一种飞机零部件装配关系自动梳理方法
文献发布时间:2023-06-19 19:30:30
技术领域
本申请属于飞机装配技术领域,特别涉及一种飞机零部件装配关系自动梳理方法。
背景技术
目前国内梳理飞机零部件重量重心数据时,主要由重量专业的工程师们人工综合重量、重心、图号等信息梳理出零部件之间的装配关系。由于数据量非常庞大,各结构和系统汇总过来的重量重心数据装配关系计算机不可读、不严格正确,且重量重心数据也存在一定的误差,数据梳理工作需要投入大量的人力资源且梳理结果也存在不少错误。因此,重量专业亟需一个能够快速、准确梳理出零部件装配关系的方法。
发明内容
本申请的目的是提供了一种飞机零部件装配关系自动梳理方法,以解决现有技术中需要人为梳理零部件装配关系而导致效率较低的问题。
本申请的技术方案是:一种飞机零部件装配关系自动梳理方法,包括:
检验飞机各数据是否满足格式要求,定位出问题数据并进行更正;
按照当前航空发动机的零部件等级划分,获取所有待梳理数据中重量最大数据的最佳子一级数据;
遍历各子一级数据,获取各子一级数据中的最佳子一级数据;
判断所有已梳理数据的末级数据是否含有子集,若无,则进行下一步,若有则重复遍历各子一级数据,直至找出不含有子集的最佳子一级数据;
判断是否完成所有数据的梳理,若是,则进行下一步骤;若否,有则重复遍历各子一级数据,直至找出不含有子集的最佳子一级数据;
评估数据装配关系混乱程度并输出梳理结果。
优选地,所述最佳子一级数据的获取采用模拟退火算法方法来计算,计算方法为:
获取所有待梳理数据行数R,以及最大待梳理重量W、最小待梳
num max
理重量W
总体状态能量E采用飞机零部件装配关系混乱程度衡量标准,改进后主状态能量E
以最小待梳理重量为装配体,随机产生一个行数不多于子集元素行数限制的子一级子集,计算主目标函数,判断主目标函数是否满足设计要求;
若不满足设计要求,则计算主目标函数增量ΔE
若满足设计要求,则计算副目标函数ΔE
判断循环次数是否已到达马尔科夫链长度,若是则执行下一步,若否则重新计算主目标函数;
设置当前温度t=t*a;
判断当前温度是否已达到最低温度T
优选地,所述最佳子一级数据的获取方法为:输入所有的数据,已知总重量和重心,先设定一个预估的零部件数量,从数据列表中选出预估数量的部分零部件数据列,挑出重量较大的数据列,去除重量较小的数据列放入原数据列表中,计算挑出的数据列与总重量的差值;然后再挑出部分或全部满足重量的数据列,分一次或多次挑选;直至满足总重要求,计算选出数据列的重心和转动惯量;重复上述步骤,找出多组满足重量要求的数据列,而后计算重心与原重心差距最小、同时转动惯量最小的一组,即找到最佳子一集数据。
优选地,所述数据装配关系混乱程度的表示方法为:通过顶图数量以及顶图和其子级之间的重量重心关系获得能够衡量零部件装配关系混乱情况的正实数;正实数数值越大,装配关系越混乱。
