一种表单联动变化中数值推荐方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及信息技术领域,尤其涉及一种表单联动变化中数值推荐方法。
背景技术
低代码应用开发系统可以对表单控件进行拖拽后直接生成可以使用的内容;但是对于包含数值内容的的表单控件,一般只能产生类型而无法直接产生数值;例如把一个日期控件拖动进去,自己填写日期,或者把金额控件拖进去后,再填写金额;然而,当需要填写的数值内容很多的时候,会产生两个问题,一是填写的内容过多工作量大,二是极易填写错误;例如一张都是数值的表单,或者一张排版了多种数值类型的表单,都很容易填写错误;根据一个用户以前填写过的信息或者同一个家公司相同岗位的不同用户填写的信息,虽然可以对需填写的内容进行一些推荐,但是较难挖掘什么样填写过的表单是相互关联的以及主表单与子表单之间的关联性;此外,表单之间也存在以一定频率进行数值更新的情况,例如价格可能是根据月或者周在更新的,而生日则是经常不再更新的,购买C端商品的客户的名称可能是每次都不同的,而购买B端商品的客户则可能回购率更高,更新不频繁;对于不用更新的数值可以继续用于数值内容填写推荐,但对需要更新的数值内容如何进行推测、数值内容如何进行更新频率的预测是一个未解决的问题;与此同时,针对推荐后出错严重度的预测,也是一个亟待解决的问题;一个数值如果是生日推荐错误,可能影响不大,如果是价格推荐错误,导致用户默认选择了系统的推荐导致价格错误,可能导致后面很大的问题,因此数值关联推荐的误差和风险也需要进行预估。因此需要提出一种考虑表单联动变化的数值推荐方法。
发明内容
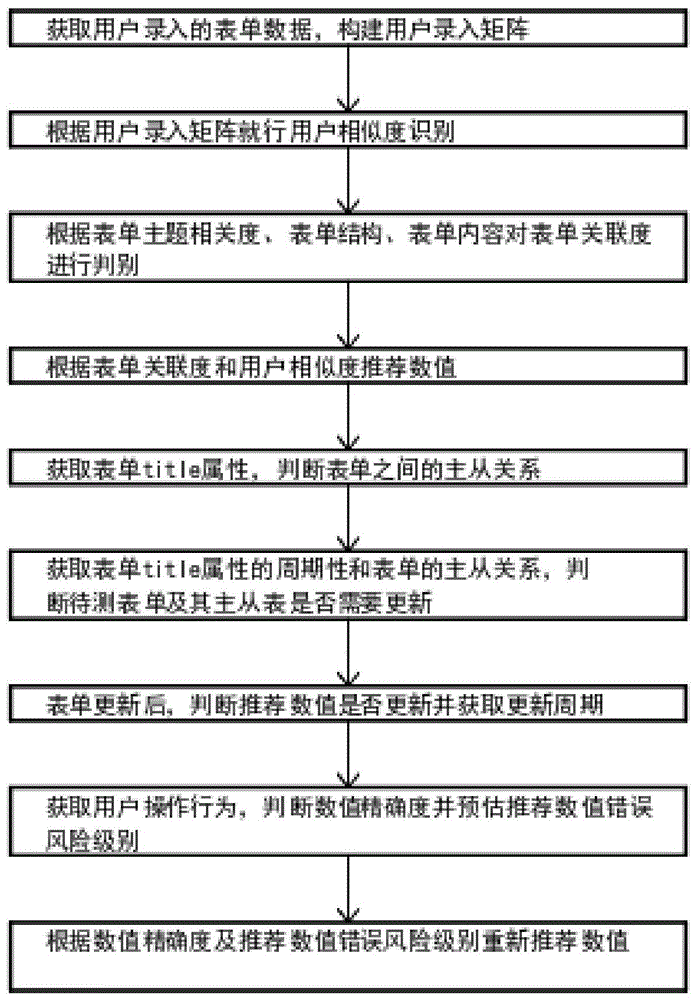
本发明提供了一种表单联动变化中数值推荐方法,主要包括:
获取用户录入的表单数据,构建用户录入矩阵;根据用户录入矩阵就行用户相似度识别;根据表单主题相关度、表单结构、表单内容对表单关联度进行判别,所述根据表单主题相关度、表单结构、表单内容对表单关联度进行判别,具体包括:计算表单主题相关度,基于决策树的表单结构分类,获取表单控件的title属性并计算表单内容相似度;根据表单关联度和用户相似度推荐数值,具体包括:根据用户相似度确定推荐数值序列;获取表单title属性,判断表单之间的主从关系;获取表单title属性的周期性和表单的主从关系,判断待测表单及其主从表是否需要更新;表单更新后,判断推荐数值是否更新并获取更新周期;获取用户操作行为,判断数值精确度并预估推荐数值错误风险级别;根据数值精确度及推荐数值错误风险级别重新推荐数值。
进一步可选地,所述获取用户录入的表单数据,构建用户录入矩阵包括:
获取用户在表单内录入的所有内容;构建一个用户录入模型,所述用户录入模型包括一个用户录入矩阵M;用户录入矩阵M描述了用户在其填写的表单时所有录入值出现次数的矩阵;用户录入矩阵M为一个m*n阶矩阵,U是用户集合,I是表单中的录入值,Sij是用户在其填写表单时各录入值被填写的次数。
进一步可选地,所述根据用户录入矩阵就行用户相似度识别包括:
获取目标用户历史填写记录,转化为目标用户的用户录入矩阵M;在构建了用户录入矩阵M的基础上,通过皮尔逊相关系数法动态获取目标用户Ua与用户集合U的相似度集合S;所述相似度集合S是目标用户Ua和用户集合U中每个用户的历史填写记录的相似度值的集合,方法如下:遍历用户集合U,分别计算目标用户Ua与用户集合U的相似度值,并用集合S表示;将集合S中的相似度值元素Sm按从大到小的顺序排列,相似度值元素Sm越大用户相似度越高,相似度值元素Sm越小用户相似度越小。
进一步可选地,所述根据表单主题相关度、表单结构、表单内容对表单关联度进行判别包括:
