一种基于多级视听融合的构音障碍语音识别方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及构音障碍语音识别技术领域,特别是涉及一种基于多级视听融合的构音障碍语音识别方法,可应用于识别构音障碍者的言语发音。
背景技术
构音障碍是指由于神经和肌肉的器质性病变,造成与构音相关的肌肉麻痹、收缩力减弱及运动不精确或不协调,从而导致呼吸、喉发声、共鸣、构音和韵律等异常。构音障碍导致说话人发音不准确、语速缓慢、音量与清晰度低下,这使得构音障碍者难以通过言语与他人沟通,沟通效率低下,给日常生活造成困扰和极大不便。
自动语音识别能够显著提升沟通效率,因此构音障碍自动语音识别领域已有大量研究。然而,由于构音障碍语音难以采集,这导致构音障碍语音数据集的样本量稀少,因此自动语音识别系统中的机器学习模型训练不够充分。为了解决构音障碍数据样本稀少导致模型训练不充分的问题,可以使用健康语音来生成构音障碍语音。这类方法能够一定程度上补充构音障碍数据,生成的语音在声学和感知上与真实的构音障碍语音相似,但此类方法不足以有效提升模型的泛化能力,规则的制定也依赖领域知识,通常难以做到在多个数据集之间通用。
近年来,视听融合方法被应用于识别语音,根据McGurk效应原理,人类对语音的感知受到视觉的影响,因此视听融合模型可以有效地为自动语音识别任务提供视觉信息,从而提高识别的准确性。人所发出的语音,是发音器官协调运动的结果,其中舌、唇、齿、鼻等器官的贡献最为突出。发音器官的运动数据也被应用于构音障碍自动语音识别任务,并取得了不错的成效。然而,使用传感器采集构音障碍者的发音器官运动数据成本高昂,并且目前采用的视听融合方法也存在数据量少的问题,因此训练获得的模型仍存在泛化性能低下的问题,针对构音障碍语音识别的效率低、精度不足。
发明内容
为了克服上述现有技术的不足,本发明提出了一种基于多级视听融合的构音障碍语音识别方法,能够降低构音障碍语音识别成本,提升构音障碍语音识别精度。
本发明通过设计二级融合架构引入视觉信息以增加特征。在第一级融合框架中,本发明提出将构音障碍说话人的面部言语功能区域的运动视觉信号作为线索,并对各言语功能区域做视觉融合编码,这有别于传统单纯依靠唇部运动作为视听融合系统的线索,本发明使用摄像头采集面部视觉信号替代传感器采集的发音器官运动数据降低了成本。在第二级融合框架中,将视觉融合编码与声学特征融合,形成视听融合的构音障碍语音识别,从而更适用于构音障碍语音。
本发明提供的技术方案是:
一种基于多级视听融合的构音障碍语音识别方法,包括如下步骤:
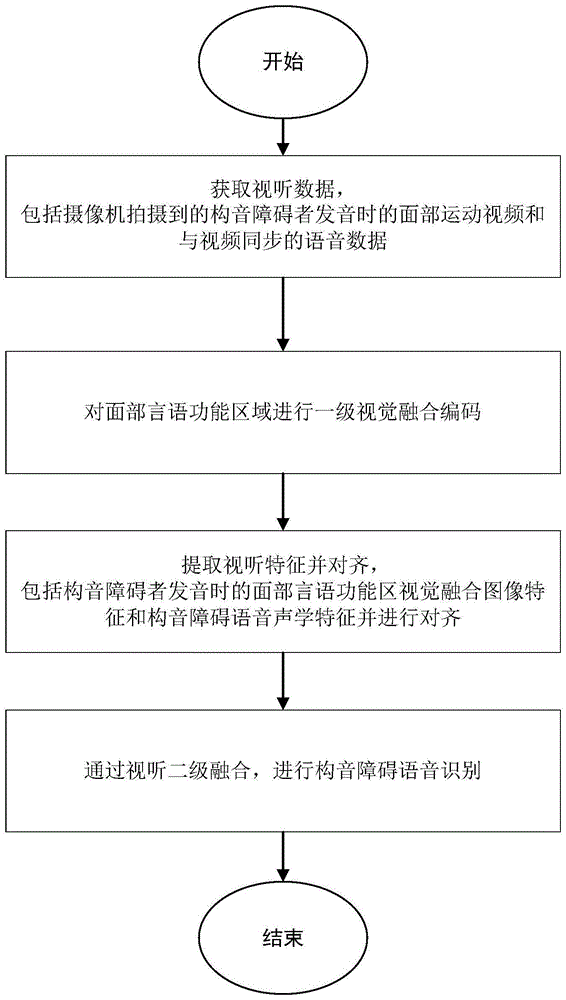
步骤S1.获取视听数据,所述视听数据包括:拍摄到的构音障碍者发音时的面部运动视频和与视频同步的语音数据;
步骤S2.对面部运动视频分帧,得到构音障碍者发音图像,然后基于图像定义和划分面部言语功能区域。其次,再对面部言语功能区域进行一级视觉融合编码,将构音障碍者的面部运动视频(面部言语功能区域的运动视觉信号)作为线索,并对各个面部言语功能区域做视觉融合编码(即一级融合编码);
具体实施时构建了一级视觉融合编码模块,包括:
S2.1特征提取模块
用于提取源图像的不同特征。
S2.2特征融合模块
将提取好的图像特征级联得到融合特征。
S2.3图像重建模块
对融合后的特征进行图像重建,采用密集连接的方法将提取的纹理细节信息融合到提取的空间信息中,最后得到融合后的视觉特征,即视觉融合图像。
步骤S3.提取视听特征并对齐,视听特征包括构音障碍者发音时的面部言语功能区视觉融合图像特征和构音障碍语音声学特征;得到对齐好的视听特征;
S3.1提取构音障碍者发音时的视觉融合图像特征;
本发明具体实施中,利用ResNet-18网络提取图像的方向梯度直方图特征;
S3.2提取构音障碍语音声学特征,可采用梅尔语谱参数向量;
