一种神话诗歌修复方法、系统、电子设备及介质
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及可控文本生成领域,特别是涉及一种神话诗歌修复方法、系统、电子设备及介质。
背景技术
神话诗歌是民众对世界思考与探索的产物,其多以纸质文本为载体。然而,由于自然、历史和人为等因素,记录神话诗歌内容的纸张会产生破裂、腐朽及字迹褪色等种种损伤,使得其完整性遭到破坏,故针对神话诗歌缺失句子进行修复,具有丰富的现实意义,有助于学者研究文化文学,推动文学的保护、传承与发展。
目前,缺损神话诗歌修复方法主要是文学研究人员依据其文学素养和专业领域知识补全缺失句子,由于神话诗歌文章篇幅长,研究人员需要耗费大量时间理解神话诗歌内容,同时文学专业研究人力资源稀缺,仅靠人工修复无法充分满足当前神话诗歌的修复需求,故需建立一种计算机辅助手段,帮助文学研究人员快速修复神话诗歌。
文本生成是指自动生成类似自然语言的文本,公知的基于文本生成的修复方法在预训练语言模型的基础上,能很好地生成话语流畅和语句多样的文本句子。例如,申请号为202211593665.9的专利,基于标准的Transformer模型对输入文本进行注意力计算,并结合输入文本的词性知识和句法知识提升生成的文本句子的流畅性。申请号为202211609591.3的专利,分别训练主题、情感和写作风格的判别器模型,利用贝叶斯公式、联合预训练语言模型的输出概率和判别器模型的输出概率,从而生成同时满足主题、情感和写作风格要求的文本句子。然而,这些方法仅使用生成句子之前的文本句子信息,并未考虑生成句子之后的文本句子信息,难以扩展到同时具有上下文信息的神话诗歌修复任务上。
文本修复是根据上下文信息自动生成文本句子或段落中的缺失部分,目前公知的基于预训练语言模型的文本修复方法实现了文本句子中缺失词汇的修复。例如,田文靖提出的基于深度学习的文本填充算法研究的文献中,提出了一种基于预测网络与语义相似度融合损失的文本填充方法,首先使用双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)对缺失文本句子进行编码,得到上下文语义特征,然后使用Transformer网络基于上下文语义特征逐一填充句子空白缺失部分,最后基于语义相似度融合损失方法,提升填充后文本句子的语义连贯性和流畅性。盛威等提出的基于深度学习的中医古籍缺失文本修复研究的文献中,将深度学习技术应用于中医古籍缺失文本修复中,选取《黄帝内经》和《金匮要略》等经典中医古籍构建数据集,使用RoBERTa预训练语言模型对中医文本句子的缺失词汇进行生成。然而,这些方法未考虑文本句子之间的关联关系,并且存在特定领域文本中独有词汇生成困难的问题,难以扩展到具有独有词汇的神话诗歌缺失句子修复任务上。
因此,如何实现神话诗歌修复,有效提升神话缺失句子的上下文相关性和连贯性成为目前亟待解决的问题。
发明内容
基于此,本发明实施例提供一种神话诗歌修复方法、系统、电子设备及介质,以有效提升神话缺失句子的上下文相关性和连贯性。
为实现上述目的,本发明实施例提供了如下方案:
一种神话诗歌修复方法,包括:
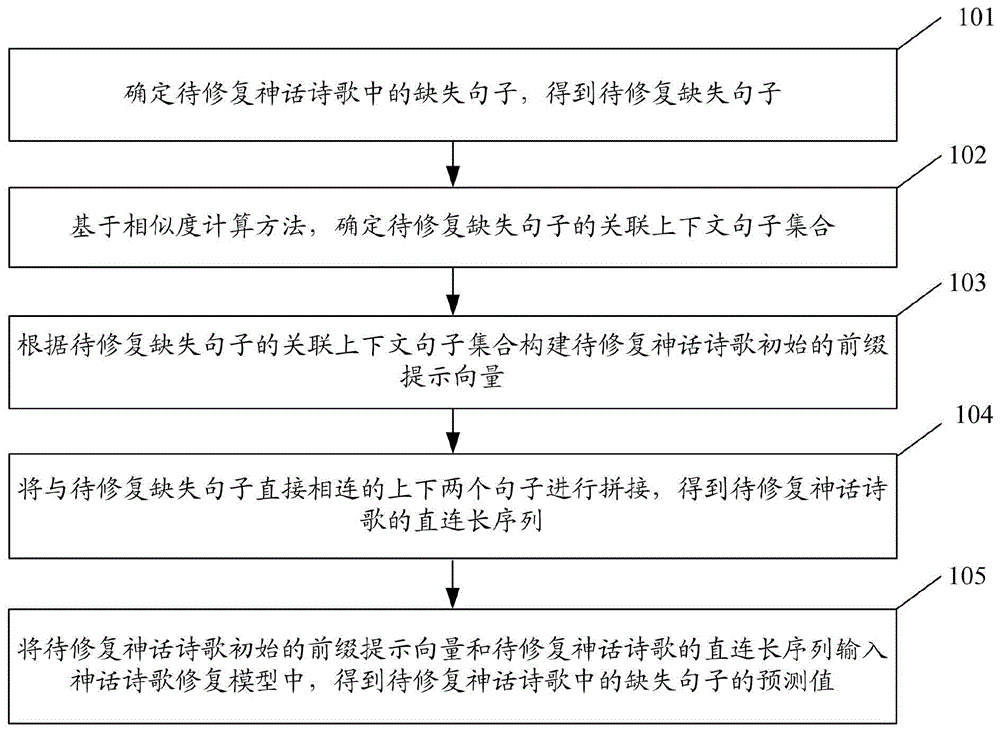
确定待修复神话诗歌中的缺失句子,得到待修复缺失句子;
基于相似度计算方法,确定待修复缺失句子的关联上下文句子集合;