表单关联度判别包括计算表单主题相关度、基于决策树的表单结构分类和计算表单内容相似度;所述计算表单主题相关度包括通过表单标题确定表单的主题,将标题相似度作为表单主题相似度值;所述基于决策树的表单结构分类包括,判断表单是否属于数值录入表单,若属于则记为1,否则记为0;所述计算表单内容相似度包括根据表单中对应数值输入控件的title属性判断表单内容的相似度;给三个结果分别赋予相应权重,记为w1、w2、w3,则表单关联度=w1*表单主题相似度+w2*表单结构分类结果+w3*表单内容相似度;其中三个权重需要通过反复测试修改得到;包括:计算表单主题相关度;基于决策树的表单结构分类;获取表单控件的title属性并计算表单内容相似度;
所述计算表单主题相关度,具体包括:
获取表单的标题,使用jieba对标题进行分词并去除停用词后输出词语;基于语料库计算词语相似度,根据语料库对不同词语的编号计算两个词语之间的相似度;首先判断在语料库中作为叶子节点的两个词语的编号在哪一层不同,相同则乘1,否则乘相应的系数,然后再乘以调节参数和控制参数;则词语A和词语B的相似度=各层系数*调节参数*控制参数;其中各层系数由多次实验后确定;表单主题相关度等于标题词语相似度的平均值。
所述基于决策树的表单结构分类,具体包括:
获取表单集合,根据是否包含数值输入框将表单集合分为两大类:数值录入表单和非数值录入表单,并给每个表单打上类别标签;将带标签的表单集合作为训练集训练决策树;通过训练好的决策树提取表单结构特征,生成一棵用于判断表单结构类型的决策树;决策过程包括:首先分别对训练集中两大类别计数,并计算各类别出现的概率P和信息熵;然后将待分类表单的特征值输入决策树,每次决策时重新计算一次信息熵,选择信息熵增加最大的分支作为决策结果;对于生成的决策树使用以下规则进行分类:如果表单中不存在标签,那么是非数值录入表单,如果含有标签,抽取表单控件的约束类型,如果约束类型是数值型,那么是数值录入表单,否则属于非数值录入表单。
所述获取表单控件的title属性并计算表单内容相似度,具体包括:
表单内容相似度包括根据表单中对应数值输入控件的title属性判断表单内容的相似度;获取类别为数值录入表单中对应数值输入控件的title属性作为特征词汇;首先进行预处理,去除title属性中出现在括号中的内容,如果特征词汇由多个词语构成则使用jieba进行分词操作,并去除无意义的停用词;然后计算表单内容的相似度;将处理后的title属性作为特征向量,基于《同义词词林》利用特征向量计算待测title属性的相似度;遍历待测表单对应数值输入控件的title属性,计算各个title属性与待比较表单内的title属性的相似度,将待测表单与待比较表单中所有title属性的平均相似度作为两个表单内容相似度值。
进一步可选地,所述根据表单关联度和用户相似度推荐数值包括:
获取目标用户历史填写数据以及所有用户填写过的表单集合;其中用户历史填写数据包括用户填写表单、用户填写内容;同一用户填写过表单,从历史填写数据中推荐,不同用户但填写的表单部分信息相同,则根据表单关联度和用户相似度推荐;首先,在用户历史填写数据中匹配用户当前填写的表单,若匹配结果不为空,则向用户推荐距离当前时间最近的历史填写数据;若匹配结果为空,首先获取用户当前填写的表单与后台表单集合的关联度,取关联度的平均值作为第一阈值;然后提取与用户当前填写的表单关联度大于第一阈值的表单作为关联表单,计算用户当前填写的表单和关联表单的内容相似度,并输出内容相似度大于平均内容相似度的title属性,获取所述title属性对应的已填写的用户集合,根据用户相似度确定推荐数值序列;包括:根据用户相似度确定推荐数值序列;
所述根据用户相似度确定推荐数值序列,具体包括:
获取用户相似度,选取相似度排名前K的用户作为相似用户集合;其中,K值根据用户总量设置;获取目标用户录入矩阵和所有相似用户的用户录入矩阵;提取目标用户和相似用户集合中每个用户之间共同的输入值集合,作为推荐数值序列。