S3.3对齐构音障碍语音声学特征和发音时的视觉融合图像特征,发音音素同时对应一段发音视频和一段语音片段,即得到对齐好的视听特征。
步骤S4通过视听二级融合,进行构音障碍语音识别,得到一串音素字符;包括如下步骤:
S4.1融合对齐好的视听特征,即包括构音障碍者发音时的视觉融合图像特征和构音障碍语音声学特征,获得语音和视频的融合特征参数矩阵。根据所获得的融合特征参数矩阵,通过训练深层时序神经网络映射模型,获得由视听融合特征到音素字符的映射关系。
在一个具体实施例中,本发明采用Transformer-CTC和Transformer-S2S深度时序神经网络,具有连接时间分类(Transformer-CTC,TM-CTC)的序列到序列(S2S)Transformer模型。在训练阶段,选择连接时间分类(Connectionist Temporal Classification,CTC)和序列到序列(Sequence to Sequence,S2S)目标的线性组合作为目标函数:
L=αlogp
其中,x=(x
S4.2对得到的音素字符进行解码。
在解码过程中,使用RNN语言模型p
logp
其中,θ为控制语言模型的贡献的参数。
通过上述步骤,实现基于多级视听融合的构音障碍语音的识别。
与现有技术相比,本发明的有益效果:
本发明提出将构音障碍说话人的面部言语功能区域的运动视觉信号作为线索,并使用CNN网络对各言语功能区域做视觉融合编码,这有别于传统单纯依靠唇部运动作为视听融合系统的线索;本文设计了二级融合架构,先将面部言语功能区的运动视觉信息做第一级融合,再使用Transformer-CTC、Transformer-S2S架构将视觉和听觉信息做第二级融合,这保证整个视听融合架构能够捕捉到充足的视觉和听觉信息,从而更适用于构音障碍语音,因此本发明即可以降低成本,又可以提高构音障碍语音的识别准确率。
附图说明
图1为本发明一个实施例中基于多级视听融合的构音障碍语音识别方法流程框图。
图2为本发明一个实施例中对面部言语功能区域进行一级视觉融合编码方法流程框图。
图3为本发明一个实施例中对使用dlib库中的人脸检测器来检测-裁取多部分面部言语功能区方法流程框图
图4为本发明一个实施例中与说话关联度最密切的六条肌肉位置图
图5为本发明一个实施例中对各个面部言语功能区域做一级视觉融合编码方法流程框图。
图6为本发明一个实施例中视听二级融合构音障碍语音识别方法流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于多级视听融合的构音障碍语音识别方法,包括如下步骤:
步骤S1.获取视听数据,所述视听数据包括:拍摄到的构音障碍者发音时的面部运动视频和与视频同步的语音数据;
步骤S2.对面部言语功能区域进行一级视觉融合编码,将构音障碍说话人的面部言语功能区域的运动视觉信号作为线索,并对各个面部言语功能区域做视觉融合编码;包括如下步骤:
S2.1定义面部言语功能区域
从解剖学角度出发,上唇提肌、上轮匝肌、下轮匝肌、下唇压降肌、口角降唇肌和颏肌对言语发音功能贡献最大。因此,本文选用唇、下巴、左右腭部区域和鼻多个(5个)部分区域作为面部言语功能区域进行视觉融合编码。
S2.2裁取得到多个部分的面部言语功能区域
对采集到的视频分帧,可以逐帧获得源图像(面部图像)。根据S2.1划分的多个部分面部言语功能区域,在其中一个实施例中,使用机器学习库(dlib库)中的人脸检测器来检测-提取5部分图像。
S2.3对各个面部言语功能区域做一级视觉融合编码
对S2.2截取好的多个部分面部言语功能区域进行图像融合,图像的像素预测不仅要考虑图像中的低频信息,如纹理细节、颜色等,还需考虑到图像的高频信息,如空间信息。具体实施时构建了一级视觉融合编码模块,包括:
S2.3.1构建特征提取模块,通过采用CNN提取得到图像特征;