根据待修复缺失句子的关联上下文句子集合构建待修复神话诗歌初始的前缀提示向量;
将与待修复缺失句子直接相连的上下两个句子进行拼接,得到待修复神话诗歌的直连长序列;
将待修复神话诗歌初始的前缀提示向量和待修复神话诗歌的直连长序列输入神话诗歌修复模型中,得到待修复神话诗歌中的缺失句子的预测值;
其中,所述神话诗歌修复模型采用训练数据对混合概率生成网络进行训练得到;所述训练数据根据多篇未缺失的神话诗歌确定;所述混合概率生成网络包括:编码器模块、前缀调优模块、解码器模块和混合概率模块;
所述编码器模块用于提取直连长序列中每个字的隐向量,得到第一隐向量;所述前缀调优模块用于对初始的前缀提示向量进行优化,得到前缀提示优化向量;所述解码器模块用于根据前缀提示优化向量提取缺失句子中每个字的隐向量,得到第二隐向量;所述混合概率模块用于根据所述第一隐向量和所述第二隐向量确定缺失句子的预测值。
本发明还提供了一种神话诗歌修复系统,包括:
待修复缺失句子确定单元,用于确定待修复神话诗歌中的缺失句子,得到待修复缺失句子;
关联上下文句子确定单元,用于基于相似度计算方法,确定待修复缺失句子的关联上下文句子集合;
初始前缀提示向量构建单元,用于根据待修复缺失句子的关联上下文句子集合构建待修复神话诗歌初始的前缀提示向量;
直连长序列拼接单元,用于将与待修复缺失句子直接相连的上下两个句子进行拼接,得到待修复神话诗歌的直连长序列;
缺失句子预测单元,用于将待修复神话诗歌初始的前缀提示向量和待修复神话诗歌的直连长序列输入神话诗歌修复模型中,得到待修复神话诗歌中的缺失句子的预测值;
其中,所述神话诗歌修复模型采用训练数据对混合概率生成网络进行训练得到;所述训练数据根据多篇未缺失的神话诗歌确定;所述混合概率生成网络包括:编码器模块、前缀调优模块、解码器模块和混合概率模块;
所述编码器模块用于提取直连长序列中每个字的隐向量,得到第一隐向量;所述前缀调优模块用于对初始的前缀提示向量进行优化,得到前缀提示优化向量;所述解码器模块用于根据前缀提示优化向量提取缺失句子中每个字的隐向量,得到第二隐向量;所述混合概率模块用于根据所述第一隐向量和所述第二隐向量确定缺失句子的预测值。
本发明还提供了一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行上述的神话诗歌修复方法。
本发明还提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述的神话诗歌修复方法。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明实施例基于相似度计算方法,确定待修复缺失句子的关联上下文句子集合,并由关联上下文句子集合构建待修复神话诗歌初始的前缀提示向量,不仅避免了不重要词汇与不同故事情节带来的干扰,又使得民间神话诗歌缺失句子生成过程中同时获得了上下文信息,从而提高了生成的缺失句子的上下文相关性和连贯性;基于混合概率生成网络构建神话诗歌修复模型,将初始的前缀提示向量和直连长序列输入神话诗歌修复模型中,使神话诗歌修复模型能够从与缺失句子直接连接的直连长序列中复制词汇,从而降低了民间神话诗歌中独有词汇生成的难度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的神话诗歌修复方法的流程图;