进一步可选地,所述获取表单title属性,判断表单之间的主从关系包括:
分别获取待判断的表单的所有title属性和各表单的主键或外键;根据title属性和各表单的主键或外键判断表单之间的主从关系,包括设表单编号分别为A和B,若表单B的主键或外键包含于表单A的title属性集中,则表单B是表单A的子表单,表单A是表单B的父表单。
进一步可选地,所述获取表单title属性的周期性和表单的主从关系,判断待测表单及其主从表是否需要更新包括:
获取所有数值录入表单中数值录入控件的title属性,并标注该属性属于周期性还是非周期性,最后标注每张表单属于需更新的表单还是不需更新的表单;将标注后的数据作为训练集,基于朴素贝叶斯模型判断表单是否需要更新;获取用户当前填写的表单,提取数值录入控件的title属性,遍历训练集中的title属性并计算其与用户当前填写的表单title属性的相似度,取相似度最高的title属性对应的周期性或非周期性作为用户当前填写的表单特征值;将待测表单特征值输入已训练好的朴素贝叶斯模型,输出待测表单更新类别;若待测表单属于需更新的表单,则获取待测表单的主从关系;若待测表单是父表单,则将待测表单的子表单也标记为需更新的表单,若待测表单为子表单则其父表单无需标记。
进一步可选地,所述表单更新后,判断推荐数值是否更新并获取更新周期包括:
获取需更新表单中数值录入控件的title属性,通过相似度判断title属性属于周期性还是非周期性;若title属性是非周期性,则推荐数值不用更新;若title属性是周期性,则推荐数值需要更新;获取周期性title属性对应的用户录入数据,并为每条数据附上时间戳且以天数为时间单位,采用带时间戳的用户录入数据构建时间序列数据集;利用傅里叶变换获取所述时间序列数据集的周期,首先计算各数值的频率,然后按照频率高低降序排列,选取频率最高的转化为更新周期。
进一步可选地,所述获取用户操作行为,判断数值精确度并预估推荐数值错误风险级别包括:
获取推荐数值后用户的操作行为数据,分别统计推荐总次数和用户选择了推荐数值的次数,并计算数值精确度;然后估计推荐数值错误的风险等级;获取所有的title属性,若title属性是非周期的则剔除数据,然后提取周期;根据所有title属性的周期大小确定三等分点,将所有title属性分为三个推荐数值错误风险级别,其中级别一推荐数值错误风险最高,周期最小。
进一步可选地,所述根据数值精确度及推荐数值错误风险级别重新推荐数值包括:
获取数值精确度及title属性的风险级别;判断数值精确度是否小于第二阈值,若数值精确度大于或等于第二阈值则不进行操作,否则判断title属性的风险级别;若title属性的风险级别为级别一或级别二则向用户推送提示框,提示用户考虑重新推荐数值,并输出数值精确度,然后重新推荐数值;采用马尔可夫模型为用户重新推荐数值;首先获取用户历史填写表单的数据,生成用户录入矩阵,进而确定一步转移概率矩阵;求出n步转移概率矩阵,计算用户在n步之后可能录入的数值;其中n根据title周期确定;将预测的数值重新推荐给用户。
本发明实施例提供的技术方案可以包括以下有益效果:
本发明能够对低代码中表单进行关联分析,实现联动变化后,用户在拖拽数值型控件时,对需要填写的数值进行预测,减少用户自己填写数值的麻烦。同时对数值推荐中存在的风险和推荐精度进行预测,若推荐结果错误风险很大则提示用户,避免了推荐的错误。
附图说明
图1为本发明的一种表单联动变化中数值推荐方法的流程图。
图2为本发明的一种表单联动变化中数值推荐方法的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本实施例一种表单联动变化中数值推荐方法具体可以包括:
步骤101,获取用户录入的表单数据,构建用户录入矩阵。
