一种利用生物质谱技术筛选低丰度蛋白的方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及生物筛选技术领域,具体涉及一种利用生物质谱技术筛选低丰度蛋白的方法。
背景技术
间充质干细胞(Mesenchymal stromal/stem cells,MSCs)是一种多能性干细胞,具有自我更新和多向分化潜能,以及免疫调节特性和丰富的分泌功能,在成体组织的修复和再生过程中发挥着重要作用。相较于胚胎干细胞和诱导多能干细胞,其易于获得,易于体外扩增,无伦理问题等他特点更为其临床应用带来了极大的优势,为多种急、难病患者带来了新的希望。自从20世纪70年代Friedenstein等人发现MSCs以来,其就一直是临床转化研究的焦点。
近年来研究表明,间充质干细胞主要通过分泌组,即可溶性因子以及与细胞外囊泡(EV)相关的分子的混合物的时空特异性释放调控体内受损部位的炎症反应并促进局部再生。MSC分泌组成分受到微环境的影响,具有高度的特异性,甚至不同供体、不同组织来源,不同培养条件和传代次数都会造成MSC分泌组的巨大差异。因此,明确定义MSC分泌组成分,筛选MSC分泌组中具有治疗效果的组分,针对于受损的靶细胞或组织“操控”MSC分泌具有生物价值的组分,是MSC真正进入临床转化的前提。
长期以来,间充质干细胞分泌组成分的基本检测多基于酶联免疫吸附剂测定(enzyme linked immunosorbent assay,ELISA)、蛋白质印迹(Western Blot)等低通量的检测手段[7]。蛋白质芯片技术虽能一次性检测数十种分泌物组分,但检测靶标也局限于常见的MSC分泌因子,且无法评价MSC响应细胞外微环境进行特定分泌行为的细胞内信号转导和调控个过程。液相色谱-串联质谱(LC-MS/MS)虽能够高通量地检出已知和未知的MSC分泌组,但现有技术对高丰度(表达)分泌组因子检测效率较高,而对低丰度(表达)和组成型表达的成分鉴别尚需完善。
发明内容
为解决上述问题,本发明提供了一种利用生物质谱技术筛选低丰度蛋白的方法。
为实现上述目的,本发明采取的技术方案为:
一种利用生物质谱技术筛选低丰度蛋白的方法,包括如下步骤:
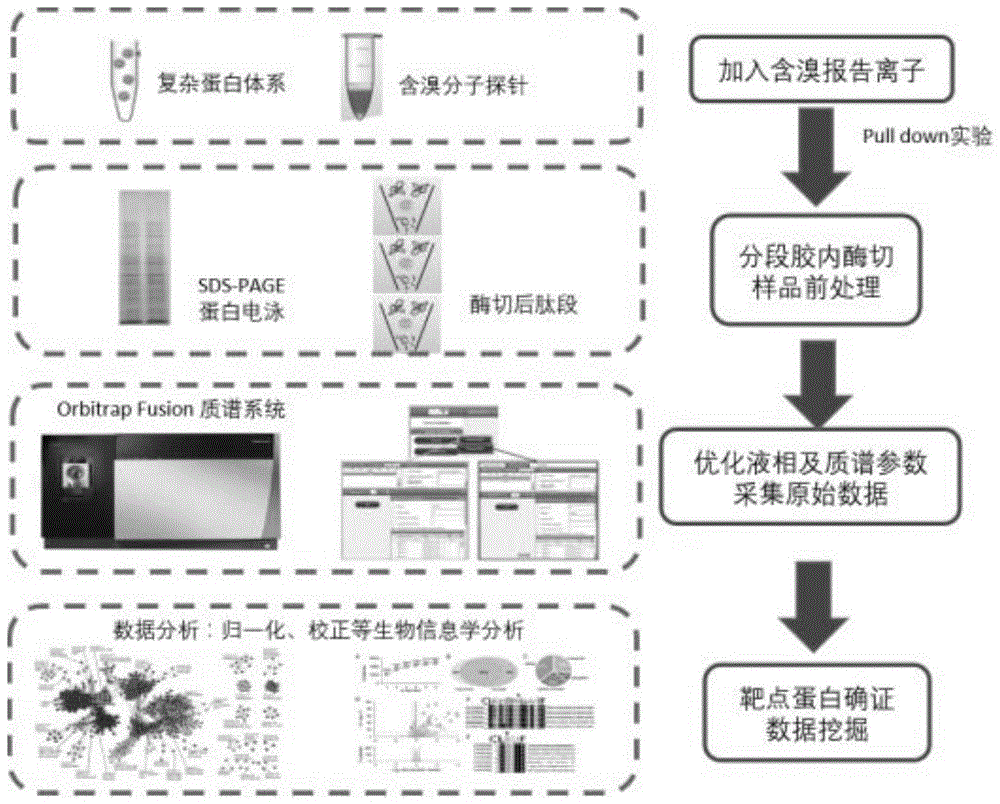
S1、收集样本后进行蛋白质和含溴分子探针的孵育;
S2、pull down实验后分段胶内酶切;
S3、优化液相梯度和相关参数并进行HPLC分离,分级进入MS电场进一步离子化,通过优化质谱参数获得各离子质荷比和峰型信息;
S4、数据库检索比对获得蛋白质的定性和序列信息进行确证。
进一步地,利用常用的Uniprot蛋白组学数据库中分泌蛋白的注释信息及蛋白序列建立分泌组蛋白数据库,并辅以RefSeq数据库完善同工酶等蛋白信息及序列,对于新分泌蛋白及非经典途径分泌蛋白的筛选及纳入,我们采用CJ-SPHMM,TMHMM和PSORT三个工具进行预测,选择至少2个工具预测为分泌蛋白的纳入数据库。
进一步地,通过已建立的分泌蛋白数据库中蛋白的注释信息,将已获得蛋白结果利用生物信息学分析的方法,根据关键蛋白来源及分类通过生物信息学分析的方法生成可视化蛋白互作网络图的步骤。
进一步地,所述步骤S3中,优化质谱检测过程中的液相梯度和相关参数,实现最大限度正确识别MSC分泌组,其中,
样品拾取和加载参数:取样量1ul,流量20ul/min;样品加载:10ul,600bar;
坡度参数:60~120分钟内设置不同流速和不同比例A、B相,观察实时质谱信号并调整梯度,最终优化得到质谱能在梯度时间内捕获到的总离子流最佳的梯度洗脱信息;
预柱和分析柱参数:柱前:2ul,600bar;分析柱:5ul,600bar
自动采样器参数:标准:100ul。
