一种基于深度学习的复合音频实时传输方法及系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及音频传输领域,特别是一种基于深度学习的复合音频实时传输方法及系统。
背景技术
在生活中涉及很多复合音频传输情况,例如在电脑端同时播放音乐和人声,并传输至广播中供人们收听;或者耳机采集外界音频后,在耳机内部进行音频复合、降噪等处理,传输至人耳内等等。在音频复合处理和传输处理过程中会存在多种问题,例如音频噪音过大,音频传输失真等,所以需要解决音频复合处理和传输处理过程出现的问题。获取一种基于深度学习的复合音频实时传输方法,能够提高传输效率,对生活中的音频传输方面起良好效果。
发明内容
本发明克服了现有技术的不足,提供了一种基于深度学习的复合音频实时传输方法及系统。
为达到上述目的,本发明采用的技术方案为:
本发明第一方面提供了一种基于深度学习的复合音频实时传输方法,包括以下步骤:
通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
进一步的,本发明的一个较佳实施例中,所述通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频,具体为:
确定目标音频信息,通过音频采集设备,获取包含目标音频信息的音频,并构建音频存储库,将采集获取的音频导入音频存储库中进行存储;
在所述音频存储库中,对采集音频进行音频预处理,所述音频预处理包括将采集的音频进行回声消除处理、音频增强处理和静音剪裁处理,得到处理音频;
将所述处理音频转化为处理音频样本,并通过傅里叶变换对所述处理音频样本进行特征提取,得到处理音频样本特征数据;
构建音频中心,并对所述音频中心进行初始化处理,一个音频中心代表一个类别的处理音频,引入模糊聚类法对处理音频样本特征数据进行迭代计算,得到迭代计算结果,所述迭代计算为反复计算处理音频样本特征数据与音频中心的欧氏距离;
基于所述迭代计算结果,计算每个音频处理样本与音频中心的隶属度,并根据每个音频处理样本与音频中心的隶属度,对音频处理样本进行划分,得到不同类别的处理音频。
进一步的,本发明的一个较佳实施例中,所述对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频,具体为:
计算目标音频信息与不同类别处理音频之间的欧氏距离,并预设欧氏距离区间;
基于所述欧氏距离区间,若存在目标音频信息与任意处理音频之间的欧氏距离在同一欧氏距离区间中,则将对应类别的处理音频定义为目标处理音频;
对所述目标处理音频进行数字编码,并结合混音算法,对数字编码后的目标处理音频进行音频复合处理,得到复合处理音频;
获取复合处理音频的时域特征和能量分布特征,并引入自适应滤波器,所述自适应滤波器基于所述复合处理音频的时域特征和能量分布特征,生成权重系数,并基于所述权重系数,对自适应滤波器进行自适应训练,得到训练后的自适应滤波器;
将所述复合处理音频导入至训练后的自适应滤波器中进行噪声相位和噪声反相位获取,将复合处理音频的噪声相位和噪声反相位结合,得到初步复合音频;
对所述初步复合音频进行音频幅度自适应调整,得到复合音频。
进一步的,本发明的一个较佳实施例中,所述基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整,具体为:
将大数据网络与所述音频存储库连接,使所述音频存储库在大数据网络中下载人声音频声纹信息储存;
预设一帧音频的时间,基于所述一帧音频的时间,将所述复合音频进行分帧处理,得到复合音频帧;
对所有的复合音频帧进行线性编码处理,得到复合音频帧线性编码结果,并将所有复合音频帧线性编码结果合成,生成一类复合音频声纹信息;
计算所述人声音频声纹信息和一类复合音频声纹信息之间的马氏距离,并构建人声音频声纹马氏距离区间,对马氏距离在人声音频声纹马氏距离区间内的一类复合音频声纹信息进行特征提取,定义为一类人声音频声纹信息;