获取用户在表单内录入的所有内容;构建一个用户录入模型,所述用户录入模型包括一个用户录入矩阵M;用户录入矩阵M描述了用户在其填写的表单时所有录入值出现次数的矩阵;用户录入矩阵M为一个m*n阶矩阵,U是用户集合,I是表单中的录入值,Sij是用户在其填写表单时各录入值被填写的次数;例如,用户张三和李四在网站A上填写表单。表单内容包括不同供应商售卖产品的价格,一共有三种价位:I1=5499、I2=5999、I3=5200。假设用户张三和李四填写记录分别为I1:3次、I2:12次、I3:1次,I1:12次、I2:3次、I3:1次。则用户录入矩阵M表示为{(3,12,1)(12,3,1)}。在Sij中,i表示第i位用户,j表示第j个录入值。
步骤102,根据用户录入矩阵就行用户相似度识别。
获取目标用户历史填写记录,转化为目标用户的用户录入矩阵M;在构建了用户录入矩阵M的基础上,通过皮尔逊相关系数法动态获取目标用户Ua与用户集合U的相似度集合S;所述相似度集合S是目标用户Ua和用户集合U中每个用户的历史填写记录的相似度值的集合,方法如下:遍历用户集合U,分别计算目标用户Ua与用户集合U的相似度值,并用集合S表示;将集合S中的相似度值元素Sm按从大到小的顺序排列,相似度值元素Sm越大用户相似度越高,相似度值元素Sm越小用户相似度越小。例如,王五的用户录入矩阵M={(9,1,0)}。构建用户录入模型矩阵为{(3,12,1)(12,3,1)}。王五和张三的相似度S1=|(9-7.5)(3-7.5)+(1-7.5)(12-7.5)+(0-1)(1-1)|/根号(6.75^2+35.75^2+0)=1.168。同理,王五和李四的相似度S2=|(9-7.5)(12-7.5)+(1-7.5)(3-7.5)+(0-1)(1-1)|/根号(8.75^2+29.25^2+0)=1.245。则S={S1,S2}。使用皮尔逊相关系数法计算用户相似度,公式为:
,其中a,b表示用户a和用户b,Saj和Sbj分别表示用户a和用户b在填写表单时第j项各录入值被填写的次数,s表示所有用户录入第j项内容的平均录入次数。
步骤103,根据表单主题相关度、表单结构、表单内容对表单关联度进行判别。
表单关联度判别包括计算表单主题相关度、基于决策树的表单结构分类和计算表单内容相似度;所述计算表单主题相关度包括通过表单标题确定表单的主题,将标题相似度作为表单主题相似度值;所述基于决策树的表单结构分类包括,判断表单是否属于数值录入表单,若属于则记为1,否则记为0;所述计算表单内容相似度包括根据表单中对应数值输入控件的title属性判断表单内容的相似度;给三个结果分别赋予相应权重,记为w1、w2、w3,则表单关联度=w1*表单主题相似度+w2*表单结构分类结果+w3*表单内容相似度;其中三个权重需要通过反复测试修改得到。例如,表单1和表单2的主题相关度、结构分类结果和内容相似度分别为0.71、1、0.5,设定的权重分别为0.2、0.3、0.5。则表单关联度=0.2*0.71+0.3*1+0.5*0.5=0.692。
计算表单主题相关度。
获取表单的标题,使用jieba对标题进行分词并去除停用词后输出词语;基于语料库计算词语相似度,根据语料库对不同词语的编号计算两个词语之间的相似度;首先判断在语料库中作为叶子节点的两个词语的编号在哪一层不同,相同则乘1,否则乘相应的系数,然后再乘以调节参数和控制参数;则词语A和词语B的相似度=各层系数*调节参数*控制参数;其中各层系数由多次实验后确定;表单主题相关度等于标题词语相似度的平均值。例如,‘Ac05B01=’:邮差、投递员、信使、快递员,‘Ac05B02=’:通讯员、交通员、交通,Ac05B03=联络员、联系人、联系官。选取《同义词词林》作为语料库,《同义词词林》给每个中文词语赋予了编号,编号包括八位数。第一位表示第一层,第二位表示第二层,第三、四位表示第三层,第五位表示第四层,第六、七位表示第五层,第八位是词语关系码不分层,不同层次代表词语所属的不同类别。