本发明可以应用于肿瘤和干细胞分泌组等复杂低丰度蛋白高通量鉴定,填补技术空白,预期最终鉴定的有效蛋白数量提高20%,数据重现性预期提高20%以上,显著提高低丰度蛋白鉴定的效率和准确性。建立基于质谱的细胞分泌组鉴定、细胞分泌行为调控机制研究和可视化分析流程,提高生物、化学和医学相关领域科研和转化工作效率,解决MSC临床转化过程中的重要问题。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明实施例一种利用生物质谱技术筛选低丰度蛋白的方法的流程图。
图2为本发明实施例中利用生物信息学技术研究MSC细胞分泌功能调控机制图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
药物化学生物学国家重点实验室质谱平台Orbitrap Fusion,是四极杆-静电场轨道阱-线性离子阱三合一组合式质谱。Fusion使用的Orbitrap为超高场质量分析器;Fusion具有超高分辨、高灵敏度、多级质谱能力,并且配备多种裂解模式(CID、HCD),适合蛋白质组学中复杂体系的高通量蛋白,为项目的顺利实施提供了强有力硬件保障。
1.Uniprot蛋白数据库的建立
Uniprot作为通用蛋白资源联盟,涵盖大部分Swiss-Prot、TreEMBL、Ensembl数据库中的蛋白序列及注释信息,包括蛋白功能、翻译后修饰、结构域和功能位点、二级结构、同源蛋白和疾病关联信息等内容,并有专业人员不定时校验并完善最新信息。我们通过Uniprot数据库检索人类来源的蛋白,下载了全部蛋白信息,在全部人类蛋白的基础上,检索蛋白关键词“secreted”和“extracellular matrix”,纳为分泌蛋白;检索关键词“membrane”和“junction”,纳为膜蛋白;检索关键词“nucleus”,纳为核蛋白;检索关键词“Cytoplasm”,纳为胞浆蛋白。
1.2.2RefSeq蛋白数据库的补充
RefSeq蛋白数据库作为补充,主要用于同工酶序列的完善,在NCBI数据库中检索人类蛋白,下载全部蛋白信息。与已建立的Uniprot数据库中蛋白序列进行blast,去除冗余蛋白,将与Uniprot数据库中基因ID相同的非分泌蛋白去除,将基因ID相同的同工酶蛋白序列进行补充。其余蛋白序列按照新分泌蛋白及非经典途径分泌蛋白的筛选及纳入方法,采用CJ-SPHMM,TMHMM和PSORT三个工具进行预测,选择至少2个工具预测为分泌蛋白的纳入数据库。
2.质谱检测参数的优化
由于细胞培养过程中采用胎牛血清培养,并使用猪胰酶消化,在样品制备的过程中可能混杂为处理干净的杂蛋白。同时,由于细胞培养过程中,可能由于操作不当等造成细胞凋亡、死亡等,释放大量膜蛋白、胞内蛋白等,蛋白信号显著掩盖种类众多但含量甚微的分泌蛋白信号,造成干扰。优化质谱检测过程中的液相梯度和相关参数(表1),实现最大限度正确识别MSC分泌组。
表-1Easy-nlc1000液相梯度及参数设置内容
表-2Maxquant2.0.3.0搜库参数设置内容
3.数据可视化的建立
通过蛋白库中蛋白注释信息,采用生物信息学的技术和策略对所获蛋白数据的来源及功能进行差异及聚类分析,将关键蛋白调控网络进行可视化作图,阐明对细胞组成成分,分子功能及关键通路的调控。
实施例1
一种利用生物质谱技术筛选低丰度蛋白的方法,包括如下步骤:
收集样本后进行蛋白质和含溴分子探针的孵育→pull down实验后分段胶内酶切→优化液相梯度并进行HPLC分离→分级进入MS电场进一步离子化→通过优化质谱参数获得各离子质荷比和峰型信息→数据库检索比对获得蛋白质的定性和序列信息进行确证(图1)。
通过已建立的分泌蛋白数据库中蛋白的注释信息,将已获得蛋白结果利用生物信息学分析的方法,根据关键蛋白来源及分类通过生物信息学分析的方法生成可视化蛋白互作网络图(图2)。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 用于筛选和鉴定低丰度小RNA表达谱的新型小RNA芯片的制备方法和应用
- 一种低丰度蛋白质翻译后修饰组的直接质谱检测方法