本申请的一种飞机零部件装配关系自动梳理方法,在进行飞机零部件数据的筛选时,先进行数据的更正,而后按照当前航空发动机的零部件等级划分,先找到重量最大数据的最佳子一级数据,而后按照层级从大至小的顺序依次对每一层级的数据进行筛选,直至筛选完成所有数据,最后进行混乱程度的评价以完成所有梳理,能够快速、准确地梳理出飞机各个系统、结构的零部件重量数据装配关系,并指出所提供数据中的错误,给出了数据梳理前后装配关系混乱程度值的变化,为后续的数据计算、分析奠定了数据基础。
附图说明
为了更清楚地说明本申请提供的技术方案,下面将对附图作简单地介绍。显而易见地,下面描述的附图仅仅是本申请的一些实施例。
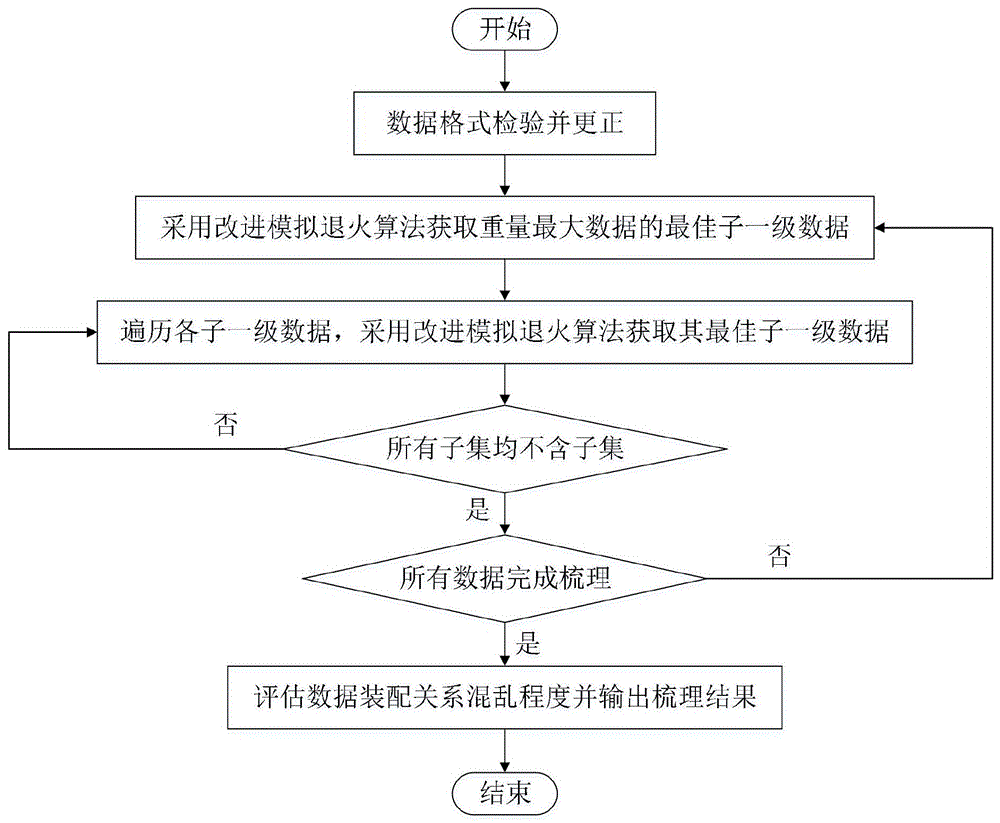
图1为本申请整体流程示意图;
图2为本申请模拟退火算法流程示意图。
具体实施方式
为使本申请实施的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行更加详细的描述。
一种飞机零部件装配关系自动梳理方法,为我院某型号一轮全机重量重心数据部分计算任务,其数据见附表1。重量专业将各专业提供的数量庞大、数据有误差、装配关系错乱且装配关系计算机不可读的飞机零部件重量重心数据,通过VBA编程,对各专业提供的Excel格式的数据进行处理。
表1
/>
如图1所示,包括如下步骤:
步骤S100,针对附表1数据,检验飞机各数据是否满足格式要求,定位出问题数据并进行更正;在接收的飞机各数据中,存在数据非数字、重心未提供、数据含空格等问题,如果不进行更正,有可能出现筛选错误,因此需要先找到问题数据并更正后,然后进行数据的梳理。
步骤S200,按照当前航空发动机的零部件等级划分,获取所有待梳理数据中重量最大数据的最佳子一级数据;
目前的航空发动机从整机到、组件和零件划分成多个层级,不同层级依据数据RGB值的装配等级表示方法,如表2所示。
表2
每个下一级数据均与一个上一级数据存在对应关系,本申请采用从大的层级至小的层级依次向下的方式来进行自动的梳理。
其中重量最大数据也就是最高一级数据,为了找到所需的数据,本申请采用两种算法,第一种为优化后的模拟退火算法,如图2所示,具体包括如下步骤:
Step1:获取所有待梳理数据行数R
Step2:总体状态能量E采用飞机零部件装配关系混乱程度衡量标准,改进后主状态能量E
优选地,总体状态能量E为:
其中,k
改进后主状态能量E
副状态能量E
在一个具体实施例中,设置初始温度T
Step3:以最小待梳理重量W
Step4:若不满足设计要求,则计算主目标函数增量ΔE
Step5:若满足设计要求,则计算副目标函数ΔE
Step6:判断循环次数是否已到达马尔科夫链长度,若是则执行下一步,若否则重新计算主目标函数;
Step7:设置当前温度t=t*a;
Step8:判断当前温度是否已达到最低温度T