用abcde分别表示各层系数,假设a=0.1,b=0.65,c=0.8,d=0.9,e=0.96。调节参数公式为cos(n*Π/180),控制参数公式为(n-k+1)/n。n为分支层的节点总数,k为两个分支间的距离。将邮差和联络员的相似度记为Sim(A,B),则Sim(A,B)=e*cos(3*Π/180)*(3-2+1)/3=0.64,其中从编码可以看出,Ac05B01=和Ac05B03=只在第七位不同,则分支层为第五层,系数为e,由于第五层一共存在三个分支因此n=3,而邮差在第一分支,联络员在第三分支因此k=3-1=2。若表单主题分别为“上海程序员的薪资水平”和“北京程序员的薪资水平”,经过分词并去除停用词后得到“上海、程序员、薪资水平”和“北京、程序员、薪资水平”,若求得词语相似度分别为0.13、1、1,则表单主题相关度=(0.13+1+1)/3=0.71。
基于决策树的表单结构分类。
获取表单集合,根据是否包含数值输入框将表单集合分为两大类:数值录入表单和非数值录入表单,并给每个表单打上类别标签;将带标签的表单集合作为训练集训练决策树;通过训练好的决策树提取表单结构特征,生成一棵用于判断表单结构类型的决策树;决策过程包括:首先分别对训练集中两大类别计数,并计算各类别出现的概率P和信息熵;然后将待分类表单的特征值输入决策树,每次决策时重新计算一次信息熵,选择信息熵增加最大的分支作为决策结果;对于生成的决策树使用以下规则进行分类:如果表单中不存在标签,那么是非数值录入表单,如果含有标签,抽取表单控件的约束类型,如果约束类型是数值型,那么是数值录入表单,否则属于非数值录入表单。例如,对于表单有以下特征{:yes,num:yes}{:yes,num:yes}{:yes,num:no}假设训练集两大类别出现的概率分别为0.6和0.4,则初始h=-(0.6*log(0.6)+0.4*log(0.4))=0.29。信息熵公式为h=-Σ(p*log(p))。则对第一条规则进行决策时含input的信息熵为h1=p1*h=1*0.29=0.29,不含input的信息熵为0,因此第一次决策结果为含input,则继续判断约束类型。h2=p2*h1=2/3*0.29=0.19,h3=0.097,则第二次判断结果为数值型约束,因此属于数值录入表单。
获取表单控件的title属性并计算表单内容相似度。
表单内容相似度包括根据表单中对应数值输入控件的title属性判断表单内容的相似度;获取类别为数值录入表单中对应数值输入控件的title属性作为特征词汇;首先进行预处理,去除title属性中出现在括号中的内容,如果特征词汇由多个词语构成则使用jieba进行分词操作,并去除无意义的停用词;然后计算表单内容的相似度;将处理后的title属性作为特征向量,基于《同义词词林》利用特征向量计算待测title属性的相似度;遍历待测表单对应数值输入控件的title属性,计算各个title属性与待比较表单内的title属性的相似度,将待测表单与待比较表单中所有title属性的平均相似度作为两个表单内容相似度值。例如,待测表单有两个数值输入控件,对应的title属性分别为:在上海的月薪和年龄。待比较表单只有一个数值输入控件,对应的title属性为:年龄。则预处理之后得到特征向量分别为:1{上海、月薪}2{年龄}、3{年龄}。设基于《同义词词林》计算相似度结果如下:向量1和向量3相似度=0,向量2和向量3相似度=1,则两个表单内容相似度值=(0+1)/2=0.5。
步骤104,根据表单关联度和用户相似度推荐数值。