用于提取源图像的不同特征,提取得到源图像的纹理细节、颜色和空间信息等特征。
S2.3.2特征融合模块
将提取好的图像特征级联得到融合特征。
S2.3.3图像重建模块
对融合后的特征进行图像重建,采用密集连接的方法将提取的纹理细节信息融合到提取的空间信息中,最后得到融合后的视觉特征,即视觉融合图像。
步骤S3.提取视听特征并对齐,视听特征包括步骤2得到的构音障碍者发音时的面部言语功能区视觉融合图像特征和构音障碍者的语音声学特征;
S3.1对视觉融合图像提取得到构音障碍者发音时的视觉融合图像特征;
本发明具体实施中,根据步骤S2得到视觉融合图像,然后提取图像特征,在一个实施例中,利用ResNet-18网络提取图像的方向梯度直方图特征;
S3.2提取构音障碍语音声学特征,可采用梅尔语谱参数向量;
本发明具体实施中,声学特征采用梅尔语谱参数,具体计算方法如下;
根据语音波形信号经短时傅里叶变换,再由梅尔滤波器组计算得到梅尔语谱参数;
S3.3对齐构音障碍语音声学特征和发音时的视觉融合图像特征,发音音素同时对应一段发音视频和一段语音片段。
步骤S4通过视听二级融合,进行构音障碍语音识别,得到一串音素字符,包括如下步骤:
融合对齐好的视听特征,即包括构音障碍者发音时的视觉融合图像特征和构音障碍语音声学特征,获得语音和视频的融合特征参数矩阵。根据所获得的融合特征参数矩阵,通过训练深层时序神经网络映射模型,获得由视听融合特征到音素字符的映射关系。在一个具体实施例中,本发明采用Transformer-CTC和Transformer-S2S深度时序神经网络。在训练阶段,选择连接时间分类(Connectionist Temporal Classification,CTC)和序列到序列(Sequence to Sequence,S2S)目标的线性组合作为目标函数:
L=αlogp
其中,x=(x
S4.2对音素进行解码识别,得到构音障碍语音。
在解码过程中,使用RNN语言模型p
logp
其中,θ为控制语言模型的贡献的参数。
通过上述步骤,实现基于多级视听融合的构音障碍语音识别方法。
如图1所示,在本发明一个实施例中,一种基于多级视听融合的构音障碍语音识别方法方法包含四个主要步骤:
步骤S1,获取视听数据,包括拍摄到的构音障碍者说话时的面部运动视频和与视频同步的语音数据。本次构音障碍数据集UASpeech包含了29个说话人102.7小时的语音记录,发音文本均为孤立单词,包括了数字、计算机指令、无线电字母、普通和生僻单词。29个说话人当中有16人是构音障碍者,其余13人是健康对照组,16个构音障碍者当中仅有8个同时拥有视听数据。该数据集数据在实验室环境中收集,受试者从电脑显示器上阅读单词。记录音频数据的是一个7通道的麦克风,记录双音多频信号的是一个8通道麦克风,记录视频数据的是一台数码相机。UASpeech的语音清晰度得分是根据5名母语人士在听力测试中的平均得分计算得出的。可理解度评分在2%到95%之间。根据语音可解性评分将构音障碍者分为四组,即0-25%为极低组,25-50%为低组,50-75%为中组,75-100%为高组,对应的构音障碍水平为:极其严重(very low)、严重(low)、中度(mild)、轻度(high)。
步骤S2,面部言语功能区域一级融合,首先根据生理知识划分5部分面部言语功能区,在一个实施例中使用dlib库中的人脸检测器来检测-提取这5部分图像,最后在一个实施例中使用CNN网络对各言语功能区域做视觉融合。
步骤S3,提取视听特征并对齐,包括构音障碍者发音时的面部言语功能区视觉融合图像特征和构音障碍语音声学特征并进行对齐。在一个实施例中,以10毫秒的步幅从原始波形中提取39维梅尔语谱特征参数,以25Hz为采样率从视频中提取图像。然后本文将4个连续的声学特征连接为一帧,然后再将它们输入到模型中,从而使声学和视觉特征输入长度相同。