将剩余的复合音频声纹信息定义为二类复合音频声纹信息,对二类复合音频声纹信息进行声纹图构建,得到二类复合音频声纹图,所述二类复合音频声纹图中包含二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数;
引用支持向量机,将二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数导入所述支持向量机中,得到二类人声音频声纹信息和其他音频声纹信息,所述支持向量机用于二类复合音频声纹信息的特征分类处理;
基于各类音频声纹信息将复合音频分为人声降噪音频和环境降噪音频,获取复合音频的传输性质,基于所述复合音频的传输性质,对复合音频中的人声降噪音频和环境降噪音频进行音频输出调整,得到输出调整复合音频。
进一步的,本发明的一个较佳实施例中,所述对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正,具体为:
获取音频传输设备,所述输出调整复合音频通过音频传输设备,向目标设备实时传输输出调整复合音频,在输出调整复合音频传输过程中,获取输出调整后复合音频频率图;
获取输出调整前复合音频频率图,输出调整前后复合音频频率图中均含有音频频率值,将输出调整前后的复合音频频率图进行频率图重合分析,得到频率图重合率,若频率图重合率在预设范围内,则判断频率图中是否存在输出调整前后复合音频频率值的差值大于预设值的情况;
若是,则将输出调整前后复合音频频率值的差值大于预设值的对应音频进行标记,并通过大数据网络检索获取音频频率修正方法输出;
若不是,则不需要对音频传输后的调整复合音频进行修正;
若频率图重合率不在预设范围内,则获取输出调整前后复合音频频率值的差值大于预设值的输出调整后复合音频帧,定义为异常复合音频帧;
获取异常复合音频帧的失真原因,并进行相应修正处理,得到修正复合音频。
进一步的,本发明的一个较佳实施例中,所述获取异常复合音频帧的失真原因,并进行相应修正处理,得到修正复合音频,具体为:
对所述异常复合音频帧进行失真分析,获取异常复合音频帧的失真类型和失真程度;
构建复合音频模型,并将异常复合音频帧的类型和失真程度导入所述复合音频模型中进行模型更新处理,得到异常复合音频模型;
基于所述异常复合音频模型,获取异常复合音频帧的时域特征和频域特征,基于所述异常复合音频帧的时域特征和频域特征,对异常复合音频帧进行重采样处理和插值处理,并在重采样处理和插值处理过程中通过迭代算法计算异常复合音频帧的信噪比及频率值;
当异常复合音频帧的信噪比及频率值均在标准范围内,停止迭代计算,生成修正复合音频帧,并对所有的修正复合音频帧进行音频帧合成处理,输出修正复合音频。
本发明第二方面还提供了一种基于深度学习的复合音频实时传输系统,所述复合音频实时传输系统包括存储器与处理器,所述存储器中储存有复合音频实时传输方法,所述复合音频实时传输方法被所述处理器执行时,实现如下步骤:
通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
本发明解决的背景技术中存在的技术缺陷,本发明具备以下有益效果:对采集音频进行音频预处理和音频分类处理,得到不同类别的处理音频,并对不同类别的处理音频进行复合与降噪处理,得到复合音频;通过对复合音频进行声纹分析,调整复合音频的音频输出效果,最后对复合音频在音频传输过程中出现的失真情况进行分析及修正。本发明能够在复合音频传输前进行音频预处理,并在传输过程中改善传输情况,提高传输效率,对生活中的音频传输方面起良好效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他实施例的附图。
图1示出了一种基于深度学习的复合音频实时传输方法的流程图;