获取目标用户历史填写数据以及所有用户填写过的表单集合;其中用户历史填写数据包括用户填写表单、用户填写内容;同一用户填写过表单,从历史填写数据中推荐,不同用户但填写的表单部分信息相同,则根据表单关联度和用户相似度推荐;首先,在用户历史填写数据中匹配用户当前填写的表单,若匹配结果不为空,则向用户推荐距离当前时间最近的历史填写数据;若匹配结果为空,首先获取用户当前填写的表单与后台表单集合的关联度,取关联度的平均值作为第一阈值;然后提取与用户当前填写的表单关联度大于第一阈值的表单作为关联表单,计算用户当前填写的表单和关联表单的内容相似度,并输出内容相似度大于平均内容相似度的title属性,获取所述title属性对应的已填写的用户集合,根据用户相似度确定推荐数值序列。例如,张三在10月1号和10月2号分别填写了一次表1,则张三在10月3号再次填写表2时,属于同一用户填写过表单的情况,应向其推荐10月2日填写的数据。王五没填写过表1,经计算与表1相关联的表单有表2和表3,从中筛选出内容相似度大于平均内容相似度的title属性有公司代码和岗位代码。进而获取填写过这两项属性的用户集合:张三和李四,经计算,和王五相似的用户是李四,则王五和李四共同的输入值集合应作为推荐值。
根据用户相似度确定推荐数值序列。
获取用户相似度,选取相似度排名前K的用户作为相似用户集合;其中,K值根据用户总量设置;获取目标用户录入矩阵和所有相似用户的用户录入矩阵;提取目标用户和相似用户集合中每个用户之间共同的输入值集合,作为推荐数值序列。例如,王五的用户录入矩阵M={(9,1,0)},相似用户录入矩阵为{(3,12,1)(12,3,1)}。假设岗位代码录入值共有3个,分别为I1=5499、I2=5999、I3=5200。假设用户张三和李四填写记录分别为I1:3次、I2:12次、I3:1次,I1:12次、I2:3次、I3:1次。王五和张三的相似度为1.168,和李四的相似度为1.245。若K=1,则李四是相似用户。由于王五和李四共同的输入值集合={I1,I2},因此5499和5999应作为推荐值。K值限定了相似用户集合的数量,由于每个用户录入数据量不同,所以得到的推荐输入值集合也不同,为了便于用户查看并选择推荐的数值,K值应根据用户总量设定。
步骤105,获取表单title属性,判断表单之间的主从关系。
分别获取待判断的表单的所有title属性和各表单的主键或外键;根据title属性和各表单的主键或外键判断表单之间的主从关系,包括设表单编号分别为A和B,若表单B的主键或外键包含于表单A的title属性集中,则表单B是表单A的子表单,表单A是表单B的父表单;例如,表单A为产品信息表,表单B为订货表。由于订货表用产品编号作外键,用来获取产品信息,二产品编号包含于产品信息表中。因此,表单A是父表单,表单B是子表单。父表单为主表,子表单为从表。
步骤106,获取表单title属性的周期性和表单的主从关系,判断待测表单及其主从表是否需要更新。
获取所有数值录入表单中数值录入控件的title属性,并标注该属性属于周期性还是非周期性,最后标注每张表单属于需更新的表单还是不需更新的表单;将标注后的数据作为训练集,基于朴素贝叶斯模型判断表单是否需要更新;获取用户当前填写的表单,提取数值录入控件的title属性,遍历训练集中的title属性并计算其与用户当前填写的表单title属性的相似度,取相似度最高的title属性对应的周期性或非周期性作为用户当前填写的表单特征值;将待测表单特征值输入已训练好的朴素贝叶斯模型,输出待测表单更新类别;若待测表单属于需更新的表单,则获取待测表单的主从关系;若待测表单是父表单,则将待测表单的子表单也标记为需更新的表单,若待测表单为子表单则其父表单无需标记。例如,年龄属于非周期性,产品售价属于周期性,只要表单中包含一个周期性数据,那么在标注整张表单时应将表单标记为需更新的表单。为了实现自动判断表单是否需要更新,需要人工标注数据集来训练判断模型。用户当前填写的表单包括年龄、产品售价、产品成本,通过计算相似度得到三个title属性对应的周期性判断结果为:非周期、周期、周期,即表单特征值。将表单特征值输入训练好的朴素贝叶斯模型。朴素贝叶斯模型通过计算条件概率实现二分类功能,即P(需更新|非周期、周期、周期)和P(不需更新|非周期、周期、周期),概率大的一方为判断结果。若待测表单为产品信息表,属于需更新的表单且是订货表的父表单,则产品信息表更新后订货表也需要同步更新,因此在判断产品信息表是否需要更新时应同步判断订货表是否需要更新。