本申请通过采用改进后的模拟退火算法找到重量最大的最佳子一级数据,通过产生随机数的方式进行最小待梳理重量的装配体的寻找,能够根据重量数据情况,确定初始温度、终止温度、冷却速度、迭代次数等参数,通过不断计算目标函数值的增量,获得最优解,从而准确高效地找到所需的最佳子一级数据。已经找到的数据从飞机内各数据中删除。
该搜索方法的改进主要是将原模拟退火算法不限制参与计算数据个数更改为当主目标函数值第一次满足要求后,随着副目标函数值的不断变小,参与计算的数据个数不断减小,使得搜索效率不断提升。当主目标函数值首次满足要求后,标志着该装配体已找到第一组满足重量重心关系的子集,由于副目标函数值反映装配体质量分布的集中程度,其搜索的更优子集的元素个数应不大于当前子集的个数,据此将每轮搜索中参与计算的数据不断减少。
第二种采用预估的方法来进行所需数据的筛选,具体包括:
输入所有的数据,已知总重量和重心,先设定一个预估的零部件数量,从数据列表中选出预估数量的部分零部件数据列,挑出重量较大的数据列,去除重量较小的数据列放入原数据列表中,计算挑出的数据列与总重量的差值;然后再挑出部分或全部满足重量的数据列,分一次或多次挑选;直至满足总重要求,计算选出数据列的重心和转动惯量;
重复上述步骤,找出多组满足重量要求的数据列,而后计算重心与原重心差距最小、同时转动惯量最小的一组,即找到最佳子一集数据。
通过采用该方法,所需处理的数据量更少,能够更加快速地找到所需的最佳子一级数据。
步骤S300,遍历各子一级数据,获取各子一级数据中的最佳子一级数据;对于至少具有十个层级的数据,需要先筛选完成上一级的所有数据之后,才能够进行下一级数据的筛选;每一层级数据的筛选均按照步骤S200中的方法进行筛选,直至筛选完成所有层级的数据。
步骤S400,判断所有已梳理数据的末级数据是否含有子集,若无,则进行下一步,若有则重复遍历各子一级数据,直至找出不含有子集的最佳子一级数据;
步骤S500,判断是否完成所有数据的梳理,若是,则进行下一步骤;若否,有则重复遍历各子一级数据,直至找出不含有子集的最佳子一级数据;
步骤S600,评估数据装配关系混乱程度并输出梳理结果。
优选地,数据装配关系混乱程度的表示方法为:通过顶图数量以及顶图和其子级之间的重量重心关系获得能够衡量零部件装配关系混乱情况的正实数;正实数数值越大,装配关系越混乱。最后得到的梳理结果见表3:
表3
/>
本申请在进行飞机零部件数据的筛选时,先进行数据的更正,而后按照当前航空发动机的零部件等级划分,先找到重量最大数据的最佳子一级数据,而后按照层级从大至小的顺序依次对每一层级的数据进行筛选,直至筛选完成所有数据,最后进行混乱程度的评价以完成所有梳理,能够快速、准确地梳理出飞机各个系统、结构的零部件重量数据装配关系,并指出所提供数据中的错误,给出了数据梳理前后装配关系混乱程度值的变化,为后续的数据计算、分析奠定了数据基础。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。