步骤S4,视听二级融合,融合提取到的视听数据特征,包括构音障碍者发音时的视觉融合图像特征和构音障碍语音声学特征,并对输出进行解码。
图2展示了面部言语功能区域进行一级视觉融合编码方法流程(步骤S2),包括:
S2.1定义面部言语功能区域
S2.2裁取得到多个部分的面部言语功能区域
S2.3对各个面部言语功能区域做一级视觉融合编码
图3展示了使用dlib库中的人脸检测器来检测-裁取多部分面部言语功能区,方法流程包括利用dlib实现人脸检测、关键点检测、人脸对齐、裁取面部言语功能区。
dlib人脸检测:利用dlib中的检测器dlib.get_frontal_face_detector()将视频帧的面部图像检测出来。
dlib关键点检测:基于dlib库的人脸68个特征点检测器shape_predictor_68_face_landmarks.dat,将人脸的关键点检测出来。
dlib人脸对齐:人脸对齐操作可以使后续模型提取到与五官的位置无关,只有五官的形状纹理相关的特征。
dlib裁取5部分面部言语功能区:根据关键点位置,按照所需唇、下巴、左右腭部区域和鼻5部分区域,进行裁剪图像。
图4为本发明一个实施例中与说话关联度最密切的六条肌肉位置图。从解剖学角度出发,上唇提肌(levator labii superioris)、上轮匝肌(orbicularis oris su-perior)、下轮匝肌(orbicularis oris inferior)、下唇压降肌(depressor labiiinferioris,)、口角降唇肌(depressor anguli oris)和颏肌(mentalis)对言语发音功能贡献最大。LLS:上唇提肌,OOS:上轮匝肌,OOI:下轮匝肌,DLI:下唇压降肌,DAO:口角降唇肌,M:颏肌。
本发明通过构建视觉融合卷积神经网络模型,根据各个面部言语功能区域进行一级视觉融合编码。图5展示了根据各个面部言语功能区域做一级视觉融合编码的方法流程。图5中,I
Y
其中,I为源图像,该融合卷积神经网络模型的卷积层采用3×3和1×1两种类型的卷积核,步长均为1。该网络模型不使用全连接层,因此输入图像可以是任何尺寸。除了最后一个卷积层由Tanh函数激活之外,其他卷积层激活函数均为ReLU函数。构建视觉融合卷积神经网络模型进行一级视觉融合编码包括以下步骤:
S231构建特征提取模块,用于提取源图像的不同特征;
根据源图像的数目,特征提取模块包括多个分支;特征提取分支模块的数目等于源图像的数目,即源图像数目为k时,特征提取模块由k个分支组成。
将每个特征提取分支模块的输入分别定义为
S232构建特征融合模块,用于融合特征提取模块对源图像提取得到的不同特征;
在特征融合模块部分,将k个特征提取分支模块的输出
S233构建图像重建模块,用于重建融合图像;
视觉融合卷积神经网络模型的图像重建模块部分包括8个卷积层,定义为
/>
最后得到融合后的视觉特征Fusion Image。
图6显示的是视听二级融合构音障碍语音识别方法流程,包括:
S41提取视听特征,并对齐图像特征和声学特征,即将构音障碍者发音时的面部言语功能区视觉融合图像特征和构音障碍语音声学特征进行对齐。对于视频,获得面部言语功能区域融合后图像方向梯度直方图特征,对于音频,采用梅尔语谱参数作为声学特征,计算过程包括语音时域波形信号经短时傅里叶变换计算得到时频分析语谱参数,再由梅尔滤波器组计算得到39维梅尔语谱参数。本发明将声学特征和视觉特征在帧级别对齐。本发明以10毫秒的步幅从原始波形中提取26维log filterbank energy特征,以25Hz为采样率从视频中提取图像。然后本发明将4个连续的声学特征连接为一帧,然后再将它们输入到模型中,从而使声学和视觉特征输入长度相同。
S42视听二级融合。在其中一个实施例中,融合方法采用拼接方法,。逐帧拼接视觉融合图像特征参数向量和语音声学特征参数向量,获得语音和视频的融合特征参数矩阵;融合特征参数矩阵中,低维度矩阵为语音声学特征参数向量,高纬度矩阵为视觉融合图像特征参数向量。