图2为本发明实施例提供的神话诗歌修复方法的一个更为具体的实现过程图;
图3为本发明实施例提供的关联上文句子获得方法的示意图;
图4为本发明实施例提供的神话诗歌修复模型的结构示意图;
图5为本发明实施例提供的神话诗歌修复系统的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例一
参见图1,本实施例的神话诗歌修复方法,包括:
步骤101:确定待修复神话诗歌中的缺失句子,得到待修复缺失句子。
步骤102:基于相似度计算方法,确定待修复缺失句子的关联上下文句子集合。
该步骤,具体包括:
(1)构建待修复缺失句子的完整上下文数据集;待修复缺失句子的完整上下文数据集为待修复神话诗歌中除待修复缺失句子之外的句子.
(2)采用训练好的Sentence-Bert网络提取待修复缺失句子的完整上下文数据集中每个句子的句特征向量,并计算句特征向量之间的余弦相似度确定待修复缺失句子的关联上下文句子集合。具体的:
完整上下文数据集包括:完整上文数据集和完整下文数据集,待修复缺失句子为s
首先,根据完整上文数据集构建关联上文句子集合。具体的:采用训练好的Sentence-Bert网络提取完整上文数据集中句子s
然后,根据完整下文数据集构建关联下文句子集合。具体的:采用训练好的Sentence-Bert网络提取完整上文数据集中句子s
步骤103:根据待修复缺失句子的关联上下文句子集合构建待修复神话诗歌初始的前缀提示向量。
该步骤,具体包括:将待修复缺失句子的关联上下文句子集合中每个句子的句特征向量组成句向量特征矩阵;将所述句向量特征矩阵作为待修复神话诗歌初始的前缀提示向量。
步骤104:将与待修复缺失句子直接相连的上下两个句子进行拼接,得到待修复神话诗歌的直连长序列。
该步骤,具体包括:将与待修复缺失句子直接相连的上文句子、分隔符以及与待修复缺失句子直接相连的下文句子依次拼接,得到待修复神话诗歌的直连长序列。
步骤105:将待修复神话诗歌初始的前缀提示向量和待修复神话诗歌的直连长序列输入神话诗歌修复模型中,得到待修复神话诗歌中的缺失句子的预测值。
其中,所述神话诗歌修复模型采用训练数据对混合概率生成网络进行训练得到;所述训练数据根据多篇未缺失的神话诗歌确定;所述混合概率生成网络包括:编码器模块、前缀调优模块、解码器模块和混合概率模块。
所述编码器模块用于提取直连长序列中每个字的隐向量,得到第一隐向量;所述前缀调优模块用于对初始的前缀提示向量进行优化,得到前缀提示优化向量;所述解码器模块用于根据前缀提示优化向量提取缺失句子中每个字的隐向量,得到第二隐向量;所述混合概率模块用于根据所述第一隐向量和所述第二隐向量确定缺失句子的预测值。
具体的,在根据所述第一隐向量和所述第二隐向量确定缺失句子的预测值方面,所述混合概率模块,具体用于:
计算所述第一隐向量Hi和所述第二隐向量
在一个示例中,所述神话诗歌修复模型的确定方法,具体包括:
(1)获取多篇未缺失的神话诗歌。
(2)对于任一未缺失的神话诗歌,随机选取未缺失的神话诗歌中的句子构建目标缺失句子数据集,并构建所述目标缺失句子数据集中每个目标缺失句子的完整上下文数据集;目标缺失句子的完整上下文数据集为未缺失的神话诗歌中除目标缺失句子之外的句子。
(3)根据所有未缺失的神话诗歌的目标缺失句子数据集和对应的完整上下文数据集,确定为训练数据。