图2示出了基于复合音频传输情况,获取复合音频失真情况,并对复合音频进行修正的方法流程图;
图3示出了一种基于深度学习的复合音频实时传输系统的视图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
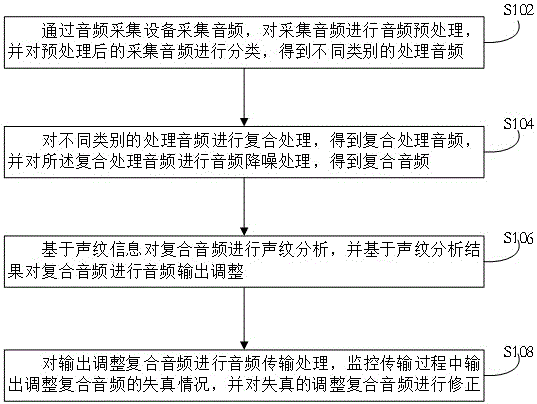
图1示出了一种基于深度学习的复合音频实时传输方法的流程图,包括以下步骤:
S102:通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
S104:对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
S106:基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
S108:对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
进一步的,本发明的一个较佳实施例中,所述通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频,具体为:
确定目标音频信息,通过音频采集设备,获取包含目标音频信息的音频,并构建音频存储库,将采集获取的音频导入音频存储库中进行存储;
在所述音频存储库中,对采集音频进行音频预处理,所述音频预处理包括将采集的音频进行回声消除处理、音频增强处理和静音剪裁处理,得到处理音频;
将所述处理音频转化为处理音频样本,并通过傅里叶变换对所述处理音频样本进行特征提取,得到处理音频样本特征数据;
构建音频中心,并对所述音频中心进行初始化处理,一个音频中心代表一个类别的处理音频,引入模糊聚类法对处理音频样本特征数据进行迭代计算,得到迭代计算结果,所述迭代计算为反复计算处理音频样本特征数据与音频中心的欧氏距离;
基于所述迭代计算结果,计算每个音频处理样本与音频中心的隶属度,并根据每个音频处理样本与音频中心的隶属度,对音频处理样本进行划分,得到不同类别的处理音频。
需要说明的是,在音频采集现场中,可能会同时采集到多种种类的音频,例如背景音乐、背景噪声、人声等,在音频进行复合传输之前应当对采集的音频进行预处理和分类处理,方便接下来对采集音频的进一步处理以及提高传输效率效果。所述回声消除处理为若采集的音频存在回声现象则需要消除回声,提高传输效果;所述静音剪裁处理为在一段采集音频中可能存在音频是静音状态,为提高传输效率,需要精心处理得到处理音频。使用模糊聚类法通过计算处理音频样本与音频中心的隶属度,实现对处理音频的分类。本发明能够通过对采集音频进行预处理和分类,提高音频传输效率。
进一步的,本发明的一个较佳实施例中,所述对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频,具体为:
计算目标音频信息与不同类别处理音频之间的欧氏距离,并预设欧氏距离区间;
基于所述欧氏距离区间,若存在目标音频信息与任意处理音频之间的欧氏距离在同一欧氏距离区间中,则将对应类别的处理音频定义为目标处理音频;
对所述目标处理音频进行数字编码,并结合混音算法,对数字编码后的目标处理音频进行音频复合处理,得到复合处理音频;
获取复合处理音频的时域特征和能量分布特征,并引入自适应滤波器,所述自适应滤波器基于所述复合处理音频的时域特征和能量分布特征,生成权重系数,并基于所述权重系数,对自适应滤波器进行自适应训练,得到训练后的自适应滤波器;
将所述复合处理音频导入至训练后的自适应滤波器中进行噪声相位和噪声反相位获取,将复合处理音频的噪声相位和噪声反相位结合,得到初步复合音频;
对所述初步复合音频进行音频幅度自适应调整,得到复合音频。