S5对构音障碍语音进行识别。在其中一个实施例中,语音识别框架采用的深层时序神经网络模型为Transformer-CTC和Transformer-S2S架构,模型输入为融合特征参数矩阵,模型输出为识别得到的一串音素字符。
在训练阶段,选择连接时间分类(Connectionist Temporal Classification,CTC)和序列到序列(Sequence to Sequence,S2S)目标的线性组合作为目标函数:
L=αlogp
其中,x=(x
S6利用语言模型(如4-gram语言模型)对数据(识别得到的一串音素字符)进行解码。
利用基于LRS3训练集中文本数据训练的4-gram语言模型对数据进行解码,分别对数据分别以“仅听觉audio”、“仅视觉video”、“听觉-视觉audio-video”三种模态进行解码,其中4-gram语言模型的困惑度设置为110.5。对于CTC,本发明将波束宽度调到{5,10,20,50,100,150}之间,将语言模型权重调到{0,1,2,4,8}之间,将单词插入惩罚调到{±4,±2,0}之间。
表1展示了本发明实验结果,本发明在UASpeech数据集上进行了基于多级视听融合的构音障碍语音识别实验,采用本发明方法得到的结果与DNN(S.Liu et al.,"RecentProgress in the CUHK Dysarthric Speech Recognition System,"IEEE/ACMTransactions on Audio,Speech,and Language Processing,vol.29,pp.2267-2281,2021,doi:10.1109/taslp.2021.3091805)和Base LAS(W.Chan,N.Jaitly,Q.Le,andO.Vinyals,"Listen,attend and spell:A neural network for large vocabularyconversational speech recognition,"in 2016IEEE International Conference onAcoustics,Speech and Signal Processing(ICASSP),2016:IEEE,pp.4960-4964.)进行对比,实验结果如下表1所示。系统1、2是本发明方法的实验结果,系统1的视觉输入是面部言语功能区视觉融合,系统2的视觉输入是唇部运动。
表1视听融合构音障碍语音识别实验结果
由实验结果可以看出,视听融合比单模态识别精度要高。在轻度构音障碍情况下,系统1在听觉-视觉模态下的WER值比DNN低4.58%,系统2在听觉-视觉模态下的WER值比DNN低0.84%。同理,中度情况下,系统1的WER值比DNN低1.63%,重度情况下,系统1的WER值比DNN低2.31%,系统2的WER值比DNN低0.63%。极重度情况下,系统1的WER值比DNN低0.42%,但系统2的WER值比DNN低1.18%。
其次,对比系统1和2,可以看出进行区域融合能够显著降低WER值。在仅听觉模态情况下,轻度系统1的WER值比系统2低1.84个百分点,中度情况低2.51个百分点,重度情况低5.8个百分点。极重度情况有所特殊,系统1的WER值比系统1高0.47个百分点。极重度构音障碍者往往伴随严重的疾病,说话时头部会产生大幅度动作,这让捕捉他们的面部区域十分困难。在视听融合情况下,系统1轻度、中度和重度情况的WER值均比系统2低,分别低了3.74个百分点、4.00个百分点和1.68个百分点,重度情况系统1的WER值均比系统2高1.76个百分点。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。