步骤107,表单更新后,判断推荐数值是否更新并获取更新周期。
获取需更新表单中数值录入控件的title属性,通过相似度判断title属性属于周期性还是非周期性;若title属性是非周期性,则推荐数值不用更新;若title属性是周期性,则推荐数值需要更新;获取周期性title属性对应的用户录入数据,并为每条数据附上时间戳且以天数为时间单位,采用带时间戳的用户录入数据构建时间序列数据集;利用傅里叶变换获取所述时间序列数据集的周期,首先计算各数值的频率,然后按照频率高低降序排列,选取频率最高的转化为更新周期。例如,产品编号和产品售价两个title属性,通过计算相似度得到属于产品编号非周期性,产品售价属于周期性,则产品售价对应的推荐数值需要更新。若产品售价对应的时间序列数据集经傅里叶变换后的最高频率为0.035则周期=1/0.035=28.57(天)。更新周期的计算公式为周期=1/频率。
步骤108,获取用户操作行为,判断数值精确度并预估推荐数值错误风险级别。
获取推荐数值后用户的操作行为数据,分别统计推荐总次数和用户选择了推荐数值的次数,并计算数值精确度;然后估计推荐数值错误的风险等级;获取所有的title属性,若title属性是非周期的则剔除数据,然后提取周期;根据所有title属性的周期大小确定三等分点,将所有title属性分为三个推荐数值错误风险级别,其中级别一推荐数值错误风险最高,周期最小。例如,数值精确度=Σ(用户选择了推荐数值的次数/推荐总次数)/用户总数。系统共推荐了4次,用户1选择了2次,用户2选择了3次,则数值精确度=(2/4+3/4)/2=0.625。若title属性有年龄、产品售价、产品成本,因年龄是非周期的,所以剔除年龄属性,产品售价、产品成本周期分别为28.57,21,则三等分点分别为(28.57+21)/3=16.52和(28.57+21)*2/3=33.04,因此产品售价和产品成本属于级别二。Σ(用户选择了推荐数值的次数/推荐总次数)表示对所有用户求和。因为数值推荐存在误差,需要通过用户的操作行为估计所推荐的数值是否准确,如果失准则需要改变推荐方式。
步骤109,根据数值精确度及推荐数值错误风险级别重新推荐数值。
获取数值精确度及title属性的风险级别;判断数值精确度是否小于第二阈值,若数值精确度大于或等于第二阈值则不进行操作,否则判断title属性的风险级别;若title属性的风险级别为级别一或级别二则向用户推送提示框,提示用户考虑重新推荐数值,并输出数值精确度,然后重新推荐数值;采用马尔可夫模型为用户重新推荐数值;首先获取用户历史填写表单的数据,生成用户录入矩阵,进而确定一步转移概率矩阵;求出n步转移概率矩阵,计算用户在n步之后可能录入的数值;其中n根据title周期确定;将预测的数值重新推荐给用户。例如,用户正在录入的表单控件对应的title属性风险级别为二,数值精确度为0.625,则提示用户考虑重新推荐数值,并输出数值精确度,然后重新推荐数值。马尔可夫模型是一种根据事件目前的状况预测将来时刻变动状态的方法,是进行预测的基本方法。由于利用现有方法推荐数值不够精确,因此需要换一种推荐方法。在推荐算法中一般第二阈值取90%时表示较好的推荐准确度。
以上仅列举了本发明的一些优选实施方式,但本发明并不局限于此,还可以作出许多的改进和变换。只要是在本发明基本原理基础上所作出的改进与变换,均应视为落入本发明的保护范围内。