需要说明的是,音频传输需要进行复合处理,且所述目标音频为需要传输的音频类别,所以需要获取目标音频信息,并通过计算与不同类别处理音频之间的欧式距离,获取相似度,根据相似度大小获取目标处理音频。数字编码和混音算法可以对目标处理音频进行复合,得到复合处理音频。由于所述复合处理音频中可能存在多种噪音,比如环境中的风噪、背景噪音等,所以需要通过自适应滤波器对复合处理音频进行自适应滤波,所述自适应滤波通过将复合处理音频的噪声相位和噪声反相位相结合,形成相位抵消,实现降噪处理,并通过对音频幅度的自适应调整,得到复合音频。本发明能够通过对不同类别的处理音频进行复合处理和滤波处理,得到复合音频。
进一步的,本发明的一个较佳实施例中,所述基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整,具体为:
将大数据网络与所述音频存储库连接,使所述音频存储库在大数据网络中下载人声音频声纹信息储存;
预设一帧音频的时间,基于所述一帧音频的时间,将所述复合音频进行分帧处理,得到复合音频帧;
对所有的复合音频帧进行线性编码处理,得到复合音频帧线性编码结果,并将所有复合音频帧线性编码结果合成,生成一类复合音频声纹信息;
计算所述人声音频声纹信息和一类复合音频声纹信息之间的马氏距离,并构建人声音频声纹马氏距离区间,对马氏距离在人声音频声纹马氏距离区间内的一类复合音频声纹信息进行特征提取,定义为一类人声音频声纹信息;
将剩余的复合音频声纹信息定义为二类复合音频声纹信息,对二类复合音频声纹信息进行声纹图构建,得到二类复合音频声纹图,所述二类复合音频声纹图中包含二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数;
引用支持向量机,将二类复合音频声纹信息的光滑度参数、激活度参数和谐波参数导入所述支持向量机中,得到二类人声音频声纹信息和其他音频声纹信息,所述支持向量机用于二类复合音频声纹信息的特征分类处理;
基于各类音频声纹信息将复合音频分为人声降噪音频和环境降噪音频,获取复合音频的传输性质,基于所述复合音频的传输性质,对复合音频中的人声降噪音频和环境降噪音频进行音频输出调整,得到输出调整复合音频。
需要说明的是,在复合音频中,存在多种人声音频,背景音乐音频等,若目标传输信息中存在某种人声音频需要音调较高,则需要对复合音频进行音频输出调整,使复合音频能满足目标传输信息的要求。不同人声的声纹信息不同,在大数据中获取人声音频的声纹信息,并基于复合音频帧获取一类复合音频声纹信息,通过计算人声音频声纹信息和一类复合音频声纹信息之间的马氏距离,得到一类人声声纹信息。由于在大数据网络中可能不含有所有人的人声声纹信息,所以需要对人声声纹信息进行进一步提取,人声声纹信息和背景声音的声纹信息的光滑度参数、激活度参数和谐波参数可能存在区别,通过支持向量机能够对声纹信息进行分类,实现进一步提取人声音频声纹信息,得到二类人声音频声纹信息和其他音频声纹信息。根据各种类的音频声纹信息能够对复合音频进行音频识别,所述复合音频的传输性质即目标传输信息的传输要求,根据复合音频的传输性质,对复合音频进行输出调整。本发明能够通过对复合音频进行声纹分类和声纹分析,实现对复合音频的音频输出调整。
图2示出了基于复合音频传输情况,获取复合音频失真情况,并对复合音频进行修正的方法流程图,具体为:
S202:基于输出调整前后复合音频频率图的重合率,获取输出调整复合音频的失真情况;
S204:获取异常复合音频帧,以及异常复合音频帧的失真类型和失真程度,从而构建异常复合音频模型;
S206:基于所述异常复合音频模型,对异常复合音频帧进行修正处理,得到修正复合音频。
进一步的,本发明的一个较佳实施例中,所述基于输出调整前后复合音频频率图的重合率,获取输出调整复合音频的失真情况,具体为:
获取音频传输设备,所述输出调整复合音频通过音频传输设备,向目标设备实时传输输出调整复合音频,在输出调整复合音频传输过程中,获取输出调整后复合音频频率图;
