨率模型结构图;
图3是具体实施例图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下根据附图并列举实施例,对本发明做进一步详细说明。
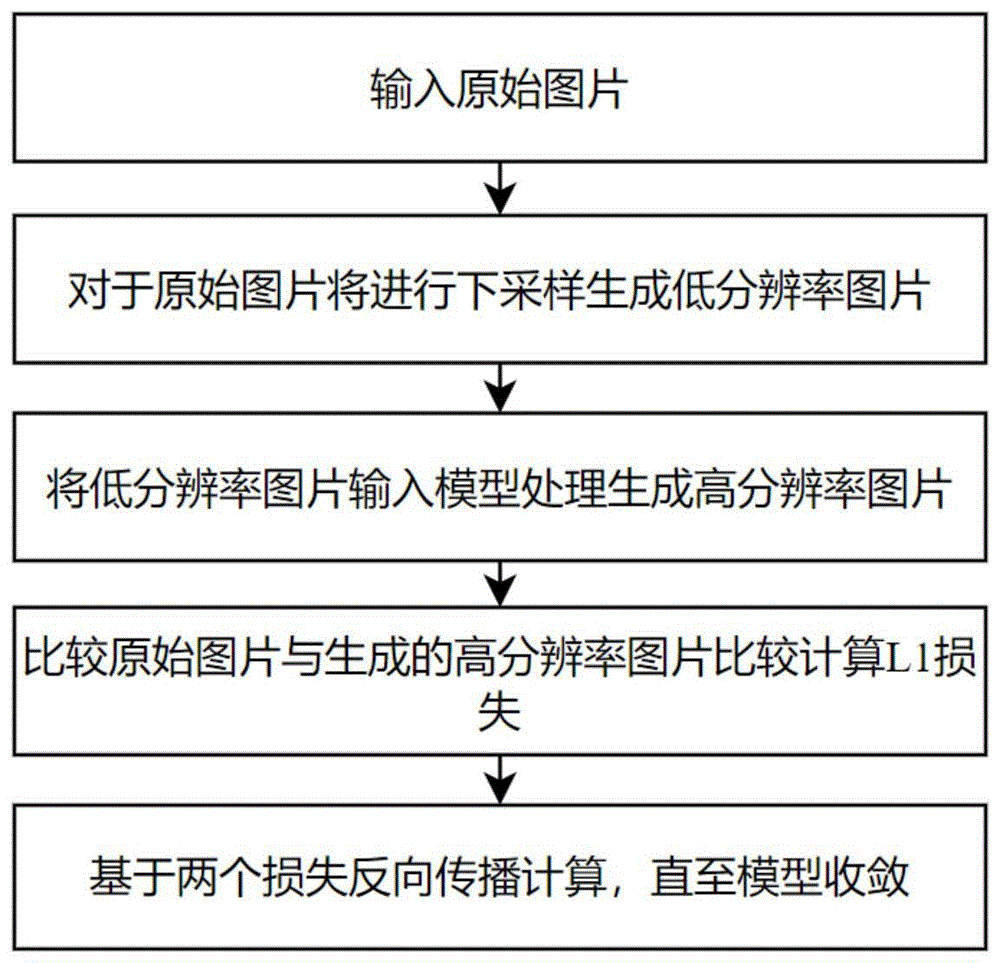
参阅图1,本发明针对现有技术的缺陷,提供了一种基于卷积神经网络的移动端轻量级图像超分辨率重建方法。仅依靠卷积神经网络且基于等价转化技术,模型较小,在有较好的图像恢复质量的同时,训练速度快,适用于移动端的场景。具体不包括:
S1:使用数据集DIV2K,DIV2K数据集包含数百张图片,低分辨率图片通过高分辨率图片双三次下采样生成,得到训练数据集;
S2:构建适用于移动端的图像超分辨率网络。
S3:训练移动端的图像超分辨率网络,将上述训练集输入到构建完成的图像超分辨率网络中,输出高分辨率图片,数据集中的图片随机旋转和翻转。
S4:比较数据集中的原始图片与生成的高分辨率图片的损失,基于损失进行反向传播计算,直至训练结束。损失函数为L1 loss,即MAE
参阅图2,本发明公开的构建适用于移动端的图像超分辨率网络,具体包括:
S22:训练阶段的图像超分辨率网络主要由如下部分组成。特征提取部分,使用卷积层以及重参数化模块对于图片的特征进行提取;在图像重建部分,使用像素重组对于提取的特征进行重建,并加上了全局的残差。最后,将特征使用算子clip转化到合适的范围中以适用于int8量化模型。
S23:推理阶段的图像超分辨率模型由S22得到的图像超分辨率模型等价转化获得,将算子repeat,算子add,算子concat,以及算子clip分别进行等价转化。具体的等价转化过程如下。对于算子repeat,由
则可以使用卷积核为repeat(I,n)的卷积替换算子repeat,其中x为输入张量,I为单位矩阵,n代表将输入张量重复n次,
对于算子add,在训练阶段的网络中之前为两个卷积网络,即
对于算子concat,在训练的网络中之前为Conv2d_ReLU层,则可以转化如下,卷积核变为
对于算子clip,根据算子clip与ReLU的等价转化关系为
clip(x)=ReLU(-ReLU(-x+255)+255)
可以将算子clip等价转化为两个卷积层,卷积核为-I,偏置为255
经过如上所述的四个算子的等价转化,可以将训练过程的模型转化为推理时的模型,并使得推理时训练速度大大加快。
实施例
参阅图3,本实施例具体包括如下步骤:
S1:得到训练数据集,使用数据集DIV2K,DIV2K数据集包含800张图片,低分辨率图片通过高分辨率图片双三次下采样生成。具体地,图3中的(a)为真实图片,图3中的(b)为使用双三次下采样生成的低分辨率图片;
S2:构建适用于移动端的图像超分辨率网络;
S3:训练移动端的图像超分辨率网络,将上述训练集输入到构建完成的图像超分辨率网络中,输出高分辨率图片,数据集中的图片随机旋转和翻转,较数据集中的原始图片与生成的高分辨率图片的损失,基于损失进行反向传播计算,直至训练结束。损失函数为L1loss,即MAE
S4:将需要测试的图片输入推理时网络,将使用双三次下采样生成的低分辨率图片图3(b)输入推理网络,即可以得到图3(c),可以发现图3(c)相比于图3(b)实现了更好的PSNR和更好的视觉效果,更加接近真实图片(a)。在取得较好的PSNR和视觉效果的同时,由于本模型面对移动端进行了优化,因此速度更快,更为轻量级。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的实施方法,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。