(4)对于训练数据中任一目标缺失句子,采用训练好的Sentence-Bert网络提取目标缺失句子的完整上下文数据集中每个句子的句特征向量,并计算句特征向量之间的余弦相似度确定所述目标缺失句子的关联上下文句子集合。
(5)根据目标缺失句子的关联上下文句子集合中每个句子的句特征向量构建目标缺失句子初始的前缀提示向量。
(6)将与目标缺失句子直接相连的上下两个句子进行拼接,得到目标缺失句子的直连长序列。
(7)将所述训练数据中所有目标缺失句子初始的前缀提示向量和所有目标缺失句子的直连长序列输入所述混合概率生成网络,以损失函数最小为目标对所述混合概率生成网络进行多次迭代训练,并将训练好的混合概率生成网络确定为神话诗歌修复模型,具体的:
①将目标缺失句子初始的前缀提示向量输入前缀调优模块,得到目标缺失句子的前缀提示优化向量。
②将目标缺失句子的前缀提示优化向量和目标缺失句子的真实子序列输入解码器模块,得到目标缺失句子中每个字的隐向量。
③将目标缺失句子的直连长序列输入编码器模块得到目标缺失句子的直连长序列中每个字的隐向量。
④将目标缺失句子中每个字的隐向量和目标缺失句子的直连长序列中每个字的隐向量输入混合概率模块,以损失函数最小为目标对所述混合概率生成网络进行多次迭代训练,并将训练好的混合概率生成网络确定为神话诗歌修复模型。损失函数包括字词层面的交叉熵损失和句子层面的均方误差损失。
本实施例采用Sentence-Bert提取神话诗歌句子丰富的句特征向量,并通过比较句特征向量之间的余弦相似度,找到与神话诗歌缺失句子关联紧密的上下文句子,避免神话诗歌不重要词汇与不同故事情节的干扰;使用上下文句子的句特征向量构建前缀提示信息,充分利用上下文信息,指导神话缺失句子字符的生成;提出改进的混合概率生成网络,降低神话诗歌中独有词汇生成难度。本实施例提出的方法能有效提升神话诗歌缺失句子的上下文相关性和连贯性,为神话诗歌修复工作提供技术支持,推动文学的保护、传承与发展。
下面对本示例中混合概率生成网络的具体训练过程进行进一步详细说明,主要包括如下几个部分:
(1)数据预处理:在神话诗歌中选择诗歌句子作为目标缺失句子,构建神话诗歌数据集,将数据集划分为训练集和验证集,并根据诗歌句子间的语义关联程度,获取关联上下文句子集合。
(2)关联上下文句子特征提取:提取神话诗歌数据集中关联上下文句子的句特征,构建前缀提示向量,并将直接连接的关联上下文句子拼接成长句子,基于预训练语言模型提取与缺失句子直接连接的上长句和下长句中每个字的隐向量。
(3)神话诗歌缺失句子生成:使用构建的前缀提示向量指导神话诗歌缺失句子字符的生成,并利用直连长序列中每个字的隐向量提高神话诗歌独有词汇的输出概率,得到神话诗歌缺失句子的预测值。
(4)模型训练及神话诗歌修复:将神话诗歌训练集输入混合概率生成网络模型,计算损失函数并进行反向传播,迭代计算模型参数的权重,并使用训练好的模型对神话诗歌进行修复。
参见图2,下面对各个部分进行详细介绍。
1:数据预处理
1.1:神话诗歌数据集构建
1.1.1:目标缺失句子的确定
收集神话诗歌,将其记为
1.1.2:神话诗歌数据集划分
将神话诗歌缺失语句修复数据集D按照7∶3的比例,划分为神话诗歌缺失语句修复训练数据集D
1.2:关联上下文句子集合获取