获取输出调整前复合音频频率图,输出调整前后复合音频频率图中均含有音频频率值,将输出调整前后的复合音频频率图进行频率图重合分析,得到频率图重合率,若频率图重合率在预设范围内,则判断频率图中是否存在输出调整前后复合音频频率值的差值大于预设值的情况;
若是,则将输出调整前后复合音频频率值的差值大于预设值的对应音频进行标记,并通过大数据网络检索获取音频频率修正方法输出;
若不是,则不需要对音频传输后的调整复合音频进行修正。
需要说明的是,输出调整复合音频在进行传输过程中,可能由于多种原因造成失真,失真的结果是输出调整复合音频的频率出现异常,所以需要获取输出调整前后复合音频的频率图并进行重合率分析,重合率越高证明输出调整后复合音频的失真现象越低。当重合率在预设范围内是,也有可能是某处音频失真现象较大,但其他音频无失真现象,使平均值被降低,所以需要继续分析。判断频率图中是否存在输出调整前后复合音频频率值的差值大于预设值的情况,若是则证明复合音频中存在失真现象较大处,需要进行修正;若不是,则直接输出复合音频。本发明能够通过对复合音频进行失真情况分析,判断重合率,并采取相应修正方法。
进一步的,本发明的一个较佳实施例中,所述基于所述异常复合音频模型,对异常复合音频帧进行修正处理,得到修正复合音频,具体为:
基于所述异常复合音频模型,获取异常复合音频帧的时域特征和频域特征,基于所述异常复合音频帧的时域特征和频域特征,对异常复合音频帧进行重采样处理和插值处理,并在重采样处理和插值处理过程中通过迭代算法计算异常复合音频帧的信噪比及频率值;
当异常复合音频帧的信噪比及频率值均在标准范围内,停止迭代计算,生成修正复合音频帧,并对所有的修正复合音频帧进行音频帧合成处理,输出修正复合音频。
需要说明的是,当频率图重合率不在预设范围内,证明当前复合音频失真效果较严重,需要进行修正处理。所述异常复合音频帧为当前帧的复合音频处于频率偏差值较大状态,构建异常复合音频模型目的是方便获取异常复合音频帧的特征参数。通过异常复合音频帧的时域特征和频域特征可以获取当前异常复合音频帧的异常状态,所述重采样处理能改变音频的采样率,调整音频,减少失真;所述插值处理能补偿因失真而导致缺失的音频,迭代算法能够持续对异常复合音频帧进行迭代计算,并分析信噪比和频率值,直至达到标准,从而后去修正复合音频。本发明能够过异常复合音频帧进行修复,获取修正复合音频。
此外,所述一种基于深度学习的复合音频实时传输方法,还包括以下步骤:
当频率图重合率不在预设范围内,则获取输出调整前后复合音频频率值的总差值,获取音频传输设备的工作温度,并使用灰色关联法计算音频传输设备的工作温度与输出调整前后复合音频频率值的总差值之间的关联性,得到第一关联值;
若所述第一关联值在预设范围内,则继续通过灰色关联法计算环境温度与音频传输设备的工作温度之间的关联性,得到第二关联值;
若所述第二关联值在预设范围内,则将音频传输设备的工作状态定义为第一异常状态,若所述第二关联值不在预设范围内,则将音频传输设备的工作状态定义为第二异常状态;
若音频传输设备输出第一异常状态,则对所述音频传输设备进行保护处理,保护处理包括对音频传输设备进行外部冷却及外部防护,使音频输出设备的工作温度回落并保持在正常温度;
若音频传输设备输出第二异常状态,则获取当前音频传输设备的实时工作参数,并基于构建马尔可夫模型对音频传输设备的实时工作参数进行分析,得到工作状态转移概率值,使用贝叶斯网络分析所述工作状态转移概率值,得到音频传输设备的故障位置;
对所述音频传输设备的故障位置进行相应修复,并实时监控音频传输设备的工作温度,使音频输出设备的工作温度回落并保持在正常温度。
需要说明的是,频率图重合率不在预设范围内证明复合音频失真现象较严重,可能使音频传输设备出现了问题。当音频传输设备工作温度过高时,音频传输设备工作性能会相应减小,负载增大,影响复合音频传输,可能给复合音频带来失真。使音频传输设备工作温度过高可能是环境温度过高,或者内部出现故障,导致工作温度过高。所述第一异常状态为环境温度过高影响工作温度,对环境温度进行调控并通过外部物理降温即可。所述第二异常状态为内部出现故障,导致工作温度过高,通过马尔可夫模型和贝叶斯网络能够定位音频传输模型的故障位置并进行修复。本发明能够通过对音频传输设备进行工作温度分析以及故障检测修正,维持复合音频不失真。
此外,所述一种基于深度学习的复合音频实时传输方法,还包括以下步骤:
若所述第一关联值不在预设范围内,则将音频传输设备的工作状态定义为第三异常状态;
若音频传输设备输出第三异常状态,则获取输出调整前后复合音频之间的音频传输时间,并获取标准音频传输时间,从而获取音频传输时间差;
若所述音频传输时间差大于预设值,则基于所述音频传输时间差,结合互相关函数,计算获取输出调整复合音频时延频率;
获取音频传输设备周边的电磁感应设备,结合音频传输设备和电磁感应设备,构建电磁感应系统模型,在所述电磁感应系统模型中对所述音频传输设备进行模拟电磁感应强度调控,同时实时获取音频传输设备的负载变化情况和输出调整复合音频时延频率变化情况;
若音频传输设备的负载程度在预设值内,且输出调整复合音频时延频率维持在预设范围内,则直接对电磁感应设备进行电磁感应强度调控;
若音频传输设备的负载程度和输出调整复合音频时延频率均不在预设值内,则基于大数据获取音频传输设备的各种网络拓扑结构,在电磁感应系统模型中应用各种网络拓扑结构从而对输出调整复合音频时延频率进行分析,并选取输出调整复合音频时延频率与标准值相似度最高的网络拓扑结构输出;
若更换网络拓扑结构后输出调整复合音频时延频率仍不在预设范围内,则在音频传输设备中接入低时延编解码器,调整输出调整复合音频时延频率,实现输出调整复合音频时延补偿。
需要说明的是,复合音频传输过程中失真,若不是与音频传输设备工作温度相关,则判断为音频传输设备的通信状态出现问题。音频传输设备的通信状态出现问题,则会使复合音频出现时延失真,影响复合音频同步性和完整性。所述音频传输时间差即为输出调整复合音频时延性。所述输出调整复合音频时延频率反映了复合音频的时延状态。复合音频出现时延失真原因可能为周边电磁设备的电磁感应强度过高,对音频传输设备的负载会造成相应影响,负载过高,在音频传输设备中会造成网络拥堵、丢包率升高,从而造成复合音频出现时延失真。对电磁感应强度进行调控能控制音频传输设备的负载值,从而降低复合音频时延失真程度。若电磁感应强度调控后音频传输设备的负载值仍较高,则判断音频传输设备中的网络拓扑结构不正常,可能是网络节点较少,导致网络出现拥堵情况。改变网络拓扑结构,降低负载值,使输出调整复合音频时延频率维持在正常范围内;当更换网络拓扑结构后输出调整复合音频时延频率仍不在预设范围内,则直接使用外部设备进行时延补偿。本发明能够通过对电磁感应强度进行调控,以及更改网络拓扑结构,改善复合音频的时延失真情况。
如图3所示,本发明第二方面还提供了一种基于深度学习的复合音频实时传输系统,所述复合音频实时传输系统包括存储器31与处理器32,所述存储器31中储存有复合音频实时传输方法,所述复合音频实时传输方法被所述处理器32执行时,实现如下步骤:
通过音频采集设备采集音频,对采集音频进行音频预处理,并对预处理后的采集音频进行分类,得到不同类别的处理音频;
对不同类别的处理音频进行复合处理,得到复合处理音频,并对所述复合处理音频进行音频降噪处理,得到复合音频;
基于声纹信息对复合音频进行声纹分析,并基于声纹分析结果对复合音频进行音频输出调整;
对输出调整复合音频进行音频传输处理,监控传输过程中输出调整复合音频的失真情况,并对失真的调整复合音频进行修正。
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 一种基于单芯片的网络音频传输系统及方法
- 一种基于深度学习的实时视频传输自适应前向纠错方法和系统
- 基于实时传输协议的双向音频映射系统及方法