由于神话诗歌篇幅长,难以将其缺失句子的所有上下文句子全部作为语言模型输入,考虑到缺失部分与整篇神话诗歌中不同位置的词汇和语句具有不同程度的关联,且不重要词汇与其他故事情节的干扰会导致生成的神话诗歌缺失句子质量下降。因此,采用能快速提取高质量语义信息的Sentence-Bert模型来提取神话诗歌句子中具有诗歌体裁语义信息的句特征,并使用余弦相似度(Cosine Similarity)衡量神话诗歌句子间的语义关联程度,在完整上下文数据集
(1)神话诗歌B
(2)使用Sentence-Bert提取句子
(3)将关联上文句子集合
(4)重复执行上述步骤(1)、(2)和(3),得到神话诗歌缺失语句修复数据集D中所有目标缺失句子的整体关联上下文集合
2:关联上下文句子特征提取
2.1:前缀提示向量构建
基于前缀提示向量的方式指导神话诗歌缺失句子生成,前缀提示向量越好,神话诗歌缺失句子的生成质量就越高。由于神话诗歌缺失句子的语义信息具有多样性,难以手动定义最佳前缀提示向量,故使用前缀调优模块自动学习最佳前缀提示向量。考虑到前缀提示向量搜索速度和最终值较大程度上取决于其初始值,且神话诗歌缺失句子与其上下文句子具有连贯性和相关性,故使用获得的关联上下文集合
2.2:直连长序列字特征提取
针对神话诗歌中独有词汇生成困难的问题,考虑到这些独有词汇在近邻句子中会重复出现的特点,将关联上下文集合
3:神话缺失句子生成
混合概率生成网络由一个编码器模块、一个前缀调优模块、一个解码器模块和一个混合概率模块组成,编码器模块用于提取与缺失句子直接连接的上下文句子中每个字的隐向量,即第一隐向量,前缀调优模块基于关联上下文集合数据自动学习前缀提示向量,解码器模块基于前缀提示向量生成缺失句子的字隐向量,即第二隐向量,从而基于两种字隐向量实现缺失句子生成。
3.1:直连长序列语义特征向量获取
将步骤2.1得到的句特征向量矩阵S
其中,W
再根据公式(3-3),将注意力权重
其中,
3.2:神话诗歌缺失句子生成
为缓解神话诗歌中独有词汇生成困难、并保留模型产生新词汇能力,混合概率模块如公式(3-4)所示,将生成概率P
P=θP
其中,θ为生成概率P
其中,W
基于步骤3.1的当前位置直连长序列语义特征
其中,W
混合概率模块的复制层根据公式(3-7)统计当前位置输出字的复制概率P
其中,ω为词汇表中的任意字符。
最后,取P最大时对应的字符作为当前位置缺失句子的输出字
4:模型训练及神话诗歌修复
4.1损失函数的构建和计算
使用Sentence-Bert提取生成神话诗歌缺失句子的句特征向量,并对其进行均方误差(Mean Squared Error)惩罚,以提高生成缺失句子整体语义性。损失函数
(1)字词层面的交叉熵损失
其中,P(y)为目标缺失句子中字的概率值,
(2)句子层面的均方误差损失
其中,
(3)损失函数
其中,λ(0<λ<1)是为平衡交叉熵损失与均方误差损失的超参数。
4.2:模型参数的迭代更新
将步骤2.1得到的前缀提示向量和步骤2.2得到的直连长序列作为输入,对混合概率生成网络模型进行训练。首先加载bert-base-chinese预训练模型参数作为编码器模块的初始化参数,gpt2-chinese-cluecorpussmall预训练模型参数作为解码器模块的参数且后续不进行更新,对前缀调优模块和生成网络的参数进行随机初始化,接着对步骤3.2中总体损失函数的各参数计算其梯度值,采用Adam优化算法迭代更新网络模型的权重参数:
其中,β
4.3:神话诗歌缺失句子修复
按照本示例的思想,神话诗歌缺失句子修复任务被视为序列预测任务。待修复神话诗歌首先通过步骤1.2获取其缺失句子的关联上下文集合,并按照步骤2.1使用关联上下文集合构建前缀提示向量,然后按照步骤2.2将与缺失句子直接相连的上下两个句子拼接成直连长序列。将前缀提示向量和直连长序列输入到步骤4.2训练好的混合概率生成网络模型中,迭代执行步骤3.1和步骤3.2,依次得到输出字符,将其按输出顺序拼接得到输出序列,并作为解码器的输入序列,直到输出字符为终止字符[EOS]时结束,最后的输出序列即为神话诗歌缺失句子。
上述神话诗歌修复方法是基于混合概率生成网络的神话诗歌缺失句子修复方法,采用Sentence-Bert提取神话诗歌句子具有诗歌语义信息的句特征向量,计算句特征向量之间的余弦相似度,找到与神话诗歌缺失句子关联紧密的上下文句子,解决语言模型输入文本长度受限制的问题,同时,避免不重要词汇与其他故事情节的干扰;使用关联紧密上下文句子的句特征向量构建前缀提示信息,充分利用上下文信息,更细粒度地指导缺失句子字符的生成,提高生成的神话诗歌缺失句子的上下文相关性和连贯性;提出基于混合概率的字符生成模型,降低神话诗歌中独有词汇生成难度,提高神话诗歌缺失句子的生成质量。
下面给出一个实际应用中的具体实例,对上述神话诗歌修复方法的实现过程进行说明。
本具体实例对《云南少数民族古典史诗全集》中的民间神话诗歌《人类和万物的来源》,修复其中缺失的句子。
1:数据预处理
按照步骤1.1,将《云南少数民族古典史诗全集》收录的40篇民间神话诗歌作为初始数据集
按照步骤1.2,获取目标缺失诗句的关联上下文句子集合。图3示出了判断能否加入关联上文句子集合
在诗歌《人类和万物的来源》未缺失句子{“天地哪里来?”,...,“代代传唱《创世歌》!”}中找到与缺失句子“锁虚的篾活做得好,后人封她为篾神。”语义关联紧密的句子,假设目前关联上文集合
2:关联上下文句子特征提取
按照步骤2.1,使用Sentence-Bert获得关联上下文集合
按照步骤2.2,将“伐木破竹盖新房,”和“先要祭奠他。”拼接得到直接连接上长句“伐木破竹盖新房,先要祭奠他。”,将“篾匠师傅做篾活,”和“要把篾神祭。”拼接得到直接连接下长句“篾匠师傅做篾活,要把篾神祭。”,并用特殊字符[SEP]分隔组成一个长度为29的直连长序列“伐木破竹盖新房,先要祭奠他。[SEP]篾匠师傅做篾活,要把篾神祭。”,将其输入编码器中,得到直连长序列中每个字的隐向量矩阵
3:民间神话缺失句子生成
按照步骤3.1,句特征向量矩阵S
表1前缀调优模块特征维度变换
将前缀调优模块的第3个全连接层输出特征向量的维度变换为9×24×12×64,得到连续前缀提示向量矩阵
表2直连长序列注意力权重示例
根据公式(3-3)将注意力权重
按照步骤3.2,根据公式(3-5)计算得到当前位置输出字的生成概率P
4:模型训练及民间神话诗歌修复
按照步骤4.1,将民间神话诗歌训练集D
按照步骤4.2,设定一阶矩衰减系数β
按照步骤4.3,使用训练好的混合概率生成网络模型对缺损的民间神话诗歌进行修复,图4示出了基于混合概率生成网络的神话诗歌修复模型的结构。
上述所有实施例的神话诗歌修复方法,具有如下优点:
本发明提出了一种基于提示学习和混合概率生成网络的字符序列生成模型,实现民间神话诗歌缺失句子修复,克服了公知技术未充分利用上下文信息和独有词汇生成困难等不足,为与民间神话诗歌类似的特殊领域文本修复提供了新的解决方案。
本发明提出了一种关联上下文句子划分方法,并使用获得的紧密关联上下文句子的句特征向量构建连续前缀提示向量,不仅避免了不重要词汇与不同故事情节带来的干扰,又使得民间神话诗歌缺失句子生成过程中同时获得了上下文信息,从而提高了生成的缺失句子的上下文相关性和连贯性。
本发明基于混合概率生成网络,通过将民间神话诗歌缺失句子的字输出概率分为生成概率和复制概率,使语言模型能够从与缺失句子直接连接的长序列中复制词汇,从而降低了民间神话诗歌中独有词汇生成的难度。
实施例二
为了执行上述实施例一对应的方法,以实现相应的功能和技术效果,下面提供一种神话诗歌修复系统。
参见图5,所述系统,包括:
待修复缺失句子确定单元501,用于确定待修复神话诗歌中的缺失句子,得到待修复缺失句子。
关联上下文句子确定单元502,用于基于相似度计算方法,确定待修复缺失句子的关联上下文句子集合。
初始前缀提示向量构建单元503,用于根据待修复缺失句子的关联上下文句子集合构建待修复神话诗歌初始的前缀提示向量。
直连长序列拼接单元504,用于将与待修复缺失句子直接相连的上下两个句子进行拼接,得到待修复神话诗歌的直连长序列。
缺失句子预测单元505,用于将待修复神话诗歌初始的前缀提示向量和待修复神话诗歌的直连长序列输入神话诗歌修复模型中,得到待修复神话诗歌中的缺失句子的预测值。
其中,所述神话诗歌修复模型采用训练数据对混合概率生成网络进行训练得到;所述训练数据根据多篇未缺失的神话诗歌确定;所述混合概率生成网络包括:编码器模块、前缀调优模块、解码器模块和混合概率模块。
所述编码器模块用于提取直连长序列中每个字的隐向量,得到第一隐向量;所述前缀调优模块用于对初始的前缀提示向量进行优化,得到前缀提示优化向量;所述解码器模块用于根据前缀提示优化向量提取缺失句子中每个字的隐向量,得到第二隐向量;所述混合概率模块用于根据所述第一隐向量和所述第二隐向量确定缺失句子的预测值。
实施例三
本实施例提供一种电子设备,包括存储器及处理器,存储器用于存储计算机程序,处理器运行计算机程序以使电子设备执行实施例一的神话诗歌修复方法。
可选地,上述电子设备可以是服务器。
另外,本发明实施例还提供一种计算机可读存储介质,其存储有计算机程序,该计算机程序被处理器执行时实现实施例一的神话诗歌修复方法。
本发明针对现有技术没有充分利用上下文信息、未考虑神话诗歌中独有词汇生成困难等不足,基于语义相似度获得与缺失句子关联紧密的上下文句子,提取其句特征向量构建用于指导缺失句子字符生成的前缀提示向量,充分利用上下文信息,并基于混合概率的方式降低神话诗歌中独有词汇生成难度,为神话诗歌修复工作提供技术支持。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 电子设备系统自修复方法、装置、设备及介质
- 一种分布式系统部署方法、系统、电子设备及存储介质
- 一种操作系统的预安装方法、系统、电子设备及存储介质
- 一种用于化妆间盒子的交易方法、系统、电子设备及存储介质
- 一种日志处理方法、系统及电子设备和存储介质
- 一种睡眠修复配方方法及系统、存储介质、电子设备
- 一种修复固件bug的方法、系统、电子设备及存储介质